1. Introduction
As one of the frontiers of current ocean development, deep-sea manned submersibles represent a country’s comprehensive scientific and technological strength in materials, control and marine disciplines [
1]. As China’s first self-designed and self-developed operational deep-sea manned submersible, Jiaolong has performed many deep-sea dive missions and completed scientific investigations in the fields of marine geology, marine biology, and marine environment [
2,
3]. The fault detection of deep-sea manned submersibles has become one of the most significant tasks during the execution of the dive mission due to the person safety threat and economic loss caused by downtime of submersibles [
4,
5].
With the improvement of computing power and the development of signal processing technology, many researchers have made great achievements in the field of fault detection [
6,
7,
8]. We can divide the fault detection methods into four categories: distance-based methods, clustering-based methods, probability distribution-based methods, and the deep learning-based methods. For distance-based methods, K-Nearest Neighbor (KNN) algorithm supposes that the k nearest neighbor distances of the fault sample are much larger than the normals’ [
9]. However, KNN is suitable for the situations where the density of each cluster is relatively uniform. Local Outlier Factor (LOF) method pays more attention to the detection of local outliers, and the detected outliers can be considered as fault samples [
10]. Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [
11], K-Means [
12], and WaveCluster [
13] are the representative algorithms of clustering-based methods. The limitation of them lies in requiring prior knowledge about data cluster number. In probability distribution-based methods, Gaussian Mixture Model (GMM) is a popular approach [
14], which fits the dataset to a mixed Gaussian distribution, and discordant observations are probably caused by the failure events. However, the cluster type and number can act on the detection performance. In recent years, the deep learning-based methods have gained much popularity in fault detection [
15,
16,
17,
18,
19]. In [
20], a fuzzy neural network model combining BP neural network and fuzzy theory was established for fault diagnosis. A method based on a deep convolutional neural network was proposed for diagnosing bearing faults in [
21]. Xu et al. proposed an fault diagnosis method based on deep transfer convolutional neural network [
22], which combined transfer learning theory and convolutional neural network to realize online fault detection and diagnosis.
However, there are two critical problems in submersible fault detection.
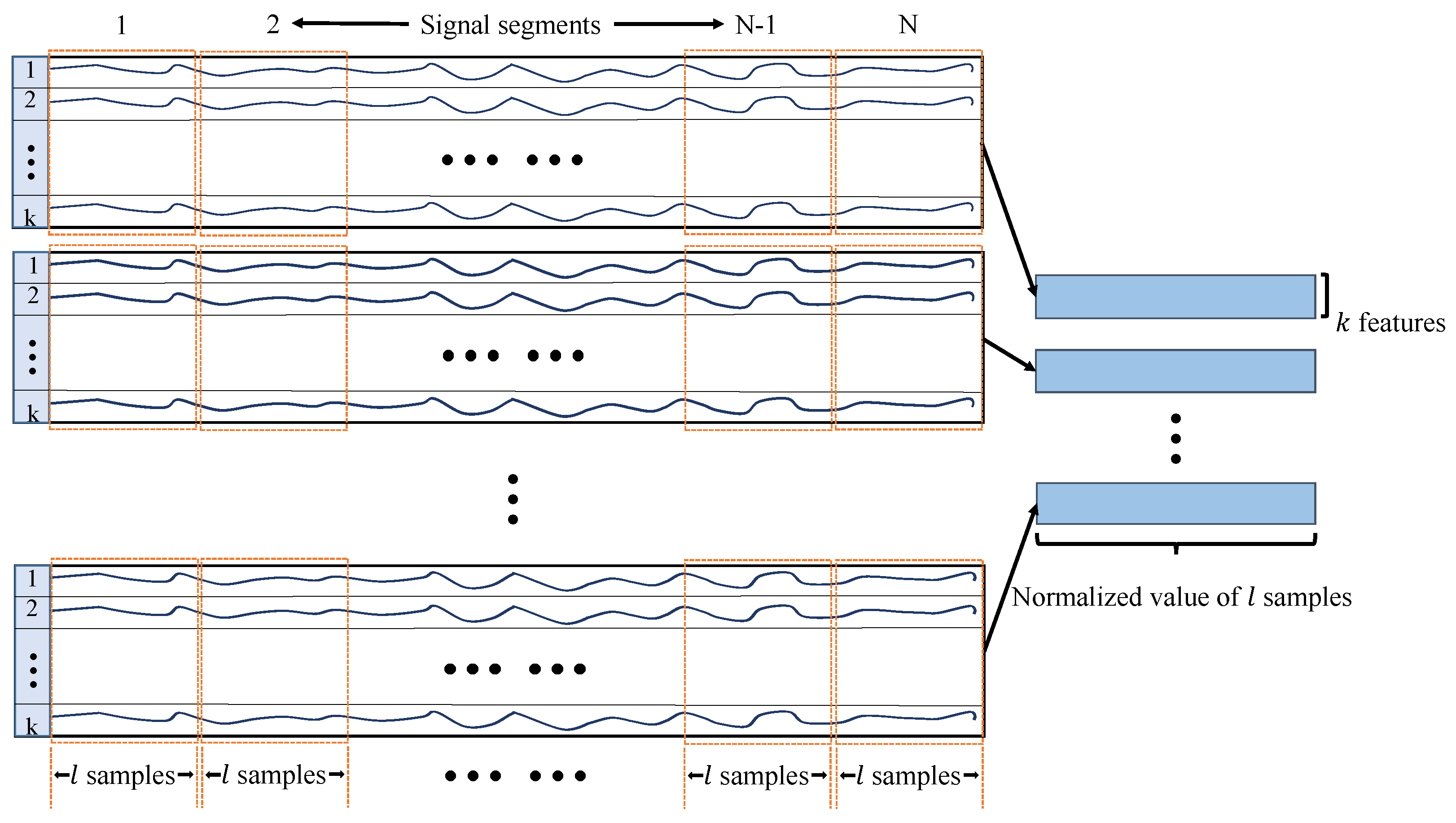
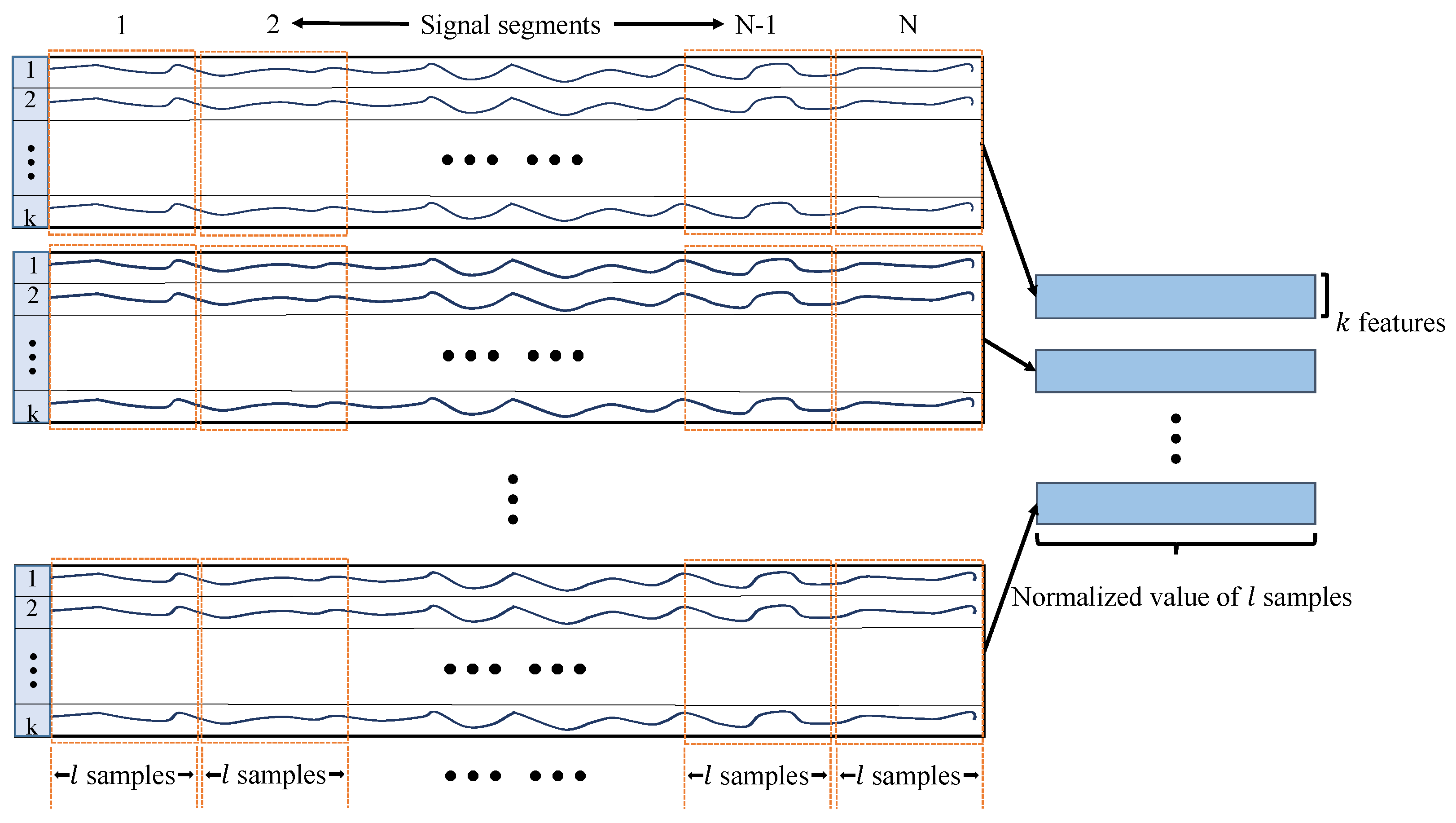
(1) High-dimensional sensor data. The raw data from submersible sensing system is high in dimensionality, but redundant feature variables will bring challenges to fault detection and cause the increase in overfitting.
(2) Limited fault issues. Due to the low fault frequency of submersibles, only limited sensor data including fault samples is collected, which imposes limitations on model training and is a challenging problem for fault detection.
To address above-mentioned redundant features caused by high-dimensional dataset, a large collection of methods have been proposed, including Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA) and feature selection composed of sub-approaches such as filter, wrapper, and embedded. In [
23], PCA as an unsupervised dimensionality reduction method was used to remove redundant features in order to get the low-dimensional feature matrix and retain the essential attributes for the fault detection of rotor system. LDA processes labeled data, and when projecting them to a low-dimensional space, it satisfies as much as possible to retain the information of the data [
24]. In [
25], filter and wrapper methods were used to form a hybrid feature selection framework to get the best feature set, thereby improving the generalization and detection accuracy of model. In terms of small sample fault detection, data augmentation methods and siamese neural networks have become popular [
26,
27,
28]. In order to obtain sufficient data and improve the robustness of the detection model, data augmentation is an significant technology in data processing [
29]. Previously, methods such as noise addition, interpolation, window slicing, position replacement and sequence fusion have been maturely applied in data augmentation for fault detection [
30]. With the development of deep learning, Generative Adversarial Networks (GAN) have been proposed as powerful tools for data generation [
31]. In [
32], a small-sample fault detection method using synthetic data was proposed, which improved GANs to generate more realistic fault data and enhance the detection accuracy. A multiple-objective generative adversarial active learning model was designed to detect outliers using limited data in high-dimensional space in [
33]. In addition, siamese neural networks have made great achievements in small samples detection and one-shot learning [
34], and to alleviate the over-fitting issue in anomaly detection of industrial cyber-physical systems, a siamese convolution neural network based few-shot learning model was proposed in [
35].
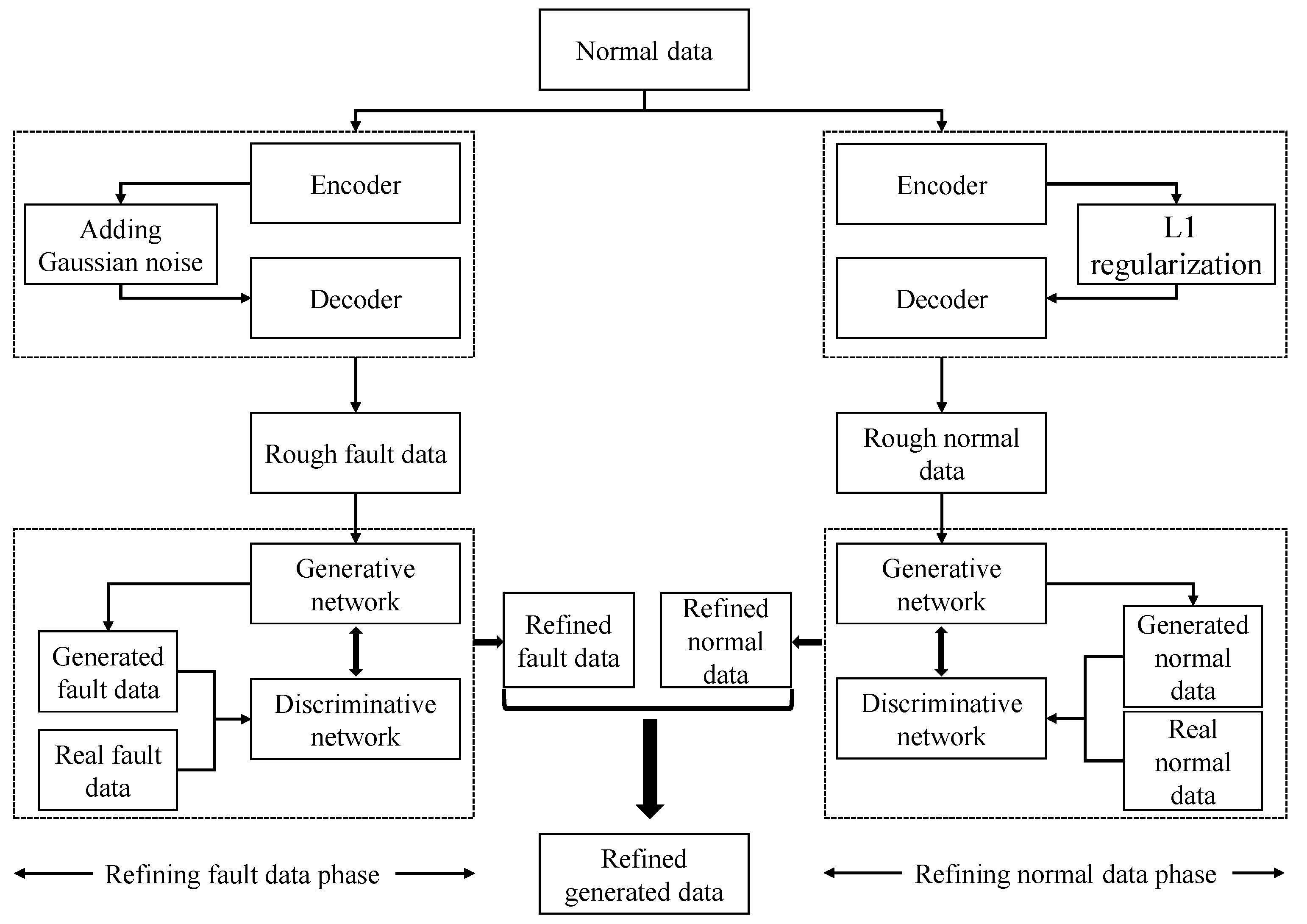
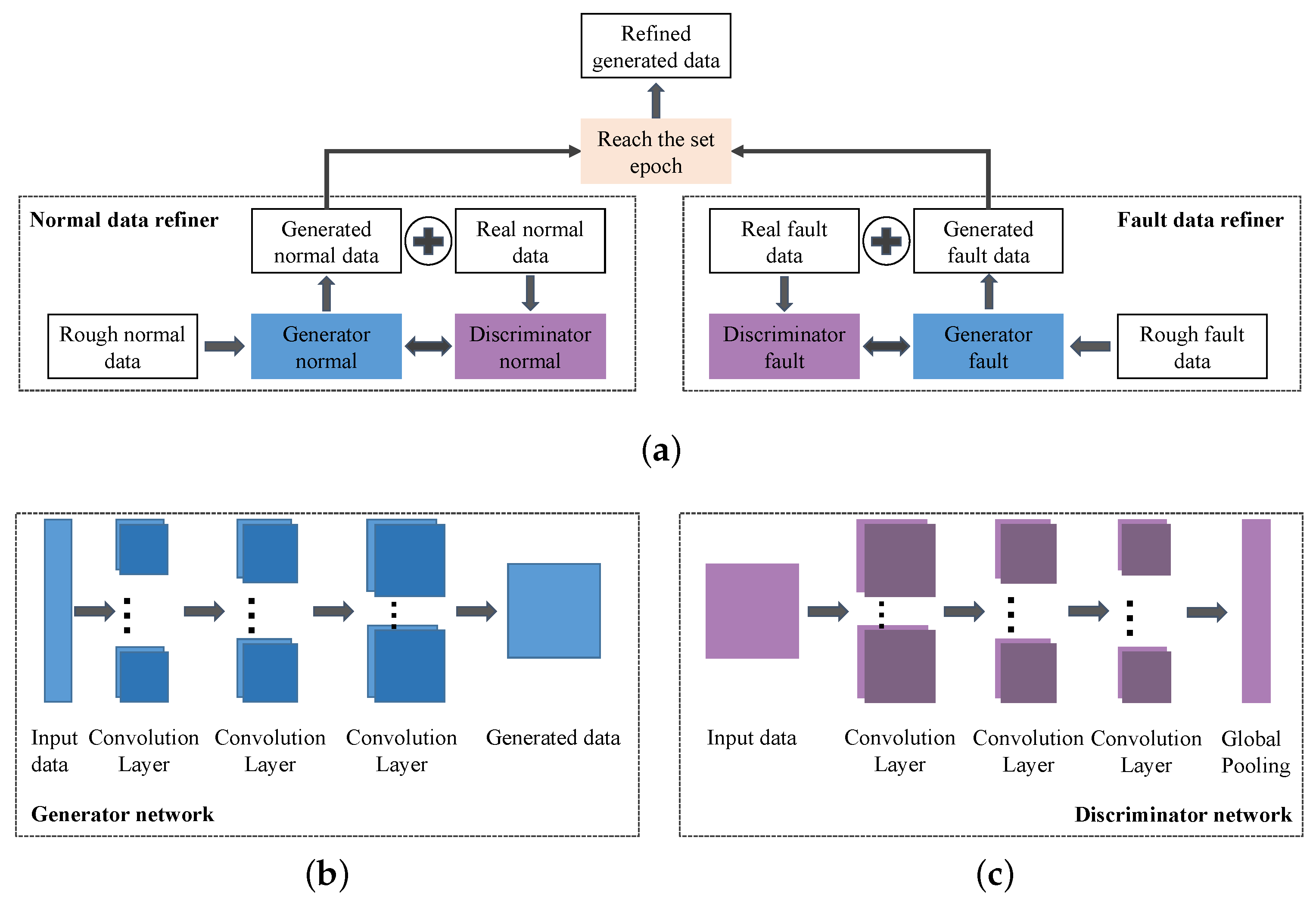
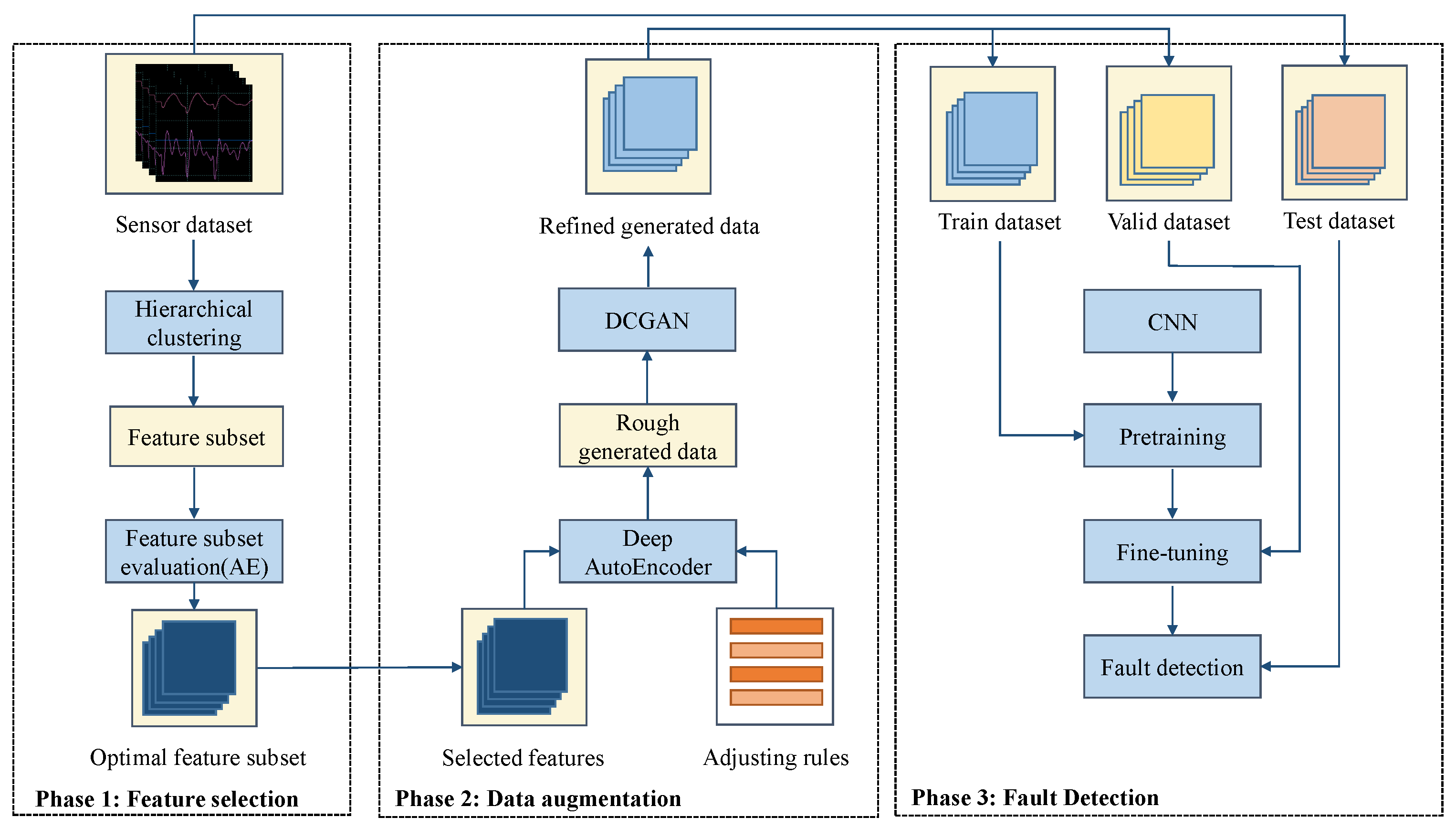
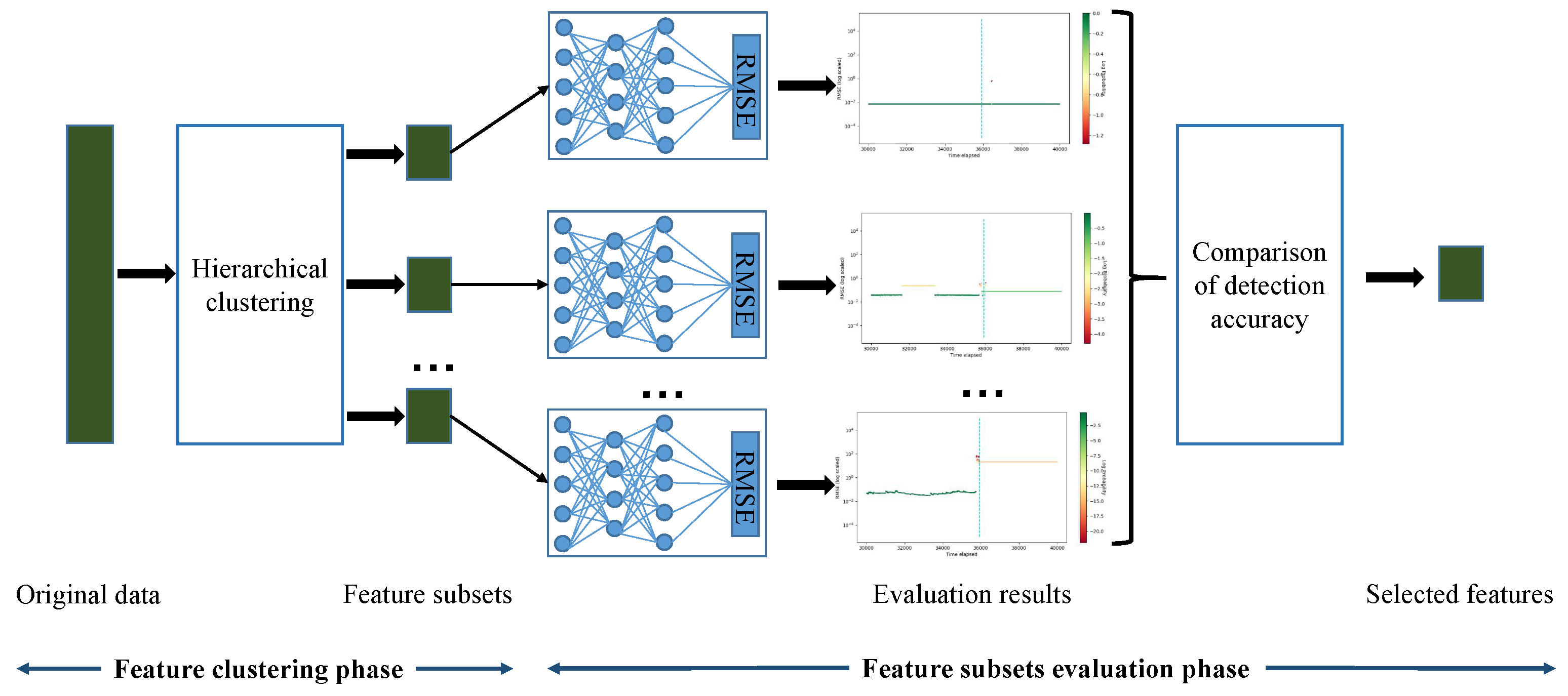
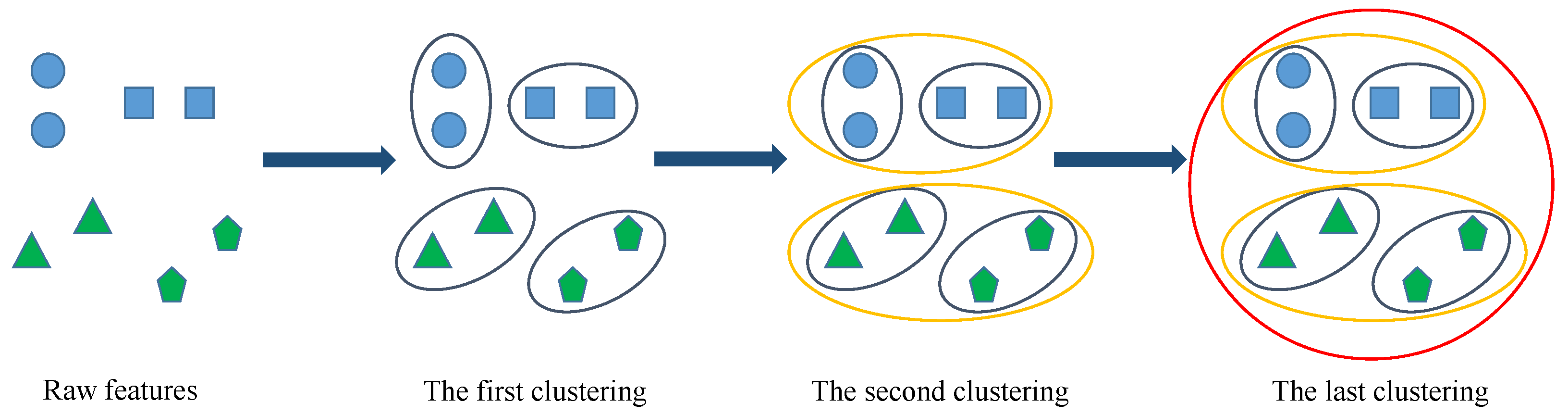
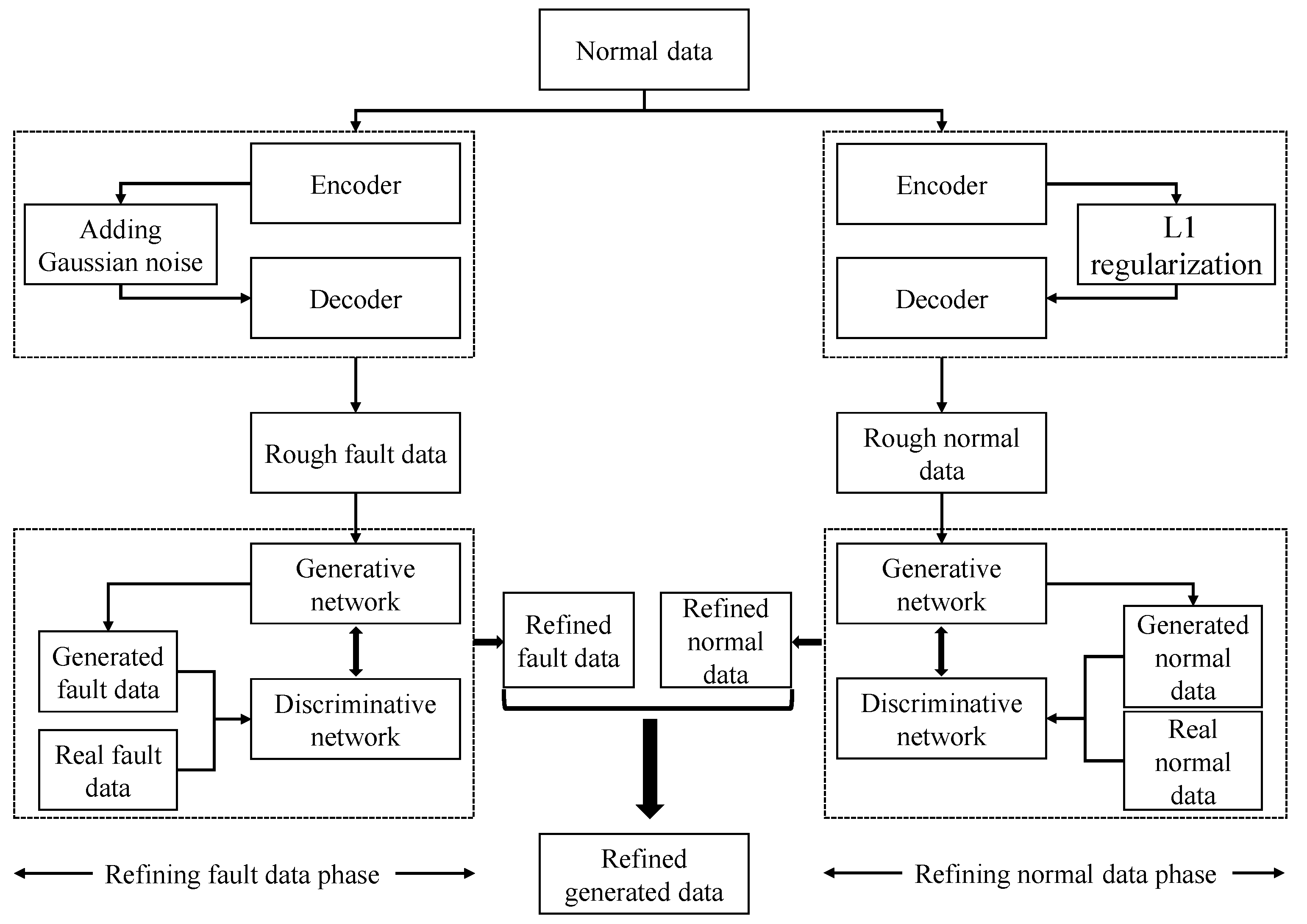
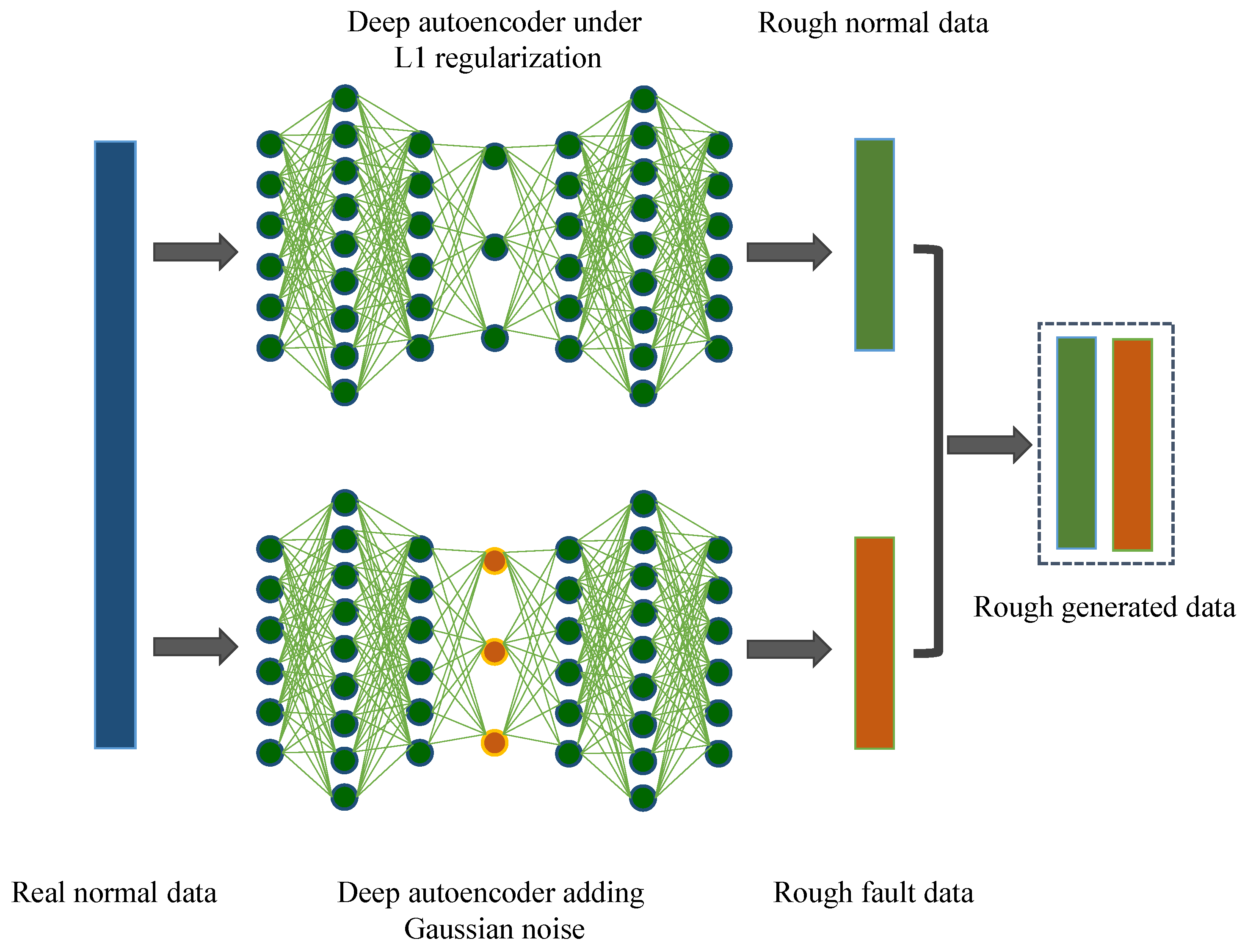
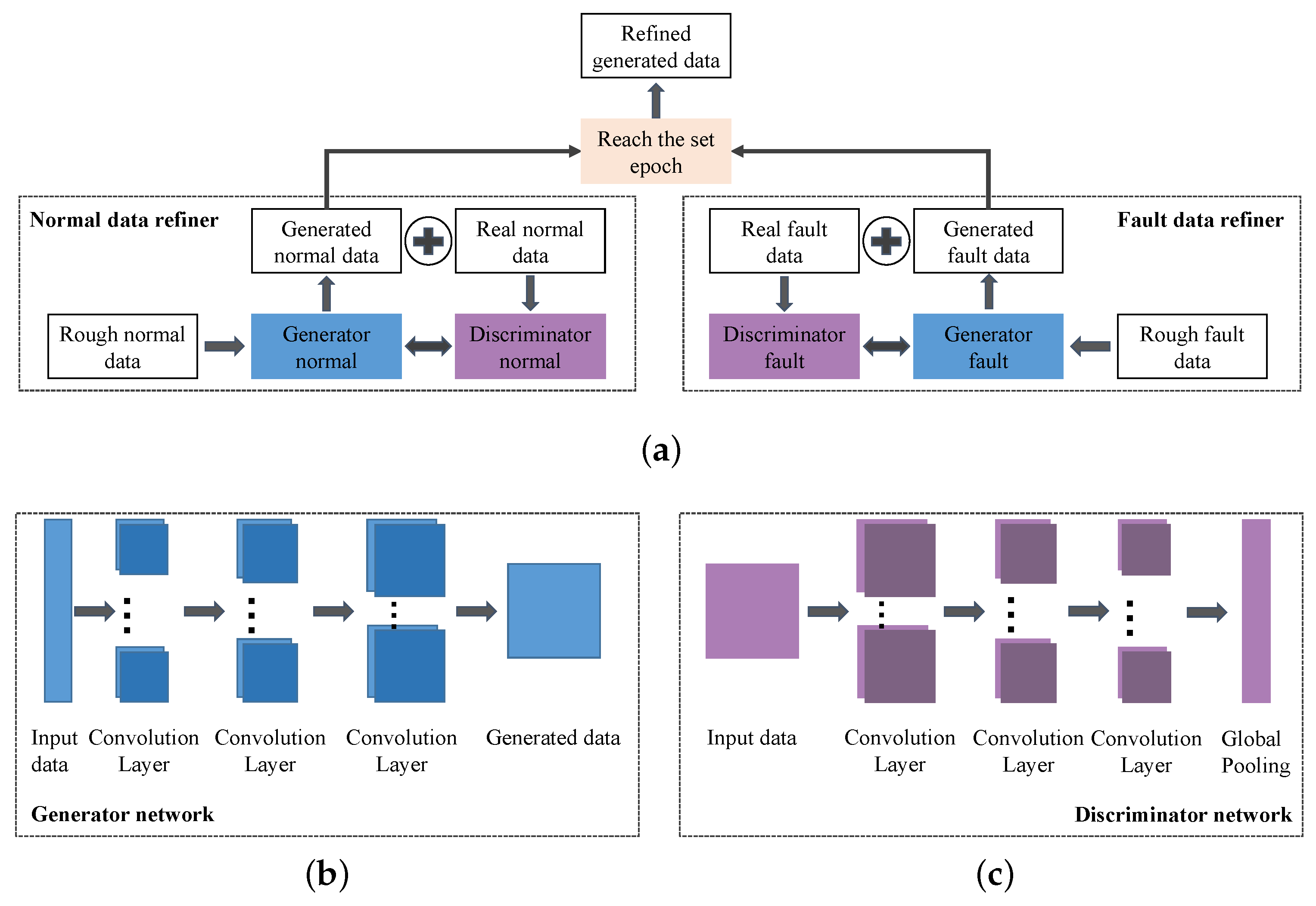
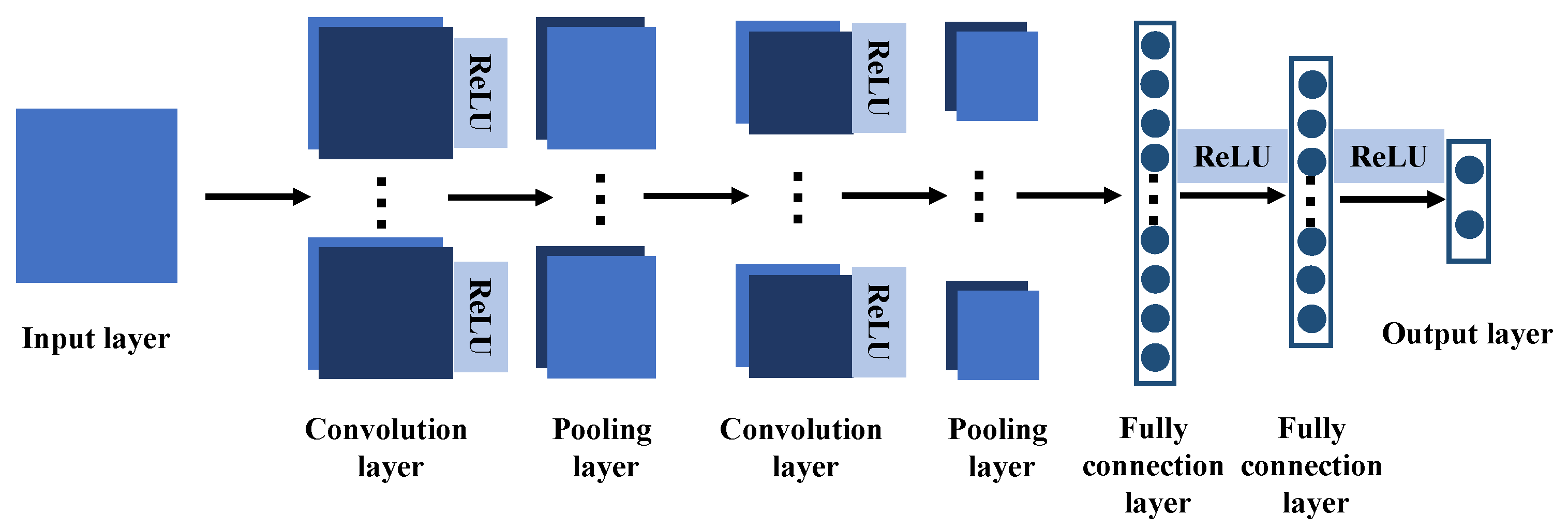
We propose a novel high-dimensional and small-sample submersible fault detection method, which applies hierarchical clustering and AEs to select significant features and use GANs to synthesize data. In this paper, hierarchical clustering is used to cluster the raw data with the degree of similarity, and then AE is applied to evaluate the features of each cluster to determine the correlation between the feature groups and labels, so as to obtain the effective features for submersible fault detection. To get enough training data, a rough simulated data generation process is developed to transform the normal sensor data to rough simulated data according to adding adjusting rules in deep autoencoders. The improved DCGAN is the data refiner, which is trained to obtain realistic data transformed from the rough simulated data. Based on the above two processing methods, we have gotten a meaningful feature group and sufficient training data, so that CNN can be used for fault detection, which is pretrained and fine-tuned with generated data, and tested with the real sensor data.
The main contributions of this paper are as follows.
(1) A novel submersible fault detection method is designed, which innovatively completes the fault detection of submersible hydraulic system, and greatly improves the accuracy of detection by comparing with other classical algorithms.
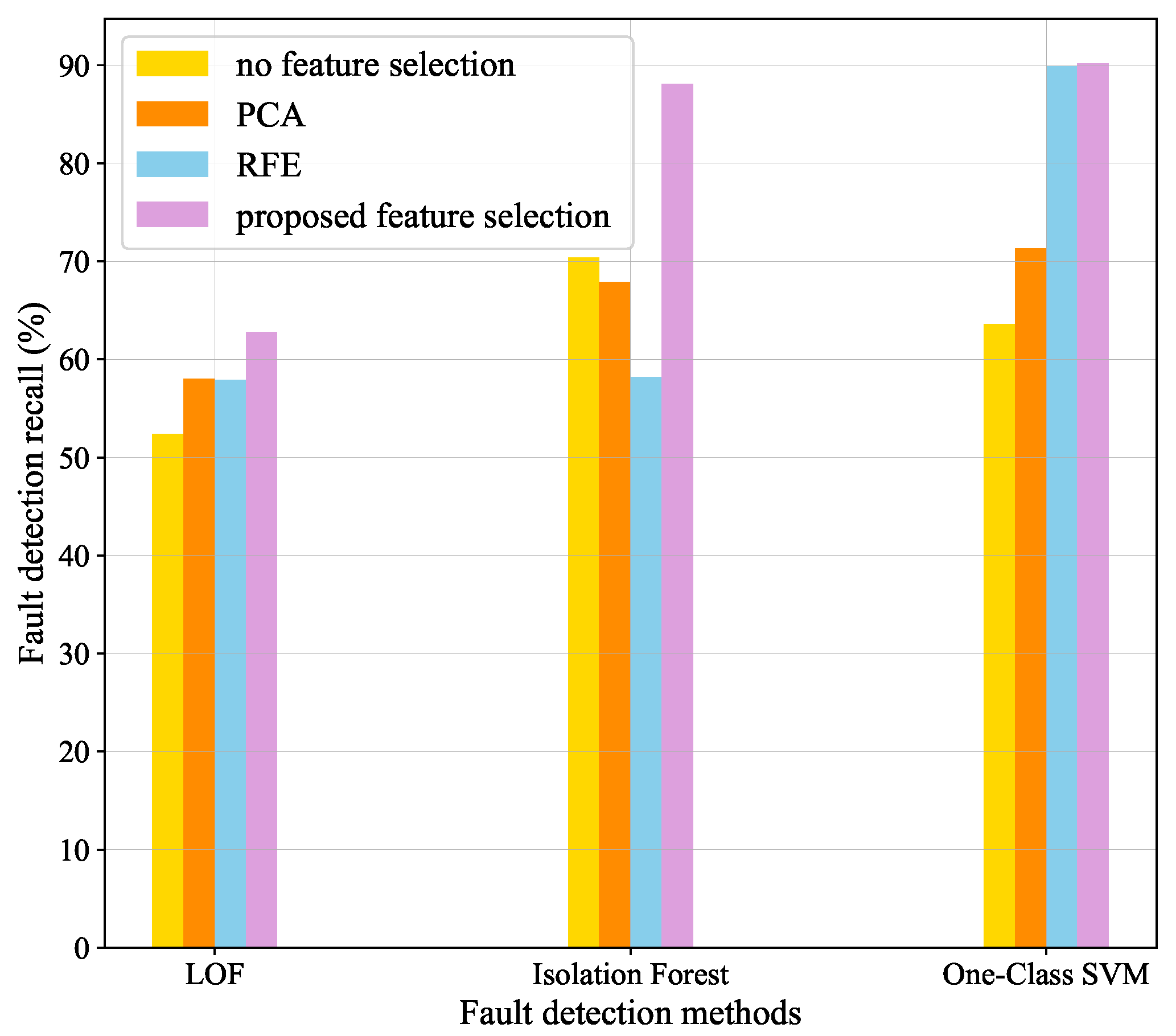
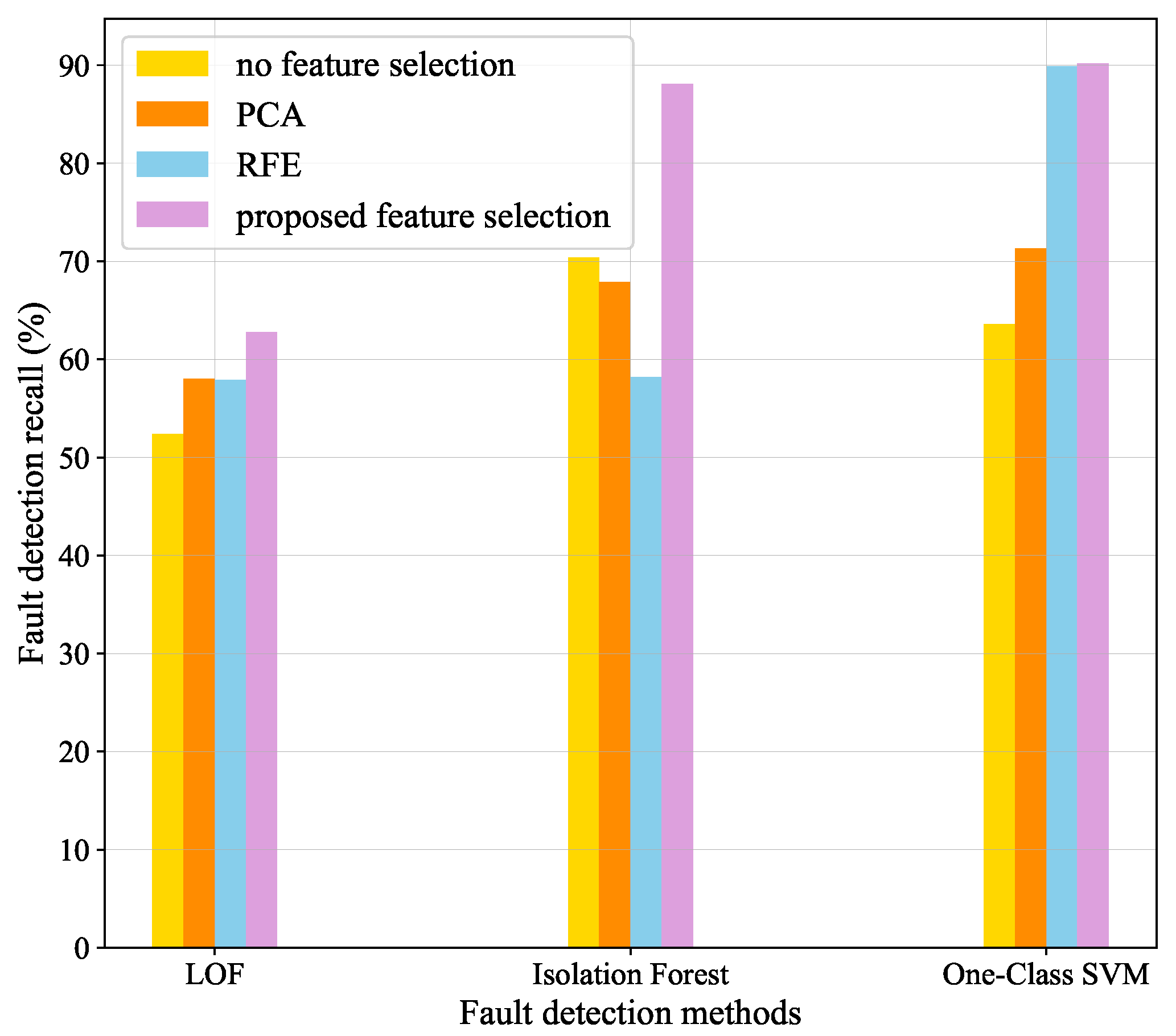
(2) A feature selection model is proposed to select features strongly associated with fault event and able to effectively improve results of submersible fault detection and outperform several other state-of-art dimensional reduction methods.
(3) A data augmentation method based on improved DCGAN is developed, which generates more realistic data as training dataset for fault detection model. No real sensor data are required in fault detector training phase and the fault samples in submersible sensor dataset can be precisely detected.
The remainder of this paper is organized as follows.
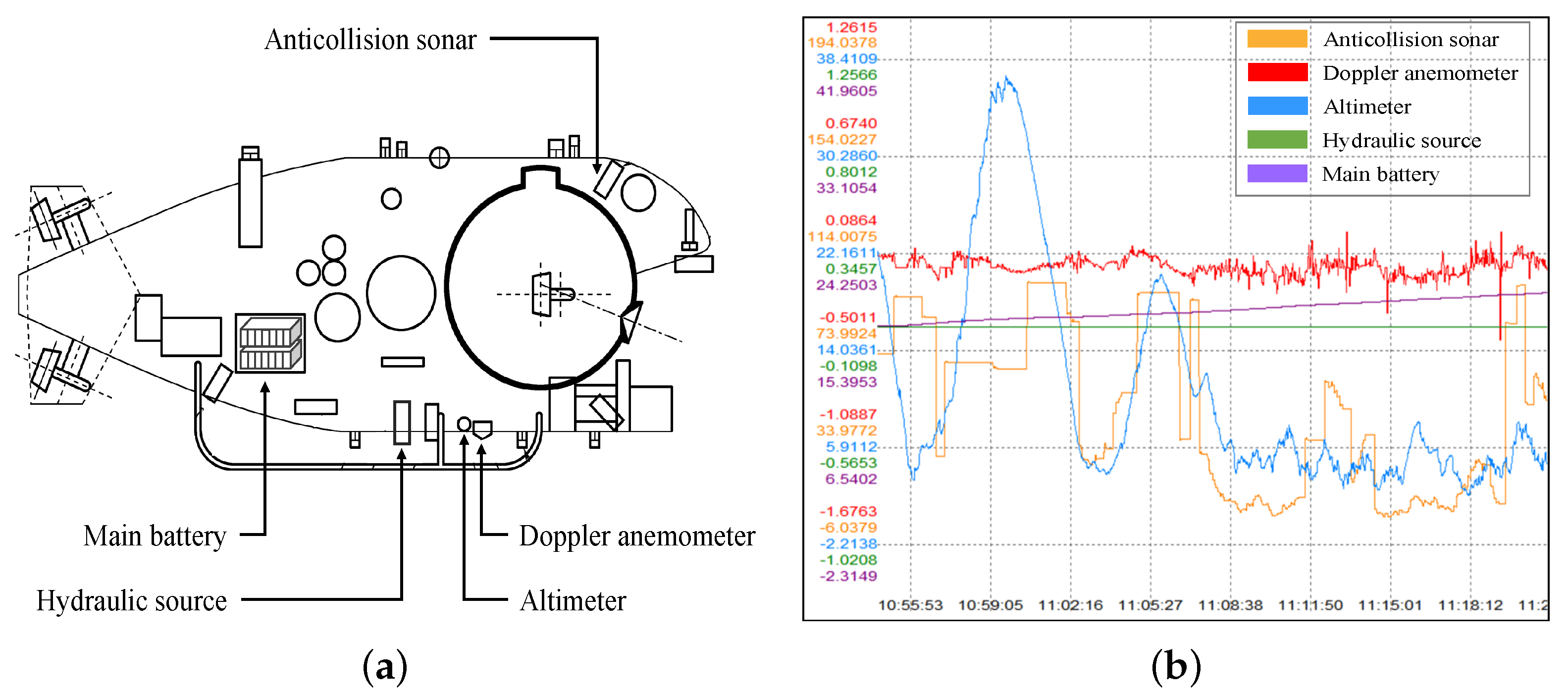
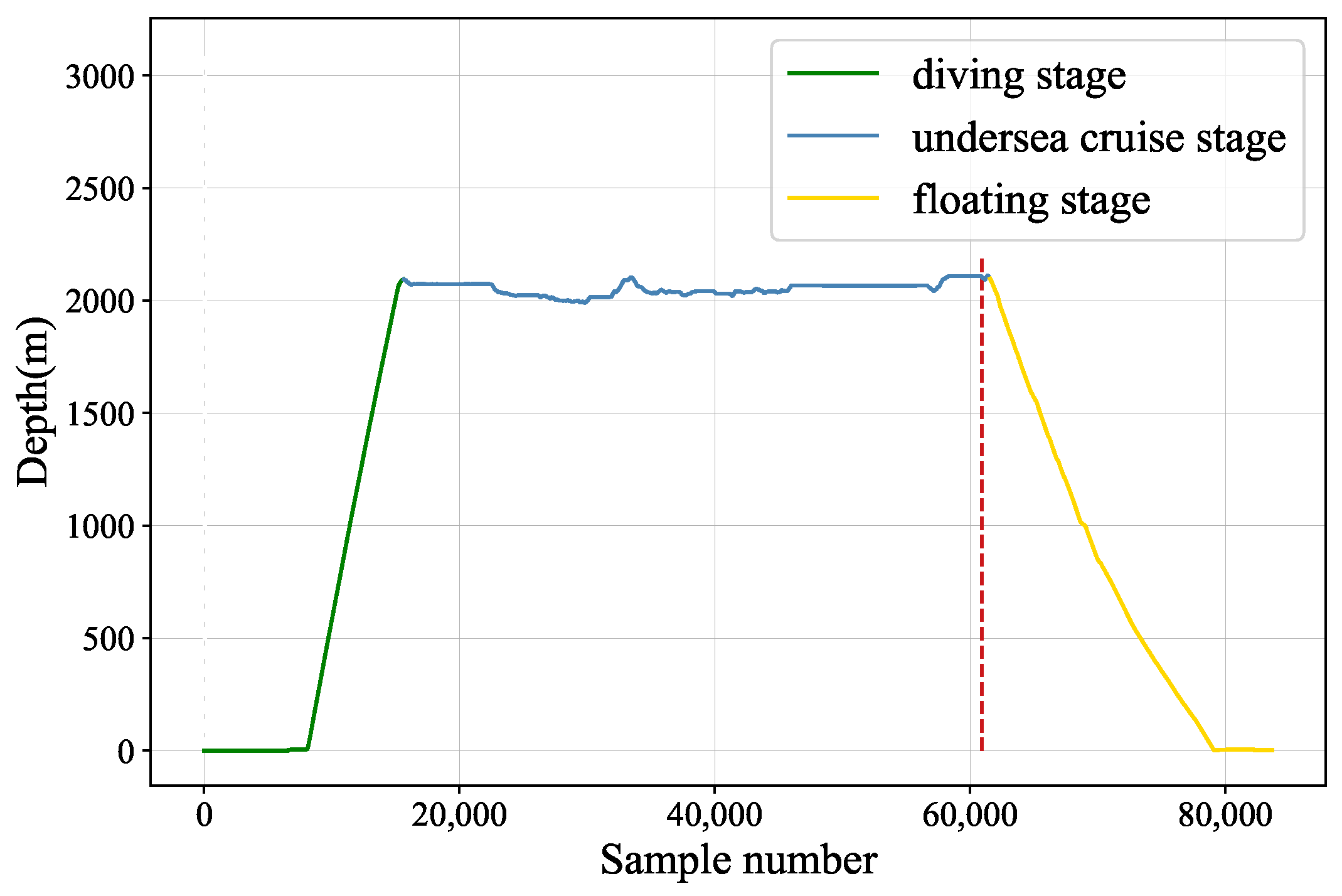
Section 2 is the description of the target submersible and sensor data set collected from the submersible. The submersible fault detection model is illustrated in
Section 3. In
Section 4, experiments and analysis are performed. Finally,
Section 5 summarizes the conclusion of this paper with future work.
5. Conclusions
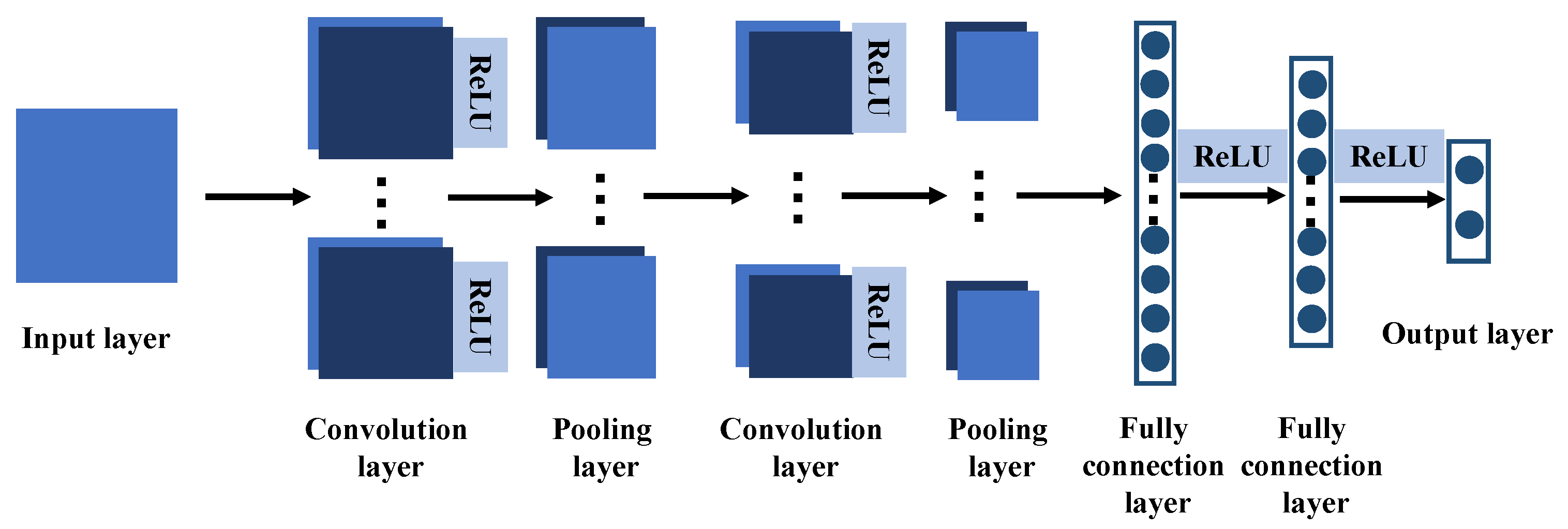
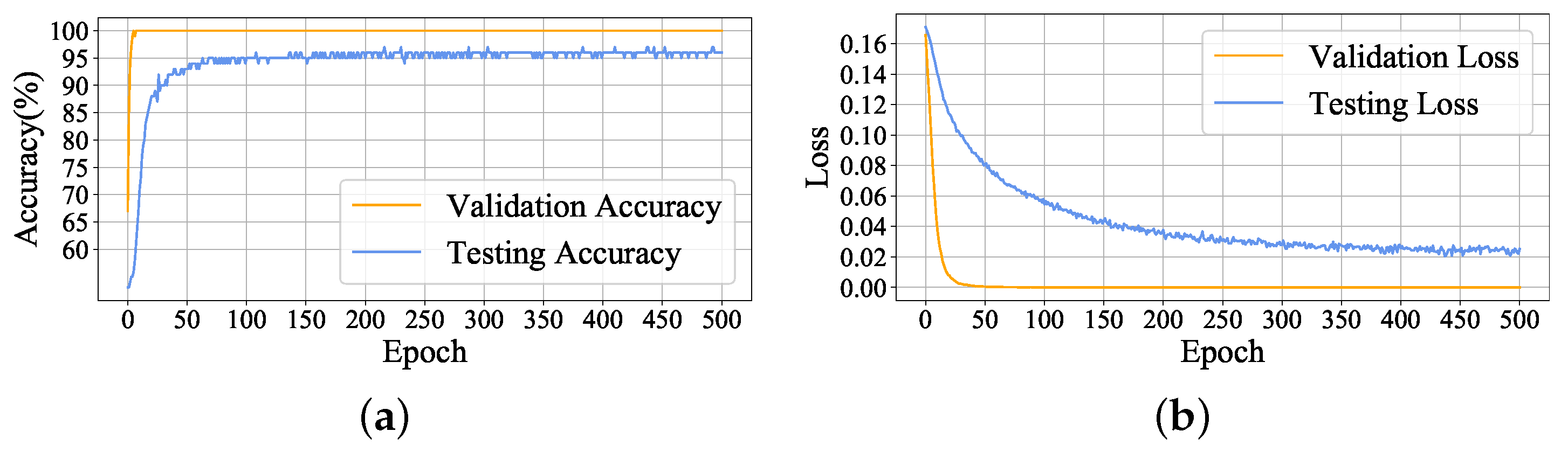
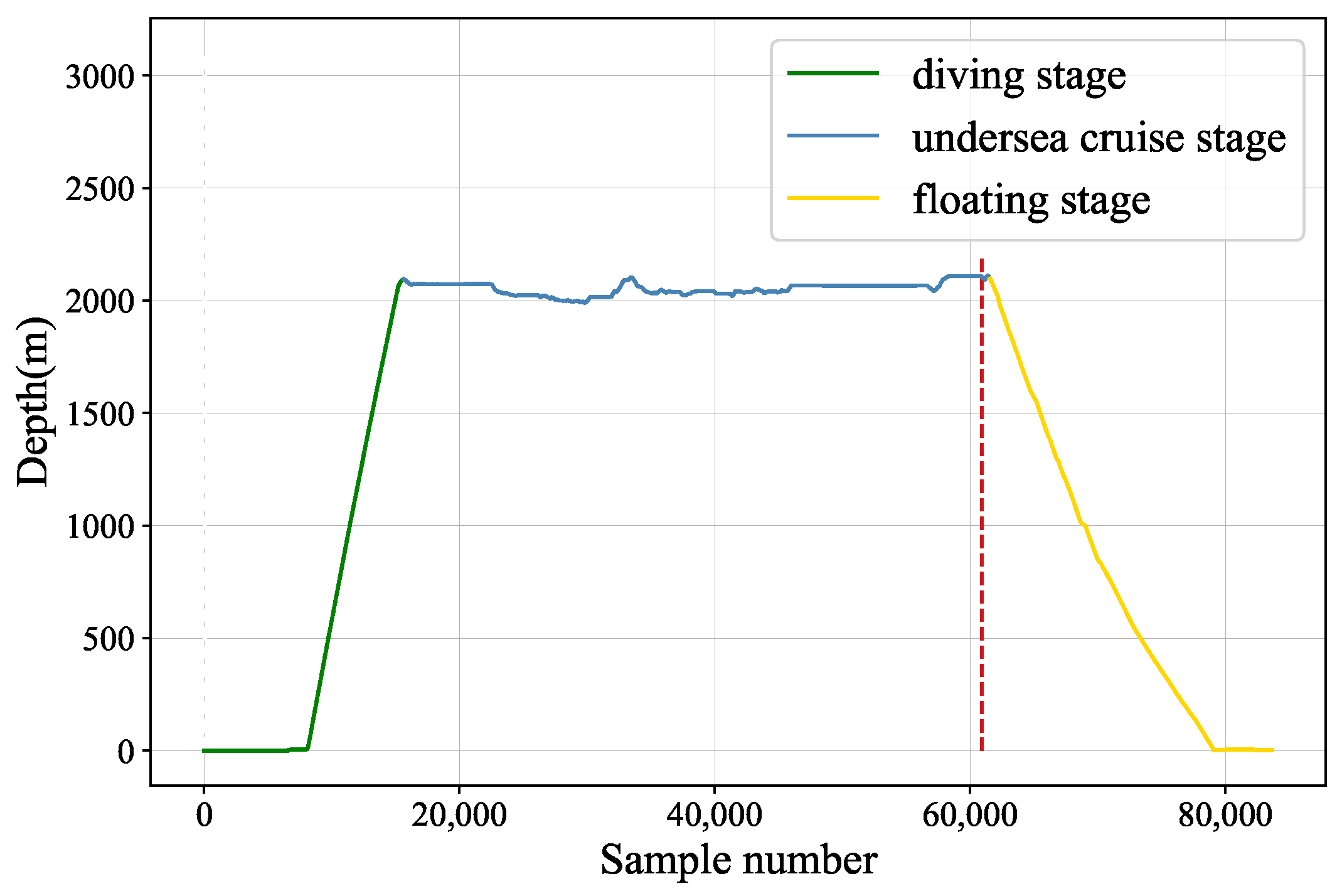
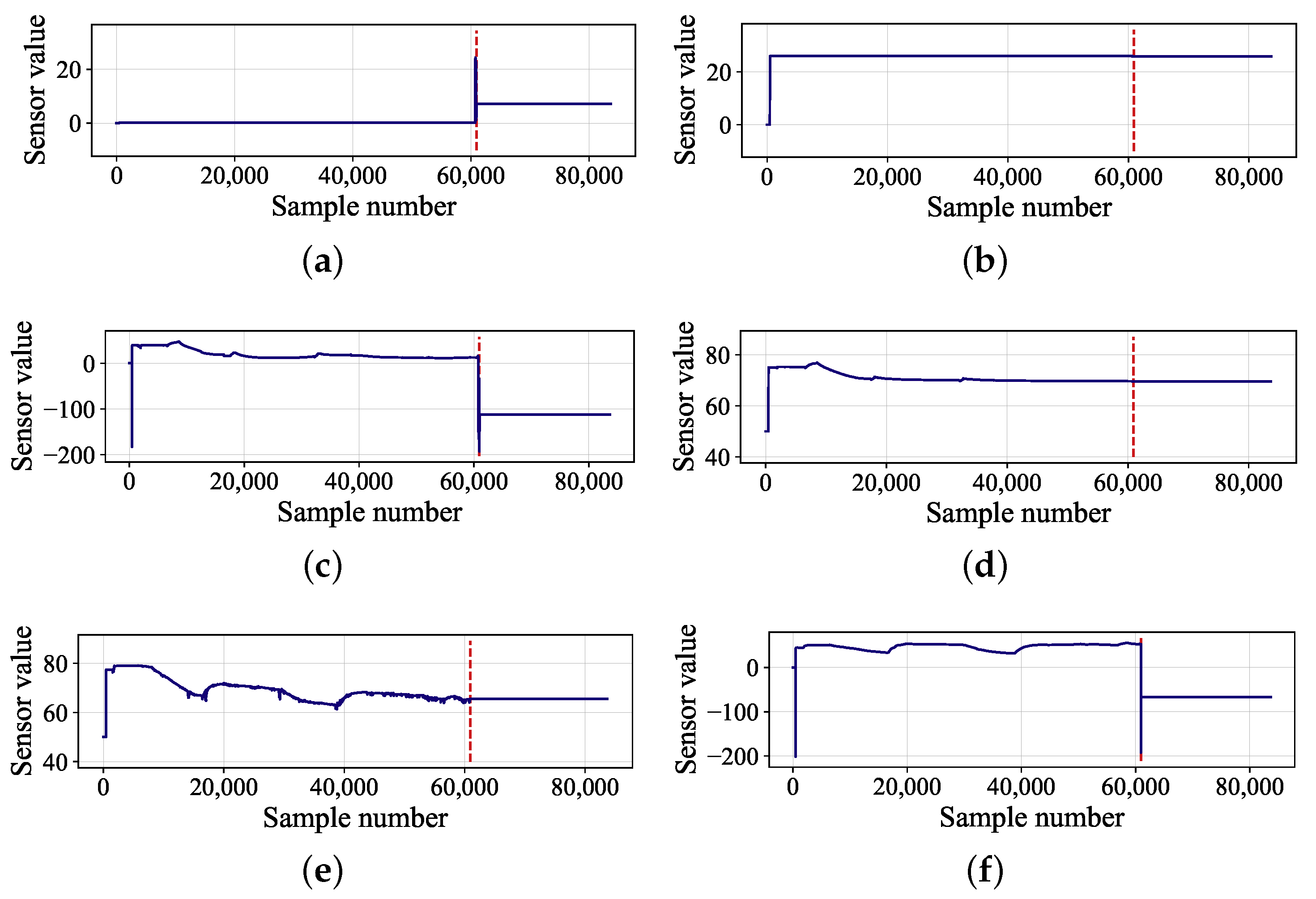
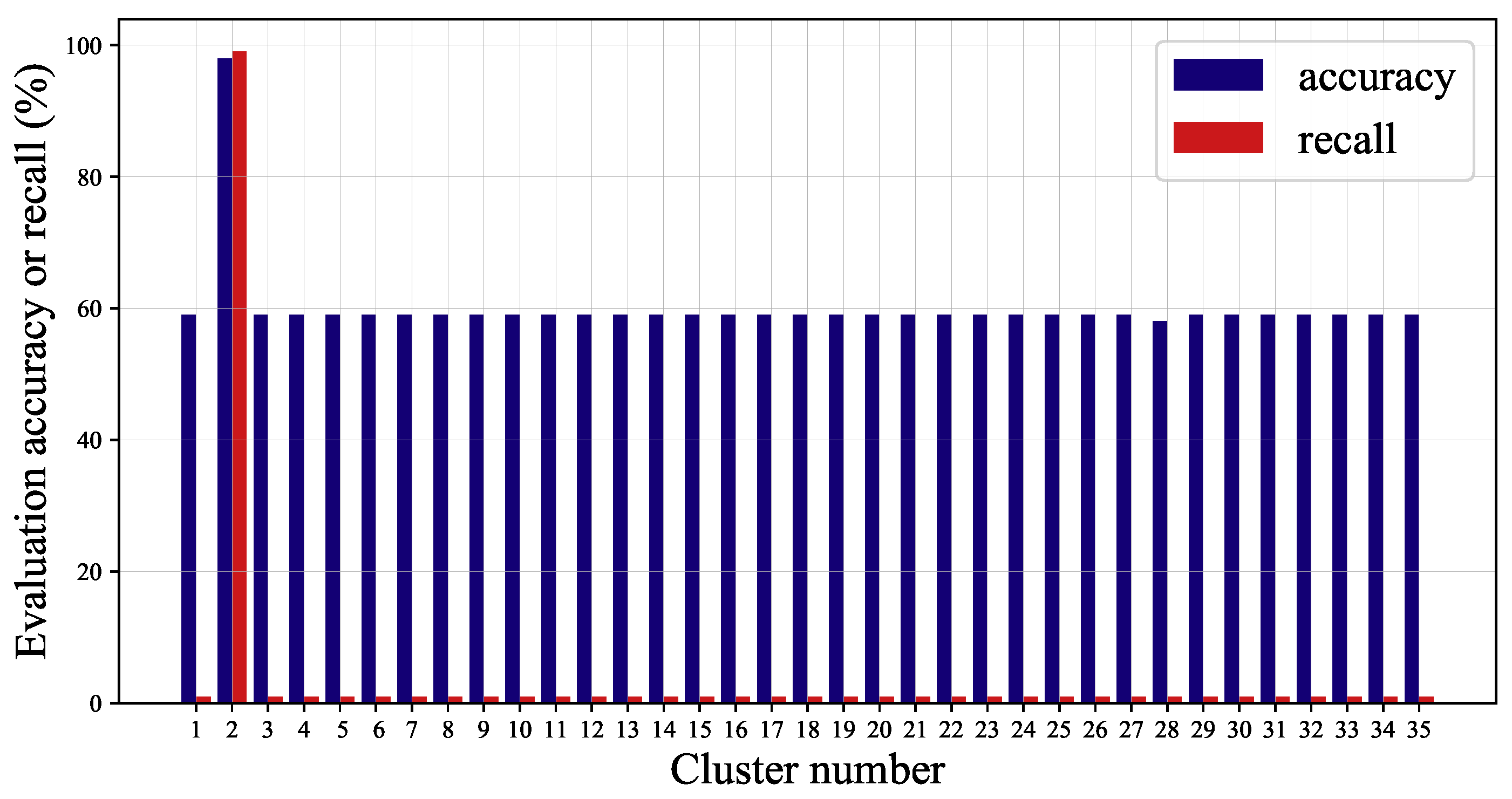
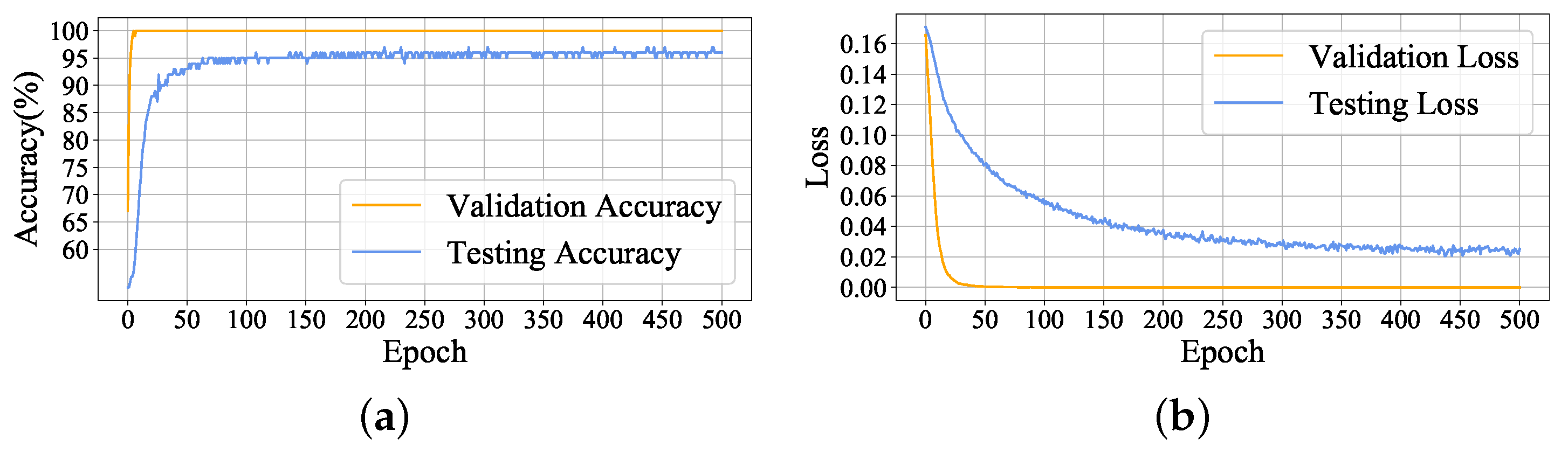
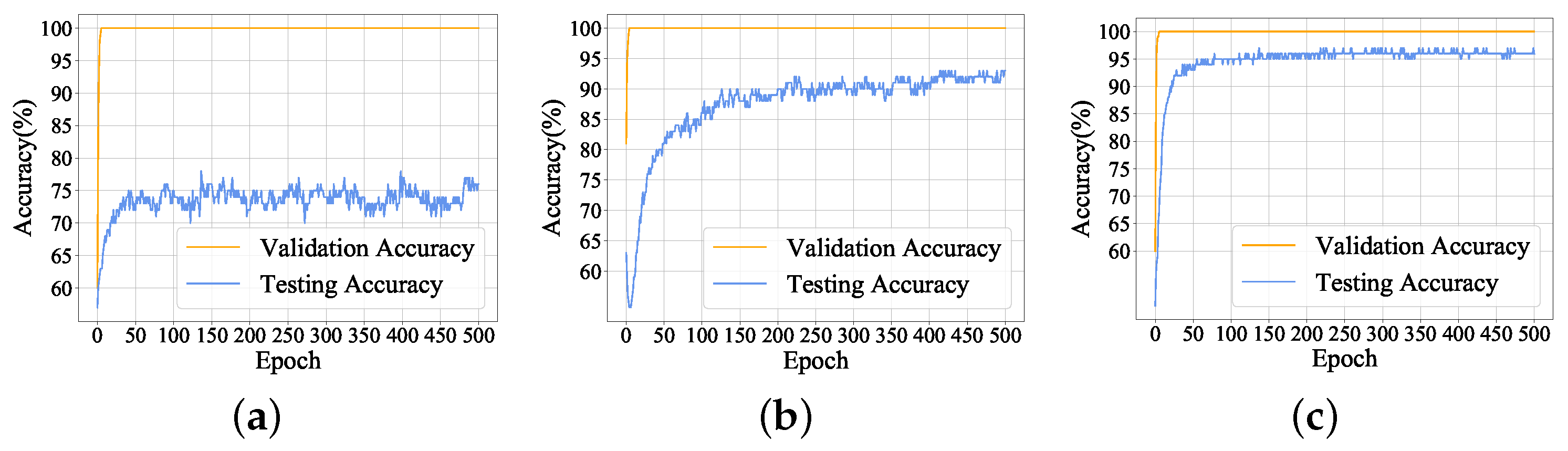
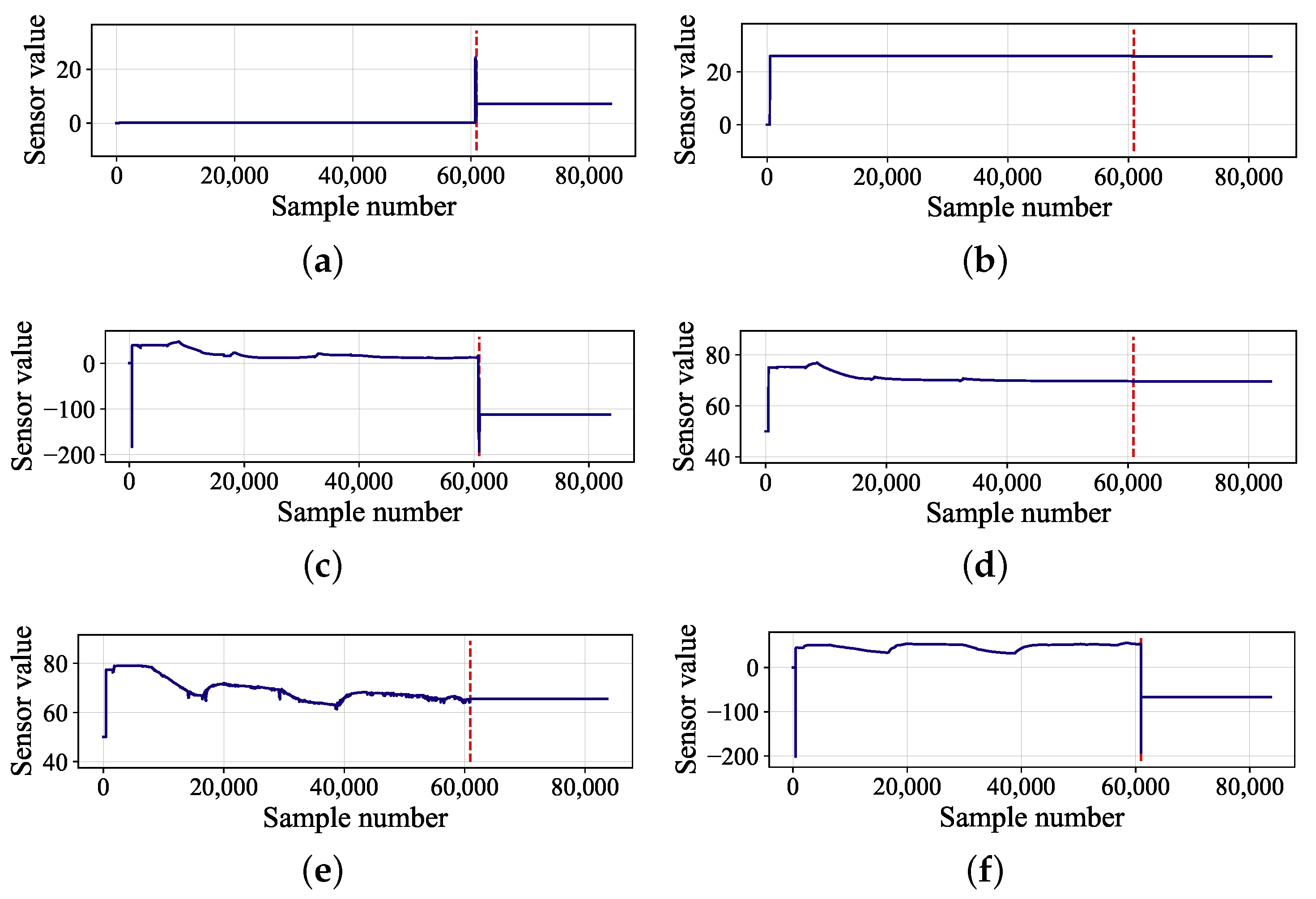
In this paper, a submersible fault detection method is proposed. The method is designed to overcome the difficulties of scarce dive data and high dimensionality. There are three modules in this method: feature selection, data augmentation and fault detection. In the first module, agglomerative hierarchical clustering and AEs are used to select the optimal feature subset related to the fault event. In the second module, the proposed adjusting rules is used to generated rough data with deep autoencoders, then the improved DCGAN as refiner transforms the rough data to realistic data. In the third module, LeNet-5 structure-based CNN model is applied as the fault detector, which is trained and fine-tuned with generated data. The proposed method is tested by the real submersible sensor data, and the results indicate that our method can effectively detect fault occurring in submersible hydraulic system. In comparison with several classic algorithm, in terms of accuracy, recall, precision and F1, the proposed method outperforms other fault detection algorithms. We have also analyzed the relationship between fault event and sensor signals, which can provide information for the retrospect of the fault details.
Although good results have achieved in this paper, there are still some limitations in our study. First, we currently only detect and analyze the failure of the hydraulic system in the submersible. Second, our proposed method currently only processes the sensor signal of the submersible. Third, we can only simulate the fault occurred to generate data. Therefore, we will continue the study focusing on three aspects: (1) After obtaining the fault data of other systems, we will improve the algorithm according to its data characteristics to achieve accurate fault detection. (2) The adaptive improvement of the algorithm is made to transfer it to other data sets so as to realize the fault detection of other applications. (3) We will introduce expert knowledge in fault data generation to detect possible faults.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}