Sonobuoy is a combination of sonar and buoy, and refers to a device that collects underwater information through sound waves. Sonobuoy is a disposable device that is dropped from the maritime patrol to the area of interest. It is designed to transmit the collected underwater signal to the maritime patrol via wireless communication and sink to the sea when the mission is completed. Sonobuoy is divided into passive and active types according to the detection method and the detection range, operating time, and service life vary widely for each product model [
1]. Among them, the transmission bit rate of signals is used from hundreds of kbps (kilobits per second) to tens of Mbps (Megabits per second) [
2].
The sonobuoy may be operated in a monostatic sonobuoy when the active sonobuoy (CASS) or DICASS (Directional CASS) is used alone. It may be operated in a bistatic and multi-static sonobuoy with an explosive sound source or a combination of active and passive sonobuoys [
3]. In general, since a bistatic target detection has different positions of a transmitter and a receiver, the detection area is wider and confidentiality is guaranteed compared to monostatic target detection [
4].
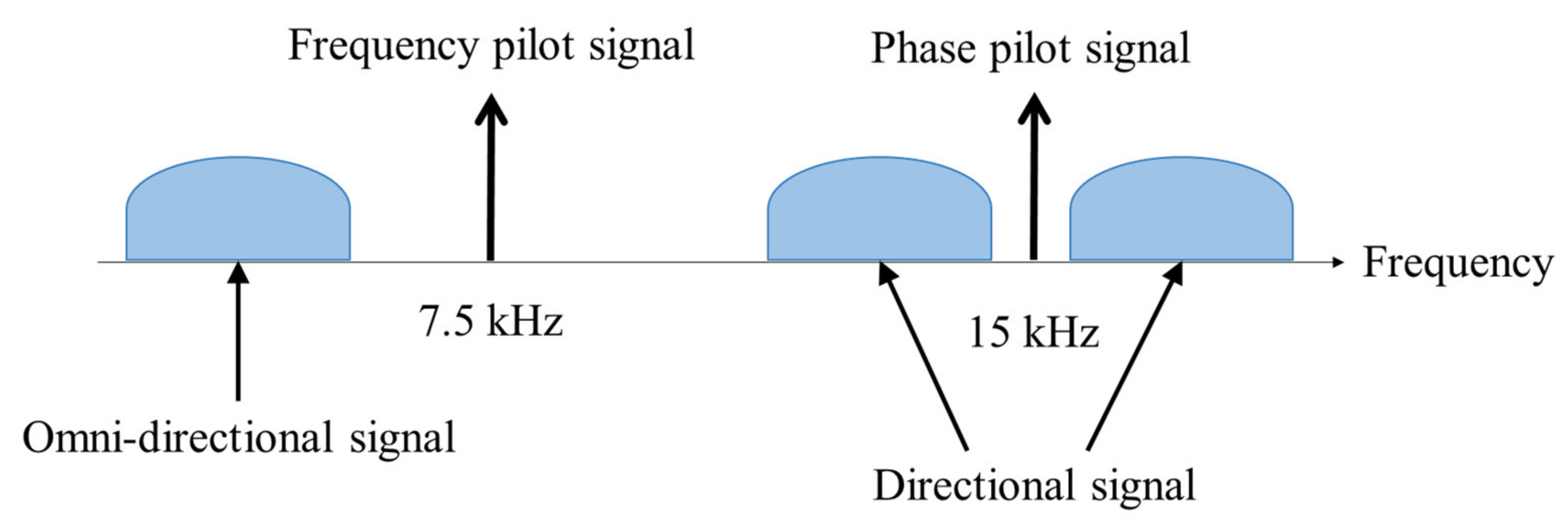
Figure 1 presents a research conceptual diagram schematically illustrating a bistatic target detection environment using active and passive sonobuoys in anti-submarine warfare (ASW). Since the system of the electronic unit of the sonobuoy cannot perform complex signal processing, sonobuoy inevitably transmits the collected underwater signal to the maritime patrol plane or the ship through wireless communication. The existing signal modulation and demodulation methods used in wireless communication include frequency division multiplexing [
5] and frequency shift keying (FSK) [
6]. Such a signal modulation and demodulation method have a disadvantage in that a high bit rate is required due to the large amount of information to be transmitted because it is the entire acoustic signal. In addition, since the frequency band of the modulated signal is easily analyzed, the modulation scheme is relatively easy to predict and is highly likely to be demodulated, resulting in low security.
Conversely, using deep neural nets recently, there have been great achievements in various fields, i.e., speech recognition, visual object recognition, object detection, and natural language processing [
7]. In particular, autoencoder is an unsupervised learning-based feature extraction technique that can obtain high-level features of input signals by learning and using unlabeled data. It is more practical because it can be applied to a wider range of data than supervised learning, which is expensive to obtain labeled data. The autoencoder mainly consists of encoder and decoder parts, where the encoder yields high-level features, usually called codes or latent variables. These represent input signals compressively well, and the decoder is trained to restore the codes as close as possible to the original inputs. Autoencoder is similar to principal component analysis (PCA) in that it compresses inputs into latent variables by reducing the dimension of data in the encoding process. However, autoencoder is a nonlinear generalization of PCA and presents superior performance to PCA in general [
8]. Normally, the structure of the autoencoder is stacked by multiple layers to extract high-level features. Denoising, sparse, and variational autoencoders are developed for further performance improvements in the feature representation [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]. According to [
10,
11], denoising autoencoders learn more key high-dimensional features in the training process by performing denoising tasks on noisy input signals and are known to be superior to the traditional autoencoder [
10,
11]. Usually, traditional and denoising autoencoders are implemented as under-complete models in which the input dimension is larger than the hidden layer, and as the autoencoder is stacked, the input of the layer is compressed and the number of activations (outputs of each layer) is reduced. Conversely, sparse autoencoders are implemented as over-complete models, which have a larger dimension of hidden layer than the dimension of input, unlike traditional and denoising autoencoders [
12,
13]. Sparse autoencoders are other methods for extracting interesting structures of data by imposing “sparsity”, which means most nodes are inactive and active nodes exist very rarely, on nodes of layers. However, the disadvantage of sparse autoencoders is the computational complexity of which the activation value must be calculated in advance in order to add sparsity to the cost function [
12]. An efficient algorithm to iteratively solve this problem has been proposed [
13]. In addition, variational autoencoders are the ones that involve the notion of probability [
14,
15]. Variational autoencoders are stochastic generative models that model the probability distribution of parameters, whereas the other autoencoders are deterministic discriminative models that model the value itself of parameters [
15]. The common and ultimate goals of the above-mentioned methods are to extract high-dimensional features or representations of the input and to improve the performance of tasks (mainly classification) with the features. The results of the autoencoders are used independently or in combination with other methods, i.e., support vector machine (SVM), convolutional neural network (CNN), and Gaussian mixture model (GMM), mainly as a front-end for parameter initialization of supervised learning [
16,
17,
18].
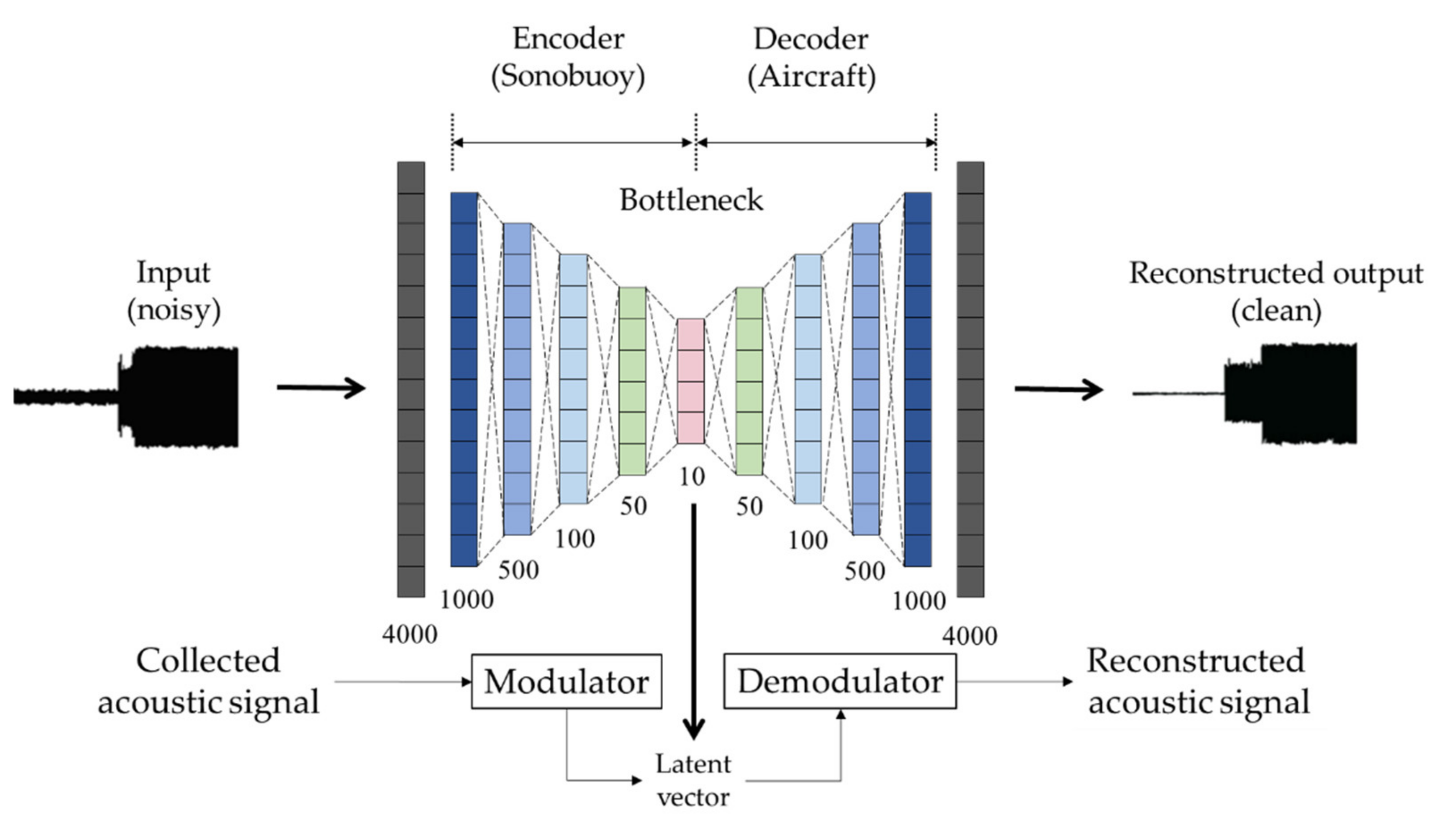
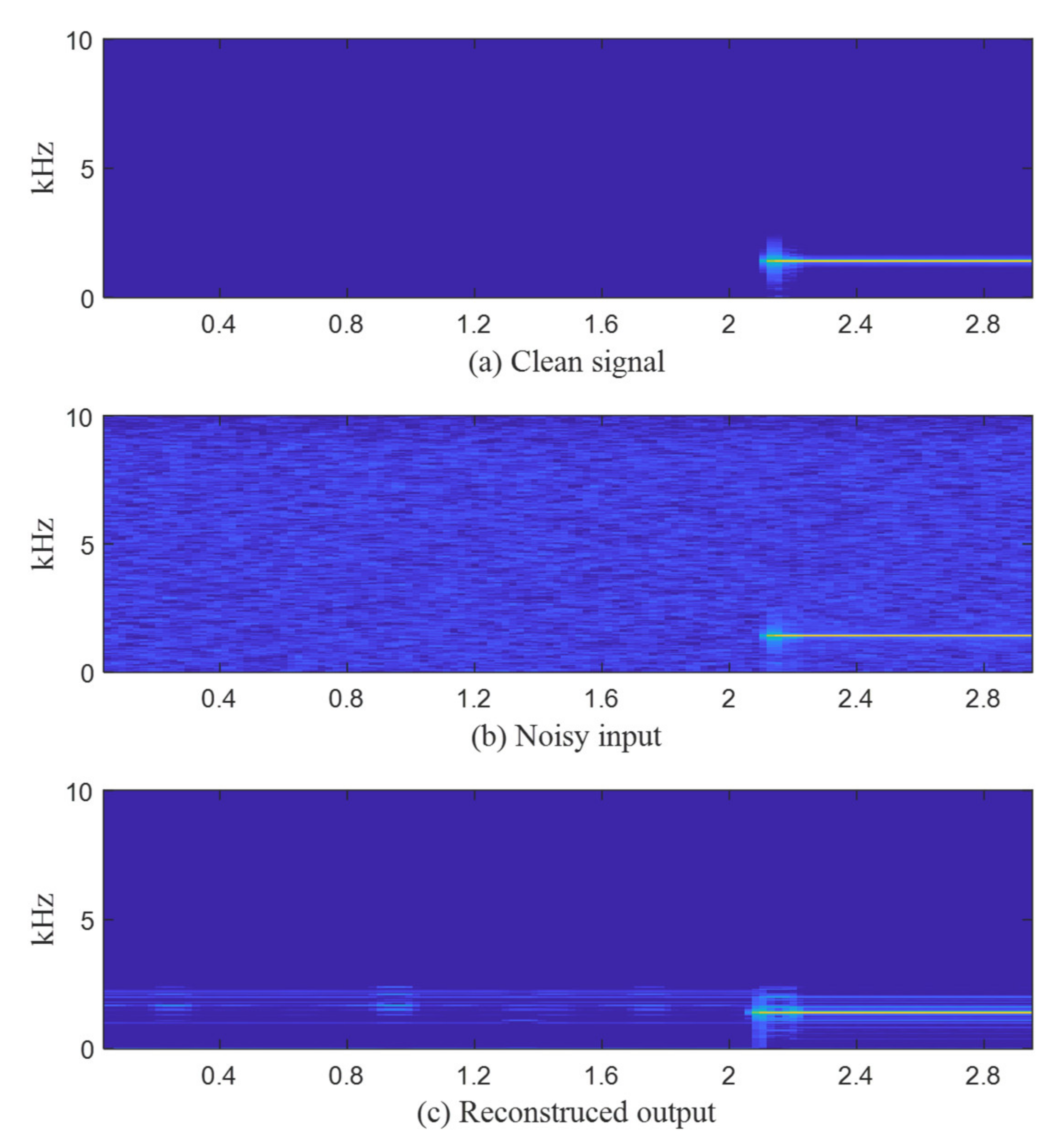
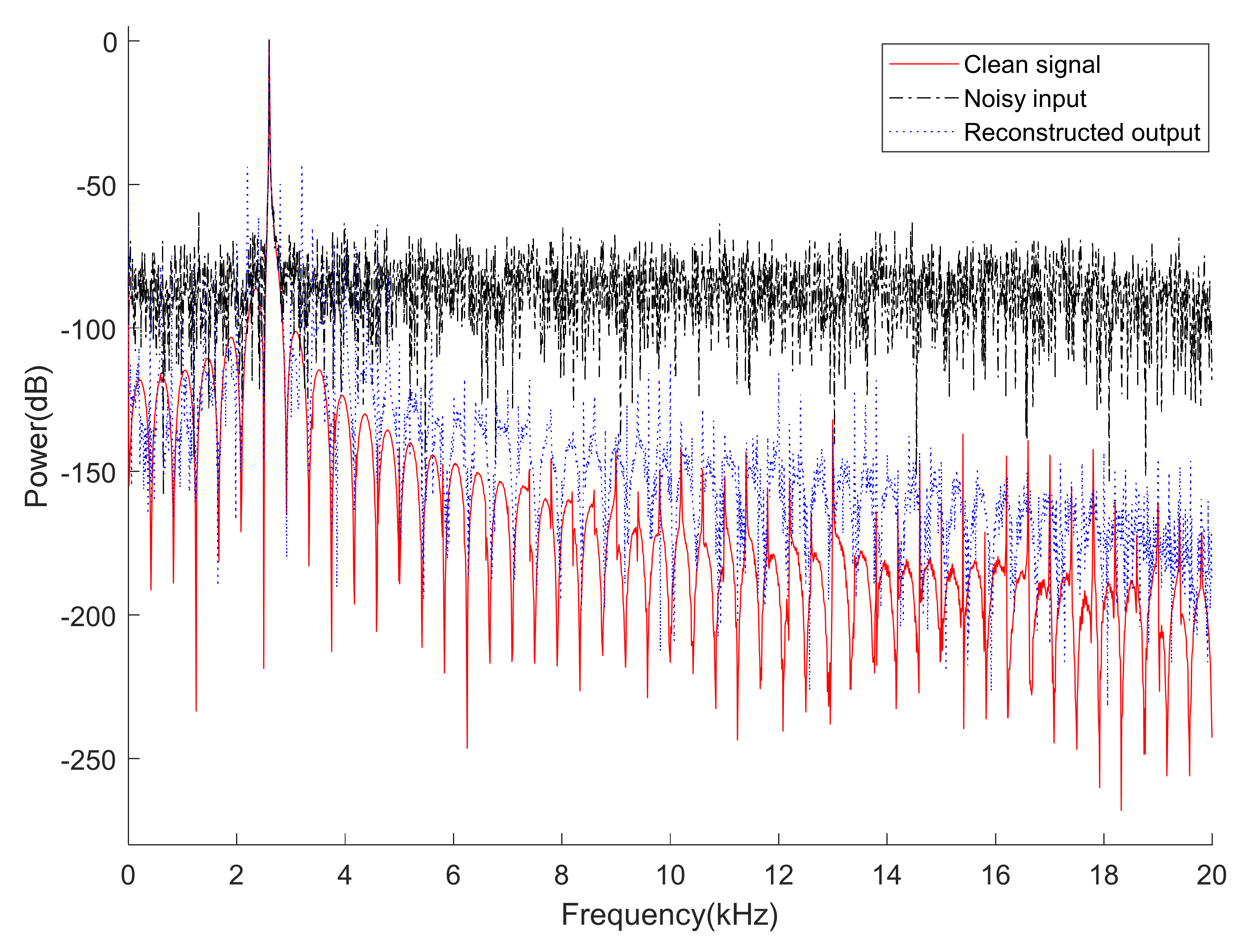
In this paper, a novel approach to apply the under-complete structure of the autoencoder to sonobuoy signal modulation and demodulation for signal transmission and reception in order to decrease the amount of information to be transmitted and increase security. Our contributions are two-fold. First, we propose a method that modulates the transmission signal to a low-dimensional latent vector using an autoencoder to transmit the latent vector to an aircraft or vessel and demodulates the received latent vector to reduce the amount of transmission information and improve the security of the signal. Second, a denoising autoencoder that reduces ambient noises in the reconstructed outputs while maintaining the merit of the proposed autoencoder is also proposed.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}