Enhancing Optical Correlation Decision Performance for Face Recognition by Using a Nonparametric Kernel Smoothing Classification


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
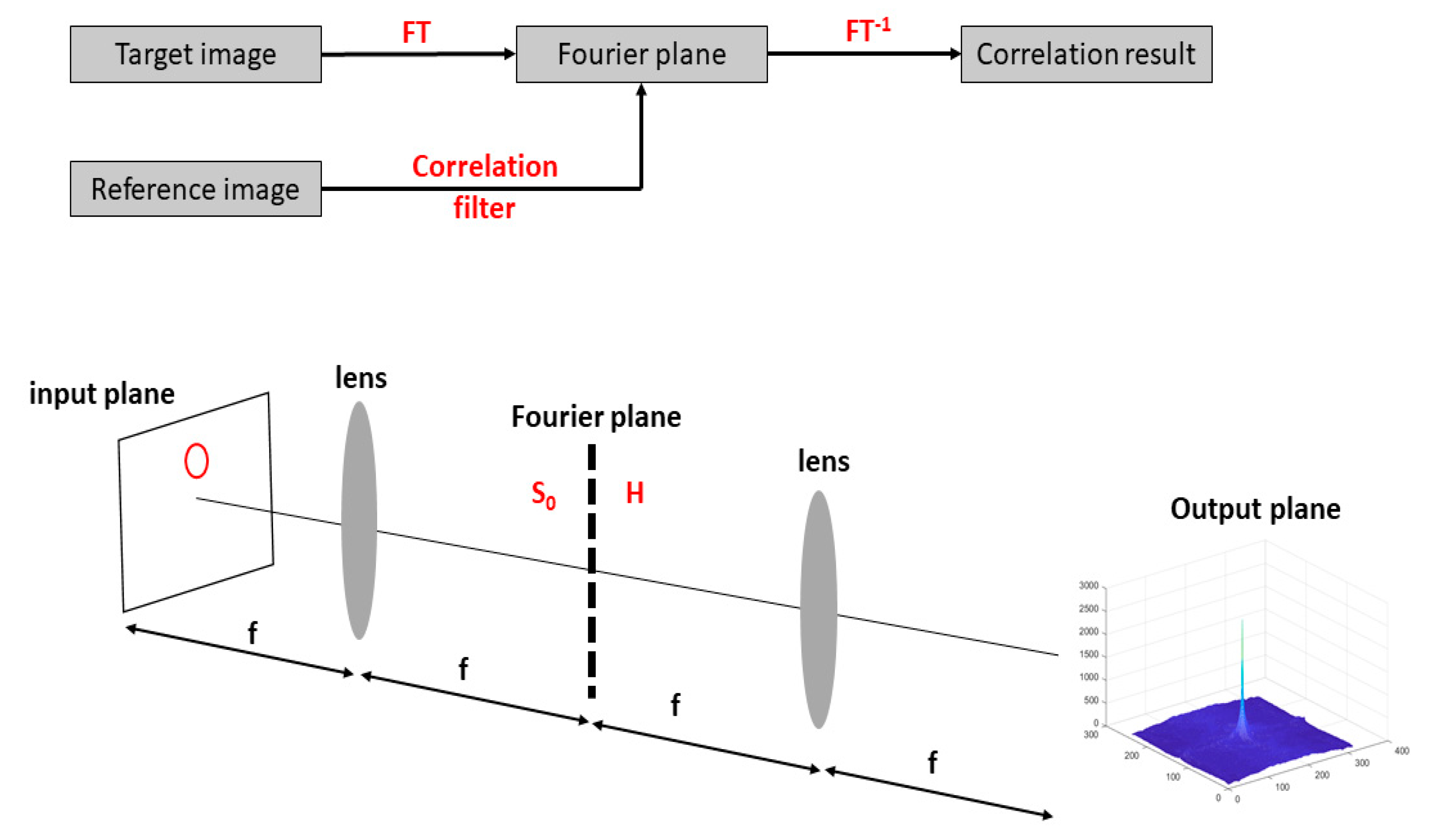
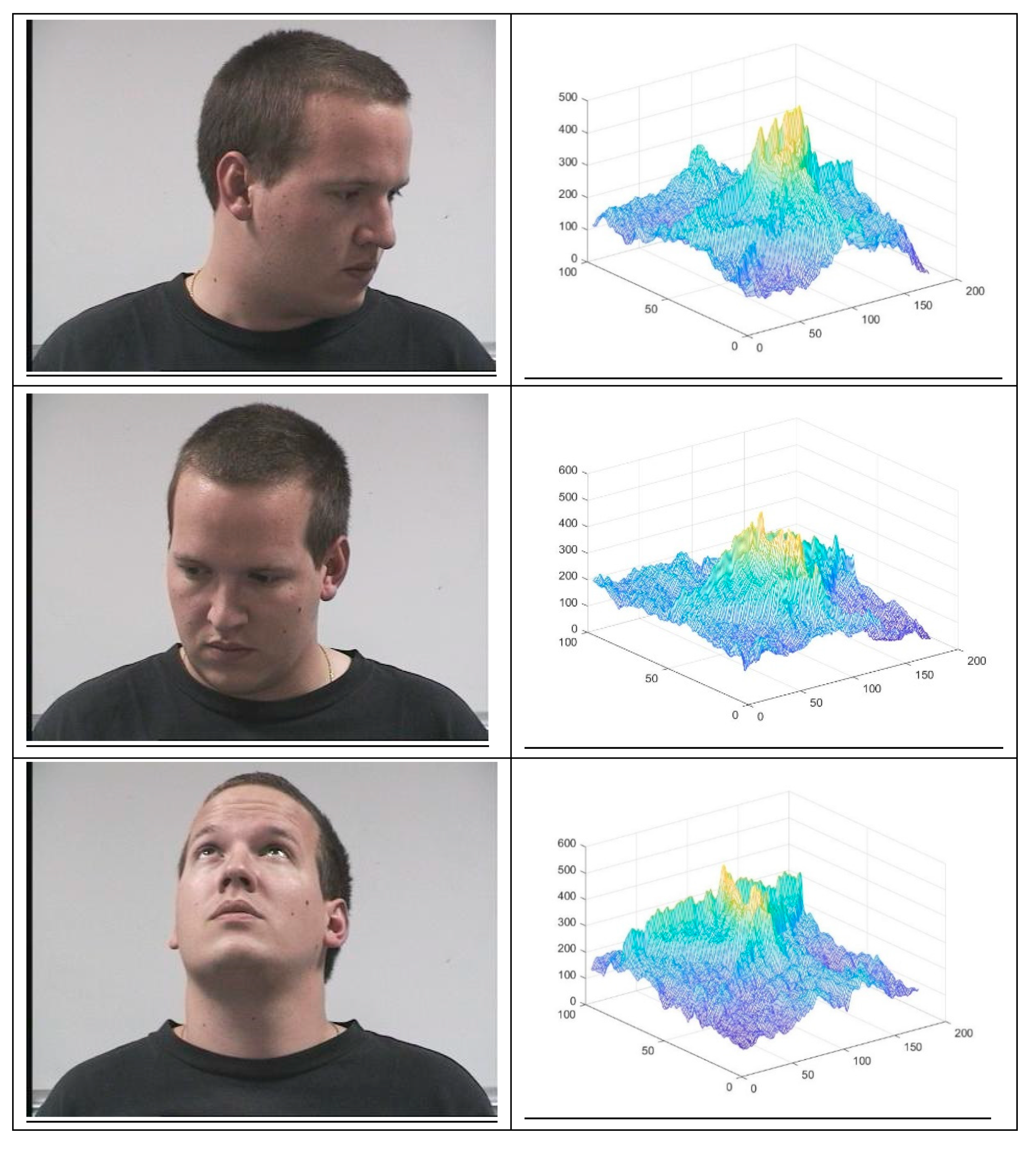
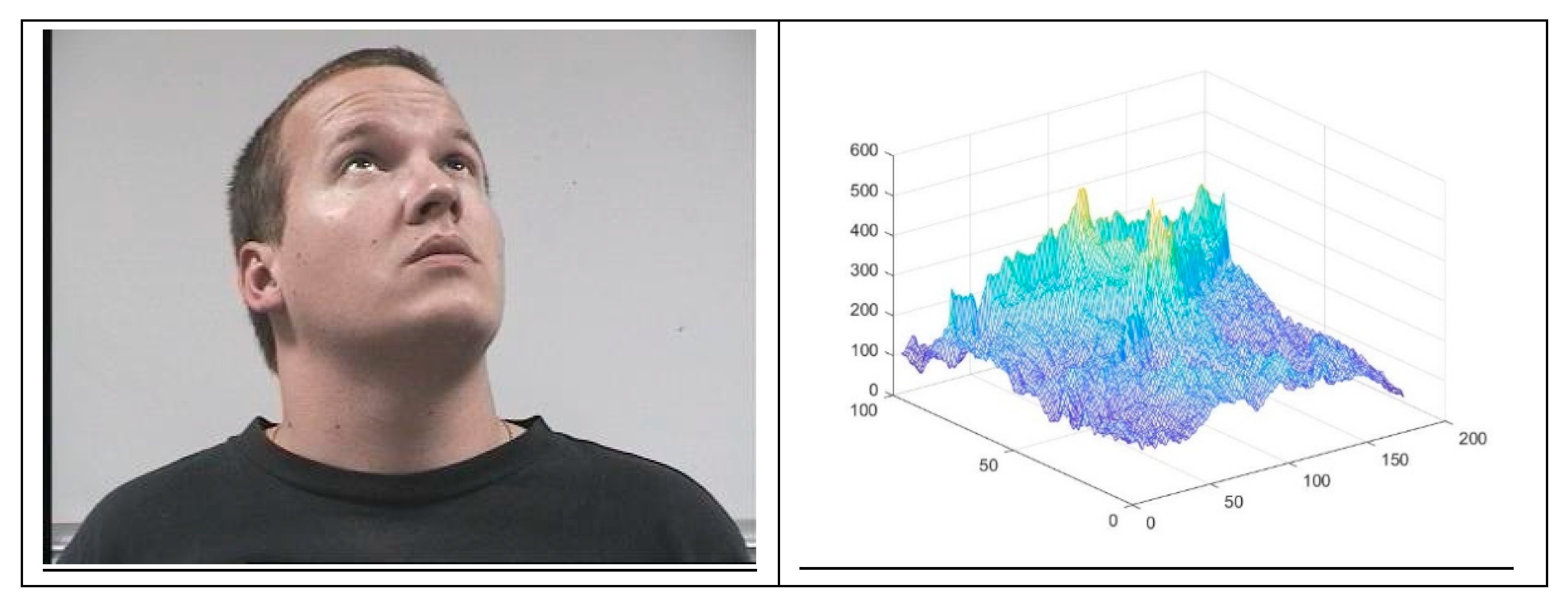
2. Modeling Correlation
3. Dataset
4. Overview of the Method
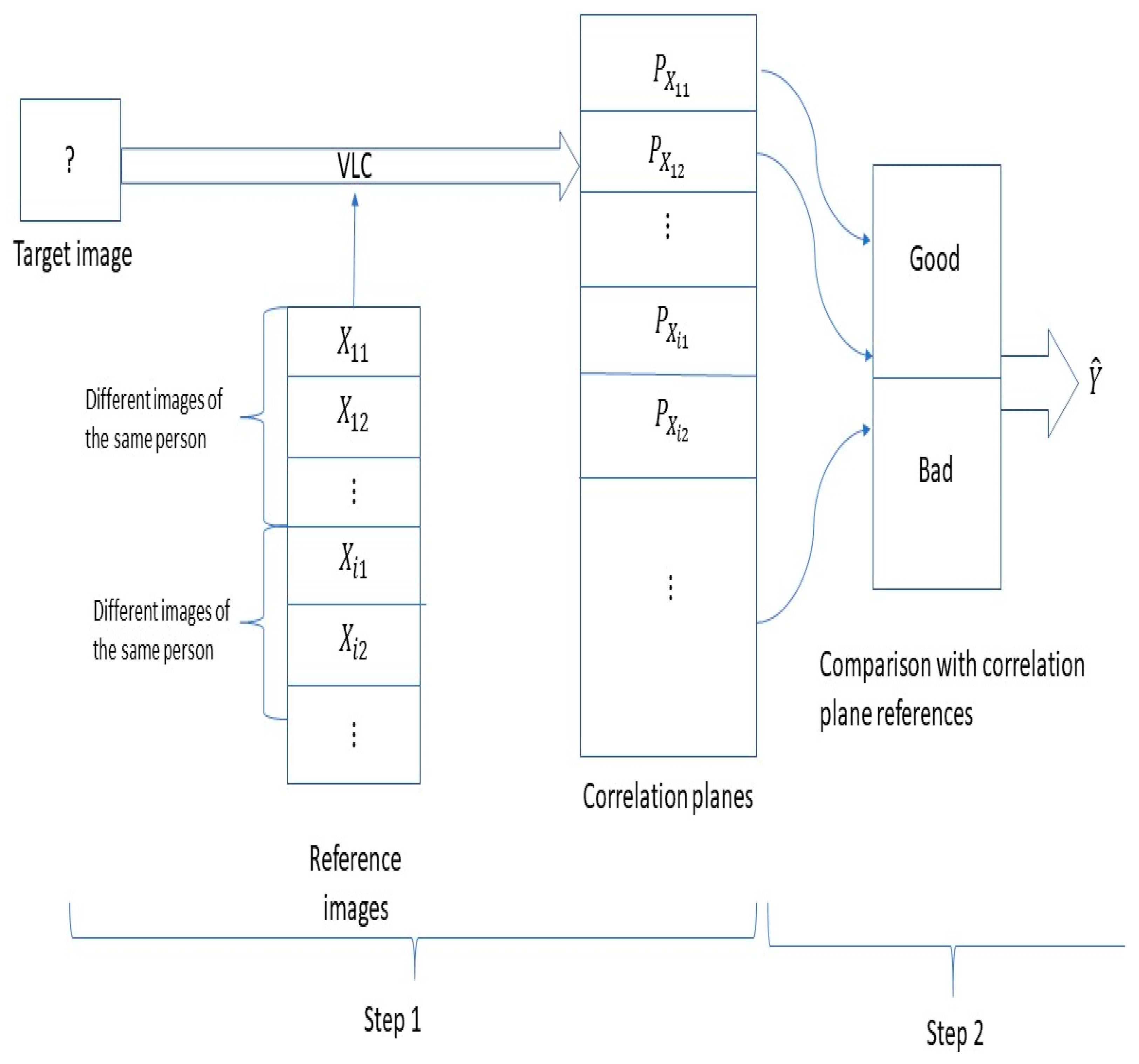
- Step 1:
- Step 1 began with the target image, which is the image to be recognized. The target image was introduced in a VLC correlator to be compared with all reference images of a database. This reference image database contains n different persons (X1,, Xn) (Xi is the ith person); Xij represents the different variations that the person Xi can have (m is the number of variations considered).A set of reference images were used with the target image to generate different correlation planes (Px11,,Pxnm). These correlation planes were then compared in step 2 with pre-computed correlation planes, known as the reference database.
- Step 2:
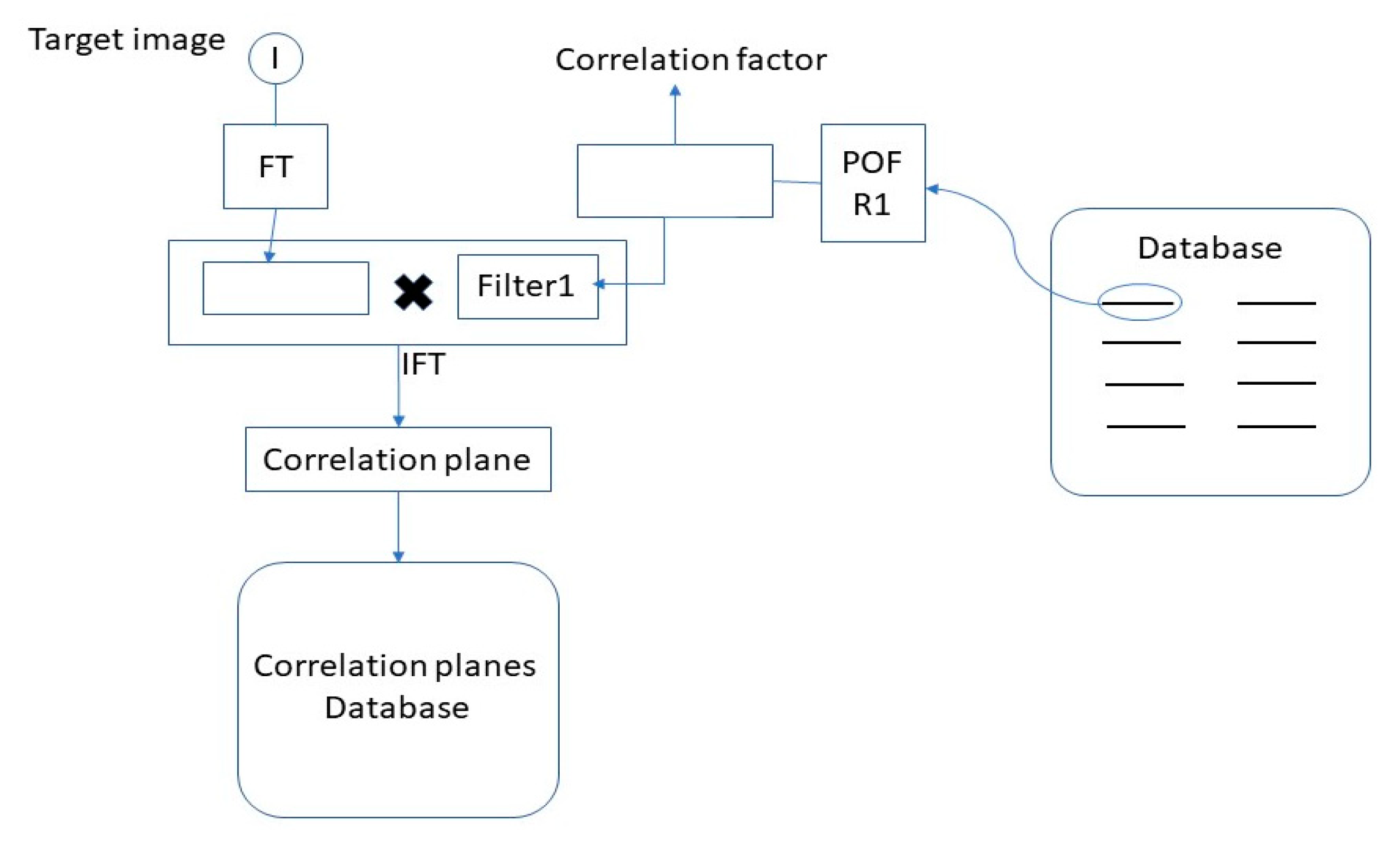
- The correlation planes (Px11,,Pxnm) were compared with a correlation plane database realized in step 1. This database was divided in two parts: The first part contained the good correlation plane of references and another part listed the bad correlations, i.e., the false correlation plane of references. We will compare the good and bad correlation planes in Section 5. The construction of these correlation planes of references was made as follows: The correlation planes of various images of person A, the correlation planes of various images of person B, , and the correlations planes of various images of person Z, which constitute the good correlation planes of reference. The reference database of bad correlation planes was constructed as follows: We calculated the correlation planes between various images of person A and various images of person B, etc.
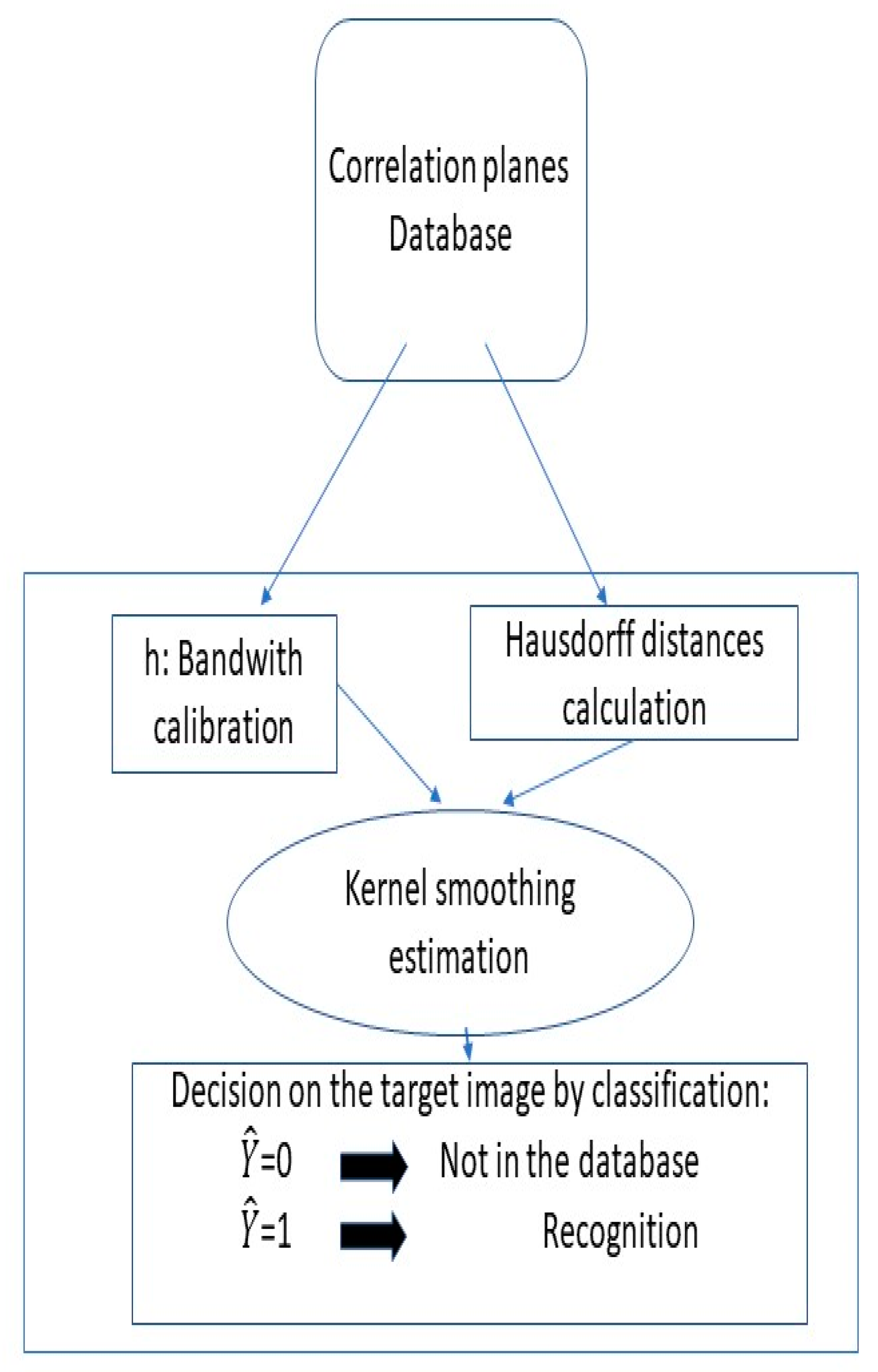
5. Nonparametric Model
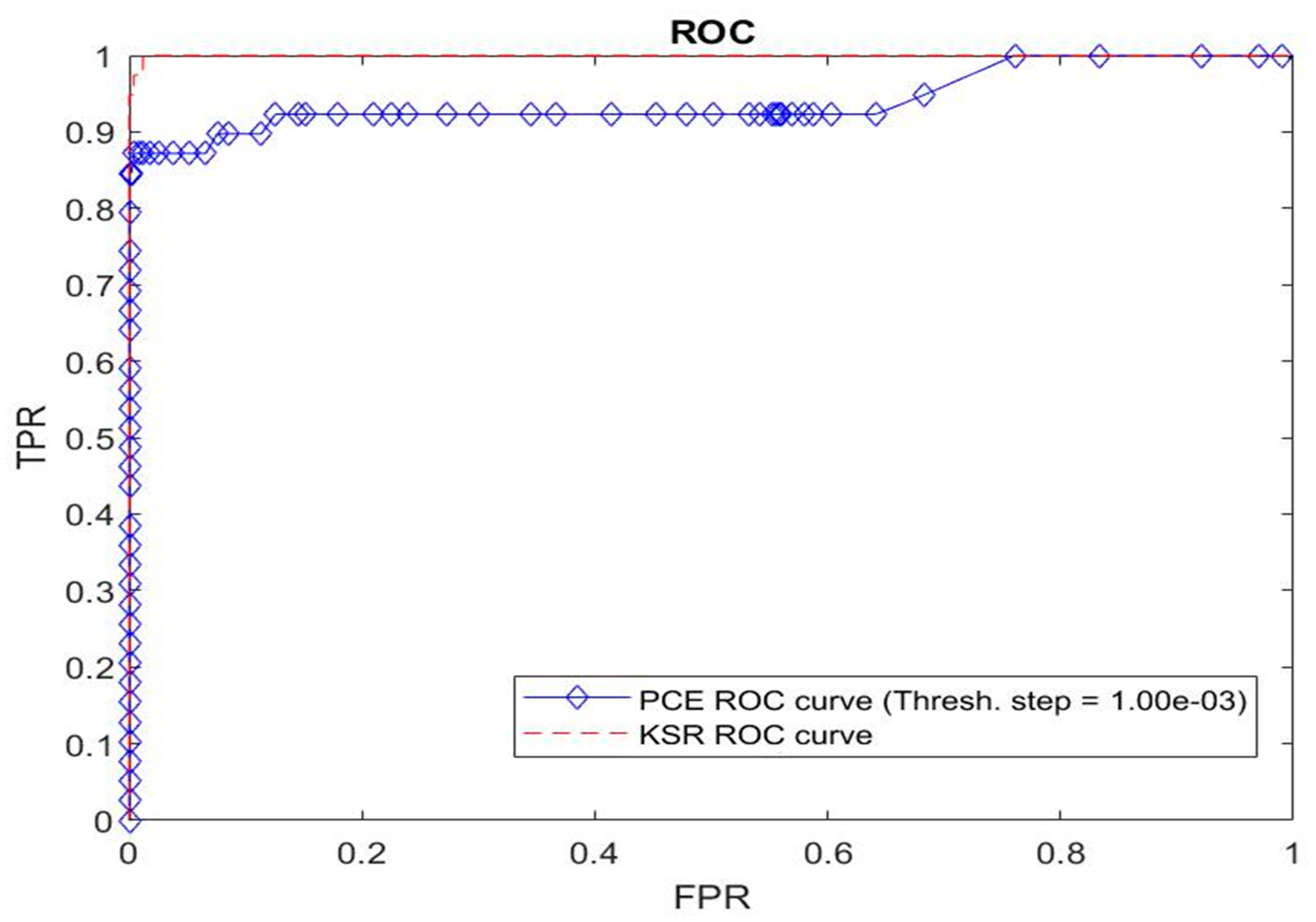
6. Numerical Results and Discussion
6.1. A Brief Description of the Training Testing Set
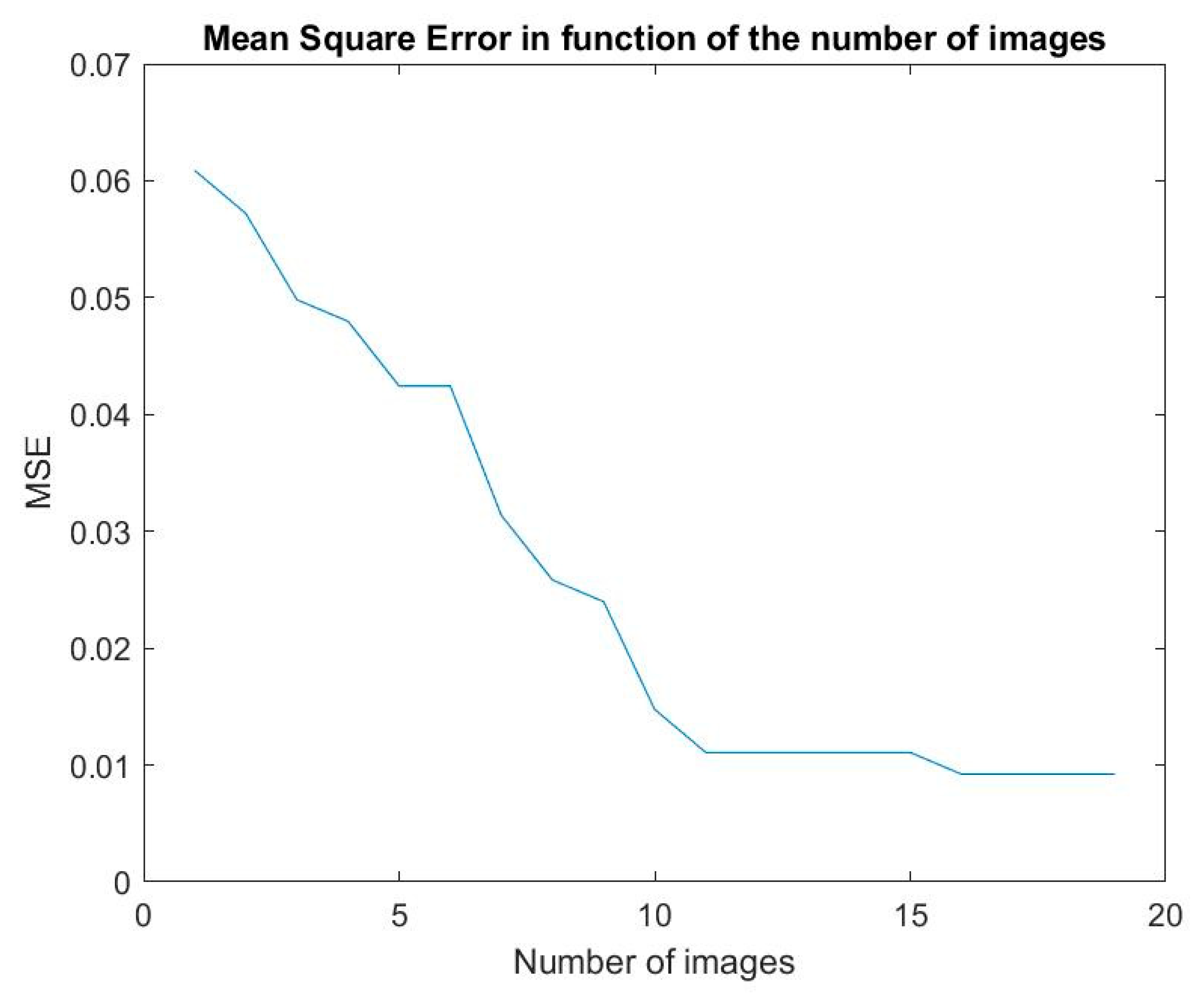
6.2. Bandwidth Calibration
6.3. Simulations for a First Series of Faces from the PHPID Database
6.4. Computation Time
6.5. Simulations for a Second Series of Faces from the PHPID Database
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alfalou, A.; Brosseau, C. Understanding correlation techniques for face recognition: From basics to applications. In Face Recognition; Oravec, M., Ed.; In-Tech: Rijeka, Croatia, 2010; pp. 354–380. ISBN 978-953-307-060-5. [Google Scholar]
- Elbouz, M.; Alfalou, A.; Brosseau, C. Fuzzy logic and optical correlation-based face recognition method for patient monitoring application in home video surveillance. Opt. Eng. 2011, 50, 067003. [Google Scholar] [CrossRef]
- Weaver, C.S.; Goodman, J.W. A technique for optically convolving two functions. Appl. Opt. 1966, 5, 1248. [Google Scholar] [CrossRef] [PubMed]
- Lugt, V.A. Signal detection by complex spatial filtering. IEEE Trans. Inf. Theory 1964, 10, 139–145. [Google Scholar] [CrossRef]
- Goodman, J.W. Introduction to Fourier Optics; McGraw-Hill: New York, NY, USA, 1968. [Google Scholar]
- Goodfellow, I.J.; Bengio, J.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Marechale, C.S.; Groce, P. Un filtre de fréquences spatial pour l’amélioration du contraste des images optiques. C. R. Acad. Sci. 1953, 127, 607. [Google Scholar]
- Horner, J.; Gianino, P. Phase-only matched filtering. Appl. Opt. 1984, 23, 812. [Google Scholar] [CrossRef] [PubMed]
- Taouche, C.; Batouche, M.C.; Chemachema, M.; Taleb-Ahmed, A.; Berkane, M. New face recognition method based on local binary pattern histogram. In Proceedings of the IEEE International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Hammamet, Tunisia, 21–23 December 2014; pp. 508–513. [Google Scholar]
- Armitage, J.D.; Lohmann, A.W. Character recognition by incoherent spatial filtering. Appl. Opt. 1965, 4, 461. [Google Scholar] [CrossRef]
- Dai-Xian, Z.; Zhe, S.; Jing, W. Face recognition method combined with gamma transform and Gabor transform. In Proceedings of the IEEE international Conference on Signal Processing, Communications and Computing (ICSPCC), Ningbo, China, 19–22 September 2015; pp. 1–4. [Google Scholar]
- Marcolin, F.; Vezzetti, E. Novel descriptors for geometrical 3D face analysis. Multimed. Tools Appl. 2017, 76, 13805–13834. [Google Scholar] [CrossRef]
- Moos, S.; Marcolin, F.; Tornincasa, S.; Vezzetti, E.; Violante, M.G.; Fracastoro, G.; Speranza, D.; Padula, F. Cleft lip pathology diagnosis and foetal landmark extraction via 3D geometrical analysis. Int. J. Interact. Design Manuf. (IJIDeM) 2017, 11. [Google Scholar] [CrossRef]
- Wassermann, L. All of Nonparametric Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Tsybakov, A. Introduction to Nonparametric Estimation; Springer: New York, NY, USA, 2009. [Google Scholar]
- Ramsay, J.; Silverman, B.W. Functional Data Analysis; Springer: New York, NY, USA, 2005. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis. Theory and Practice; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2006. [Google Scholar]
- Gourier, N.; Hall, D.; Crowley, J.L. Estimating Face Orientation from Robust Detection of Salient Facial Features. In Proceedings of the Pointing 2004, ICPR, International Workshop on Visual Observation of Deictic Gestures, Cambridge, UK, 23–26 August 2004. [Google Scholar]
- Rucklidge, W. Efficient Visual Recognition Using the Hausdorff Distance; Springer: Berlin, Germany, 1996. [Google Scholar]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Jesorsky, O.; Kirchberg, K.J.; Frischholz, R.W. Robust Face Detection Using the Hausdorff Distance. In Proceedings of the Third International Conference on Audio- and Video-based Biometric Person Authentication, Halmstad, Sweden, 6–8 June 2001; pp. 90–95. [Google Scholar]
- Dubuisson, M.-P.; Jain, A.K. A Modified Hausdorff Distance for Object Matching. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994. [Google Scholar]
- Devroye, L.; Gyorfi, L.; Lugosi, G. A Probabilistic Theory of Pattern Recognition; Springer: New York, NY, USA, 1996. [Google Scholar]



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saumard, M.; Elbouz, M.; Aron, M.; Alfalou, A.; Brosseau, C. Enhancing Optical Correlation Decision Performance for Face Recognition by Using a Nonparametric Kernel Smoothing Classification. Sensors 2019, 19, 5092. https://doi.org/10.3390/s19235092
Saumard M, Elbouz M, Aron M, Alfalou A, Brosseau C. Enhancing Optical Correlation Decision Performance for Face Recognition by Using a Nonparametric Kernel Smoothing Classification. Sensors. 2019; 19(23):5092. https://doi.org/10.3390/s19235092
Chicago/Turabian StyleSaumard, Matthieu, Marwa Elbouz, Michaël Aron, Ayman Alfalou, and Christian Brosseau. 2019. "Enhancing Optical Correlation Decision Performance for Face Recognition by Using a Nonparametric Kernel Smoothing Classification" Sensors 19, no. 23: 5092. https://doi.org/10.3390/s19235092
APA StyleSaumard, M., Elbouz, M., Aron, M., Alfalou, A., & Brosseau, C. (2019). Enhancing Optical Correlation Decision Performance for Face Recognition by Using a Nonparametric Kernel Smoothing Classification. Sensors, 19(23), 5092. https://doi.org/10.3390/s19235092