
A Few-Shot U-Net Deep Learning Model for COVID-19 Infected Area Segmentation in CT Images

 ,
,  ,
, 
Abstract
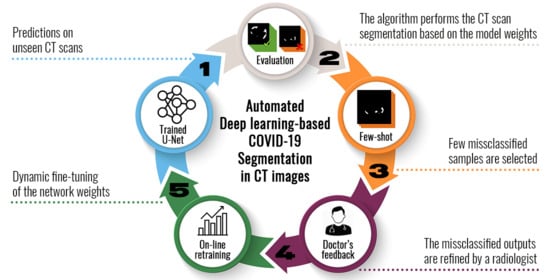
1. Introduction
2. Related Work
3. Materials and Methods
4. Employed Deep Learning Techniques: Moving from Local Processing to Global-Local Analysis
Local vs. Global-Local Processing
5. U-Nets for COVID-19 Segmentation
The Proposed Few-Shot U-Net Model
6. Experimental Results
6.1. Dataset Description
6.2. Implementation and Limitations of Mitigation Strategies
6.3. Experiments and Comparisons
6.3.1. Comparisons with Other Deep Learning Models
6.3.2. The Performance of the Proposed Few-Shot U-Net Model
7. Discussion
8. Conclusions and Future Work
- The proposed few-shot U-Net model, using 4-fold cross-validation results of the different classifiers, presented an IoU increment of 5.388 ± 3.046% for all test data compared to that of a conventional U-Net.
- Similarly, regarding the F1-Score, we observed an improvement of 5.394 ± 3.015%. As far as the precision and recall values were concerned, we observed an increment of 1.162 ± 2.137% and 4.409 ± 4.790% respectively.
- The p-value of the Kruskal-Wallis test on the obtained F1-score and IoU results, was 0.026 (less than 0.05) between the proposed few-shot U-Net model and the traditional one. That implies, with a confidence level of 95%, that a significant difference exists in the metrics of the two methods.
- The proposed model required few new incoming samples and roughly 8 images to efficiently adapt its behavior.
- The computational complexity of the proposed few-shot U-Net model was similar to that of the traditional U-Net since the new incoming data were combined with the previous samples to improve the generalization capabilities of the network.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef]
- Fernandes, N. Economic Effects of Coronavirus Outbreak (COVID-19) on the World Economy. SSRN Electron. J. 2020, 3557504. [Google Scholar] [CrossRef]
- Wordometers. Coronavirus Death Toll and Trends—Worldometer. Available online: https://www.worldometers.info/coronavirus/coronavirus-death-toll/ (accessed on 8 March 2021).
- Wadman, J.M.; Couzin-Frankel, J.; Kaiser, J.; Matacic, C. How does coronavirus kill? Clinicians trace a ferocious rampage through the body, from brain to toes. Science. 17 April 2020. Available online: https://www.sciencemag.org/news/2020/04/how-does-coronavirus-kill-clinicians-trace-ferocious-rampage-through-body-brain-toes (accessed on 7 May 2020).
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of Chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Wang, J.; Shi, J.; Wu, Z.; Wang, Q.; Tang, Z.; He, K.; Shi, Y.; Shen, D. Review of Artificial Intelligence Techniques in Imaging Data Acquisition, Segmentation, and Diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 2021, 14, 4–15. [Google Scholar] [CrossRef]
- Katsamenis, I.; Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N. Transfer Learning for COVID-19 Pneumonia Detection and Classification in Chest X-ray Images. In Proceedings of the 24th Pan-Hellenic Conference on Informatics, Athens, Greece, 20–22 November 2020. [Google Scholar]
- Calisto, M.B.; Lai-Yuen, K.L. AdaEn-Net: An ensemble of adaptive 2D-3D Fully Convolutional Networks for medical image segmentation. Neural Netw. 2020, 126, 76–94. [Google Scholar] [CrossRef] [PubMed]
- Saeedizadeh, N.; Minaee, S.; Kafieh, R.; Yazdani, S.; Sonka, M. COVID TV-UNet: Segmenting COVID-19 chest CT images using connectivity imposed U-Net. arXiv 2020, arXiv:2007.12303. [Google Scholar]
- Zheng, C.; Deng, X.; Fu, Q.; Zhou, Q.; Feng, J.; Ma, H.; Liu, W.; Wang, X. Deep learning-based detection for COVID-19 from chest CT using weak label. MedRxiv 2020. [Google Scholar] [CrossRef]
- Voulodimos, A.; Protopapadakis, E.; Katsamenis, I.; Doulamis, A.; Doulamis, N. Deep learning models for COVID-19 infected area segmentation in CT images. MedRxiv 2020. [Google Scholar] [CrossRef]
- Li, A.; Huang, W.; Lan, X.; Feng, J.; Li, Z.; Wang, L. Boosting Few-Shot Learning with Adaptive Margin Loss. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 12573–12581. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Li, Y.; Xia, L. Coronavirus Disease 2019 (COVID-19): Role of Chest CT in Diagnosis and Management. Am. J. Roentgenol. 2020, 214, 1280–1286. [Google Scholar] [CrossRef]
- Ding, X.; Xu, J.; Zhou, J.; Long, Q. Chest CT findings of COVID-19 pneumonia by duration of symptoms. Eur. J. Radiol. 2020, 127, 109009. [Google Scholar] [CrossRef]
- Meng, H.; Xiong, R.; He, R.; Lin, W.; Hao, B.; Zhang, L.; Lu, Z.; Shen, X.; Fan, T.; Jiang, W.; et al. CT imaging and clinical course of asymptomatic cases with COVID-19 pneumonia at admission in Wuhan, China. J. Infect. 2020, 81, e33–e39. [Google Scholar] [CrossRef]
- 1Abbas, A.; Abdelsamea, M.M.; Gaber, M.M. Classification of COVID-19 in chest X-ray images using DeTraC deep convo-lutional neural network. Appl. Intell. 2021, 51, 854–864. [Google Scholar]
- Kenny, E.S. An Illustrated Guide to the Chest CT in COVID-19. PulmCCM. 16 March 2020. Available online: https://pulmccm.org/uncategorized/an-illustrated-guide-to-the-chest-ct-in-covid-19/ (accessed on 6 May 2020).
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Le, N.Q.K. Fertility-GRU: Identifying Fertility-Related Proteins by Incorporating Deep-Gated Recurrent Units and Original Position-Specific Scoring Matrix Profiles. J. Proteome Res. 2019, 18, 3503–3511. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 2020, 200905. [Google Scholar] [CrossRef]
- Islam, Z.; Islam, M.; Asraf, A. A combined deep CNN-LSTM network for the detection of novel coronavirus (COVID-19) using X-ray images. Inform. Med. Unlocked 2020, 20, 100412. [Google Scholar] [CrossRef]
- Fan, D.-P.; Zhou, T.; Ji, G.-P.; Zhou, Y.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Inf-Net: Automatic COVID-19 Lung Infection Segmentation From CT Images. IEEE Trans. Med. Imaging 2020, 39, 2626–2637. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Gozes, O.; Frid‑Adar, M.; Greenspan, H.; Browning, P.D.; Zhang, H.; Ji, W.; Bernheim, A.; SIiegel, E. Rapid ai development cycle for the coronavirus (covid-19) pandemic: Initial results for automated detection & patient monitoring using deep learning ct image analysis. arXiv 2020, arXiv:2003.05037. [Google Scholar]
- Wu, X.; Hui, H.; Niu, M.; Li, L.; Wang, L.; He, B.; Yang, X. Deep learning-based multi-view fusion model for screening 2019 novel coro- navirus pneumonia: A multicentre study. Eur. J. Radiol. 2020, 128, 109041. [Google Scholar] [CrossRef]
- Baldeon-Calisto, M.; Lai-Yuen, S.K. AdaResU-Net: Multiobjective adaptive convolutional neural network for medical image segmentation. Neurocomputing 2020, 392, 325–340. [Google Scholar] [CrossRef]
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Chen, Q.; Huang, S.; Yang, M.; Yang, X.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convo- lutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef] [PubMed]
- Cifci, M.A. Deep learning model for diagnosis of corona virus disease from CT images. Int. J. Sci. Eng. Res. 2020, 11, 273–278. [Google Scholar]
- Singh, D.; Kumar, V.; Kaur, M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution-based convolutional neural networks. Eur. J. Clin. Microbiol. Infect. Dis. 2020, 39, 1379–1389. [Google Scholar] [CrossRef]
- Farid, A.A.; Selim, G.I.; Khater, H.A.A. A Novel Approach of CT Images Feature Analysis and Prediction to Screen for Corona Virus Disease (COVID-19). Int. J. Sci. Eng. Res. 2020, 11, 1141–1149. [Google Scholar] [CrossRef]
- Hu, S.; Gao, Y.; Niu, Z.; Jiang, Y.; Li, L.; Xiao, X.; Wang, M.; Fang, E.F.; Menpes-Smith, W.; Xia, J.; et al. Weakly Supervised Deep Learning for COVID-19 Infection Detection and Classification from CT Images. IEEE Access 2020, 8, 118869–118883. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Akram, T.; Attique, M.; Gul, S.; Shahzad, A.; Altaf, M.; Naqvi, S.S.R.; Damaševičius, R.; Maskeliūnas, R. A novel framework for rapid diagnosis of COVID-19 on computed tomography scans. Pattern Anal. Appl. 2021, 1–14. [Google Scholar] [CrossRef]
- Chakraborty, S.; Mali, K. SuFMoFPA: A superpixel and meta-heuristic based fuzzy image segmentation approach to explicate COVID-19 radiological images. Expert Syst. Appl. 2021, 167, 114142. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Standford, CA, USA, 25–28 October 2016; IEEE: New York, NY, USA, 2016; pp. 565–571. [Google Scholar]
- Shan, F.; Gao, Y.; Wang, J.; Shi, W.; Shi, N.; Han, M.; Xue, Z.; Shen, D.; Shi, Y. Lung infection quantification of covid-19 in ct images with deep learning. arXiv 2020, arXiv:2003.04655. [Google Scholar]
- Abdel-Basset, M.; Chang, V.; Hawash, H.; Chakrabortty, R.K.; Ryan, M. FSS-2019-nCov: A deep learning architecture for semi-supervised few-shot segmentation of COVID-19 infection. Knowl. Based Syst. 2021, 212, 106647. [Google Scholar] [CrossRef]
- Shi, W.; Peng, X.; Liu, T.; Cheng, Z.; Lu, H.; Yang, S.; Zhang, J.; Wang, M.; Gao, Y.; Shi, Y.; et al. A Deep learning-based quantitative computed tomography model in predicting the severity of COVID-19: A retrospective study in 196 patients. Ann. Transl. Med. 2020, 9, 216. [Google Scholar] [CrossRef]
- Shi, F.; Xia, L.; Shan, F.; Song, B.; Wu, D.; Wei, Y.; Yuan, H.; Jiang, H.; He, Y.; Gao, Y.; et al. Large-scale screening of COVID-19 from community acquired pneumonia using infection size-aware classification. Phys. Med. Biol. 2021. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Stathaki, T. Automatic crack detection for tunnel inspection using deep learning and heuristic image post-processing. Appl. Intell. 2019, 49, 2793–2806. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Saito, S.; Li, T.; Li, H. Real-Time Facial Segmentation and Performance Capture from RGB Input. In Proceedings of the Lecture Notes in Computer Science; J.B. Metzler: Stuttgart, Germany, 2016; pp. 244–261. [Google Scholar]
- Garcia-Peraza-Herrera, L.C.; Li, W.; Gruijthuijsen, C.; Devreker, A.; Attilakos, G.; Deprest, J.; Poorten, E.V.; Stoyanov, D.; Vercauteren, T.; Ourselin, S. Real-Time Segmentation of Non-rigid Surgical Tools Based on Deep Learning and Tracking. In Lecture Notes in Computer Science; J.B. Metzler: Stuttgart, Germany, 2017; pp. 84–95. [Google Scholar]
- Dong, H.; Yang, G.; Liu, F.; Mo, Y.; Guo, Y. Automatic Brain Tumor Detection and Segmentation Using U-Net Based Fully Convolutional Networks. In Proceedings of the Advances in Service-Oriented and Cloud Computing; J.B. Metzler: Stuttgart, Germany, 2017; pp. 506–517. [Google Scholar]
- Doulamis, N.; Doulamis, A. Semi-supervised deep learning for object tracking and classification. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2014; pp. 848–852. [Google Scholar]
- Radiopaedia.org. Available online: https://radiopaedia.org/ (accessed on 4 May 2020).
- Ma, J.; Ge, C.; Wang, Y.; An, X.; Gao, J.; Yu, Z.; Zhang, M.; Liu, X.; Deng, X.; Cao, S.; et al. COVID-19 CT Lung and Infection Segmentation Dataset. Zenodo 2020. [Google Scholar] [CrossRef]
- Ma, J.; Wang, Y.; An, X.; Ge, C.; Yu, Z.; Chen, J.; Zhu, Q.; Dong, G.; He, J.; He, Z.; et al. Towards Efficient COVID-19 CT Annotation: A Benchmark for Lung and Infection Segmentation. arXiv 2020, arXiv:2004.12537. [Google Scholar]
- Khan, A.I.; Shah, J.L.; Bhat, M.M. CoroNet: A deep neural network for detection and diagnosis of COVID-19 from chest x-ray images. Comput. Methods Programs Biomed. 2020, 196, 105581. [Google Scholar] [CrossRef]
- Ma, X.; Ng, M.; Xu, S.; Xu, Z.; Qiu, H.; Liu, Y.; Lyu, J.; You, J.; Zhao, P.; Wang, S.; et al. Development and validation of prognosis model of mortality risk in patients with COVID-19. Epidemiol. Infect. 2020, 148, 1–25. [Google Scholar] [CrossRef]
- Doumpos, M.; Doulamis, A.; Zopounidis, C.; Protopapadakis, E.; Niklis, D. Sample selection algorithms for credit risk modelling through data mining techniques. Int. J. Data Min. Model. Manag. 2019, 11, 103. [Google Scholar] [CrossRef]
- Makantasis, K.; Protopapadakis, E.; Doulamis, A.; Matsatsinis, N. Semi-supervised vision-based maritime surveillance system using fused visual attention maps. Multimed. Tools Appl. 2015, 75, 15051–15078. [Google Scholar] [CrossRef]
- Kaselimi, M.; Doulamis, N.; Doulamis, A.; Voulodimos, A.; Protopapadakis, E. Bayesian-optimized Bidirectional LSTM Regression Model for Non-intrusive Load Monitoring. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 2747–2751. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hy-perparameter optimization. J. Mach. Learn. Res. 2016, 18, 6765–6816. [Google Scholar]
- Versaci, M.; Morabito, F.C.; Angiulli, G. Adaptive Image Contrast Enhancement by Computing Distances into a 4-Dimensional Fuzzy Unit Hypercube. IEEE Access 2017, 5, 26922–26931. [Google Scholar] [CrossRef]
- Polat, K.; Şahan, S.; Güneş, S. A new method to medical diagnosis: Artificial immune recognition system (AIRS) with fuzzy weighted pre-processing and application to ECG arrhythmia. Expert Syst. Appl. 2006, 31, 264–269. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. COVID-19 detection using deep learning models to exploit Social Mimic Optimization and structured chest X-ray images using fuzzy color and stacking approaches. Comput. Biol. Med. 2020, 121, 103805. [Google Scholar] [CrossRef]
- Kruskal, W.H.; Wallis, W.A. Use of Ranks in One-Criterion Variance Analysis. J. Am. Stat. Assoc. 1952, 47, 583. [Google Scholar] [CrossRef]
- Han, Z.; Ma, H.; Shi, G.; He, L.; Wei, L.; Shi, Q. A review of groundwater contamination near municipal solid waste landfill sites in China. Sci. Total. Environ. 2016, 569–570, 1255–1264. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques/Models | Works | Number of Classes |
|---|---|---|
| Convolutional Neural Networks (CNN) | [14] | 2 (COVID-19, non-pneumonia) |
| [20] | 3 (COVID-19, CAP, non-pneumonia) | |
| [32] | 2 (COVID-19, SARS) | |
| U-Net | [6,25,28] | 2 (COVID-19, non-pneumonia) |
| LSTM-CNN | [22] | 2 (COVID-19, non-pneumonia) |
| CNN + Fuzzy Inference System | [31] | 2 (COVID-19, non-pneumonia) |
| ResNet50 | [26] | 3 (COVID-19, CAP, non-pneumonia) |
| AlexNet, Inception-V4 | [30] | 2 (COVID-19, other disease) |
| AlexNet, VGG-16, VGG-19, SqueezeNet, GoogleNet, MobileNet-V2, ResNet-18, ResNet-50, ResNet-101, and Xception | [29] | 2 (COVID-19, non-pneumonia) |
| Volumetric Medical Image segmentation networks (V-Net) | [37,40] | 2 (COVID-19, non-pneumonia) |
| Random Forests | [41] | 3 (COVID-19, CAP, non-pneumonia) |
| Genetic Algorithm + Naïve Bayes | [35] | 2 (COVID-19, non-pneumonia) |
| Type 2 fuzzy clustering + Fuzzy Modified Flower Pollination Algorithm | [36] | 2 (COVID-19, non-pneumonia) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Voulodimos, A.; Protopapadakis, E.; Katsamenis, I.; Doulamis, A.; Doulamis, N. A Few-Shot U-Net Deep Learning Model for COVID-19 Infected Area Segmentation in CT Images. Sensors 2021, 21, 2215. https://doi.org/10.3390/s21062215
Voulodimos A, Protopapadakis E, Katsamenis I, Doulamis A, Doulamis N. A Few-Shot U-Net Deep Learning Model for COVID-19 Infected Area Segmentation in CT Images. Sensors. 2021; 21(6):2215. https://doi.org/10.3390/s21062215
Chicago/Turabian StyleVoulodimos, Athanasios, Eftychios Protopapadakis, Iason Katsamenis, Anastasios Doulamis, and Nikolaos Doulamis. 2021. "A Few-Shot U-Net Deep Learning Model for COVID-19 Infected Area Segmentation in CT Images" Sensors 21, no. 6: 2215. https://doi.org/10.3390/s21062215
APA StyleVoulodimos, A., Protopapadakis, E., Katsamenis, I., Doulamis, A., & Doulamis, N. (2021). A Few-Shot U-Net Deep Learning Model for COVID-19 Infected Area Segmentation in CT Images. Sensors, 21(6), 2215. https://doi.org/10.3390/s21062215