
A Semi-Supervised Transfer Learning with Grid Segmentation for Outdoor Localization over LoRaWans †




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
2.1. Localization Results
2.2. Motivation
3. Preliminaries
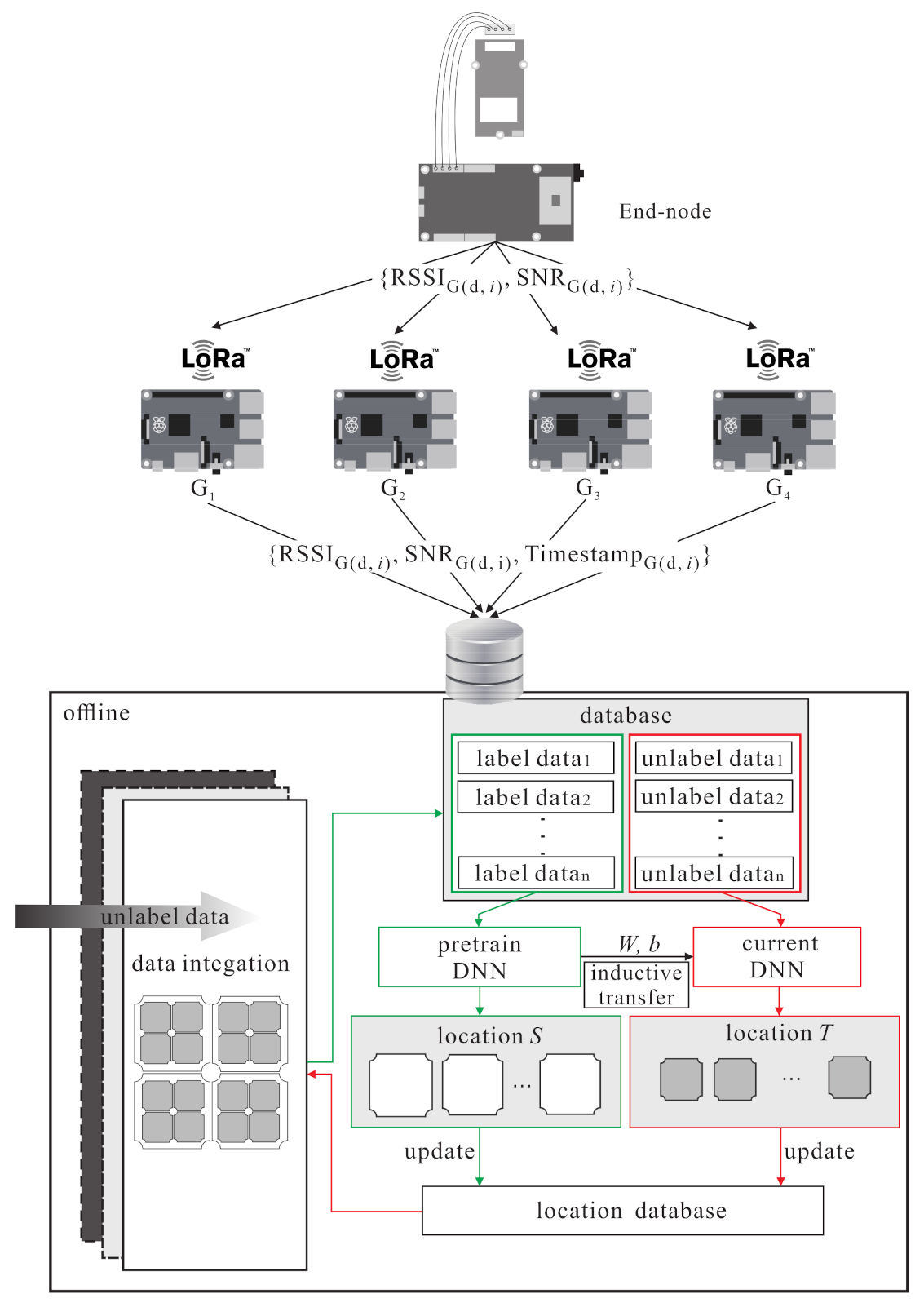
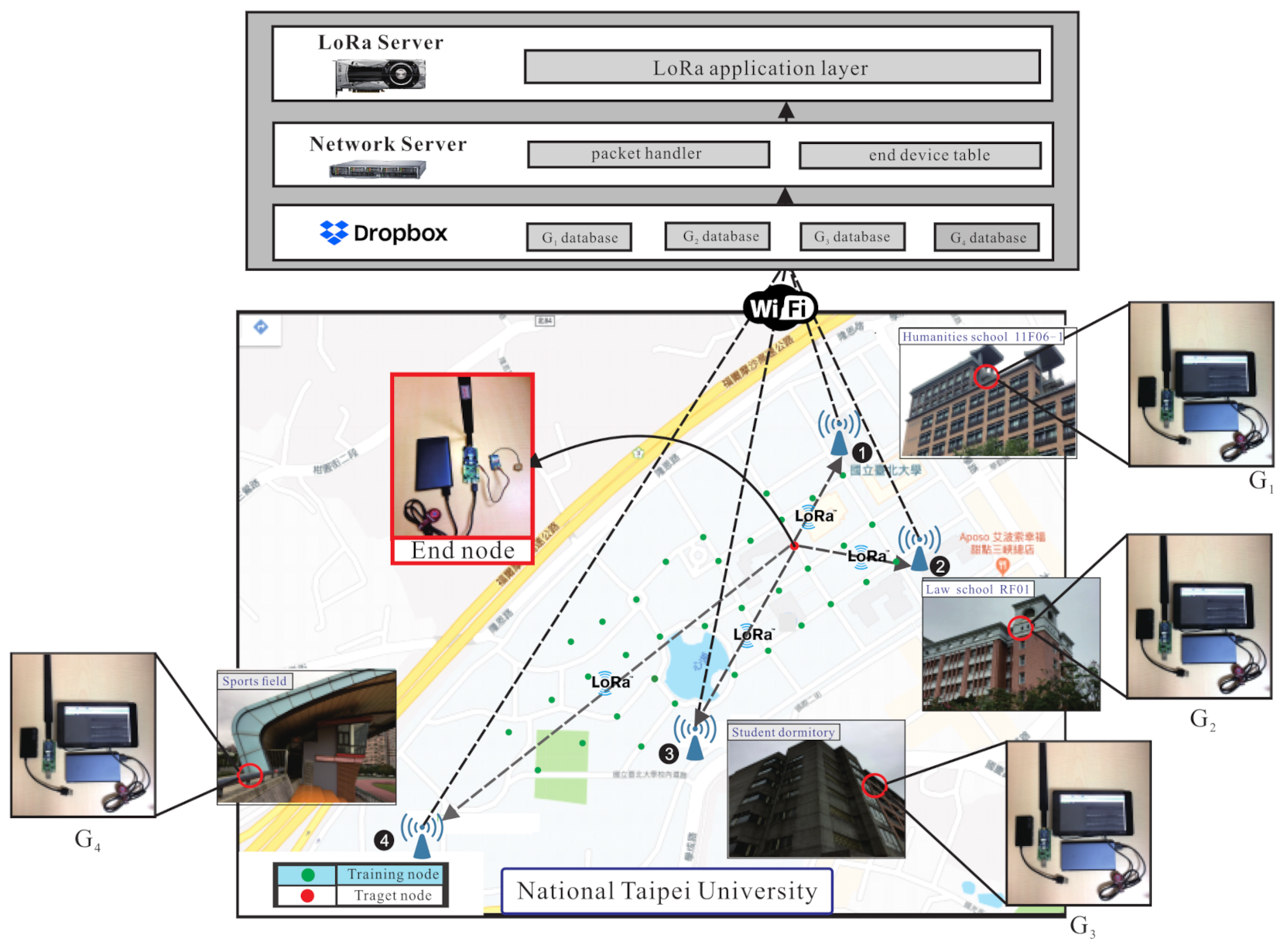
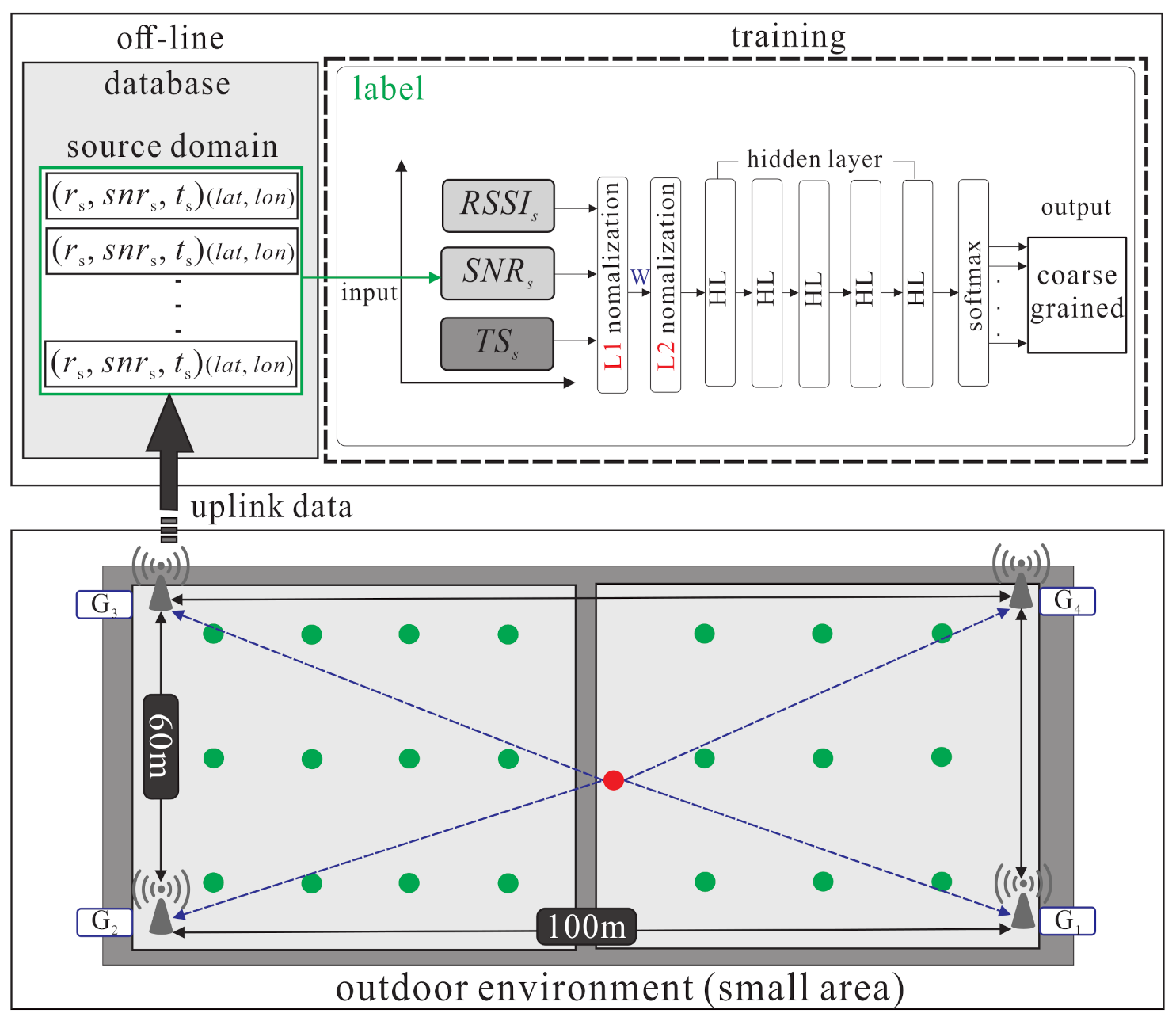
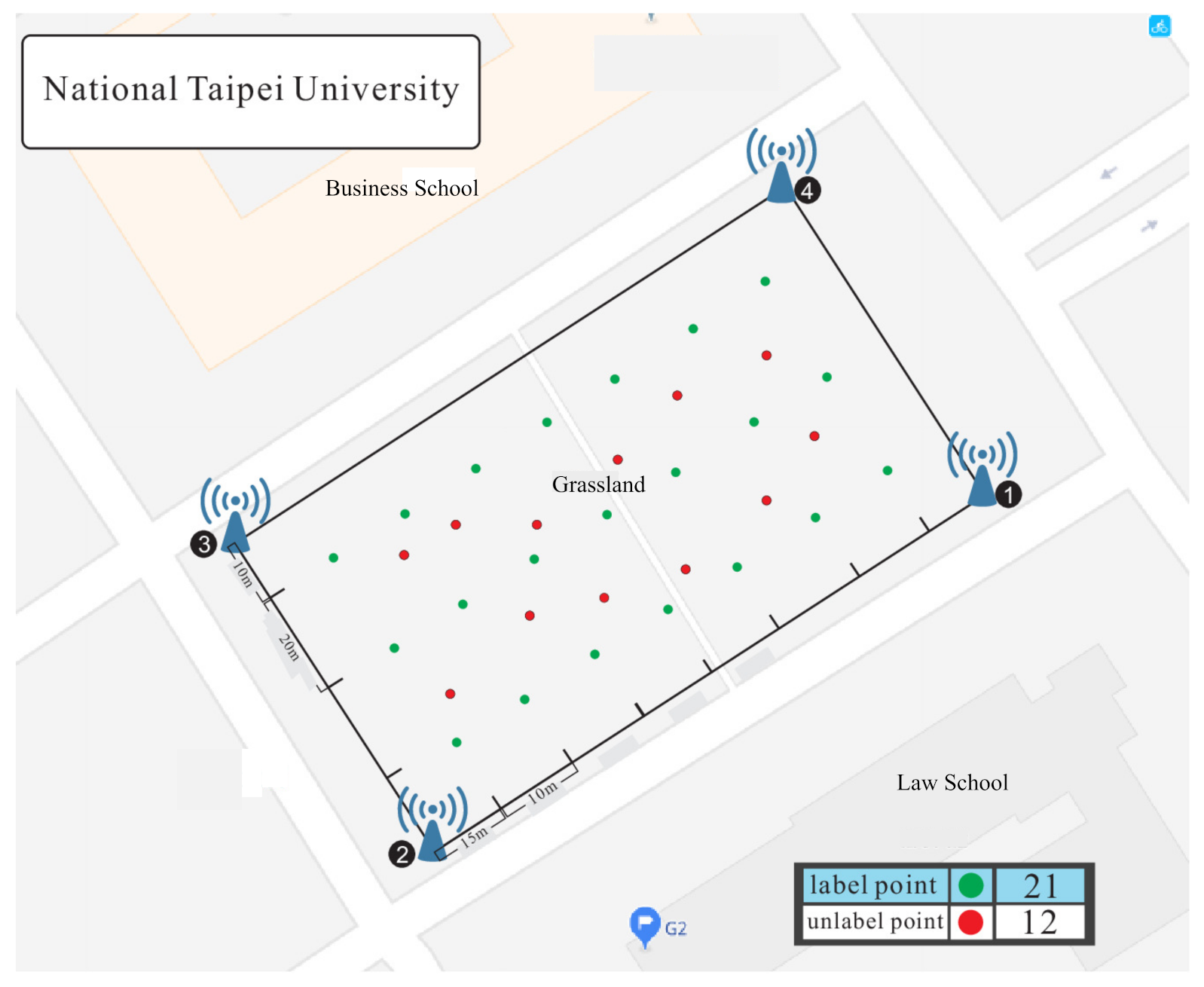
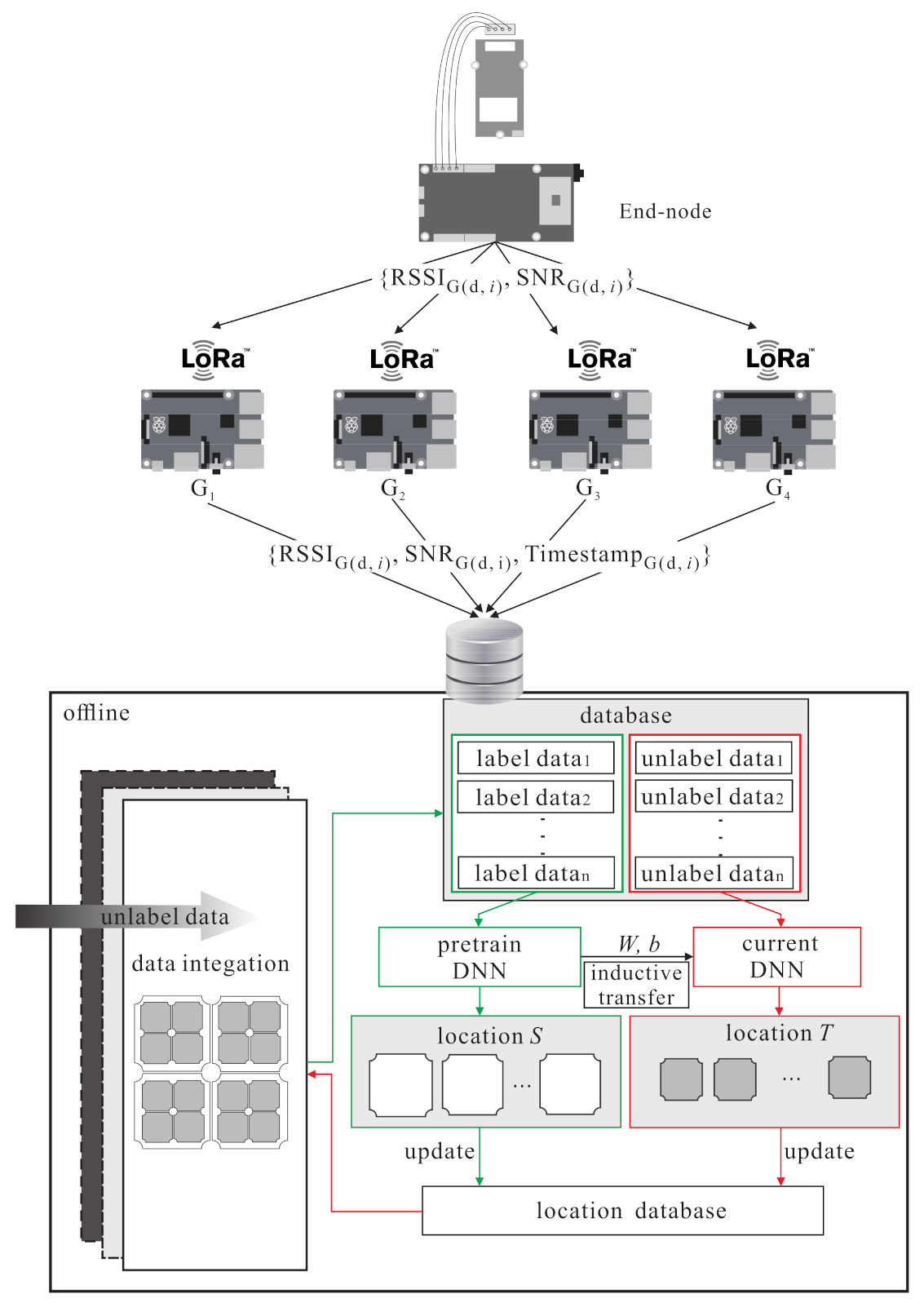
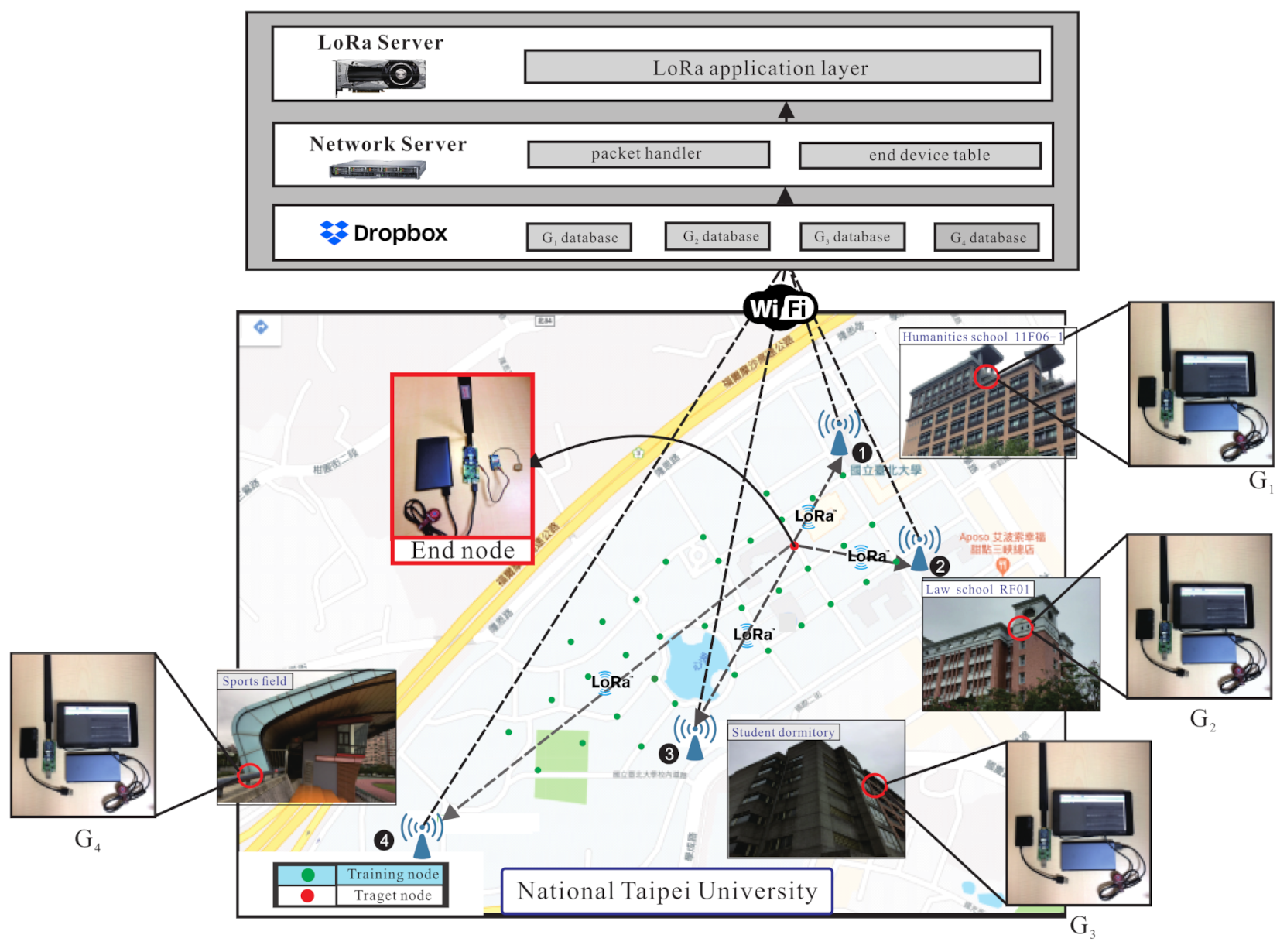
3.1. System Model
3.2. Problem Formulation
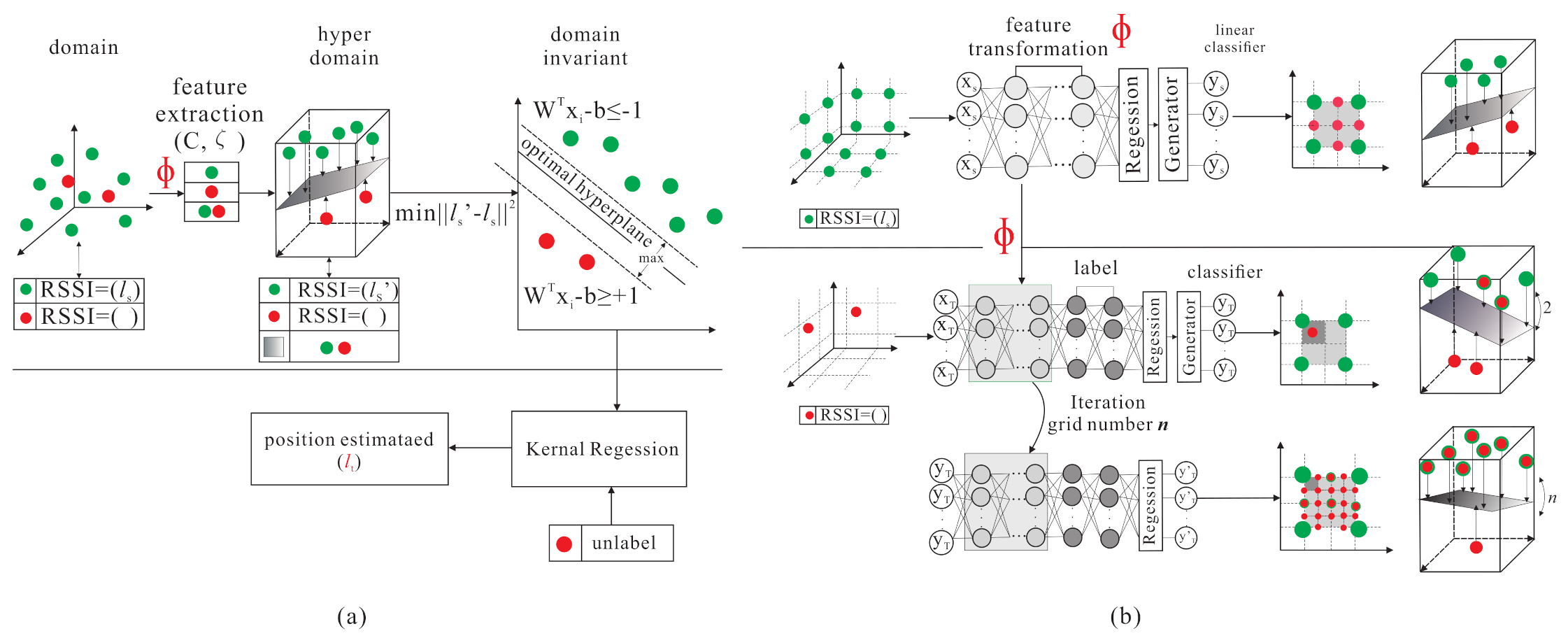
3.3. Basic Idea
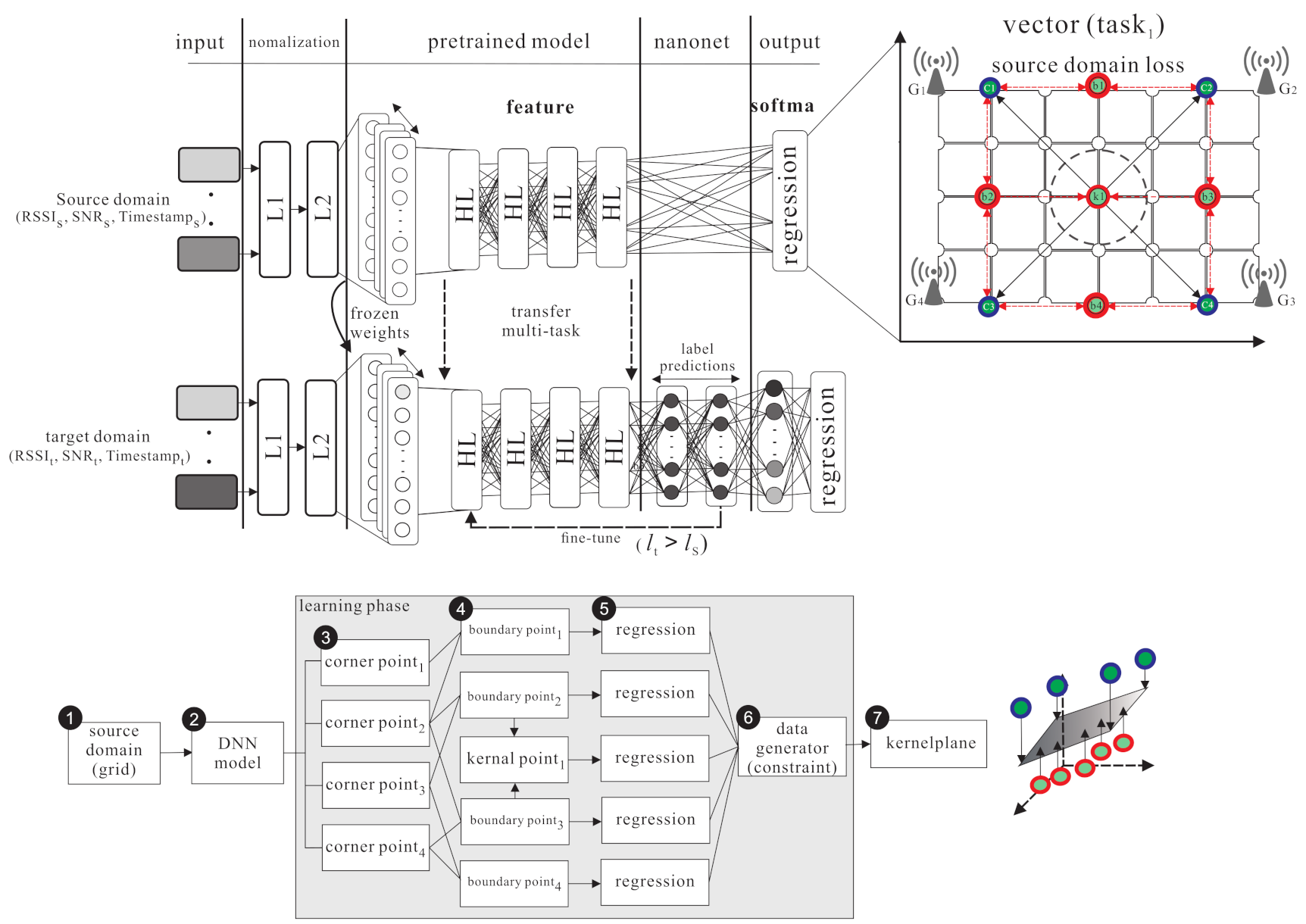
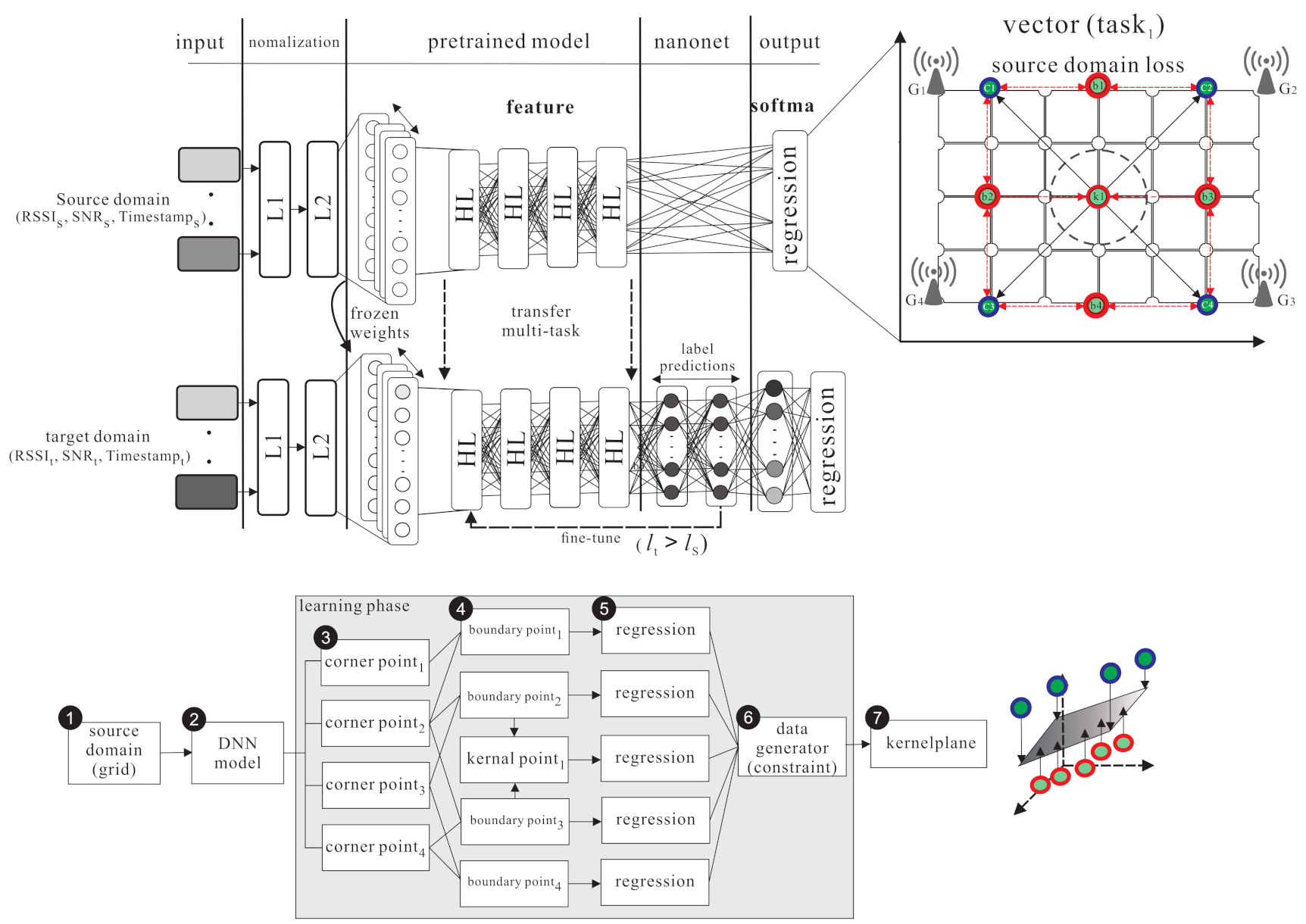
4. The Proposed Outdoor Localization Scheme Using Semi-Supervised Transfer Learning with Grid Segmentation
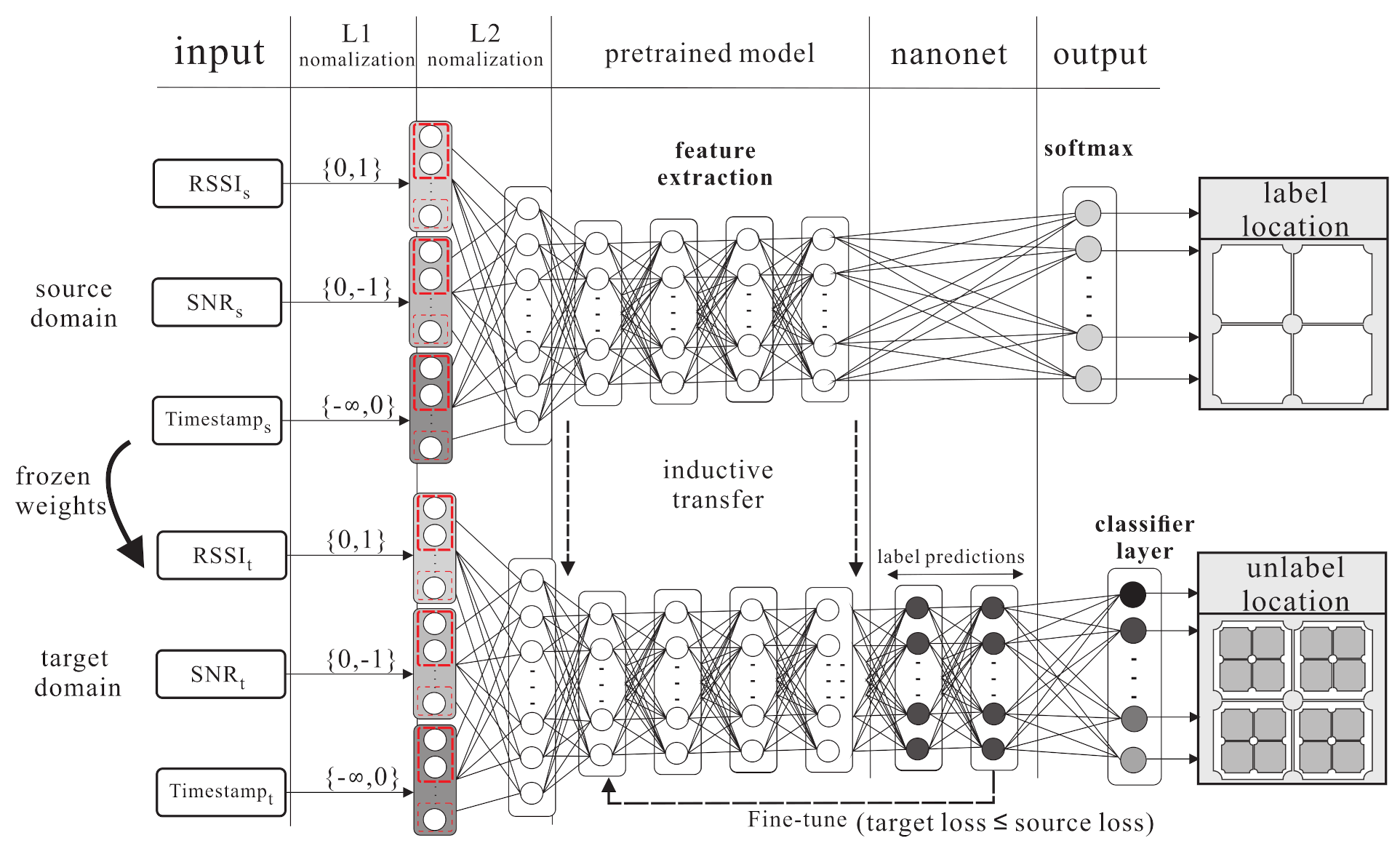
4.1. Source Domain Kernel Pre-Training Phase
- S1.
- The end-node transmits the sample to the gateways, then the gateways uplink the dataset to the database of the server. is shown in Equation (7):
- S2.
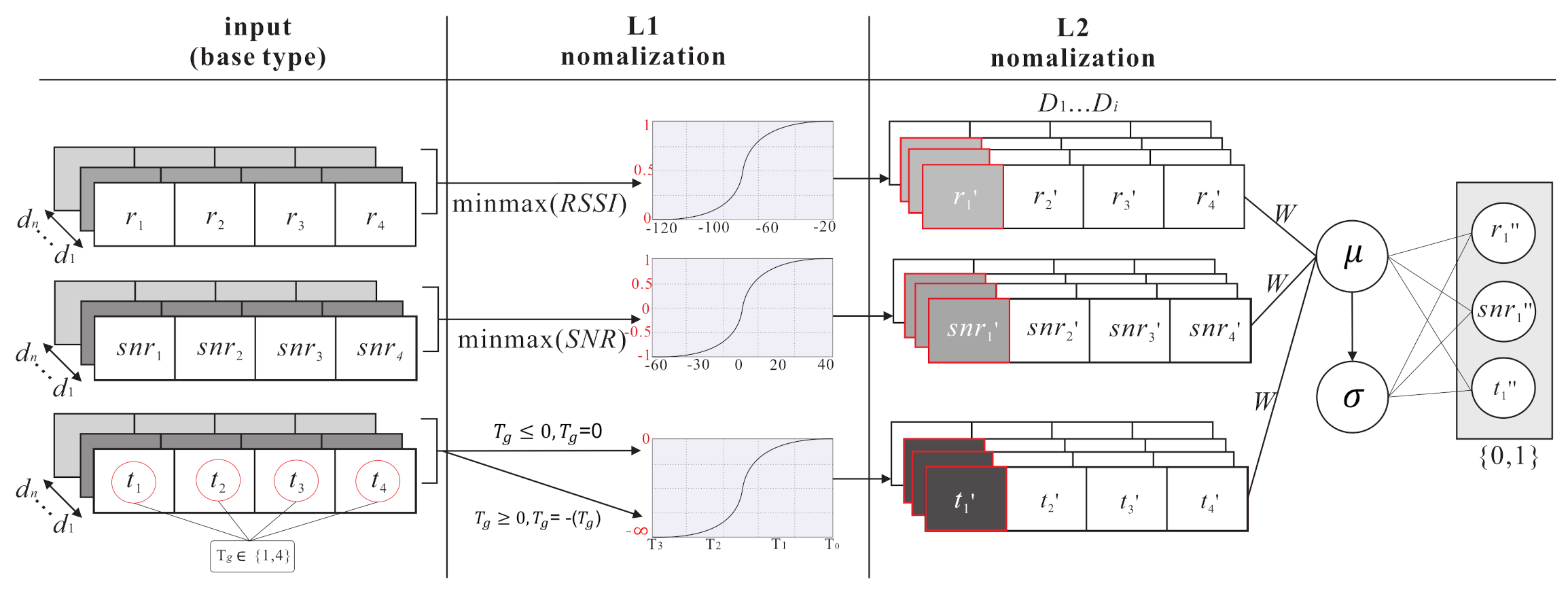
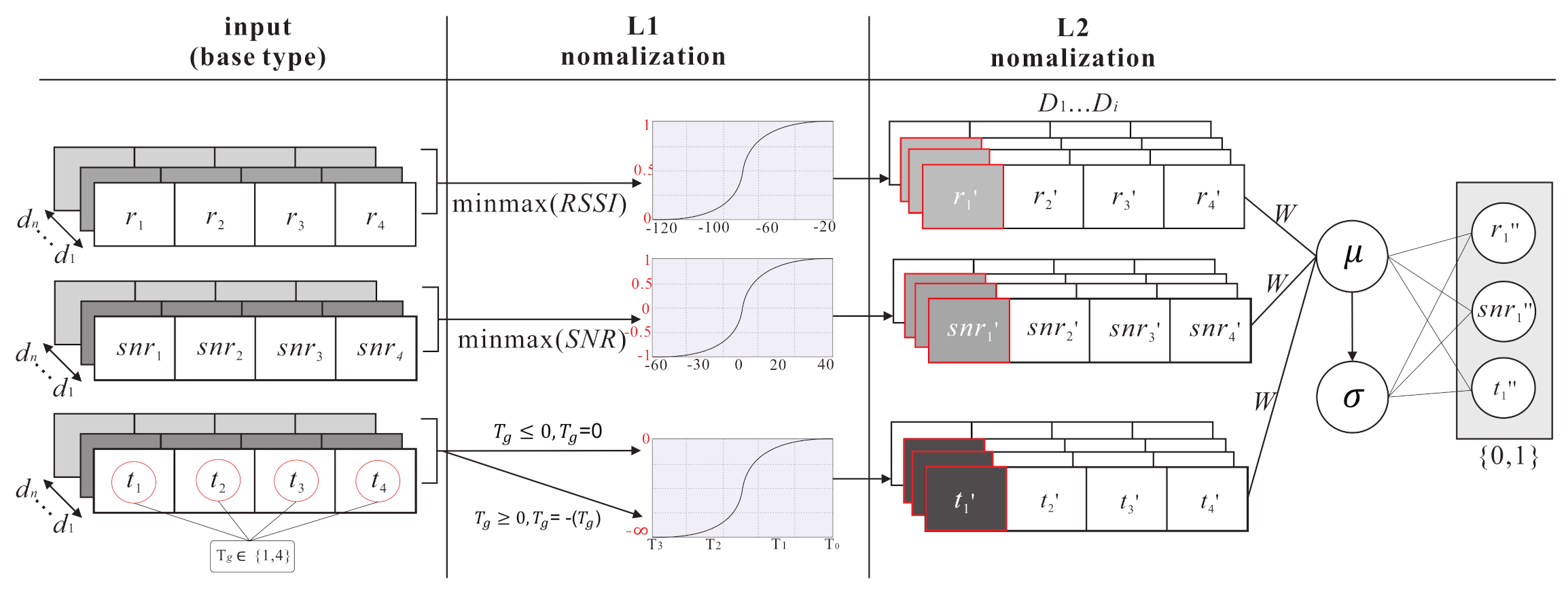
- During the normalization layers (i.e., L1 and L2 , L1 focuses on extracting the feature range of individual parameter and uses a minmaxscaler function to reduce the error between each parameters, where . The L1 normalization function is shown as follows:Then, the labelled samples are fed into L2 . L2 focuses on extracting the feature range of all the parameters. The batch normalization function [25] has mini-batch data processing and considers the average means and standard deviation of all parameters so as to normalize the feature range, where . The L2 normalization function is shown as follows:
- S3.
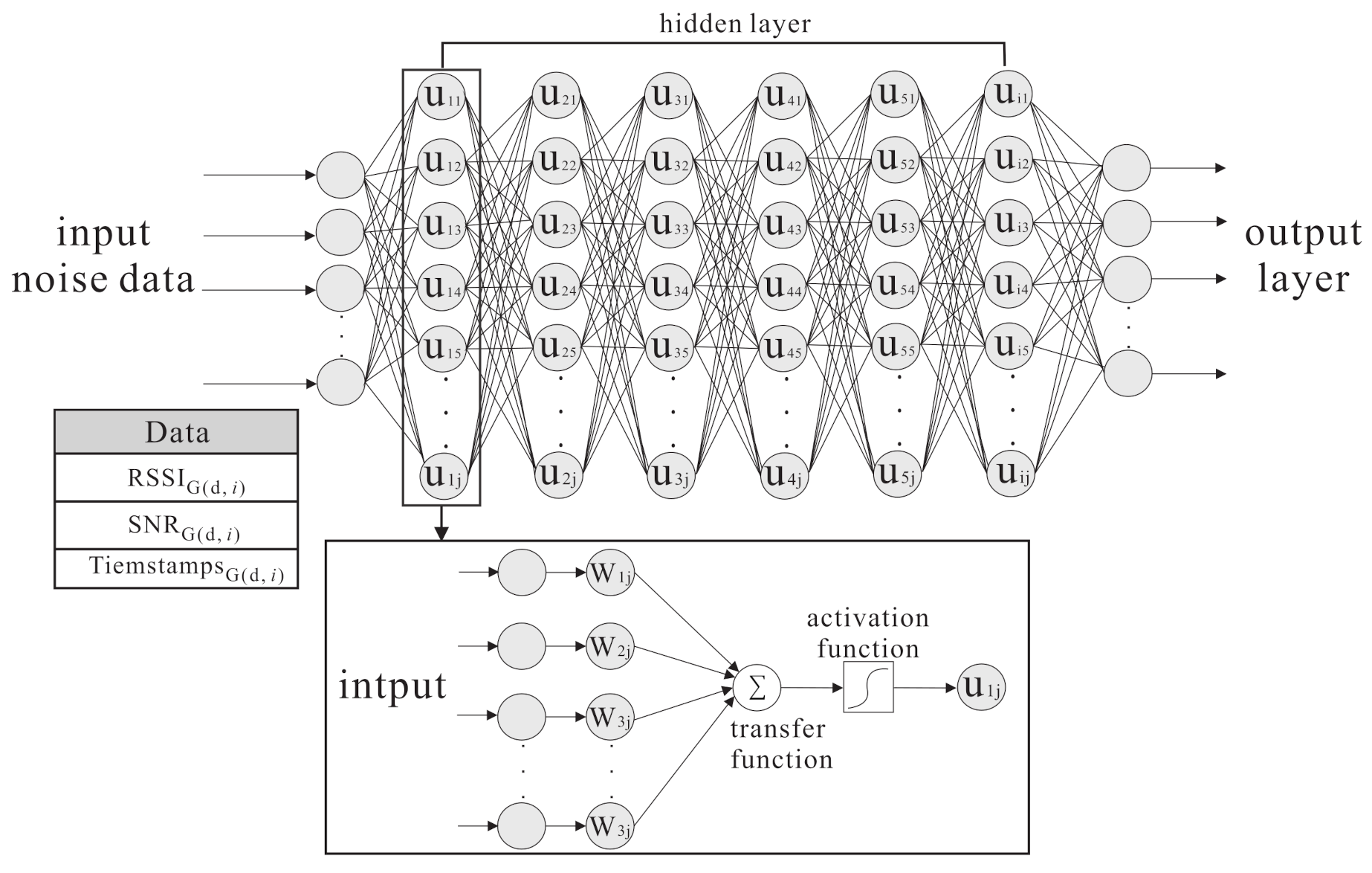
- This step puts the normalized into the DNN architecture, and uses m hidden layers () and l encoder layers and l decoder layers to extract feature and each class regression kernel. The equations are shown as follows:In the pre-train model, the labelled samples and input data are got from the gateways, including .
- S4.
- After going through the supervised DNN model, the output class is obtained, then the difference between the real class and the output class is calculated. The back propagation (BP) algorithm is used to update neurons in each hidden layer with both and , to minimize the difference between and . The equation is shown as follows:
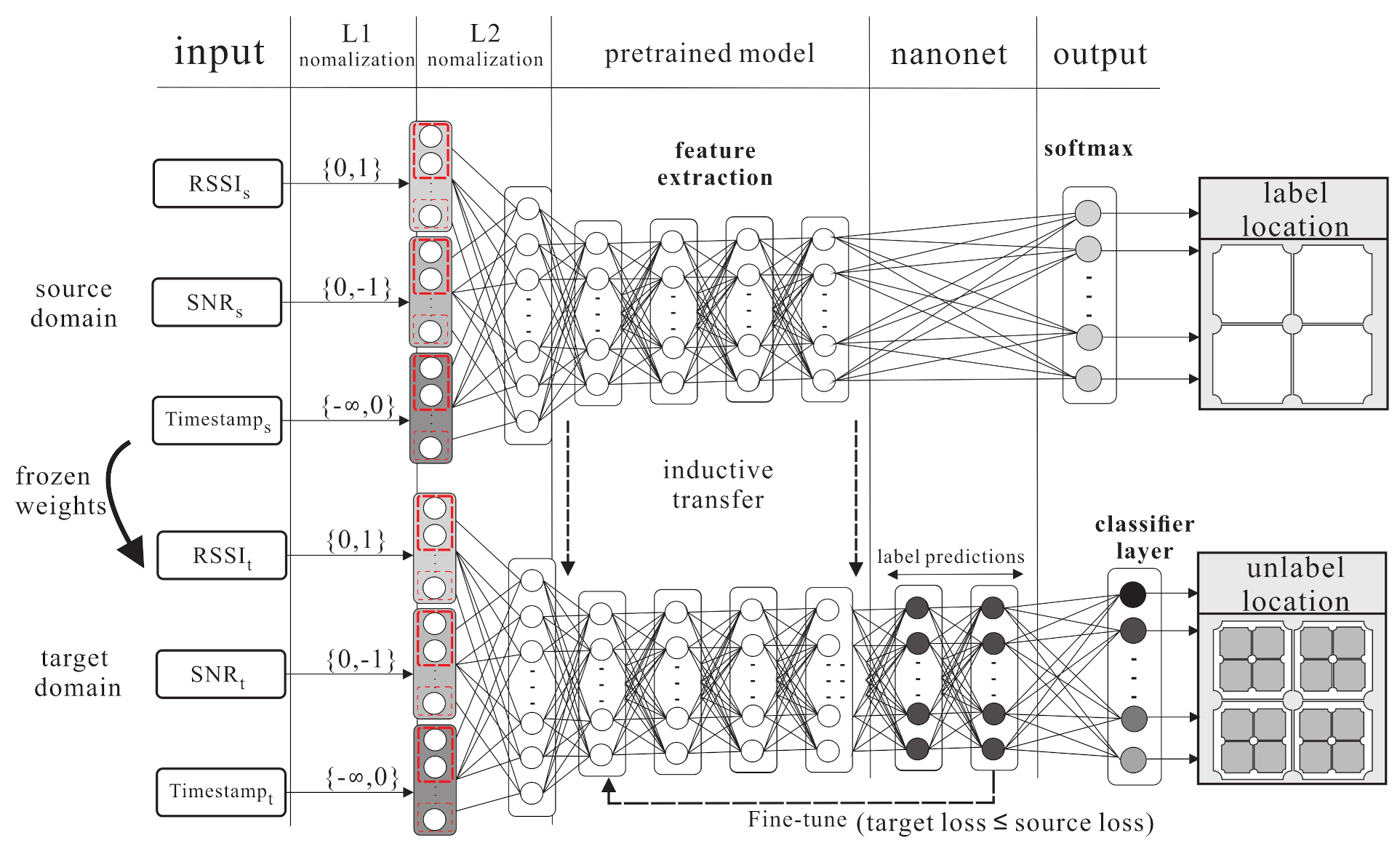
4.2. Kernel Knowledge Transferring Phase
- S1.
- In this step, the softmax function uses the logistic regression for multi-class problems. The labelled class y is taken from the source domain, where . The probabilities of each class with instance can be estimated as follows:
- S2.
- The KL divergence (Kullback–Leibler divergence) is a non-symmetric measurement of the divergence between two probabilities of the embedded instance, which is between the source domain and target domain (denoted as ). The probability is denoted as . The total statements can be written as , where .
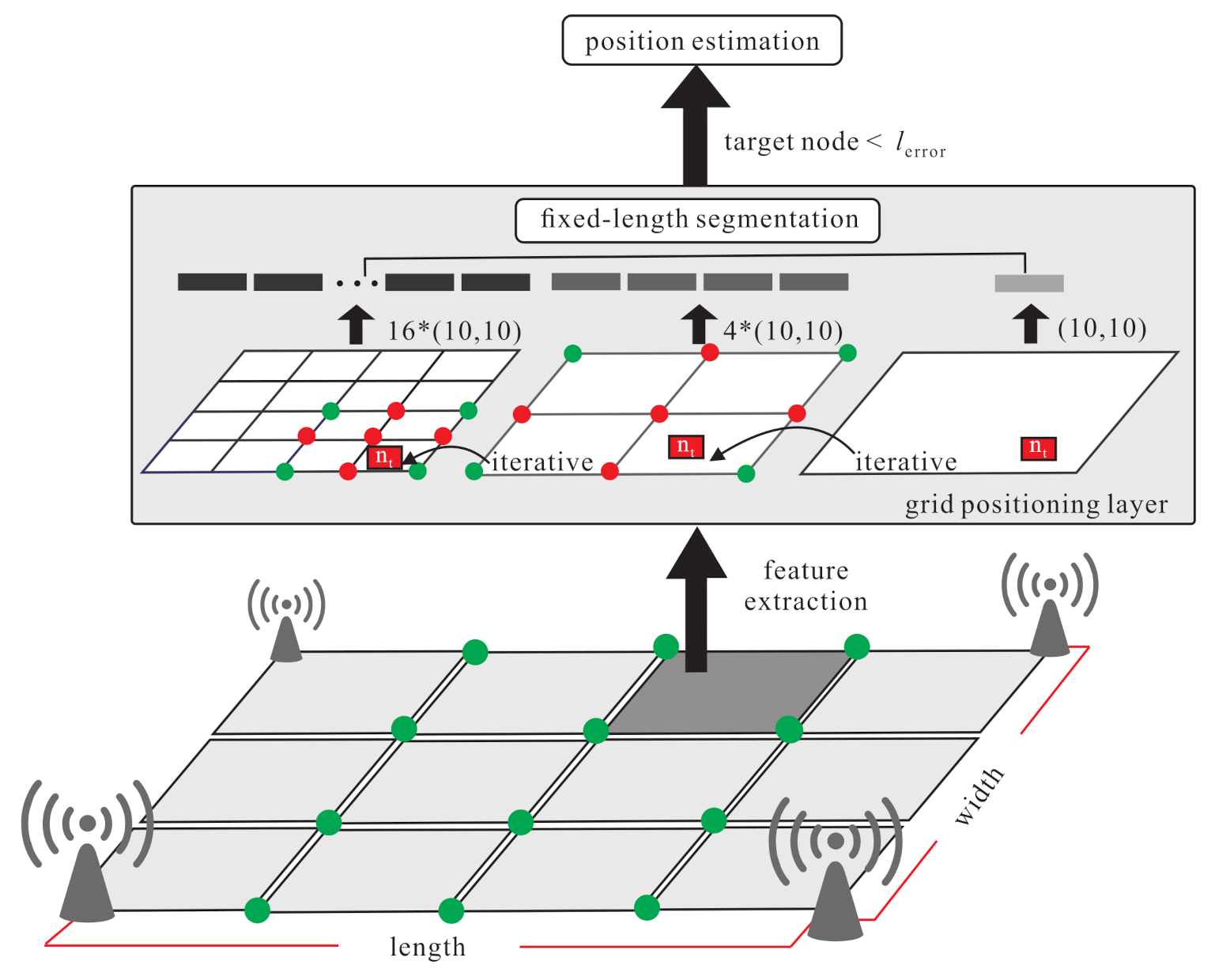
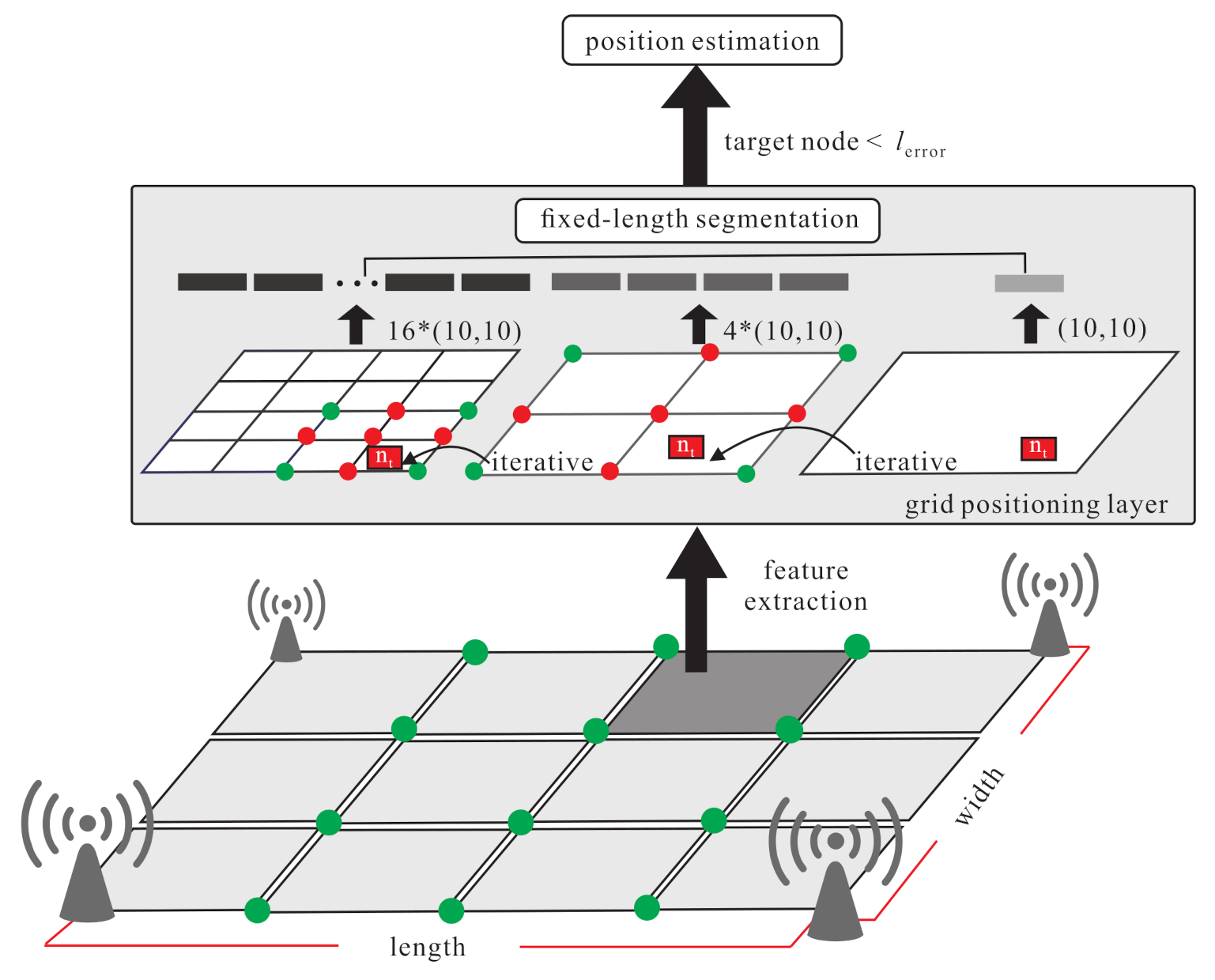
4.3. Source Domain Grid Segmentation phase
- S1.
- Each labelled point has a corresponding feature (denoted as f). The labelled point, the corner point, the boundary point, the kernel point, and their corresponding features are denoted as , , , and , respectively. Those data are collected from a true noisy environment.
- S2.
- The DNN model is used to learn the boundary and kernel points from the corner points. This model uses supervised learning to generate boundary points from two constrained corners, , and , where is the input data, is the output data, is the weight in the hidden layer j, is the bias of the hidden layer j, is the reconstruction input of the hidden layer j. can be derived from the followng equation:
- S3.
- The softmax function is used to calculate the regression probability of the output (). KL divergence is used to calculate the loss function and sgd optimizer so as to fine-tune the weight and bias of each hidden layer . Finally, to get the minimized error function, the frozen layer is added to transfer knowledge to the target domain..
4.4. Grid Segmentation Fine-Tuning Phase
- S1.
- Given unlabelled sample , learn the weight and bias of each hidden layers from so as to fine-tune the coarse location as follows:
- S2.
- The grid is divided iteratively to get the new boundary points and new kernel points from the new corner points of the divided grid. The new corner points (denoted as ) are the surrounding points of the original grid. Use the data generator to generate the corresponding data. Generate the new boundary points (denoted as ) and the new kernel point (denoted as ), and use the softmax function and KL divergence to derive the constraint regression. The weight and bias of the new hidden layer is frozen and . Finally, the fine-tuned location can be derived as follows:
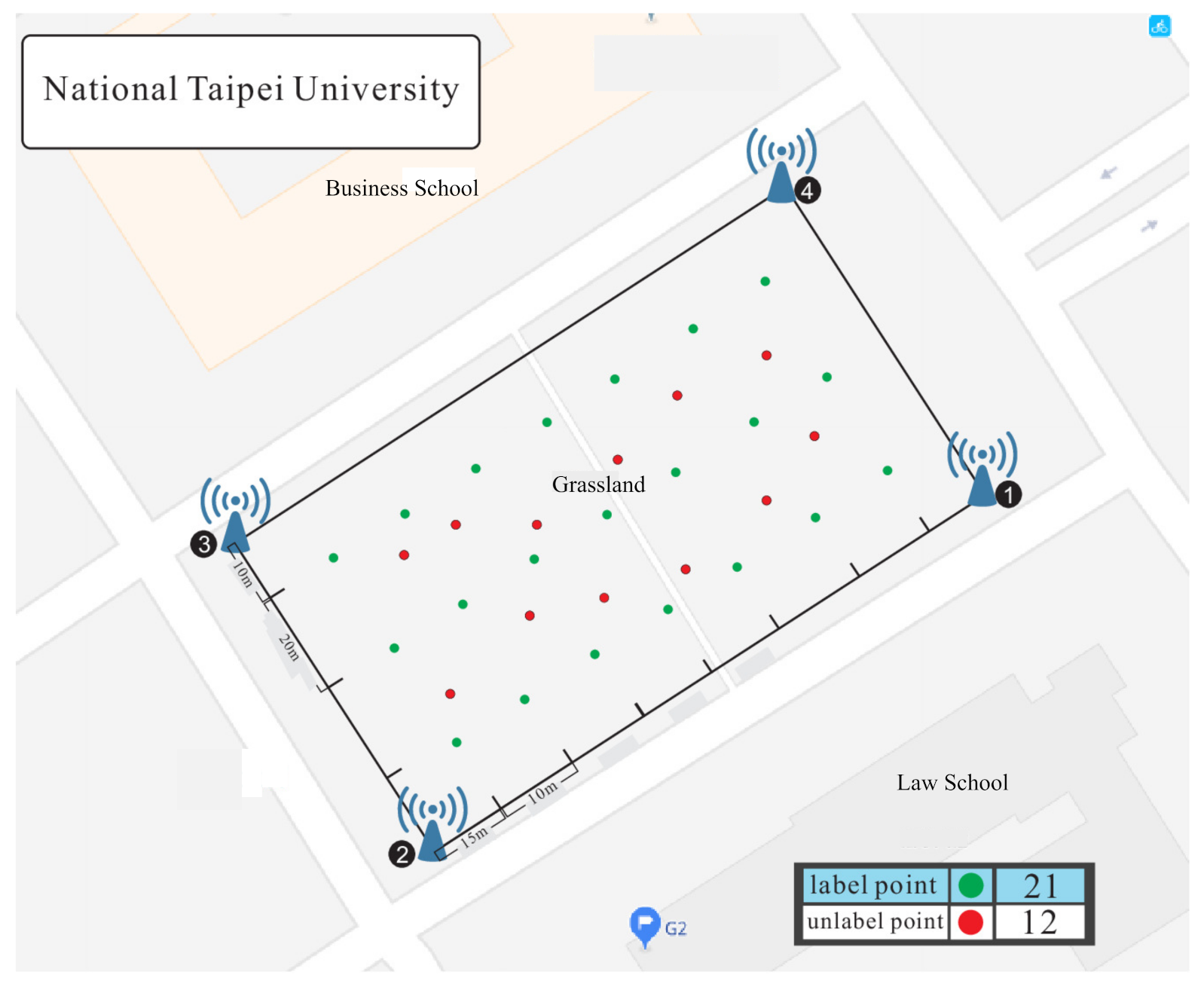
5. Experimental Results
- Localization error: the mean difference between the real location and the predicted location.
- Data accuracy: the match rate of the output target data and the input data.
- Training time: the training time required to operate the entire system with different samples and different models.
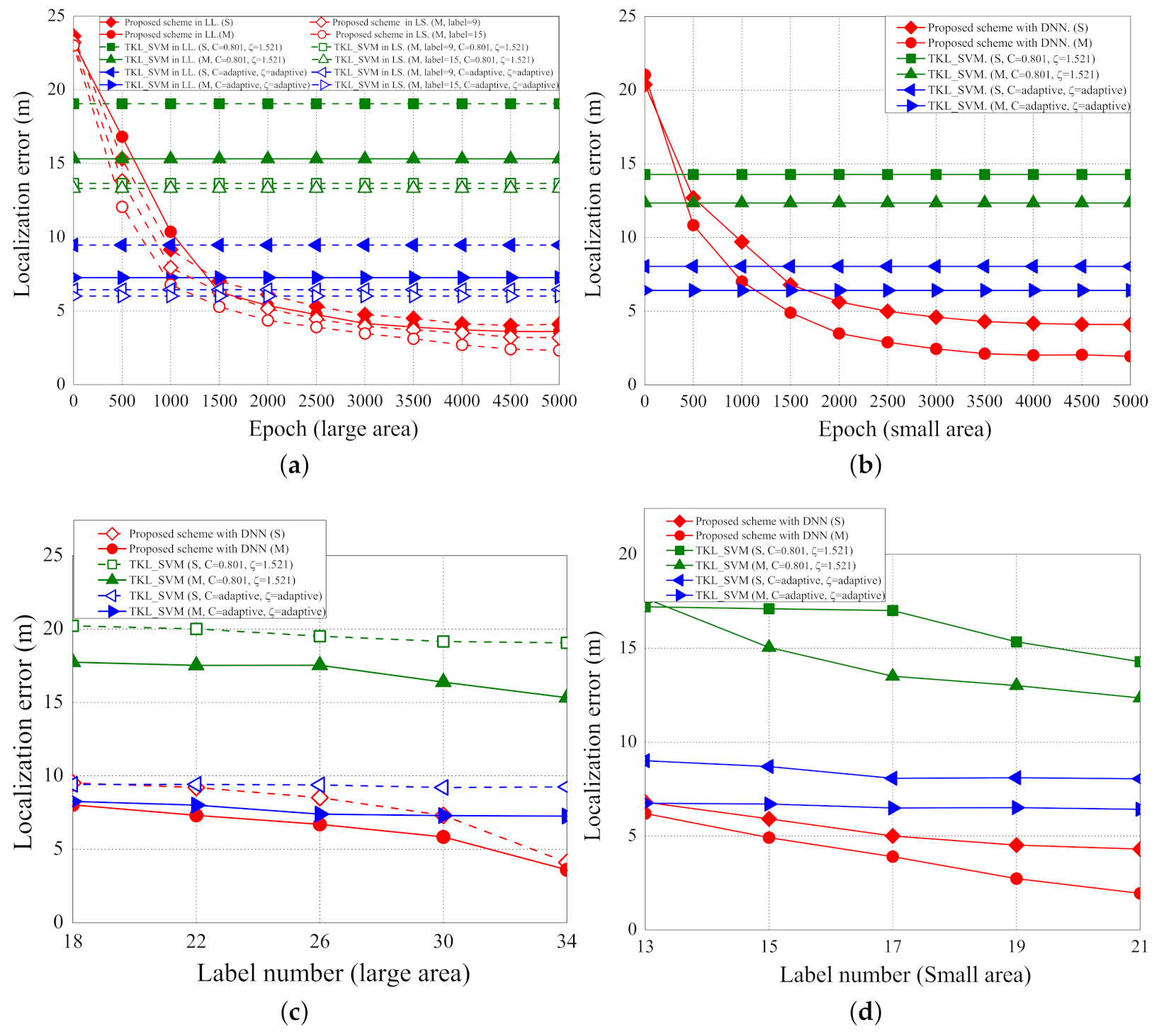
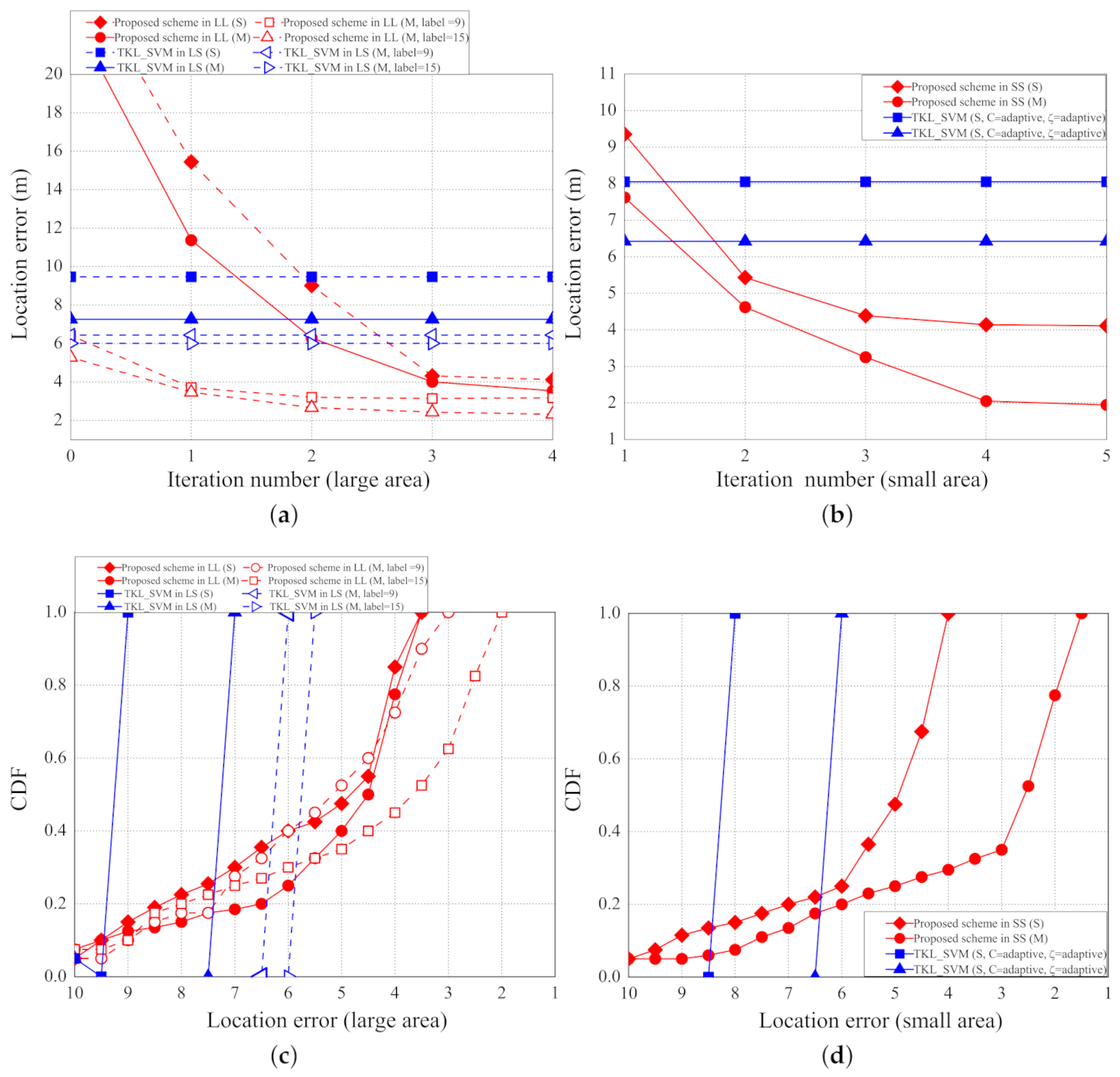
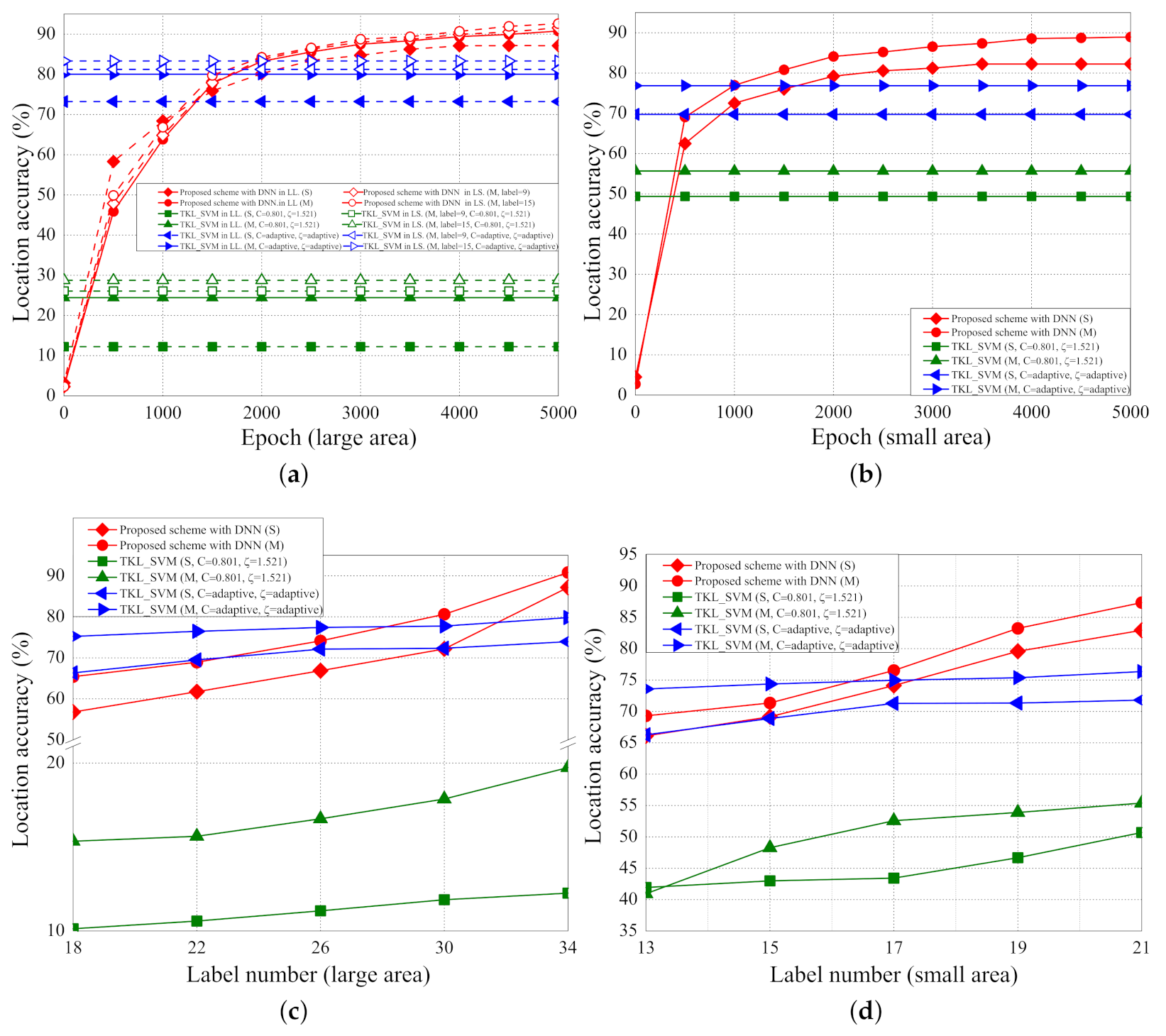
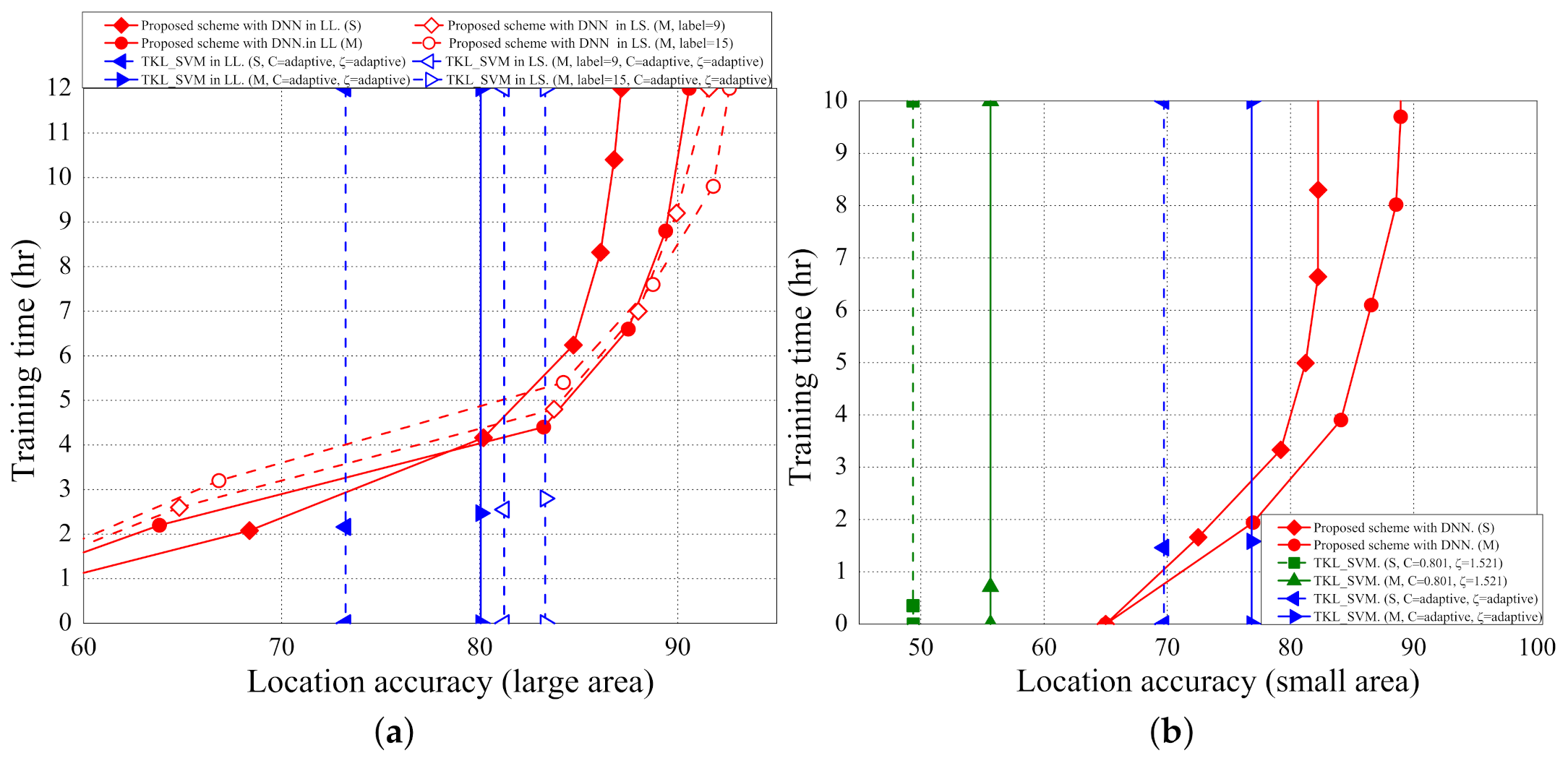
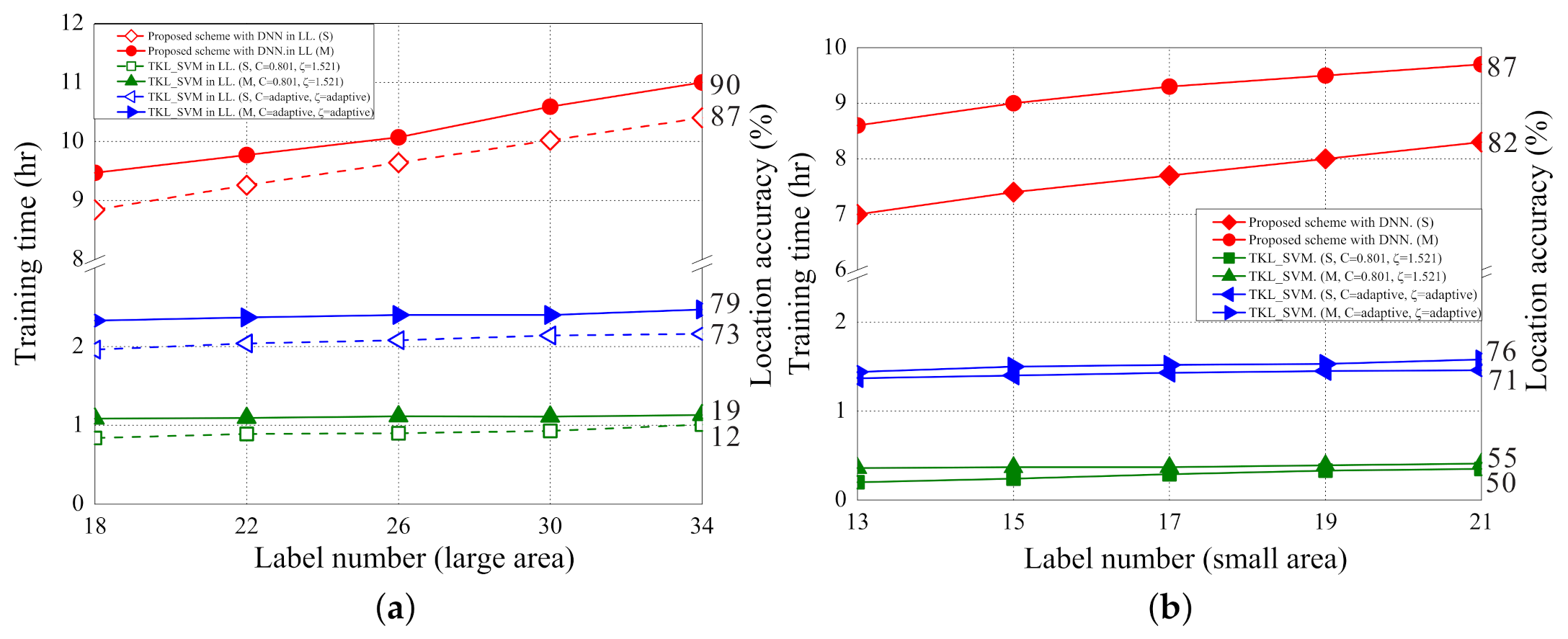
5.1. Localization Error
5.2. Location Accuracy
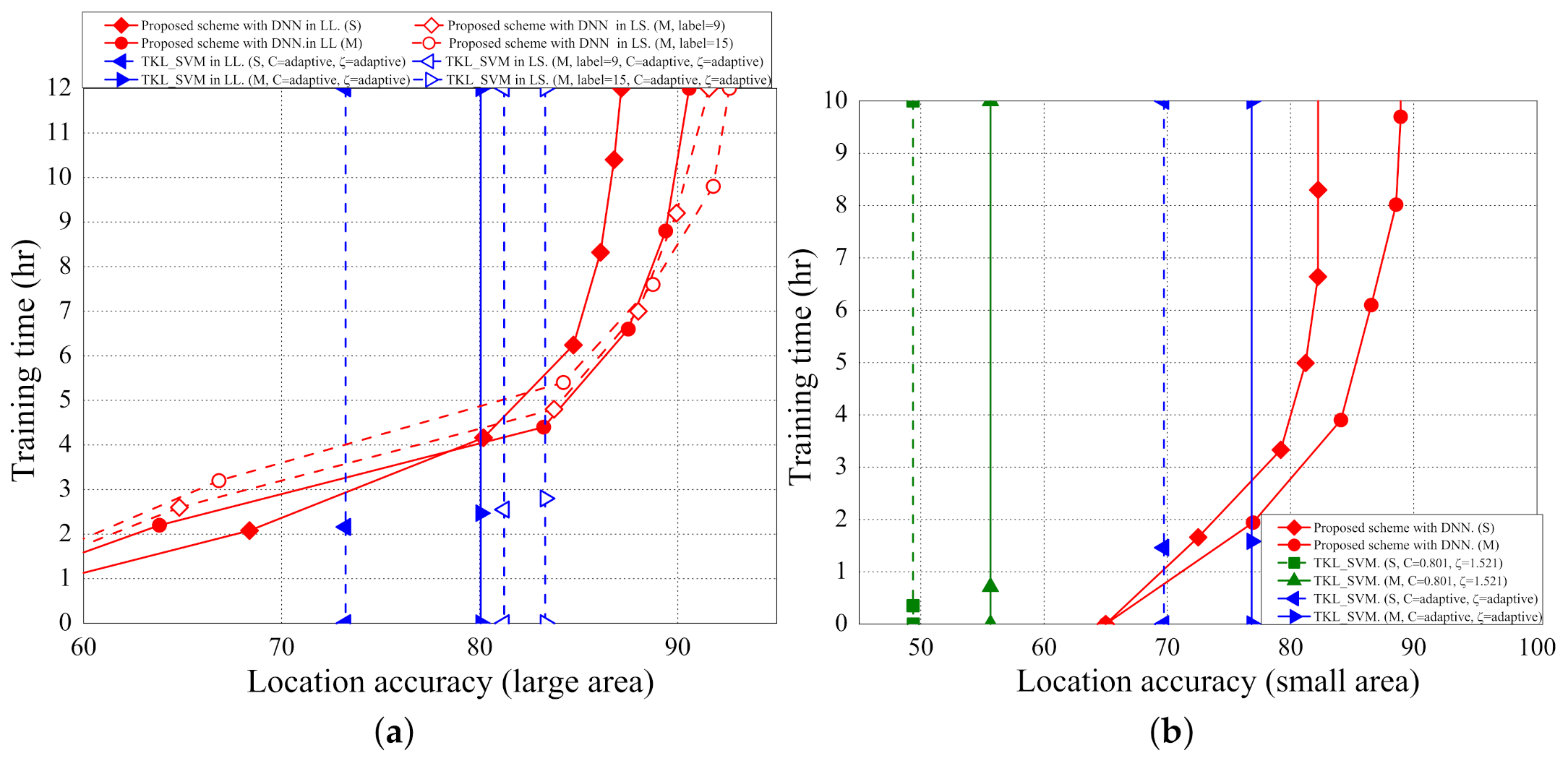
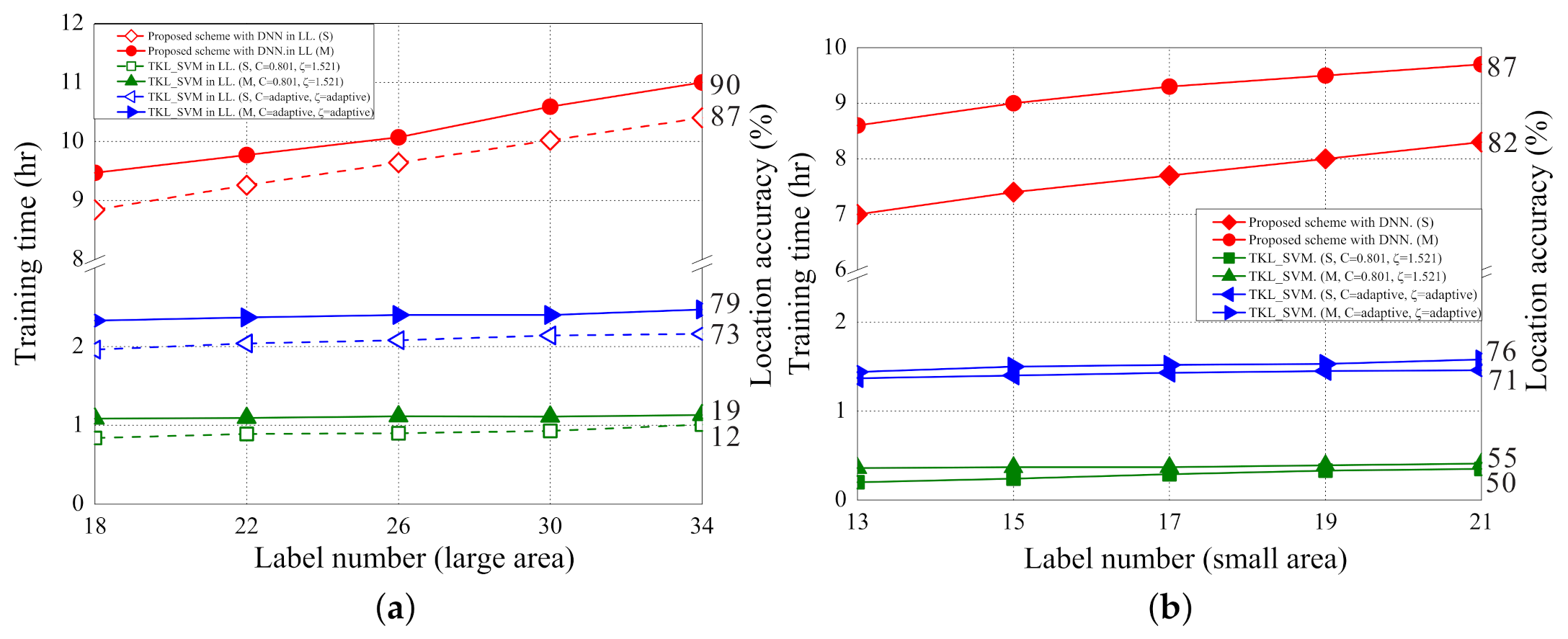
5.3. Training Time
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Hsu, C.; Huang, C.; Hung, H. Outdoor Localization for LoRaWans Using Semi-Supervised Transfer Learning with Grid Segmentation. In Proceedings of the IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), Singapore, 28–30 August 2019. [Google Scholar]
- Chiumento, H.S.A.; Pollin, S. Localization in Long-Range Ultra Narrow Band IoT Networks Using RSSI. In Proceedings of the IEEE International Conference on Communications (ICC 2017), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Lam, K.; Cheung, C.; Lee, W. LoRa-based Localization Systems for Noisy Outdoor Environmen. In Proceedings of the IEEE Wireless and Mobile Computing, Networking and Communications, (WiMob 2017), Rome, Italy, 9–11 October 2017; pp. 278–284. [Google Scholar]
- Lam, K.H.; Cheung, C.C.; Lee, W.C. New RSSI-Based LoRa Localization Algorithms for Very Noisy Outdoor Environment. In Proceedings of the IEEE Annual Computer Software and Applications Conference, (COMPSAC 2018), Tokyo, Japan, 23–27 July 2018; pp. 1–6. [Google Scholar]
- LoRa Localization. Available online: https://www.link-labs.com/blog/lora-localization (accessed on 30 June 2016).
- Fargas, B.C.; Petersen, M.N. GPS-Free Geolocation Using LoRa in Low-Power WANs. In Proceedings of the IEEE Global Internet of Things Summit, (GIoTS 2017), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Anjum, M.; Khan, M.A.; Hassan, S.A.; Mahmood, A.; Qureshi, H.K.; Gidlund, M. RSSI Fingerprinting-Based Localization Using Machine Learning in LoRa Networks. IEEE Internet Things Mag. 2020, 3, 53–59. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Sun, J.; Yu, P.S. Domain Invariant Transfer Kernel Learning. IEEE Trans. Knowl. Data Eng. 2015, 27, 1519–1532. [Google Scholar] [CrossRef]
- Deng, Z.; Choi, K.; Jiang, Y.; Wang, S. Generalized Hidden-Mapping Ridge Regression, Knowledge-Leveraged Inductive Transfer Learning for Neural Networks, Fuzzy Systems and Kernel Methods. IEEE Trans. Cybern. 2014, 44, 2585–2599. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Liu, K.; Zhang, W.; Zhang, Y.; Gu, J. Deep Neural Networks for Wireless Localization in Indoor and Outdoor Environments. Elsevier Neurocomput. 2016, 194, 279–287. [Google Scholar] [CrossRef]
- Purohit, J.; Wang, X.; Mao, S.; Sun, X.; Yang, C. Fingerprinting-based Indoor and Outdoor Localization with LoRa and Deep Learning. In Proceedings of the IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar]
- Lam, K.H.; Cheung, C.C.; Lee, W.C. RSSI-Based LoRa Localization Systems for Large-Scale Indoor and Outdoor Environments. IEEE Trans. Veh. Technol. 2019, 68, 11778–11791. [Google Scholar] [CrossRef]
- Podevijn, N.; Plets, D.; Trogh, J.; Martens, L.; Suanet, P.; Hendrikse, K.; Joseph, W. TDoA-Based Outdoor Positioning with Tracking Algorithm in a Public LoRa Network. Wirel. Commun. Mob. Comput. 2018, 2018, 1864209. [Google Scholar] [CrossRef]
- Xiao, C.; Yang, D.; Chen, Z.; Tan, G. 3D BLE Indoor Localization based on Denoising Autoencoder. IEEE Access 2017, 5, 12751–12760. [Google Scholar] [CrossRef]
- Robyns, P.; Marin, E.; Lamotte, W.; Quax, P.; Singelee, D.; Preneel, B. Physical-Layer Fingerprinting of LoRa Devices Using Supervised and Zero-Shot Learning. In Proceedings of the ACM Conference on Security and Privacy in Wireless and Mobile Networks, (WiSec 2017), Boston, MA, USA, 18–20 July 2017; pp. 58–63. [Google Scholar]
- Khatab, Z.; Hajihoseini, A.; Ghorash, S. A Fingerprint Method for Indoor Localization Using Autoencoder based Deep Extreme Learning Machine. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Mao, S. ResLoc: Deep Residual Sharing Learning for Indoor Localization with CSI Tensor. In Proceedings of the IEEE Personal Indoor, and Mobile Radio Communications, (PIMRC 2017), Montreal, QC, Canada, 8–13 October 2017; pp. 1–6. [Google Scholar]
- Decurninge, A.; Ordonez, L.G.; Ferrand, P.; Gaoning, H.; Bojie, L.; Wei, Z. CSI-based Outdoor Localization for Massive MIMO: Experiments with a Learning Approach. arXiv 2018, arXiv:1806.07447. [Google Scholar]
- Zou, H.; Zhou, Y.; Jiang, H.; Huang, B. Adaptive Localization in Dynamic Indoor Environments by Transfer Kernel Learning. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC 2017), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Chandran, S.; Panicker, J. An Efficient Multi-Label Classification System Using Ensemble of Classifiers. In Proceedings of the IEEE International Conference on Intelligent Computing, Instrumentation and Control Technologies, (ICICICT 2017), Kannur, India, 6–7 July 2016; pp. 1–4. [Google Scholar]
- Chen, Q.; Mutka, M.W. Self-Improving Indoor Localization by Profiling Outdoor Movement on Smartphones. In Proceedings of the IEEE International Symposium on A World of Wireless, Mobile and Multimedia Networks, (WoWMoM 2017), Macau, China, 12–15 June 2017; pp. 1–9. [Google Scholar]
- Wang, J.; Tan, N.; Luo, J.; Pan, S.J. WOLoc: WiFi-only Outdoor Localization Using Crowdsensed Hotspot Labels. In Proceedings of the IEEE Computer Communications Conference, (INFOCOM 2017), Atlanta, GA, USA, 1–4 May 2017; pp. 1–6. [Google Scholar]
- Gu, C.; Jiang, L.; Tan, R. LoRa-Based Localization: Opportunities and Challenges. arXiv 2018, arXiv:1812.11481. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, (ICML 2015), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Hsu, C.-S.; Huang, C.-Y. A Semi-Supervised Transfer Learning with Grid Segmentation for Outdoor Localization over LoRaWans. Sensors 2021, 21, 2640. https://doi.org/10.3390/s21082640
Chen Y-S, Hsu C-S, Huang C-Y. A Semi-Supervised Transfer Learning with Grid Segmentation for Outdoor Localization over LoRaWans. Sensors. 2021; 21(8):2640. https://doi.org/10.3390/s21082640
Chicago/Turabian StyleChen, Yuh-Shyan, Chih-Shun Hsu, and Chan-Yin Huang. 2021. "A Semi-Supervised Transfer Learning with Grid Segmentation for Outdoor Localization over LoRaWans" Sensors 21, no. 8: 2640. https://doi.org/10.3390/s21082640
APA StyleChen, Y.-S., Hsu, C.-S., & Huang, C.-Y. (2021). A Semi-Supervised Transfer Learning with Grid Segmentation for Outdoor Localization over LoRaWans. Sensors, 21(8), 2640. https://doi.org/10.3390/s21082640