
Orchestrating Heterogeneous Devices and AI Services as Virtual Sensors for Secure Cloud-Based IoT Applications †

Abstract
:1. Introduction
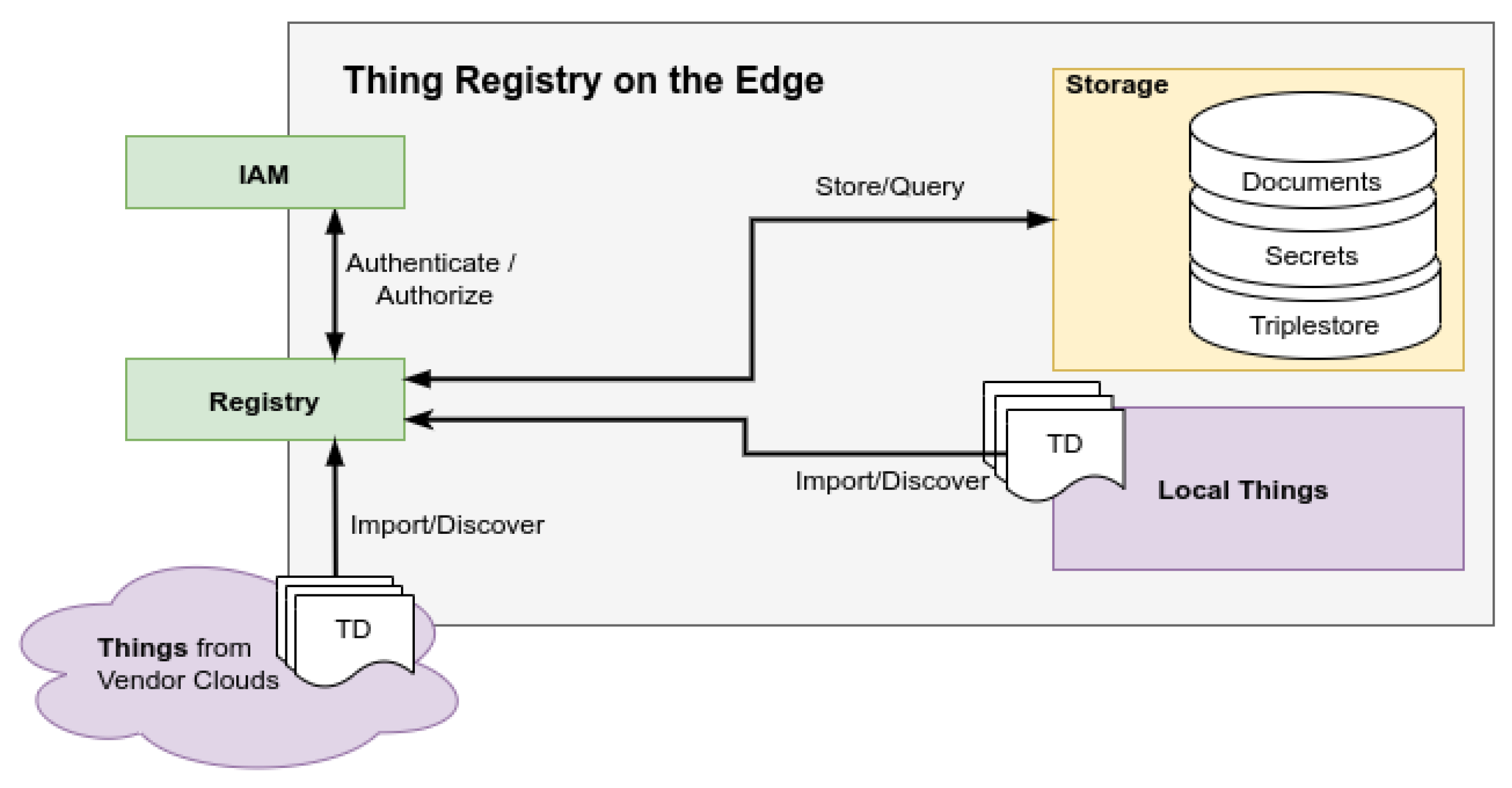
2. Gathering Resources in the Thing Registry
2.1. Discovery
2.2. Authentication, Authorization, and Encryption
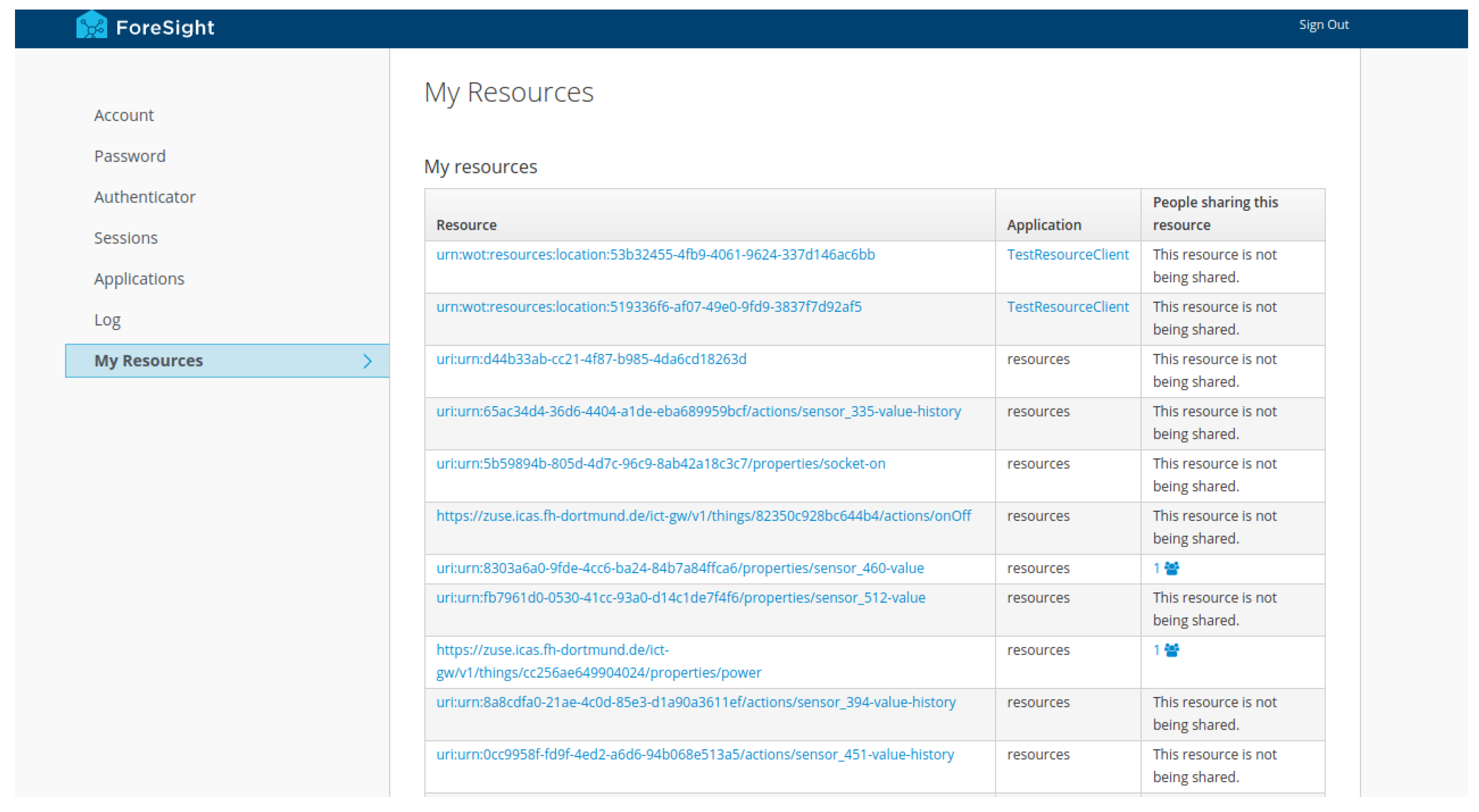
2.3. Querying Metadata
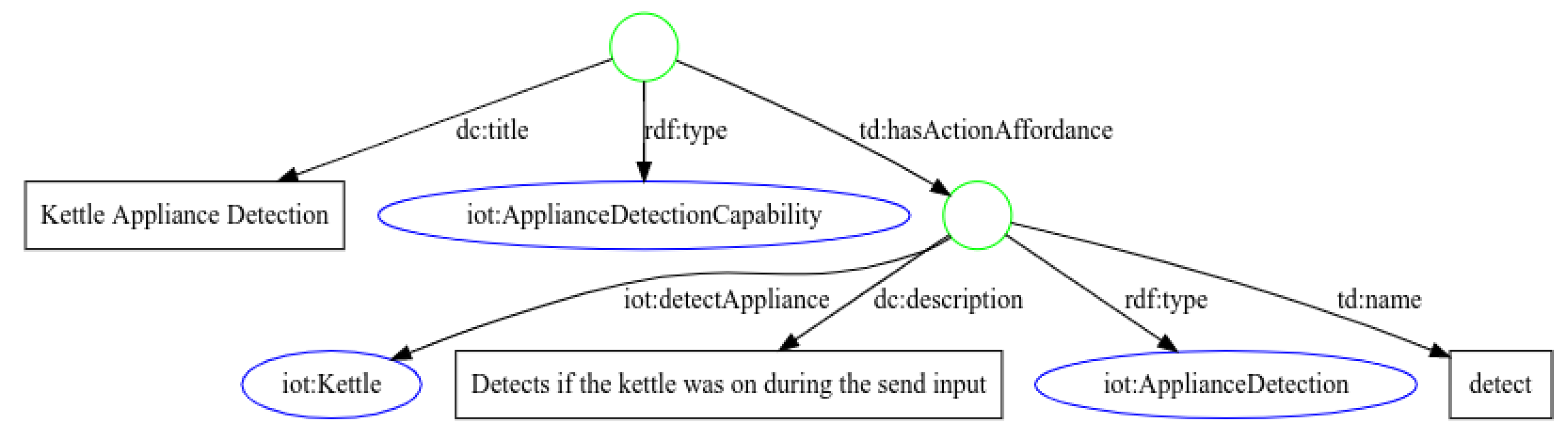
2.4. Exposed Thing
2.4.1. Payload Mapping
- key:
- the key to be used for this key value pair.
- value:
- the value used for this key value pair. The value of a JSON Object can again be a JSON object or JSON array defined in the lowering template.
- data:
- if an object should refer to incoming data, this specifies the related resource of the input graph.
- root:
- the root of the hierarchy.
2.4.2. Protocol Mapping
3. Security and Privacy
3.1. Encryption
3.2. Authentication
3.3. Authorization
Example
- urn:dev:ops:32473-WoTLamp-1234
- urn:dev:ops:32473-WoTLamp-1234/properties/status
- urn:dev:ops:32473-WoTLamp-1234/actions/toggle
3.4. Integration
4. Virtual Sensors
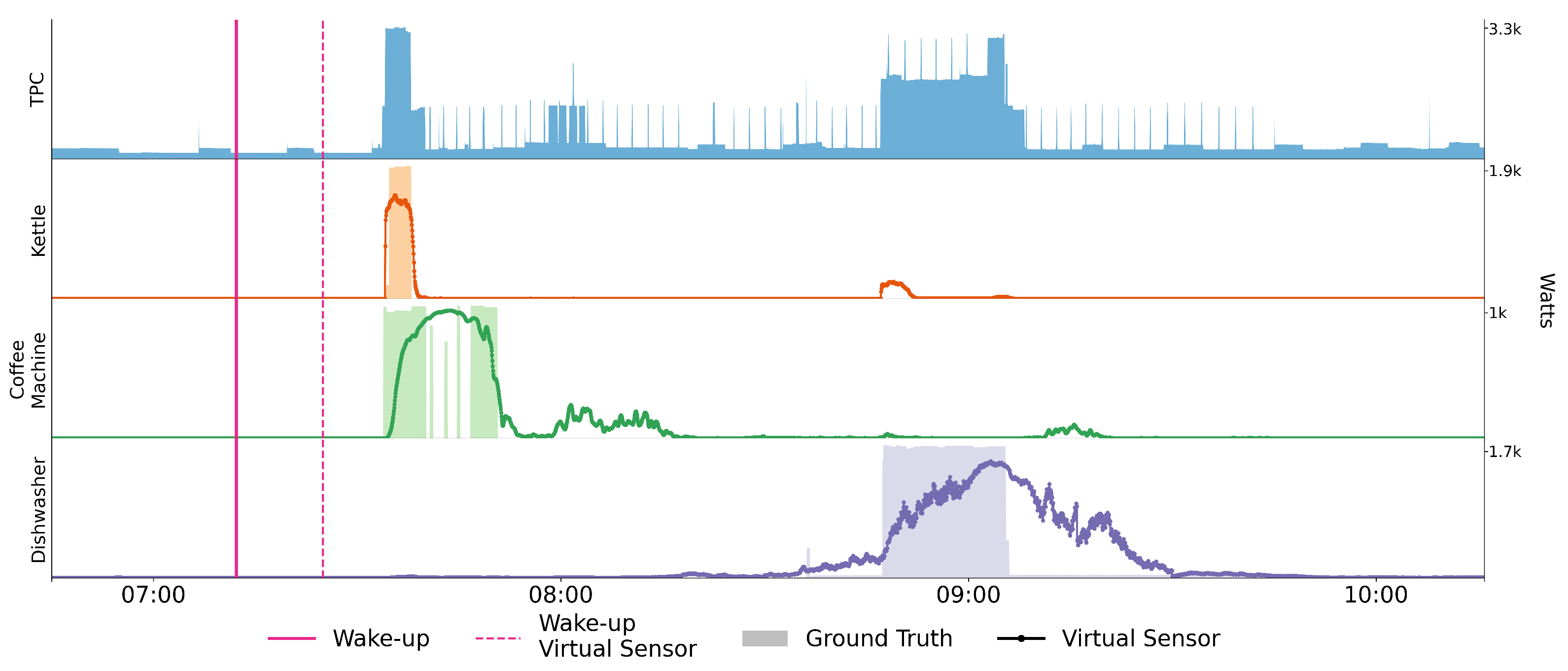
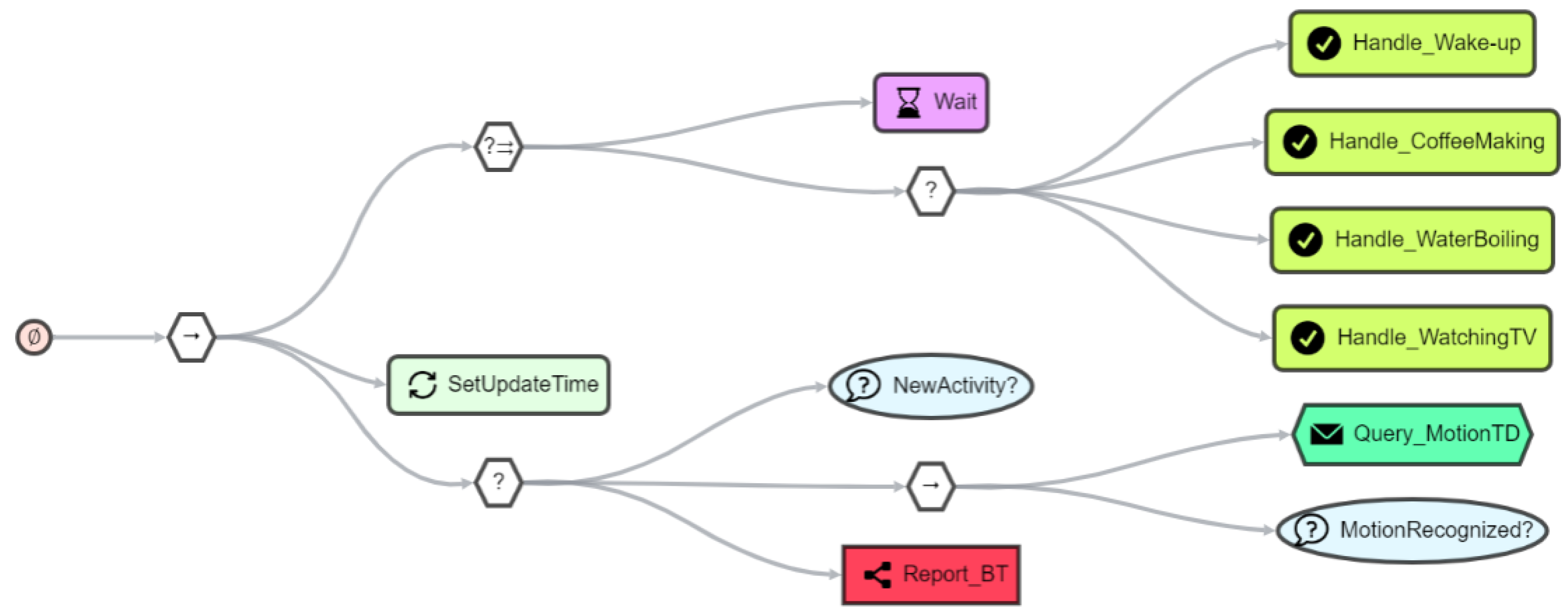
4.1. Appliance Detection
4.2. Detecting the Time of Wake-Up
4.3. Summary
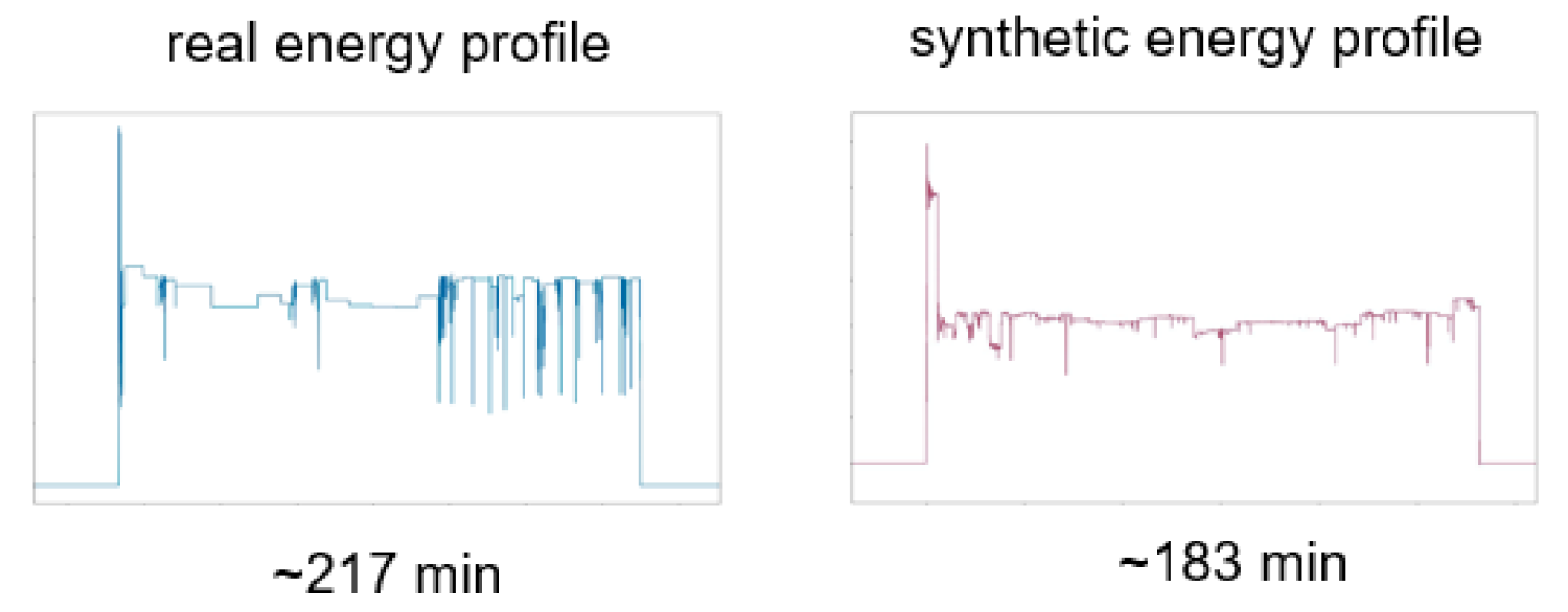
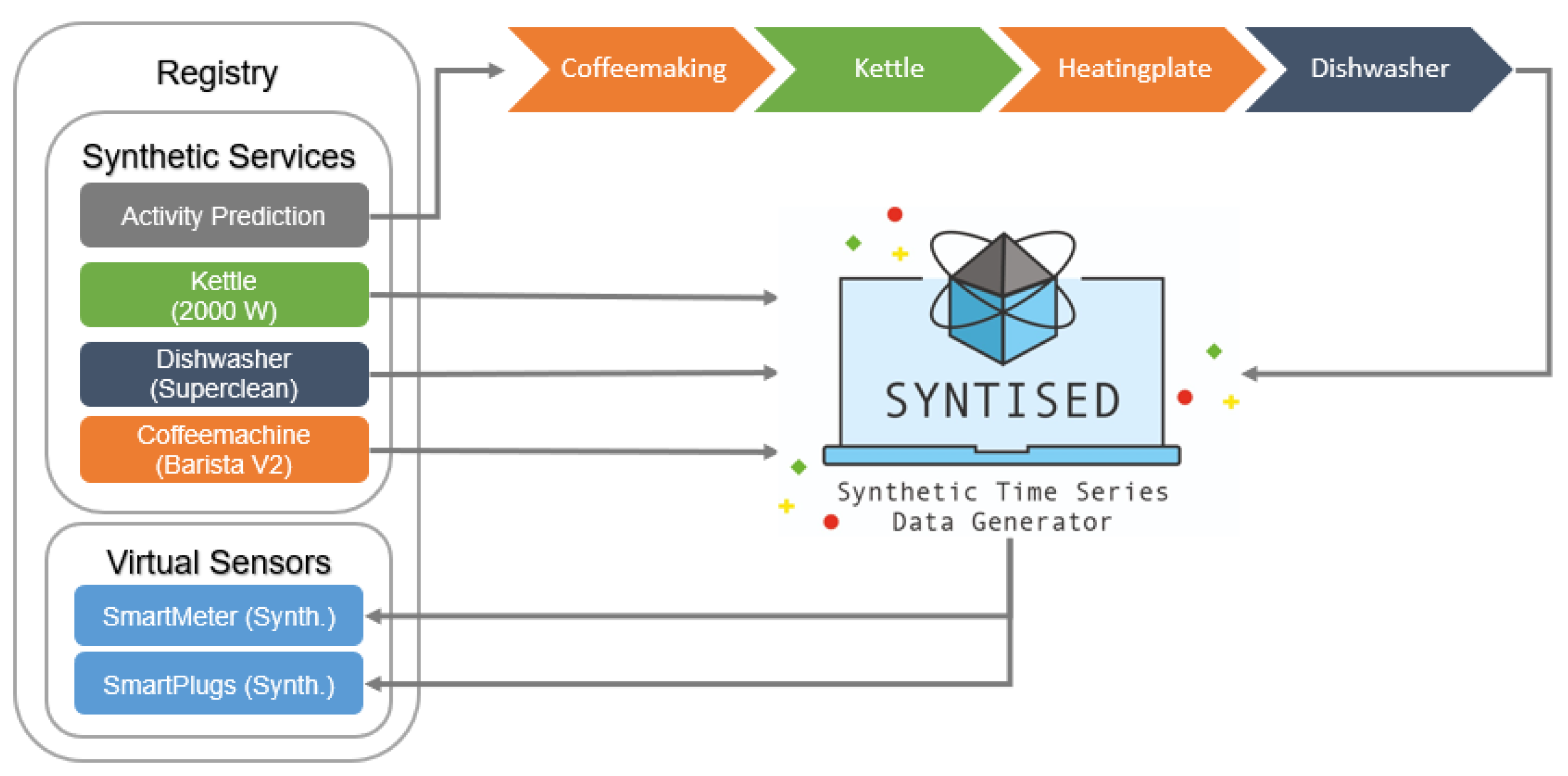
5. Synthetic Sensor Data
5.1. Synthetic Power Consumption Data
- Constantly-on: these include devices that always consume energy without any downtime (e.g., a WiFi router).
- Periodical: these include devices that have periodic consumption patterns and operate independently (e.g., a fridge).
- Single pattern: these include devices that are operated by a user and always have a very similar power consumption pattern (e.g., a kettle).
- Multi-pattern: these include devices that are operated by a user but can have completely different power consumption patterns, depending on their programs (e.g., a dishwasher)
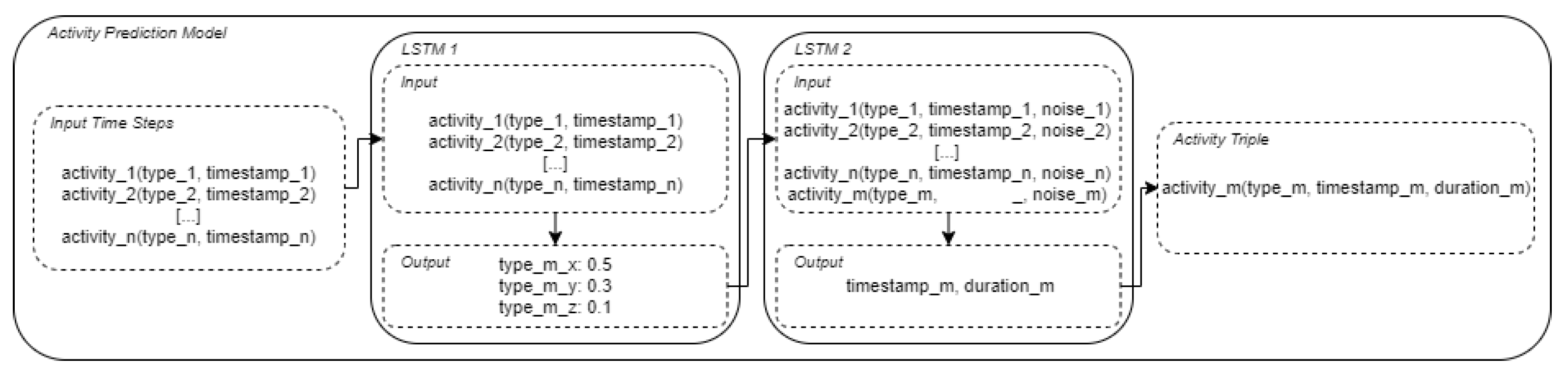
5.2. Activity Sequence Generation
- [’wakeUp’, 15780, 1]
- [’kettle’, 17520, 185]
- [’coffeeMaking’, 17700, 30]
- [’kettle’, 40860, 132]
- [’tvWatching’, 66240, 7153]
5.3. Synthetic Labeled Time Series Data
6. Integrating Virtual Sensors into the Registry
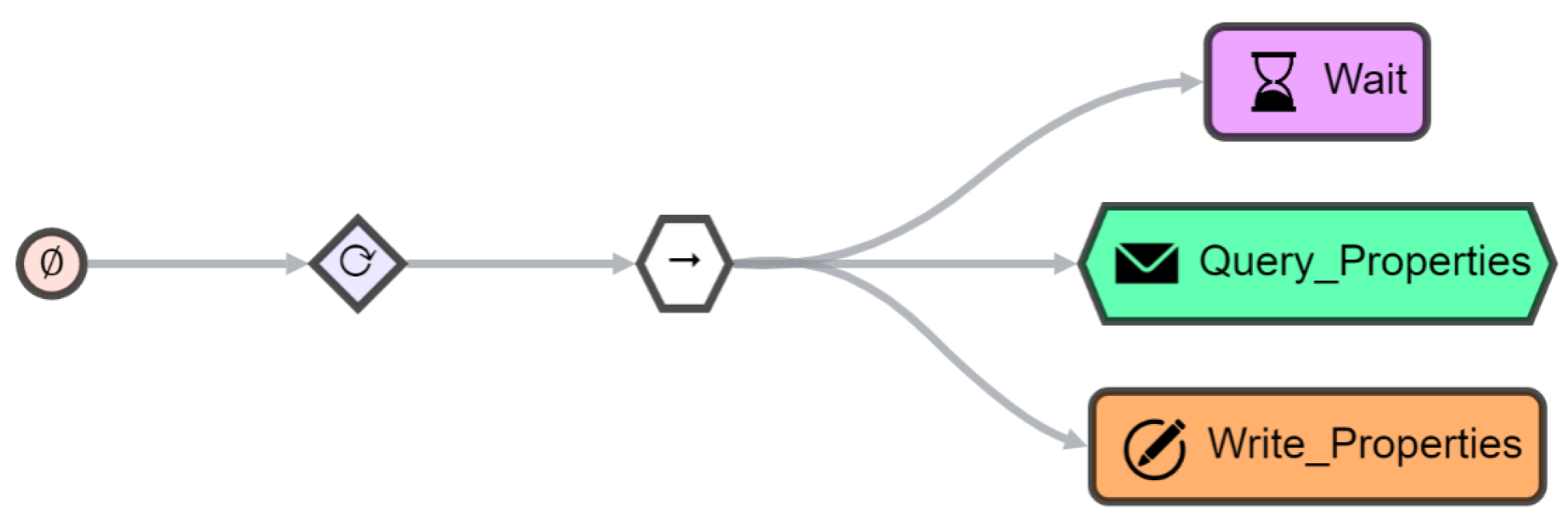
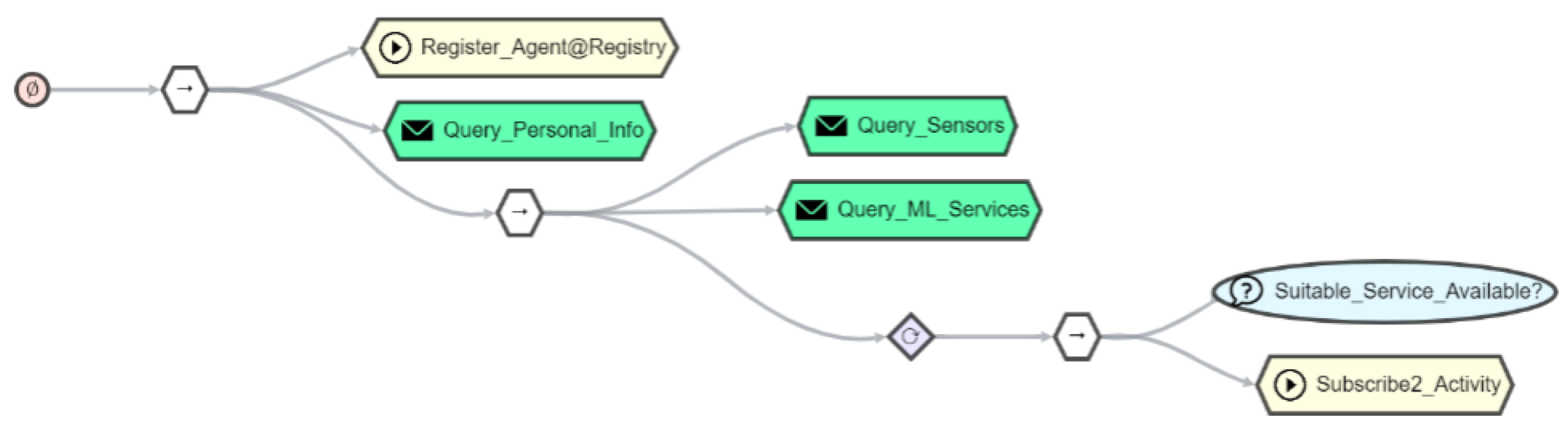
7. Orchestrating Things and Services with AJAN
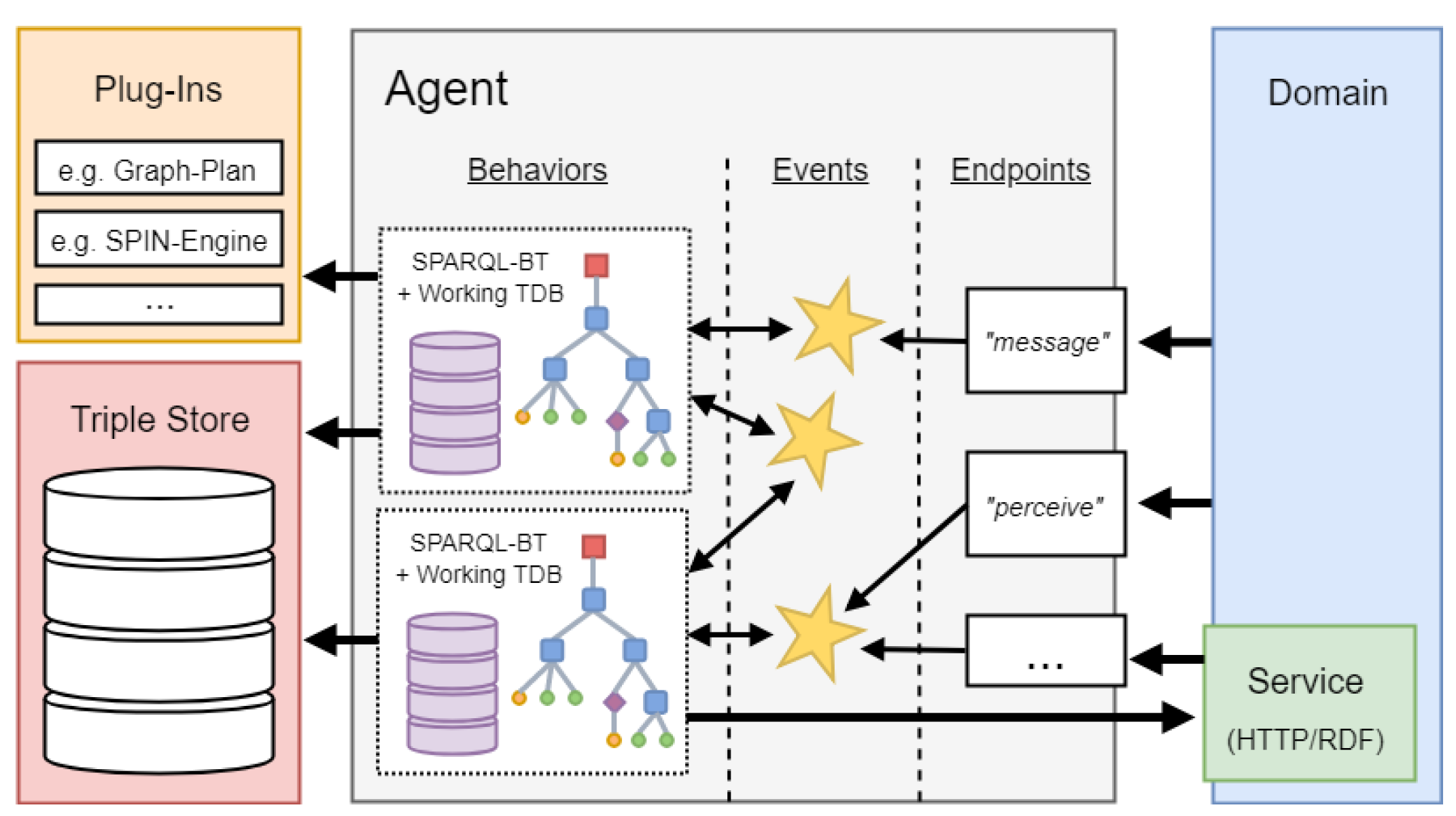
7.1. AJAN Agent Model
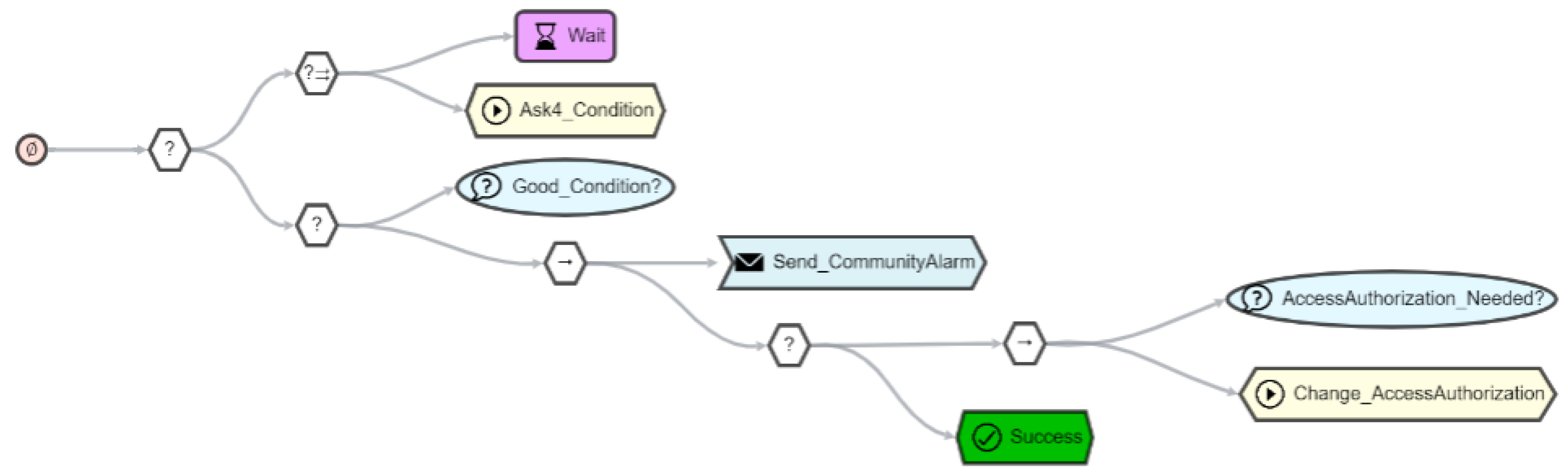
7.2. Behavior Trees for Orchestration
7.3. Incorporating Things
8. Use Case
9. Related Work
10. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | internet of things |
| ML | machine learning |
| IAM | identity and access management |
| TPC | total power consumption |
| NILM | non-intrusive load monitoring |
| WoT | web of things |
| LD | linked data |
| RDF | resource description framework |
| RDFS | RDF-schema |
| OWL | web ontology language |
| TD | Thing Description |
| JSON | javascript object notation |
| IRI | internationalized resource identifier |
| AJAN | accessible java agent nucleus |
| BMWi | Bundesministeriums für Wirtschaft und Energie |
| BOT | building topology ontology |
| API | application programming interface |
| RML | RDF mapping language |
| XML | full extensible markup language |
| DFKI | German Research Center for Artificial Intelligence |
| TDD | Thing Description Directory |
| TDT | Thing Description Template |
| OAuth | Open Authorization |
| OIDC | OpenID Connect |
| UMA | user-management access |
| GUI | graphical user interface |
References
- Lynn, T.; Mooney, J.; Lee, B.; Endo, P. The Cloud-to-Thing Continuum. Opportunities and Challenges in Cloud, Fog and Edge Computing; Palgrave Macmillan: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Rahman, H.; Hussain, M.I. A comprehensive survey on semantic interoperability for Internet of Things: State-of-the-art and research challenges. Trans. Emerg. Telecommun. Technol. 2020, 31, e3902. [Google Scholar] [CrossRef]
- Kabadayi, S.; Pridgen, A.; Julien, C. Virtual sensors: Abstracting data from physical sensors. In Proceedings of the 2006 International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM’06), Coimbra, Portugal, 21–24 June 2006; p. 592. [Google Scholar] [CrossRef] [Green Version]
- Alberternst, S.; Anisimov, A.; Antakli, A.; Duppe, B.; Hoffmann, H.; Meiser, M.; Muaz, M.; Spieldenner, D.; Zinnikus, I. From Things into Clouds—And back. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 668–675. [Google Scholar] [CrossRef]
- Heiler, S. Semantic interoperability. ACM Comput. Surv. (CSUR) 1995, 27, 271–273. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Murray, D.; Liao, J.; Stankovic, L.; Stankovic, V.; Hauxwell-Baldwin, R.; Wilson, C.; Coleman, M.; Kane, T.; Firth, S. A data management platform for personalised real-time energy feedback. In Proceedings of the 8th International Conference on Energy Efficiency in Domestic Appliances and Lighting, Lucerne, Switzerland, 26–28 August 2015. [Google Scholar]
- Chalmers, C.; Fergus, P.; Montanez, C.A.C.; Sikdar, S.; Ball, F.; Kendall, B. Detecting activities of daily living and routine behaviours in dementia patients living alone using smart meter load disaggregation. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Devlin, M.A.; Hayes, B.P. Non-Intrusive Load Monitoring and Classification of Activities of Daily Living Using Residential Smart Meter Data. IEEE Trans. Consum. Electron. 2019, 65, 339–348. [Google Scholar] [CrossRef]
- Zhang, X.; Kato, T.; Matsuyama, T. Learning a context-aware personal model of appliance usage patterns in smart home. In Proceedings of the 2014 IEEE Innovative Smart Grid Technologies-Asia (ISGT ASIA), Kuala Lumpur, Malaysia, 20–23 May 2014; pp. 73–78. [Google Scholar]
- Reinhardt, A.; Klemenjak, C. Device-Free User Activity Detection using Non-Intrusive Load Monitoring: A Case Study. In Proceedings of the 2nd ACM Workshop on Device-Free Human Sensing, Yokohama, Japan, 16 November 2020; pp. 1–5. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-point learning with neural networks for non-intrusive load monitoring. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Klemenjak, C.; Kovatsch, C.; Herold, M.; Elmenreich, W. A synthetic energy dataset for non-intrusive load monitoring in households. Sci. Data 2020, 7, 1–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harell, A.; Jones, R.; Makonin, S.; Bajić, I.V. TraceGAN: Synthesizing Appliance Power Signatures Using Generative Adversarial Networks. IEEE Trans. Smart Grid 2021, 12, 4553–4563. [Google Scholar] [CrossRef]
- Nasr Esfahani, S.; Latifi, S. Image Generation with Gans-based Techniques: A Survey. Int. J. Comput. Sci. Inf. Technol. 2019, 11, 33–50. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5769–5779. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar] [CrossRef] [Green Version]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Daoud, A. Semantic Web Environments for Multi-Agent Systems: Enabling agents to use Web of Things via semantic web. arXiv 2020, arXiv:2003.02054. [Google Scholar]
- Ciortea, A.; Mayer, S.; Gandon, F.; Boissier, O.; Ricci, A.; Zimmermann, A. A decade in hindsight: The missing bridge between multi-agent systems and the World Wide Web. In Proceedings of the AAMAS, Montreal, QC, Canada, 13–17 May 2019. [Google Scholar]
- Chung, E.; Lefrançois, M.; Boissier, O. Increasing interoperability in the Web of Things using Autonomous Agents (Position Paper). In Proceedings of the 18e Rencontres des Jeunes Chercheurs en Intelligence Artificielle, Angers, France, 29 June–3 July 2020. [Google Scholar]
- Antakli, A.; Spieldenner, T.; Rubinstein, D.; Spieldenner, D.; Herrmann, E.; Sprenger, J.; Zinnikus, I. Agent-based Web Supported Simulation of Human-robot Collaboration. In Proceedings of the 15th International Conference on Web Information Systems and Technologies (WEBIST), Vienna, Austria, 18–20 September 2019; pp. 88–99. [Google Scholar]
- Martens, C.; Butler, E.; Osborn, J.C. A Resourceful Reframing of Behavior Trees. arXiv 2018, arXiv:1803.09099. [Google Scholar]
- Colledanchise, M.; Ogren, P. Behavior Trees in Robotics and AI: An Introduction; CRC Press: Boca Raton, FL, USA, 2018; pp. 3–43. [Google Scholar]
- Lanthaler, M.; Guetl, C. Hydra: A Vocabulary for Hypermedia-Driven Web APIs. In Proceedings of the LDOW, Rio de Janeiro, Brazil, 14 May 2013; Volume 996. [Google Scholar]
- Binz, T.; Breitenbücher, U.; Kopp, O.; Leymann, F. TOSCA: Portable Automated Deployment and Management of Cloud Applications. In Advanced Web Services; Bouguettaya, A., Sheng, Q.Z., Daniel, F., Eds.; Springer: New York, NY, USA, 2014; pp. 527–549. [Google Scholar] [CrossRef]
- Challita, S.; Korte, F.; Erbel, J.; Zalila, F.; Grabowski, J.; Merle, P. Model-Based Cloud Resource Management with TOSCA and OCCI. Softw. Syst. Model. 2021, 20, 1609–1631. [Google Scholar] [CrossRef]
- Lentzas, A.; Vrakas, D. Non-intrusive human activity recognition and abnormal behavior detection on elderly people: A review. Artif. Intell. Rev. 2020, 53, 1975–2021. [Google Scholar] [CrossRef]
- Hou, X.; Ren, Z.; Yang, K.; Chen, C.; Zhang, H.; Xiao, Y. IIoT-MEC: A novel mobile edge computing framework for 5G-enabled IIoT. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–7. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Washing Machine | Dishwasher | Coffee Machine | Kettle | |
|---|---|---|---|---|
| max power | 2050 | 1850 | 1600 | 2950 |
| window size | 30 | 45 | 15 | 7 |
| activity duration | ||||
| recall | 1.0 | 0.9996 | 0.88 | 0.97 |
| precision | 0.9993 | 0.93 | 0.92 | 0.72 |
| Asleep | Recently Awake | Awake | |
|---|---|---|---|
| precision | 0.861 | 0.960 | 0.969 |
| recall | 0.978 | 0.816 | 0.975 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alberternst, S.; Anisimov, A.; Antakli, A.; Duppe, B.; Hoffmann, H.; Meiser, M.; Muaz, M.; Spieldenner, D.; Zinnikus, I. Orchestrating Heterogeneous Devices and AI Services as Virtual Sensors for Secure Cloud-Based IoT Applications. Sensors 2021, 21, 7509. https://doi.org/10.3390/s21227509
Alberternst S, Anisimov A, Antakli A, Duppe B, Hoffmann H, Meiser M, Muaz M, Spieldenner D, Zinnikus I. Orchestrating Heterogeneous Devices and AI Services as Virtual Sensors for Secure Cloud-Based IoT Applications. Sensors. 2021; 21(22):7509. https://doi.org/10.3390/s21227509
Chicago/Turabian StyleAlberternst, Sebastian, Alexander Anisimov, Andre Antakli, Benjamin Duppe, Hilko Hoffmann, Michael Meiser, Muhammad Muaz, Daniel Spieldenner, and Ingo Zinnikus. 2021. "Orchestrating Heterogeneous Devices and AI Services as Virtual Sensors for Secure Cloud-Based IoT Applications" Sensors 21, no. 22: 7509. https://doi.org/10.3390/s21227509
APA StyleAlberternst, S., Anisimov, A., Antakli, A., Duppe, B., Hoffmann, H., Meiser, M., Muaz, M., Spieldenner, D., & Zinnikus, I. (2021). Orchestrating Heterogeneous Devices and AI Services as Virtual Sensors for Secure Cloud-Based IoT Applications. Sensors, 21(22), 7509. https://doi.org/10.3390/s21227509