
Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition

Abstract
:1. Introduction
- We propose an AAM-GCN network to model dynamic skeletons for action recognition, which can construct the graph structure adaptively during the training process and explicitly explore the latent dependency among the joints.
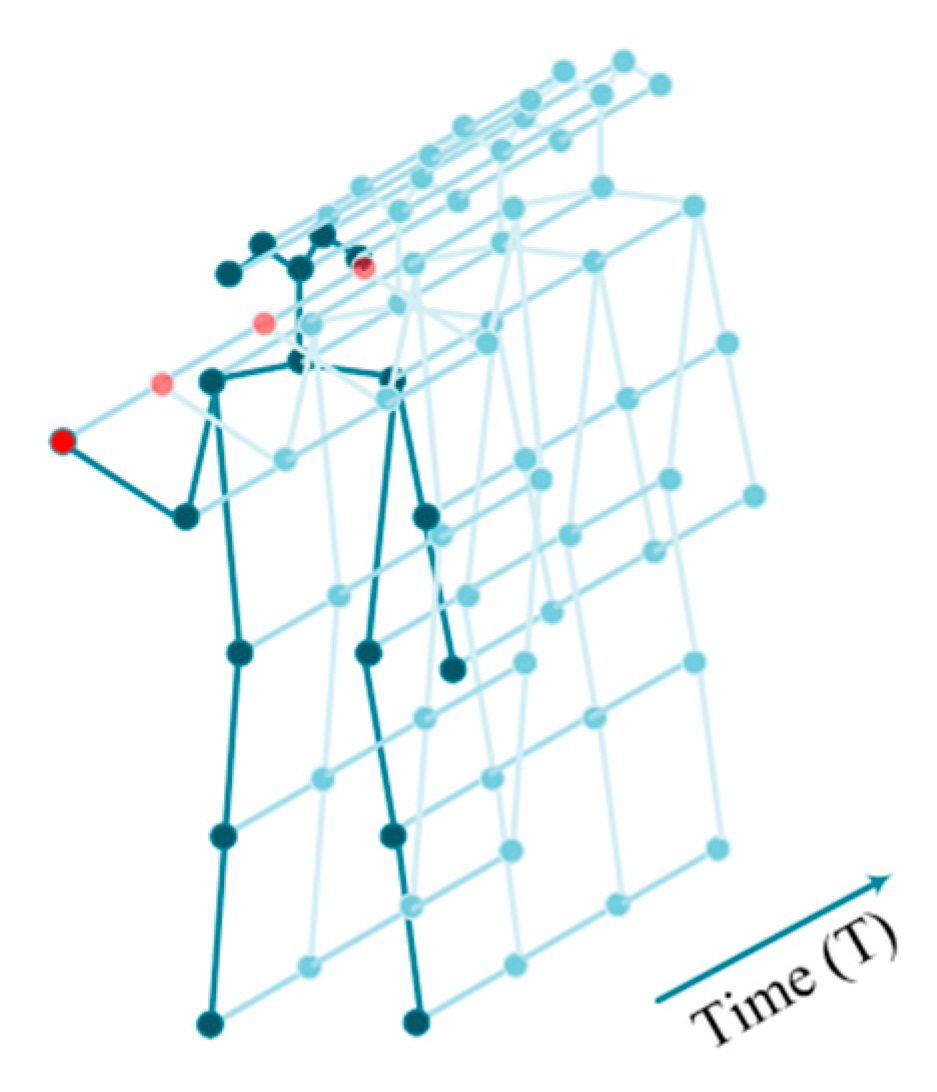
- By constructing an attention-enhanced memory, AAM-GCN can selectively focus on key frames and capture both long-range discriminative temporal features in the past and the future.
- We evaluate the proposed model on three large datasets: NTU RGB+D [28], Kinetics [29] and Motion Capture Dataset HDM05 [30]. It exhibits superior performance than some other state-of-the-art methods in both constrained and unconstrained environments. Furthermore, we conduct an ablation study to demonstrate the effectiveness of each individual part of our model.
2. Related Works
3. Graph Convolutional Networks
4. Adaptive Attention Memory Graph Convolutional Network
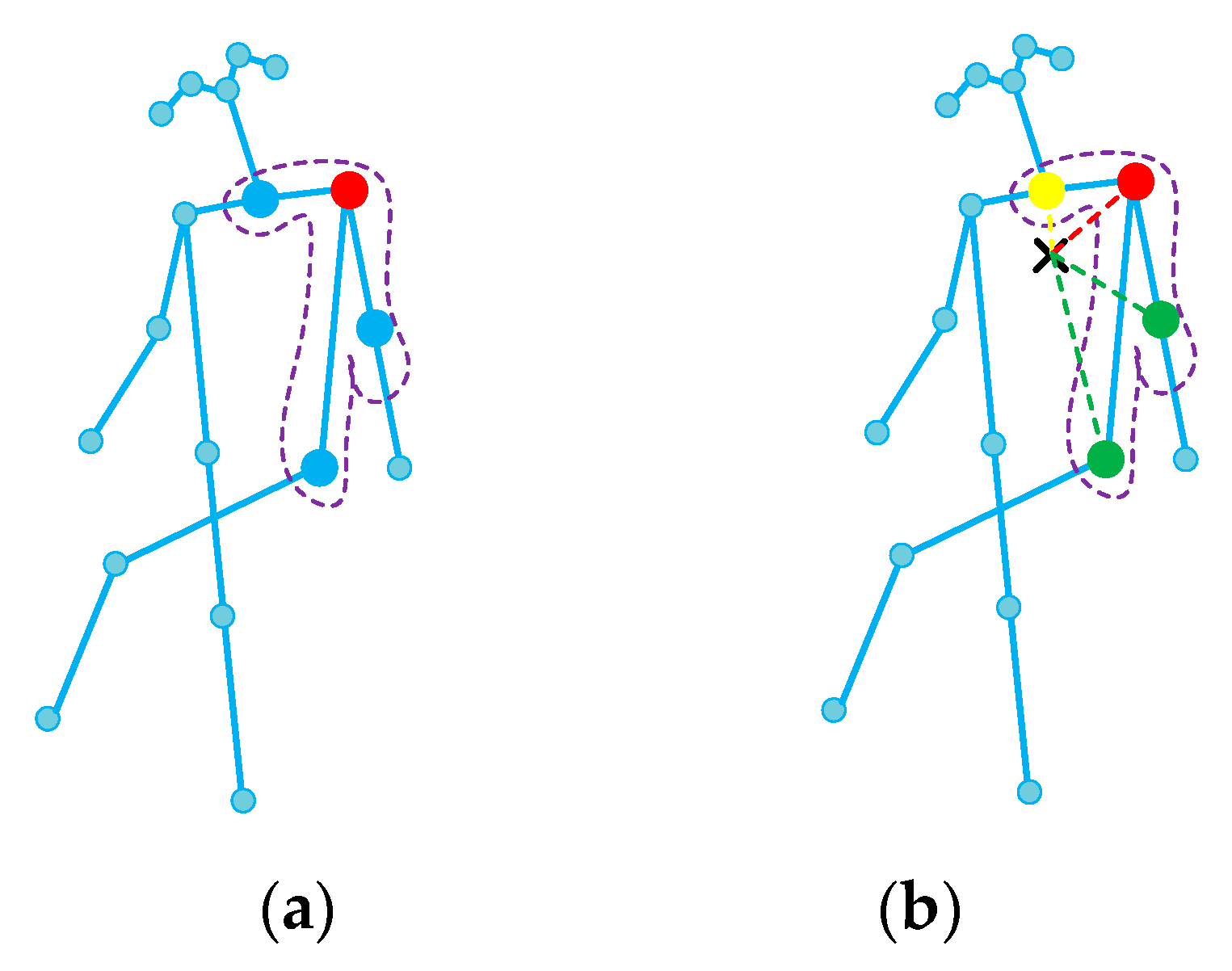
4.1. Adaptive Spatial Graph Convolution
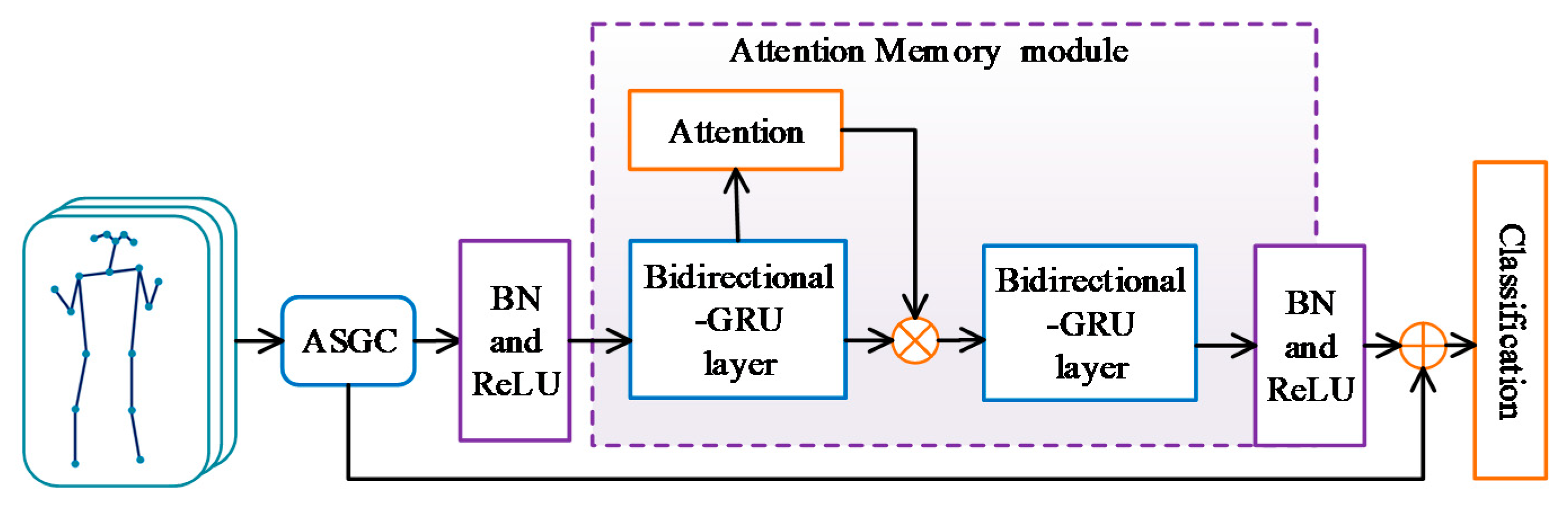
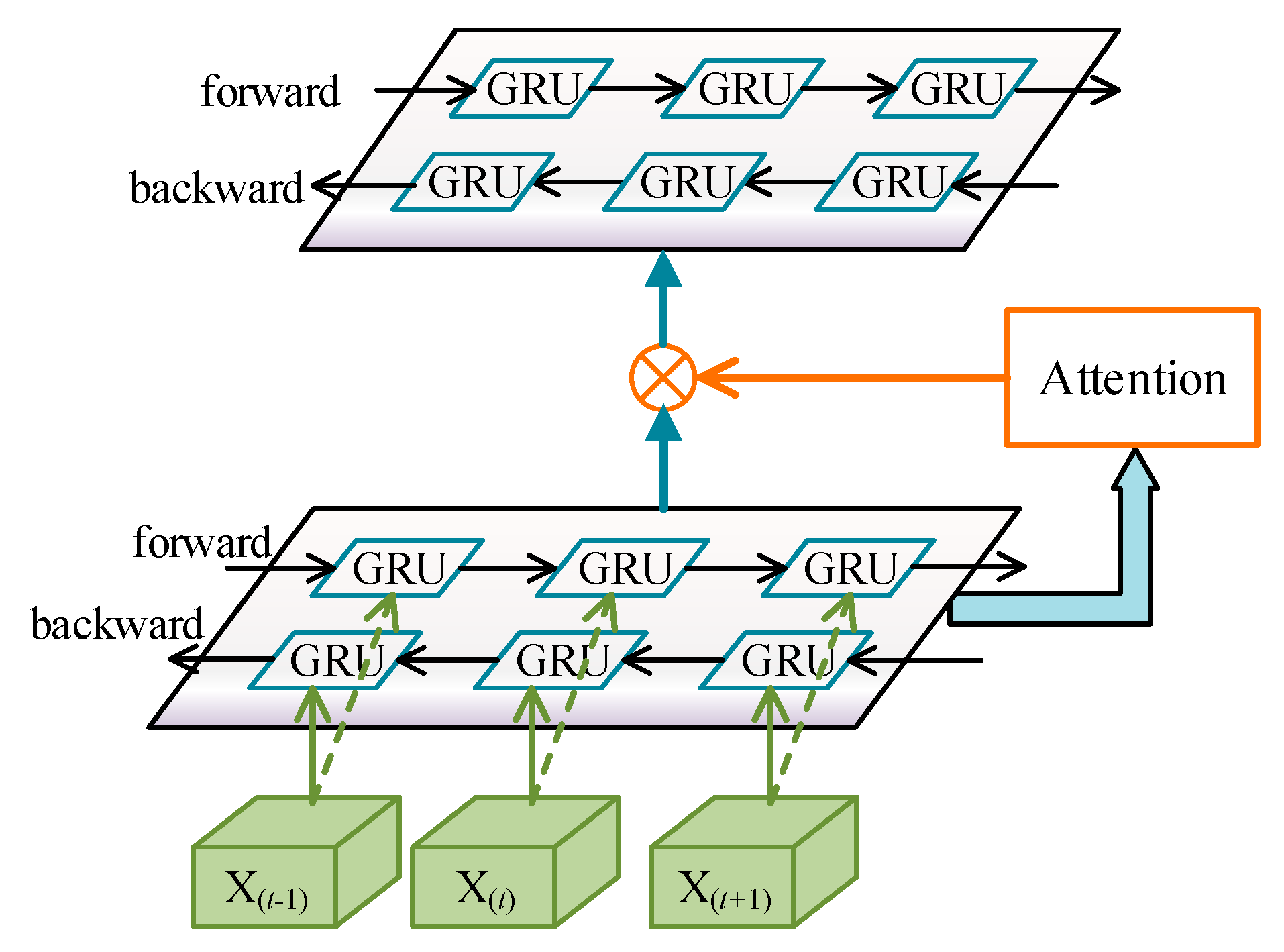
4.2. Attention Memory Module
4.3. Model Architecture and Training Detail
5. Experiments
5.1. Datasets
5.2. Comparisons with the State-of-the-Art

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Top-1 Acc (%) | Top-5 Acc (%) |
|---|---|---|
| Deep LSTM [28] | 16.40 | 35.30 |
| Temporal Conv [34] | 20.30 | 40.00 |
| ST-GCN [20] | 30.70 | 53.80 |
| ST-GGN [54] | 33.10 | 55.20 |
| AS-GCN [17] | 34.80 | 56.50 |
| AAM-GCN (DeepCut) | 33.24 | 55.58 |
| AAM-GCN (ours) | 33.12 | 55.65 |
5.3. Visualization of the Actions
5.4. Ablation Study
5.4.1. Effect of Adaptive Graph Structure
5.4.2. Effect of Attention Mechanism
5.4.3. Effect of Bidirectional Memory
5.4.4. Effect of ASGC Concatenation
5.4.5. Other Parameters Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, J.; Zhu, E.; Wang, S.; Liu, X.; Guo, X.; Yin, J. An Efficient and Robust Unsupervised Anomaly Detection Method Using Ensemble Random Projection in Surveillance Videos. Sensors 2019, 19, 4145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duric, Z.; Gray, W.D.; Heishman, R.; Li, F.; Rosenfeld, A.; Schoelles, M.J.; Schunn, C.; Wechsler, H. Integrating perceptual and cognitive modeling for adaptive and intelligent human-computer interaction. Proc. IEEE 2002, 90, 1272–1289. [Google Scholar] [CrossRef]
- Sudha, M.R.; Sriraghav, K.; Abisheck, S.S.; Jacob, S.G.; Manisha, S. Approaches and applications of virtual reality and gesture recognition: A review. Int. J. Ambient. Comput. Intell. 2017, 8, 1–18. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9912, pp. 20–36. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal LSTM with trust gates for 3D human action recognition. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 816–833. [Google Scholar]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time Representation of People based on 3D Skeletal Data: A Review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef] [Green Version]
- Presti, L.L.; La Cascia, M. 3D skeleton-based human action classification: A survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2017, arXiv:1611.08050. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. ICCV. 2017. Available online: https://github.com/MVIG-SJTU/AlphaPose (accessed on 23 March 2021).
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar]
- Xie, C.; Li, C.; Zhang, B.; Chen, C.; Han, J.; Zou, C.; Liu, J. Memory attention networks for skeleton-based action recognition. arXiv 2018, arXiv:1804.08254. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling Video Evolution for Action Recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1227–1236. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Svoboda, J.; Bronstein, M.M. Geometric Deep Learning on Graphs and Manifolds Using Mixture Model CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-temporal graph routing for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8561–8568. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7912–7921. [Google Scholar]
- Wen, Y.; Gao, L.; Fu, H.; Zhang, F.; Xia, S. Graph CNNs with motif and variable temporal block for skeleton-based action recognition. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8989–8996. [Google Scholar]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. Shallow Graph Convolutional Network for Skeleton-Based Action Recognition. Sensors 2021, 21, 452. [Google Scholar] [CrossRef] [PubMed]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Müller, M.; Röder, T.; Clausen, M.; Eberhardt, B.; Krüger, B.A. Weber: Documentation Mocap Database HDM05; Technical Report, No. CG-2007-2; Universität Bonn, June 2007; ISSN 1610-8892. Available online: http://resources.mpi-inf.mpg.de/HDM05/ (accessed on 7 October 2021).
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2405–2415. [Google Scholar] [CrossRef] [Green Version]
- Baradel, F.; Wolf, C.; Mille, J. Human Action Recognition: Pose-based Attention Draws Focus to Hands. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 604–613. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-Occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence IJCAI-18, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3D Human Action Analysis with Temporal Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 4570–4579. [Google Scholar]
- Li, W.; Wen, L.; Chang, M.C.; Lim, S.N.; Lyu, S. Adaptive RNN tree for large-scale human action recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1444–1452. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. arXiv 2016, arXiv:1611.06067. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition From Skeleton Data. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Cho, K.; Merrienboer, V.B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. Available online: https://arxiv.org/abs/1406.1078 (accessed on 1 August 2021).
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 143–152. [Google Scholar]
- Ye, F.; Pu, S.; Zhong, Q.; Li, C. Dynamic GCN: Context-enriched Topology Learning for Skeleton-based Action Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 55–63. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial Temporal Transformer Network for Skeleton-Based Action Recognition. In International Conference on Pattern Recognition; Springer: Cham, Switzerland, 2021; Volume 12663. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Yuan, C. Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Sharma, S.; Kiros, R.; Salakhutdinov, R. Action recognition using visual attention. arXiv 2015, arXiv:1511.04119. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4507–4515. [Google Scholar]
- Stollenga, M.F.; Masci, J.; Gomez, F.; Schmidhuber, J. Deep networks with internal selective attention through feedback connections. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Wang, Y.; Wang, S.; Tang, J.; O’Hare, N.; Chang, Y.; Li, B. Hierarchical Attention Network for Action Recognition in Videos. arXiv 2016, arXiv:1607.06416. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. MIT Press. 2016. Available online: http://www.deeplearningbook.org (accessed on 1 September 2021).
- Cho, K.; Chen, X. Classifying and Visualizing Motion Capture Sequences using Deep Neural Networks. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 122–130. [Google Scholar]
- Peng, W.; Shi, J.; Varanka, T.; Zhao, G. Rethinking the ST-GCNs for 3D skeleton-based human action recognition. Neurocomputing 2021, 454, 45–53. [Google Scholar] [CrossRef]
- Pishchulin, L.; Insafutdinov, E.; Tang, S. Deepcut: Joint Subset Partition and Labeling for Multi Person Pose Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Li, K.; Miao, Q.; Sheng, L. 3D Skeleton-Based Video Action Recognition by Graph Convolution Network. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 500–501. [Google Scholar]
- Jiang, X.; Xu, K.; Sun, T. Action Recognition Scheme Based on Skeleton Representation with DS-LSTM Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2129–2140. [Google Scholar] [CrossRef]



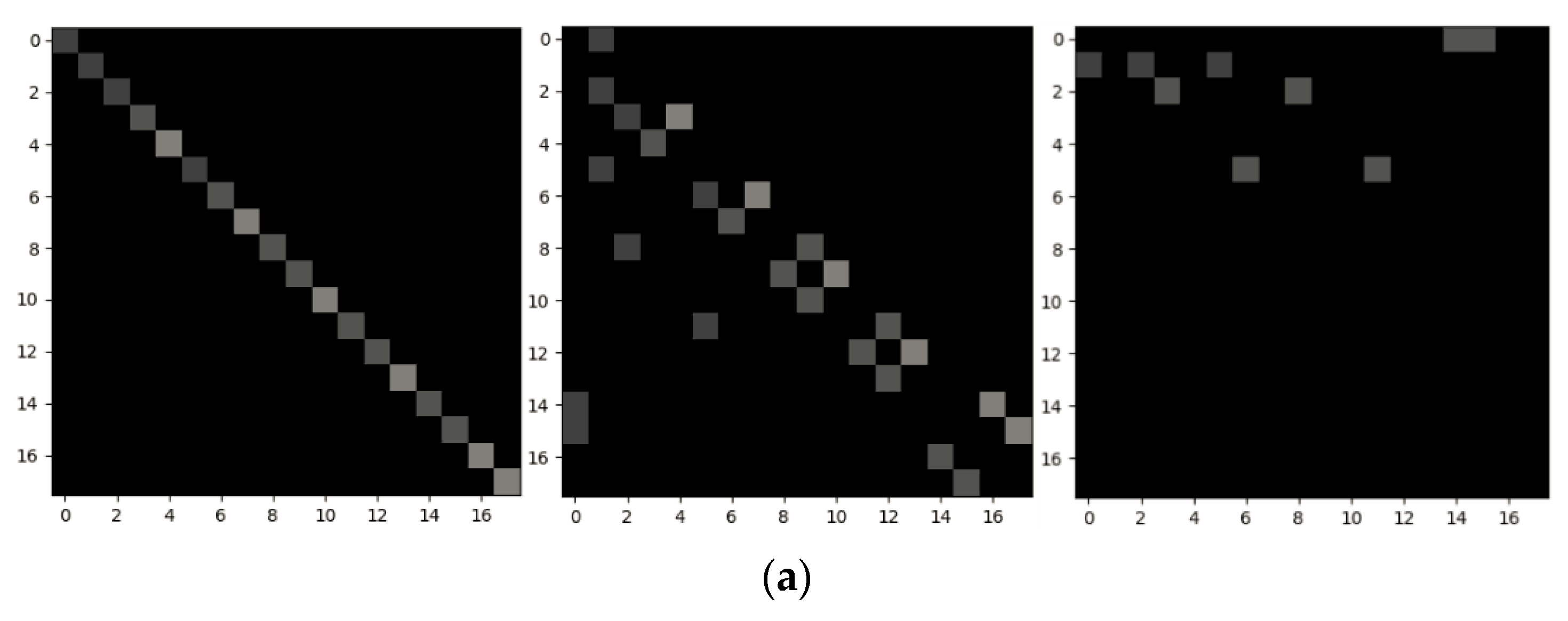
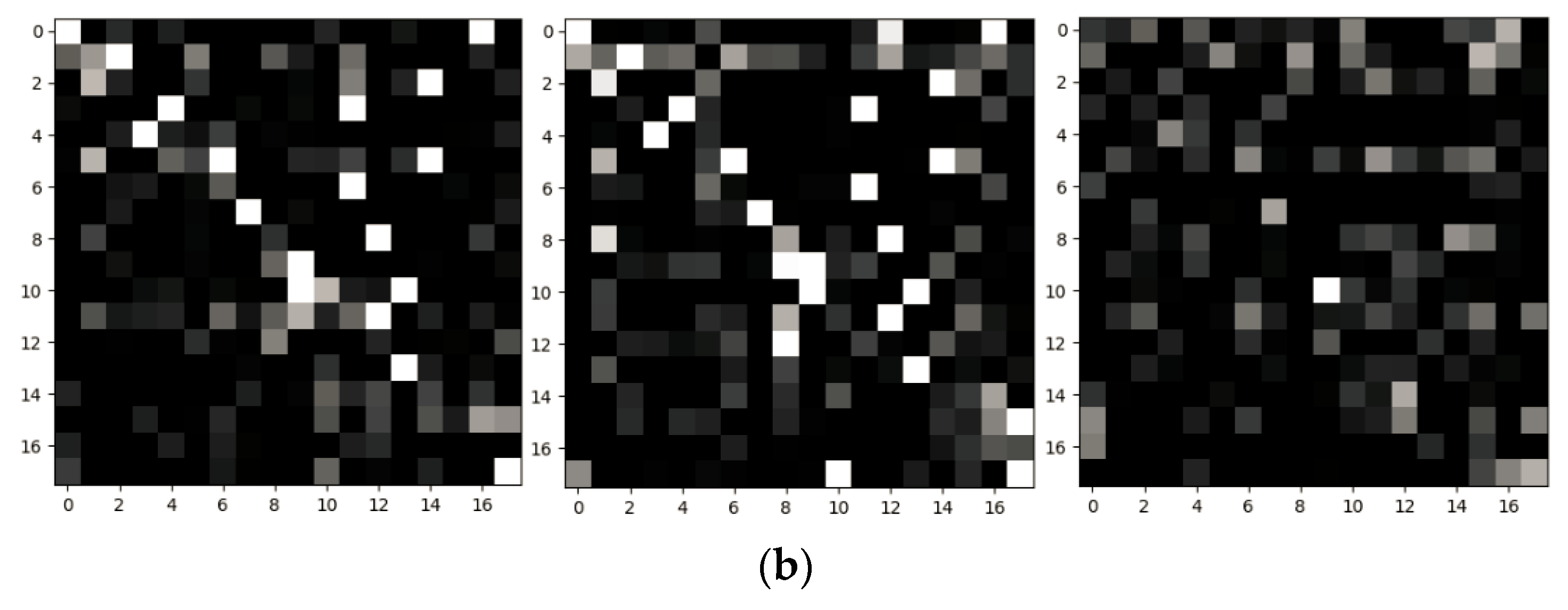

| Methods | Cross Subject (%) | Cross View (%) |
|---|---|---|
| ST-LSTM [6] | 69.20 | 77.70 |
| Two-stream RNN [15] | 71.30 | 79.50 |
| GCA-LSTM [12] | 74.40 | 82.80 |
| Visualization CNN [35] | 76.00 | 82.60 |
| VA-LSTM [39] | 79.40 | 87.60 |
| Clips+CNN+MTLN [36] | 79.57 | 84.83 |
| ST-GCN [20] | 81.50 | 88.30 |
| 3D-GCN [56] | 82.60 | 89.60 |
| DS-LSTM [57] | 77.80 | 87.33 |
| AAM-GCN (ours) | 82.73 | 90.12 |
| Methods | Acc (%) |
|---|---|
| Multi-layer Perceptron [53] | 95.59 |
| Hierarchical RNN [11] | 96.92 |
| ST-GCN [20] | 96.50 |
| Deep LSTM+Co-occurrence+In-depth Dropout [40] | 97.25 |
| AS-GCN [17] | 97.40 |
| AAM-GCN (ours) | 98.30 |
| Methods | Top-1 Acc (%) | Top-5 Acc (%) |
|---|---|---|
| ST-GCN [20] | 30.70 | 53.80 |
| AAM-GCN wo/adap | 31.53 | 53.82 |
| AAM-GCN wo/att | 32.11 | 53.64 |
| AAM-GCN wo/bidire | 32.27 | 54.50 |
| AAM-GCN wo/con | 31.81 | 54.17 |
| AAM-GCN (ours) | 33.12 | 55.65 |
| Methods | Cross Subject (%) | Cross View (%) |
|---|---|---|
| ST-GCN [20] | 81.50 | 88.30 |
| AAM-GCN wo/adap | 82.09 | 89.32 |
| AAM-GCN wo/att | 81.72 | 88.75 |
| AAM-GCN wo/bidire | 81.85 | 89.03 |
| AAM-GCN wo/con | 82.34 | 89.65 |
| AAM-GCN (ours) | 82.73 | 90.12 |
| Number of Bidirectional GRU Layers | Cross Subject (%) | Cross View (%) |
|---|---|---|
| 1 | 81.85 | 89.43 |
| 2 | 82.73 | 90.12 |
| 3 | 82.52 | 90.03 |
| Number of Hidden Neurons | Top-1 Acc (%) | Top-5 Acc (%) | |
|---|---|---|---|
| 1st Layer | 2nd Layer | ||
| 256 | 128 | 32.70 | 54.30 |
| 128 | 64 | 33.12 | 55.65 |
| 64 | 32 | 31.67 | 54.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Xu, H.; Wang, J.; Lu, Y.; Kong, J.; Qi, M. Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition. Sensors 2021, 21, 6761. https://doi.org/10.3390/s21206761
Liu D, Xu H, Wang J, Lu Y, Kong J, Qi M. Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition. Sensors. 2021; 21(20):6761. https://doi.org/10.3390/s21206761
Chicago/Turabian StyleLiu, Di, Hui Xu, Jianzhong Wang, Yinghua Lu, Jun Kong, and Miao Qi. 2021. "Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition" Sensors 21, no. 20: 6761. https://doi.org/10.3390/s21206761
APA StyleLiu, D., Xu, H., Wang, J., Lu, Y., Kong, J., & Qi, M. (2021). Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition. Sensors, 21(20), 6761. https://doi.org/10.3390/s21206761