
Application of Machine Learning for Fenceline Monitoring of Odor Classes and Concentrations at a Wastewater Treatment Plant

Abstract
:1. Introduction
2. Materials and Methods
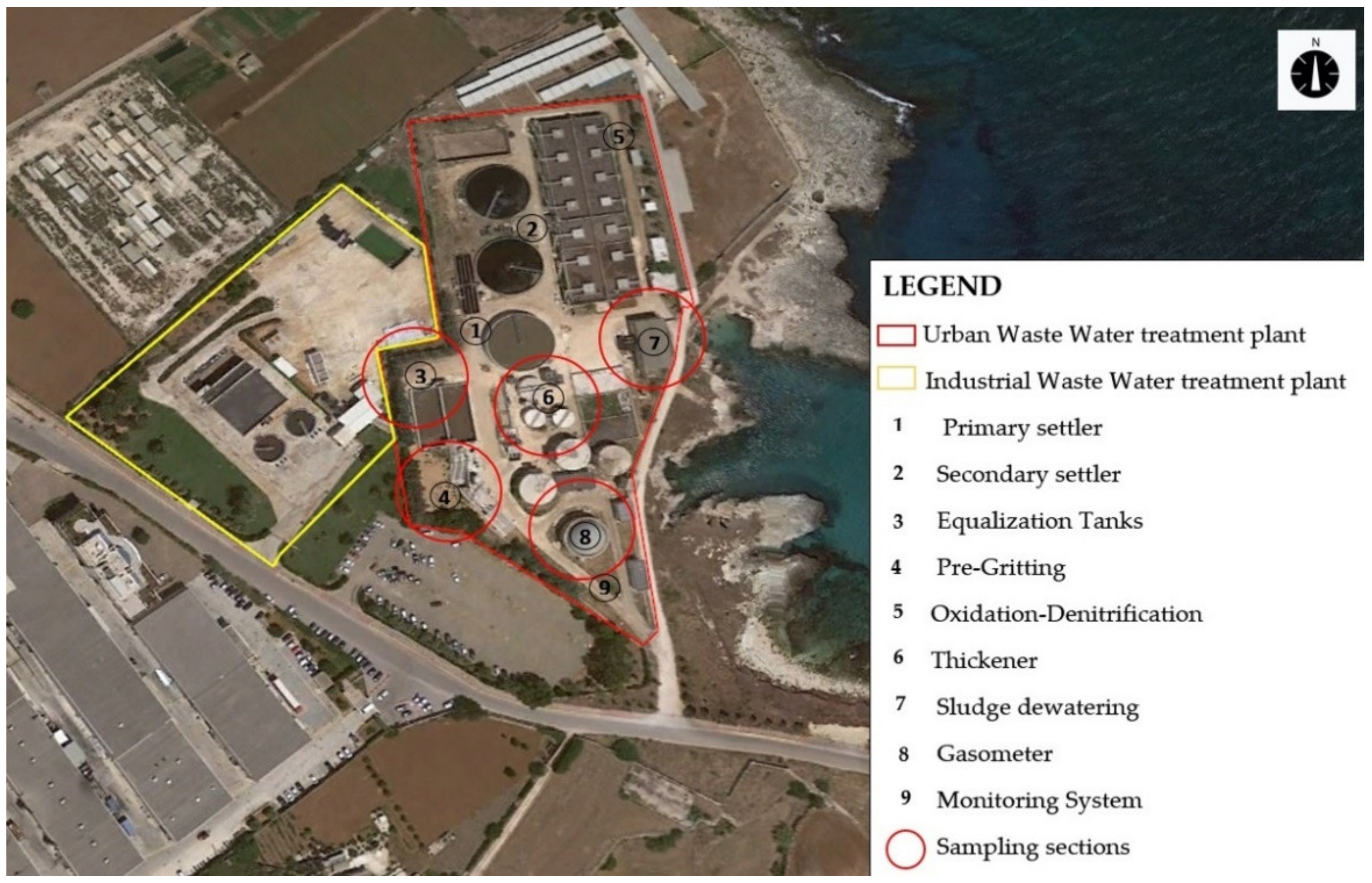
2.1. Odor Emission Source Characterization
2.2. Experimental Protocol for Data Acquisition
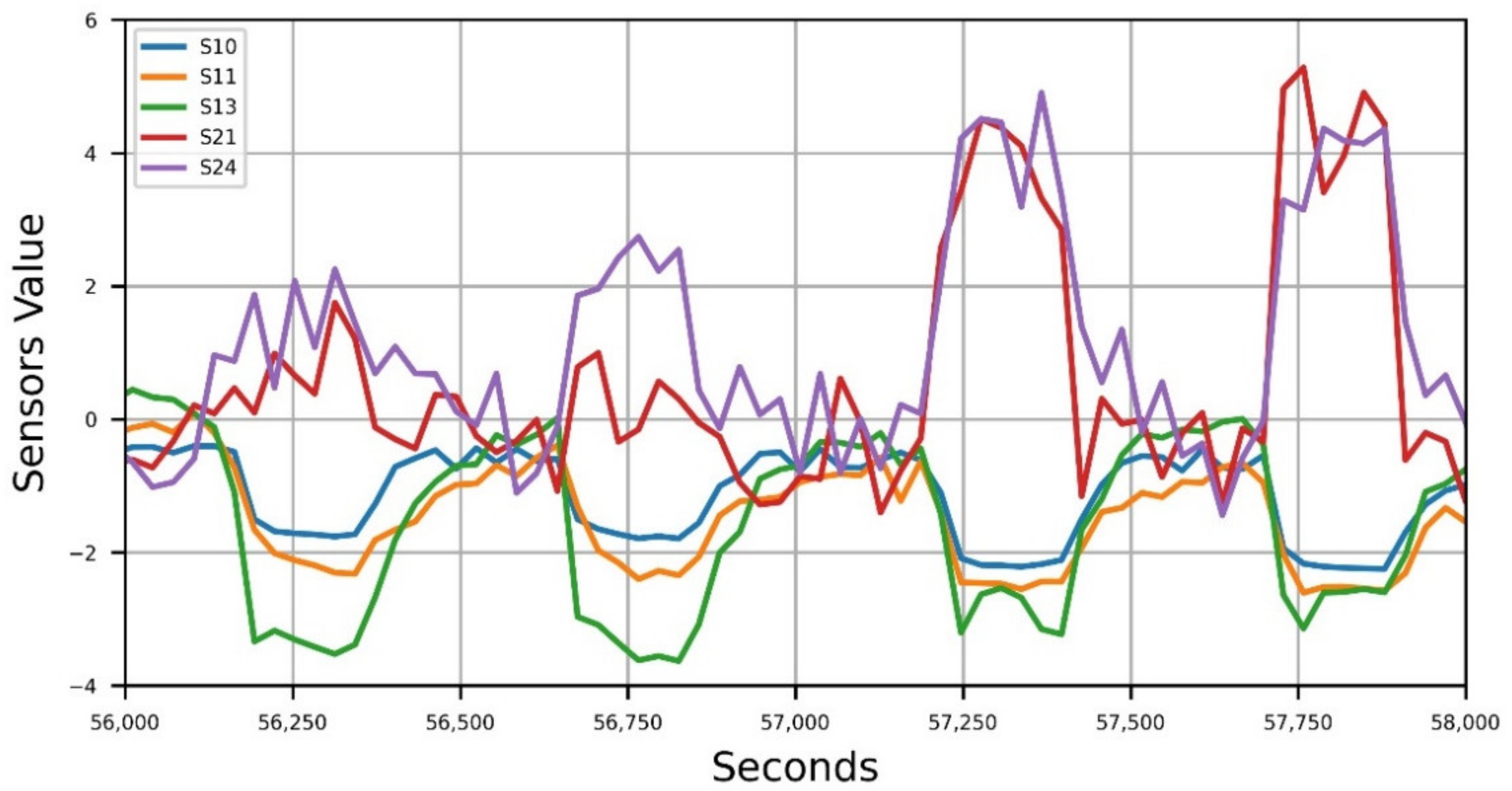
2.3. Data Pretreatment
2.4. Algorithms for Odor Classification and Regression
2.4.1. Feature Extraction and General Workflow
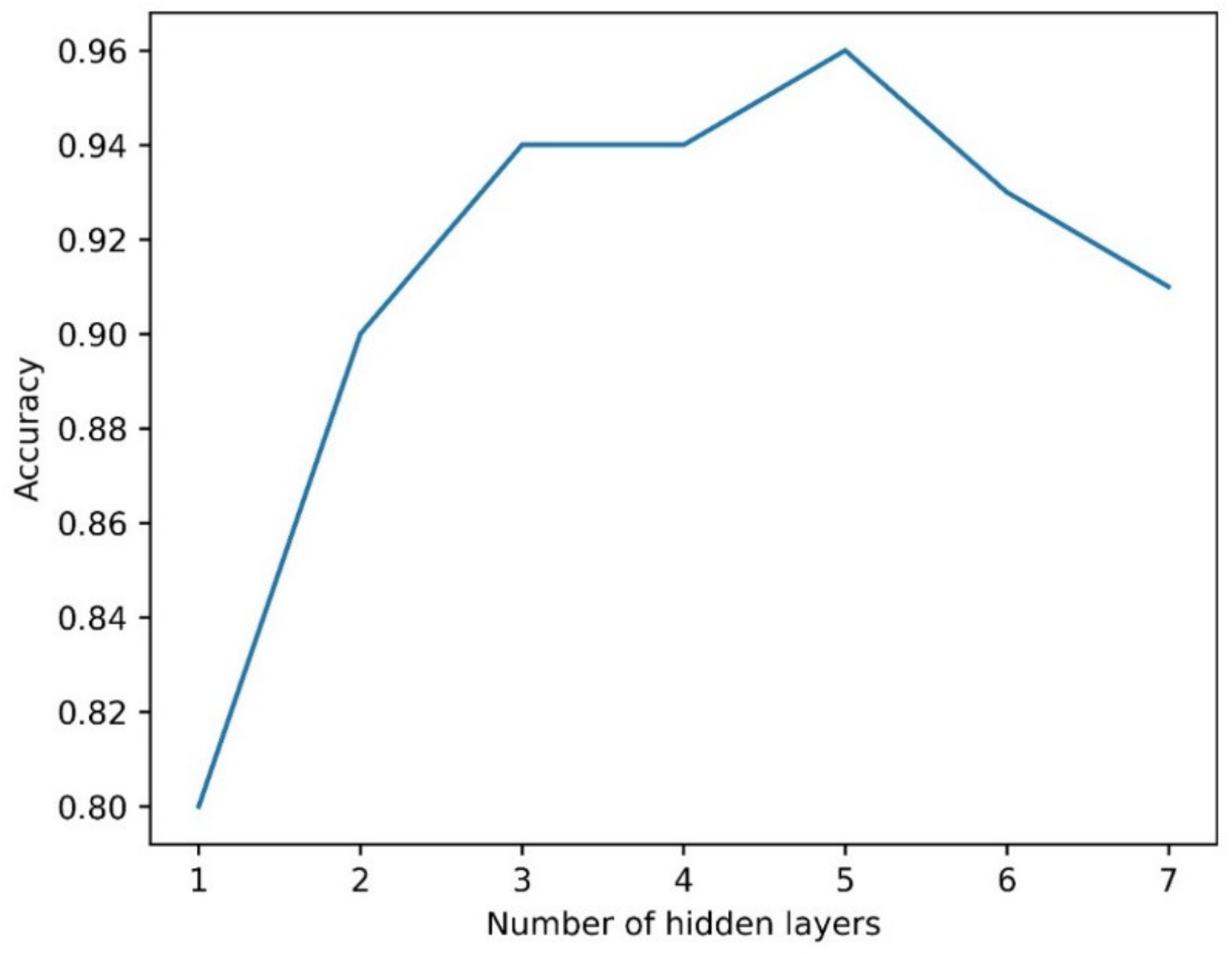
2.4.2. Artificial Neural Network
- First, a single hidden layer was employed, the accuracy was calculated, and then other layers were added until the appropriate accuracy was obtained;
- In order to further increase the accuracy, an increasing number of neurons per layer was tested, starting from 10.
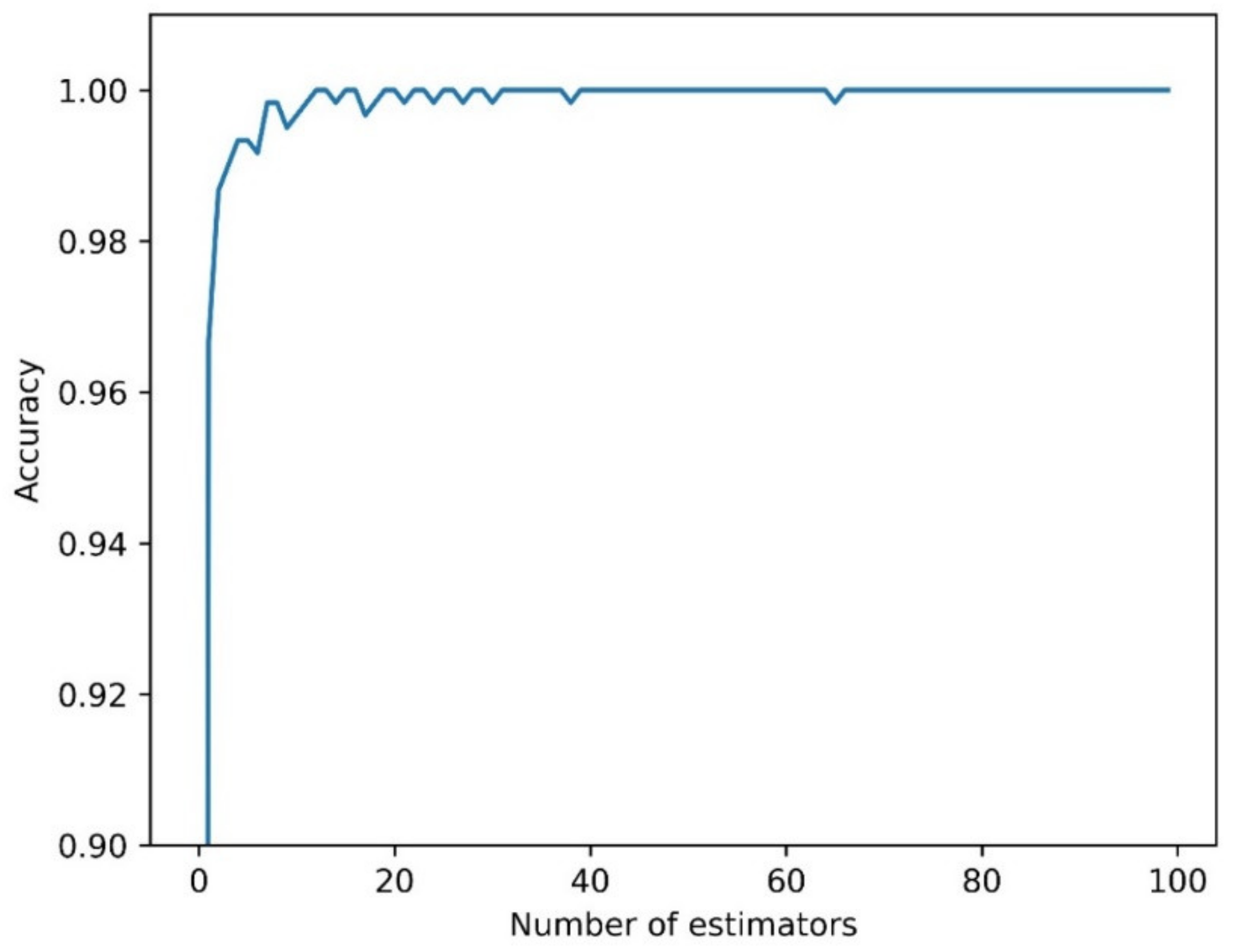
2.4.3. Random Forest
3. Results and Discussion
3.1. Feature Selection
3.2. Classification
3.3. Regression
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hayes, J.E.; Stevenson, R.J.; Stuetz, R.M. The impact of malodour on communities: A review of assessment techniques. Sci. Total Environ. 2014, 500, 395–407. [Google Scholar] [CrossRef]
- Bokowa, A.; Diaz, C.; Koziel, J.A.; McGinley, M.; Barclay, J.; Schauberger, G.; Guillot, J.-M.; Sneath, R.; Capelli, L.; Zorich, V.; et al. Summary and overview of the odour regulations worldwide. Atmosphere 2021, 12, 206. [Google Scholar] [CrossRef]
- General Determinations Regarding the Characterization of Atmospheric Emissions from Activities with a High Odour Impact, D.g.r. 15 February 2012–n. IX/3018. Available online: http://www.olfattometria.com/download/dgr-lomb.pdf (accessed on 2 July 2021).
- Law on Odour Emissions. L.R. 16 July 2018–n. 32. Available online: http://www.ager.puglia.it/documents/10192/29519220/LR_32_2018.pdf (accessed on 2 July 2021).
- Brattoli, M.; Mazzone, A.; Giua, R.; Assennato, G.; de Gennaro, G. Automated Collection of Real-Time Alerts of Citizens as a Useful Tool to Continuously Monitor Malodorous Emissions. Int. J. Environ. Res. Pub. Health 2016, 13, 263. [Google Scholar] [CrossRef] [Green Version]
- Real Time, Automatic and Remote-Activated Sampling System for Industrial Odour Emissions Compliant with the European Standard EN 13725, CORDIS EU Research Results. Available online: cordis.europa.eu/project/id/756865 (accessed on 2 July 2021).
- Lotesoriere, B.; Giacomello, A.; Bax, C.; Capelli, L. The Italian Pilot Study of the D-NOSES Project: An Integrated Approach Involving Citizen Science and Olfactometry to Identify Odour Sources in the Area of Castellanza (VA). Chem. Eng. Trans. 2021, 85, 145–150. [Google Scholar]
- Karakaya, D.; Ulucan, O.; Turkan, M. Electronic Nose and Its Applications: A Survey. Int. J. Aut. Comp. 2020, 17, 179–209. [Google Scholar] [CrossRef] [Green Version]
- Stuetz, R.M.; Fenner, R.A.; Engin, G. Assessment of odours from sewage treatment works by an electronic nose, H2S analyzer and olfactometry. Water Res. 1999, 33, 453–461. [Google Scholar] [CrossRef]
- Qu, G.; Omotoso, M.M.; el-Din, M.G.; Feddes, J.J.R. Development of an integrated sensor to measure odors. Environ. Monit. Assess. 2008, 144, 277–283. [Google Scholar] [CrossRef]
- Bax, C.; Sironi, S.; Capelli, L. How Can Odors Be Measured? An Overview of Methods and Their Applications. Atmosphere 2020, 11, 92. [Google Scholar] [CrossRef] [Green Version]
- Yan, J.; Guo, X.; Duan, S.; Jia, P.; Wang, L.; Peng, C.; Zhang, S. Electronic Nose Feature Extraction Methods: A Review. Sensors 2015, 15, 27804–27831. [Google Scholar] [CrossRef] [PubMed]
- Zarra, T.; Galang, M.G.K.; Ballesteros, F.C., Jr.; Belgiorno, V.; Naddeo, V. Instrumental Odour Monitoring System Classification Performance Optimization by Analysis of Different Pattern-Recognition and Feature Extraction Techniques. Sensors 2021, 21, 114. [Google Scholar] [CrossRef]
- Vanarse, A.; Espinosa-Ramos, J.I.; Osseiran, A.; Rassau, A.; Kasabov, N. Application of a Brain-Inspired Spiking Neural Network Architecture to Odor Data Classification. Sensors 2020, 20, 2756. [Google Scholar] [CrossRef] [PubMed]
- Wen, T.; Mo, Z.; Li, J.; Liu, Q.; Wu, L.; Luo, D. An Odor Labeling Convolutional Encoder–Decoder for Odor Sensing in Machine Olfaction. Sensors 2021, 21, 388. [Google Scholar] [CrossRef]
- Yan, L.; Wu, C.; Liu, J. Visual Analysis of Odor Interaction Based on Support Vector Regression Method. Sensors 2020, 20, 1707. [Google Scholar] [CrossRef] [Green Version]
- Misselbrook, T.H.; Hobbs, P.J.; Persaud, K.C. Use of an Electronic Nose to Measure Odour Concentration Following Application of Cattle Slurry to Grassland. J. Agric. Eng. Res. 1997, 66, 213–220. [Google Scholar] [CrossRef]
- Aguilera, T.; Lozano, J.; Paredes, J.; Álvarez, F.; Suárez, J. Electronic nose based on independent component analysis combined with partial least squares and artificial neural networks for wine prediction. Sensors 2012, 12, 8055–8072. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.; Nie, H.; Dang, L.; Li, G.; Ye, Q.; Kadri, C. Classification of multiple indoor air contaminants by an electronic nose and a hybrid support vector machine. Sens. Actuators B Chem. 2012, 174, 114–125. [Google Scholar] [CrossRef]
- Men, H.; Fu, S.; Yang, J.; Cheng, M.; Shi, Y.; Liu, J. Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples. Sensors 2018, 18, 285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cangialosi, F.; Intini, G.; Colucci, D. On Line Monitoring of Odour Nuisance at a Sanitary Landfill for Non-Hazardous Waste. Chem. Eng. Trans. 2018, 68, 127–132. [Google Scholar]
- Bax, C.; Lotesoriere, B.; Capelli, L. Real-time Monitoring of Odour Concentration at a Landfill Fenceline: Performance Verification in the Field. Chem. Eng. Trans. 2021, 85, 19–24. [Google Scholar]
- Cangialosi, F. Advanced Data Mining for Odour Emissions Monitoring: Experimental Peak-to-mean Calculations and Spectral Analysis of Data Derived from Ioms in two waste Treatment Plants. Chem. Eng. Trans. 2021, 85, 7–12. [Google Scholar]
- Majchrzak, T.; Wojnowski, W.; Dymerski, T.; Gębicki, J.; Namieśnik, J. Electronic noses in classification and quality control of edible oils: A review. Food Chem. 2018, 246, 192–201. [Google Scholar] [CrossRef]
- Tan, J.; Xu, J. Applications of electronic nose (e-nose) and electronic tongue (e-tongue) in food quality-related properties determination: A. review. Artific. Intell. Agric. 2020, 4, 104–105. [Google Scholar] [CrossRef]
- Wijaya, D.R.; Sarno, R.; Zulaika, E. DWTLSTM for electronic nose signal processing in beef quality monitoring. Sens. Actuators B Chem. 2021, 326. [Google Scholar] [CrossRef]
- Bax, C.; Sironi, S.; Capelli, L. Definition and Application of a Protocol for Electronic Nose Field Performance Testing: Example of Odor Monitoring from a Tire Storage Area. Atmosphere 2020, 11, 426. [Google Scholar] [CrossRef] [Green Version]
- Oliva, G.; Zarra, T.; Pittoni, V.; Senatore, V.; Galang, M.G.M.; Castellani, M.; Belgiorno, V.; Naddeo, V. Next-generation of instrumental odour monitoring system (IOMS) for the gaseous emissions control in complex industrial plants. Chemosphere 2021, 271, 129768. [Google Scholar] [CrossRef] [PubMed]
- Research Project ASPIDI. Available online: https://www.progettoaspidi.com (accessed on 2 June 2021).
- Galang, M.G.; Zarra, T.; Naddeo, V.; Belgiorno, V.; Ballesteros, F.C., Jr. Artificial Neural Network in the Measurement of Environmental Odours by E-Nose. Chem. Eng. Trans. 2018, 68, 247–252. [Google Scholar]
- Zarra, T.; Galang, M.G.; Ballesteros, F.; Naddeo, V.; Belgiorno, V. Environmental odour management by artificial neural network—A review. Environ. Int. 2019, 133, 105189. [Google Scholar] [CrossRef]
- Naddeo, V.; Zarra, T.; Oliva, G.; Kubo, A.; Ukida, N.; Higuchi, T. Odour measurement in wastewater treatment plant by a new prototype of e.Nose: Correlation and comparison study with reference to both European and Japanese approaches. Chem. Eng. Trans. 2016, 54, 85–90. [Google Scholar]
- Guidelines for Issuing Technical Opinions Regarding the Emissions into Atmosphere Produced by Wastewater Treatment Plant. ARPA Puglia (rev. 2014). Available online: https://old.arpa.puglia.it/c/document_library/get_file?uuid=6e747fc8-859a-4cd6-9302-bb73913f7410&groupId=13879 (accessed on 2 June 2021).
- UNI 11761:2019; Emissioni e Qualità Dell’aria-Determinazione Degli Odori Tramite IOMS (Instrumental Odour Monitoring Systems). Available online: http://store.uni.com/catalogo/uni-11761-2019 (accessed on 2 June 2021).
- Eusebio, L.; Capelli, L.; Sironi, S. Electronic Nose Testing Procedure for the Definition of Minimum Performance Requirements for Environmental Odor Monitoring. Sensors 2016, 16, 1548. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Zhang, H.; Sun, W.; Lu, N.; Yan, M.; Wu, Y.; Hua, Z.; Fan, S. Development of a Low-Cost Portable Electronic Nose for Cigarette Brands Identification. Sensors 2020, 20, 4239. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1965, 36, 1627–1639. [Google Scholar] [CrossRef]
- De Oliveira, M.A.; Araujo, N.V.S.; Da Silva, R.N.; Da Silva, T.I.; Epaarachchi, J. Use of Savitzky–Golay Filter for Performances Improvement of SHM Systems Based on Neural Networks and Distributed PZT Sensors. Sensors 2018, 18, 152. [Google Scholar] [CrossRef] [Green Version]
- Stetter, J.R.; Penrose, W.R. Understanding chemical sensors and chemical sensor arrays (electronic noses): Past, present, and future. Sensors 2002, 10, 189–229. [Google Scholar] [CrossRef]
- Demarchi, L.; Kania, A.; Ciężkowski, W.; Piórkowski, H.; Oświecimska-Piasko, Z.; Chormański, J. Recursive Feature Elimination and Random Forest Classification of Natura 2000 Grasslands in Lowland River Valleys of Poland Based on Airborne Hyperspectral and LiDAR Data Fusion. Remote Sens. 2020, 12, 1842. [Google Scholar] [CrossRef]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comp. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. Available online: https://arxiv.org/pdf/2008.05756v1.pdf (accessed on 2 July 2021).
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perception)—A review of applications in the atmospheric sciences. Atmos. Environ. 1997, 32, 2627–2636. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3 December 2018. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Men, H.; Jiao, Y.; Shi, Y.; Gong, F.; Chen, Y.; Fang, H.; Liu, J. Odor Fingerprint Analysis Using Feature Mining Method Based on Olfactory Sensory Evaluation. Sensors 2018, 18, 3387. [Google Scholar] [CrossRef] [Green Version]
- Oliva, G.; Zarra, T.; Massimo, R.; Senatore, V.; Buonerba, A.; Belgiorno, V.; Naddeo, V. Optimization of Classification Prediction Performances of an Instrumental Odour Monitoring System by Using Temperature Correction Approach. Chemosensors 2021, 9, 147. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; p. 201. [Google Scholar]
- Van Harreveld, A.P. Update on the revised EN 13725:2021. Chem. Eng. Trans. 2021, 85, 115–120. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Number of Samples 1 | Number of Data | Concentrations Range [ouE/m3] |
|---|---|---|---|
| Class 0 | 28 | 216 | 20–200 |
| Class 1 | 24 | 160 | 25–2435 |
| Class 2 | 28 | 214 | 40–510 |
| Class 3 | 24 | 160 | 64–1866 |
| Classes | MLP | RF |
|---|---|---|
| Class 0 | 0.99 | 1 |
| Class 1 | 0.99 | 1 |
| Class 2 | 1 | 1 |
| Class 3 | 1 | 1 |
| Overall | 0.99 | 1 |
| Overall Classification Accuracy | ||
|---|---|---|
| MLP | RF | |
| First Split | 0.95 | 0.97 |
| Second Split | 0.98 | 0.98 |
| Third Split | 0.97 | 0.97 |
| Fourth Split | 0.98 | 0.99 |
| Fifth Split | 0.97 | 0.97 |
| Mean CV Score | 0.97 | 0.98 |
| Standard Deviation CV Score | 0.05 | 0.03 |
| Classes | MLP | RF |
|---|---|---|
| Class 0 | 0.98 | 0.97 |
| Class 1 | 0.98 | 0.98 |
| Class 2 | 0.98 | 0.99 |
| Class 3 | 1 | 1 |
| Overall Accuracy Rate | 0.98 | 0.98 |
| Cohen’s Kappa | 0.97 | 0.97 |
| Classes | MLP | RF | ANN [30] |
|---|---|---|---|
| R2 | 0.99 | 0.99 | 0.9976 |
| RMSE (ouE/m3) | 36.9 | 6.8 | 523,4 |
| NRMSE (%) | 1.52 | 0.28 | 1.05 |
| Classes | MLP | RF |
|---|---|---|
| R2 | 0.9 | 0.92 |
| RMSE (ouE/m3) | 130 | 97 |
| NRMSE (%) | 5.37 | 4.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cangialosi, F.; Bruno, E.; De Santis, G. Application of Machine Learning for Fenceline Monitoring of Odor Classes and Concentrations at a Wastewater Treatment Plant. Sensors 2021, 21, 4716. https://doi.org/10.3390/s21144716
Cangialosi F, Bruno E, De Santis G. Application of Machine Learning for Fenceline Monitoring of Odor Classes and Concentrations at a Wastewater Treatment Plant. Sensors. 2021; 21(14):4716. https://doi.org/10.3390/s21144716
Chicago/Turabian StyleCangialosi, Federico, Edoardo Bruno, and Gabriella De Santis. 2021. "Application of Machine Learning for Fenceline Monitoring of Odor Classes and Concentrations at a Wastewater Treatment Plant" Sensors 21, no. 14: 4716. https://doi.org/10.3390/s21144716
APA StyleCangialosi, F., Bruno, E., & De Santis, G. (2021). Application of Machine Learning for Fenceline Monitoring of Odor Classes and Concentrations at a Wastewater Treatment Plant. Sensors, 21(14), 4716. https://doi.org/10.3390/s21144716