

Rethinking Gradient Weight’s Influence over Saliency Map Estimation



Abstract
:1. Introduction
- A new saliency map generation scheme is formulated by introducing a global guidance map that incorporates the elementwise influence of the gradient tensor onto the saliency map.
- Acquired boundaries for the saliency maps are crisper than contemporary studies and perform efficiently within single/multi-class/multi-instance-single class cases.
- To validate our study, we perform seven different metric analyses on three different datasets, and the proposed study achieves state-of-the-art performance in most cases.
2. Related Work
2.1. Backprop-Based Methods
2.2. Activation-Based Methods
2.3. Perturbation-Based Methods
3. Proposed Methodology
3.1. Baseline Formulation
3.2. Incorporating Global Guidance
4. Performance Evaluation
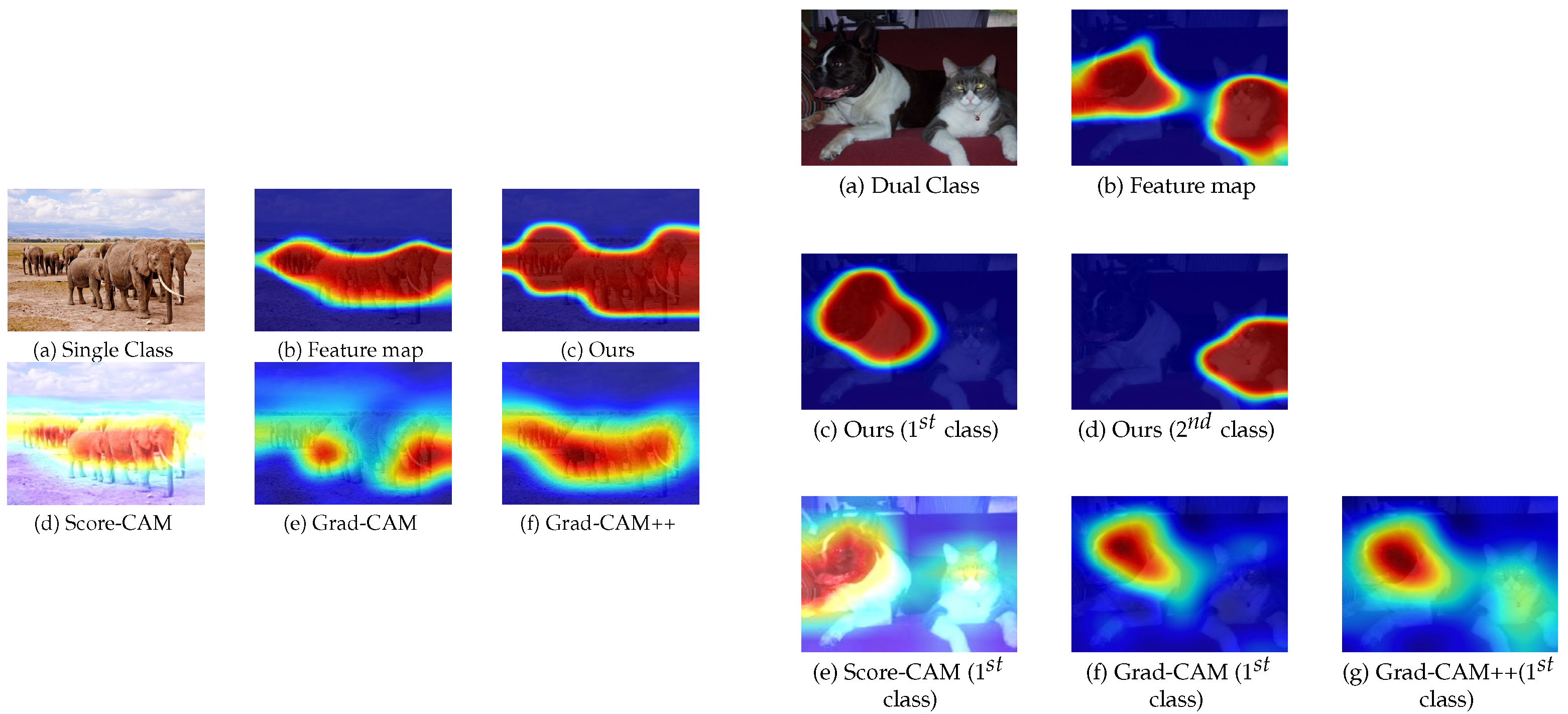
4.1. Visual Demonstration
4.2. Quantitative Analysis
4.3. Interpretation Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Petsiuk, V.; Das, A.; Saenko, K. RISE: Randomized Input Sampling for Explanation of Black-box Models. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Sattarzadeh, S.; Sudhakar, M.; Lem, A.; Mehryar, S.; Plataniotis, K.N.; Jang, J.; Kim, H.; Jeong, Y.; Lee, S.; Bae, K. Explaining Convolutional Neural Networks through Attribution-Based Input Sampling and Block-Wise Feature Aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 11639–11647. [Google Scholar]
- Sudhakar, M.; Sattarzadeh, S.; Plataniotis, K.N.; Jang, J.; Jeong, Y.; Kim, H. Ada-Sise: Adaptive Semantic Input Sampling for Efficient Explanation of Convolutional Neural Networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1715–1719. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free?—Weakly-supervised learning with convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 685–694. [Google Scholar] [CrossRef]
- Fu, R.; Hu, Q.; Dong, X.; Guo, Y.; Gao, Y.; Li, B. Axiom-based Grad-CAM: Towards accurate visualization and explanation of CNNs. arXiv 2020, arXiv:2008.02312. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Srinivas, S.; Fleuret, F. Full-Gradient Representation for Neural Network Visualization. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Sattarzadeh, S.; Sudhakar, M.; Plataniotis, K.N.; Jang, J.; Jeong, Y.; Kim, H. Integrated Grad-CAM: Sensitivity-Aware Visual Explanation of Deep Convolutional Networks via Integrated Gradient-Based Scoring. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1775–1779. [Google Scholar]
- Desai, S.; Ramaswamy, H.G. Ablation-CAM: Visual Explanations for Deep Convolutional Network via Gradient-free Localization. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 972–980. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Lin, Z.L.; Brandt, J.; Shen, X.; Sclaroff, S. Top-Down Neural Attention by Excitation Backprop. Int. J. Comput. Vis. 2017, 126, 1084–1102. [Google Scholar] [CrossRef]
- Rebuffi, S.A.; Fong, R.; Ji, X.; Vedaldi, A. There and Back Again: Revisiting Backpropagation Saliency Methods. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 5–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Zhou, K.; Kainz, B. Efficient Image Evidence Analysis of CNN Classification Results. arXiv 2018, arXiv:1801.01693. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing Deep Neural Network Decisions: Prediction Difference Analysis. arXiv 2017, arXiv:1702.04595. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 13–19 June 2020; pp. 111–119. [Google Scholar] [CrossRef]
- Wang, P.; Kong, X.; Guo, W.; Zhang, X. Exclusive Feature Constrained Class Activation Mapping for Better Visual Explanation. IEEE Access 2021, 9, 61417–61428. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-CAM: Class Activation Map using Principal Components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Jalwana, M.; Akhtar, N.; Bennamoun, M.; Mian, A. CAMERAS: Enhanced Resolution and Sanity preserving Class Activation Mapping for image saliency. In Proceedings of the CVPR, Online, 19–25 June 2021. [Google Scholar]
- Lee, J.R.; Kim, S.; Park, I.; Eo, T.; Hwang, D. Relevance-CAM: Your Model Already Knows Where to Look. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 14944–14953. [Google Scholar]
- Balduzzi, D.; Frean, M.; Leary, L.; Lewis, J.; Ma, K.W.D.; McWilliams, B. The shattered gradients problem: If resnets are the answer, then what is the question? In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 342–350. [Google Scholar]
- Mopuri, K.R.; Garg, U.; Babu, R.V. CNN fixations: An unraveling approach to visualize the discriminative image regions. IEEE Trans. Image Process. 2018, 28, 2116–2125. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [9] | [10] | [8] | [25] | [11] | [11] | [12] | [22] | [26] | Proposed | |
|---|---|---|---|---|---|---|---|---|---|---|
| Increase for salience zone ↑ | 0.0366 | 0.0716 | 0.0366 | 0.0715 | 0.0421 | 0.0421 | 0.0172 | 0.0506 | 0.0559 | 0.0786 |
| Drop for context zone ↑ | 0.9395 | 0.8812 | 0.9429 | 0.8834 | 0.9083 | 0.9281 | 0.8124 | 0.9389 | 0.9089 | 0.9443 |
| Pointing Game ↑ | 0.3355 | 0.4731 | 0.3733 | 0.4412 | 0.3713 | 0.4422 | 0.2642 | 0.4322 | 0.532 | 0.5945 |
| Dice ↑ | 0.2822 | 0.3422 | 0.2934 | 0.3342 | 0.2942 | 0.3328 | 0.1834 | 0.3321 | 0.411 | 0.4321 |
| IoU ↑ | 0.0823 | 0.1122 | 0.0901 | 0.1007 | 0.0812 | 0.0963 | 0.0625 | 0.0943 | 0.121 | 0.1321 |
| Drop for salience zone ↓ | 0.8996 | 0.8064 | 0.8745 | 0.8201 | 0.8873 | 0.8762 | 0.9399 | 0.8567 | 0.8333 | 0.7784 |
| Increase for context zone ↓ | 0.0172 | 0.0312 | 0.0205 | 0.0244 | 0.0291 | 0.0215 | 0.0411 | 0.0151 | 0.029 | 0.0183 |
| [9] | [10] | [8] | [25] | [11] | [11] | [12] | [22] | [26] | Proposed | |
|---|---|---|---|---|---|---|---|---|---|---|
| Drop for context zone ↑ | 0.9023 | 0.9495 | 0.9142 | 0.9424 | 0.8961 | 0.9025 | 0.8607 | 0.9183 | 0.9081 | 0.9391 |
| Increase for saliency zone ↑ | 0.0490 | 0.0913 | 0.0555 | 0.0935 | 0.0455 | 0.0495 | 0.0796 | 0.0695 | 0.089 | 0.0999 |
| Drop for saliency zone ↓ | 0.8394 | 0.7243 | 0.8081 | 0.7325 | 0.8454 | 0.8288 | 0.7713 | 0.7822 | 0.7357 | 0.6493 |
| Increase for context zone ↓ | 0.0245 | 0.0165 | 0.0215 | 0.0172 | 0.0311 | 0.0315 | 0.0335 | 0.0205 | 0.0311 | 0.0152 |
| [9] | [10] | [8] | [25] | [11] | [11] | [12] | [22] | [26] | Proposed | |
|---|---|---|---|---|---|---|---|---|---|---|
| Drop for context zone ↑ | 0.8767 | 0.9178 | 0.8698 | 0.9335 | 0.8379 | 0.8548 | 0.8938 | 0.8585 | 0.8541 | 0.9392 |
| Increase for saliency zone ↑ | 0.0535 | 0.0903 | 0.0635 | 0.0936 | 0.0803 | 0.0669 | 0.0435 | 0.1003 | 0.0969 | 0.1008 |
| Drop for saliency zone ↓ | 0.7906 | 0.6717 | 0.7682 | 0.7302 | 0.7775 | 0.7844 | 0.7267 | 0.6975 | 0.6844 | 0.6492 |
| Increase for context zone ↓ | 0.0234 | 0.0067 | 0.0368 | 0.0134 | 0.0502 | 0.0301 | 0.0301 | 0.0468 | 0.0602 | 0.0012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fahim, M.A.N.I.; Saqib, N.; Siam, S.K.; Jung, H.Y. Rethinking Gradient Weight’s Influence over Saliency Map Estimation. Sensors 2022, 22, 6516. https://doi.org/10.3390/s22176516
Fahim MANI, Saqib N, Siam SK, Jung HY. Rethinking Gradient Weight’s Influence over Saliency Map Estimation. Sensors. 2022; 22(17):6516. https://doi.org/10.3390/s22176516
Chicago/Turabian StyleFahim, Masud An Nur Islam, Nazmus Saqib, Shafkat Khan Siam, and Ho Yub Jung. 2022. "Rethinking Gradient Weight’s Influence over Saliency Map Estimation" Sensors 22, no. 17: 6516. https://doi.org/10.3390/s22176516
APA StyleFahim, M. A. N. I., Saqib, N., Siam, S. K., & Jung, H. Y. (2022). Rethinking Gradient Weight’s Influence over Saliency Map Estimation. Sensors, 22(17), 6516. https://doi.org/10.3390/s22176516