
Domain Adaptation for Imitation Learning Using Generative Adversarial Network



Abstract
:1. Introduction
- 1.
- 2.
- Humans can recognize structural differences (i.e., domain shift) and similarities between the expert and themselves in order to adapt their behaviors accordingly [8].
- A features extractor, which is capable of deriving domain-shared and domain-specific features, is proposed.
- The DAIL-GAN model is proposed. The model leverages adversarial training [21] to learn the extracted features, while at the same time, seeking for an optimal learner domain policy.
- A comprehensive experiment on both low and high-dimensional tasks is conducted to evaluate the performance of the proposed model.
2. Related Work
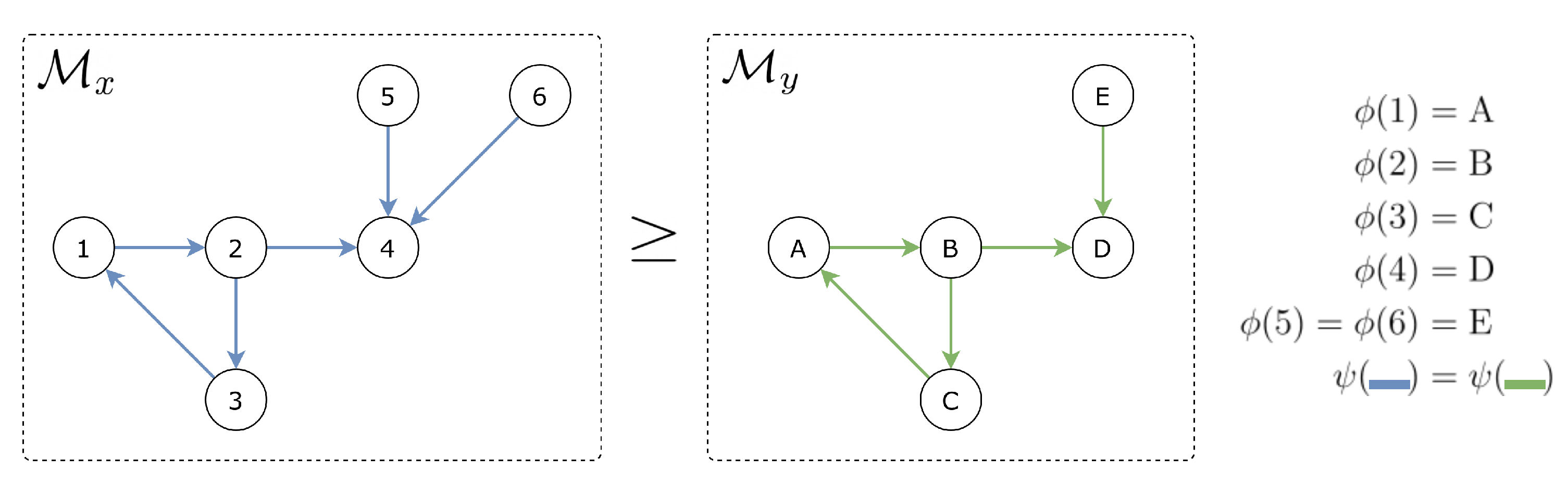
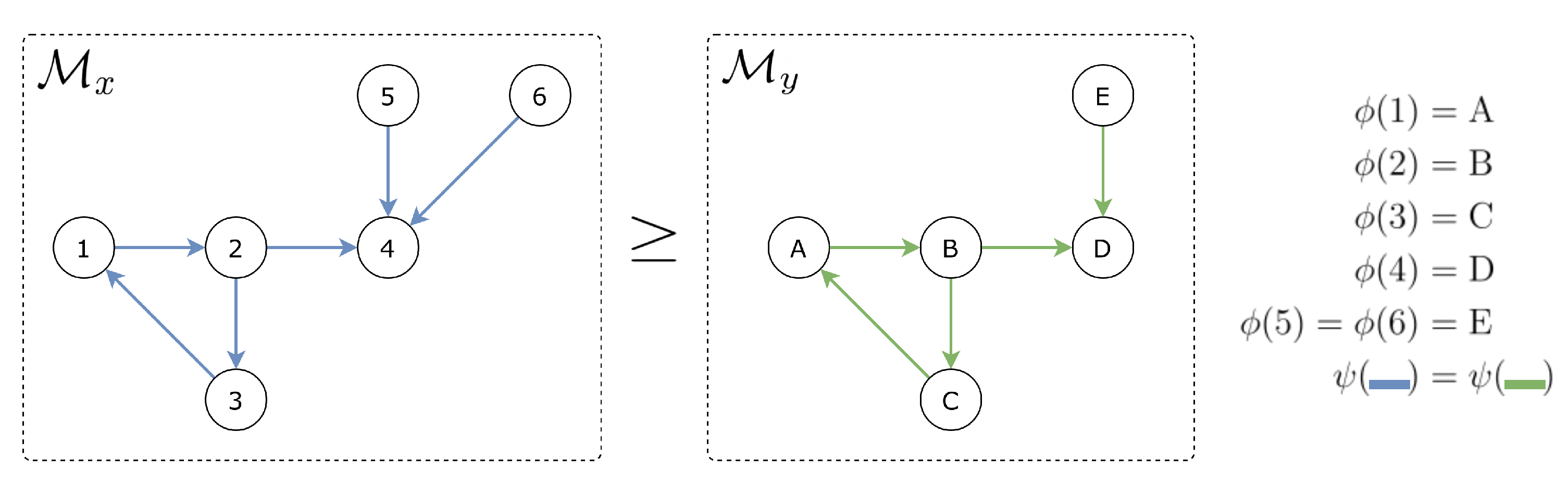
3. Problem Formulation
4. The Proposed DAIL-GAN Model
4.1. Feature Extractor Network F
4.2. Discriminator Network D and Generator Network G
4.3. Full Objective
| Algorithm 1: DAIL-GAN |
|
5. Performance Evaluation
5.1. Experimental Settings
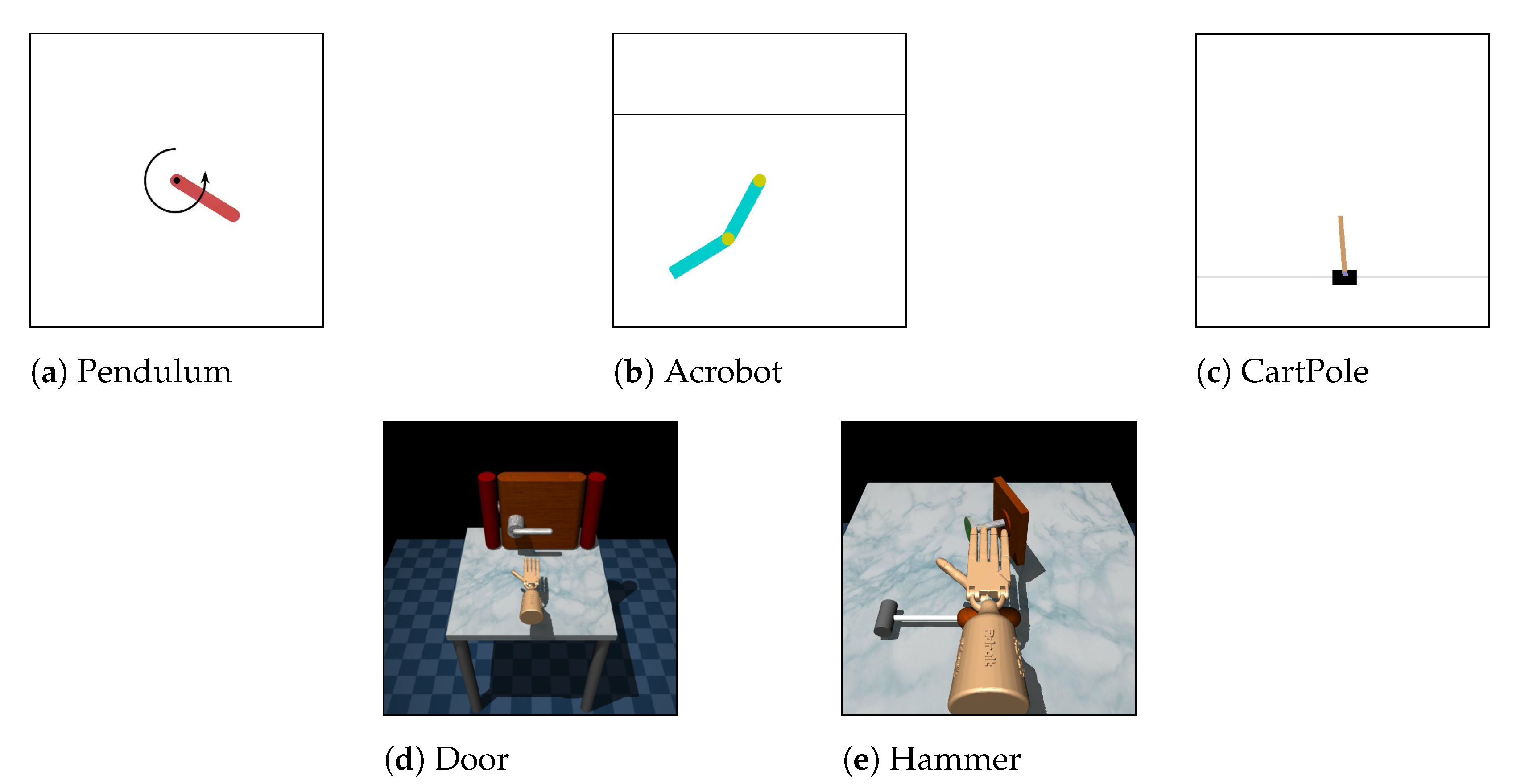
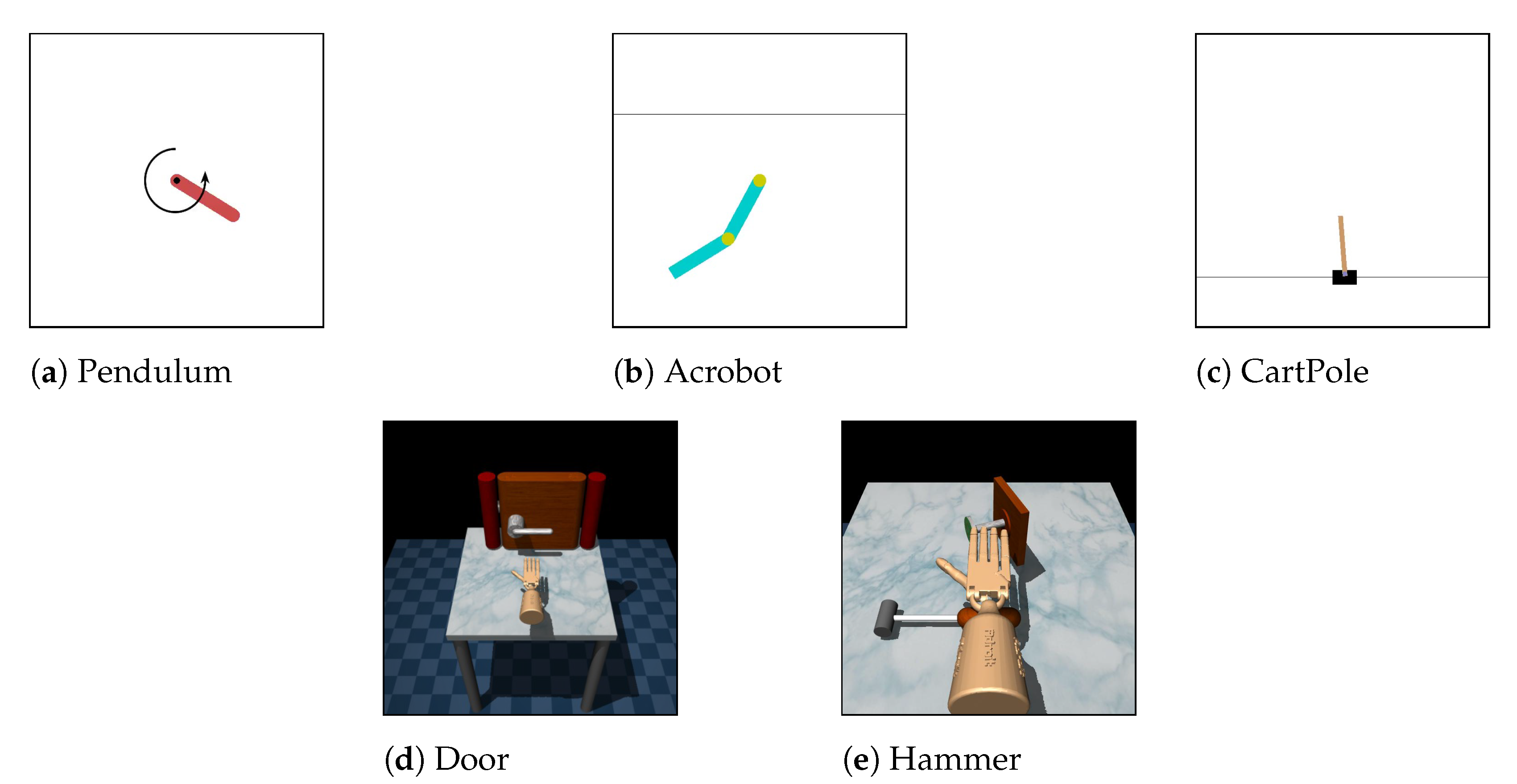
5.1.1. Environments
- Low-dimensional tasks:
- –
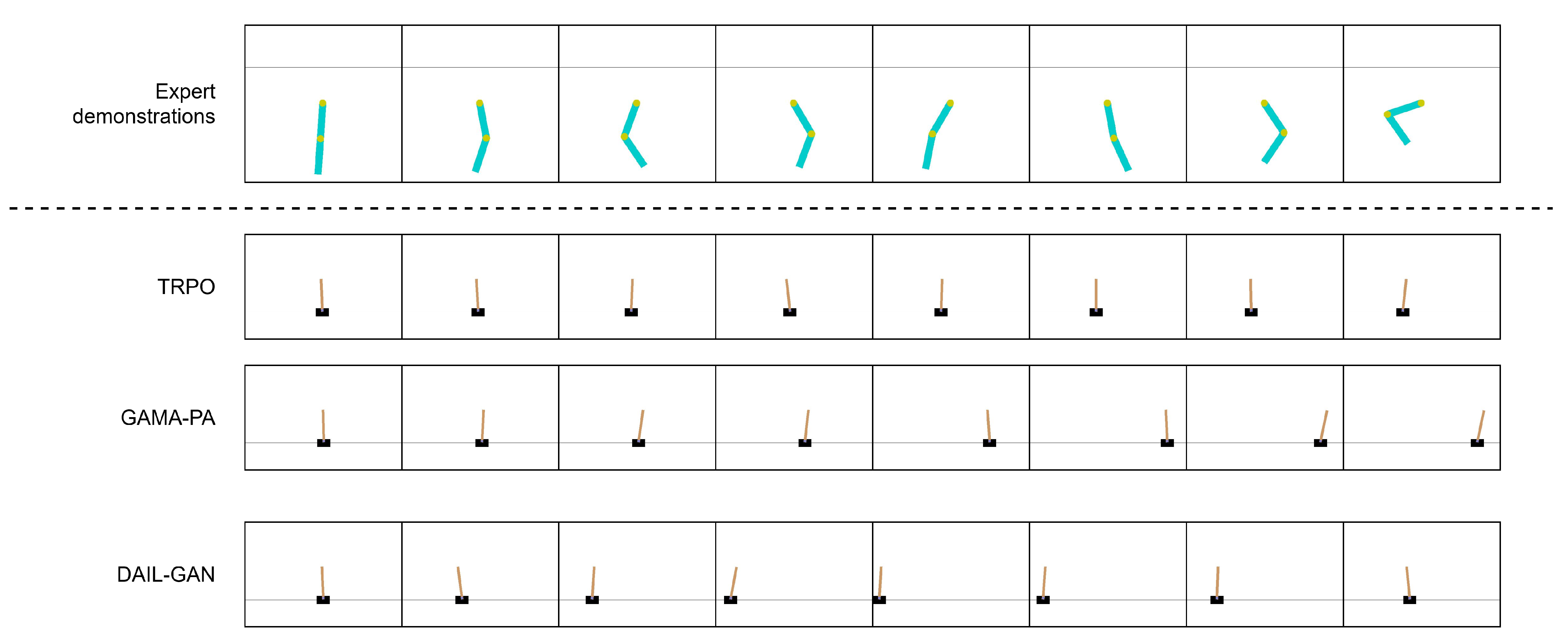
- Pendulum–Acrobot: Expert domain is Pendulum and learner domain is Acrobot.
- –
- Pendulum–CartPole: Expert domain is Pendulum and learner domain is CartPole.
- –
- Acrobot–CartPole: Expert domain is Acrobot and learner domain is CartPole.
To provide expert demonstrations, for each task, the Trust Region Policy Optimization method [42] is first trained on the expert domain using the shaped reward signal. Then, 20 expert demonstrations are collected by executing the learned policies in the expert domain simulator. Each demonstration includes a sequence of state–action pairs. It should be noted that we only collect successful demonstrations where the learned policies can accomplish the task. The impacts of demonstrations on the performance of the proposed model will be analyzed in our future work. - High-dimensional tasks:
- –
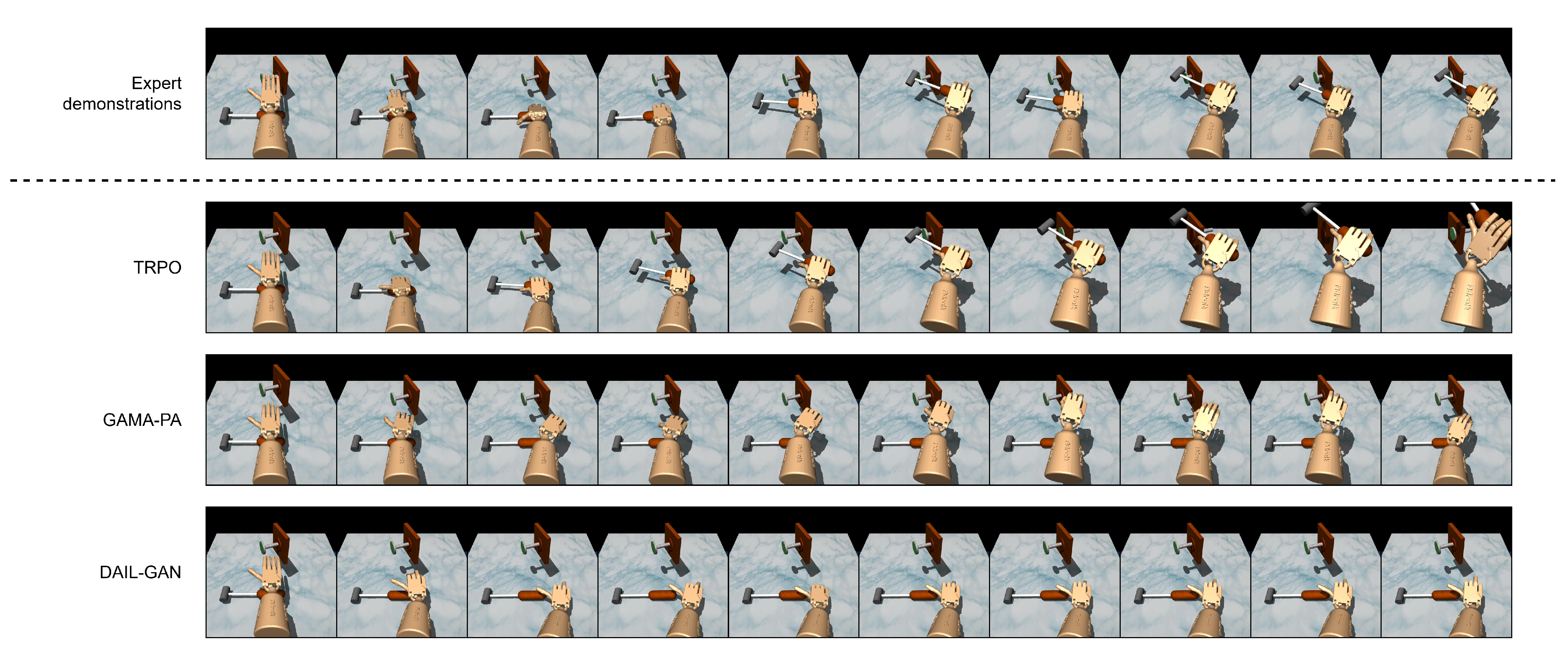
- Door–Door: The expert and learner domains have different friction parameters. The friction parameter in expert domain is , while, in the learner domains, it is .
- –
- Hammer–Hammer: The expert and learner domains have different mass of the hammer. The mass of the hammer in expert domain is 0.253442, while, in the learner domain, it is 1.0.
5.1.2. Baselines
- Trust Region Policy Optimization (TRPO) [42] is a Reinforcement learning-based model. The model was trained directly on the learner domain and had access to the shaped reward function. This baseline set an upper bound for the performance of domain adaptation algorithms.
- GAMA-PA [14]: The model introduced a two-step approach for domain adaptation in imitation learning. It first learns the state–action maps between expert and learner domains, and then utilizes it to learn an optimal policy. The model parameters are employed as reported in [14] in order to ensure a fair comparison.
5.1.3. Network Structure and Hyperparameters
5.2. Results
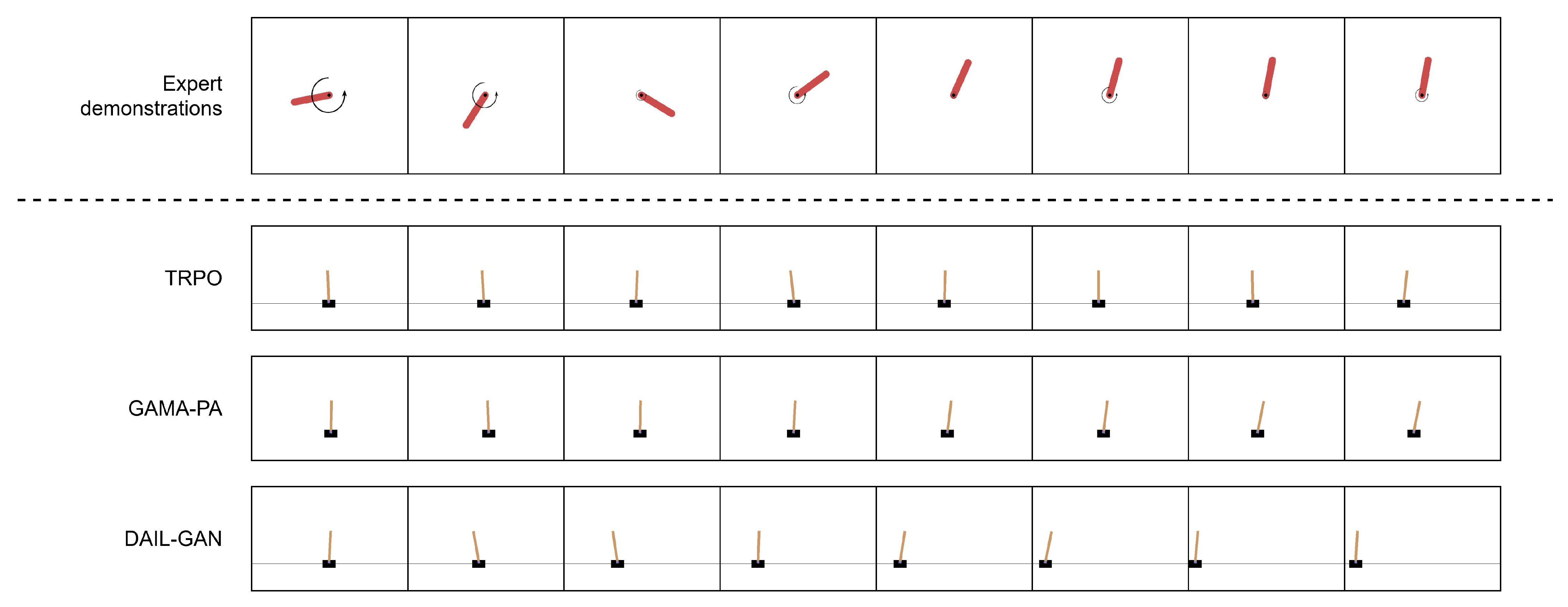
5.2.1. Low-Dimensional Tasks
5.2.2. High-Dimensional Tasks
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RL | Reinforcement Learning |
| IRL | Inverse Reinforcement Learning |
| GAN | Generative Adversarial Network |
| BC | Behavior Cloning |
| MDP | Markov Decision Process |
References
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Duan, Y.; Andrychowicz, M.; Stadie, B.C.; Ho, J.; Schneider, J.; Sutskever, I.; Abbeel, P.; Zaremba, W. One-shot imitation learning. arXiv 2017, arXiv:1703.07326. [Google Scholar]
- Sermanet, P.; Lynch, C.; Chebotar, Y.; Hsu, J.; Jang, E.; Schaal, S.; Levine, S.; Brain, G. Time-Contrastive Networks: Self-Supervised Learning from Video. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; Institute of Electrical and Electronics Engineers Inc.: Brisbane, Australia, 2018; pp. 1134–1141. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gupta, A.; Abbeel, P.; Levine, S. Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; Institute of Electrical and Electronics Engineers Inc.: Brisbane, Australia, 2018; pp. 1118–1125. [Google Scholar] [CrossRef] [Green Version]
- Schaal, S. Is imitation learning the route to humanoid robots? Trends Cogn. Sci. 1999, 3, 233–242. [Google Scholar] [CrossRef]
- Baker, C.L.; Tenenbaum, J.B.; Saxe, R.R. Goal inference as inverse planning. In Proceedings of the Annual Meeting of the Cognitive Science Society, Nashville, TN, USA, 1–4 August 2007; Volume 29. [Google Scholar]
- Bao, Y.; Cuijpers, R.H. On the imitation of goal directed movements of a humanoid robot. Int. J. Soc. Robot. 2017, 9, 691–703. [Google Scholar] [CrossRef] [Green Version]
- Tomov, M.S.; Schulz, E.; Gershman, S.J. Multi-task reinforcement learning in humans. Nat. Hum. Behav. 2021, 5, 764–773. [Google Scholar] [CrossRef] [PubMed]
- Ng, A.Y.; Russell, S.J. Algorithms for inverse reinforcement learning. In Proceedings of the ICML, Stanford, CA, USA, 29 June–2 July 2000; Volume 1, p. 2. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on MACHINE Learning, Banff, AB, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Levine, S.; Popovic, Z.; Koltun, V. Nonlinear inverse reinforcement learning with gaussian processes. Adv. Neural Inf. Process. Syst. 2011, 24, 19–27. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 4565–4573. [Google Scholar]
- Kim, K.; Gu, Y.; Song, J.; Zhao, S.; Ermon, S. Domain Adaptive Imitation Learning. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 5286–5295. [Google Scholar]
- Baram, N.; Anschel, O.; Caspi, I.; Mannor, S. End-to-End Differentiable Adversarial Imitation Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Sydney, Australia, 2017; Volume 70, pp. 390–399. [Google Scholar]
- Behbahani, F.; Shiarlis, K.; Chen, X.; Kurin, V.; Kasewa, S.; Stirbu, C.; Gomes, J.; Paul, S.; Oliehoek, F.A.; Messias, J.; et al. Learning from demonstration in the wild. In Proceedings of the IEEE 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 775–781. [Google Scholar]
- Li, Y.; Song, J.; Ermon, S. InfoGAIL: Interpretable Imitation Learning from Visual Demonstrations. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3815–3825. [Google Scholar]
- Zhang, X.; Li, Y.; Zhou, X.; Luo, J. cGAIL: Conditional Generative Adversarial Imitation Learning—An Application in Taxi Drivers’ Strategy Learning. IEEE Trans. Big Data 2020. [Google Scholar] [CrossRef]
- Chi, W.; Dagnino, G.; Kwok, T.M.; Nguyen, A.; Kundrat, D.; Abdelaziz, M.E.; Riga, C.; Bicknell, C.; Yang, G.Z. Collaborative robot-assisted endovascular catheterization with generative adversarial imitation learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2414–2420. [Google Scholar]
- Zhou, Y.; Fu, R.; Wang, C.; Zhang, R. Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning. Sensors 2020, 20, 5034. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network; Technical Report; Carnegie-Mellon Univ Pittsburgh pa Artificial Intelligence and Psychology: Pittsburgh, PA, USA, 1989. [Google Scholar]
- Rahmatizadeh, R.; Abolghasemi, P.; Bölöni, L.; Levine, S. Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3758–3765. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 49–58. [Google Scholar]
- Kalakrishnan, M.; Pastor, P.; Righetti, L.; Schaal, S. Learning objective functions for manipulation. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1331–1336. [Google Scholar]
- Arora, S.; Doshi, P. A survey of inverse reinforcement learning: Challenges, methods and progress. Artif. Intell. 2021, 297, 103500. [Google Scholar] [CrossRef]
- Naumann, M.; Sun, L.; Zhan, W.; Tomizuka, M. Analyzing the Suitability of Cost Functions for Explaining and Imitating Human Driving Behavior based on Inverse Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5481–5487. [Google Scholar]
- Bing, Z.; Lemke, C.; Cheng, L.; Huang, K.; Knoll, A. Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning. Neural Netw. 2020, 129, 323–333. [Google Scholar] [CrossRef] [PubMed]
- Zelinsky, G.J.; Chen, Y.; Ahn, S.; Adeli, H.; Yang, Z.; Huang, L.; Samaras, D.; Hoai, M. Predicting Goal-directed Attention Control Using Inverse-Reinforcement Learning. arXiv 2020, arXiv:2001.11921. [Google Scholar]
- KWON, H.; KIM, Y.; YOON, H.; CHOI, D. CAPTCHA Image Generation Systems Using Generative Adversarial Networks. IEICE Trans. Inf. Syst. 2018, 543–546. [Google Scholar] [CrossRef] [Green Version]
- Qi, M.; Li, Y.; Wu, A.; Jia, Q.; Li, B.; Sun, W.; Dai, Z.; Lu, X.; Zhou, L.; Deng, X.; et al. Multi-sequence MR image-based synthetic CT generation using a generative adversarial network for head and neck MRI-only radiotherapy. Med. Phys. 2020, 47, 1880–1894. [Google Scholar] [CrossRef]
- Song, J.; He, T.; Gao, L.; Xu, X.; Hanjalic, A.; Shen, H.T. Unified binary generative adversarial network for image retrieval and compression. Int. J. Comput. Vis. 2020, 128, 2243–2264. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Wang, Y.; Shu, H.; Wen, C.; Xu, C.; Shi, B.; Xu, C.; Xu, C. Distilling portable generative adversarial networks for image translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3585–3592. [Google Scholar]
- Stadie, B.C.; Abbeel, P.; Sutskever, I. Third-Person Imitation Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Sutton, R.S. Generalization in reinforcement learning: Successful examples using sparse coarse coding. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1996; pp. 1038–1044. [Google Scholar]
- Geramifard, A.; Dann, C.; Klein, R.H.; Dabney, W.; How, J.P. RLPy: A value-function-based reinforcement learning framework for education and research. J. Mach. Learn. Res. 2015, 16, 1573–1578. [Google Scholar]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Trans. Syst. Man Cybern. 1983, 5, 834–846. [Google Scholar] [CrossRef]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Kumar, V.; Todorov, E. Mujoco haptix: A virtual reality system for hand manipulation. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 657–663. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | State Space | Action Space | Description |
|---|---|---|---|
| Pendulum [37] | 3 (continuous) | 1 (continuous) | Swinging up a pendulum. |
| Acrobot [37,38,39] | 6 (continuous) | 3 (discrete) | Swinging the end of the lower link up to a given height |
| CartPole [37,40] | 4 (continuous) | 2 (discrete) | Preventing the pendulum from falling over by applying a force to the cart. |
| Door [41] | 39 (continuous) | 28 (continuous) | A 24-DoF hand attempts to undo the latch and swing the door open. |
| Hammer [41] | 46 (continuous) | 26 (continuous) | A 24-DoF hand attempts to use a hammer to drive the nail into the board. |
| Feature Extractor F | Generator G | Discriminator D | |
|---|---|---|---|
| Low-dimensional Tasks | - 32 - 32 - 16 | - 32 - 32 - | - 32 - 32 - 1 |
| High-dimensional Tasks | - 128 - 128 - 64 | - 128 - 64 - | - 128 - 64 - 1 |
| Task | TRPO [42] | GAMA-PA [14] | DAIL-GAN |
|---|---|---|---|
| Pendulum–Acrobot | −63.18 ± 7.05 | −386.31 ± 49.20 | −83.31 ± 32.61 |
| Pendulum–CartPole | 497.13 ± 28.56 | 144.03 ± 89.09 | 289.74 ± 171.21 |
| Acrobot–CartPole | 497.13 ± 28.56 | 93.05 ± 88.97 | 153.86 ± 81.79 |
| Task | TRPO [42] | GAMA-PA [14] | DAIL-GAN |
|---|---|---|---|
| Door–Door | 2449.06 ± 1175.25 | −65.19 ± 0.77 | −33.51 ± 8.87 |
| Hammer–Hammer | 17,030.25 ± 4357.23 | −252.52 ± 4.91 | −78.84 ± 19.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen Duc, T.; Tran, C.M.; Tan, P.X.; Kamioka, E. Domain Adaptation for Imitation Learning Using Generative Adversarial Network. Sensors 2021, 21, 4718. https://doi.org/10.3390/s21144718
Nguyen Duc T, Tran CM, Tan PX, Kamioka E. Domain Adaptation for Imitation Learning Using Generative Adversarial Network. Sensors. 2021; 21(14):4718. https://doi.org/10.3390/s21144718
Chicago/Turabian StyleNguyen Duc, Tho, Chanh Minh Tran, Phan Xuan Tan, and Eiji Kamioka. 2021. "Domain Adaptation for Imitation Learning Using Generative Adversarial Network" Sensors 21, no. 14: 4718. https://doi.org/10.3390/s21144718
APA StyleNguyen Duc, T., Tran, C. M., Tan, P. X., & Kamioka, E. (2021). Domain Adaptation for Imitation Learning Using Generative Adversarial Network. Sensors, 21(14), 4718. https://doi.org/10.3390/s21144718