
Deep Q-Learning-Based Buffer-Aided Relay Selection for Reliable and Secure Communications in Two-Hop Wireless Relay Networks

 , ,
, ,
Abstract
1. Introduction
2. Related Work
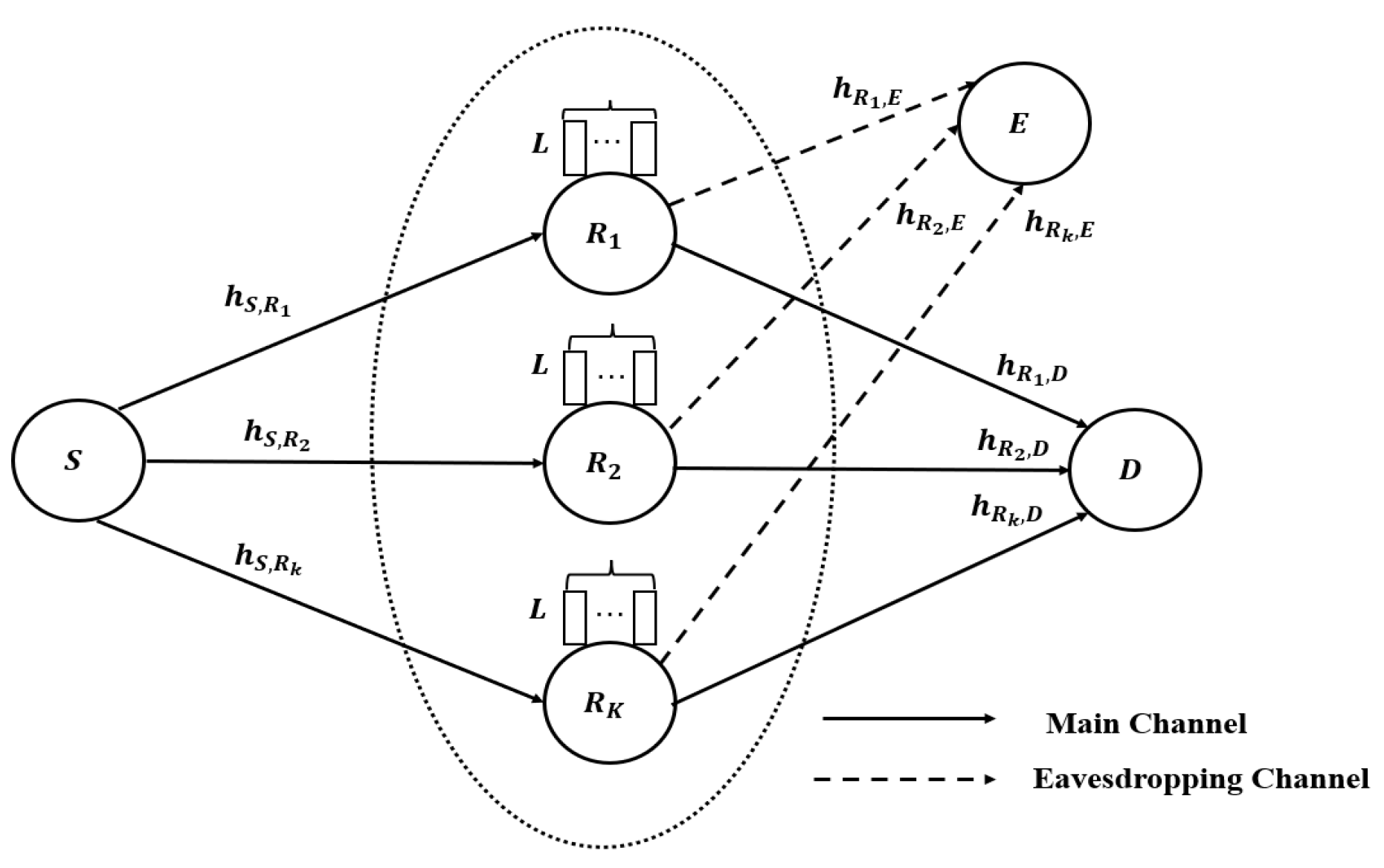
- To propose a DQL-based buffer-aided relay selection scheme, we first analyze the communication model of a two-hop AF buffer-aided relay network with the presence of a passive eavesdropper and then model the information transmission process as an MDP.
- We then propose a DQL-based buffer-aided relay selection scheme to optimize the above MDP. In the proposed scheme, we consider both the legal channel states and eavesdropping channel states, buffer states, target rate and target secrecy rate and use DNNs to fit the Q-function and select the link with the maximum Q-function value each time.
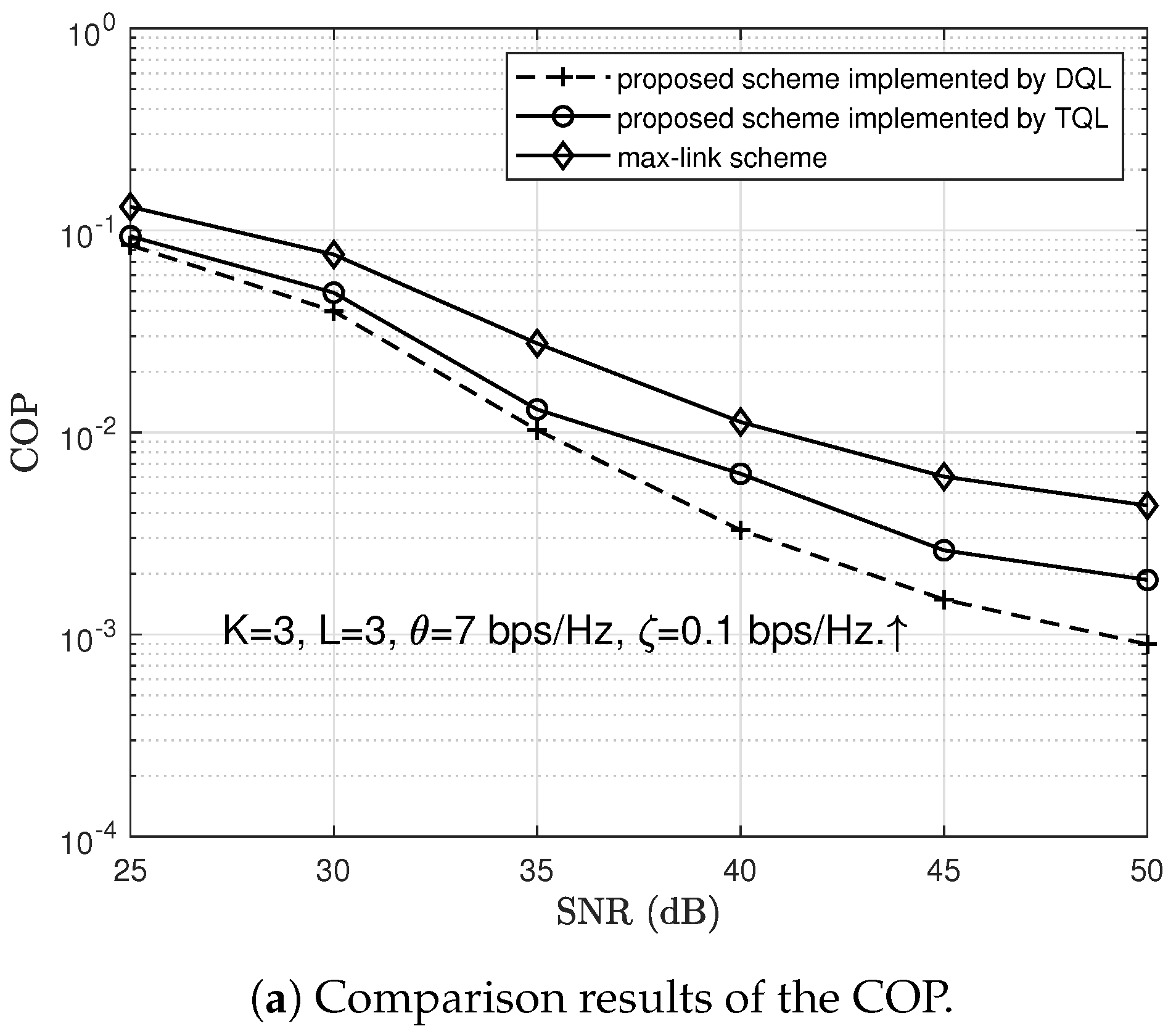
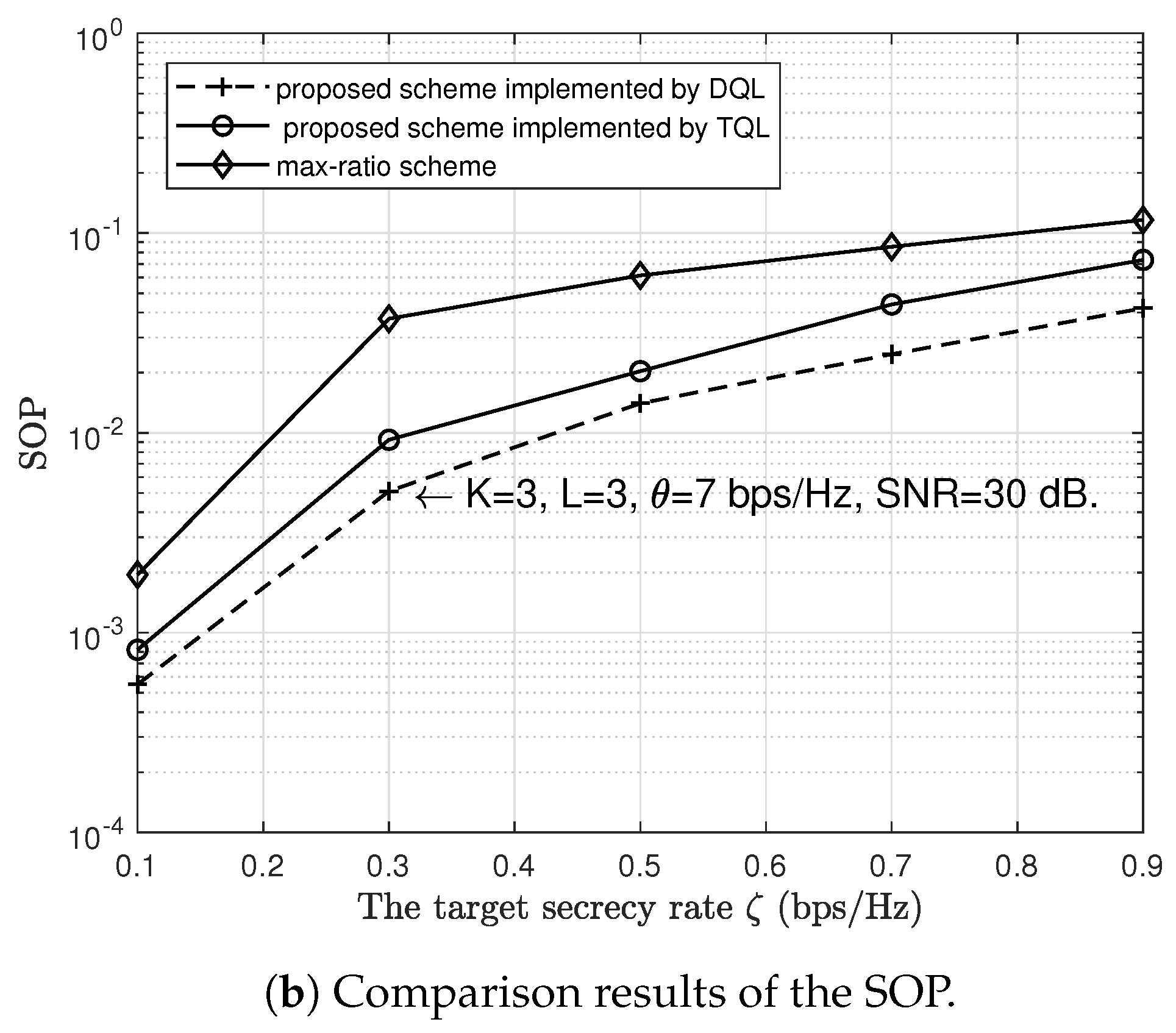
- Finally, we verify the reliability and security performances of the proposed scheme by using Monte Carlo simulations. The reliability and security performances are measured by the COP and the SOP, respectively. Simulation results demonstrate that the proposed scheme can achieve reliable and secure communications. We also compare the COP and SOP of the proposed scheme with the max-link and max-ratio schemes, respectively. The comparison results show that the proposed scheme outperforms max-ratio schemes in terms of security performance.
3. System Model
4. The Framework of Information Transmission Based on MDP
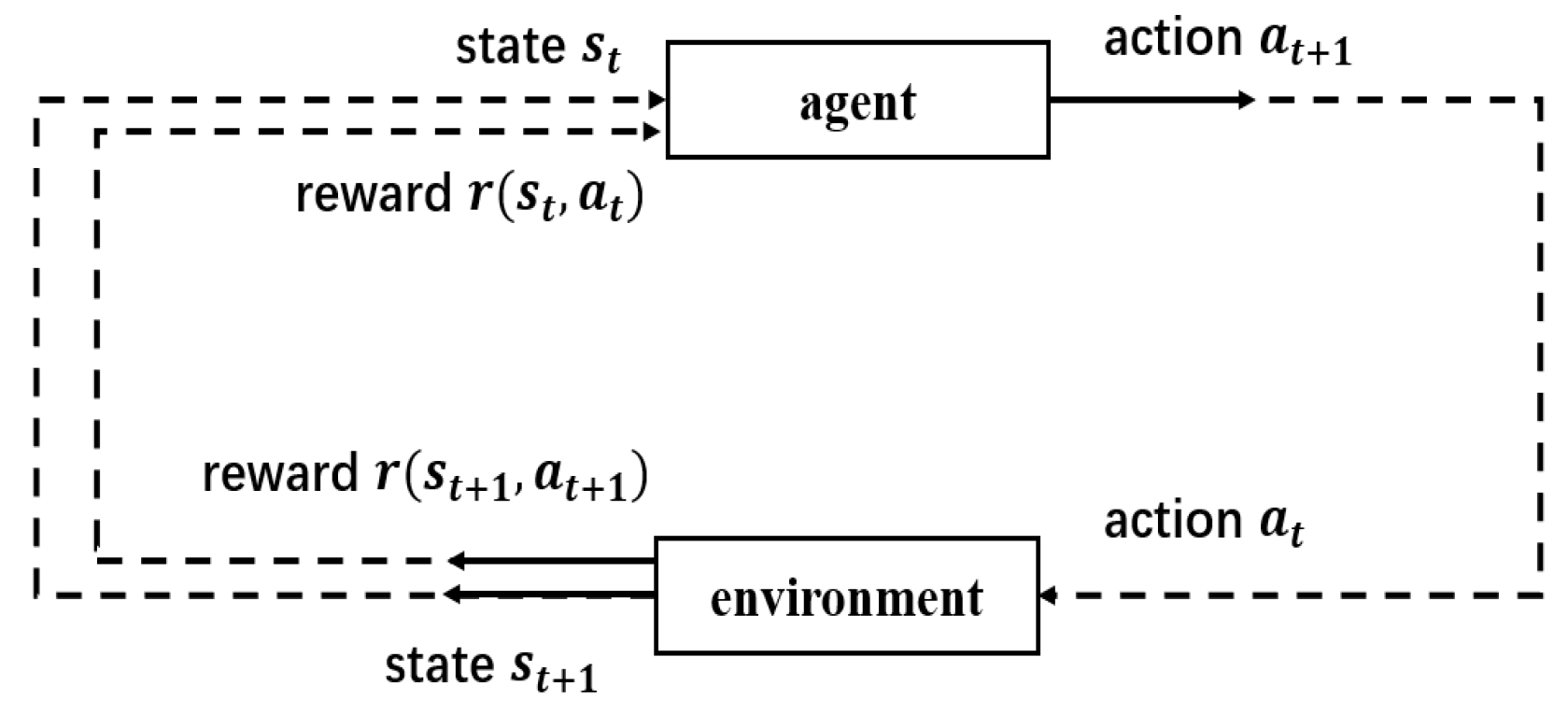
4.1. Agent and Environment
4.2. State
- denotes and the corresponding link is unreliable. When , the corresponding link can not transmit the signals at the target rate .
- denotes and the corresponding link is reliable. When , the corresponding link can transmit the signals at the target rate .
- denotes and the corresponding link is unreliable. When , the corresponding link can not transmit the signals at the target rate .
- denotes , and the corresponding link is reliable but not secure, where is the target secrecy rate. When , the corresponding link can transmit the signals with the target rate but cannot transmit the signals at the target secrecy rate .
- denotes , and corresponding link is reliable and secure. When , the corresponding link can transmit the signals at the target secrecy rate .
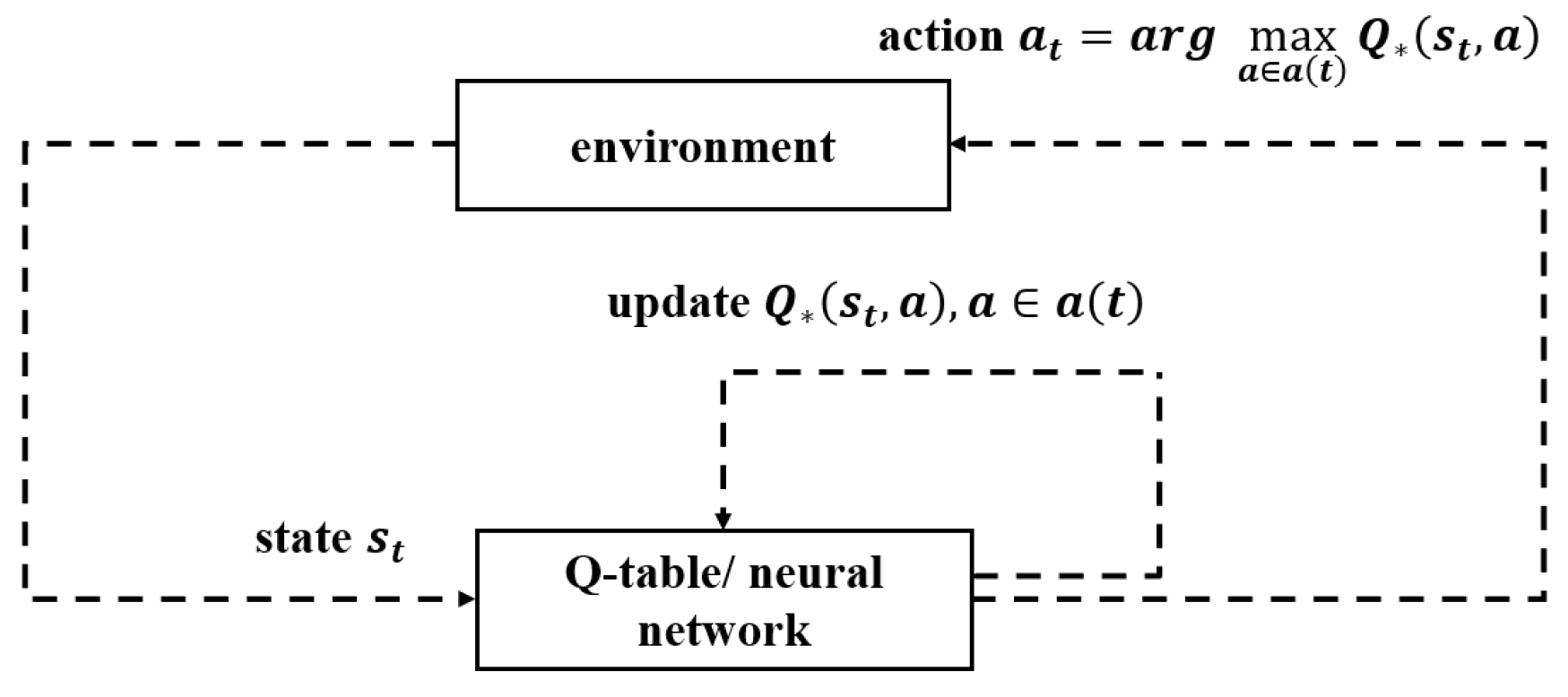
4.3. Action and Policy
4.4. Reward and Return
- Positive reward: the selected link satisfies the transmission requirements, in which the target transmission rate and target secrecy transmission rate are both considered, and the corresponding buffer-aided relay node is available.
- Negative reward: the selected link can not satisfy the transmission requirements or the corresponding buffer-aided relay node is unavailable.
- Neutral reward: no link is selected.
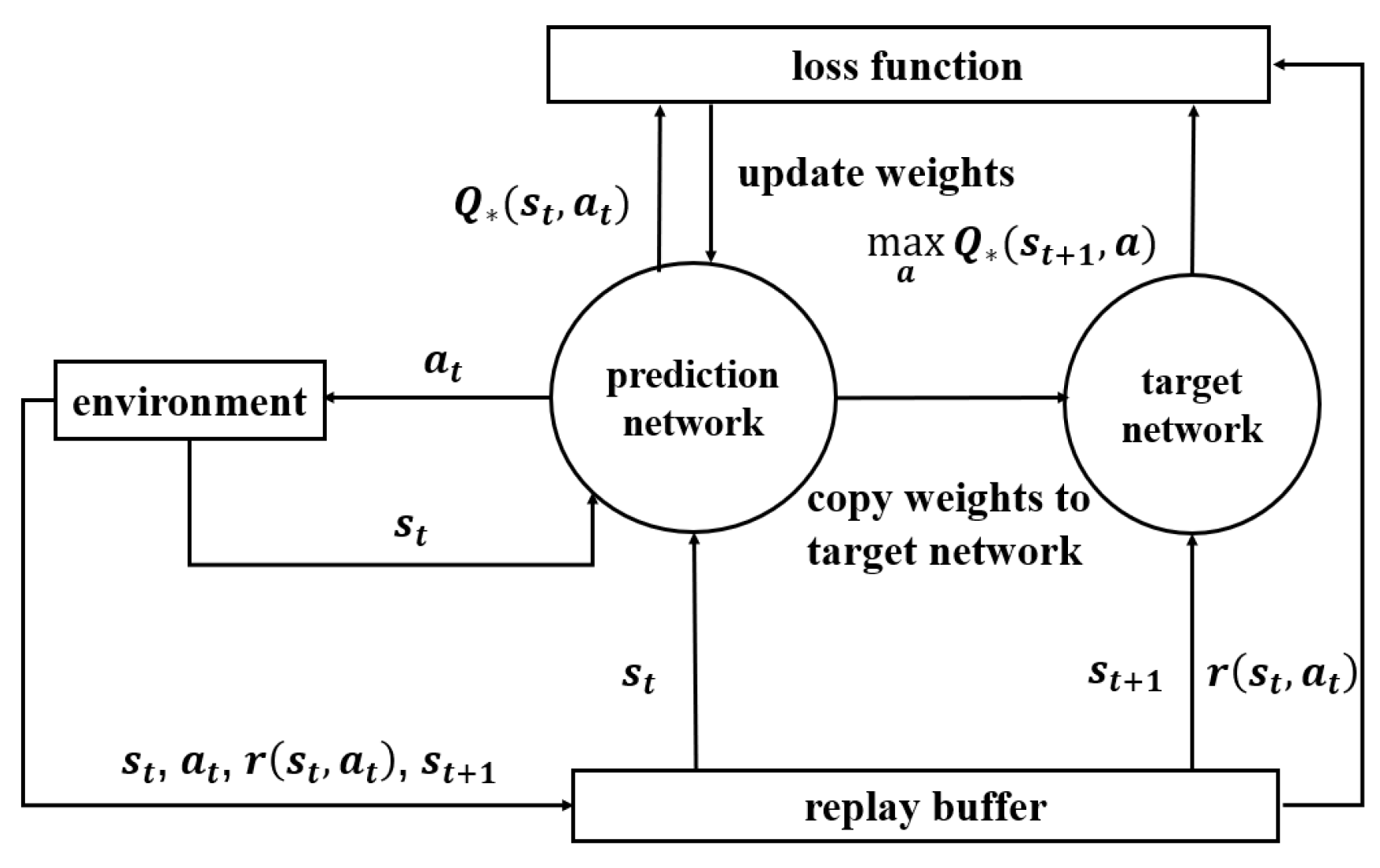
5. The Proposed Buffer-Aided Relay Selection Scheme
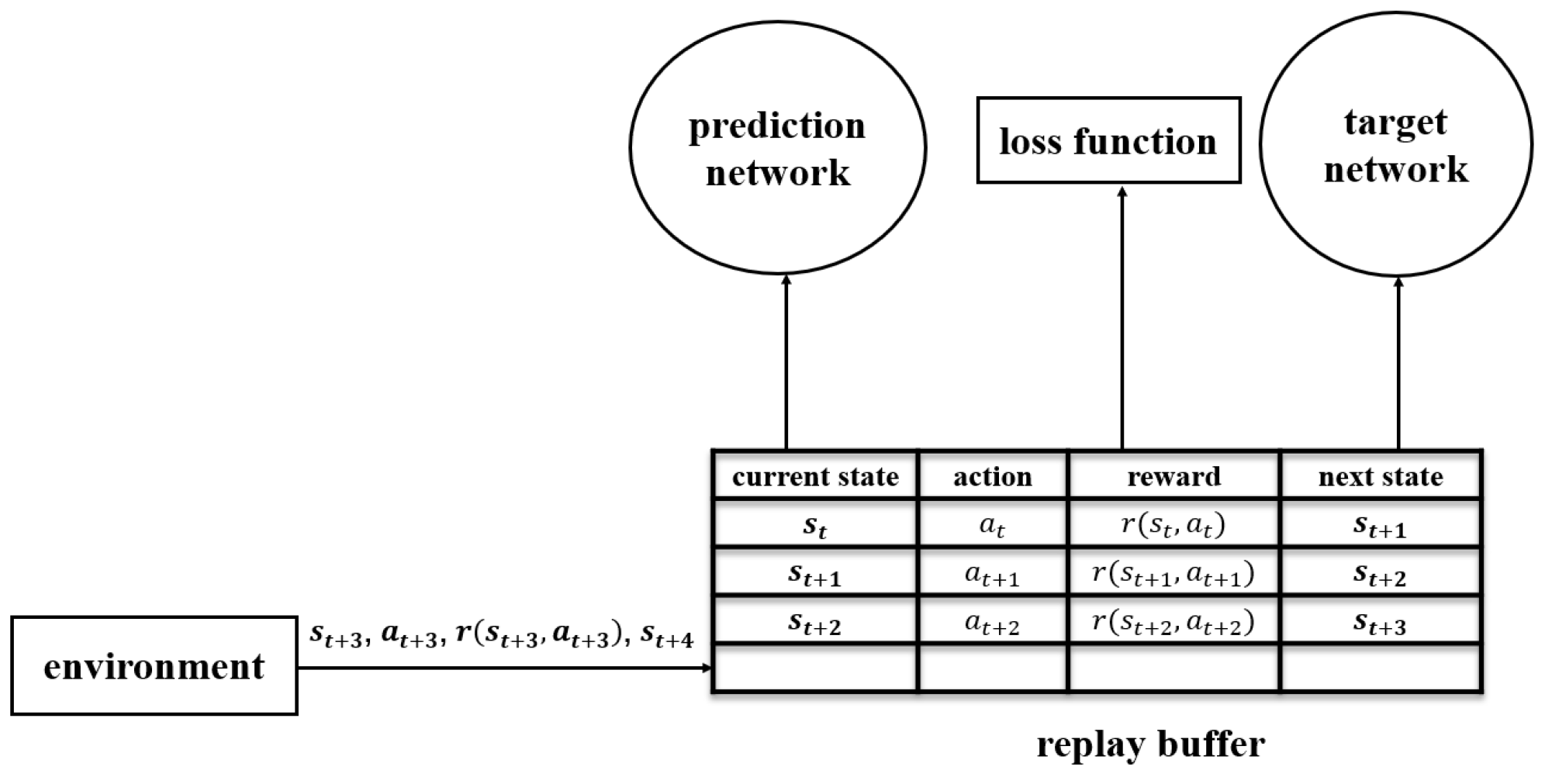
5.1. Experience Collection
5.2. Training the Network Model
5.3. Deployment Online
| Algorithm 1 The proposed buffer-aided relay scheme based on DQL |
|
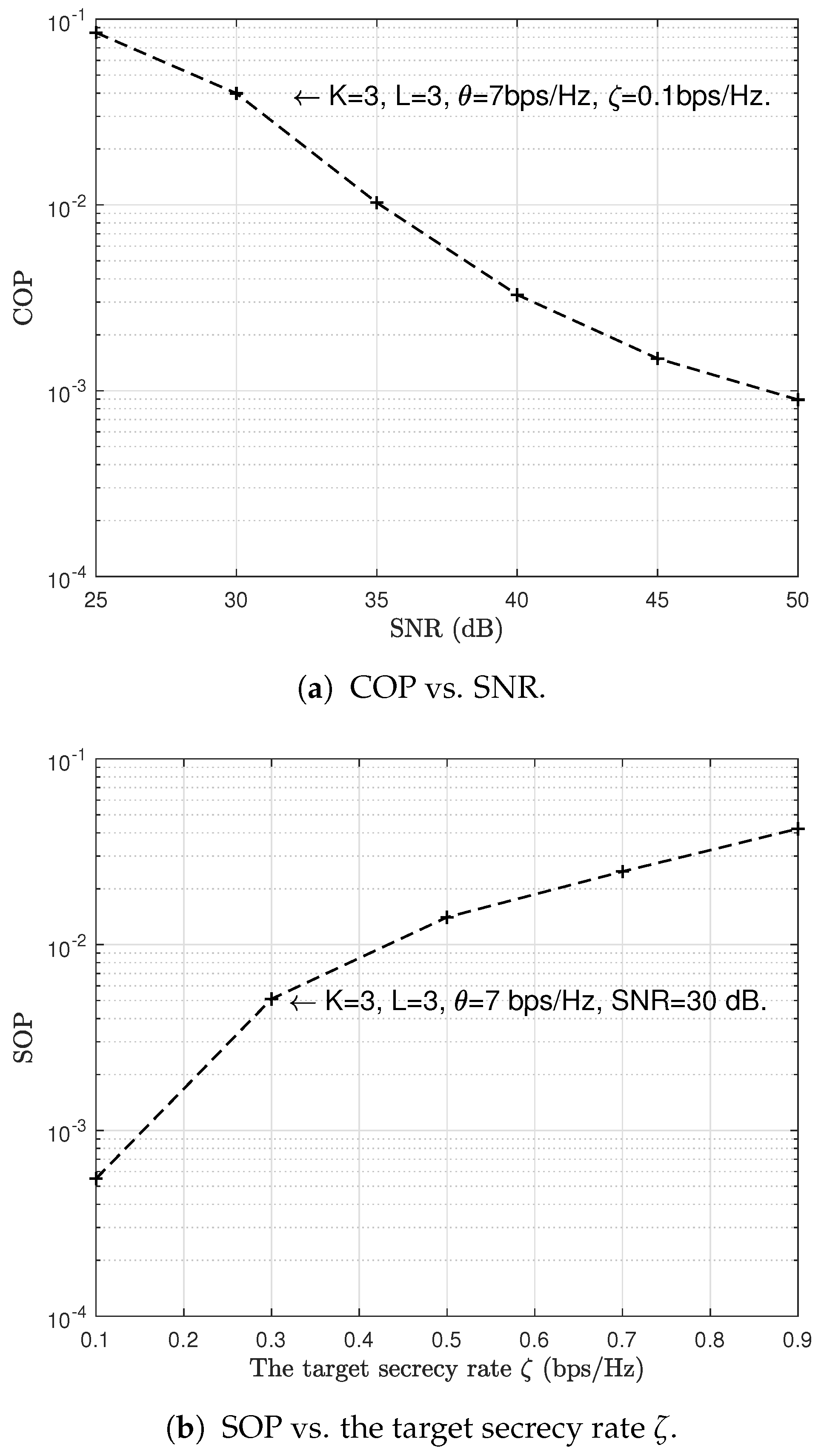
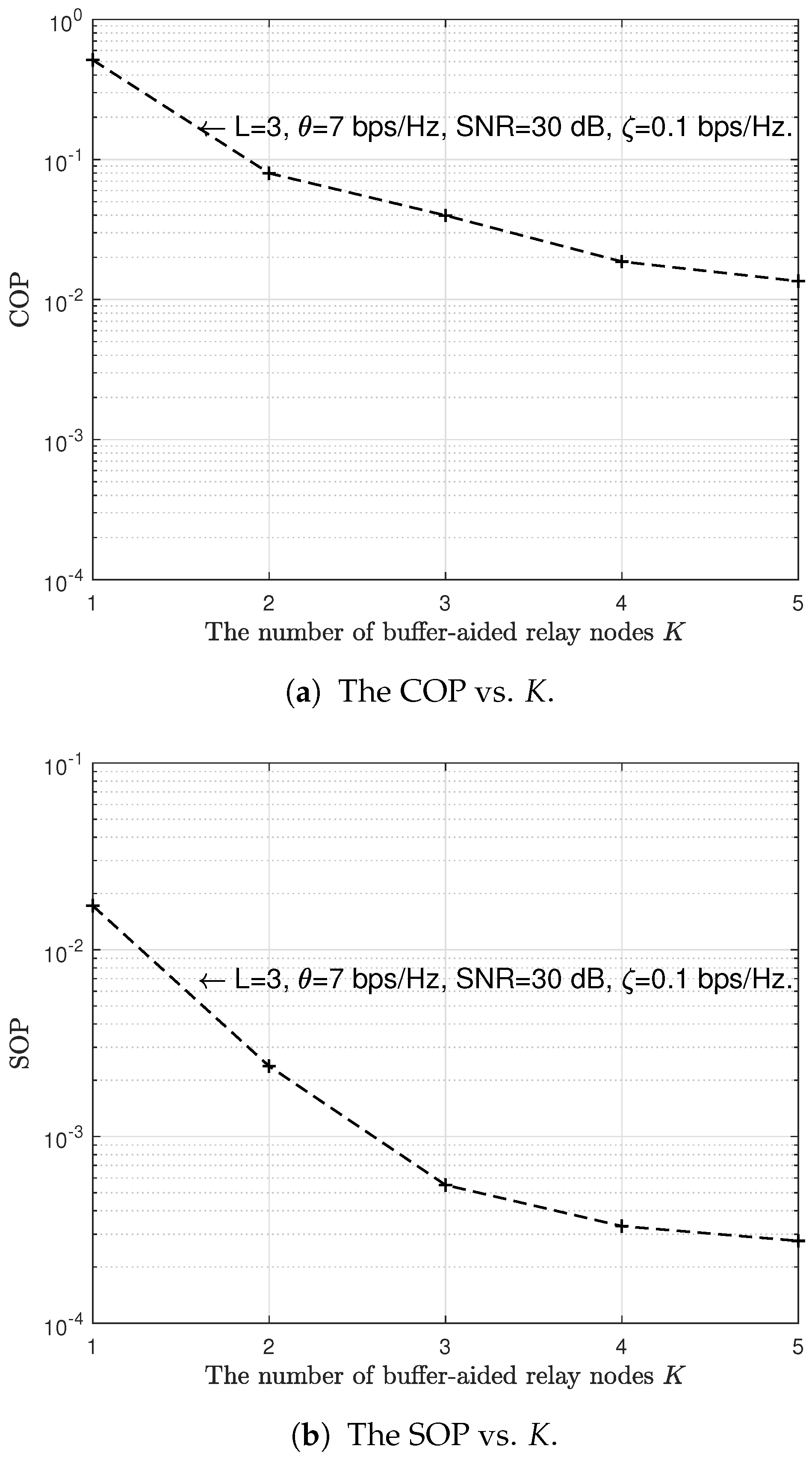
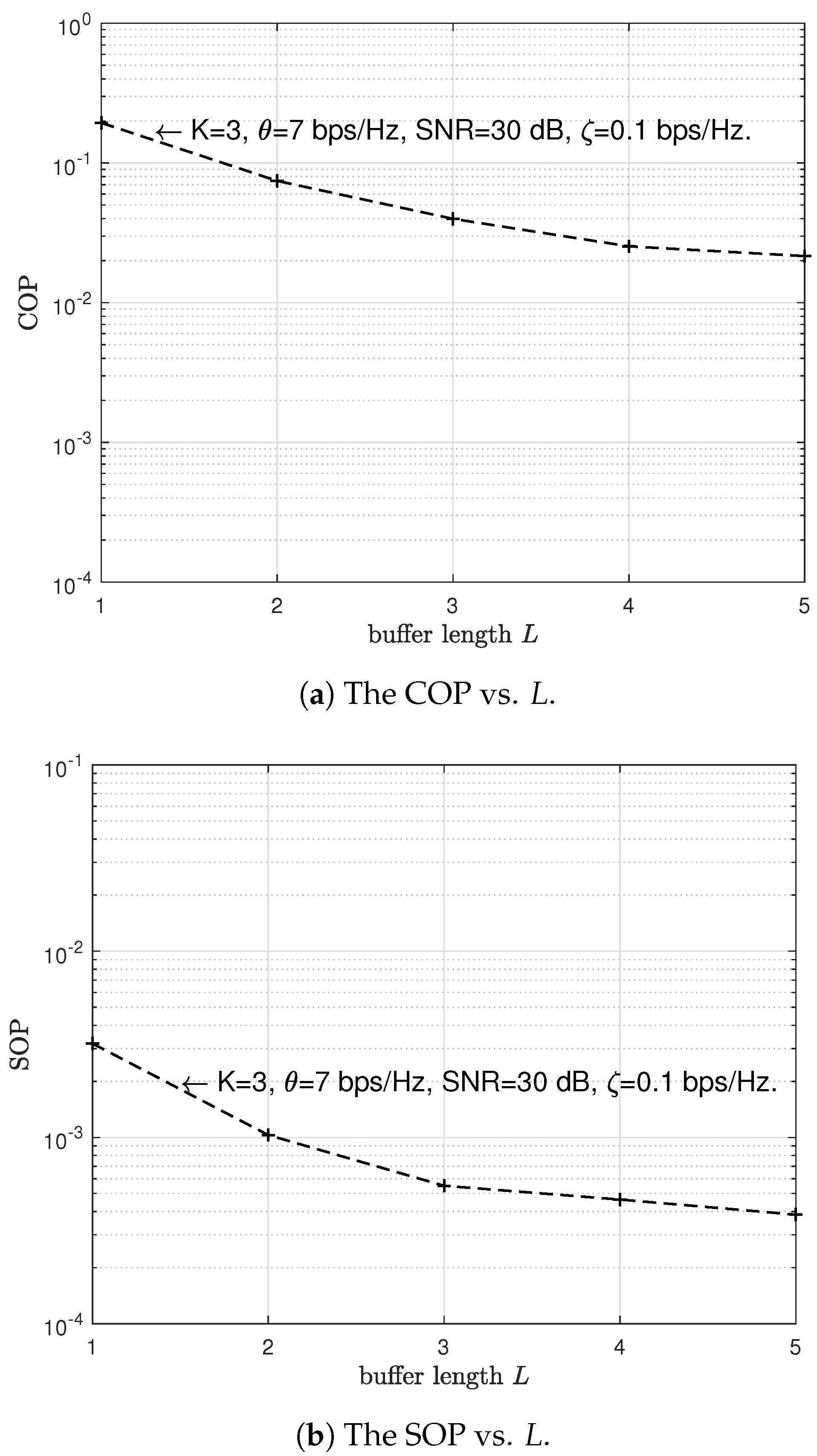
6. Simulation Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AF | Amplify-and-forward |
| DQL | Deep Q-learning |
| COP | Connection outage probability |
| SOP | Secrecy outage probability |
| WSNs | Wireless sensor networks |
| CRNs | Cognitive radio networks |
| IoTs | Internet of Things |
| PLS | Physical-layer security |
| CSI | Channel-state information |
| TQL | Traditional Q-learning |
| MC | Markov chain |
| MDP | Markov decision process |
| FD | Full-duplex |
| CJ | Cooperative jamming |
| EH | Energy harvesting |
| DL | Deep learning |
| DNN | Deep neural network |
| PA | Power allocation |
| DF | Decode-and-forward |
| RF | Randomize-and-forward |
| HD | Half-duplex |
| AWGN | Additive white Gaussian noise |
| SNR | Signal-to-noise ratio |
| MSE | Mean square error |
Symbols
| Channel coefficient between m and n | |
| Channel gain between m and n | |
| Average channel gain between m and n | |
| Expectation operator | |
| The received signal of at time t | |
| The signal sent by S at time t | |
| AWGN noise of at time t | |
| SNR of S to link at t | |
| Channel capacity of S to link | |
| Amplification factor of at | |
| The end-to-end secrecy rate | |
| The target rate | |
| The target secrecy rate | |
| The state at time t | |
| The action at time t | |
| State space | |
| Action space | |
| Discount factor | |
| Action-value function | |
| The optimal action-value function | |
| Exploration probability | |
| MSE loss function | |
| Training episodes | |
| Capacity of replay buffer |
References
- Ding, Y.; Yang, Y.; Jiang, W.; Liu, Y.; He, T.; Zhang, D. Nationwide Deployment and Operation of a Virtual Arrival Detection System in the Wild. IEEE/ACM Trans. Netw. 2023, 31, 574–589. [Google Scholar] [CrossRef]
- Li, Z.; Wang, S.; Han, S.; Meng, W.; Li, C. Joint Design of Beam Hopping and Multiple Access Based on Cognitive Radio for Integrated Satellite-Terrestrial Network. IEEE Netw. 2023, 37, 36–43. [Google Scholar] [CrossRef]
- Xie, H.; Xia, M.; Wu, P.; Wang, S.; Poor, H.V. Edge Learning for Large-Scale Internet of Things With Task-Oriented Efficient Communication. IEEE Trans. Wirel. Commun. 2023, 1–16. [Google Scholar] [CrossRef]
- Bapatla, D.; Prakriya, S. Performance of Two-Hop Links With an Energy Buffer-Aided IoT Source and a Data Buffer-Aided Relay. IEEE Internet Things J. 2021, 8, 5045–5061. [Google Scholar] [CrossRef]
- Yerrapragada, A.K.; Eisman, T.; Kelley, B. Physical Layer Security for Beyond 5G: Ultra Secure Low Latency Communications. IEEE Open J. Commun. Soc. 2021, 2, 2232–2242. [Google Scholar] [CrossRef]
- Angueira, P.; Val, I.; Montalbán, J.; Seijo, O.; Iradier, E.; Sanz, P.; Fanari, L.; Arriola, A. A Survey of Physical Layer Techniques for Secure Wireless Communications in Industry. IEEE Commun. Surv. Tutor. 2022, 24, 810–838. [Google Scholar] [CrossRef]
- Mitev, M.; Chorti, A.; Poor, H.V.; Fettweis, G.P. What Physical Layer Security Can Do for 6G Security. IEEE Open J. Veh. Technol. 2023, 4, 375–388. [Google Scholar] [CrossRef]
- Huynh, P.; Phan, K.T.; Liu, B.; Ross, R. Throughput Analysis of Buffer-Aided Decode-and-Forward Wireless Relaying with RF Energy Harvesting. Sensors 2020, 20, 1222. [Google Scholar] [CrossRef]
- Lu, X.; Xiao, L.; Li, P.; Ji, X.; Xu, C.; Yu, S.; Zhuang, W. Reinforcement Learning-Based Physical Cross-Layer Security and Privacy in 6G. IEEE Commun. Surv. Tutor. 2023, 25, 425–466. [Google Scholar] [CrossRef]
- Arzykulov, S.; Celik, A.; Nauryzbayev, G.; Eltawil, A.M. Artificial Noise and RIS-Aided Physical Layer Security: Optimal RIS Partitioning and Power Control. IEEE Wirel. Commun. Lett. 2023, 1–5. [Google Scholar] [CrossRef]
- Huang, H.; Hu, S. Generalized Relays Subsets Selection Algorithm in Cloud-Based 6G Large-Scale Relays Network. IEEE Internet Things J. 2022, 9, 24754–24766. [Google Scholar] [CrossRef]
- Zhou, F.; Chu, Z.; Sun, H.; Hu, R.Q.; Hanzo, L. Artificial Noise Aided Secure Cognitive Beamforming for Cooperative MISO-NOMA Using SWIPT. IEEE J. Sel. Areas Commun. 2018, 36, 918–931. [Google Scholar] [CrossRef]
- Vaishnavi, K.N.; Khorvi, S.D.; Kishore, R.; Gurugopinath, S. A Survey on Jamming Techniques in Physical Layer Security and Anti-Jamming Strategies for 6G. In Proceedings of the 2021 28th International Conference on Telecommunications (ICT), London, UK, 1–3 June 2021; pp. 174–179. [Google Scholar] [CrossRef]
- Shukla, A.K.; Bhatnagar, M.R. Differential Modulation-Based Buffer-Aided Cooperative Relaying Network. IEEE Syst. J. 2022, 1–12. [Google Scholar] [CrossRef]
- Xu, P.; Wang, Y.; Chen, G.; Krikidis, I.; Wong, K.K. Novel Mode Selection Schemes for Buffer-Aided Cooperative NOMA System. IEEE Trans. Veh. Technol. 2022, 72, 866–880. [Google Scholar] [CrossRef]
- Ikhlef, A.; Michalopoulos, D.S.; Schober, R. Max-Max Relay Selection for Relays with Buffers. IEEE Trans. Wirel. Commun. 2012, 11, 1124–1135. [Google Scholar] [CrossRef]
- Hamamreh, J.M.; Furqan, H.M.; Arslan, H. Classifications and Applications of Physical Layer Security Techniques for Confidentiality: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2019, 21, 1773–1828. [Google Scholar] [CrossRef]
- Guo, W.; Qureshi, N.M.F.; Siddiqui, I.F.; Shin, D.R. Cooperative Communication Resource Allocation Strategies for 5G and Beyond Networks: A Review of Architecture, Challenges and Opportunities. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8054–8078. [Google Scholar] [CrossRef]
- Krikidis, I.; Charalambous, T.; Thompson, J.S. Buffer-Aided Relay Selection for Cooperative Diversity Systems without Delay Constraints. IEEE Trans. Wirel. Commun. 2012, 11, 1957–1967. [Google Scholar] [CrossRef]
- Gong, Y.; Chen, G.; Xie, T. Using Buffers in Trust-Aware Relay Selection Networks With Spatially Random Relays. IEEE Trans. Wirel. Commun. 2018, 17, 5818–5826. [Google Scholar] [CrossRef]
- Alam, M.Z.; Abkenar, F.S.; Adhicandra, I.; Murali, S.; Jamalipour, A. Low-Delay Path Selection for Cluster-Based Buffer-Aided Vehicular Communications. IEEE Trans. Veh. Technol. 2020, 69, 9356–9363. [Google Scholar] [CrossRef]
- Adanvo, V.F.; Mafra, S.; Montejo-Sánchez, S.; Fernández, E.M.G.; Souza, R.D. Buffer-Aided Relaying Strategies for Two-Way Wireless Networks. Sustainability 2022, 14, 13829. [Google Scholar] [CrossRef]
- Jadoon, M.A.; Kim, S. Relay selection algorithm for wireless cooperative networks: A learning-based approach. IET Commun. 2017, 11, 1061–1066. [Google Scholar] [CrossRef]
- Wang, X.; Jin, T.; Hu, L.; Qian, Z. Energy-Efficient Power Allocation and Q-Learning-Based Relay Selection for Relay-Aided D2D Communication. IEEE Trans. Veh. Technol. 2020, 69, 6452–6462. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, F.; Joe, I.; Lin, H.; Jiao, W.; Zhang, Y. Learning for Multiple-Relay Selection in a Vehicular Delay Tolerant Network. IEEE Access 2020, 8, 175602–175611. [Google Scholar] [CrossRef]
- Chen, G.; Tian, Z.; Gong, Y.; Chen, Z.; Chambers, J.A. Max-Ratio Relay Selection in Secure Buffer-Aided Cooperative Wireless Networks. IEEE Trans. Inf. Forensics Secur. 2014, 9, 719–729. [Google Scholar] [CrossRef]
- Mekkawy, T.; Yao, R.; Qi, N.; Lu, Y. Secure Relay Selection for Two Way Amplify-and-Forward Untrusted Relaying Networks. IEEE Trans. Veh. Technol. 2018, 67, 11979–11987. [Google Scholar] [CrossRef]
- Zhang, C.; Liao, X.; Wu, Z.; Qiu, G. Buffer-Aided Relay Selection for Wireless Cooperative Relay Networks with Untrusted Relays. In Proceedings of the 2021 International Conference on Networking and Network Applications (NaNA), Lijiang, China, 29 October–1 November 2021; pp. 69–74. [Google Scholar] [CrossRef]
- Nie, Y.; Lan, X.; Liu, Y.; Chen, Q.; Chen, G.; Fan, L.; Tang, D. Achievable Rate Region of Energy-Harvesting Based Secure Two-Way Buffer-Aided Relay Networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1610–1625. [Google Scholar] [CrossRef]
- Srirutchataboon, G.; Sugiura, S. Physical Layer Security of Buffer-Aided Hybrid Virtual Full-Duplex and Half-Duplex Relay Selection. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–5. [Google Scholar] [CrossRef]
- He, J.; Liu, J.; Su, W.; Shen, Y.; Jiang, X.; Shiratori, N. Jamming and Link Selection for Joint Secrecy/Delay Guarantees in Buffer-Aided Relay System. IEEE Trans. Commun. 2022, 70, 5451–5468. [Google Scholar] [CrossRef]
- Wang, Y.; Yin, H.; Zhang, T.; Yang, W.; Shang, X.; Shen, Y. Secure Transmission for Energy Harvesting Sensor Networks with a Buffer-Aided Sink Node. IEEE Internet Things J. 2021, 9, 6703–6718. [Google Scholar] [CrossRef]
- Mao, Q.; Hu, F.; Hao, Q. Deep Learning for Intelligent Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2595–2621. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Buenrostro-Mariscal, R.; Santana-Mancilla, P.C.; Montesinos-López, O.A.; Nieto Hipólito, J.I.; Anido-Rifón, L.E. A Review of Deep Learning Applications for the Next Generation of Cognitive Networks. Appl. Sci. 2022, 12, 6262. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Huang, Y.; Zhang, P. Neural Network-Based Relay Selection in Two-Way SWIPT-Enabled Cognitive Radio Networks. IEEE Trans. Veh. Technol. 2020, 69, 6264–6274. [Google Scholar] [CrossRef]
- Zhou, D.; Yan, B.; Li, C.; Wang, A.; Wei, H. Relay selection scheme based on deep reinforcement learning in wireless sensor networks. Phys. Commun. 2022, 54, 101799. [Google Scholar] [CrossRef]
- Rezwan, S.; Choi, W. A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks. Electronics 2021, 10, 449. [Google Scholar] [CrossRef]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A New Deep-Q-Learning-Based Transmission Scheduling Mechanism for the Cognitive Internet of Things. IEEE Internet Things J. 2018, 5, 2375–2385. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Gong, Y. Delay-Constrained Buffer-Aided Relay Selection in the Internet of Things With Decision-Assisted Reinforcement Learning. IEEE Internet Things J. 2021, 8, 10198–10208. [Google Scholar] [CrossRef]
- Huang, C.; Zhong, J.; Gong, Y.; Abdullah, Z.; Chen, G. Novel deep reinforcement learning-based delay-constrained buffer-aided relay selection in cognitive cooperative networks. Electron. Lett. 2020, 56, 1148–1150. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Gong, Y.; Xu, P. Deep Reinforcement Learning Based Relay Selection in Delay-Constrained Secure Buffer-Aided CRNs. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Gong, Y.; Han, Z. Joint Buffer-Aided Hybrid-Duplex Relay Selection and Power Allocation for Secure Cognitive Networks With Double Deep Q-Network. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 834–844. [Google Scholar] [CrossRef]
- El-Zahr, S.; Abou-Rjeily, C. Threshold Based Relay Selection for Buffer-Aided Cooperative Relaying Systems. IEEE Trans. Wirel. Commun. 2021, 20, 6210–6223. [Google Scholar] [CrossRef]
- Xu, P.; Quan, J.; Chen, G.; Yang, Z.; Li, Y.; Krikidis, I. A Novel Link Selection in Coordinated Direct and Buffer-Aided Relay Transmission. IEEE Trans. Wirel. Commun. 2022, 22, 3296–3309. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References and Our Work | Feature | ||||
|---|---|---|---|---|---|
| System Model | Eavesdropper | Method | Reliability | Security | |
| [19] | Two-hop DF relay network | ✘ | MC | ✓ | ✘ |
| [23] | Two-hop AF relay network | ✘ | TQL | ✓ | ✘ |
| [26] | Two-hop AF relay network | ✘ | MC | ✘ | ✓ |
| [40] | Delay-constrained DF relay IOT | ✘ | DQL | ✓ | ✘ |
| [43] | RF relay CRN | ✓ (untrusted users) | DQL+PA | ✓ | ✓ |
| Our Work | Two-hop AF relay network | ✓ | DQL | ✓ | ✓ |
| Action | Link State | Buffer State | Result |
|---|---|---|---|
| 0 | full | connection outage | |
| 0 | not full | connection outage | |
| 2 | not full | successful transmission | |
| 2 | full | connection outage | |
| 2 | empty | connection outage | |
| 2 | not empty | successful transmission | |
| 1 | empty | secrecy outage | |
| 1 | not empty | secrecy outage | |
| 0 | empty | connection outage | |
| 0 | not empty | connection outage | |
| ∅ | any | connection outage |
| Q-Table | |||||
|---|---|---|---|---|---|
| ⋯ | |||||
| ⋯ | |||||
| ⋯ | |||||
| ⋯ | |||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ⋯ | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Liao, X.; Wu, Z.; Qiu, G.; Chen, Z.; Yu, Z. Deep Q-Learning-Based Buffer-Aided Relay Selection for Reliable and Secure Communications in Two-Hop Wireless Relay Networks. Sensors 2023, 23, 4822. https://doi.org/10.3390/s23104822
Zhang C, Liao X, Wu Z, Qiu G, Chen Z, Yu Z. Deep Q-Learning-Based Buffer-Aided Relay Selection for Reliable and Secure Communications in Two-Hop Wireless Relay Networks. Sensors. 2023; 23(10):4822. https://doi.org/10.3390/s23104822
Chicago/Turabian StyleZhang, Cheng, Xuening Liao, Zhenqiang Wu, Guoyong Qiu, Zitong Chen, and Zhiliang Yu. 2023. "Deep Q-Learning-Based Buffer-Aided Relay Selection for Reliable and Secure Communications in Two-Hop Wireless Relay Networks" Sensors 23, no. 10: 4822. https://doi.org/10.3390/s23104822
APA StyleZhang, C., Liao, X., Wu, Z., Qiu, G., Chen, Z., & Yu, Z. (2023). Deep Q-Learning-Based Buffer-Aided Relay Selection for Reliable and Secure Communications in Two-Hop Wireless Relay Networks. Sensors, 23(10), 4822. https://doi.org/10.3390/s23104822