1. Introduction
To protect Global Navigation Satellite System (GNSS) information from spoofing and meaconing, one can employ two different protection layers: data-level protection by means of the Navigation Message Authentication (NMA), and signal-level protection (authentication) by using encryption of signal codes. Signal-level protection is currently employed for the Global Positioning System (GPS) Precise Positioning Service (PPS) with L1 and L2 P(Y) code ranging signals, the GALILEO Public Regulated Service (PRS) with authorized access to PRS E1A and E6A code signals, and the forthcoming GALILEO High Accuracy Service (HAS) with encrypted (E6-B) and pilot (E6-C) signal components. Although signal-level protection provides essential protection from spoofing, those signals are still vulnerable to the meaconing type of receive and replay attack [
1,
2,
3]. Furthermore, those services employing NMA [
4,
5] such as GALILEO Open Service (OS-NMA) and Commercial Service Authentication (CAS) are essentially not providing protection from the meaconing type of receive and replay attack [
1,
2,
3], and have limited protection from certain types of spoofing attacks (e.g., the spoofer’s ability to broadcast valid navigation messages) [
6]. Both direct meaconing (utilizing beforehand processing of the authentic signal, extraction of its parameters, followed by its modified replay delay) and indirect meaconing attack (utilizing reception of authentic signals from different satellites by an antenna array, followed by their replay with different relative delays) is claimed to be particularly effective even against signal-level protection [
7]. Therefore, Safety-of-Life (SoL) and the critical infrastructure’s GNSS users being aware of both meaconing (non-manipulated delayed GNSS information) and spoofing (intentionally manipulated GNSS information) is of utmost importance.
In this manuscript, we further explore the possibility of applying a supervised machine learning-based approach to detect GNSS signal manipulation attempts, particularly spoofing and meaconing attempts. The motivation behind employing the supervised machine learning algorithms for detection of GNSS signal spoofing and meaconing, in particular, a C-Support Vector Machine (SVM) classification we introduce in this paper, lies in the fact that, at GNSS user receiver level, a number of measurements and observables are generated. The correlation patterns within those data can be established and monitored with the purpose of distinguishing between false and authentic GNSS measurements and observables. In addition, the application of an SVM classifier to GNSS spoofing detection has been previously demonstrated as promising by [
8,
9,
10,
11].
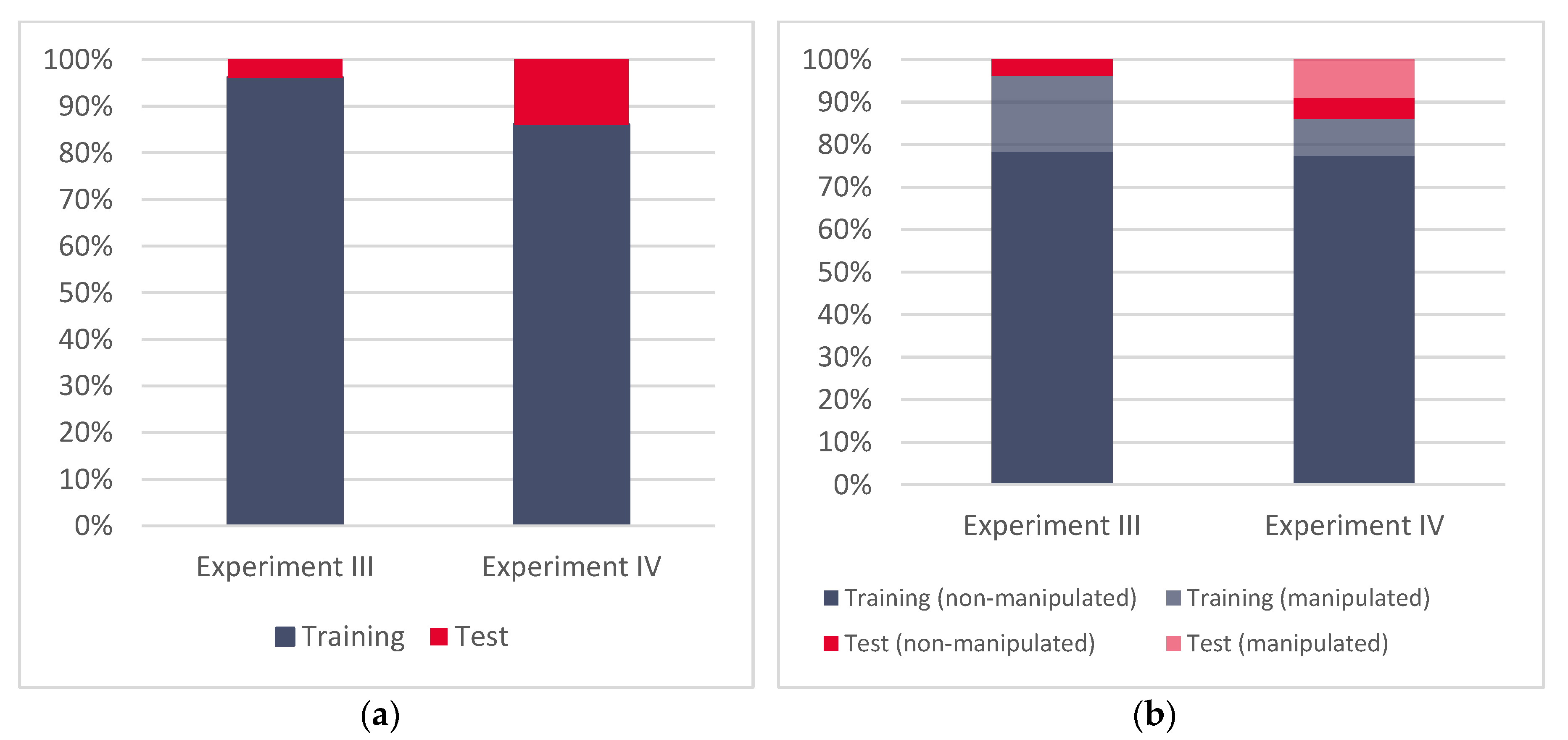
As was described in depth in Part I of this publication [
11], various datasets for the C-Support Vector Machine model building and its validation have been used. As in Experiments I and II [
11], all three groups of GNSS datasets are also used in Experiments III and IV.
These are:
(i) The laboratory spoofing dataset synthetically generated (simulated) in the laboratory;
(ii) The real-world meaconing dataset recorded during a real-world meaconing event (unintentional re-radiation of GNSS signal). In the context of validation, this dataset is titled the meaconing validation dataset;
(iii) The real-world spoofing dataset recorded during a real-world spoofing event (intentional spoofing signal generated and radiated over the air). In the context of validation, this dataset is titled as spoofing validation dataset.
Terminology wise, we define GNSS signals in our work as either non-manipulated (authentic) or manipulated (false). Both non-manipulated (authentic) and manipulated (false) signal records are contained in each of the above listed datasets.
In Part I [
11], Experiments I and II were conducted by using the synthetically generated spoofing dataset for training dataset formation followed by the C-SVM model building, with eventual validation of the model by the meaconing validation dataset (Experiment I) and spoofing validation dataset (Experiment II).
Results of applying C-SVM in the Experiments I and II [
11] showed that a relatively high number of supporting vectors has been involved in the separation between the authentic and false GNSS observables, which points to the higher complexity of the C-SVM model with potential overfitting. However, in the results of model validation by two independent datasets, the meaconing and spoofing datasets in Experiment I and II, respectively, demonstrated a high success rate and a lack of overfitting.
Following these findings [
11], we wanted to examine the effect of enriching the training data for the supervised machine learning-based approach with the real-world spoofing and meaconing datasets, eventually validating the proposed approach on these independent, real-world spoofing and meaconing datasets. In more details, we wanted to gain a deeper insight into the characteristics of the real-world spoofing and meaconing datasets, and potential implications these characteristics might have within the supervised machine learning-based approach for detection of the GNSS signal manipulation attempts. We also wanted to examine how real-world spoofing and meaconing datasets compare to the synthetically generated training datasets in terms of how successfully their usage contributes to plausible detection of real-world GNSS signal manipulation attempts. To the best of our knowledge, in this paper, we present the first attempt to train the supervised machine learning-based approach on real-world GNSS signal manipulation data. It is also the first time that a classifier constructed from the real-world GNSS manipulation data is validated on independent real-world meaconing and spoofing datasets. This gave us the ability to conduct a first-of-its-kind analysis, where deeper insights into the impacts and implications of utilizing real-world GNSS signal manipulation for the construction of a supervised machine learning-based approach are presented through comparative analysis among uniformly performed experiments.
For this purpose, we have constructed two new experiments (Experiment III and Experiment IV). Subsequently, we examined and compared findings across all four experiments to achieve systematic insights into the transferability of the proposed approach.
The rest of the paper is organized as follows. The next section gives an overview of the data and methods used. In this section, we only briefly describe the datasets and the methods as a more detailed description is given in Part I of this manuscript. However, we opted to present the basics for the readers, as necessary to introduce Experiment III and Experiment IV. This is followed by the results overview across both experiments presented in this paper. Next, we take a closer look and compare the obtained results with Experiments I and II introduced in Part I of the manuscript [
11]. The findings across all four experiments are discussed and the main conclusions are highlighted in the final section.
4. Discussion
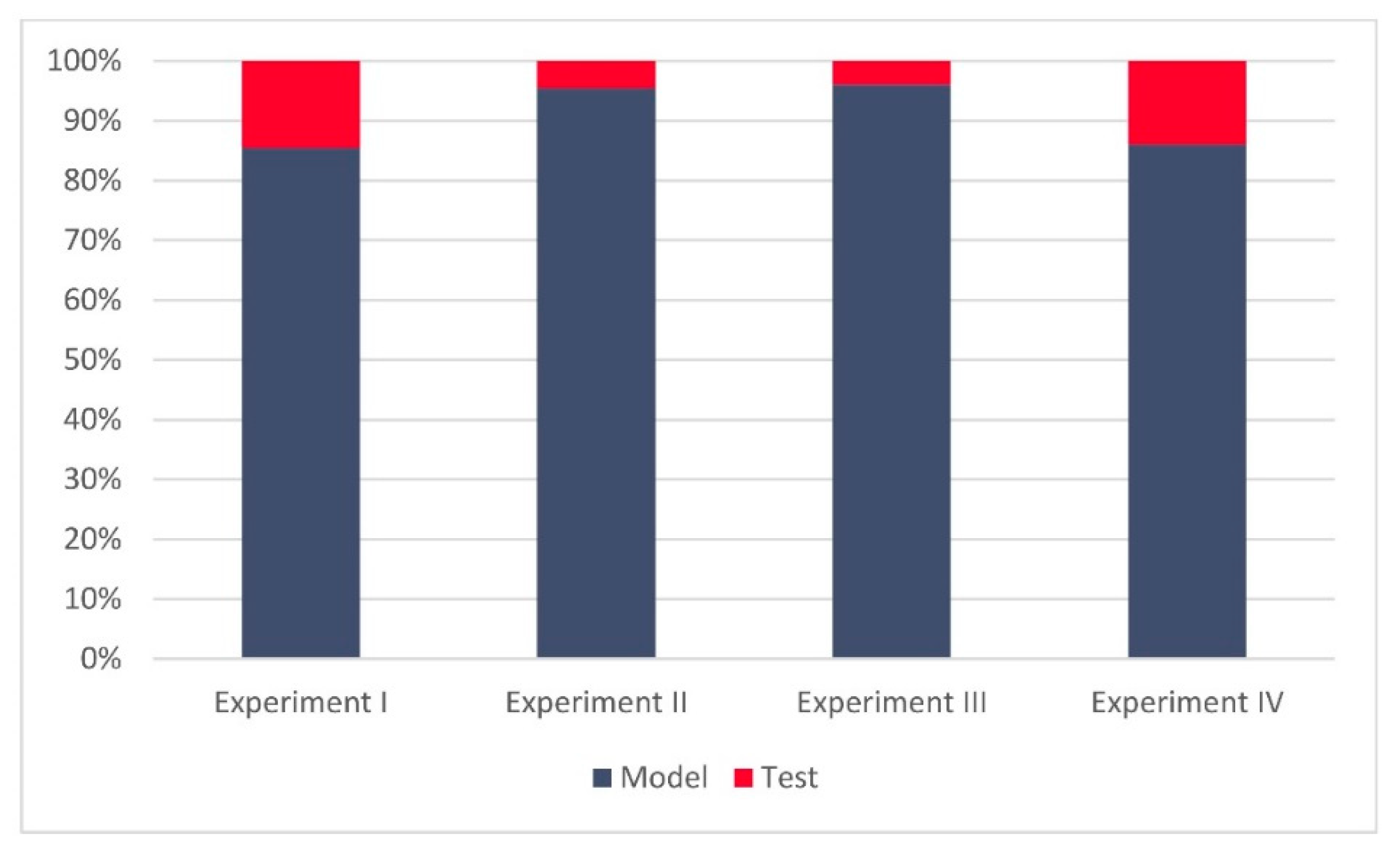
Regarding the results of Experiments III and IV, one can notice that both experiments achieved relatively high success rates (95.81% and 97.72%, respectively). However, more notably, in both experiments all the GNSS signal manipulation events were successfully recognized (as reported in
Table 3,
Table 4,
Table 5,
Table 6).
The variations in evolution of the successfully recognized GNSS signal manipulation attempts, over
, seem to be more stable in Experiment IV as the success rate rapidly grows for a small value of
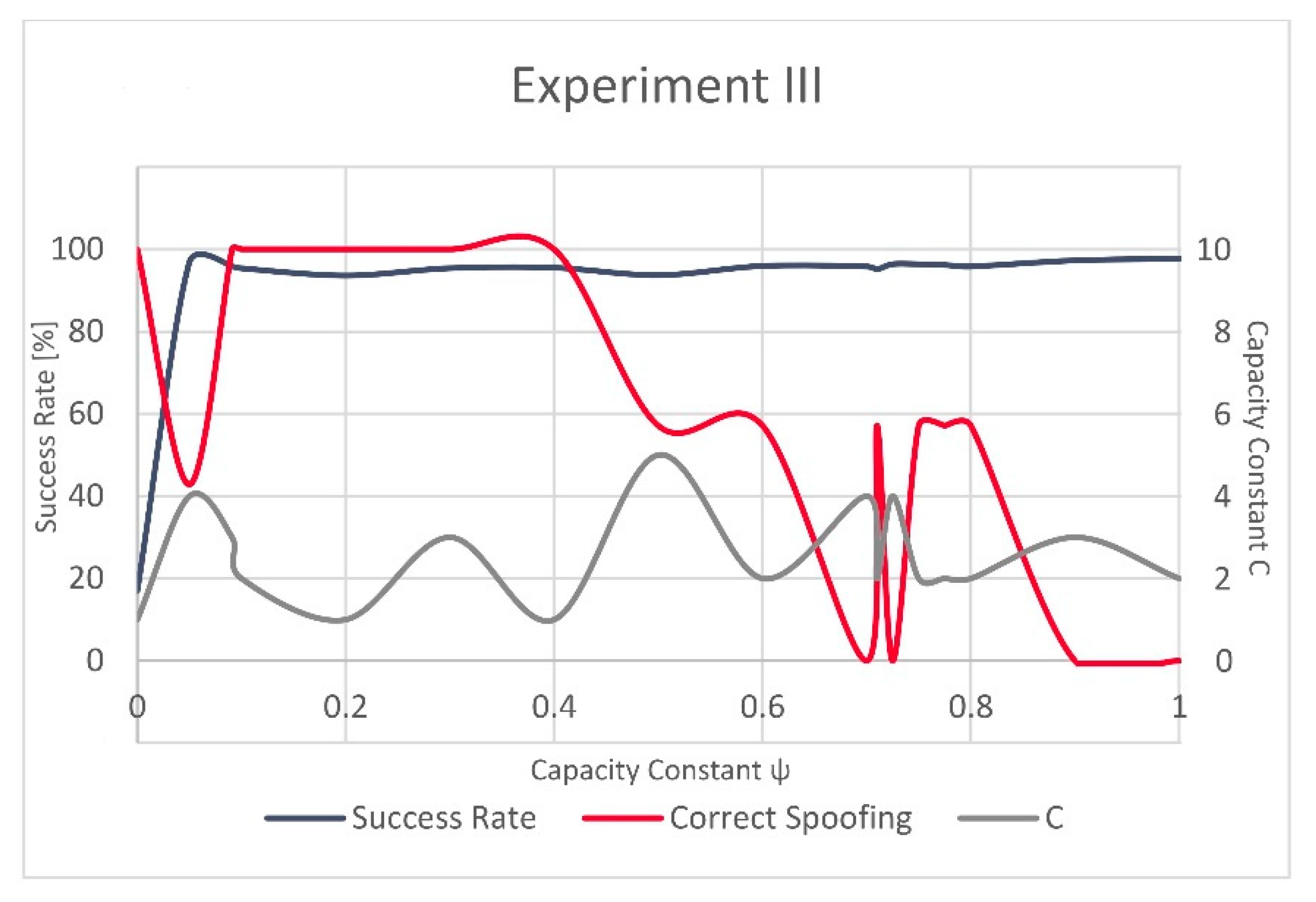
and only slightly varies after this steep increase. In Experiment III, these fluctuations are more strongly visible (
Figure 3 and
Figure 4). However, the validation dataset in Experiment III included only a small number of the actually manipulated (spoofed) records, as failing to recognize just a few of them would result in a significant variation and would reflect in decrease of the success rate equal to almost 43%.
The difference in the model complexity is also visible in the number of the present supporting vectors, since Experiment III resulted in 15% more supporting vectors than Experiment IV (
Table 3 and
Table 4). This indicates that the C-SVM-based approach found it more challenging to construct linear hyperplanes in order to correctly separate manipulated GNSS signal data points from authentic ones, in the scenario where the training dataset was composed of the simulated spoofing dataset records and those acquired from the real-world meaconing event, while the validation dataset utilized was the one created out of the real-world spoofing event records. Respectively, the linear hyperplanes for the scenario where the training set was composed of the synthetic and real-world spoofing event records, being validated on the real-world meaconing event, seemed to be a less challenging task.
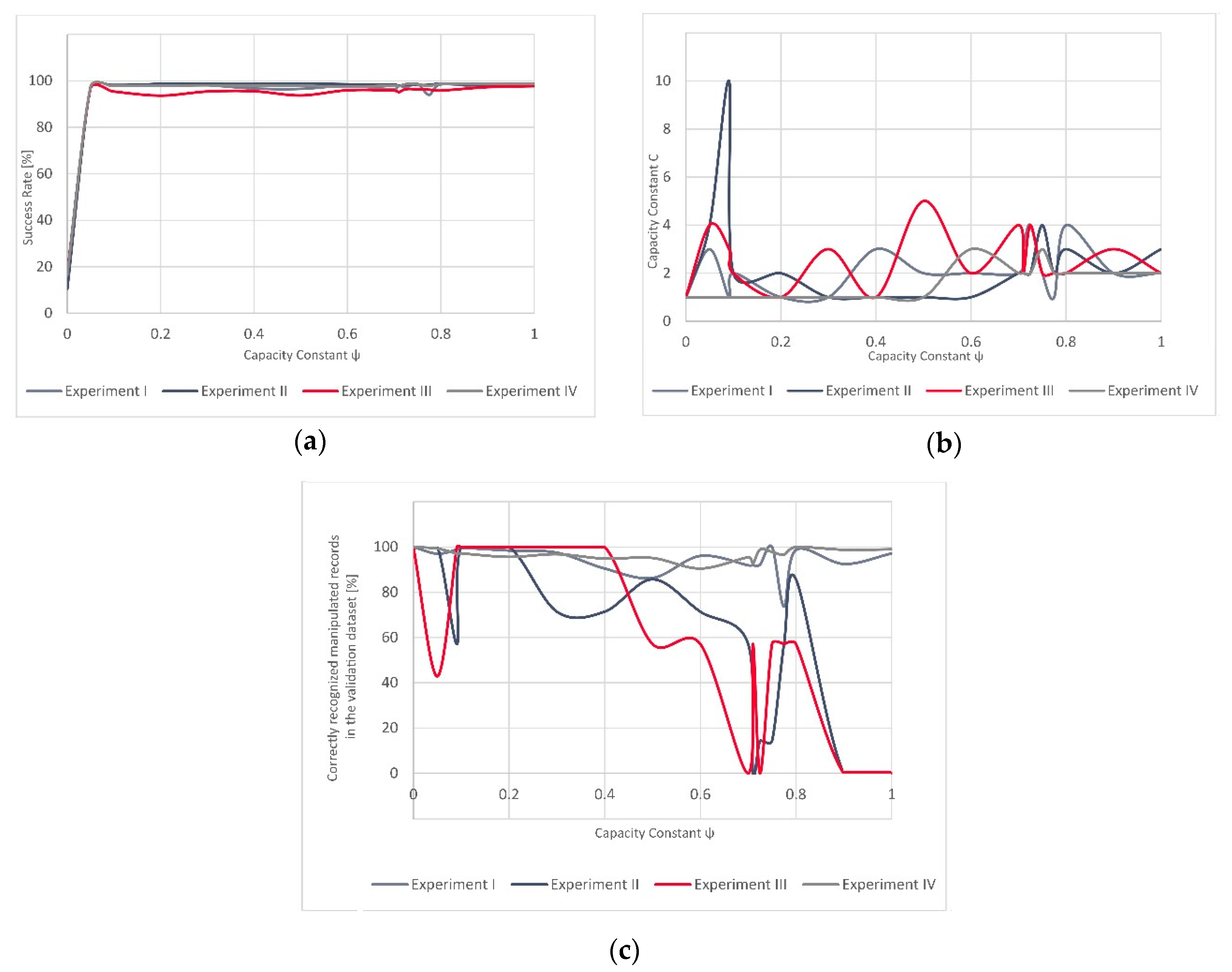
In terms of the results of all four experiments, one can notice similarities in the evolution of the success rate over all four experiments (
Figure 7). For the lowest value of
, the classifier always assigns only one class to all the validation dataset records (in our case the “manipulated GNSS signal class”). Hence, this starting success rate is low as the proportion of manipulated GNSS signal records, whether they were spoofing or meaconing-related, is also low. As the value of
ψ evolves, the model reaches different success rates. Furthermore, the values of the capacity constraint C over the full spectrum of
values remain somewhat low, with only one peak (in Experiment II). Contrary to this, the rate of successfully recognized GNSS signal manipulation attempts fluctuates significantly. This seems to be related to the characteristics of the validation dataset. In general, the training dataset composed either of only synthetically generated data (Experiment II) or a combination of synthetically generated and real-world meaconing events (Experiment III), resulting in a C-SVM-based model that had more pronounced fluctuations when being validated on a real-world spoofing event than it was in the case of the models (Experiment I and Experiment IV) that used the real-world meaconing dataset for validation. If we consider only one value of
over all four experiments, then the best overall results (global results) would be achieved for a very low value of
= 0.01 and also very low value of C (mod and median equal to 2) (
Table 7). Thus, it would be interesting in future research to see how well these values would generalize over unseen datasets (without the model training step). Such results would be particularly interesting in the context of data analytics advances, as federated learning, where models are built across multiple decentralized devices or servers holding local data samples, without exchanging the data samples. This is particularly interesting as the time-consuming training step could be avoided if the results indicated stability in such experiments. Hence, the time taken to detect a real-time sensed GNSS signal manipulation attempt would be reduced and possible mitigation strategies could be potentially developed in real-time scenarios.
To gain a better insight into the characteristics of the datasets and their impact to the training and validation roles, we have examined the principal components and the correlation patterns of the validation datasets.
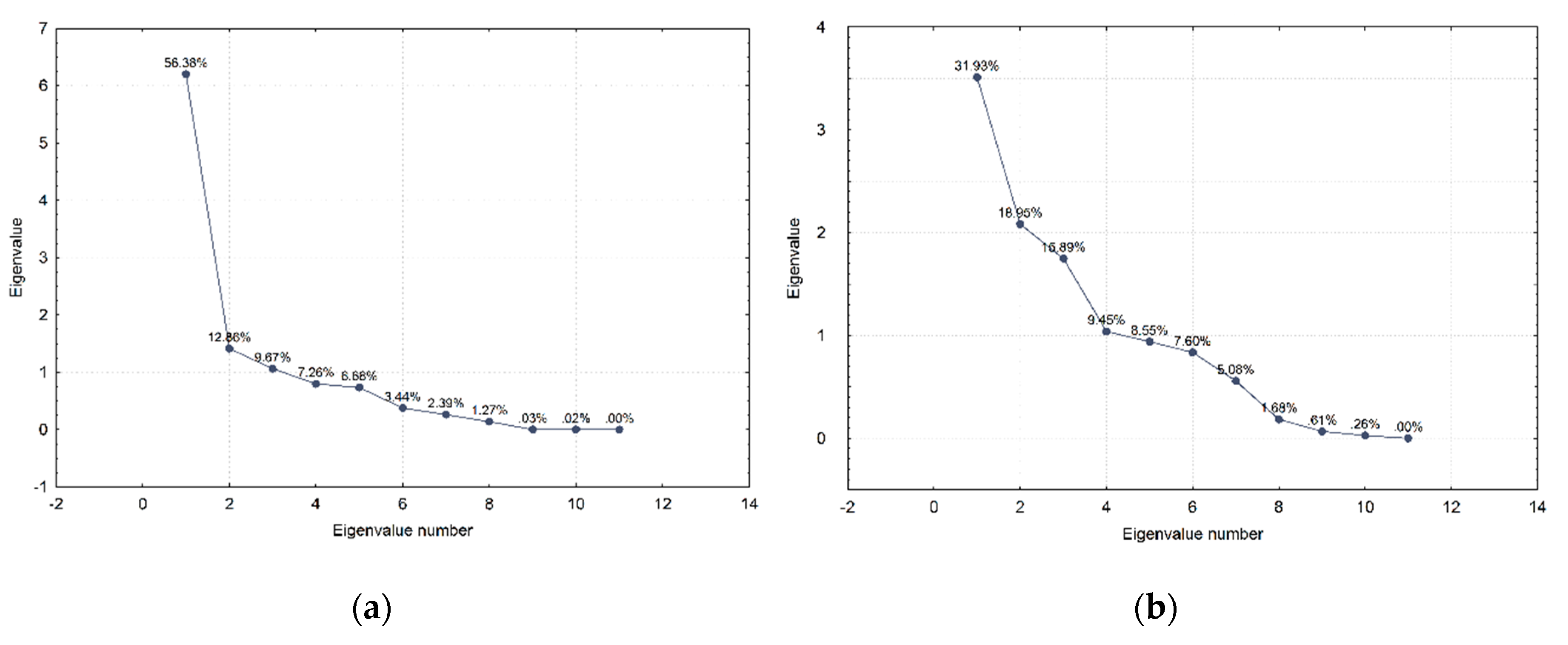
Regarding the factor analysis, or more precisely the Principal Components Analysis results for both validation datasets, one can notice that the first principal component for the real-world meaconing validation dataset accounts for 56% of variations and almost twice as many as the first principal component does in the real-world spoofing dataset (
Figure 9). Furthermore, the first two principal components in the real-world meaconing validation dataset account for a comparable amount of variations to the first three principal components in the real-world spoofing dataset. This indicates that the real-world spoofing dataset has a higher number of independent variations observed in the dataset and, hence, it is more challenging to describe it by the linear combination of the variables. Looking at the component coordinates presented in the unit circle for the first two principal components, for both real-world datasets, one can notice which variables compose a linear combination that captures observed variations in the dataset and is the best represented by the current set of principal components. For the real-world meaconing dataset, the code variance, C/N
0, full carrier phase, pseudorange, lock time, and carrier Doppler frequency compose a linear combination that is the best represented by the current set of principal components (the first component). For the real-world spoofing dataset, the first component is composed of the linear combination of C/N
0, lock time, and full carrier phase, whereas for both datasets the second principal component captures the receiver clock bias and the receiver clock drift.
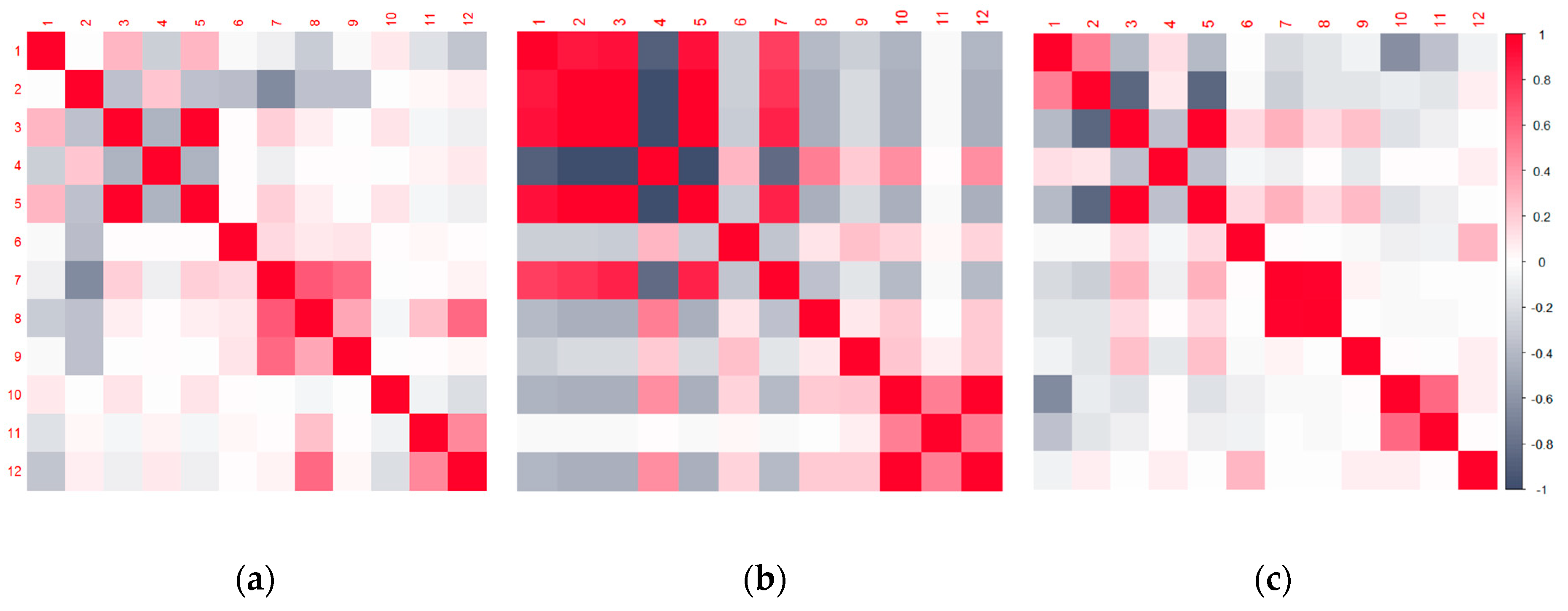
Correlation analysis (
Figure 8) also returned interesting results, indicating that, to some level, the synthetically generated spoofing dataset exhibits a similar correlation pattern as the real-world meaconing dataset. However, in the real-world meaconing dataset strength of the relationship among the observables seems to be more pronounced, hence achieving the greater absolute value of Pearson’s correlation coefficient. The real-word spoofing dataset exhibits notably stronger relationships among variables, which, to some extent, differs from the patterns among the synthetically generated and the real-world meaconing datasets. For the real-world meaconing event, the strongest and most statistically significant correlation with the indication of whether the GNSS signal is manipulated or not was observed for the receiver clock bias and receiver clock drift variables. This can be interpreted by the fact that the meaconing signal is re-radiated from a distance; this is, to some extent, the same as sending it through a delay line before adding to the direct (authentic) signal. Hence, this signal delay is translated into the observed clock drift, while the exhibited variations of the clock bias in this context seem to provide the most reliable indication of the signal being manipulated or not. For the real-world spoofing dataset, the strongest and statistically significant correlation with the indication of whether the GNSS signal is manipulated or not was observed for the multipath correction variable. This can be explained by the fact that the signals in the SDR-based spoofing scenario perceive a different (and common) transfer function, so multipath correction differs from the genuine signals. Hence, the indication of whether the signal is spoofed or not is strongly reflected in the multipath correction variable correlation.
Notably, while comparing the results of the C-SVM-based approach for all four experiments, it is indicative that, after adding the real-world examples to the training dataset, the constructed models performed overall slightly worse (in Experiment III and IV) than when only synthetically generated datasets were used for the training (in Experiment I and II). However, adding the real-world generated data points to the training datasets increased the success rate of correctly recognized GNSS signal manipulation attempts. This is evident as all the real-world spoofed data points were correctly detected after the synthetically generated training dataset was enriched with the real-world meaconing data point records. This was not the case in Experiment II where the developed approach did not succeed in recognizing all the GNSS signal manipulation attempts. Hence, these results provisionally support the hypothesis that enriched training datasets with real-world-based GNSS signal manipulation records increase the supervised machine learning-based approach performance when it comes to recognizing unseen GNSS signal manipulation attempts. Nonetheless, our results indicate that they also increase the complexity of the model, as they enrich the learner with new examples that differ from those present in the synthetically generated dataset. This is an undesired effect regarding the model’s complexity.
5. Conclusions
In this paper, we explored the possibility of applying a supervised machine learning-based approach to detect GNSS signal manipulation attempts, particularly spoofing and meaconing attempts. To do so, we constructed four experiments (two of which are presented in Part I [
11] of this publication). The two experiments presented here tackle the possibility of training the supervised machine learning-based approach on real-world GNSS signal manipulation data. We have examined and compared findings across all four experiments to achieve systematic insights into the transferability of the proposed approach. Several interesting conclusions based on our findings can be drawn.
Firstly, a supervised machine learning-based approach (in our case, C-SVM) has a high potential to be successfully implemented for GNSS signal manipulation attempt detection, as the designed model achieved high success rates over the presented experiments. Secondly, the inclusion of the real-world meaconing event increased the complexity of the model more than the inclusion of the real-world spoofing event did. This was evident in the number of supporting vectors that resulted from the model training step. However, although the increased complexity was not a desired scenario, it resulted in valuable results, as the trained model was able to detect all the real-world spoofing attempt data points in the validation step. This was not the case when the training was conducted on the simulated dataset only. Hence, enrichment of training datasets with real-world examples seems to be a valuable contribution for model creation in Safety-of-Life applications, such as the detection of GNSS signal manipulation attempts. Furthermore, if we examine all four experiments and the achieved results, there is the possibility to implement the developed approach in federated learning scenarios. This needs to be further explored in future research, but the first insights seem promising, as the values of coefficients obtained through the training in each experiment seem transferable.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}