
Road Extraction from High Resolution Remote Sensing Images Based on Vector Field Learning



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Methods
2.2.1. Data Augmentation
- rotation, rotating the image randomly 90°, 180°, 270°;
- mirror, including horizontal mirror and vertical mirror;
- random color augmentation, such as changing the image pixel value, adjusting brightness, saturation and so on.
2.2.2. Vectors Field for Road Extraction
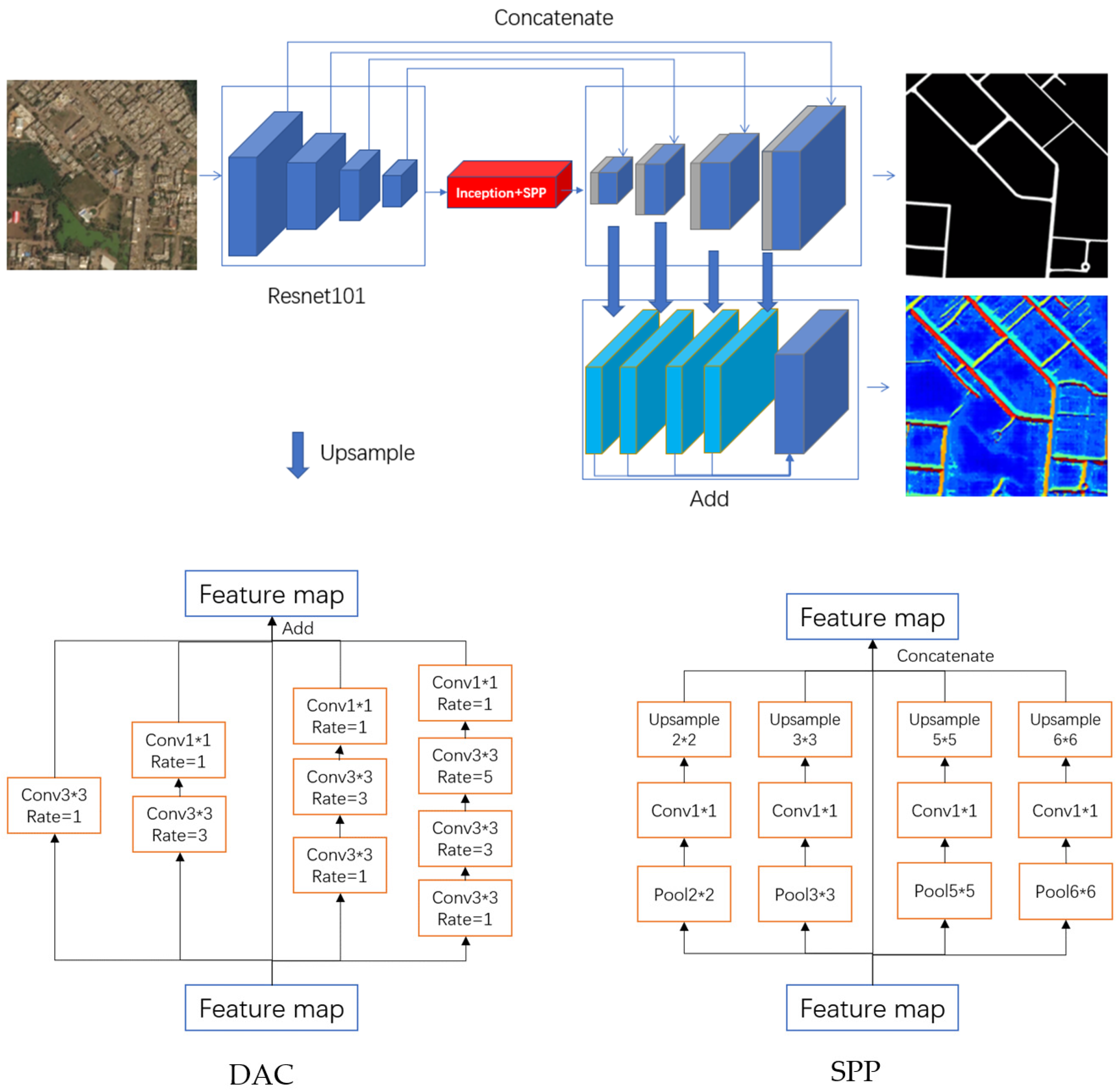
2.2.3. Network
2.2.4. Training
2.2.5. Post-Processing
3. Results and Discussion
3.1. Road Extraction Using Mask Learning Only
3.2. Road Extraction Using Mask and CVF Learning
3.3. Road Extraction Using Mask and RVF Learning
3.4. Road Extraction Using Mask and BVF Learning
3.5. Further Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jin, X.; Davis, C.H. An integrated system for automatic road mapping from high-resolution multi-spectral satellite imagery by information fusion. Inf. Fusion 2005, 6, 257–273. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Fully convolutional neural networks for remote sensing image classification. In Proceedings of the IEEE Geoscience & Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A fully convolutional neural network for road extraction in RGB imagery acquired by remote sensing from an unmanned aerial vehicle. J. Appl. Remote Sens. 2018, 12, 016020. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Constantin, A.; Ding, J.J.; Lee, Y.C. Accurate road detection from satellite images using modified U-net. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 26–30 October 2018; 2019. [Google Scholar]
- Sun, T.; Chen, Z.; Yang, W.; Wang, Y. Stacked U-nets with multi-output for road extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2017, 15, 749–753. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road extraction of high-resolution remote sensing images derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef]
- Doshi, J. Residual inception skip network for binary segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A road extraction network based on global perception of high-order spatial information. ISPRS Int. J. Geo. Inf. 2019, 8, 571. [Google Scholar] [CrossRef]
- Buslaev, A.V.; Seferbekov, S.S.; Iglovikov, V.I.; Shvets, A. Fully convolutional network for automatic road extraction from satellite imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-Scale and multi-task deep learning framework for automatic road extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Li, Y.; Peng, B.; He, L.; Fan, K.; Li, Z.; Tong, L. Road extraction from unmanned aerial vehicle remote sensing images based on improved neural networks. Sensors 2019, 19, 4115. [Google Scholar] [CrossRef] [PubMed]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic Segmentation using Adversarial Networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Costea, D.; Marcu, A.; Slusanschi, E.; Leordeanu, M. Creating roadmaps in aerial images with generative adversarial networks and smoothing-based optimization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2100–2109. [Google Scholar]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A convolution neural network for road extraction using RGB images captured by UAV. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI’18), Bangalore, India, 18–21 November 2018. [Google Scholar]
- Zhang, Y.; Xiong, Z.; Zang, Y.; Wang, C.; Li, J.; Li, X. Topology-Aware road network extraction via multi-supervised generative adversarial networks. Remote Sens. 2019, 11, 1017. [Google Scholar] [CrossRef]
- Costea, D.; Marcu, A.; Slusanschi, E.; Leordeanu, M. Roadmap generation using a multi-stage ensemble of deep neural networks with smoothing-based optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 220–224. [Google Scholar]
- Filin, O.; Zapara, A.; Panchenko, S. Road detection with EOSResUNet and post vectorizing algorithm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Han, C.; Li, G.; Ding, Y.; Yan, F.; Bai, L. Chimney detection based on faster R-CNN and spatial analysis methods in high resolution remote sensing images. Sensors 2020, 20, 4353. [Google Scholar] [CrossRef] [PubMed]
- Bai, M.; Urtasun, R. Deep watershed transform for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2858–2866. [Google Scholar]
- Wang, Y.; Xu, Y.; Tsogkas, S.; Bai, X.; Dickinson, S.; Siddiqi, K. DeepFlux for skeletons in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. TextField: Learning a deep direction field for irregular scene text detection. IEEE Trans. Image Process. 2019, 28, 5566–5579. [Google Scholar] [CrossRef] [PubMed]
- Wan, J.; Liu, Y.; Wei, D.; Bai, X.; Xu, Y. Super-BPD: Super boundary-to-pixel direction for fast image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 10377–10385. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Mask Learning_512 | 0.6942 | 0.7076 | 0.6704 |
| Mask Learning _1024 | 0.7584 | 0.7332 | 0.7089 |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Mask and CVF Learning | 0.7314 | 0.8201 | 0.7575 |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Mask and RVF Learning | 0.7315 | 0.8258 | 0.7618 |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Mask and BVF Learning | 0.7437 | 0.8060 | 0.7588 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, P.; Shi, W.; Ding, Y.; Liu, Z.; Shang, H. Road Extraction from High Resolution Remote Sensing Images Based on Vector Field Learning. Sensors 2021, 21, 3152. https://doi.org/10.3390/s21093152
Liang P, Shi W, Ding Y, Liu Z, Shang H. Road Extraction from High Resolution Remote Sensing Images Based on Vector Field Learning. Sensors. 2021; 21(9):3152. https://doi.org/10.3390/s21093152
Chicago/Turabian StyleLiang, Peng, Wenzhong Shi, Yixing Ding, Zhiqiang Liu, and Haolv Shang. 2021. "Road Extraction from High Resolution Remote Sensing Images Based on Vector Field Learning" Sensors 21, no. 9: 3152. https://doi.org/10.3390/s21093152
APA StyleLiang, P., Shi, W., Ding, Y., Liu, Z., & Shang, H. (2021). Road Extraction from High Resolution Remote Sensing Images Based on Vector Field Learning. Sensors, 21(9), 3152. https://doi.org/10.3390/s21093152