4.1. Why a New Approach Is Needed
The previous algorithms were all based on artificial neural networks, and they performed well under optimal conditions. However, the literature shows that deep neural networks (DNN) can be affected by adversarial attacks [
71]. An adversarial attack is a small perturbation (often called adversarial noise) introduced and tuned by a machine-learning algorithm to induce misclassification in the network. Segmentation neural networks are not immune to these types of attack. For example, in [
72], it was proven that an adversative attack can fool ICNet [
73], which provides semantic segmentation by controlling an autonomously driving car. The changes in the adversative algorithm applied to the input image are so subtle that a real-world light imperfection or a camera sensor not working properly can recreate the adversative pattern, leading to an accident. This unlucky (but possible) scenario reveals the second major problem of these algorithms: they are black boxes, and in many cases, after an accident, the best solution is to train the network again, hoping that no similar issues will affect the network in the future. Therefore, the concept of explainable artificial intelligence (XAI) is becoming increasingly popular. In brief, XAI is an algorithm designed to determine its actions and eventually correct them. This is of crucial importance for the real-world application of deep learning in fields such as robotics, automation, and medicine, because an XAI can be fixed after an error, and a human can eventually be held accountable for its errors. Interpreting results in medical imaging topics is a crucial task for an accurate medical report. An exhaustive survey of recent XAI techniques in medical imaging applications was presented by Chaddad et al. in [
74]. They presented several popular medical image XAI methods, regarding their performance and principles. Therefore, they emphasized the contribution of XAI to problems in the medical field and elaborated on approaches based on XAI models for better interpreting such data. Furthermore, this survey provides future perspectives to motivate researchers to adopt new XAI investigation strategies for medical imaging.
These assertions include the formulation of new methods, in which the DNN performance is guaranteed, and the correct approach of XAI must be considered. Therefore, our strategy defines a new method based on neuronal electric activity in brain, and which has formal correctness and good DNN performance, as well as in the presence of adversative noise.
4.2. Wired Behaviors in Neuronal Electric Activity
The crucial role of neuronal electric activity in brain cognitive processes is well known, for this reason it is important to describe neuronal networks in terms of wired behavior. Then, the first step is to determine a neuron model able to simulate neuronal electric activity. Use of spiking neuronal networks in signal processing is a new frontier in pattern classification, where efficient biologically inspired algorithms are used. In particular, Lobov et al. in [
75] showed that, in generating spikes, the input layer of sensory neurons can encode the input signal based both on the spiking frequency and on the latency. In this case, it implements learning working correctly for both types of coding. Based on this assumption, they investigated how a single neuron [
76] can be trained on patterns and then build a universal support that can be trained using mixed coding. Furthermore, they implemented a supervised learning method based on synchronized stimulation of a classifier neuron, with the discrimination task among three electromyographical patterns. Thier methodology showed a median accuracy 99.5%, close to the result of a multi-layer perceptron trained with a backpropagation strategy.
There are many neuronal models, but the most accurate is the Hodgkin–Huxley model [
77]. However this model is made up of several ODEs (ordinary differential equations) and some PDEs (partial differential equations). Owing to its complexity, less accurate but simpler models are preferred to the Hodgkin–Huxley model for many applications. A popular model in the application is the
Leaky, Integrate and Fire model [
78] (hereafter LIF). Moreover, an interesting methodology was proposed by Squadrani et al. in [
79], the authors planned a hybrid model, in which current deep learning methodologies are merged with classical approaches. The Bienenstock–Cooper–Munro (BCM) model created for neuroscientific simulations is finding applications in the field of data analysis, recording good performances.
The main equation of the LIF model is
where
is the external current,
is the resistor current, and
is the capacitor current. Then, it can be observed that defining
V as the membrane potential, then
and
. Then, it holds
and then
multiplying by
R
where
is the membrane time constant. Observing that
, often the previous equation takes the form
for this reason it can be assumed
(even if experimental findings suggest that is not the case).
However, this differential equation alone cannot model neuronal activity, because it is observed that if the neurons reach a threshold potential, they “fire”, which means that they come back to the resting potential
. Moreover, they keep this value for an interval of time called the refractory time. For this reason, we add to the ODE model the condition that if
V reaches the value
, then
V is reset to
and keeps this value for the refractory time
. It may seem that neuron connectivity has no role in the network activity, but this is not the case, because the term
is still unknown. This term usually includes the synaptic connections. For example, in [
80], given a neuron
i, this term takes the form
where
is not zero if there is a connection starting from the neuron
j and arriving at neuron
i, and in particular
if the connection is excitatory and
if the connection is inhibitory. The term
says that if the neuron
j fires at the time
, then it generates a reaction that is a delta distribution. In conclusion, supposing
G is the connectome of the network,
if and only if
. Therefore, the key role of connectivity in network dynamics is clear.
4.5. Model Description
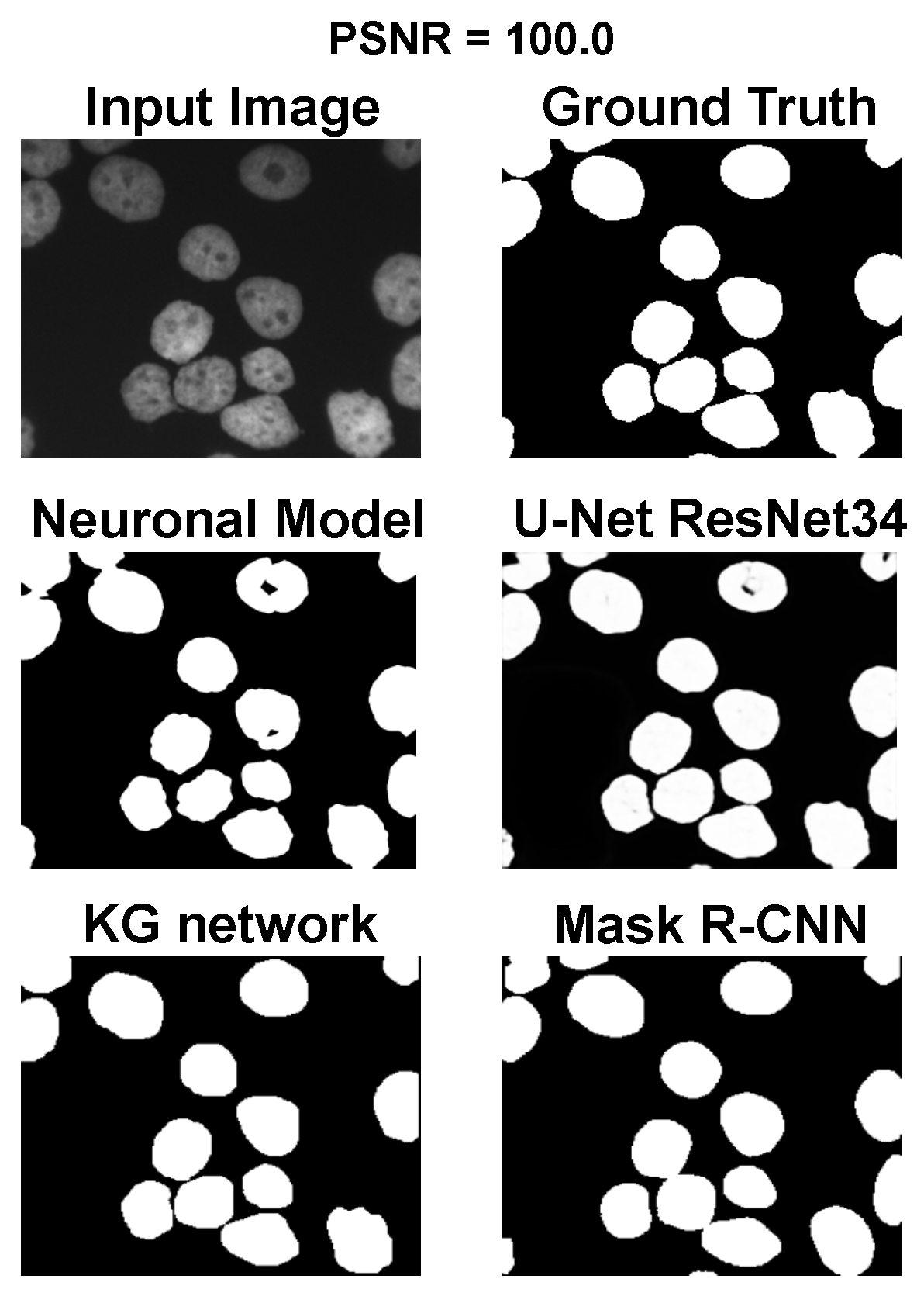
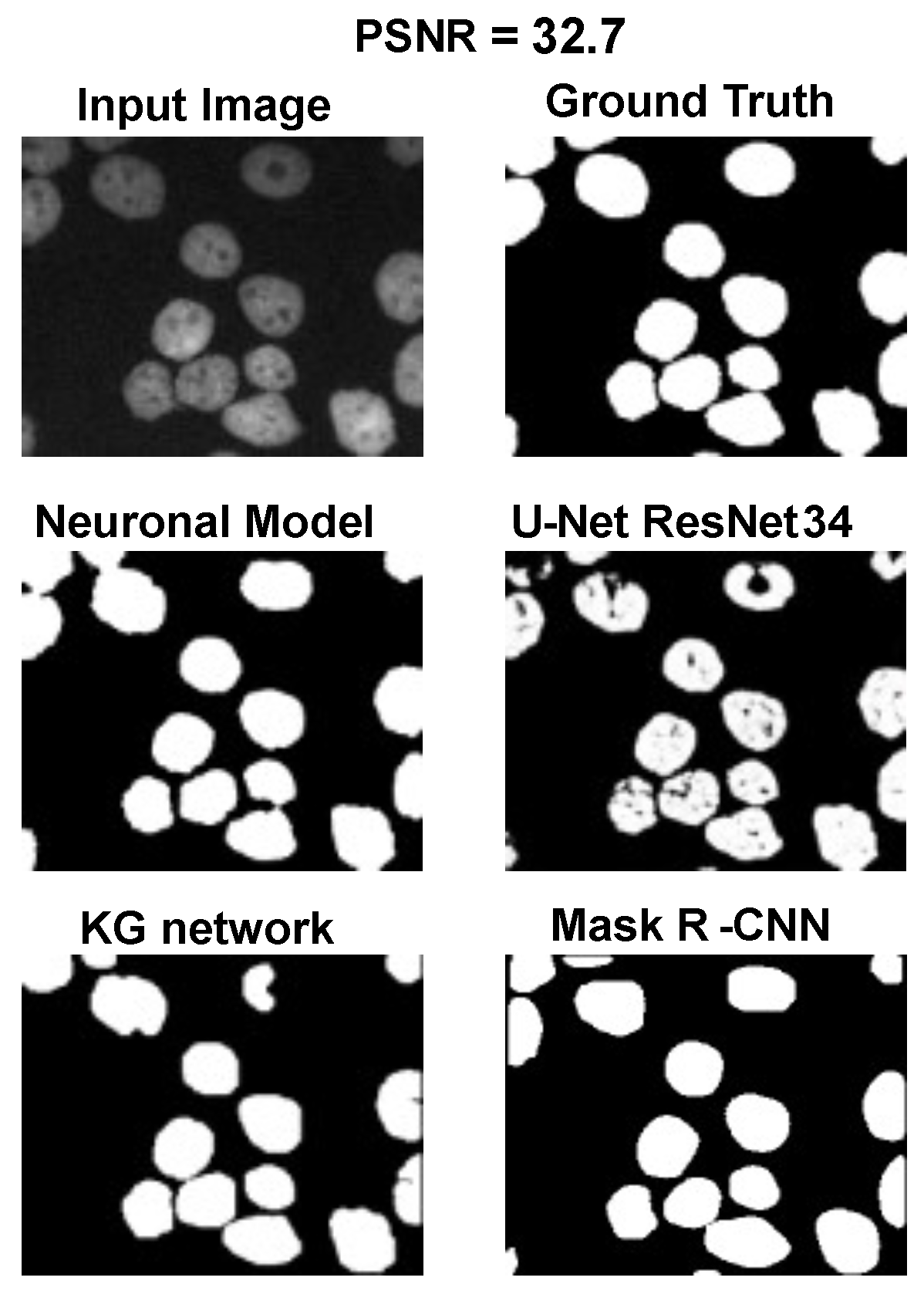
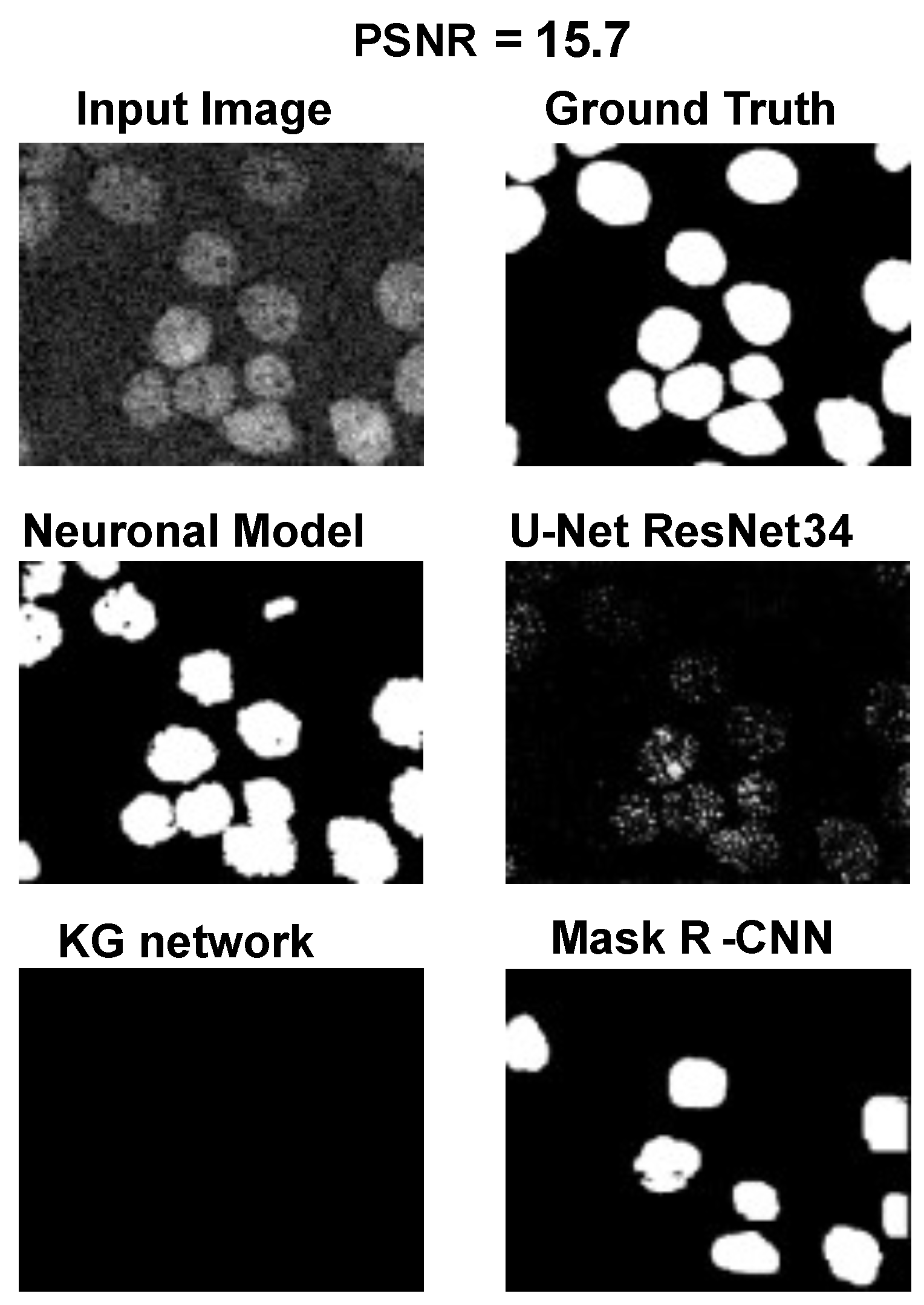
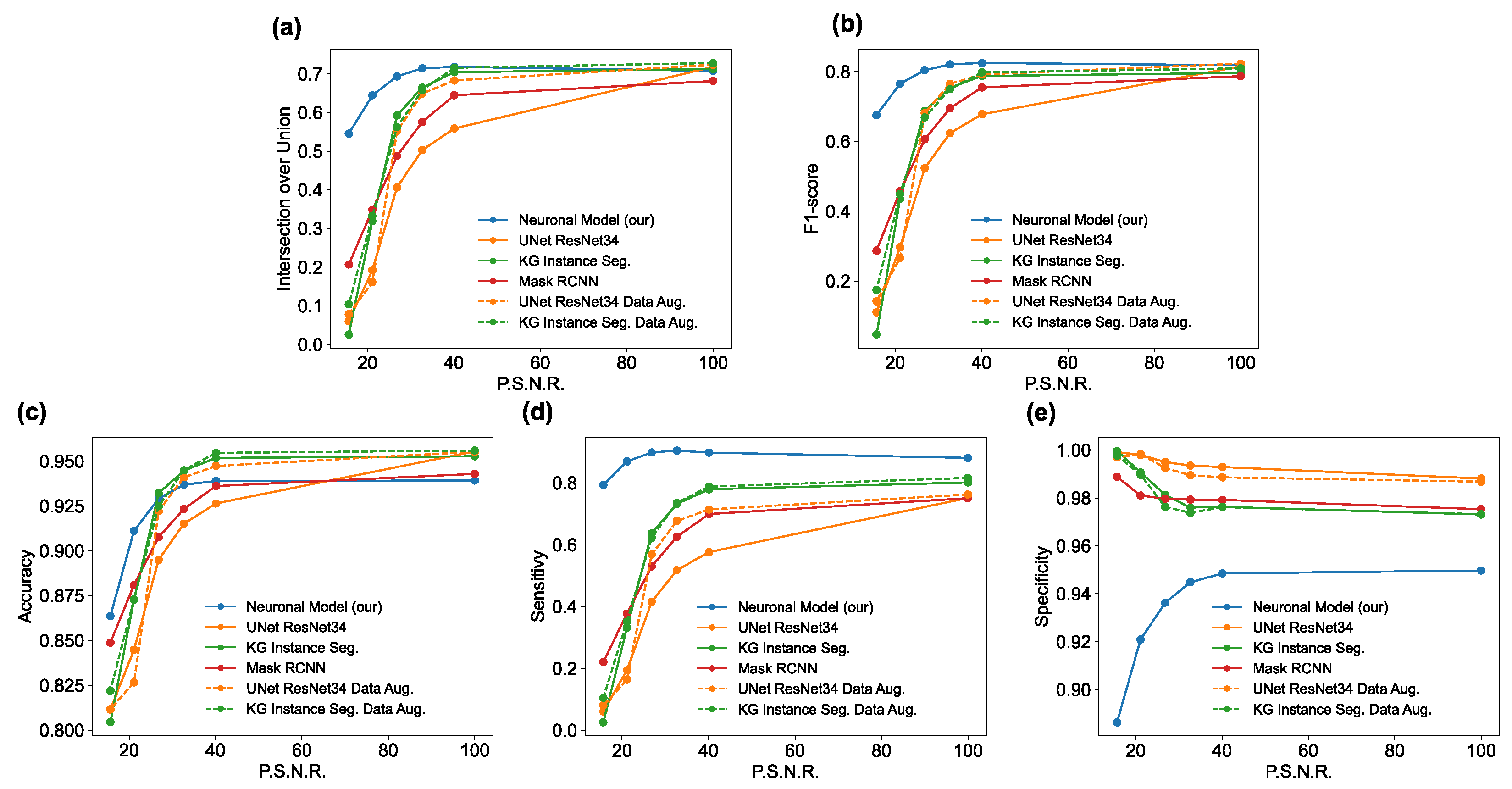
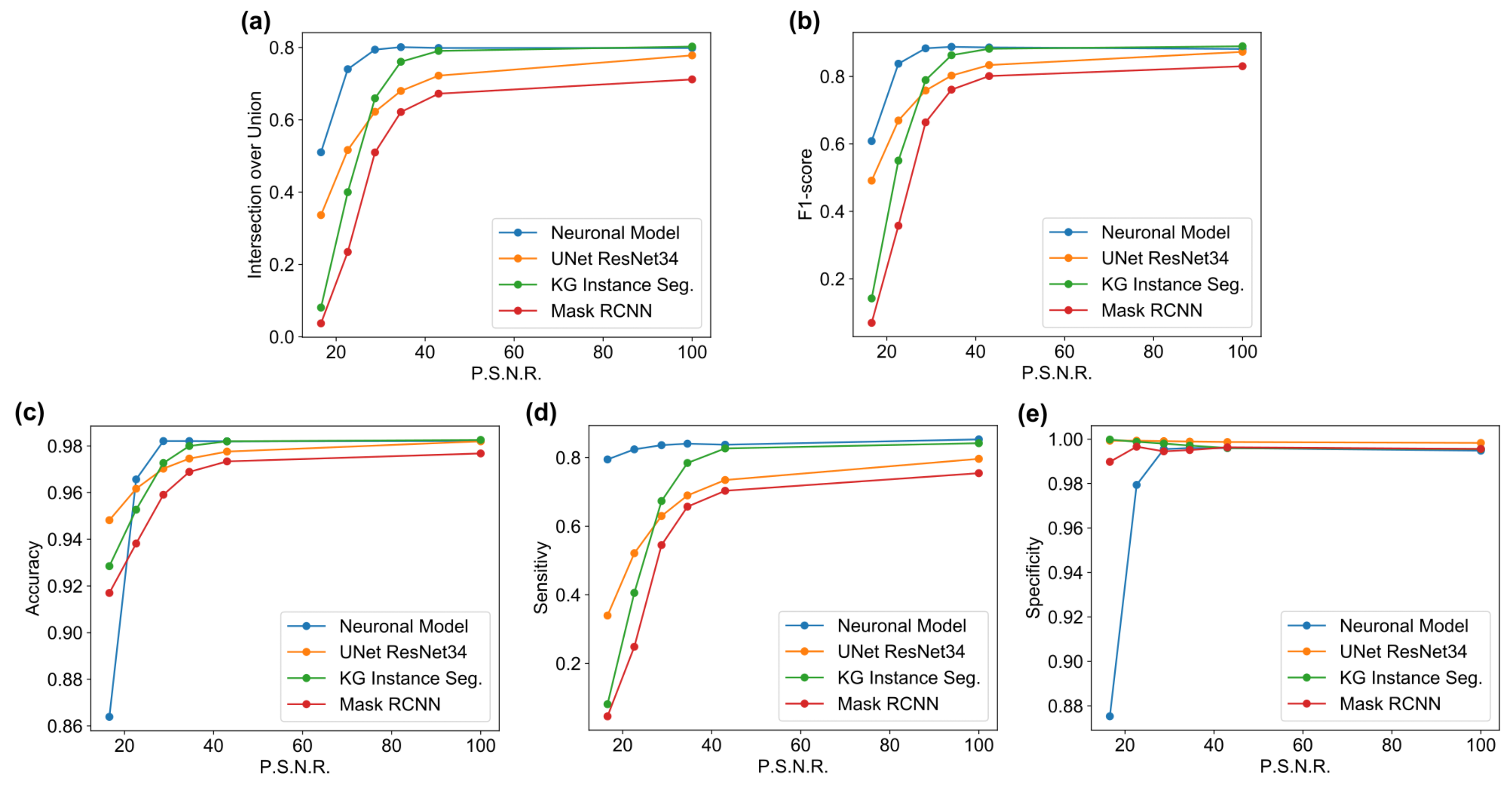
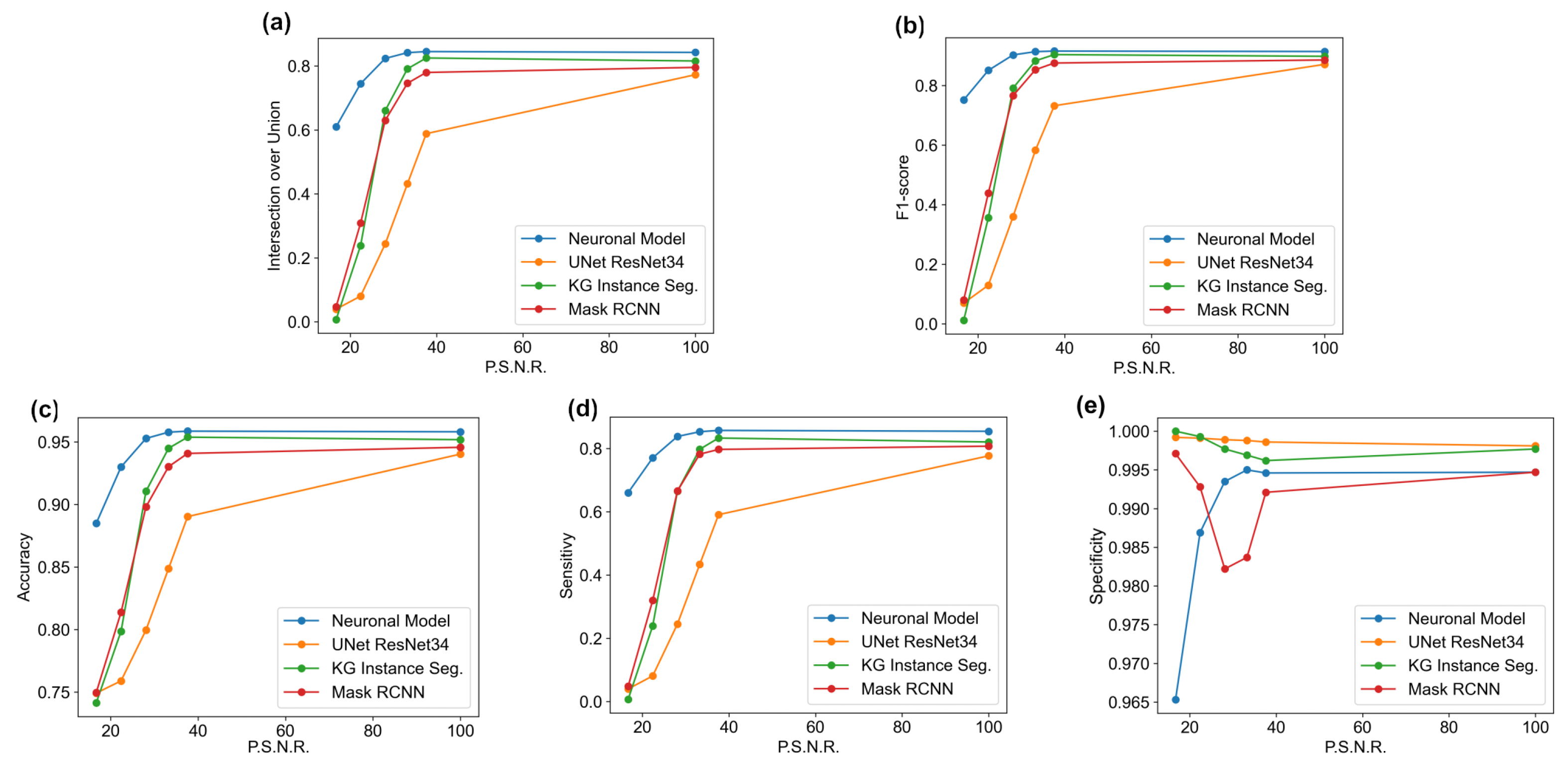
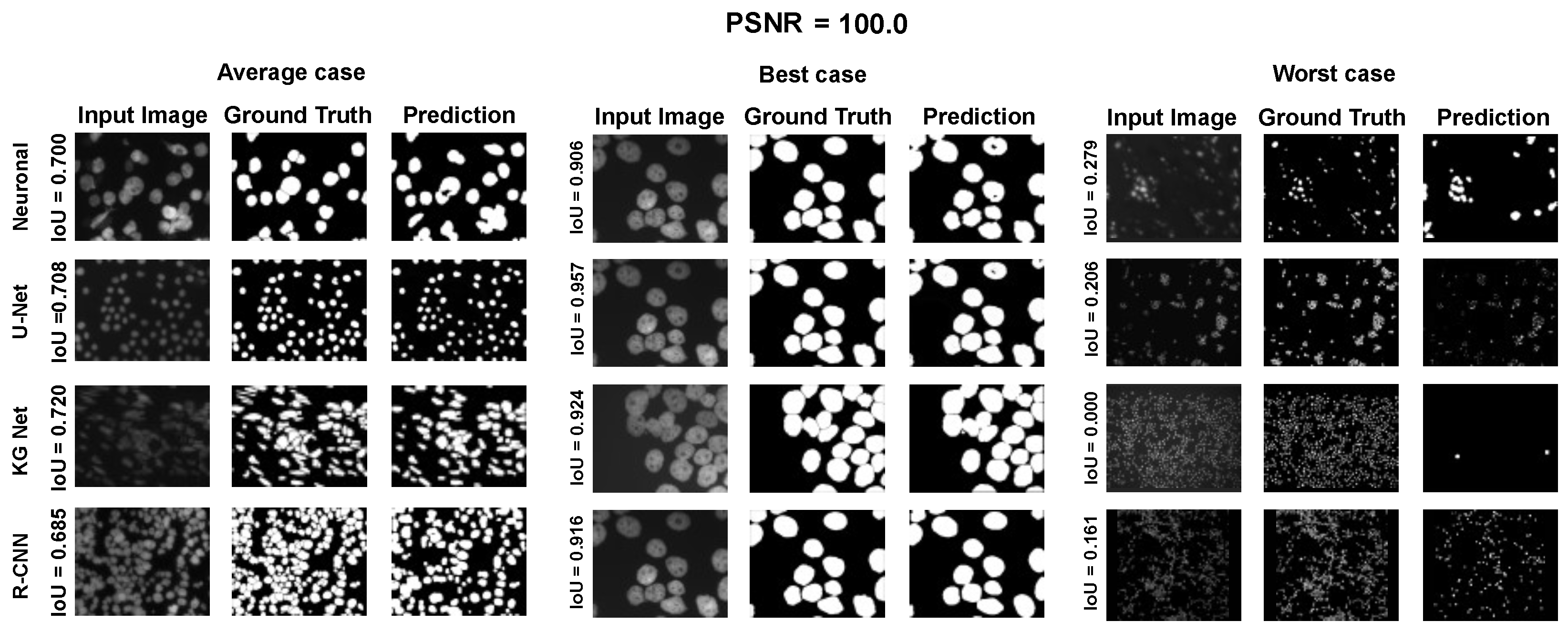
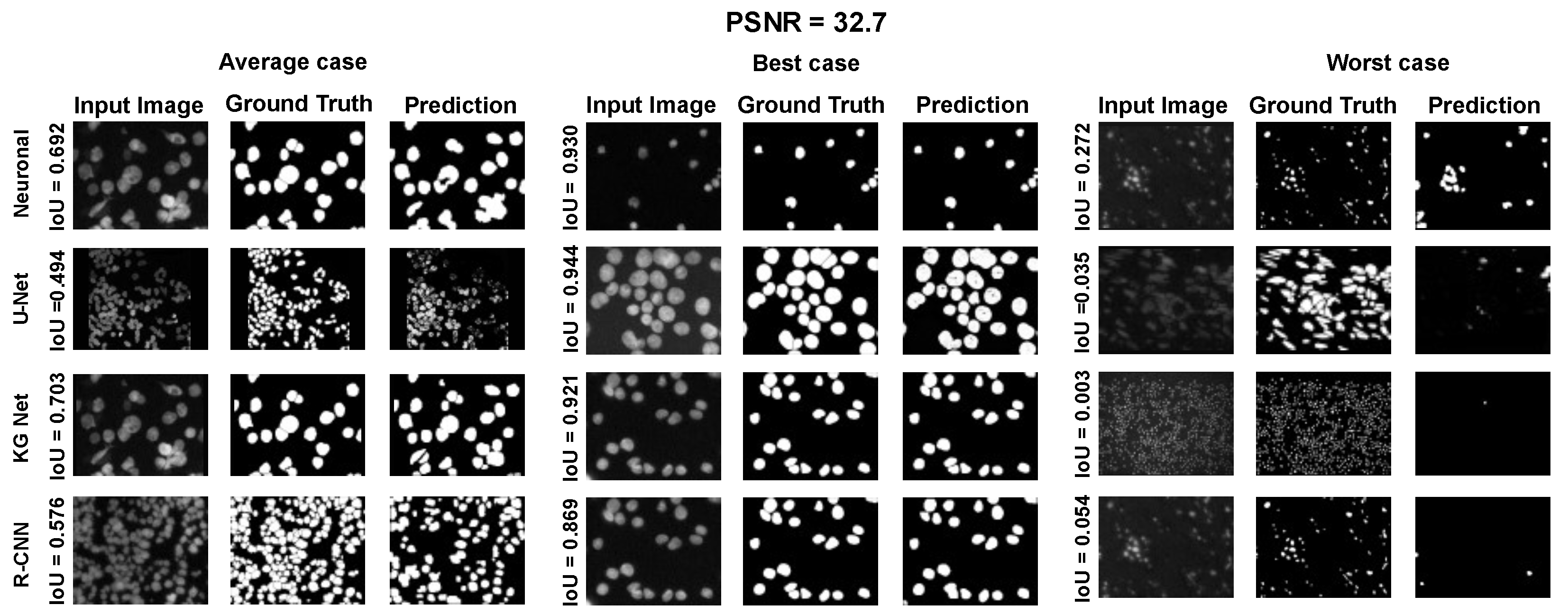
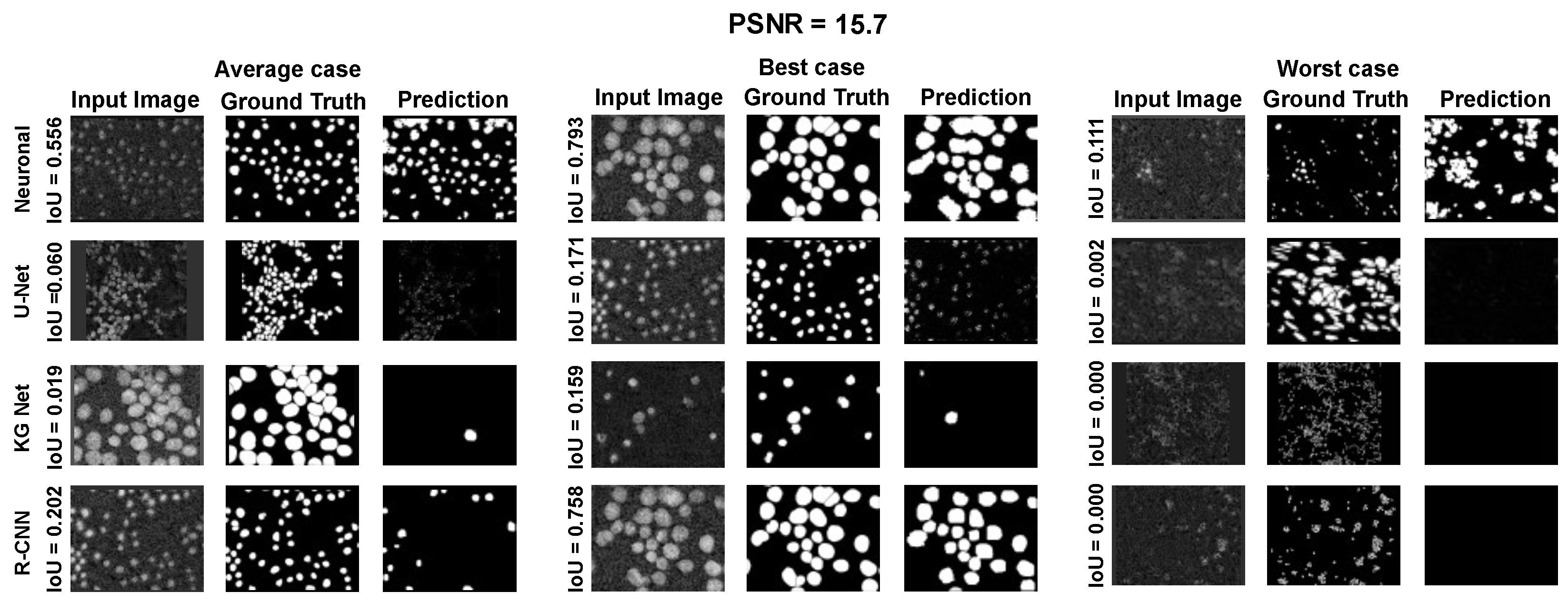
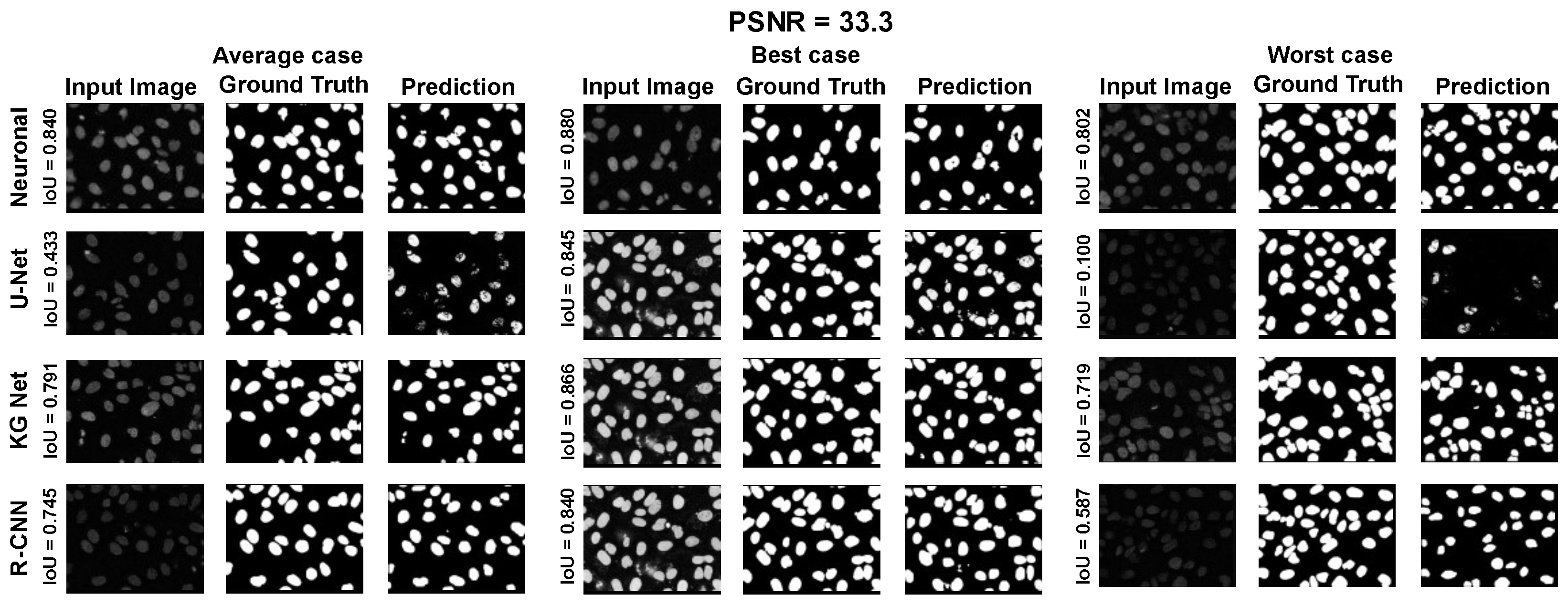
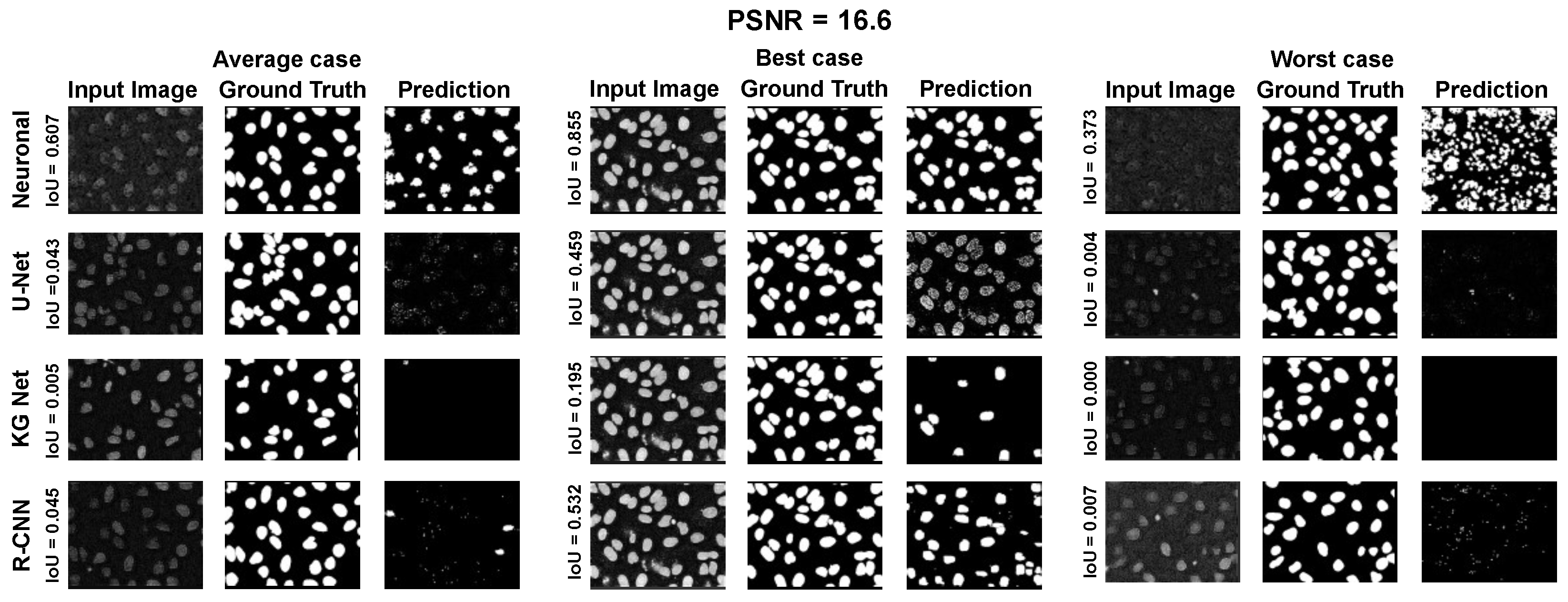
The main goal of the proposed algorithm is to segment bright (colored) cells/nuclei on a dark background in grayscale images. However, the dataset detailed in the previous sections consists of blue or green RGB images. The underlying concept is that the dataset is processed to extract the brightness of cells/nuclei, to obtain a grayscale image suitable for further processing. For example, Hoechst staining data were extracted from the dataset NucleusSegData [
67], which was obtained using U.V. light, and the color of such images was blue. Therefore, in this case, the blue channel was extracted from the image to obtain a grayscale image with the desired properties. Every step is linked to the others using a constant called the scale factor (since now
), which is defined as
where height and width are the dimensions of the image in pixels and
is the average value of image resolution for the neuroblastoma dataset (ex
). This value is introduced to provide scale-invariant properties for the algorithm. In the subsequent paragraphs, it will be necessary to estimate a real number to the nearest odd or even number. Therefore, we introduce the following functions:
and
where
denotes the ceiling approximation. These functions are often used to filter dimensions.
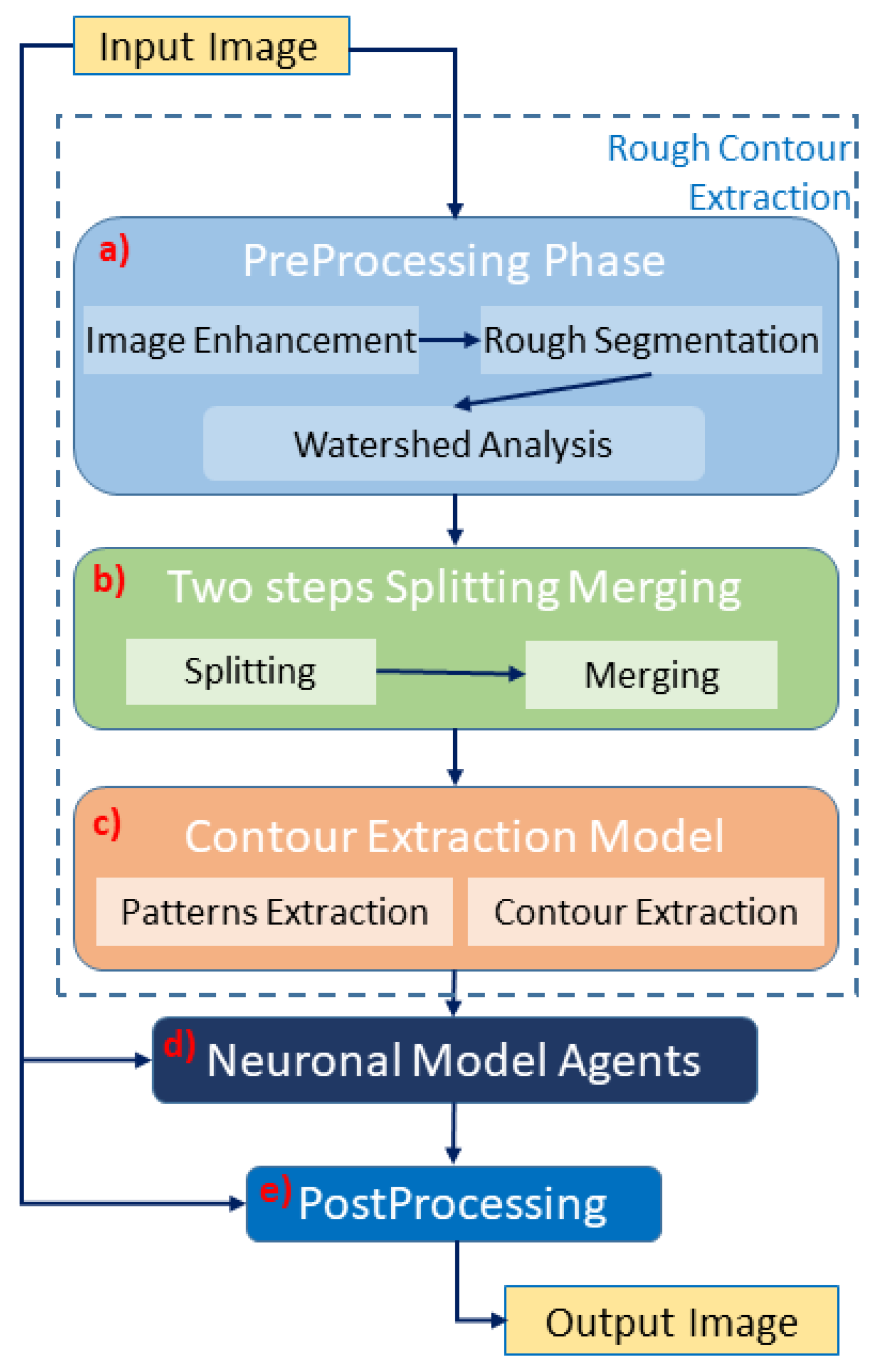
The first phase is the preprocessing (see
Figure 2a), in which a rough contour is evaluated. Thus, the image is enhanced, and a first rough segmentation is performed. Specifically, the grayscale image is sharpened through a convolution process [
54,
81] with this kernel:
Then, a median blur is applied [
54] with a 3 × 3 size. Defining as Img the result of the previous processes, a chain of Gaussian filters [
54] is then applied, with a standard deviation
Next, a type of low-pass filter is calculated using the formula
where
is the pixel-wise multiplication of image
with itself. The
is normalized to be encoded as an 8-bit depth image using the following formula:
Finally, Otsu segmentation [
45] is performed on the image
using OpenCV [
60]. Using the above segmentation, a watershed module performs a transformation [
59] with the OpenCV function [
60] to detect single cells and nuclei (see
Figure 2a). The results at this stage are poor, and further steps are required to achieve optimal performance. The main problems related to this first segmentation concern cells/nuclei that are over segmented (the mask is bigger than the ground truth) or poorly split (many cells/nuclei that should be identified as distinct are classified as a single object). Therefore, we introduced a two steps of splitting and merging task (see
Figure 2b). This routine assumes that the size of cells/nuclei in the image is uniform, and if an object is significantly larger than the average, it is a cluster. Every time the cell/nuclei splitting routine identifies a cluster, it starts trying to split it into a number of cells/nuclei coherent with its surface in relation to the average object size. In detail, the algorithm starts from the grayscale image
, for which is calculated
, as proposed in Equations (1) and (2). Then, an intermediate image is calculated as
Then, the segmentation calculated in the previous phase (with
N cells/nuclei) is loaded, and (defining
as the area of object
i), we calculate
as the average area of an object segmented as
Then, for each object
i, we calculate the ratio
This ratio encapsulates the idea that if an object is two or three times larger than the average, then it is likely to be composed of two or three different cells/nuclei. If , the algorithm attempts to split the object. In this case, the object mask is preprocessed three times through dilatation with size iterations. Then, an iterative process attempts to optimize the number of cells/nuclei using the following routine:
Given (initialized at 190) and (initialized at 0) is calculated
On the image G is performed a threshold at , creating a binary mask
The threshold binary mask is processed three times with an size and two times with an size
is calculated as the number of sufficiently large connected components of thresholding mask
The distance is calculated
If is minimal, this configuration is saved
In any case, if , then else
Return to Step 1, until the desired number of iterations is reached (in this contribution, this number is 10).
In conclusion, the optimal segmentation in terms of
is taken as the result of the splitting procedure. However, the result of this splitting procedure is undersegmentation (any regions marked as the ground truth are not present in segmentation). To combine the positive aspects of the two segmentations, we implement a fusion task between the segmentation results of the watershed module and the split-and-merge task. This process is performed by taking the segmentation computed before the splitting procedure as input. Each marked pixel of the input segmentation is then assigned to the nearest object of the split segmentation. This approach makes it possible to obtain the number of cells/nuclei for splitting segmentation using the binary mask of the original segmentation. This splitting–merge cycle is iterated twice, to improve the segmentation. Next, the contour extraction phase starts, and the result is a collection of binary masks, one for each object. Each mask is dilated three times with a kernel of the size
and then eroded three times with a kernel of size
(Pattern extraction phase in
Figure 2c). The mask is then subdivided into 30 radial bins, and the mean radius is calculated for each bin. A collection of 30 points following the contour of the mask is obtained from the bin angle and the average radius. This phase is shown in
Figure 2c as a contour–extraction module and then, the generated contour provides an idea of the displacement of an object, but this is not sufficiently precise to challenge the state-of-the-art models.
Therefore, each point of the contour is associated with a neuronal agent in the neuronal model phase (see
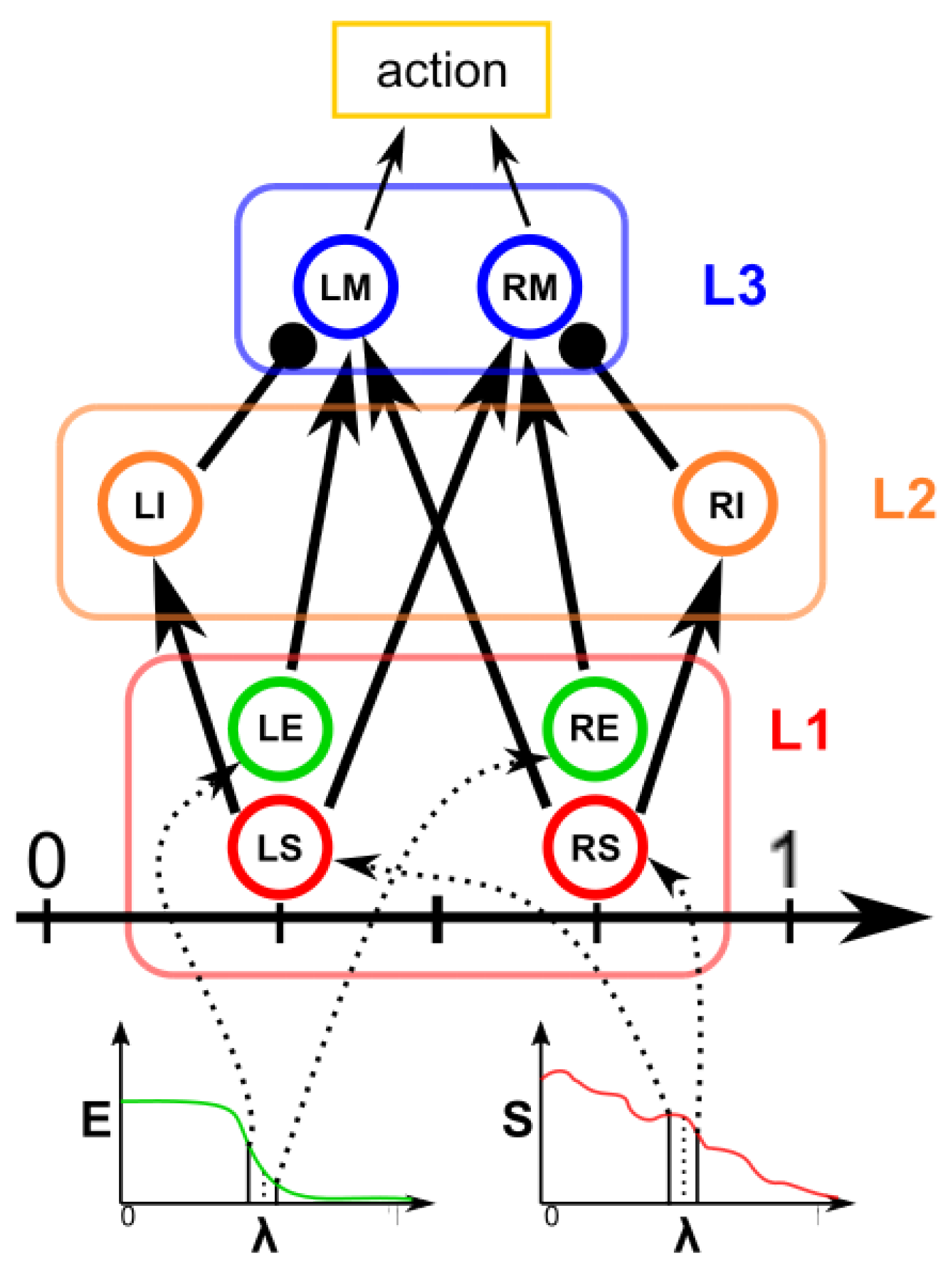
Figure 2d), which moves along the line starting from the center of the object and passing through the original contour point. This agent is then a 1D agent that can move in the direction of the center or away from the center. The motion of the agent is controlled by the simple idea that the agent is repulsed by high grayscale values in the input image but is attracted by the segmentation mask previously computed. These conditions create a system that converges on the position of equilibrium, which is the actual contour of the object. The agent is the neuronal network introduced in
Section 4.2 and built into NEST [
82], with eight neurons distributed in three layers (see
Figure 3). The first layer (L1) is the input layer and is composed of four neurons: the LS, LE, RE, and RS. To calculate the intensity of the current to which these neurons are subjected, we need to calculate the images
where
is a function of histogram equalization.
In conclusion, for each pixel
, it is possible to calculate
where
is defined as the average grayscale value of
. The defined mask as the binary mask obtained by the previous steps is dilated three times with a kernel of size
.
, the 3000 value is the stimulation intensity, and 3/8 is an empirical value fixed for all experiments.
Now, if
is the center of the object and
is the contour position, for each agent, the coordinate
is introduced, such that the position of the agent can be expressed as
We defined the stimulation current for the neurons LS (
), RS (
), LE (
), and RE (
) as
The neuron LS has an excitatory synapse on the neuron LI and the neuron RM; in contrast, the neuron RS has an excitatory synapse on the neuron RI and the neuron LM. The LE and RE neurons have excitatory synapses on the LM and RM neurons, respectively. The role of this first layer is to “perceive” the image configuration and send it to the next layers.
The second layer (L2) is made up of two inhibitory neurons, LI and RI, which have an inhibitory synapse on the neurons LM and RM. Their role is to inhibit the motor neurons LM and RM when the LS and RS neurons are activated. Neurons LM and RM, included in layer 3, are responsible for the motion of the agent. The speed of the agent is calculated as
where
and
are the number of spikes in the simulation window (5 ms). Following the previous steps, each agent reaches the convergence point. After this, the agent mask is postprocessed in the post-processing phase with a standard binary segmentation [
62] inside the masks, which has a good performance, because its content is bimodal (see
Figure 2e). However, some cells/nuclei are still clustered, and for this reason, a final splitting and merge cycle is performed. This final splitting differs from the previous splitting because it is based on the distance transform L2 [
83].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
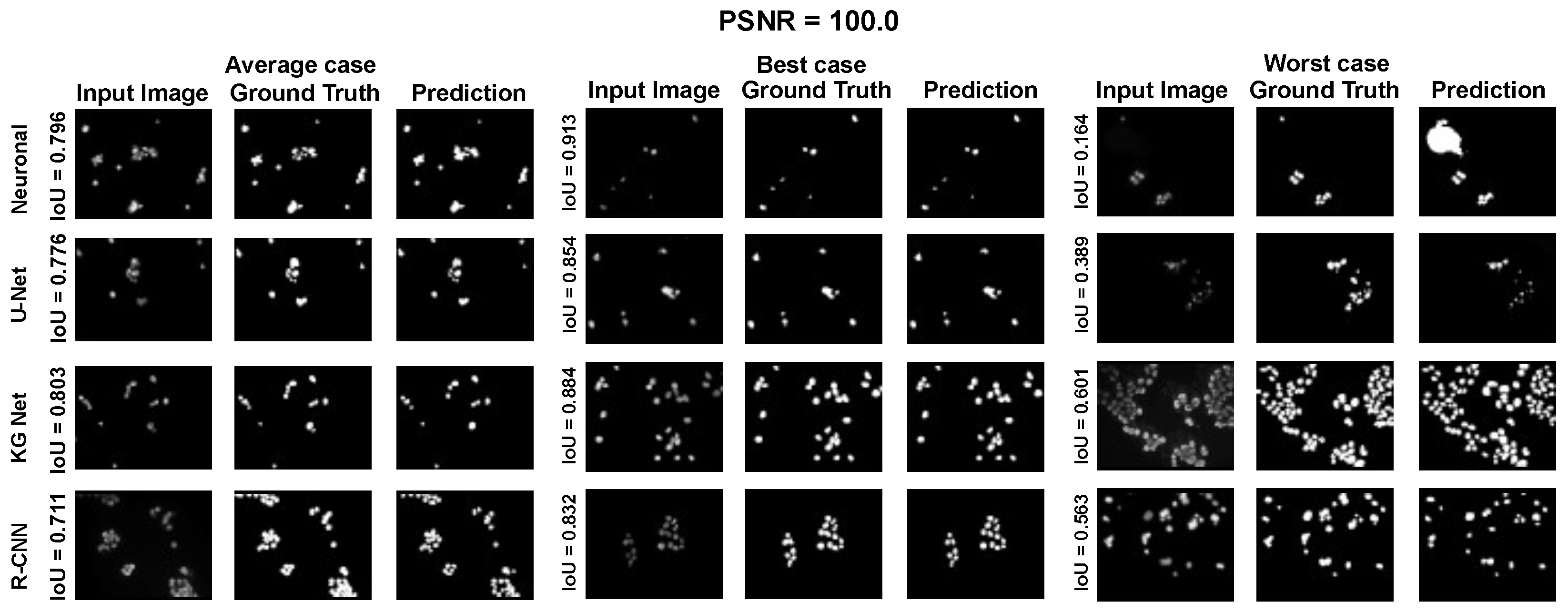{kind=link}
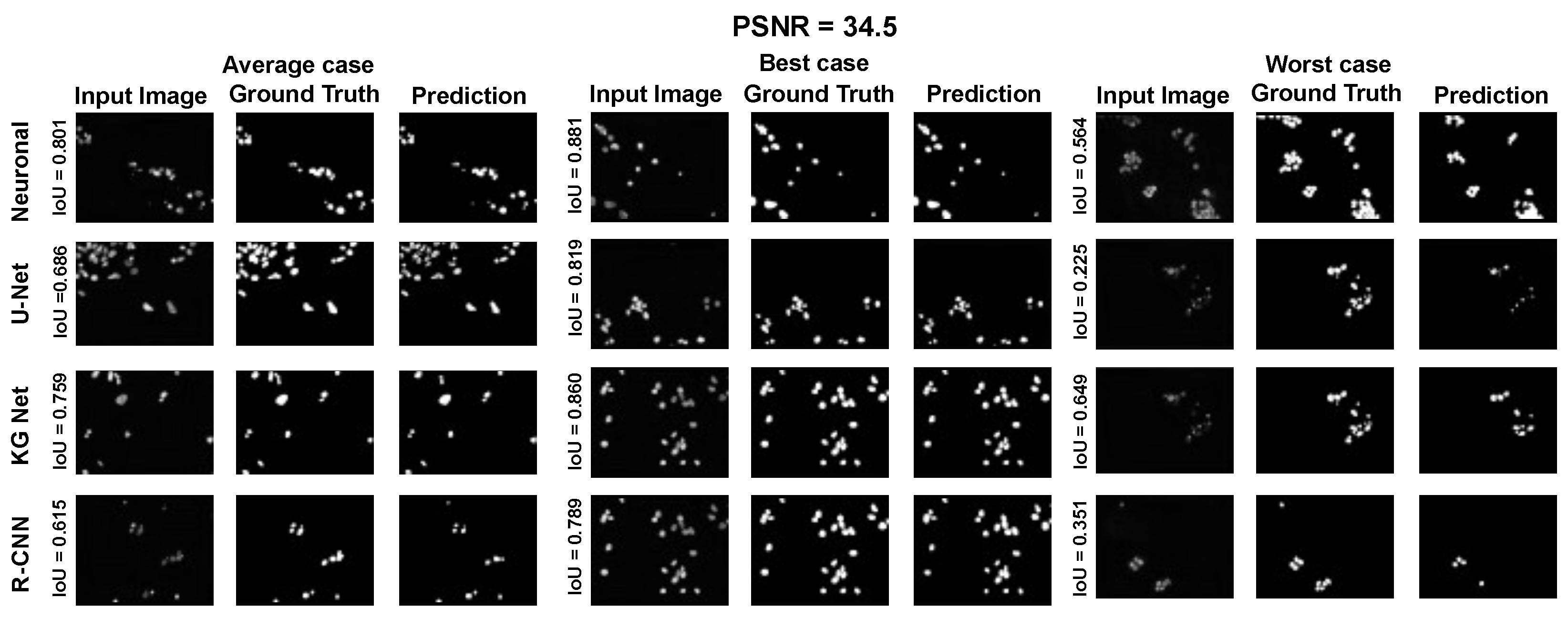{kind=link}
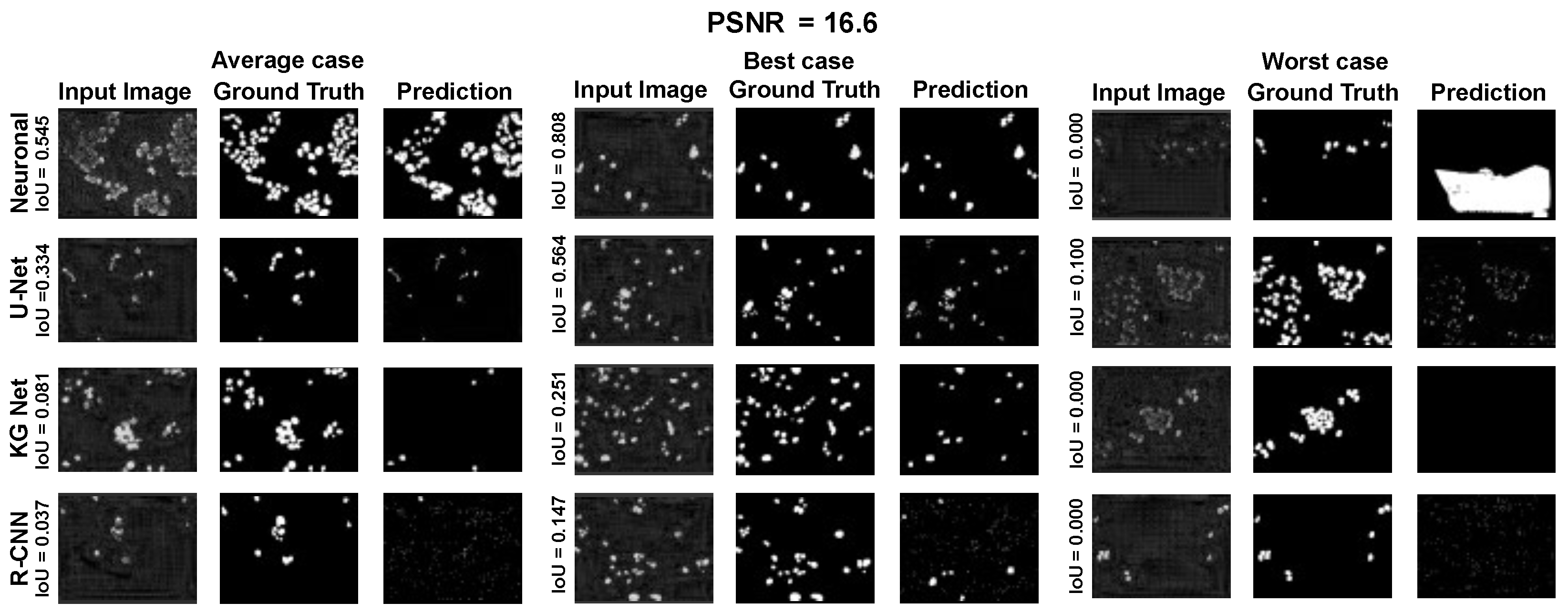{kind=link}
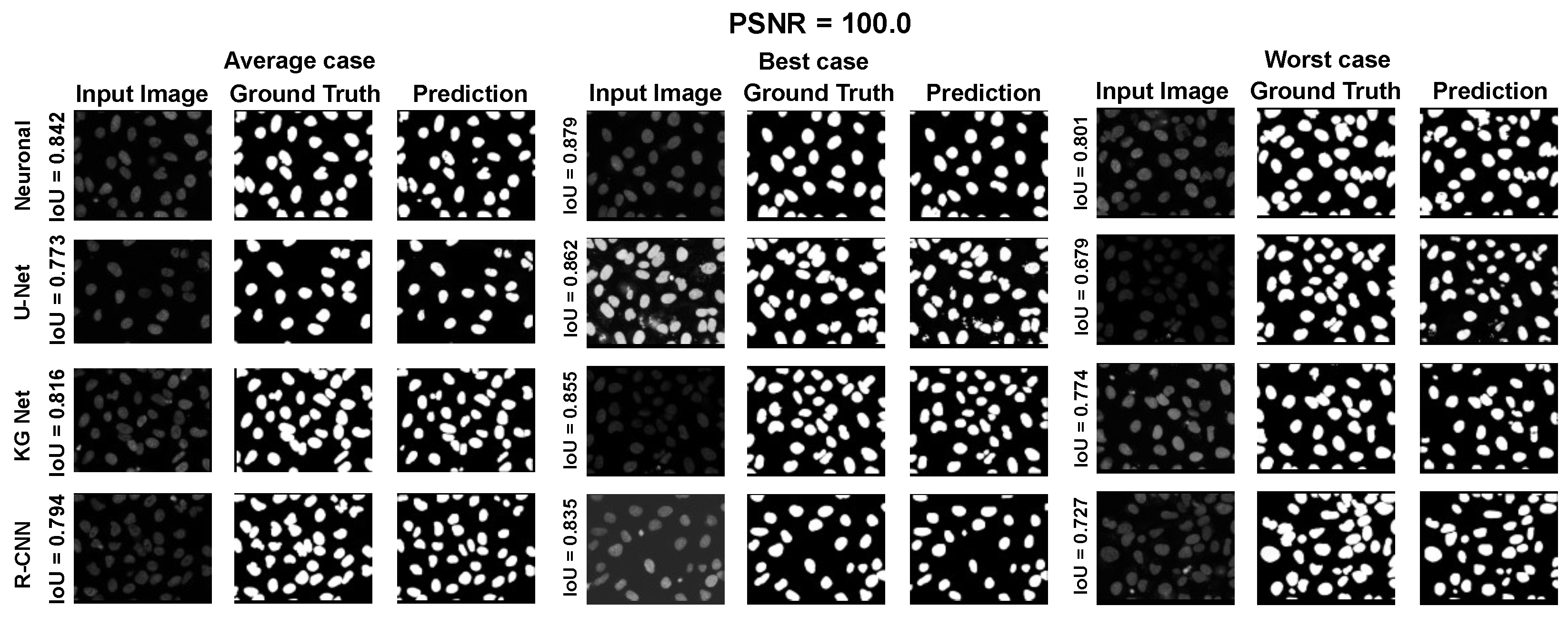{kind=link}
{kind=link}
{kind=link}








