
Method for Predicting RUL of Rolling Bearings under Different Operating Conditions Based on Transfer Learning and Few Labeled Data



Abstract
1. Introduction
- (1)
- A DAAN is used to address the problem that a network trained by data under one condition cannot then be used for different conditions. Transfer learning and MMD are employed to reduce the differences in vibration signals under different operating conditions, so the network can be used under different conditions.
- (2)
- To train the network, labeled data are needed for only one operating condition. For other conditions, unlabeled data are used. This eliminates the difficulty of obtaining large quantities of labeled data of different operating conditions.
- (3)
- Compared with the results of similar previous works, the method proposed here results in more accurate performance, with fewer data to train.
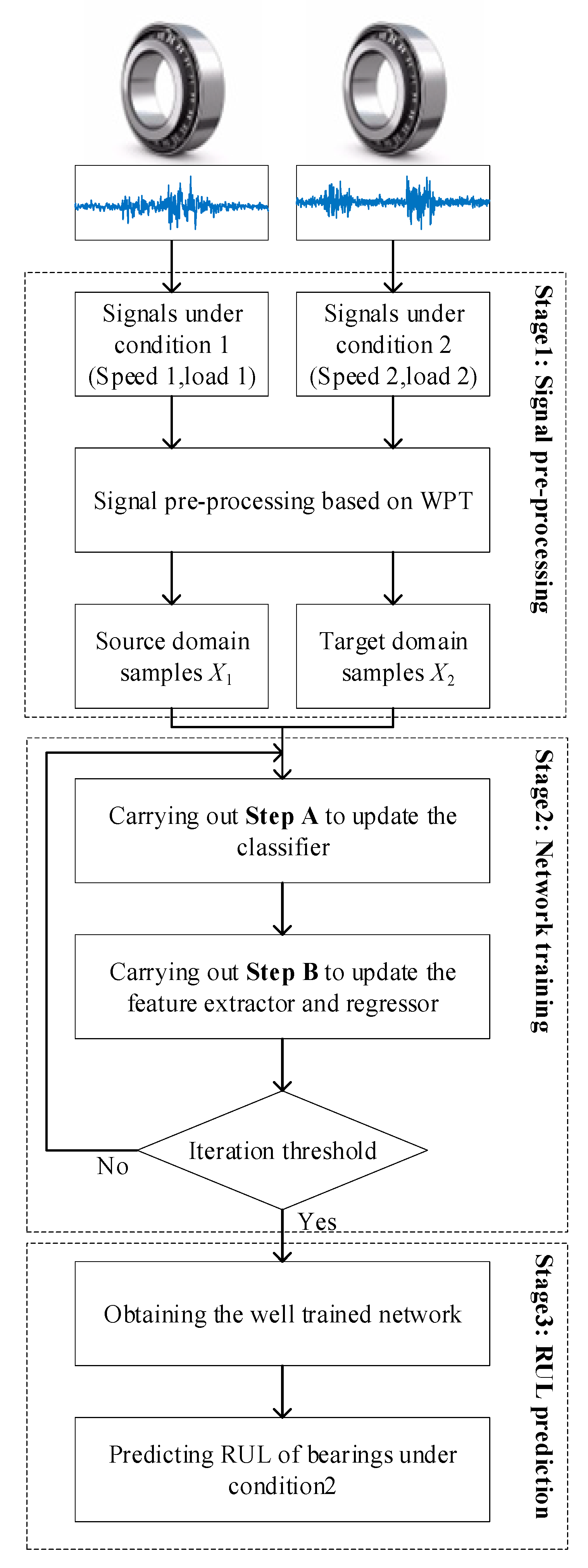
2. Proposed Method
2.1. Signal Preprocessing
2.2. Network Training
- Step A
- Step B
2.3. RUL Prediction
3. Experiment
3.1. Data Description and Parameters Configuration
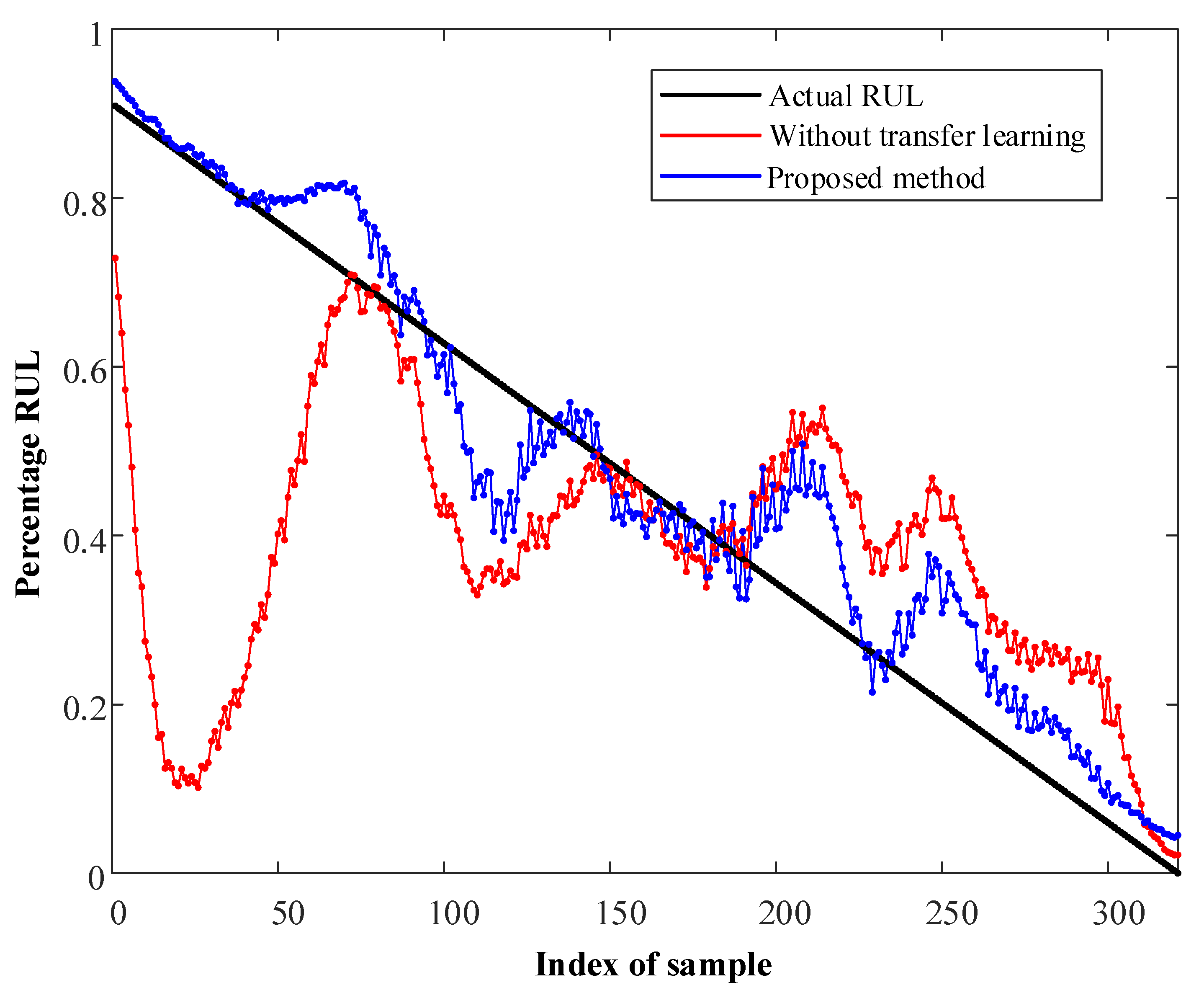
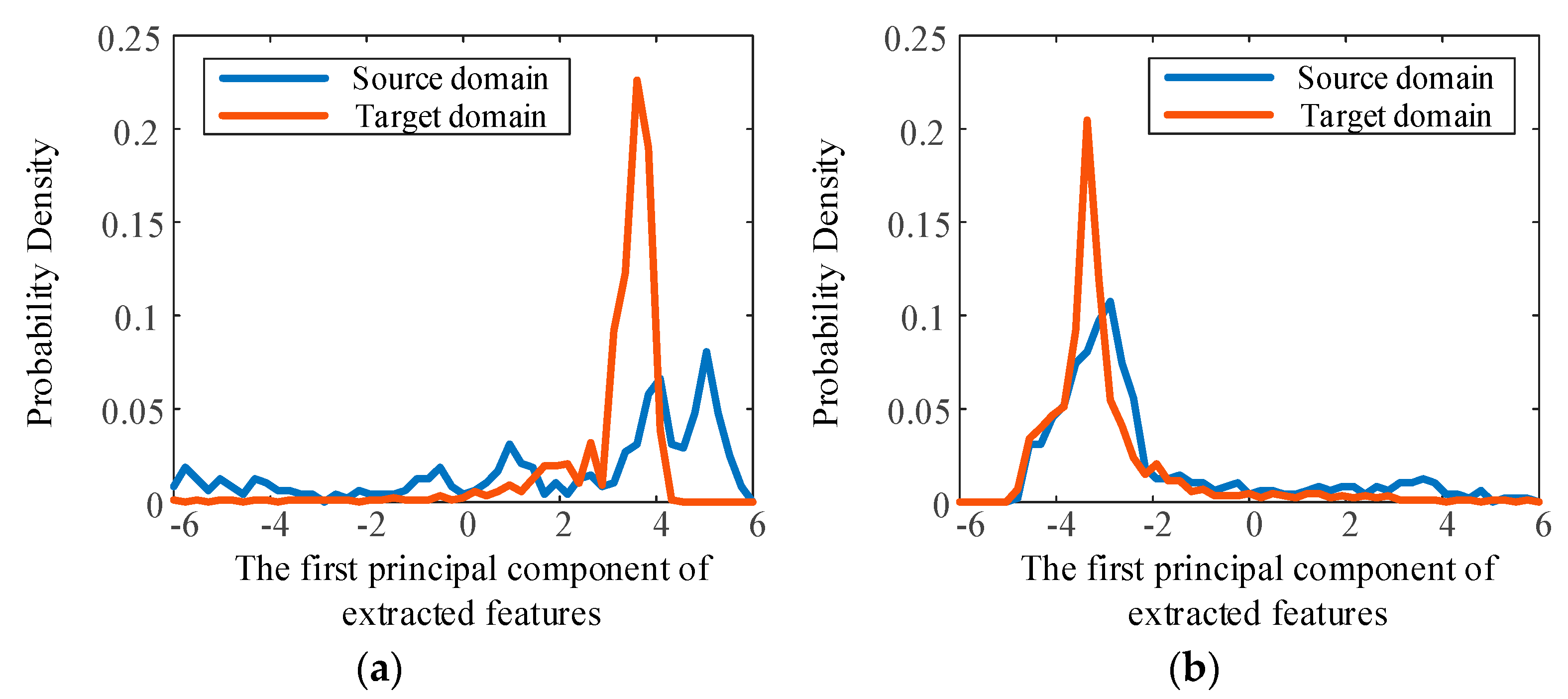
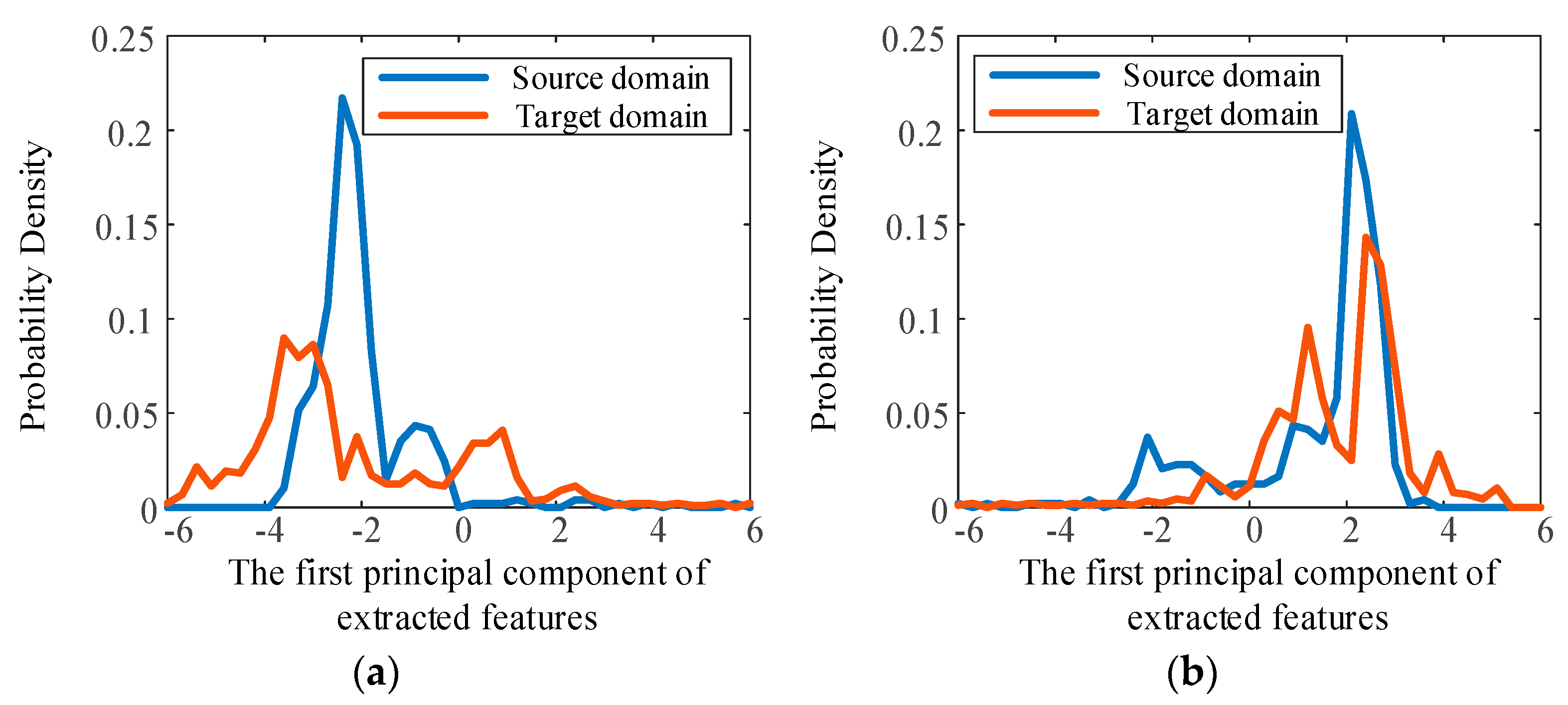
3.2. Validity and Generalization of the Proposed Method
- (1)
- RMSE is calculated as in (9) and can be used for measuring the average absolute error.
- (2)
- MAPE is calculated as in (10) and can be used for measuring relative error.
- (3)
- Precision [26] is calculated as in (11), and this metric can quantify the dispersion of the prediction error around its mean.
3.3. The Robustness of the Method
3.4. Comparison with Related Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Noun | Abbreviation |
| Electric machine system | EMS |
| Remaining useful life | RUL |
| Domain-adaptive adversarial network | DAAN |
| Convolutional neural network | CNN |
| Maximum mean discrepancy | MMD |
| Bidirectional long short-term memory | Bi-LSTM |
| Separation and domain fusion | SAE-CSDF |
| Wavelet package transformation | WPT |
| Mean square error | MSE |
| Root-mean-squared error | RMSE |
| Mean absolute percentage error | MAPE |
| Principal component analysis | PCA |
| Deep metric transfer learning for kernel regression | DTMLKR |
| Stacked contractive auto-encoder | SCAE |
| Multikernel maximum mean discrepancy | MK-MMD |
| Transfer learning method based on multilayer perceptron | TLMLP |
References
- Lei, Y.; Lin, J.; Zuo, M.J.; He, Z. Condition monitoring and fault diagnosis of planetary gearboxes: A review. Measurement 2014, 48, 292–305. [Google Scholar] [CrossRef]
- Yu, J. A nonlinear probabilistic method and contribution analysis for machine condition monitoring. Mech. Syst. Signal Process. 2013, 37, 293–314. [Google Scholar] [CrossRef]
- Qiao, W.; Lu, D. A survey on wind turbine condition monitoring and fault diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 6536–6545. [Google Scholar] [CrossRef]
- Tang, Y.X.; Lee, Y.H.; Amran, M.; Fediuk, R.; Vatin, N.; Kueh, A.B.H.; Lee, Y.Y. Artificial Neural Network-Forecasted Compression Strength of Alkaline-Activated Slag Concretes. Sustainability 2022, 14, 5214. [Google Scholar] [CrossRef]
- Abhyankar, A.; Patwardhan, A.; Paliwal, M.; Inamdar, A. Identification of Flooded Areas Due to Severe Storm Using Envisat ASAR Data and Neural Networks. J. Civ. Eng. Sci. Technol. 2019, 10, 113–120. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Liu, Z.; Fang, L.; Jiang, D.; Qu, R. A Machine-Learning-Based Fault Diagnosis Method with Adaptive Secondary Sampling for Multiphase Drive Systems. IEEE Trans. Power Electron. 2022, 37, 8767–8772. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Zhao, C.; Qu, Y.; He, D. Early Gear Pitting Fault Diagnosis Based on Bi-directional LSTM. In Proceedings of the 2019 Prognostics and System Health Management Conference, Qingdao, China, 25–27 October 2019. [Google Scholar]
- Wang, B.; Lei, Y.; Li, N.; Wang, W. Multi-Scale Convolutional Attention Network for Predicting Remaining Useful Life of Machinery. IEEE Trans. Ind. Electron. 2020, 68, 7496–7504. [Google Scholar] [CrossRef]
- Feilong, F.; Ming, C.; Qian, L. Naturally-induced Early Aviation Bearing Fault Test and Early Bearing Fault Detection. In Proceedings of the 2021 Global Reliability and Prognostics and Health Management, Nanjing, China, 15–17 October 2021. [Google Scholar]
- Wang, Y.; Wu, C.; Herranz, L.; van de Weijer, J.; Gonzalez-Garcia, A.; Raducanu, B. Transferring GANs: Generating Images from Limited Data. In Proceedings of the15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xiao, G.; Wu, Q.; Chen, H.; Cao, D.; Guo, J.; Gong, Z. A Deep Transfer Learning Solution for Food Material Recognition Using Electronic Scales. IEEE Trans. Ind. Inform. 2020, 16, 2290–2300. [Google Scholar] [CrossRef]
- Han, L.; Zhao, Y.; Chen, H.; Chandrasekar, V. Advancing Radar Nowcasting through Deep Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Selver, M.A.; Toprak, T.; Seçmen, M.; Zoral, E.Y. Transferring synthetic elementary learning tasks to classification of complex targets. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2267–2271. [Google Scholar] [CrossRef]
- Wang, Z.; He, X.; Yang, B.; Li, N. Subdomain Adaptation Transfer Learning Network for Fault Diagnosis of Roller Bearings. IEEE Trans. Ind. Electron. 2022, 69, 8430–8439. [Google Scholar] [CrossRef]
- Sun, M.; Wang, H.; Liu, P.; Huang, S.; Wang, P.; Meng, J. Stack Autoencoder Transfer Learning Algorithm for Bearing Fault Diagnosis Based on Class Separation and Domain Fusion. IEEE Trans. Ind. Electron. 2022, 69, 3047–3058. [Google Scholar] [CrossRef]
- Eom, Y.H.; Yoo, J.W.; Hong, S.B.; Kim, M.S. Refrigerant charge fault detection method of air source heat pump system using convolutional neural network for energy saving. Energy 2019, 187, 115877. [Google Scholar] [CrossRef]
- Wang, H.; Sun, W. Motor Bearing Fault Diagnosis Based on Wavelet Packet Analysis and Sparse Filtering. In Proceedings of the 2021 IEEE 4th International Electrical and Energy Conference (CIEEC), Wuhan, China, 28–30 May 2021. [Google Scholar]
- Shu-Ting, W.; Lu-Yong, L. The fault diagnosis method of rolling bearing based on wavelet packet transform and zooming envelope analysis. In Proceedings of the 2007 International Conference on Wavelet Analysis and Pattern Recognition, Beijing, China, 2–4 November 2007. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent Progress on Generative Adversarial Networks (GANs): A Survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- da Costa, P.R.d.O.; Akçay, A.; Zhang, Y.; Kaymak, U. Remaining useful lifetime prediction via deep domain adaptation. Reliab. Eng. Syst. Saf. 2022, 195, 106682. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal. Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.-P.; Scholkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. In Proceedings of the 14th Conference on Intelligent Systems for Molecular Biology, Fortaleza, Brazil, 6–10 August 2006. [Google Scholar]
- Porotsky, S.; Bluvband, Z. Remaining useful life estimation for systems with non-trendability behaviour. In Proceedings of the 2012 IEEE Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012. [Google Scholar]
- Saxena, A.; Celaya, J.; Saha, B.; Saha, S.; Goebel, K. Metrics for offline evaluation of prognostic performance. Int. J. Progn. Health Manag. 2021, 1, 4–23. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Miao, Q.; Huang, P. Remaining useful life estimation using deep metric transfer learning for kernel regression. Reliab. Eng. Syst. Saf. 2021, 212, 107583. [Google Scholar] [CrossRef]
- Ding, Y.; Ding, P.; Jia, M. A Novel Remaining Useful Life Prediction Method of Rolling Bearings Based on Deep Transfer Auto-Encoder. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Shen, C. A new data-driven transferable remaining useful life prediction approach for bearing under different working conditions. Mech. Syst. Signal Process. 2020, 139, 106602. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating Conditions | Radial Force (kN) | Rotating Speed (rpm) | Training Datasets | Test Datasets |
|---|---|---|---|---|
| Condition2 | 4.2 | 1650 | Bearing2_1 | Bearing2_2 |
| Condition3 | 5 | 1500 | Bearing3_1 | Bearing3_3 |
| Layer | Size | Activation Function |
|---|---|---|
| Input | 32 × 32 | \ |
| Convolutional layer 1 | Kernel: 5 × 5 × 1 Stride: 3 | ReLU |
| Pooling layer 1 | Pool: 1 × 1 Stride: 1 | \ |
| Convolutional layer 2 | Kernel: 5 × 5 × 6 Stride: 2 | ReLU |
| Pooling layer 2 | Pool: 1 × 1 Stride: 1 | \ |
| Net2 | Layer 1: 160 × 10 Layer 2: 10 × 1 | Sigmoid |
| Net3 | Layer 1: 160 × 10 Layer 2: 10 × 1 | Sigmoid |
| Metric | Method | Bearing3_3 | Bearing2_2 |
|---|---|---|---|
| RMSE | Without trans. | 27.23% | 39.90% |
| Proposed | 7.01% | 14.67% | |
| MAPE | Without trans. | 48.00% | 82.2% |
| Proposed | 18.36% | 28.10% | |
| Precision | Without trans. | 26.23% | 20.19% |
| Proposed | 6.48% | 12.63% |
| Standard Deviation of Noise (g) | Bearing3_3 |
|---|---|
| 0.1 | 12.07% |
| 0.2 | 17.22% |
| 0.5 | 17.12% |
| 1 | 17.00% |
| 1.5 | 17.69% |
| 2 | 26.51% |
| Method | Training Bearings ID | Test Bearings ID | Mean RMSE | Mean MAPE | |
|---|---|---|---|---|---|
| Source Domain | Target Domain | ||||
| DTMLKR [27] | Ber1_1,1_2 | Ber2_1,2_2 | Ber2_6 | 15% | 34% |
| SCAE + MK-MMD [28] | Ber1_1,1_2 | Ber2_1,2_2 | Ber2_7 | 10.78% | 14% |
| TLMLP [29] | Ber1_1,1_2,1_3, 1_4,1_5,1_6,1_7 | Ber2_1,2_2 | Ber2_6 | 29.83% | \ |
| Proposed method | Ber3_1 | Ber2_1 | Ber2_2 | 14.67% | 28.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Wang, H.; Liu, Z.; Qu, R. Method for Predicting RUL of Rolling Bearings under Different Operating Conditions Based on Transfer Learning and Few Labeled Data. Sensors 2023, 23, 227. https://doi.org/10.3390/s23010227
Sun W, Wang H, Liu Z, Qu R. Method for Predicting RUL of Rolling Bearings under Different Operating Conditions Based on Transfer Learning and Few Labeled Data. Sensors. 2023; 23(1):227. https://doi.org/10.3390/s23010227
Chicago/Turabian StyleSun, Wei, Haowen Wang, Zicheng Liu, and Ronghai Qu. 2023. "Method for Predicting RUL of Rolling Bearings under Different Operating Conditions Based on Transfer Learning and Few Labeled Data" Sensors 23, no. 1: 227. https://doi.org/10.3390/s23010227
APA StyleSun, W., Wang, H., Liu, Z., & Qu, R. (2023). Method for Predicting RUL of Rolling Bearings under Different Operating Conditions Based on Transfer Learning and Few Labeled Data. Sensors, 23(1), 227. https://doi.org/10.3390/s23010227