Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I †


Abstract
1. Introduction
2. Data and Method
2.1. Data Collection
- (i)
- three synthetically generated (simulated) datasets;
- (ii)
- a dataset that resulted from a real-world meaconing event; and
- (iii)
- a dataset that resulted from a real-world spoofing event.
2.1.1. Training Datasets
2.1.2. Validation Datasets
- (i)
- the unintentional re-radiation of the authentic GNSS signal (also known as meaconing if intentional), and
- (ii)
- the intentional radiation of the GNSS spoofing signals.
2.2. Methods
2.2.1. Experiments
2.2.2. Correlation Analysis
2.2.3. Support Vector Machines Classification
2.2.4. Principal Component Analysis
3. Results
3.1. Correlation Analysis
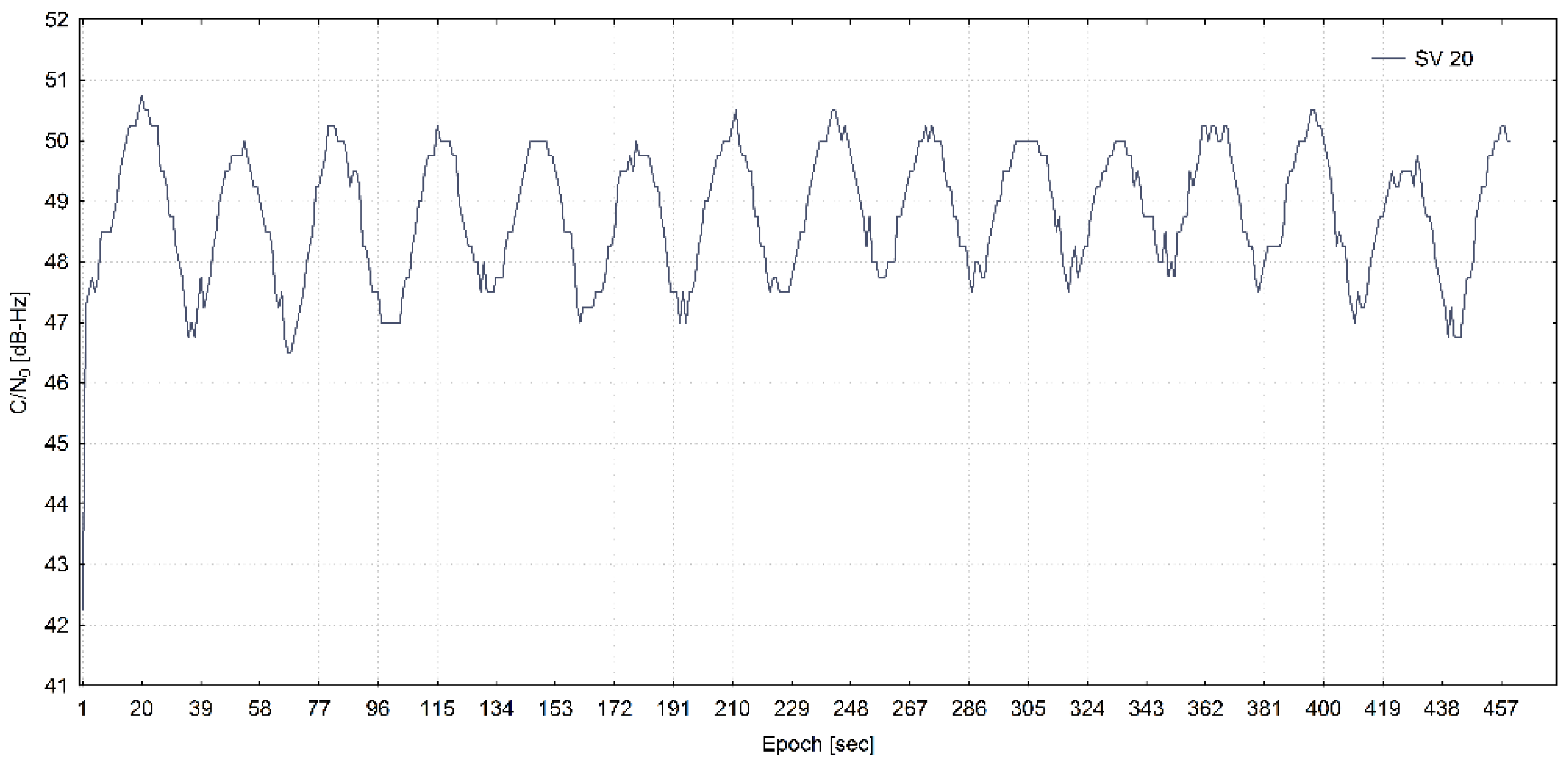
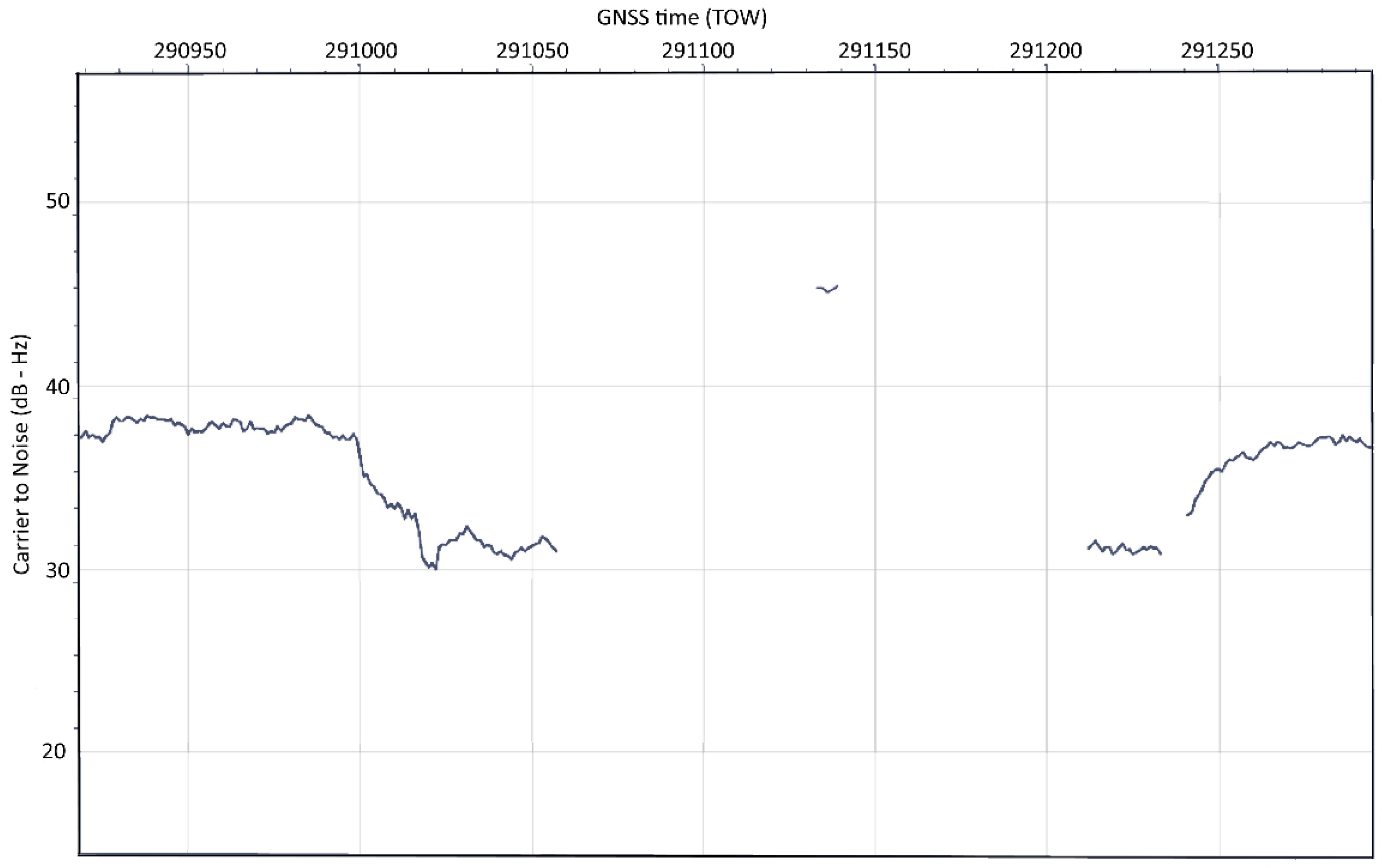
3.2. Data Exploratory Analysis
3.3. Support Vector Machines
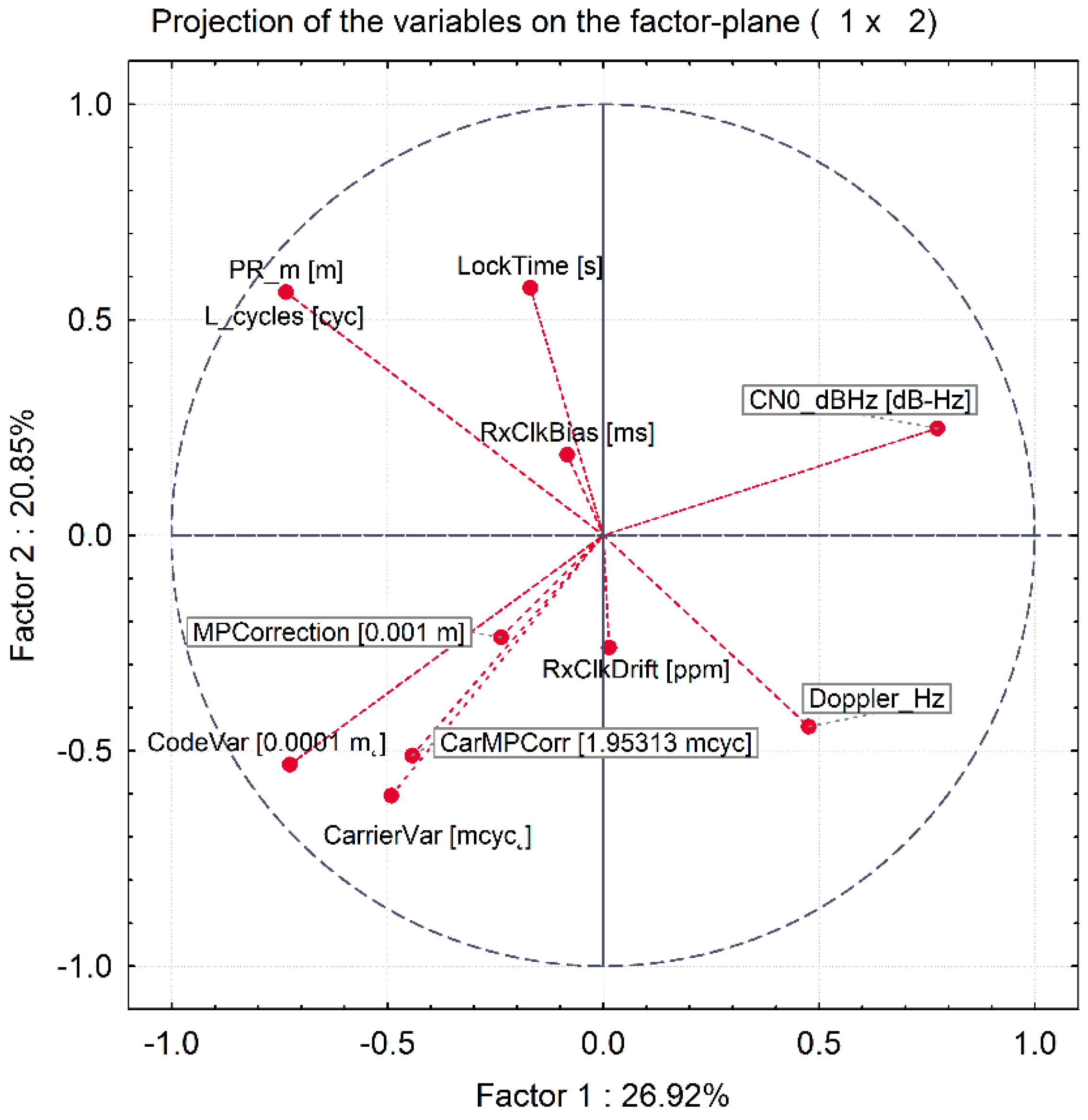
3.4. Principal Component Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schmidt, D.; Radke, K.; Camtepe, S.; Foo, E.; Ren, M. A Survey and Analysis of the GNSS Spoofing Threat and Countermeasures. ACM Comput. Surv. 2016, 48, 1–31. [Google Scholar] [CrossRef]
- Wallischeck, E. GPS Vulnerabilities in the Transportation Sector; U.S. Department of Commerce: Washington, DC, USA, 2016. [Google Scholar]
- Psiaki, M.L.; Humphreys, T.E. GNSS Spoofing and Detection. Proc. IEEE 2016, 104, 1258–1270. [Google Scholar] [CrossRef]
- Tippenhauer, N.O.; Pöpper, C.; Rasmussen, K.B.; Capkun, S. On the requirements for successful GPS spoofing attacks. In Proceedings of the 18th ACM Conference on Computer and Communications Security-CCS’11, Chicago, IL, USA, 17–21 October 2011. [Google Scholar]
- Huang, L. Low-Cost GPS Simulator-GPS Spoofing by SDR; DEFCON.ORG: Las Vegas, NV, USA, 2015. [Google Scholar]
- Hermans, B.; Gommans, L. Targeted GPS Spoofing; Research Project Report; University of Amsterdam: Amsterdam, The Netherlands, 2018; pp. 1–16. [Google Scholar]
- Horton, E.; Ranganathan, P. Development of a GPS spoofing apparatus to attack a DJI Matrice 100 Quadcopter. J. Glob. Position. Syst. 2018, 16, 1–11. [Google Scholar] [CrossRef]
- Zeng, K.C.; Liu, S.; Shu, Y.; Wang, D. All Your GPS Are Belong To Us: Towards Stealthy Manipulation of Road Navigation Systems. In Proceedings of the 27th Security Symposium (USENIX) Security 2018, USENIX Association, Baltimore, MD, USA, 15–17 August 2018. [Google Scholar]
- Kerns, A.J.; Shepard, D.P.; Bhatti, J.A.; Humpreys, T.E. Unmanned Aicraft Capture and Control via GPS Spoofing. J. Field Robot. 2014, 31, 617–636. [Google Scholar] [CrossRef]
- Panice, G.; Luongo, S.; Gigante, G.; Pascarella, D.; Di Benedetto, C.; Vozella, A.; Pescape, A. A SVM-based detection approach for GPS spoofing attacks to UAV. In Proceedings of the ICAC 2017-2017 23rd IEEE International Conference on Automation and Computing: Addressing Global Challenges through Automation and Computing, Huddersfield, UK, 7–8 September 2017. [Google Scholar]
- Sun, M.; Qin, Y.; Bao, J.; Yu, X. GPS spoofing detection based on decision fusion with a K-out-of-N rule. Int. J. Netw. Secur. 2017, 19, 670–674. [Google Scholar] [CrossRef]
- Semanjski, S.; Semanjski, I.; De Wilde, W.; Muls, A. Cyber-threats Analytics for Detection of GNSS Spoofing. In DATA ANALYTICS 2018: The Seventh International Conference on Data Analytics; The International Research and Industry Association: Wilmington, DE, USA, 2018; pp. 136–140. [Google Scholar]
- Semanjski, S.; Muls, A.; Semanjski, I.; De Wilde, W. Use and validation of supervised machine learning approach for detection of GNSS signal spoofing. In Proceedings of the 2019 International Conference on Localization and GNSS (ICL-GNSS), Nuremberg, Germany, 4–6 June 2019; pp. 2–7. [Google Scholar] [CrossRef]
- Rügamer, A.; Del Galdo, G.; Mahr, J.; Rohmer, G.; Siegert, G.; Landmann, M. Over-The-Air Testing using Wave-Field Synthesis. In Proceedings of the 26th International Technical Meeting of The Satellite Division of the Institute of Navigation (ION GNSS+2013), Nashville, TN, USA, 16–20 September 2013; pp. 1931–1943. [Google Scholar]
- Schirmer, C.; Landmann, M.H.; Kotterman, W.A.T.; Hein, M.; Thoma, R.S.; Del Galdo, G.; Heuberger, A. 3D wave-field synthesis for testing of radio devices. In Proceedings of the 8th European Conference on Antennas and Propagation, EuCAP 2014, The Hague, The Netherlands, 6–11 April 2014; pp. 3394–3398. [Google Scholar]
- De Wilde, W.; Sleewaegen, J.M.; Bougard, B.; Cuypers, G.; Popugaev, A.; Landman, M.; Schirmer, C.; Egea-Roca, D.; López-Salcedo, J.A.; Seco-Granados, G. Authentication by polarization: A powerful anti-spoofing method. In Proceedings of the 31st International Technical Meeting of The Satellite Division of the Institute of Navigation (ION GNSS+2018), Miami, FL, USA, 24–28 September 2018; pp. 3643–3658. [Google Scholar]
- Wang, J. Pearson Correlation Coefficient. Encycl. Syst. Biol. 2013, 1671. [Google Scholar] [CrossRef]
- Adler, J.; Parmryd, I. Quantifying colocalization by correlation: The pearson correlation coefficient is superior to the Mander’s overlap coefficient. Cytom. Part A 2010, 77, 733–742. [Google Scholar] [CrossRef] [PubMed]
- Joo, S.; Oh, C.; Jeong, E.; Lee, G. Categorizing bicycling environments using GPS-based public bicycle speed data. Transp. Res. Part C Emerg. Technol. 2015, 56, 239–250. [Google Scholar] [CrossRef]
- Semanjski, I.; Gautama, S. Crowdsourcing mobility insights-Reflection of attitude based segments on high resolution mobility behaviour data. Transp. Res. Part C Emerg. Technol. 2016, 71, 434–446. [Google Scholar] [CrossRef]
- Vlahogianni, E.I. Optimization of traffic forecasting: Intelligent surrogate modeling. Transp. Res. Part C Emerg. Technol. 2015, 55, 14–23. [Google Scholar] [CrossRef]
- Wang, J.; Shi, Q. Short-term traffic speed forecasting hybrid model based on Chaos-Wavelet Analysis-Support Vector Machine theory. Transp. Res. Part C 2013, 27, 219–232. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. Training v-Support Vector Classifiers: Theory and Algorithms. Neural Comput. 2001, 13, 2119–2147. [Google Scholar] [CrossRef] [PubMed]
- Broomhead, D.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; RSRE-MEMO-4148; Royal Signals Radar Establishment: Malvern, UK, 1988. [Google Scholar]
- Schölkopf, B.; Sung, K.-K.; Burges, C.J.C.; Girosi, F.; Niyogi, P.; Poggio, T.; Vapnik, V. Comparing Support Vector Machines with Gaussian Kernels to Radial Basis Function Classifiers. IEEE Trans. Signal Process. 1997, 45, 2758–2765. [Google Scholar] [CrossRef]
- Chapelle, O.; Vapnik, V. Model Selection for Support Vector Machines; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Anguita, D.; Oneto, L. In-sample Model Selection for Support Vector Machines. In Proceedings of the The 2011 International Joint Conference on Neural Networks (IEEE), San Jose, CA, USA, 31 July–5 August 2011; p. 2011. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable number | Variable name | Unit |
|---|---|---|
| 1 | Lock time | [s] |
| 2 | C/N0 | [0.25 dB-Hz] |
| 3 | Pseudorange | [m] |
| 4 | Carrier Doppler frequency | [0.0001 Hz] |
| 5 | Full carrier phase | [cycles] |
| 6 | Multipath correction | [0.001 m] |
| 7 | Code variance | [0.0001 m2] |
| 8 | Carrier variance | [mcycle2] |
| 9 | Carrier multipath correction | [1/512 cycle] |
| 10 | Receiver clock bias | [ms] |
| 11 | Receiver clock drift | [ppm] |
| 12 | Spoofing indication | No unit |
| Experiment I | Value |
|---|---|
| Number of independents | 11 |
| SVM type | Classification type 1 |
| Kernel type | Radial Basis Function |
| Number of SVs | 1693 (1662 bounded) |
| Number of SVs (0) | 845 |
| Number of SVs (1) | 848 |
| Cross -validation accuracy | 98.43% |
| Class accuracy (training dataset) | 98.70% |
| Class accuracy (independent test dataset) | 98.83% |
| Class accuracy (overall) | 98.72% |
| Experiment II | Value |
|---|---|
| Number of independents | 11 |
| SVM type | Classification type 1 |
| Kernel type | Radial Basis Function |
| Number of SVs | 1450 (1417 bounded) |
| Number of SVs (0) | 726 |
| Number of SVs (1) | 724 |
| Cross -validation accuracy | 98.55% |
| Class accuracy (training dataset) | 98.75% |
| Class accuracy (independent test dataset) | 98.82% |
| Class accuracy (overall) | 98.77% |
| Authentic GNSS Signal | Spoofed GNSS Signal | |
|---|---|---|
| Authentic GNSS signal | 2408 | 123 |
| Spoofed GNSS signal | 0 | 4408 |
| Authentic GNSS Signal | Spoofed GNSS Signal | |
|---|---|---|
| Authentic GNSS signal | 1985 | 23 |
| Spoofed GNSS signal | 1 | 6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Semanjski, S.; Semanjski, I.; De Wilde, W.; Muls, A. Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I. Sensors 2020, 20, 1171. https://doi.org/10.3390/s20041171
Semanjski S, Semanjski I, De Wilde W, Muls A. Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I. Sensors. 2020; 20(4):1171. https://doi.org/10.3390/s20041171
Chicago/Turabian StyleSemanjski, Silvio, Ivana Semanjski, Wim De Wilde, and Alain Muls. 2020. "Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I" Sensors 20, no. 4: 1171. https://doi.org/10.3390/s20041171
APA StyleSemanjski, S., Semanjski, I., De Wilde, W., & Muls, A. (2020). Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I. Sensors, 20(4), 1171. https://doi.org/10.3390/s20041171