
Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation


Abstract
:1. Introduction
Related Research
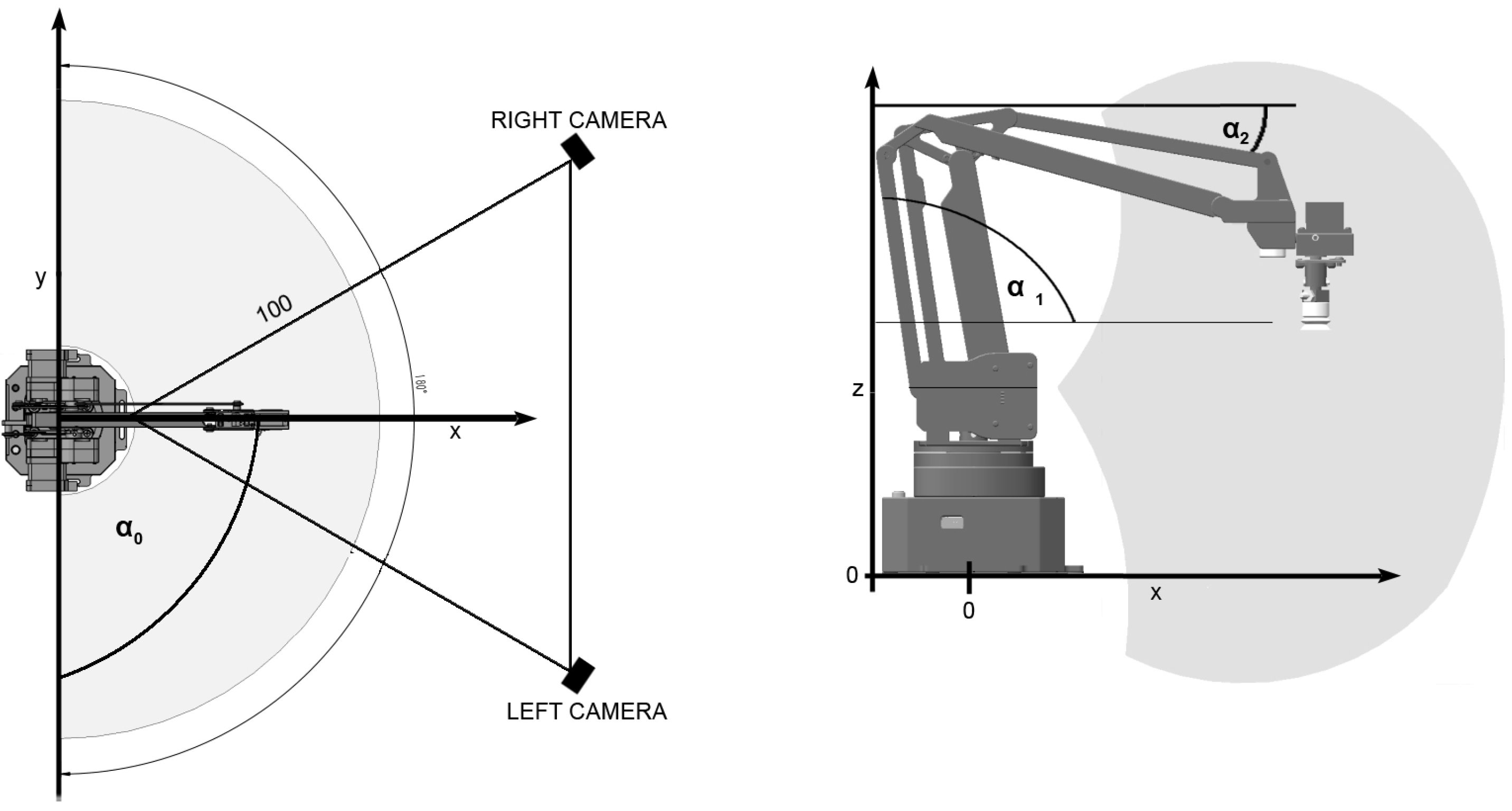
2. Materials and Methods
2.1. Image Preprocessing
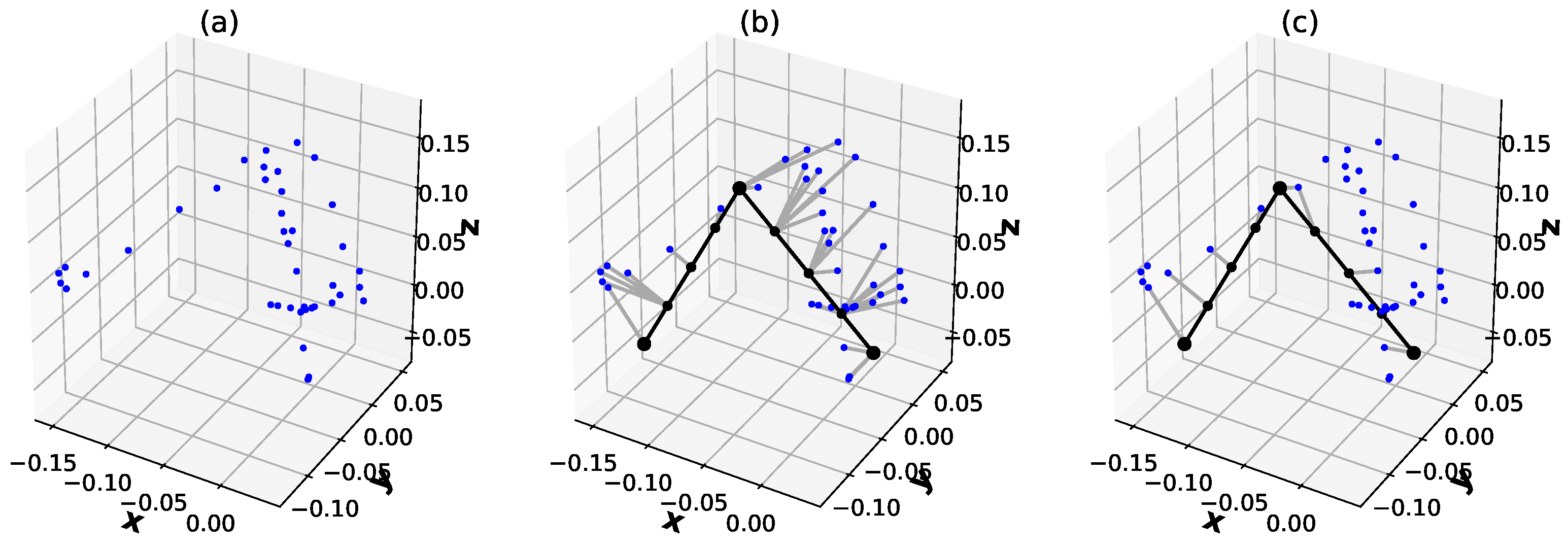
2.2. Graph Fitting

2.3. Sparse Convolutional Neural Network
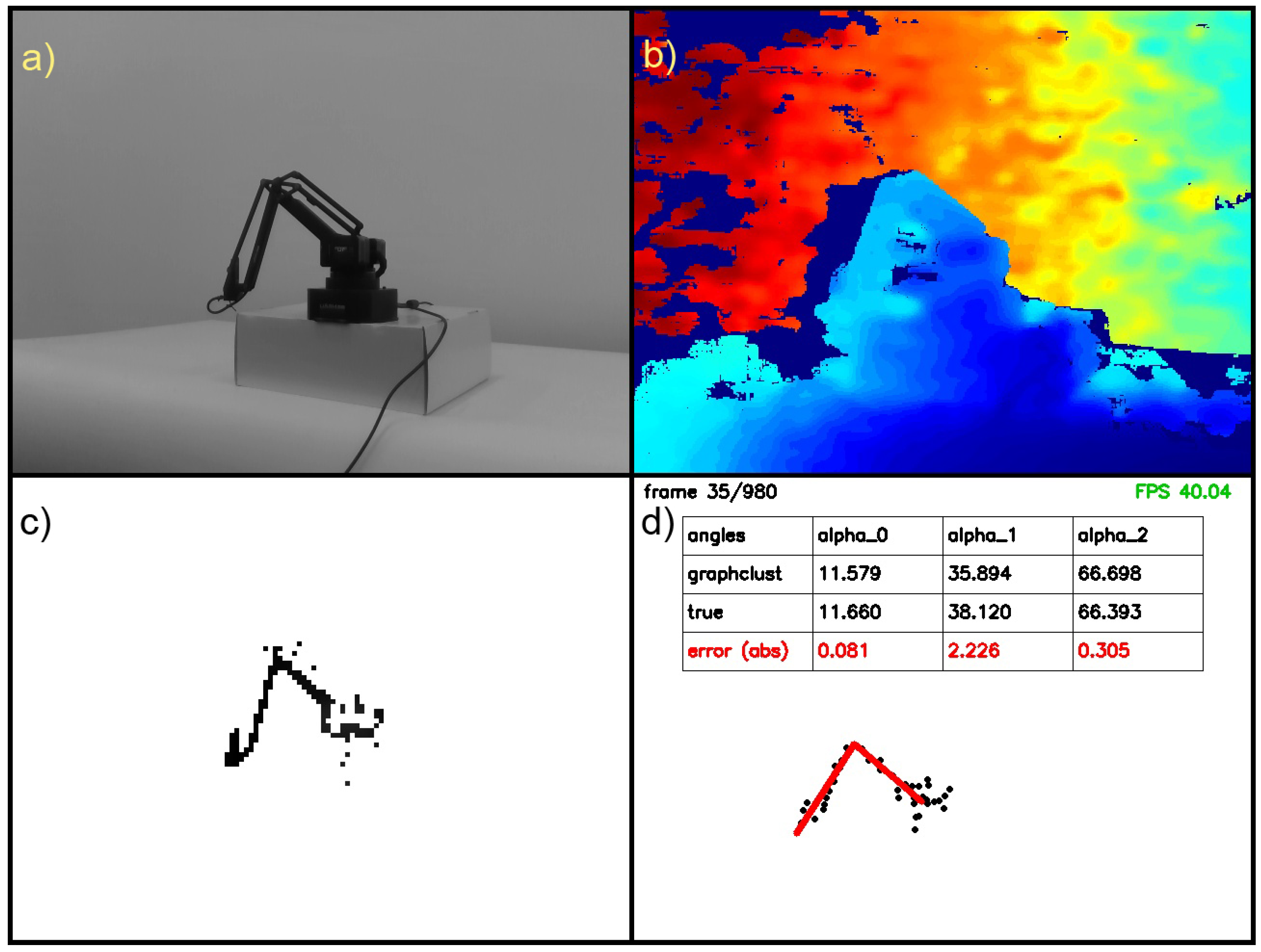
3. Experimental Results
3.1. Preparation of Experiment
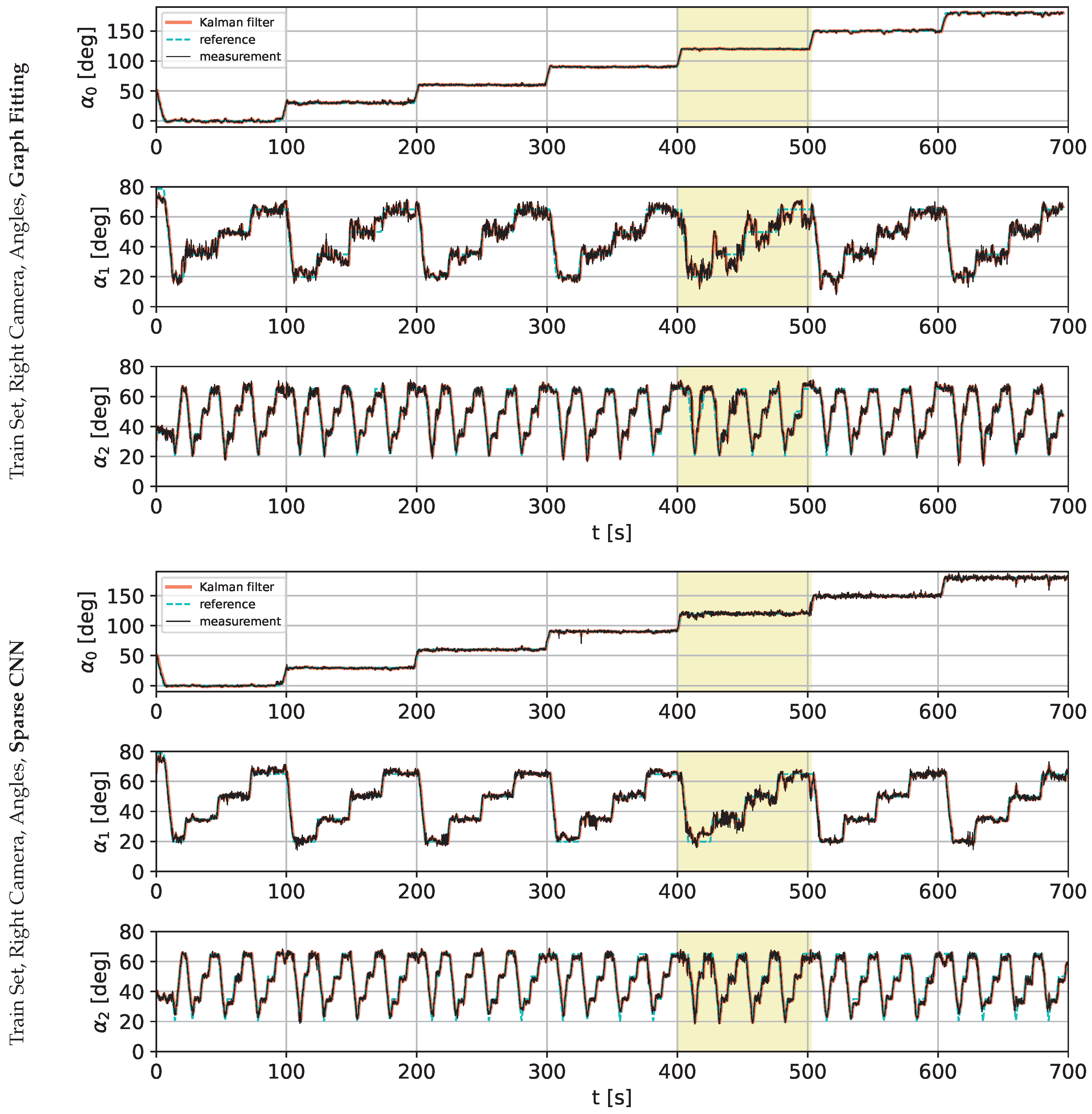
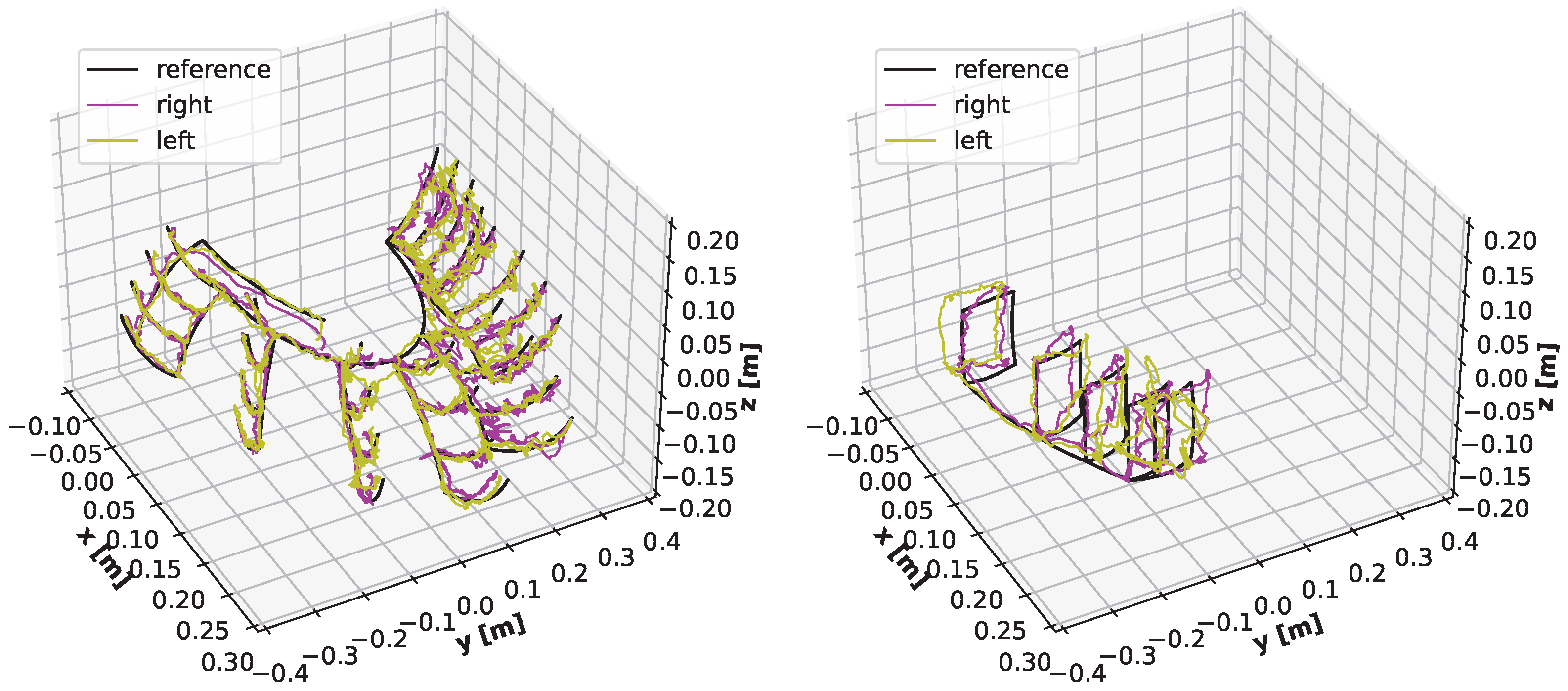
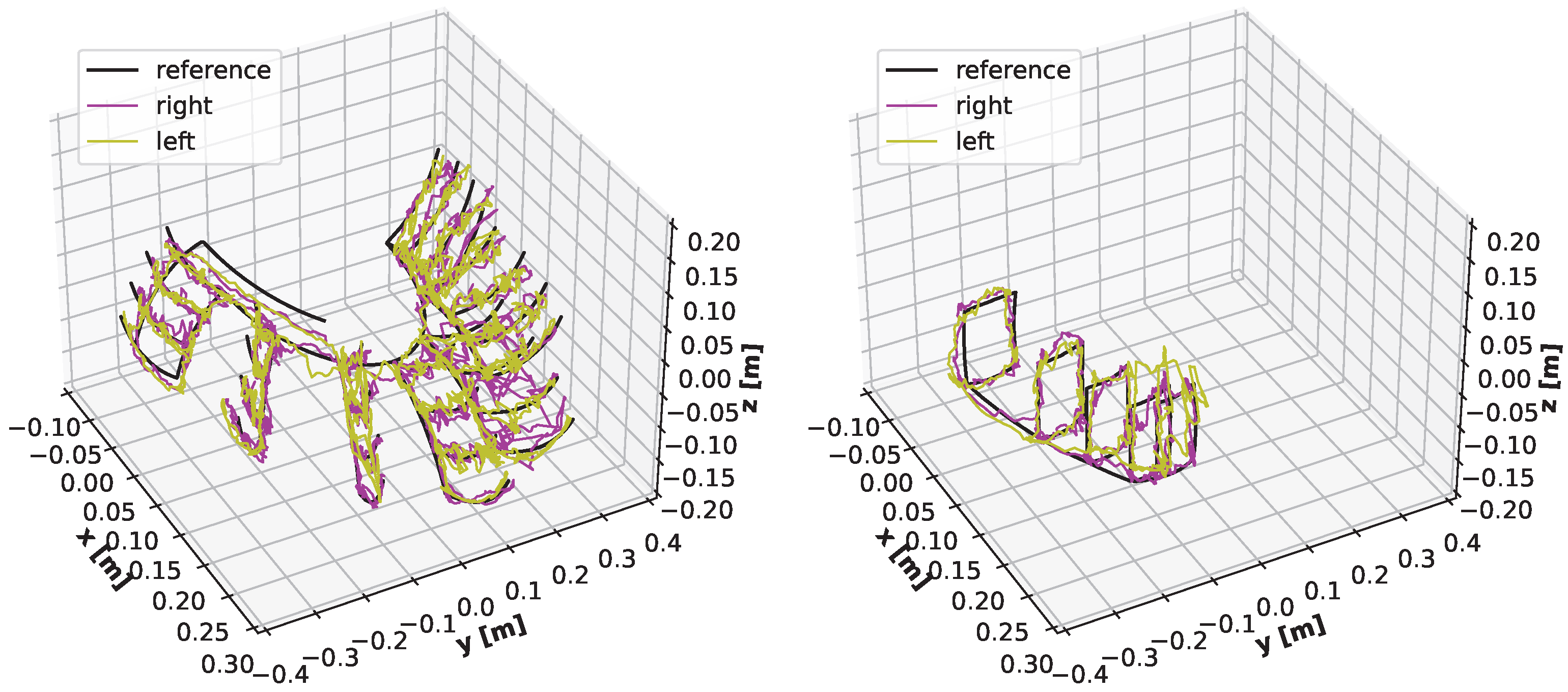
3.2. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| CNN | Convolutional Neural Network |
| Sparse CNN | CNN with sparse convolutional and pooling layers and with sparse inputs |
| Graph Fitting | Model fitting nodes of graph to the point cloud |
| FPS | Frames per Second |
| MLP | MultiLayer Perceptron |
| SGD | Stochastic Gradient Descent |
| RGB-D | RGB-Depth, combination of RGB (standard) image and depth image |
| RBF | Radial Basis Function |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| GPU | Graphics Processing Unit |
| CPU | Common x86-64 processor |
| DOF | Degrees of Freedom |
References
- UFactory. uArm Swift Pro Developers Guide V1.0.4; Technical Report; UFactory: Shenzhen, China, 2017; Available online: http://download.ufactory.cc/docs/en/uArm-Swift-Pro-Develper-Guide-171013.pdf (accessed on 24 August 2022).
- Intel RealSense. Intel RealSense TMD400 Series Product Family; Technical Report; Intel RealSense: Santa Clara, CA, USA, 2019; Available online: https://www.intel.com/content/dam/support/us/en/documents/emerging-technologies/intel-realsense-technology/Intel-RealSense-D400-Series-Datasheet.pdf (accessed on 24 August 2022).
- Schmidt, B.; Wang, L. Depth camera based collision avoidance via active robot control. J. Manuf. Syst. 2014, 33, 711–718. [Google Scholar] [CrossRef]
- Yu, H.; Fu, Q.; Yang, Z.; Tan, L.; Sun, W.; Sun, M. Robust Robot Pose Estimation for Challenging Scenes With an RGB-D Camera. IEEE Sensors J. 2019, 19, 2217–2229. [Google Scholar] [CrossRef]
- Schmidt, T.; Newcombe, R.; Fox, D. DART: Dense Articulated Real-Time Tracking with Consumer Depth Cameras. Auton. Robots 2015, 39, 239–258. [Google Scholar] [CrossRef]
- Bohg, J.; Romero, J.; Herzog, A.; Schaal, S. Robot arm pose estimation through pixel-wise part classification. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 3143–3150. [Google Scholar] [CrossRef]
- Albert, J.A.; Owolabi, V.; Gebel, A.; Brahms, C.M.; Granacher, U.; Arnrich, B. Evaluation of the Pose Tracking Performance of the Azure Kinect and Kinect v2 for Gait Analysis in Comparison with a Gold Standard: A Pilot Study. Sensors 2020, 20, 5104. [Google Scholar] [CrossRef] [PubMed]
- Michel, D.; Qammaz, A.; Argyros, A.A. Markerless 3D Human Pose Estimation and Tracking Based on RGBD Cameras: An Experimental Evaluation. In Proceedings of the 10th International Conference on PErvasive Technologies Related to Assistive Environments, Island of Rhodes, Greece, 21–23 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 115–122. [Google Scholar] [CrossRef]
- Ye, M.; Wang, X.; Yang, R.; Ren, L.; Pollefeys, M. Accurate 3D pose estimation from a single depth image. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 731–738. [Google Scholar] [CrossRef]
- Moon, S.; Park, Y.; Ko, D.W.; Suh, I.H. Multiple Kinect Sensor Fusion for Human Skeleton Tracking Using Kalman Filtering. Int. J. Adv. Robot. Syst. 2016, 13, 65. [Google Scholar] [CrossRef]
- Gil-Jiménez, P.; Losilla-López, B.; Torres-Cueco, R.; Campilho, A.; López-Sastre, R. Hand Detection and Tracking Using the Skeleton of the Blob for Medical Rehabilitation Applications. In Image Analysis and Recognition; Campilho, A., Kamel, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 130–137. [Google Scholar]
- Cordella, F.; Zollo, L.; Guglielmelli, E. A RGB-D Camera-Based Approach for RobotArm-Hand Teleoperated Control. In Proceedings of the 20th IMEKO TC4 International Symposium and18th International Workshop on ADC Modelling and Testing, Benevento, Italy, 15–17 September 2014; pp. 331–335. [Google Scholar]
- Chung, H.Y.; Chung, Y.L.; Tsai, W.F. An Efficient Hand Gesture Recognition System Based on Deep CNN. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019; pp. 853–858. [Google Scholar] [CrossRef]
- Suarez, J.; Murphy, R.R. Hand gesture recognition with depth images: A review. In Proceedings of the 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; pp. 411–417. [Google Scholar] [CrossRef]
- Cheng, H.; Yang, L.; Liu, Z. Survey on 3D Hand Gesture Recognition. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1659–1673. [Google Scholar] [CrossRef]
- Straka, M.; Hauswiesner, S.; Rüther, M.; Bischof, H. Skeletal Graph Based Human Pose Estimation in Real-Time. In Proceedings of the BMVC, Dundee, UK, 29 August–2 September 2011; pp. 69.1–69.12. [Google Scholar] [CrossRef]
- Furmonas, J.; Liobe, J.; Barzdenas, V. Analytical Review of Event-Based Camera Depth Estimation Methods and Systems. Sensors 2022, 22, 1201. [Google Scholar] [CrossRef] [PubMed]
- Glover, A.J.; Bartolozzi, C. Robust visual tracking with a freely-moving event camera. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3769–3776. [Google Scholar]
- Volinski, A.; Zaidel, Y.; Shalumov, A.; DeWolf, T.; Supic, L.; Ezra Tsur, E. Data-driven artificial and spiking neural networks for inverse kinematics in neurorobotics. Patterns 2022, 3, 100391. [Google Scholar] [CrossRef]
- Bajracharya, M.; DiCicco, M.; Backes, P. Vision-based end-effector position error compensation. In Proceedings of the 2006 IEEE Aerospace Conference, Big Sky, MT, USA, 5–11 March 2006; p. 7. [Google Scholar] [CrossRef]
- Roveda, L.; Maroni, M.; Mazzuchelli, L.; Praolini, L.; Shahid, A.A.; Bucca, G.; Piga, D. Robot End-Effector Mounted Camera Pose Optimization in Object Detection-Based Tasks. J. Intell. Robot. Syst. 2021, 104, 16. [Google Scholar] [CrossRef]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Penksy, M. Sparse Convolutional Neural Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar] [CrossRef]
- Bachhofner, S.; Loghin, A.M.; Otepka, J.; Pfeifer, N.; Hornacek, M.; Siposova, A.; Schmidinger, N.; Hornik, K.; Schiller, N.; Kähler, O.; et al. Generalized Sparse Convolutional Neural Networks for Semantic Segmentation of Point Clouds Derived from Tri-Stereo Satellite Imagery. Remote Sens. 2020, 12, 1289. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https:/tensorflow.org (accessed on 24 August 2022).
- Yan, Y.; Li, B. SpConv: PyTorch Spatially Sparse Convolution Library; Technical Report. Available online: https://github.com/traveller59/spconv (accessed on 24 August 2022).
- Graham, B.; van der Maaten, L. Submanifold Sparse Convolutional Networks. arXiv 2017, arXiv:1706.01307. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef]
- Camuffo, E.; Mari, D.; Milani, S. Recent Advancements in Learning Algorithms for Point Clouds: An Updated Overview. Sensors 2022, 22, 1357. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Bello, S.A.; Yu, S.; Wang, C.; Adam, J.M.; Li, J. Review: Deep Learning on 3D Point Clouds. Remote Sens. 2020, 12, 1729. [Google Scholar] [CrossRef]
- Kumar, A.N.; Sureshkumar, C. Background subtraction based on threshold detection using modified K-means algorithm. In Proceedings of the 2013 International Conference on Pattern Recognition, Informatics and Mobile Engineering, Salem, MA, USA, 21–22 February 2013; pp. 378–382. [Google Scholar] [CrossRef]
- Li, C.; Wang, W. Detection and Tracking of Moving Targets for Thermal Infrared Video Sequences. Sensors 2018, 18, 3944. [Google Scholar] [CrossRef]
- Bouwmans, T.; Baf, F.E.; Vachon, B. Background Modeling using Mixture of Gaussians for Foreground Detection—A Survey. Recent Patents Comput. Sci. 2008, 1, 219–237. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Williams, C.; Seeger, M. Using the Nyström Method to Speed Up Kernel Machines. In Advances in Neural Information Processing Systems; Leen, T., Dietterich, T., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2001; Volume 13, pp. 682–688. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Roweis, S.; Ghahramani, Z. A Unifying Review of Linear Gaussian Models. Neural Comput. 1999, 11, 305–345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duckworth, D. pykalman: An implementation of the Kalman Filter, Kalman Smoother, and EM algorithm in Python. 2013. Available online: https://pypi.org/project/pykalman (accessed on 24 August 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training subtractor |
|
| Removing background |
|
| errα [degree] | ||||||
|---|---|---|---|---|---|---|
| Time [ms] | [deg] | |||||
| 20 | 3 | 28.67 | 1.25 | 4.05 | 2.45 | 2.58 |
| 4 | 28.32 | 1.24 | 3.99 | 2.35 | 2.53 | |
| 5 | 28.48 | 1.20 | 4.08 | 2.37 | 2.55 | |
| 6 | 28.47 | 1.24 | 4.05 | 2.43 | 2.57 | |
| 40 | 3 | 31.66 | 1.19 | 3.66 | 2.22 | 2.36 |
| 4 | 31.91 | 1.21 | 3.61 | 2.26 | 2.36 | |
| 5 | 31.80 | 1.20 | 3.72 | 2.17 | 2.36 | |
| 6 | 31.86 | 1.14 | 3.65 | 2.27 | 2.35 | |
| 60 | 3 | 34.98 | 1.20 | 3.52 | 2.24 | 2.32 |
| 4 | 35.12 | 1.15 | 3.69 | 2.22 | 2.35 | |
| 5 | 35.01 | 1.17 | 3.55 | 2.23 | 2.32 | |
| 6 | 34.99 | 1.19 | 3.49 | 2.24 | 2.31 | |
| x | y | z | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Camera | Model | Set | [degree] | [mm] | [deg] | [mm] | ||||
| left | deep | train | 1.14 | 1.58 | 1.90 | 5.80 | 6.18 | 6.14 | 1.54 | 10.46 |
| test | 2.68 | 3.95 | 3.06 | 12.54 | 14.98 | 9.75 | 3.23 | 21.84 | ||
| graph | train | 1.01 | 2.52 | 2.01 | 6.83 | 6.09 | 8.38 | 1.85 | 12.41 | |
| test | 1.49 | 4.42 | 2.00 | 9.38 | 9.27 | 12.73 | 2.64 | 18.32 | ||
| right | deep | train | 0.98 | 1.63 | 2.16 | 6.09 | 5.64 | 6.88 | 1.59 | 10.78 |
| test | 2.06 | 2.25 | 2.23 | 9.77 | 8.48 | 6.85 | 2.18 | 14.64 | ||
| graph | train | 0.87 | 2.79 | 2.14 | 6.91 | 5.61 | 8.79 | 1.93 | 12.51 | |
| test | 1.08 | 2.58 | 1.68 | 6.61 | 6.48 | 7.22 | 1.78 | 11.74 | ||
| Model | Task | Mean Time per Frame [ms] |
|---|---|---|
| Preprocessing | Getting frame from camera | 7.07 |
| (common part) | Background subtraction | 1.20 |
| Point cloud from depth image | 4.46 | |
| Subtotal time: | 12.73 | |
| Graph | k–means | 8.55 |
| Graph fitting | 10.47 | |
| Transformation + Regression | ||
| Total time: | 31.76 | |
| Sparse CNN | Prediction | 7.03 |
| Total time: | 21.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodziewicz-Bielewicz, J.; Korzeń, M. Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation. Sensors 2022, 22, 6518. https://doi.org/10.3390/s22176518
Rodziewicz-Bielewicz J, Korzeń M. Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation. Sensors. 2022; 22(17):6518. https://doi.org/10.3390/s22176518
Chicago/Turabian StyleRodziewicz-Bielewicz, Jan, and Marcin Korzeń. 2022. "Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation" Sensors 22, no. 17: 6518. https://doi.org/10.3390/s22176518
APA StyleRodziewicz-Bielewicz, J., & Korzeń, M. (2022). Comparison of Graph Fitting and Sparse Deep Learning Model for Robot Pose Estimation. Sensors, 22(17), 6518. https://doi.org/10.3390/s22176518