
A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism

Abstract
1. Introduction
1.1. Literature Review
1.1.1. Vehicle Detection
1.1.2. Vehicle Tracking
1.2. Contributions
- We develop a vehicle detection model YOLOv5-NAM based on the YOLOv5 model. By adding the spatial attention mechanism and channel attention mechanism module into the model, the detection accuracy of small vehicles is improved. An SD-NMS method based on the idea of the penalty function is further proposed to solve the problem of missed detection of vehicles in dense scenes.
- We propose a real-time multi-vehicle tracking method JDE-YN based on the JDE algorithm, which improves the tracking accuracy of the vehicles and reduces the number of vehicle identity switching instances. Based on direction correction, we also develop a cascade matching algorithm to solve the problem of vehicle identity switching caused by occlusion.
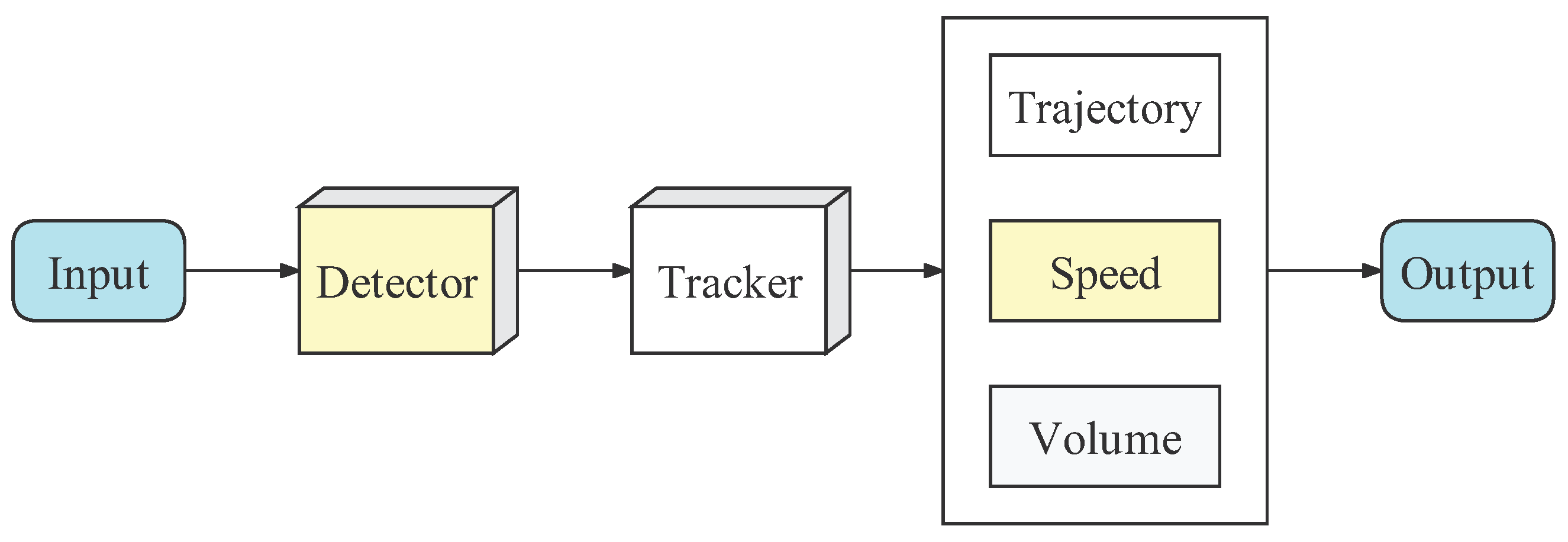
2. System Model
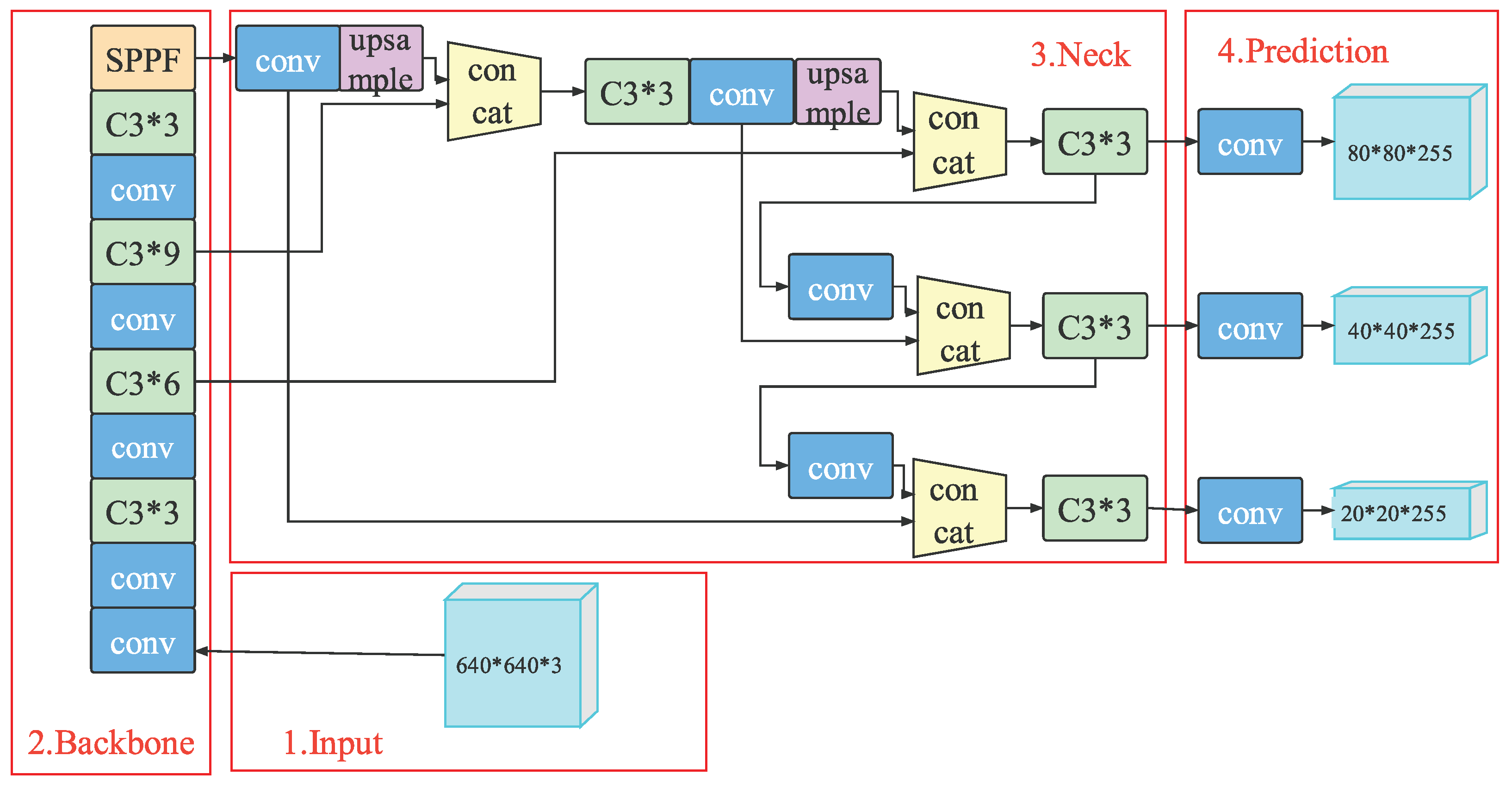
2.1. Detection Model
2.1.1. Input
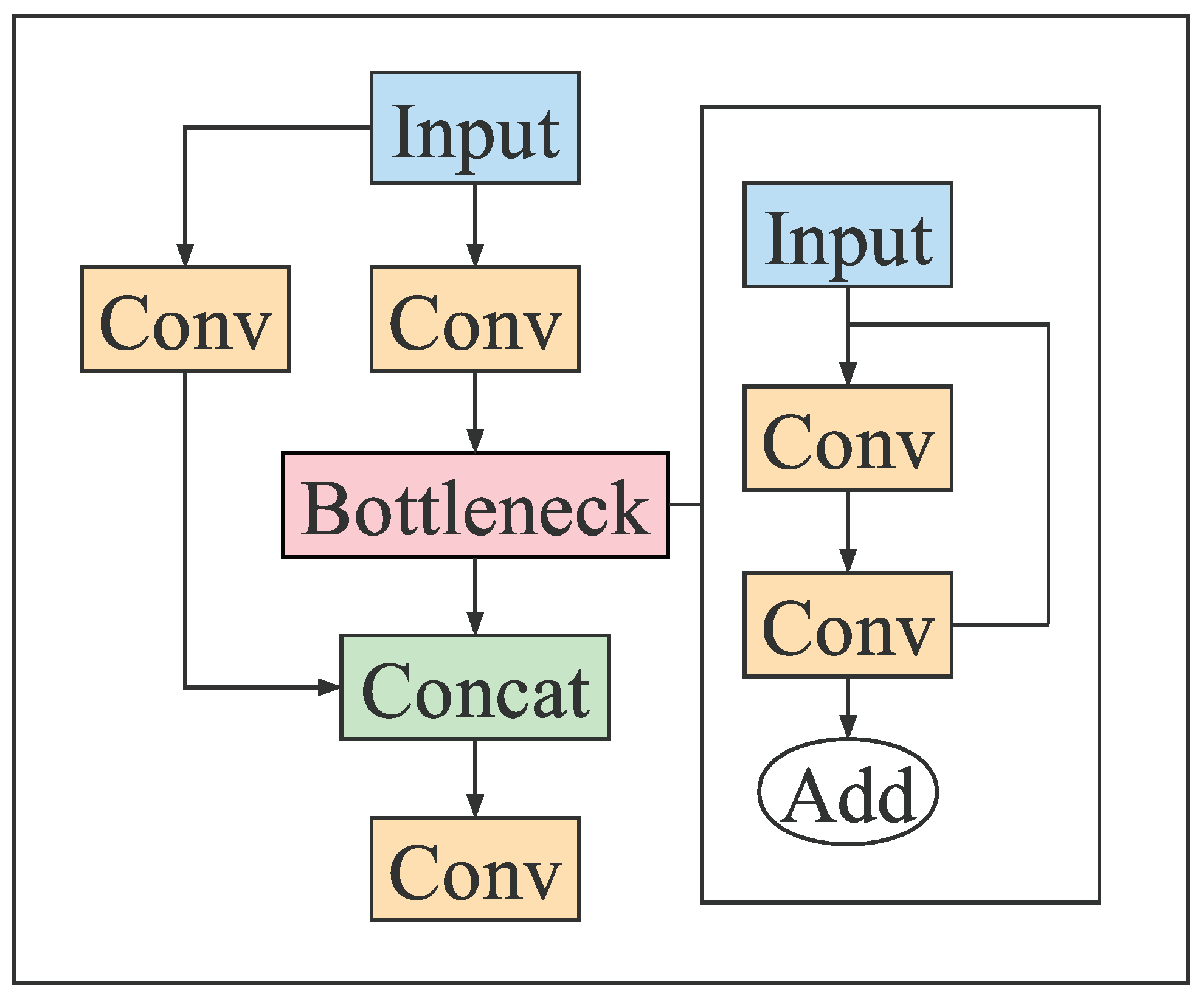
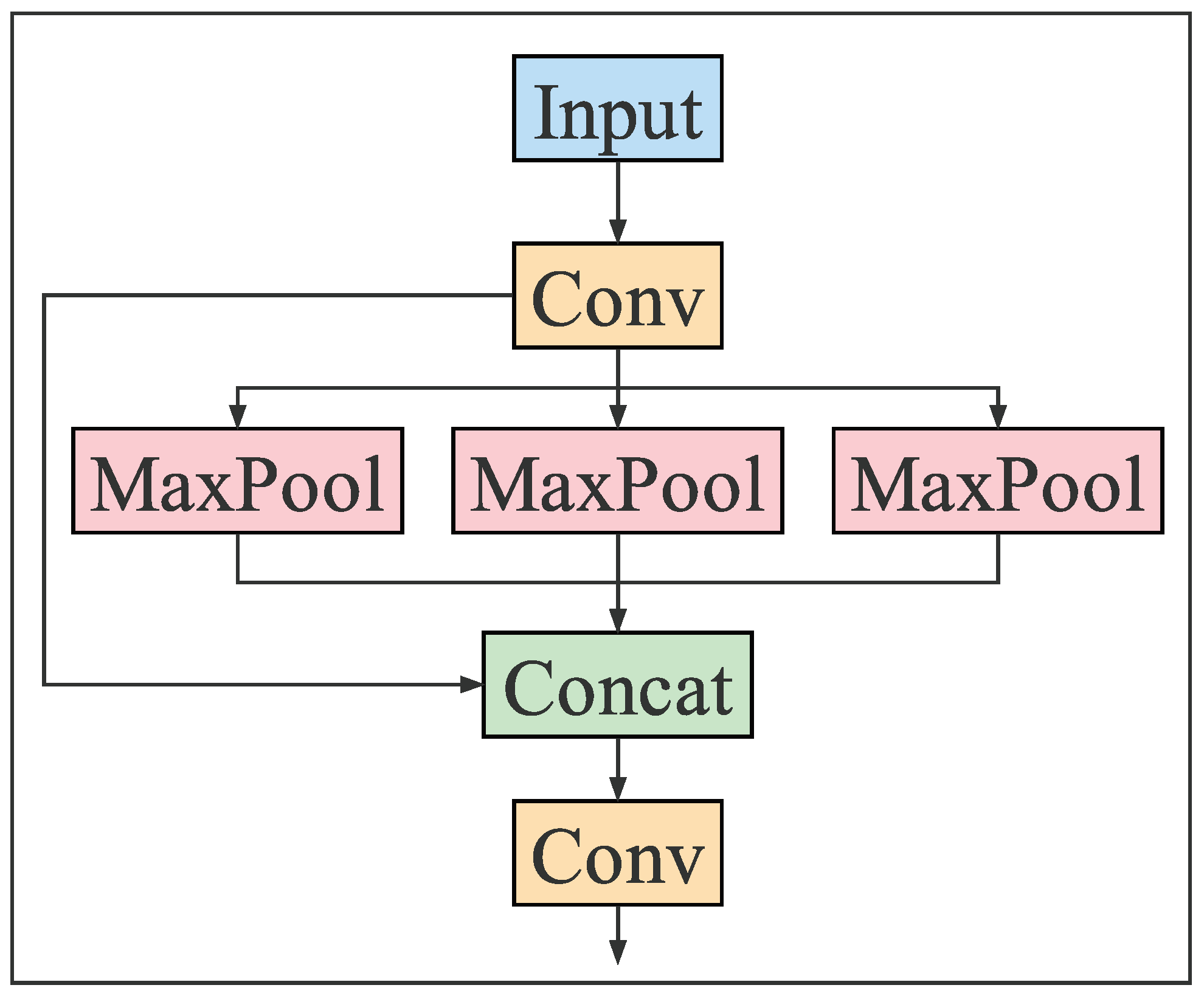
2.1.2. Backbone
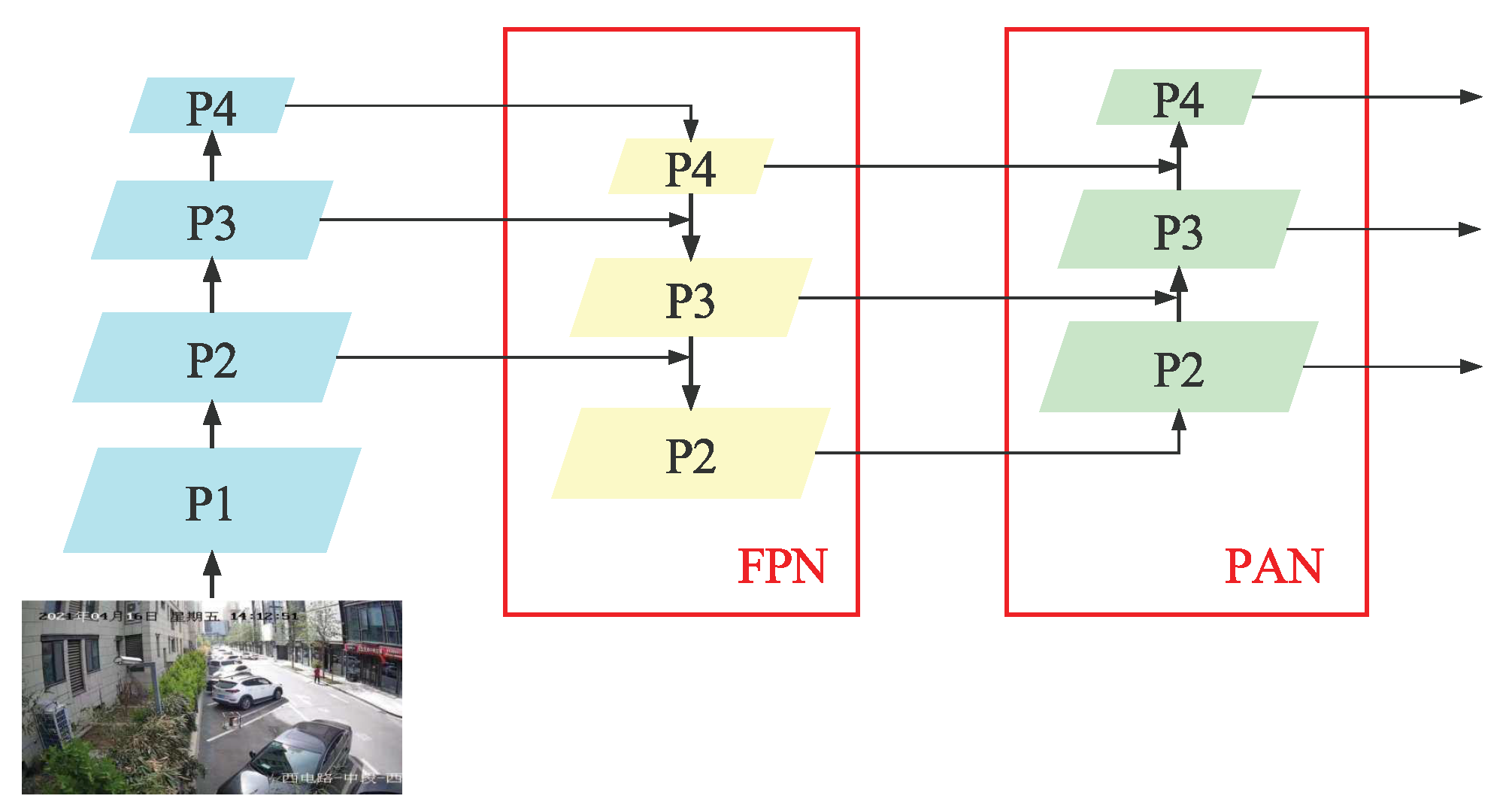
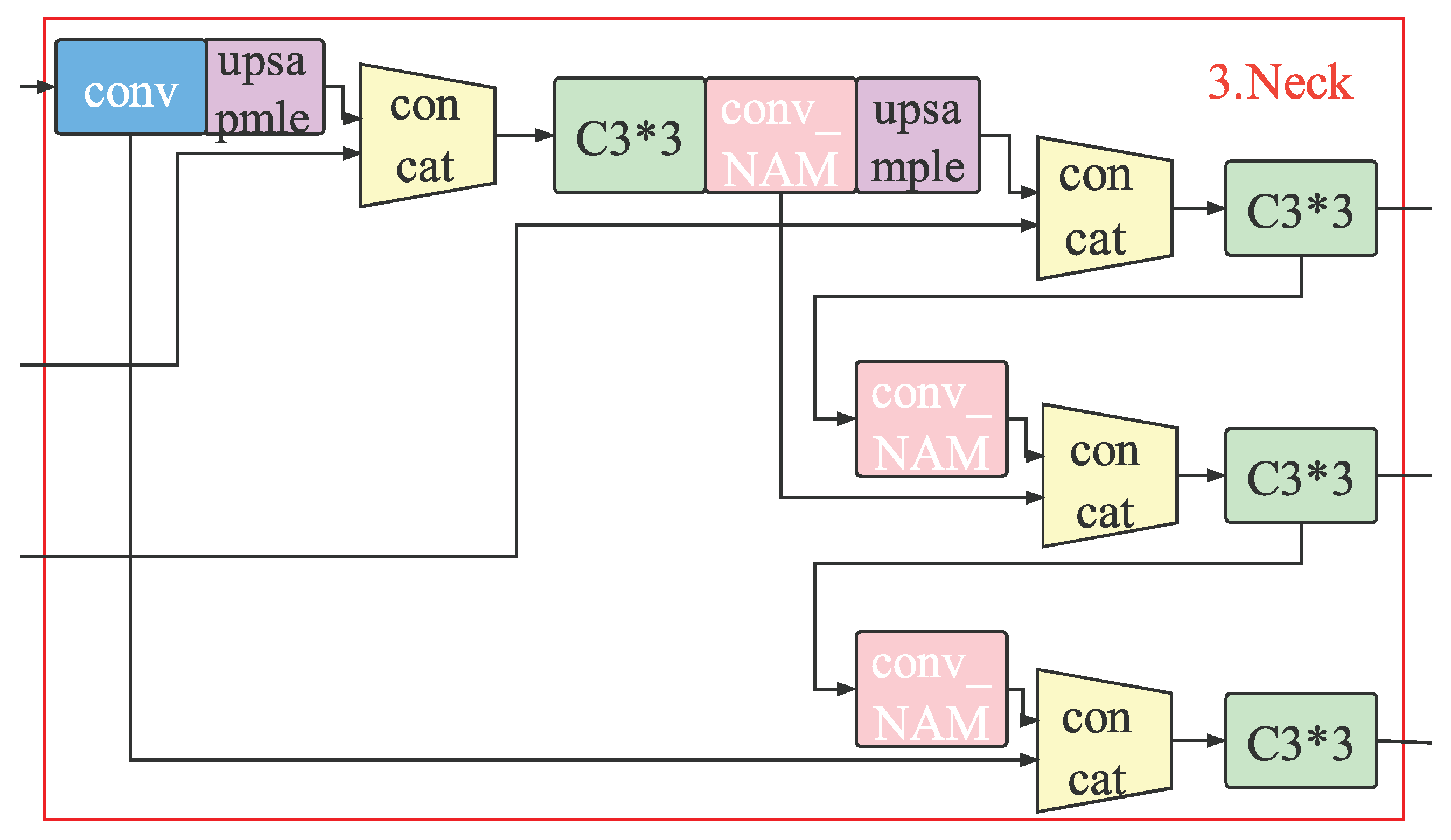
2.1.3. Neck
2.1.4. Prediction Head
2.2. Tracking Model
3. Vehicle Detection and Tracking Method
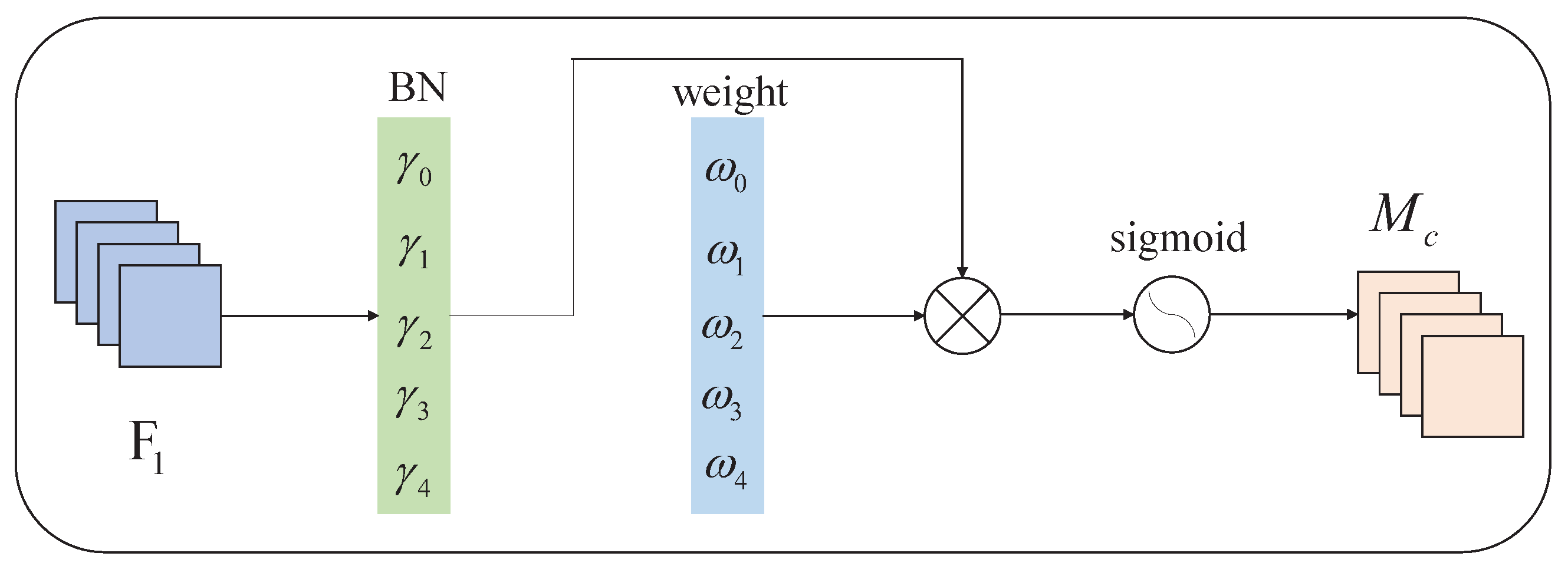
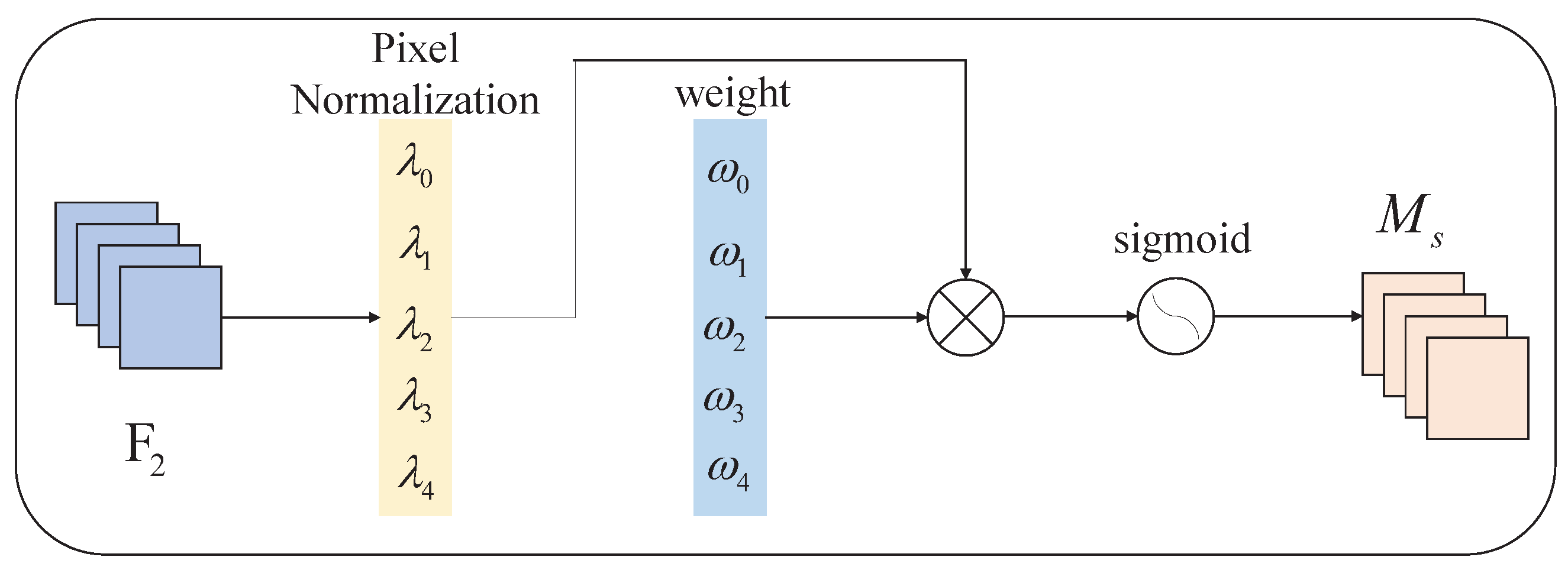
3.1. The YOLOv5-NAM Vehicle Detection Model
3.2. The Loss Function
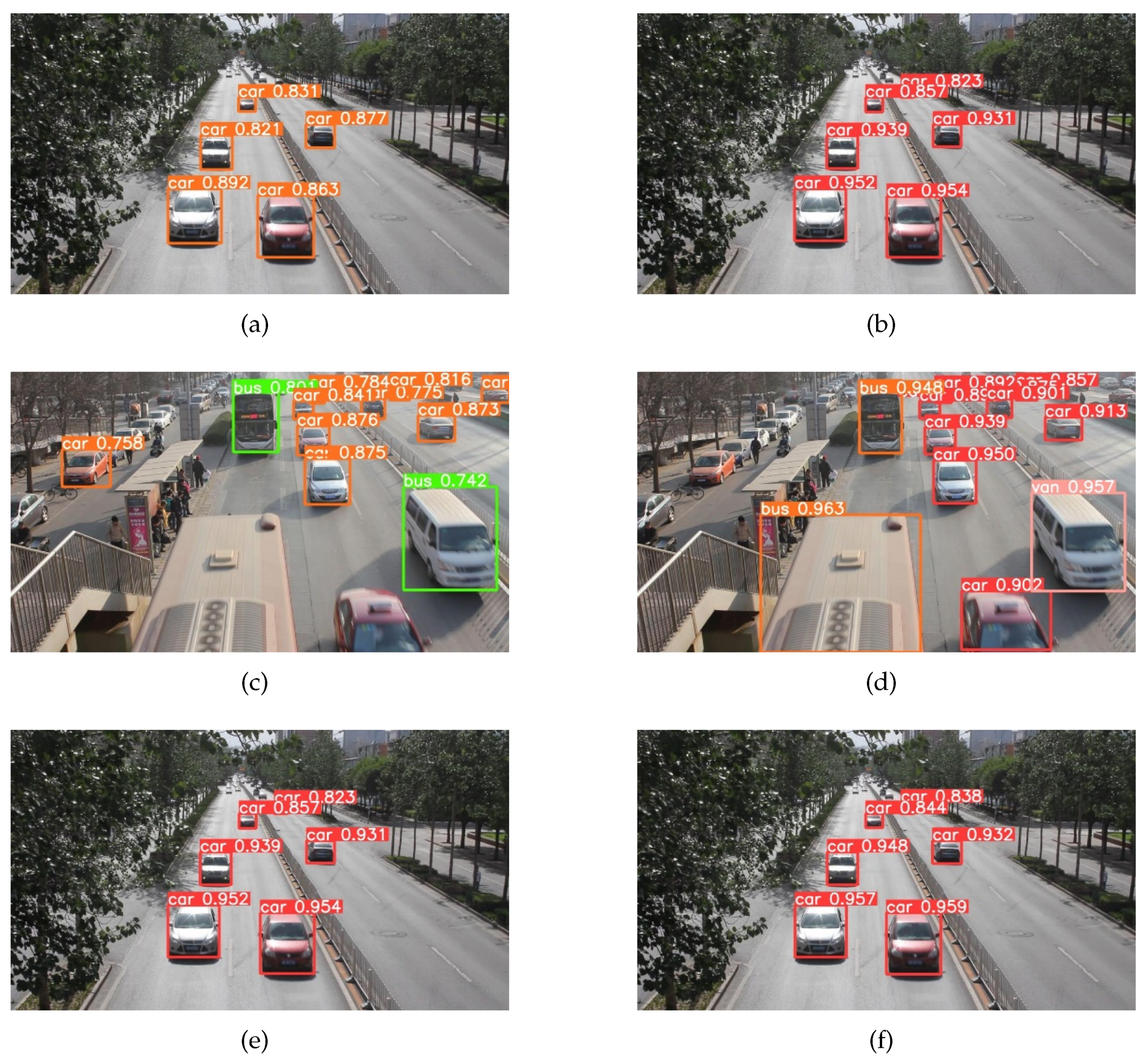
3.3. The SD-NMS Method
| Algorithm 1: The Non-Maximum Suppression algorithm |
1 While 2 3 4 5 For 6 If 7 |
3.4. The Vehicle State Estimation Model
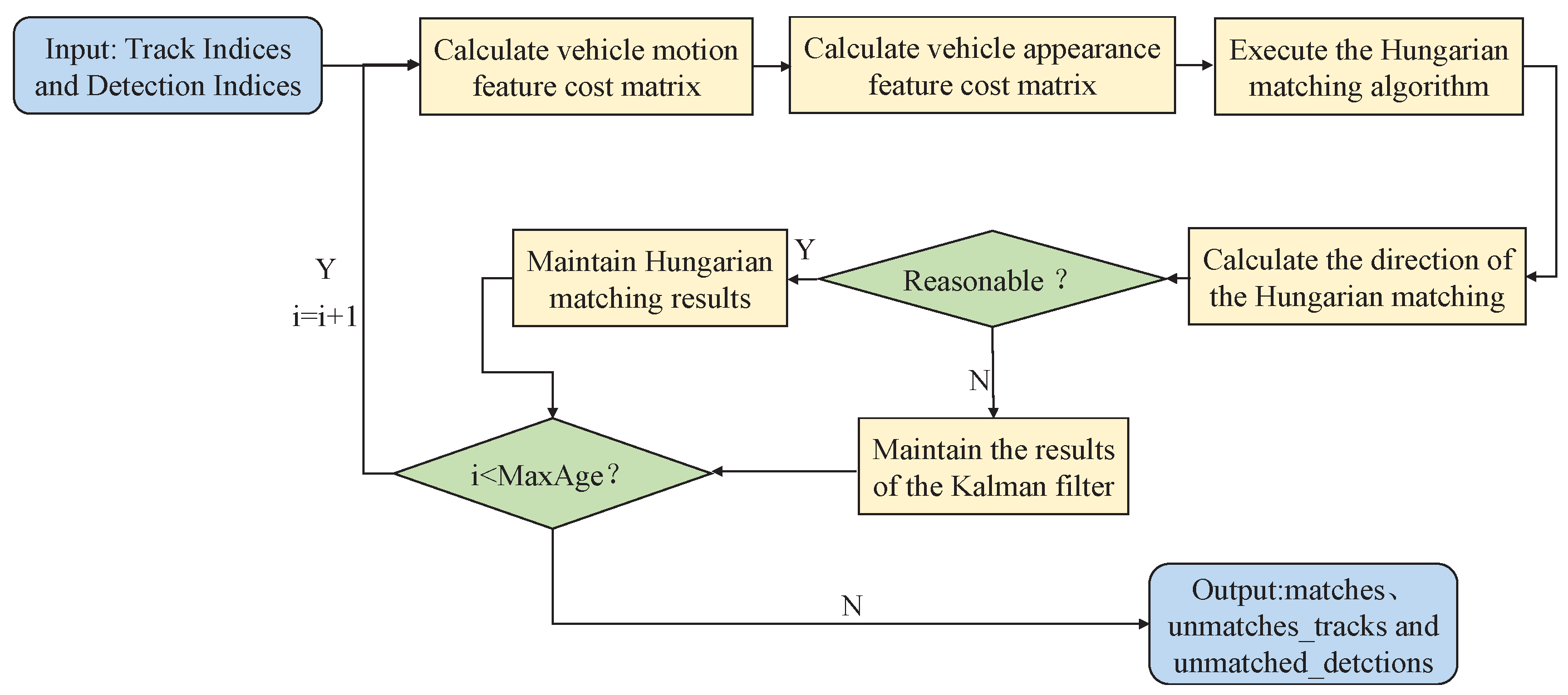
3.5. The Cascade Matching Algorithm Based on Direction Correction
4. Detection and Tracking Experience Results
4.1. Detection Results on UA-DETRAC
4.2. Detection Results on COCO
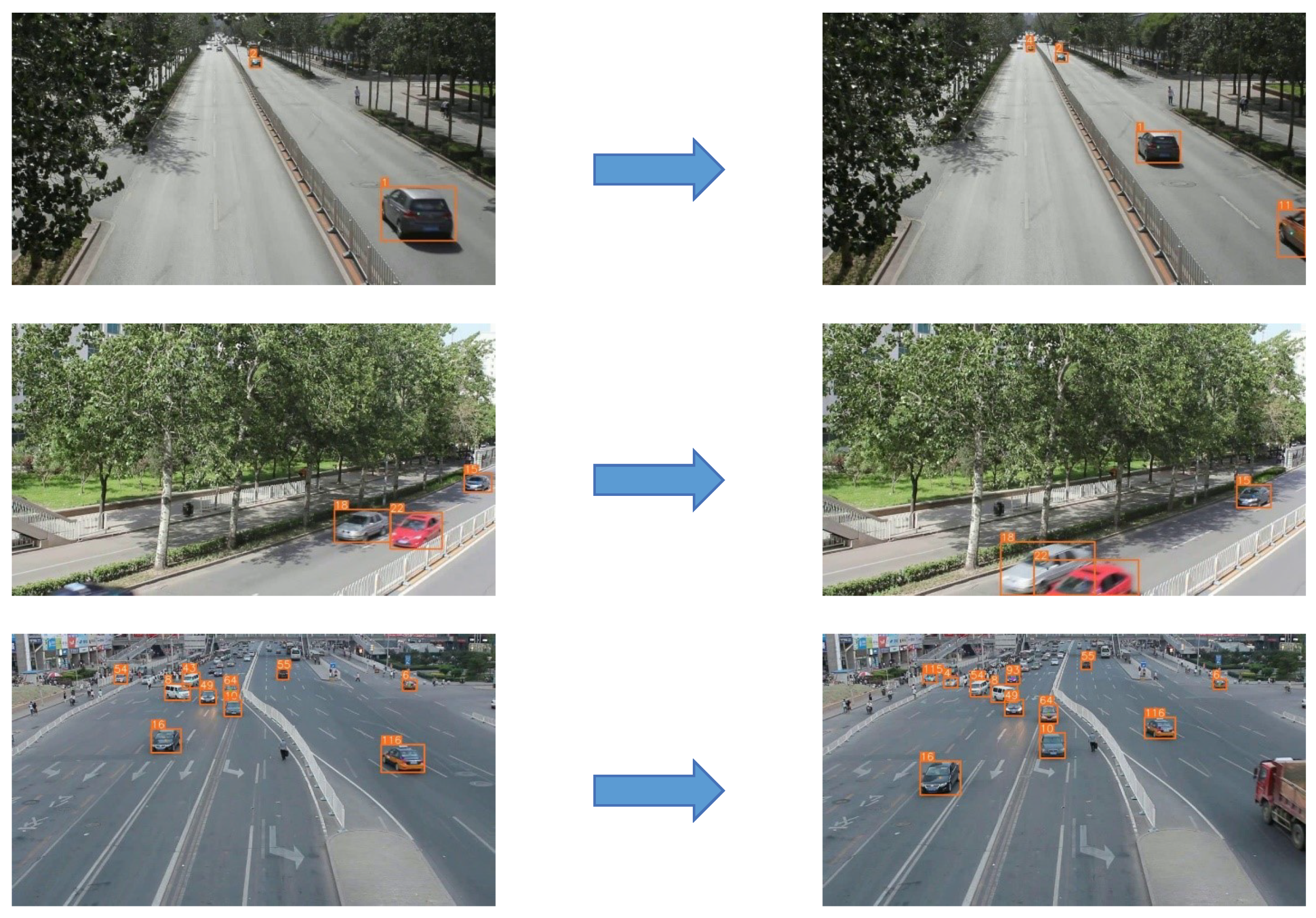
4.3. Tracking Results on UA-DETRAC
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, K.; Jia, X.; Chi, K.; Liu, X. DDPG-based joint time and energy management in ambient backscatter-assisted hybrid underlay CRNs. IEEE Trans. Commun. 2022. [Google Scholar] [CrossRef]
- Liu, X.; Xu, B.; Wang, X.; Zheng, K.; Chi, K.; Tian, X. Impacts of sensing energy and data availability on throughput of energy harvesting cognitive radio networks. IEEE Trans. Veh. Technol. 2022. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Moustafa, N.; Hawash, H.; Razzak, I.; Sallam, K.M.; Elkomy, O.M. Federated Intrusion Detection in Blockchain-Based Smart Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2523–2537. [Google Scholar] [CrossRef]
- Yan, P.; Liu, X.; Wang, F.; Yue, C.; Wang, X. LOVD: Land Vehicle Detection in Complex Scenes of Optical Remote Sensing Image. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Mao, S.; Liu, L.; Zhang, N.; Dong, M.; Zhao, J.; Wu, J.; Leung, V.C. Reconfigurable intelligent surface-assisted secure mobile edge computing networks. IEEE Trans. Veh. Technol. 2022, 71, 6647–6660. [Google Scholar] [CrossRef]
- Messoussi, O.; de Magalhães, F.G.; Lamarre, F.; Perreault, F.; Sogoba, I.; Bilodeau, G.A.; Nicolescu, G. Vehicle Detection and Tracking from Surveillance Cameras in Urban Scenes. In International Symposium on Visual Computing; Springer: Cham, Switzerland, 2021; pp. 191–202. [Google Scholar]
- Zhang, Y.; Zhou, Y.; Lu, H.; Fujita, H. Traffic Network Flow Prediction Using Parallel Training for Deep Convolutional Neural Networks on Spark Cloud. IEEE Trans. Ind. Inf. 2020, 16, 7369–7380. [Google Scholar] [CrossRef]
- Zou, B.; Qin, J.; Zhang, L. Vehicle Detection Based on Semantic-Context Enhancement for High-Resolution SAR Images in Complex Background. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4503905. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Chanussot, J.; Zareapoor, M.; Zhou, H.; Yang, J. Multipatch Feature Pyramid Network for Weakly Supervised Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5610113. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, M.; Yu, M.; Jan, M.A.; Lan, D.; Taherkordi, A. Mobility-aware multi-hop task offloading for autonomous driving in vehicular edge computing and networks. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Dai, Y.; Yu, J.; Zhang, D.; Hu, T.; Zheng, X. RODFormer: High-Precision Design for Rotating Object Detection with Transformers. Sensors 2022, 22, 2633. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Huang, H.; Pan, S. Using feature alignment can improve clean average precision and adversarial robustness in object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2184–2188. [Google Scholar]
- Chai, W.; Lu, Y.; Velipasalar, S. Weighted average precision: Adversarial example detection for visual perception of autonomous vehicles. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; Volume 2021, pp. 804–808. [Google Scholar]
- Hong, H.; He, K.; Gan, Z.; Jiang, G. Stability Precision Error Correction of Photoelectric Detection by Unmanned Aerial Vehicle. J. Sens. 2021, 2021, 5564448. [Google Scholar] [CrossRef]
- Hoffmann, J.E.; Tosso, H.G.; Santos, M.M.D.; Justo, J.F.; Malik, A.W.; Rahman, A.U. Real-Time Adaptive Object Detection and Tracking for Autonomous Vehicles. IEEE Trans. Intell. Veh. 2021, 6, 450–459. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Wang, Y.; Sheng, T.; Tang, Z. Comprehensive Feature Enhancement Module for Single-Shot Object Detector. In Proceedings of the 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 325–340. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5-Master. Available online: https://github.com/ultralytics/yolov5 (accessed on 4 March 2022).
- Isaac-Medina, B.K.S.; Poyser, M.; Organisciak, D.; Willcocks, C.G.; Breckon, T.P.; Shum, H.P.H. Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1223–1232. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar]
- Lu, Z.; Rathod, V.; Votel, R.; Huang, J. RetinaTrack: Online Single Stage Joint Detection and Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14656–14666. [Google Scholar] [CrossRef]
- Avar, E.; Avar, Y.Z. Moving vehicle detection and tracking at roundabouts using deep learning with trajectory union. Multimed. Tools. Appl. 2022, 81, 6653–6680. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. (ASME) 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 1 2019; pp. 12993–13000. [Google Scholar] [CrossRef]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2015, 193, 102907. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layer | Size | FPS | mAP |
|---|---|---|---|---|
| YOLOv5s | 213 | 13.7 M | 55 | 0.503 |
| YOLOv5-NAM | 219 | 13.9 M | 54.6 | 0.512 |
| Model | Loss | Layer | FPS | mAP |
|---|---|---|---|---|
| YOLOv5s | GIoU | 213 | 55 | 0.503 |
| YOLOv5s | CIoU | 213 | 55 | 0.505 |
| YOLOv5-NAM | GIoU | 219 | 54.6 | 0.512 |
| YOLOv5-NAM | CIoU | 219 | 54.6 | 0.515 |
| Model | NMS | FPS | mAP |
|---|---|---|---|
| YOLOv5s | IoU-NMS | 55 | 0.503 |
| YOLOv5s | SD-NMS | 52 | 0.505 |
| YOLOv5-NAM | IoU-NMS | 54.6 | 0.512 |
| YOLOv5-NAM | SD-NMS | 51.8 | 0.514 |
| Model | NMS | Cars | Buses | Vans | Other | mAP |
|---|---|---|---|---|---|---|
| YOLOv5s | IoU-NMS | 0.697 | 0.433 | 0.743 | 0.139 | 0.503 |
| YOLOv5-NAM | IoU-NMS | 0.7 | 0.46 | 0.731 | 0.175 | 0.517 |
| YOLOv5s | SD-NMS | 0.712 | 0.424 | 0.735 | 0.143 | 0.504 |
| YOLOv5-NAM | SD-NMS | 0.72 | 0.446 | 0.726 | 0.186 | 0.519 |
| Model | Backbone | AP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN [23] | VGG-16 | 0.219 | 0.427 | – | – | – | – |
| Mask R-CNN [24] | R-101-FPN | 0.382 | 0.603 | 0.417 | 0.201 | 0.411 | 0.502 |
| R-FCN [25] | R-101 | 0.299 | 0.519 | – | 0.108 | 0.328 | 0.450 |
| SSD [21] | VGG-16 | 0.288 | 0.485 | 0.303 | 0.109 | 0.318 | 0.435 |
| YOLOv3 [28] | Darknet-53 | 0.33 | – | – | – | – | – |
| RetinaNet [17] | X-101-FPN | 0.390 | 0.594 | 0.417 | 0.226 | 0.434 | 0.509 |
| FCOS [42] | X-101-FPN | 0.421 | 0.621 | 0.452 | 0.256 | 0.449 | 0.520 |
| CenterNet [43] | HG-104 | 0.421 | 0.611 | 0.459 | 0.241 | 0.455 | 0.528 |
| YOLOv4 [29] | CSP | 0.435 | 0.657 | 0.473 | 0.267 | 0.467 | 0.533 |
| YOLOv5s [30] | CSP | 0.355 | 0.55 | – | – | – | – |
| YOLOv5x [30] | CSP | 0.472 | 0.666 | – | – | – | – |
| Ours | CSP-NAM | 0.367 | 0.561 | 0.378 | 0.231 | 0.424 | 0.492 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Dong, Y.; Zhao, S.; Zhang, Z. A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism. Sensors 2023, 23, 724. https://doi.org/10.3390/s23020724
Wang J, Dong Y, Zhao S, Zhang Z. A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism. Sensors. 2023; 23(2):724. https://doi.org/10.3390/s23020724
Chicago/Turabian StyleWang, Jiandong, Yahui Dong, Shuangrui Zhao, and Zhiwei Zhang. 2023. "A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism" Sensors 23, no. 2: 724. https://doi.org/10.3390/s23020724
APA StyleWang, J., Dong, Y., Zhao, S., & Zhang, Z. (2023). A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism. Sensors, 23(2), 724. https://doi.org/10.3390/s23020724