1. Introduction
Progress in computer vision tasks such as object detection [
1], semantic segmentation [
2], optical flow [
3], and disparity estimation [
4] has been made in recent decades; however, these tasks mostly rely on monocular or stereo images [
5]. The irreversible loss of depth in 2D images is a flaw in nature, and academics have consistently worked to improve algorithms to address this issue. For instance, point cloud [
6] characteristics are added to object identification models in autonomous driving to provide a multi-modal framework that makes up for the absence of depth in images. Multiple tasks sharing comparable cues would improve overall performance in a heuristic manner, particularly in edges, according to certain research that combines image disparity estimation and semantic segmentation together [
7]. It is obvious that datasets with structural information are crucial because all of the methods mentioned above attempt to employ additional information to generate implicit depth cues.
Recently, some researchers have focused on light fields [
8] because, unlike 2D images, light field images implicitly store the directions of rays. Take into account an array light field camera as an example. Cameras with known intrinsic parameters are positioned in a plane or sphere with a specific distance between them. Although views in depth are condensed on the photosensitive plane of the camera, as in conventional cameras, rays projected in different directions from various views record the third dimension, which is perpendicular to the image plane. View images with known intrinsic and extrinsic factors enable more precise reasoning about scene structures. Overall, light field images with richer structural information will perform better as they are more adaptable to current computer vision applications.
However, there are still some difficulties in obtaining a rich and diversified light field datasets. The most notable one is high cost equipment. The current technical framework of light field mainly consists of three types: microlens array [
9], camera array [
10], and encoded mask [
11]. Both of these are too expensive on the market; as an example, the basic edition of raytrix light field [
12] costs almost close to
$100,000. Such a high price is beyond the acceptance of most researchers and impedes the development of light field technology. An approach is to build a camera array out of inexpensive cameras. These arrays can be placed in a matrix or a circle on the same surface or sphere. Alternatively, you may build a camera array out of inexpensive cameras. These arrays can be set up as a circle or a matrix on the same plane or sphere. Other issues have come up so far, the first of which is the synchronization of many cameras, which is crucial for the perception of dynamic scenes. Another issue is how to arrange the cameras to reduce the redundancy of data from various angles even though images from different views might compensate for one another in dealing with occlusions.
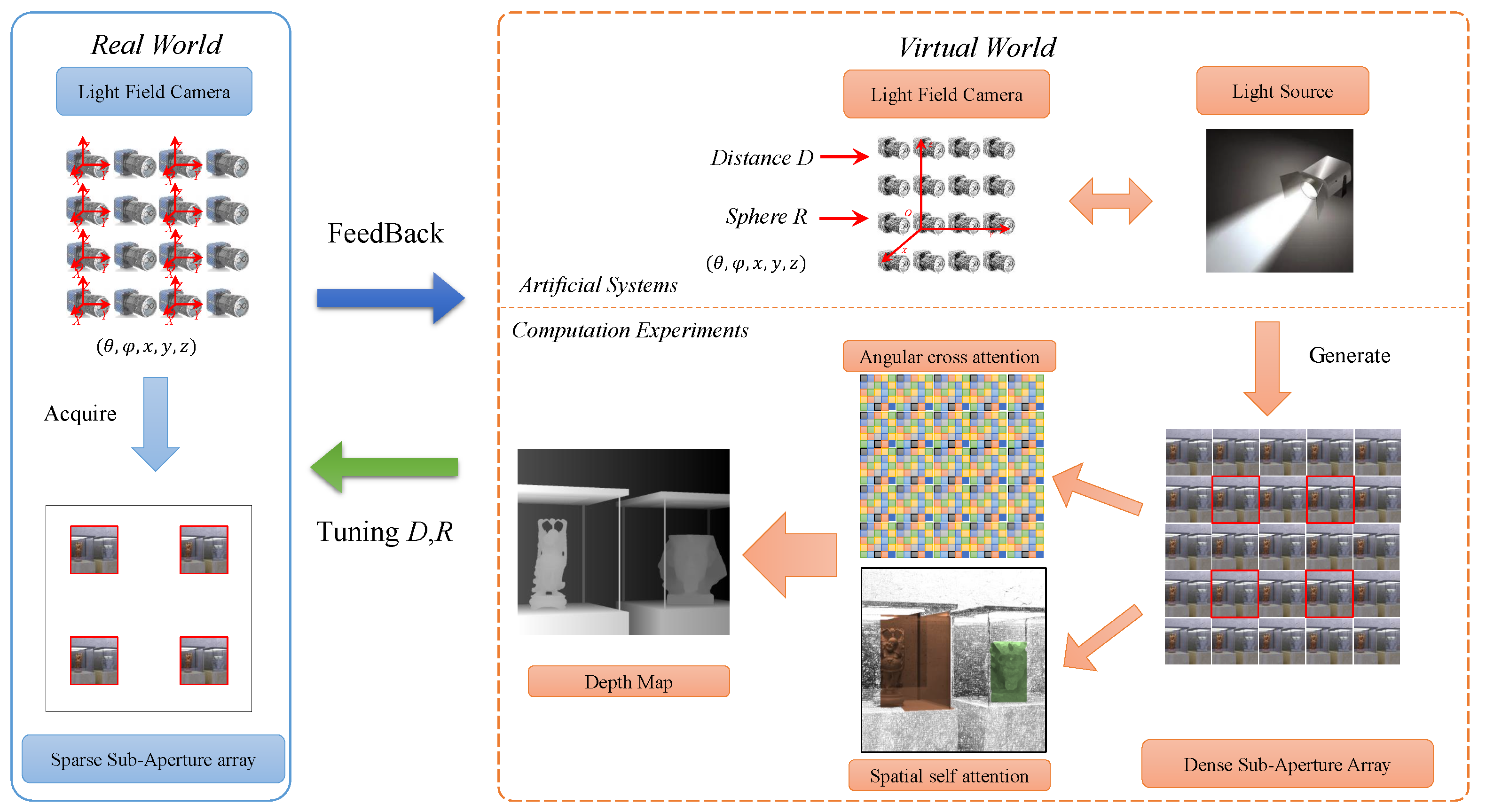
The optimal solution to this issue will significantly improve the perception of autonomous driving’s performance while parameter adjustment is time-consuming and challenging to replicate. Since experiments in the real world are not very efficient, we turn to the virtual world to find a solid plan. To collect static light field scenes with depth and dynamic scene flows, we propose a new light field collection approach based on Parallel Light Fields [
13]. The fundamental idea behind Parallel Intelligence is the ACP theory, where
A stands for Artificial Systems for modeling,
C is for Computational Experiment for analysis, and then
P is Parallel Execution for control. Parallel Intelligence, which is characterized by virtual and real interaction, was first proposed by Fei-Yue Wang in 2004 [
14] to address management and control of complex systems. Based on the ACP theory, we conduct our experiment in virtual environments, such as sensors’ simulations [
15]. To be more precise, we build digital twins of the light, camera, and scenario in the virtual world. By adjusting the parameters of these elements, we can achieve a diverse range of scenarios, which are then captured as light field images by the virtual light field cameras. We can set up numerous deployments till we find an approach that works relatively best to verify the optimum camera arrangement. Our contributions are listed as follows:
We present a new large-scale static light field dataset with up to 50 scenes; each scene contains 8–10 different perspectives, covering interior and outdoor scenes, and ground truth is produced, including disparities, depths, surface normals, segmentations, and item postures;
Using the free and open-source creation tool Blender [
16], we additionally produce a novel light field video with motion ground truth designed for 3D scene flow estimation; in addition to ground truth in static scenes, additional motion information is also collected;
With spatial and angular information that have been decoupled, we experiment with disparity estimation and angular super-resolution. Specifically, experimental results demonstrated our dataset’s potential for disparity estimation and angular super-resolution despite the fact that they contain notably higher disparities than the majority of current light field datasets.
3. Approaches
The first step in Parallel Light Fields is the construction of Artificial Systems, on top of the Computational Experiments and Parallel Executions that featured as virtual and real interaction. In this study, we use a virtual platform called Blender, an open source creation tool, to carry out light field research. First of all, in the virtual world, we can create a variety of scenarios tailored for specific tasks such as autonomous driving recognition, indoor scene perception, factory assembly line for industrial inspection, and so on. An example indoor scene is as shown in
Figure 1; as we can see, the virtual scenes with naturalism desks, chairs, bowls, ceiling lamp, and others with concrete 3D sizes created within the Blender virtual environment are observed from the perspective of a camera. Another view camera is marked in yellow from the left side of the scene. With full scene known parameters, we can flexibly arrange objects and lights to construct scenes as we need. Afterwards, since Blender offers a Python API, it is convenient for us to make user-defined add-ons, as we need to self-define virtual light field camera arrays used to collect light field images for subsequent tasks. In order to accomplish our objectives, we developed a light field add-on that simulates the sampling of light field cameras in real life. To make it, we adjusted the light field camera array layout to make the baseline distances between cameras adjustable. To be more precise, a larger baseline is more appropriate for distant and expansive circumstances, and vice versa; this is in line with how our eyes see. On the other hand, we can explore reducing redundancy of overlapped camera views by tuning baseline distances among cameras as a distribution as uniform or exponential. The basic light field camera parameters we can adjust in Blender are shown as follows in
Table 1:
The other two associated elements are digital twin light sources and digital twin scenarios. Depending on whether a scene is indoors or outside, distinct kinds of light sources are available, such as spot, dot, area, and sun light. Light field cameras may implicitly record ray direction; therefore, in addition to color rendering, we can conduct research by taking ray direction into account. For instance, in autonomous driving, afternoon sunshine shining straight into the camera lens can cause potential risks. Humans can switch to a different view to avoid this situation, but an autonomous vehicle cannot. A parallel system is an excellent setting for these tests. To solve this problem, we consult Parallel Light Fields, and one possible solution we come up with is spherical light field camera arrays by positioning cameras on surfaces with variable radii. With the help of some computer vision or graphical algorithms, we can reason about the variable directions of lights captured by different camera lenses in different positions and filter noisy lights to obtain final clear light field images.
3.1. ACP Based Optimal Camera Array Deployment
Stereo images, as we are aware, will have better depth estimation accuracy than monocular images due to the additional 3D structure information provided by a second view. For the same reason that we use light field images, more viewpoints of the image will provide significantly more cues for depth inference. Even if we have up to angular resolution, not every view has an equal effect on the final depth estimation. Adding more views therefore increases data volume and the computational burden. Additionally, these additional view images have a high level of redundancy. As far as we are aware, there is no task that specializes in optimal view selection and can extract the most information from light field images with the smallest number of views. For tasks like depth estimates, some early studies randomly selected a portion of the viewpoint. It becomes difficult and necessary to figure out how to choose the most appropriate viewpoints in order to increase efficiency. We discovered that the optimal camera array deployment may be accomplished by adjusting the distances between nearby cameras and the camera sphere in order to strike a compromise between scene depth accuracy and view redundancy. The solution to this issue will have a substantial impact on the creation and design of light field cameras in practical applications. It would be preferable if we could intelligently adjust the baselines to make our light field cameras task-specific.
The maximum recovery of 3D structural information of small objects and large-scale scenes have differing demands on camera array configurations, making the optimal view selection significant in light field camera design as well. Take camera arrays as an example. For instance, camera arrays can be placed in a sphere or a plane, and the distance between neighboring cameras can either be equal, linearly growing, inverse proportional, or exponential. It is unrealistic to conduct experiments on every single mode to figure out the optimal deployment for every single case in the real world. Due to the light field camera’s ability to restore implicit 3D structures, we believe it may eventually replace conventional cameras. Making the light field camera more adjustable will be a significant and fascinating challenge. The inflexibility may have been one of the challenges to the development and popularity of commercial light field camera devices.
We propose a solution in this essay that is based on the ACP theory as shown in
Figure 2. The Parallel Intelligent aspect of the ACP theory is abstracted to include both virtual and real interaction. Create artificial systems that are similar to real systems before conducting computational experiments there. Small data in the virtual world may then be expanded to big data for intelligent algorithms, and once smart knowledge has been obtained, it can be used in real systems for validation. Iteratively repeating this process until a complete closed loop is achieved, the systems work in an interactive way between the real and virtual worlds until final convergence. Feedback from actual systems will direct the virtual systems to update settings iteratively.
To be specific, the Blender suite is very flexible and a Python API is accessible, which means we can compile our own light field add-ons. In stereo matching, the depth and disparity follow the rule as
where
b is baseline between adjacent cameras,
f is the focal length, and, if disparity is fixed, depth is proportional to baseline distance; this is the same with our eye.
Therefore, in our settings, we choose to focus on closer scenes with cameras that are closer to the central view and faraway scenes with cameras that are farther from the central view. By adjusting camera array baseline distances to achieve a full focus mode, we carry out computational experiments in the virtual space. The scene images are then recorded using rendered light field cameras.
3.2. Light Field Static Scene Generation
By utilizing the free and open source Blender 3D creation platform, we have published a new light field image collection in this work. A virtual light field camera in the form of camera arrays was used to take the scene images with diverse lighting conditions such as sunshine, spot light, and dot light. To build the scene in Blender, we employed a number of 3D models, including indoor rooms, outdoor houses, and streets.
The 3D model that is used to build the scene in our settings comes from two sources. First, it may be acquired from a website that provides free 3D models; these models were all generated using the Blender software. Even though some of them are not very realistic, they are nevertheless useful because we are aware of all the 3D measurements and may modify the model to our preference. Second, in order to lessen the impact of natural sunlight on the rendered scene, we also collected the 3D models of a few additional objects utilizing scanning devices like RGBD cameras and iPADS. These additional objects, which primarily include real-world cars, were collected on cloudy days rather than sunny ones. In this manner, we can produce a variety of scenes in batches to meet the demands of our tasks by completely utilizing the large real-world and virtual 3D models. We use the cycle engine to imitate natural qualities of light and increase rendering realism at the expense of rendering time. The depth is generated using Blender’s Z pass, where the Z pass values correspond to the length of the ray from the object’s surface point to the camera’s pinhole. In contrast to the Eevee engine, the physical Cycle engine can track rays and support a variety of complicated materials, producing in more realistic results. Light field images require containing rays’ directions in addition to their appearance and intensity, in contrast to conventional 2D images, hence the cycle engine is the ideal option. The notion behind the volume rendering used in the well-known Neural Rendering network is comparable to how information along the ray is recorded in the cycle engine. We reduce the sampling rate, and the maximum light path bounces to a relatively smaller amount with little loss in rendering quality in order to speed up rendering.
Our light field image has a spatial resolution of
and angular resolution up to
. To verify how baseline distance between adjacent cameras will affect the depth estimation performance, we set two versions of angular resolution with
and
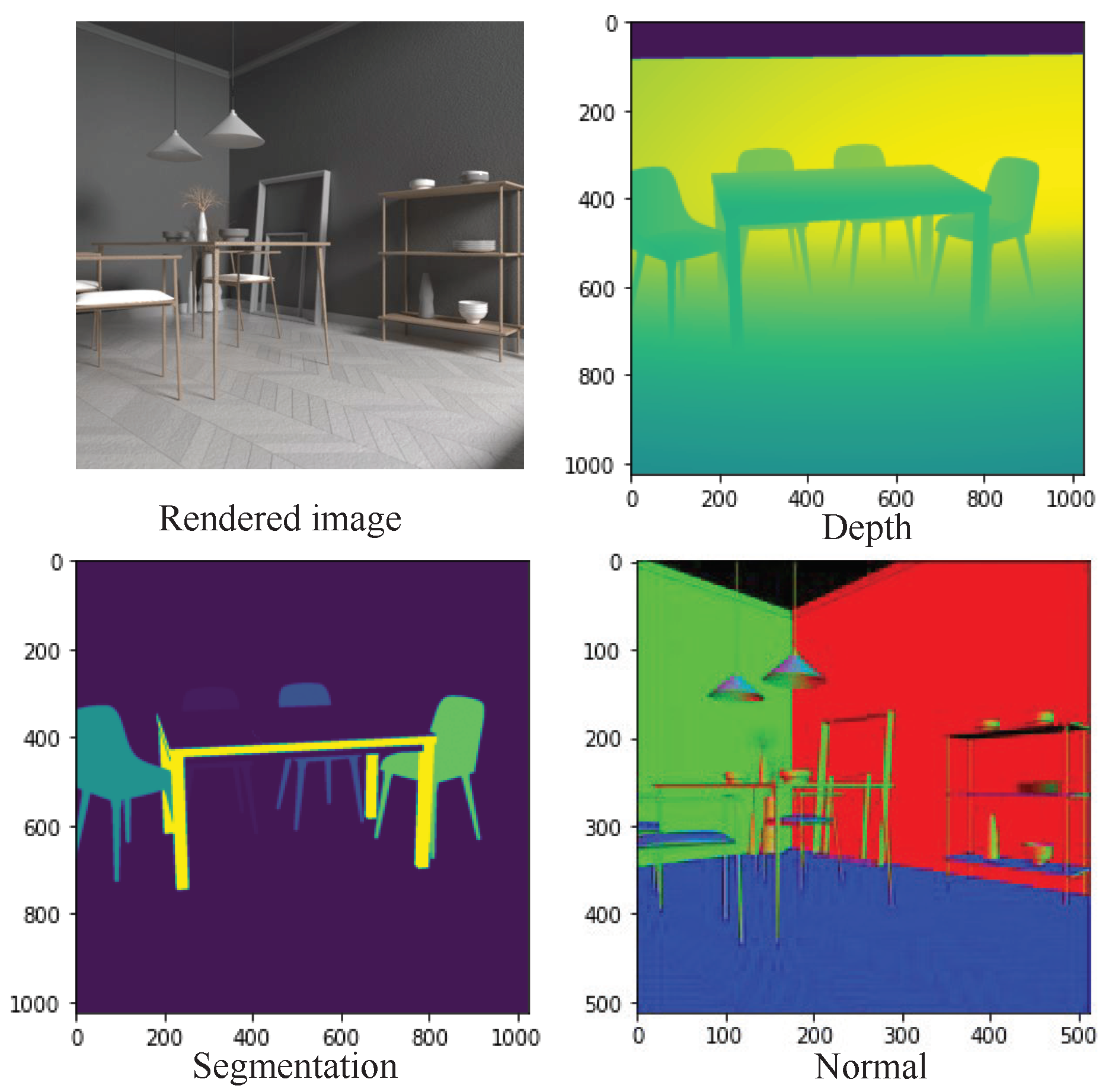
spatial resolution and the lower the spatial resolution, the longer the baseline distance. In the popular HCI dataset, the training dataset includes 16 simple scenes, and only the depth/disparity ground truth is available; on the contrary, with the HCI dataset, as depicted in
Figure 3 our captured scene is more complex, and provides ground truth including the depth/disparity for depth estimation, a normal that indicates the ray direction, and semantic cues for segmentation. In addition, the HCI dataset focuses on a relatively simple scene and distances between camera lenses are relatively small; their disparities are within –4 to 4 pixels, our goal is trying to make a dataset that is suitable for large scale scenarios, so our light field dataset has disparities ranging from 0 to 200 pixels, which is similar to current 2D autonomous driving datasets like KITTI. We hope that our light field dataset is capable of training current perception algorithms by exploiting 3D structural features more effectively and boosting their performance in tasks like depth estimation and object detection.
Our light field image has an angular resolution of up to
and a spatial resolution of
. We set up two versions of angular resolution with
and
spatial resolution, and the lower the spatial resolution, the greater the baseline distance, to investigate how baseline distance between neighboring cameras will affect the depth estimation performance. The popular HCI dataset only has depth/disparity ground truth available for 16 simple scenes in the training dataset. In contrast, our captured scene has depth/disparity for depth estimation, a normal that shows the ray direction, and semantic cues for segmentation. In addition, the HCI dataset focuses on relatively simple scenes and camera lens distances are relatively small; their disparities are within −4 to 4 pixels. Our goal is to create a dataset that is appropriate for large scale scenarios, so our light field dataset has disparities ranging from 0 to 200 pixels, as presented in
Figure 4, which is similar to current 2D autonomous driving datasets like KITTI. We anticipate that, by more efficiently exploiting 3D structural features, our light field dataset will be able to train current perception algorithms and improve their performance in tasks like depth estimation and object detection.
3.3. Light Field Dynamic Scene Generation
Videos are merely 2D frame sets with depth discarded, making them unsuitable for 3D motion estimates. In order to examine dynamic characteristics of the scene, we require 3D models with time-varying motions. We must therefore create dynamic light field videos for studying scene flow, as we do with static scenes. Comparing dynamic scenes to static scenes, merely making every object move over time is insufficient for the creation of a dynamic scene; instead, the objects in the scene must be connected by correlation relations for the scene to have any semantic significance. These semantic signals will be useful in tasks like object tracking based on light field scene flow prediction. For instance, a man should run on a road instead of on the river, as well as a boat should float on the river instead of fly in the air.
Thanks to the availability of large-scale, free 3D animated models in full 3D sizes, we are now able to create dynamic sceneries in the form of optical flow. We can render a whole scene animation and capture a dynamic full scene using our light field camera after importing 3D dynamic human models into our static scenes. In Blender, the vector pass in the data module can generate relative pixel displacement between adjacent frames, which can subsequently be used to acquire optical flow. The generated flow dataset is shown in
Figure 5. The upper row depicts a dynamic scene rendered with a moving person in a static environment, and the lower row depicts comparable flows of the dynamic scene. The colors in the flow images denote the directions and magnitudes for speeds, respectively. Our dynamic scene light field images have the same spatial and angular resolution as our static scene light field images, and each scene’s whole 6D light field dataset spans
dimensions, with 150 being the frame. For the purpose of future light field image-based perception, we also obtained ground truth of segmentations, depths, normals, and object poses in addition to flows.
4. Experiments
4.1. Light Field Disparity Estimation
Our light field dataset is more suitable to transfer to various 2D image-based deep learning algorithms since it is indoor and outdoor focused, with large depth compared to many other public datasets. We trained the widely used light field disparity estimation network DistgDisp using our light field dataset and the HCI light dataset, respectively, to validate our proposed dataset in depth estimation. In the DistgDisp [
24] benchmark, the subaperture input images are first rearranged into a macro pixel image, and fed to eight spatial residual blocks for spatial information incorporation; afterwards, a series of disparity-selective angular feature extractors were introduced to disentangle the disparity information from the macro pixel image. Similar to conventional stereo matching, the extracted features are merged to generate a cost volume. The aggregated cost is then used to regress the final disparity using 3D convolutions. Although the network used in this method is not particularly complex, which is simply a fully convolutional extractor without an attention module, it achieves a mean square error (MSE) value of 0.01896 and Badpix0.01 values of 23.328 on the HCI light field dataset, and, as of the time they submitted their results, it was ranked second:
The smaller disparity of the HCI dataset, on the one hand, is thought to be responsible for their strong performance. The HCI dataset has a maximum disparity of 4 pixels, which indicates that the view photos have a lot in common and that redundant information improves network efficiency. However, compared to monocular or stereo pictures, the combination of spatial, angular, and epipolar properties offers significantly more structural information and contributes to enhancing the disparity results.
Since our dataset has much greater disparity than the HCI dataset, we modified the refocus augmentation to adapt to our disparity range in the data augmentation stage, and the initial learning rate and decay are recalculated as and 0.75, respectively. As a result, we use DistgDisp as our baseline to evaluate our light field dataset. We have not masked out transparent or reflective parts, in contrast to the training on the HCI dataset, even though they might impair the performance of disparity estimation. Finally, we reach an MSE of 2.352, which is 120 times greater than on the HCI dataset. Given that the maximum disparity on our dataset is up to 200 pixels, we believe this is a reasonable threshold.
As can be seen, the estimated disparity map in
Figure 6 can recover certain structural elements beyond the captured depth ground truth.
On the other hand, we also conduct experiments on the epipolar plane images based light field disparity estimation method named EpiNet [
33] on our dataset. We make some modifications: the initial learning rate and decay are recalculated as
and 0.5, respectively; different from that trained on the HCI dataset, we do not mask out any reflection region pixel but train the whole area. We finally adopt 40 scenes and each with eight perspective light field images for training, the results are shown in
Table 2 the mean square error (MSE) is used as a metric, and our result is 1.245. Since our dataset has a disparity of up to more than 100 pixels and is larger than [−4,4] in the HCI dataset, in addition to the baseline distance also being larger and there being no other light field dataset similar to ours, it is hard to make a relatively fair comparison.
4.2. Light Field Angular Super-Resolution
The angular super-resolution experiment, often known as viewpoint synthesis or reconstruction, is another fundamental light field experiment. In order to evaluate on our dataset, we additionally use the DistgASR disentangling strategy. To take advantage of performance in scenes with large disparities, we conduct light field angular super-resolution. To effectively exploit correlations within each domain, DisgtASR [
24] also introduces two additional horizontal and vertical epipolar plane images (EPIs) feature extractors in addition to the spatial feature extractor and angular feature extractor. The angular feature extractor takes in an angular resolution of
and dilation by 1 to calculate correlations between different views, and the spatial feature extractor with a kernel by
and dilation by angular resolution, respectively, to extract features within each subaperture image as conventional convolutions. Features extracted from these four modules are concatenated to input to two spatial feature extract modules, and the aforementioned modules together composite the Disentangle Block (Distg-Block). After a few Distg-Blocks, a
convolution aggregate features in to dimensions of
where
is the upsampling rate,
A is original angular resolution, and
C is the feature channels. A pixel shuffle module was finally used to obtain the final upsampled result with a size of
; here, we set
as
and
A is 2. We follow the training strategy in DistgASR and use the Peak Signal Noise Ratio (PSNR) and Structural Similarity (SSIM) as the metric to evaluate our result.
To reconstruct the other 45 views, we choose the four corner views from the
views as our input. We achieve a PSNR and SSIM of 30.135487 and 0.942329 in the
to
angular super-resolution task show in
Table 3. On the contrary, the DistgASR trained on the HCI dataset achieved scores of PSNR 34.7 and SSIM 0.974, which are better than in our dataset. We attribute this to our larger scale disparity, which results in significant displacement of pixels in adjacent views. As illustrated in
Figure 7, we chose the upper left 15 views for demonstration, with View_01_01 acting as the input and the remaining views being the reconstructed views. To illustrate our finding that the reconstruction perspective becomes blurrier the farther away it is from the input perspective, we depict the same spatial location in red and yellow boxes drawn from several perspectives. As we can see, the mirror and its edge are becoming blurry in the red boxes from upper left to lower right, and in the yellow boxes as well. We believe this is because of the low roughness and shallow depth. We also trained DistgASR on the HCI dataset with two disparity ranges for verification and depict the bigger disparity ranging from −3.6 to 3.5 in
Figure 8 and the smaller disparity ranging from −1.6 to 1.2 in
Figure 9. The blurred areas in larger disparity inputs frequently occur in the lower depth region. We believe that this is because the lower depth corresponds to larger disparities, which means there is greater movement between adjacent view images and may result in errors. In contrast, in small disparity areas, the network is better capable of reconstructing the scene. In conclusion, we think that larger disparity may be the reason for performance degradation in angular super-resolution, since disparities in our dataset are much larger than in the HCI dataset; even though the PSNR and SSIM in our dataset are lower than in the HCI dataset, we think our performance is better. In addition, since no dataset currently exists with a relative disparity range as wide as ours, we expect that using our dataset would significantly improve the performance of existing algorithms developed using monocular or biocular datasets and expand their application to autonomous driving perception scenarios.
Light fields’ angular super-resolution is the inverse of light fields capturing, and the PSNR and SSIM can be seen as an indicator of correlation between the reference view image and the reconstructed view image. Based on these observations, we can choose views with the least redundancy by adjusting the baseline distances; to be concrete, if the recovered views are blurred, the PSNR and SSIM are low; then, we think a camera lens should be deployed in that position to provide some complementary cues. We will conduct such research in the future work.
5. Conclusions
In this paper, we produce a brand-new synthetic light field dataset specifically designed for static scene depth estimation and dynamic scene flow estimation by compiling an add-on using the free and open-source Python API of the Blender suite. Our static light field scene images include both indoor and outdoor scenarios. When compared to other light field datasets, our dataset is larger in terms of scene scale and depth, and it explores the potential of light field images for indoor 3D reconstruction. With the help of the Python API, light field research may be applied to the context of autonomous driving, which will, in our opinion, significantly enhance the effectiveness of visual perception algorithms. Additionally, since it is challenging to collect ground truth for 3D dynamic models, we also create a dynamic 3D motion dataset for exploring scene flow. Thanks to Blender’s virtual environment, where sizes and motion parameters are known, ground truth is also much easier to collect.
We also evaluate main stream disparity estimation and angular super-resolution algorithms on our static scene dataset, with little modification on the training strategy of the network, even though results trained on our dataset are not as good as those trained on the HCI dataset, we think it is because our dataset is more complex and has a larger disparity which is more suitable for algorithms designed for current autonomous scenarios, and our future work will fully exploit large scale scenes.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}