
Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos



Abstract
1. Introduction
- We introduce a flexible and powerful framework containing a multi-channels CGANs (four streams with nine output channels in our case) to generate multi-type future appearance and motion information. Our architecture considers more consecutive frames forward translation from t to than previous methods with only encode-decode reconstruction [6] or translation from t to [4,5]. The number of channels can be freely inserted or removed for multiple purposes.
- We experimentally prove the effectiveness of PSNR in image comparison task. Based on PSNR method, a useful descriptor of output from our generative framework and ground-truth is proposed. The size of the descriptor is also flexible (equal to the number of channels) and small to adapt to fast classifiers.
- We demonstrate the improvement of anomaly detection by adding a supervised stage exploiting the feature extractor proposed by our unsupervised architecture. We add a SVM stage that we train on abnormal samples from the test dataset. We achieve at least competitive performances on all benchmarks: Avenue, Ped1, Ped2 in term of frame-level AUC, and a huge improvement on the most challenging datasets, such as Shanghaitech.
2. Related Work
2.1. Early Works with Hand-Crafted Features
2.2. Recent Successful Models with Deep Learning Features
3. Proposed Method
3.1. Multi-Channel pix2pix-CGAN Framework
- Encoder: CE64-CE128-CE256-CE512-CE512-CE512-CE512-CE512
- Decoder: CD512-CD512-CD512-CD512-CD512-CD256-CD128-CD64
- Discriminator: C64-C128-C256-C512
3.2. Feature Extraction with PSNR
3.3. Frame-Level Inference Model
3.4. Object-Centric Anomaly Localization Model
4. Experiments
4.1. Datasets and Evaluation Metric
4.2. Implementation Details
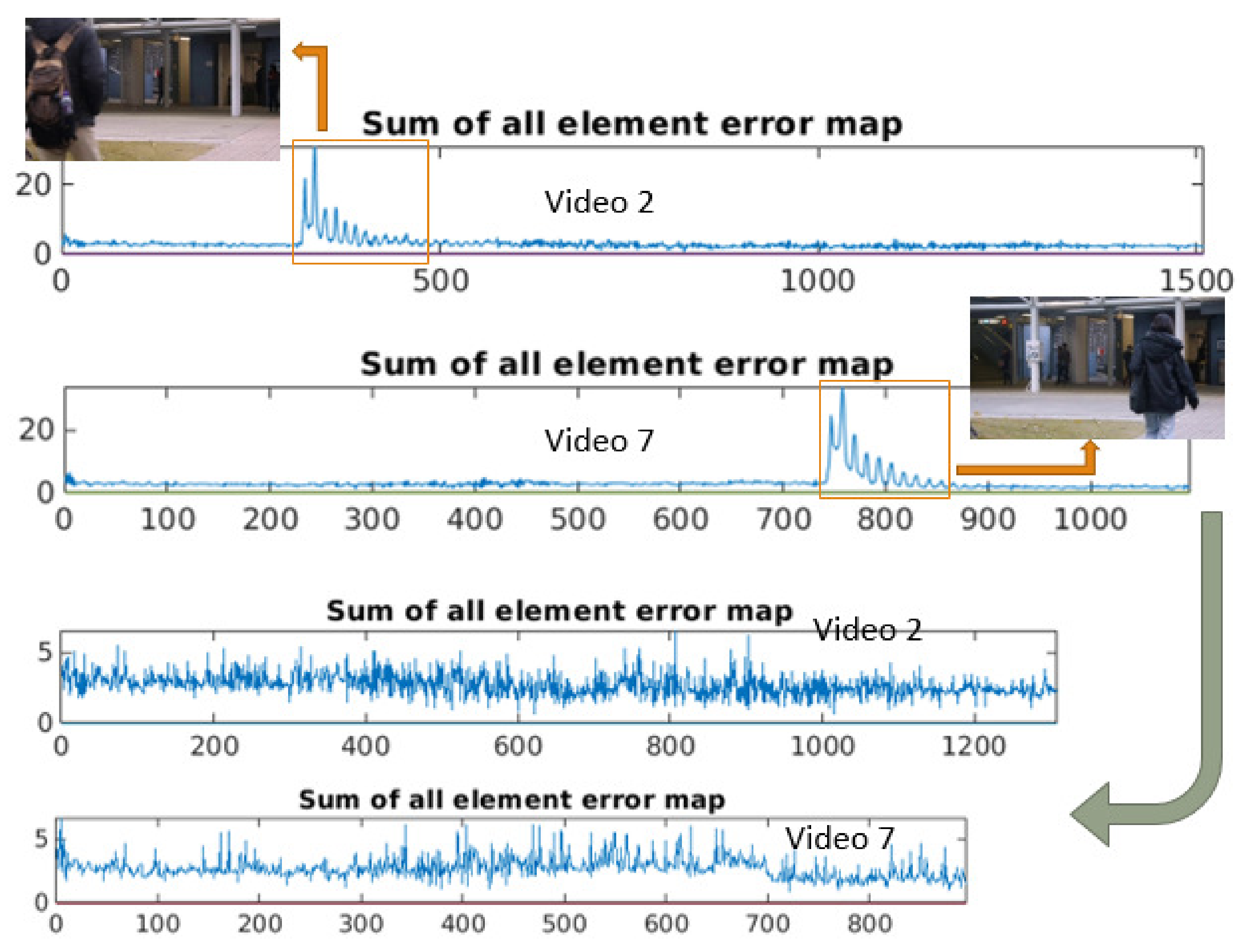
4.3. Results
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| CGAN | Conditional Generative Adversarial Network |
| SVM | Support Vector Machine |
| PSNR | Peak Signal-to-Noise Ratio |
| SHT | ShanghaiTech (dataset) |
References
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning Temporal Regularity in Video Sequences. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. Remembering history with convolutional LSTM for anomaly detection. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 439–444. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Smeureanu, S.; Alexe, B.; Popescu, M. Unmasking the Abnormal Events in Video. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2914–2922. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6536–6545. [Google Scholar]
- Nguyen, T.N.; Meunier, J. Anomaly Detection in Video Sequence with Appearance-Motion Correspondence. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ionescu, R.T.; Khan, F.; Georgescu, M.I.; Shao, L. Object-Centric Auto-Encoders and Dummy Anomalies for Abnormal Event Detection in Video. arXiv 2019, arXiv:1812.04960v2. [Google Scholar]
- Giorno, A.D.; Bagnell, J.A.; Hebert, M. A Discriminative Framework for Anomaly Detection in Large Videos. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar] [CrossRef]
- Lu, C.; Shi, J.; Jia, J. Abnormal Event Detection at 150 FPS in Matlab. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Medioni, G.; Cohen, I.; Bremond, F.; Hongeng, S.; Nevatia, R. Event detection and analysis from video streams. IEEE Trans. Pattern Anal. Machine Intell. 2001, 23, 873–889. [Google Scholar] [CrossRef]
- Zhang, T.; Lu, H.; Li, S.Z. Learning semantic scene models by object classification and trajectory clustering. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1940–1947. [Google Scholar]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Wang, T.; Snoussi, H. Histograms of Optical Flow Orientation for Visual Abnormal Events Detection. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; pp. 13–18. [Google Scholar] [CrossRef]
- Hinami, R.; Mei, T.; Satoh, S. Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3639–3647. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Vu, H.; Nguyen, T.; Le, T.; Luo, W.; Phung, D.Q. Robust Anomaly Detection in Videos Using Multilevel Representations. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Pinkney, J. Pix2pix, Matlab. Available online: https://www.mathworks.com/matlabcentral/fileexchange/74779-pix2pix (accessed on 2 May 2021).
- Chen, Q.; Koltun, V. Full Flow: Optical Flow Estimation By Global Optimization over Regular Grids. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4706–4714. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI ’81), Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Ouyang, Y.; Sanchez, V. Video Anomaly Detection by Estimating Likelihood of Representations. arXiv 2021, arXiv:2012.01468v1. [Google Scholar]
- Liu, W.; Luo, W.; Li, Z.; Zhao, P.; Gao, S. Margin Learning Embedded Prediction for Video Anomaly Detection with A Few Anomalies. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Vu, H.; Nguyen, T.; Travers, A.; Venkatesh, S.; Phung, D. Energy-based localized anomaly detection in video surveillance. In Advances in Knowledge Discovery and Data Mining; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; pp. 641–653. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Leyva, R.; Sanchez, V.; Li, C.T. The LV dataset: A realistic surveillance video dataset for abnormal event detection. In Proceedings of the 2017 5th International Workshop on Biometrics and Forensics (IWBF), Coventry, UK, 4–5 April 2017; pp. 1–6. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Input (I) | Output & Target | ||
|---|---|---|---|---|
| CGAN-1 | , | 2 | 2 | |
| CGAN-2 | , | 3 | , | 3 |
| CGAN-3 | 3 | 3 | ||
| CGAN-4 | , | 2 | 1 |
| CGAN Stream | MSE | PSNR |
|---|---|---|
| CGAN-1 | 0.72 | 0.82 |
| CGAN-2 | 0.69 | 0.81 |
| CGAN-3 | 0.73 | 0.79 |
| CGAN-4 | 0.62 | 0.67 |
| CGAN-(1 + 2 + 3 + 4) | 0.81 | 0.92 |
| CGAN Stream | Avenue | Ped1 | Ped2 | SHT |
|---|---|---|---|---|
| CGAN-1 | 0.82 | 0.75 | 0.89 | 0.68 |
| CGAN-2 | 0.81 | 0.78 | 0.92 | 0.78 |
| CGAN-3 | 0.79 | 0.64 | 0.75 | 0.73 |
| CGAN-4 | 0.67 | 0.65 | 0.77 | 0.62 |
| CGAN-(1 + 2) | 0.83 | 0.80 | 0.93 | 0.80 |
| CGAN-(3 + 4) | 0.86 | 0.70 | 0.77 | 0.81 |
| CGAN-(1 + 4) | 0.86 | 0.79 | 0.93 | 0.76 |
| CGAN-(1 + 2 + 3) | 0.86 | 0.83 | 0.95 | 0.87 |
| CGAN-(1 + 2 + 4) | 0.83 | 0.83 | 0.93 | 0.83 |
| CGAN-(1 + 2 + 3 + 4) | 0.92 | 0.85 | 0.96 | 0.94 |
| Methods | Avenue | Ped1 | Ped2 | SHT | |
|---|---|---|---|---|---|
| Unsupervised methods | |||||
| Luo et al. [2] | 0.77 | 0.88 | |||
| Nguyen et al. [5] | 0.87 | 0.96 | |||
| Hinami et al. [16] | 0.89 | 0.92 | |||
| Vu et al. [19] | 0.72 | 0.82 | 0.99 | ||
| Ouyang et al. [24] | 0.89 | 0.97 | 0.81 | ||
| Ionescu et al. [6] | 0.90 | 0.98 | 0.85 | ||
| Semi and supervised methods | |||||
| IVC with OS [25] | 0.83 | 0.56 | |||
| IVC with OS & FL [25] | 0.83 | 0.50 | |||
| IVC with OS & FL &2streams [25] | 0.81 | 0.50 | |||
| TripleLoss + OCSVM [25] | 0.80 | 0.50 | |||
| Hasan et al. [1] | 0.80 | 0.75 | 0.85 | 0.61 | |
| Luo et al. [11] | 0.82 | 0.92 | 0.68 | ||
| Ionescu et al. [3] | 0.81 | 0.68 | 0.82 | ||
| Liu et al. [4] | 0.85 | 0.83 | 0.95 | 0.73 | |
| Liu et al. [25] | 0.93 | 0.77 | |||
| Ours | 0.92 | 0.85 | 0.96 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vu, T.-H.; Boonaert, J.; Ambellouis, S.; Taleb-Ahmed, A. Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos. Sensors 2021, 21, 3179. https://doi.org/10.3390/s21093179
Vu T-H, Boonaert J, Ambellouis S, Taleb-Ahmed A. Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos. Sensors. 2021; 21(9):3179. https://doi.org/10.3390/s21093179
Chicago/Turabian StyleVu, Tuan-Hung, Jacques Boonaert, Sebastien Ambellouis, and Abdelmalik Taleb-Ahmed. 2021. "Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos" Sensors 21, no. 9: 3179. https://doi.org/10.3390/s21093179
APA StyleVu, T.-H., Boonaert, J., Ambellouis, S., & Taleb-Ahmed, A. (2021). Multi-Channel Generative Framework and Supervised Learning for Anomaly Detection in Surveillance Videos. Sensors, 21(9), 3179. https://doi.org/10.3390/s21093179