1. Introduction
The monocular visual-inertial system, which is usually composed of a low-cost MEMS (Micro-electro- mechanical Systems) IMU and a camera, has turned out to be a highly attractive solution for motion tracking and 3D reconstruction due to its lightweight characteristics of size, weight and power. As a result, monocular visual-inertial state estimation has become a highly active research topic in robotics and computer vision communities.
In the last few decades, there have been a great deal of scholarly work on monocular visual-inertial state estimation. Researchers make use of IMU measurements and monocular camera observations to recover carrier motion and 3D structure. The solutions can be divided into filtering-based approaches [
1,
2,
3,
4,
5] and graph optimization-based approaches [
6,
7,
8,
9,
10,
11]. With the maturity of feature tracking/matching techniques, feature-based approach has become a convention in visual-inertial algorithms. Most of these algorithms process image by tracking/matching sparse features, and minimize the reprojection error in the estimator [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. Recently, direct approach draw researchers’ attention with its capability to exploit information from all intensity gradients in the image [
12]. DSO (Direct Sparse Odometry), which came from Engel [
13], showed remarkable performance in weak intensity variation environments. A tightly-coupled direct approach to visual-inertial odometry was proposed in [
11] very recently, which can perform accurate and robust odometry estimation in little-texture or low-illumination environments.
However, most methods assumed sensors are synchronized well under a common clock [
1,
2,
4,
5,
6,
7,
8,
9], and some of them also required the spatial parameters are determined exactly [
1,
5,
6,
7,
8,
9]. These requirements are not easy to be satisfied in practice. As a matter of fact, for most low-cost and self-assembled sensor suites, accurate factory calibration and hardware synchronization are not available. Consequently, these methods only work properly with a few well-calibrated and strictly-synchronized sensors.
In fact, sensor calibration for the spatial or temporal parameters has gathered tremendous research efforts. The observability of the spatial parameters is analyzed in [
14,
15], and the results show that the spatial parameters are observable given sufficiently excited motions. Four kinds of non-trivial degenerate motions for spatial-temporal calibration are studied in [
16]. Furgale proposed a continuous-time batch optimization framework for spatial-temporal calibration [
17], and provided a widely-used calibration toolbox, Kalibr. However, it requires artificial calibration objects and can only perform offline calibration. For online spatial calibration, Weiss considered optimizing the spatial parameters online in a nonlinear estimator [
2]. Yang emphasized the importance of initial values for online calibration, and proposed initializing the spatial parameters together with the motion of system [
18]. A similar initialization is performed in [
19], where an iterative strategy is conducted to calibrate the extrinsic orientation and gyroscope bias. Nevertheless, these approaches did not consider the temporal offset. Moreover, Li proposed an approach to estimate motion with online temporal calibration in a multi-state constrained EKF framework. In our previous work, we studied the effect of the temporal offset on point reconstruction and proposed calibrating the temporal offset by shifting feature points to match IMU constraints [
20]. A similar approach is performed in [
21], where a coarse-to-fine strategy is applied to calibrate the temporal offset.
Among these calibration approaches, nearly all are built on feature-based visual-inertial odometry. For those approaches able to calibrate the temporal offset, the initialization for the temporal offset is not considered. Therefore, the online calibration may fail when a large temporal offset occurs.
To this end, we implement a direct version of monocular VIO, and propose reliable initialization and online calibration for the spatial-temporal parameters. We assume the spatial-temporal parameters are constant but unknown variables. First, we perform VO (Visual Odometry) only. The spatial orientation and temporal offset are continuously estimated until they converge. After the initialization succeeds, the visual-inertial alignment is carried out to recover initial states for visual-inertial state estimation once excited motion is detected. Then, the visual-inertial odometry with online spatial-temporal calibration is launched. An illustration of performing our VIO algorithm is depicted in
Figure 1. We highlight our contribution as follows:
We design a feature-based initialization algorithm to initialize monocular direct visual odometry, which can detect motion effectively and initialize the map with higher robustness and efficiency compared to the initialization of DSO.
We derive a robust and accurate optimization-based initialization to estimate the spatial orientation and temporal offset together. The initialization is able to recover sufficiently accurate results without any prior system knowledge or artificial calibration objects.
We derive a monocular direct visual-inertial estimator with online spatial-temporal calibration. The estimator can also estimate other states such as IMU pose and 3D geometry.
2. Preliminaries
In this section, we describe the necessary notations for this paper, and give a definition for the spatial parameters and temporal offset. Besides, the error functions used in the nonlinear optimization are briefly reviewed.
2.1. Notation
In this paper, we use bold upper case letters to represent matrices, bold lower case to denote vectors. Scalars are represented by light lower case . We use quaternion or rotation matrix to denote rotation. If a vector/quaternion/rotation matrix describes the relative transformation from one original frame to another frame, a right subscript is appended to indicate the original frame, and the right superscript denotes the transformed frame, e.g., denotes the translation from frame a to frame b, or denotes the rotation from frame a to frame b. Moreover, we consider v as vision frame, which is defined by the first camera frame in visual odometry. We consider w as world frame, where gravity is along with z axis. We consider b as body frame aligned with IMU frame, and c as camera frame.
2.2. Spatial Parameters Definition
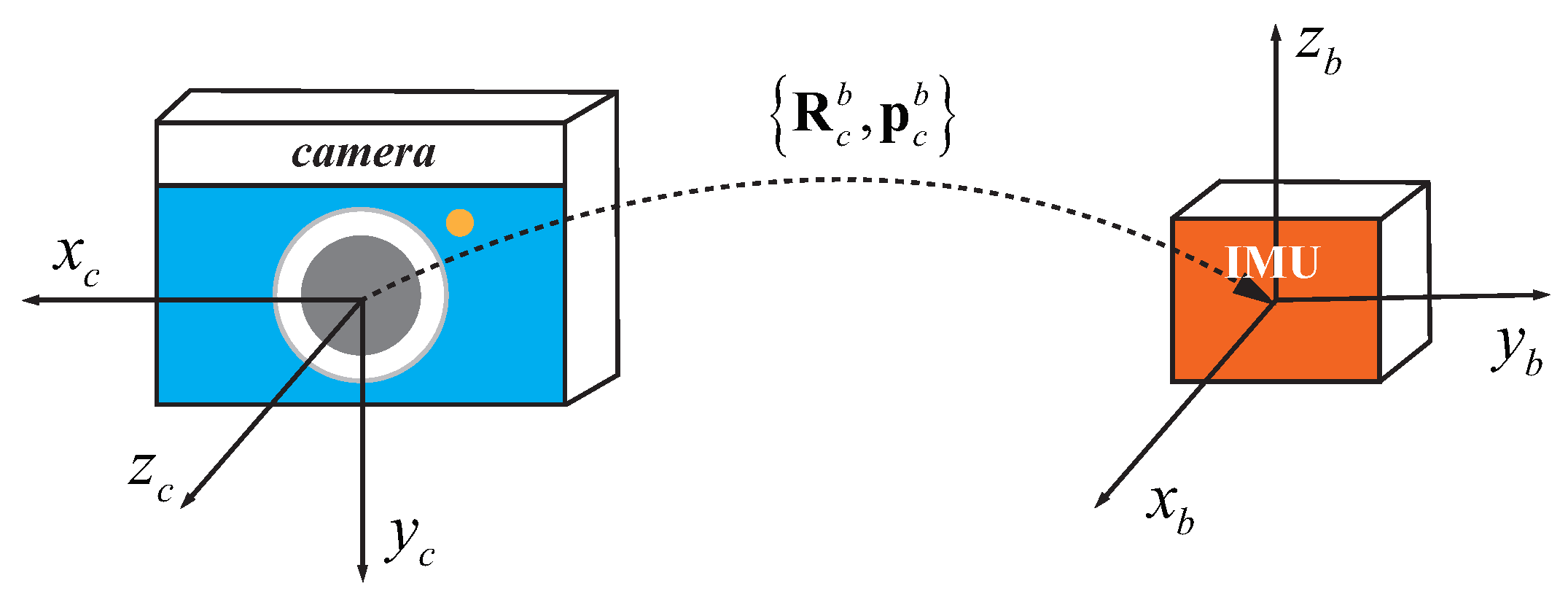
To fuse IMU and camera measurements, the coordinate transformation between IMU and camera is required. In this paper, the spatial (extrinsic) parameters
between IMU and camera is the relative transformation from
c to
b, as illustrated in
Figure 2.
2.3. Temporal Offset Definition
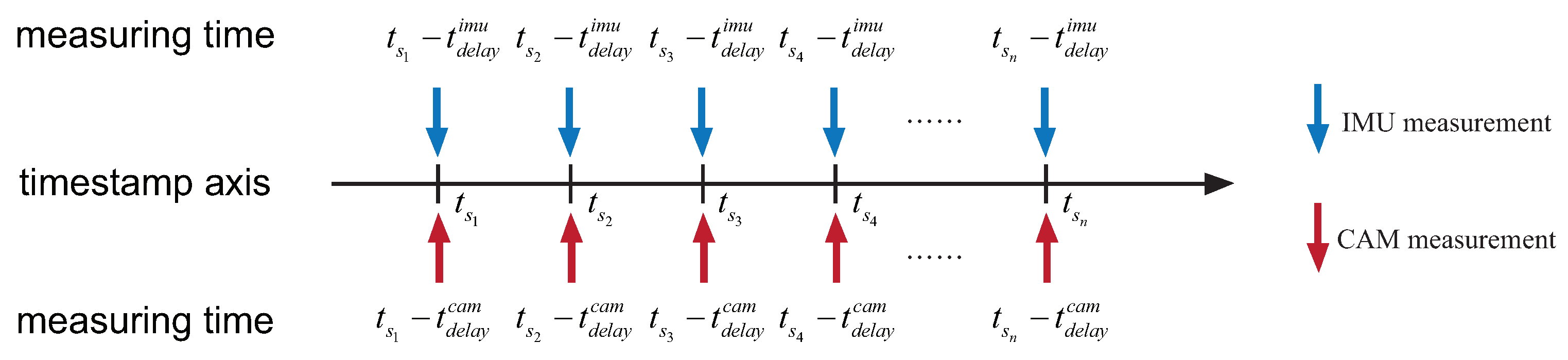
Timestamp of sensor measurements always suffers a delay, since the timestamp is generated after measurement creation. The delay has various causes: triggering delay, communication delay, unsynchronized clocks, etc. Here, we use
t to denote measuring time,
to denote timestamp, and
to denote the delay. The relationship of measuring time and timestamp is:
Therefore, if we directly align different sensors measurements with their timestamps, a temporal misalignment occurs, as illustrated in
Figure 3. In this paper, we assume sensor delays are constant. Considering the IMU and camera measurements measured at the same time
t, the timestamps of these measurements are:
The temporal offset can be defined as the difference of these two timestamps:
With this definition, we can align measurements with their timestamps easily. For example, given a camera image with a timestamp , the matching IMU measurement should have a timestamp . Conversely, given an IMU measurement with a timestamp , the image captured at the same time is attached with a timestamp .
2.4. Photometric Error
We use the same photometric error model as [
13]; the photometric error of a point
in host frame
i reprojected in a target frame
j is defined as:
where
is the point reprojected in frame
j,
is a pixel from the pixels set
of the point
p,
is the gradient-dependent weight of
,
is the pixel reprojected into frame
j,
and
are the image intensity of frame
i and frame
j,
are the exposure times,
are the illumination parameters and
is the Huber norm.
Then, we can formulate the total photometric error of all keyframes in the optimizing window as follows:
where
is a set of keyframes in the window,
is a set of sparse points in keyframe
i, and
is a set of observations of the same point in other keyframes.
2.5. IMU Error
We follow the preintegration approach first proposed in [
22] and extended by Forster [
7], and we choose the quaternion-based derivation for our implementation [
10]. This allows us to add IMU constraints between consecutive IMU states.
For two consecutive IMU states
and
, after preintegration, we obtain an IMU preintegration measurement associated with a covariance matrix
. The IMU error function is
where
,
is IMU position,
is IMU orientation,
is IMU velocity,
is accelerometer bias,
is gyroscope bias, and
is the IMU preintegration residual defined in [
10] (Equation (
16)).
3. Methodology
This section details the proposed initialization and optimization for the spatial-temporal parameters. The system starts with direct visual odometry. During visual odometry, the system stores keyframe camera poses and corresponding IMU preintegrations, and then keeps initializing the spatial orientation and temporal offset by minimizing the rotation error between camera relative rotation and IMU pre-integrated rotation until a convergence threshold is exceeded. After the sensors are aligned spatially and temporally, the visual-inertial alignment is carried out to recover the scale, gravity and velocity for visual-inertial state estimation once excited motion is detected. Then, visual-inertial odometry is performed to optimize the spatial-temporal parameters together with IMU states and point inverse depths.
3.1. Initialize Monocular Direct VO
The monocular direct visual odometry proposed in [
13] has shown high robustness and accuracy in motion tracking and 3D reconstruction, which inidicated the feasibility of using the poses from direct visual odometry to align with IMU preintegrations.
However, the initialization in [
13] is slow and quite fragile, where map points are initialized by minimizing the photometric error directly. In fact, without any motion prior or structure prior, a corrupted map is likely to be created, which will reduce the accuracy and reliability of the following camera poses. Therefore, inspired by Mur-Artal et al. [
23], we initialize visual odometry with a feature-based approach. We extract and track sparse features from the images. The camera poses and 3D points are recovered with two-view geometry constraints. Some direct approaches such as DTAM [
24] also initialize with a feature-based approach. We highlight the difference between our initialization and the others: our initialization is more robust since we verify the translation of camera before the initialization is completed. Most feature-based initialization algorithms usually end up with a verification of the reprojection error, which is not reliable enough in our view because, in monocular visual odometry, the 3D structure is only able to be recovered properly with sufficiently translation. The steps of our algorithm are as follows:
Feature extracting:
Extract sparse features [
25] in the first frame, and record the amount
N of features.
Feature tracking:
Track features using KLT optical flow algorithm [
26]. If the features amount
, reset the first frame and go to Step 1.
Optical flow check:
Measure camera motion by the root mean square optical flow . If , go to Step 2.
Motion recovery:
Find the fundamental matrix
with feature correspondences and recover camera motion by decomposing
[
27]. Then, triangulate points and check the reprojection error of the features to decide whether the recovery has succeeded or not. If the recovery fails, try to recover camera motion from the homography matrix
[
27]. If both fail, go to Step 2. Otherwise, we can obtain the relative pose
from the first frame to the current frame, and the depth
d of the features.
Translation verification:
Warp the bearing vector of features with translation only , where is the bearing vector of . Then, verify sufficient translation by checking the root mean square position offset . If , go to Step 2.
Direct bundle adjustment and point activation:
Perform direct bundle adjustment given the initial value of and d, to refine the initial reconstruction and estimate the relative illumination parameters from the first frame to the current frame. Then, extract more points on the first frame, and do a discrete search on epipolar line to activate these candidates for the following visual odometry.
An example of VO initialization on Room 1 [
28] is shown in
Figure 4. It is obvious that DSO generated a corrupted map after initialization, while the structure was recovered correctly with our feature-based initialization algorithm.
3.2. Initialization for Spatial-Temporal Parameters
Considering two consecutive frames
i and
, we get the camera rotation
and
from visual odometry, as well as the preintegrated rotation
from IMU preintegration. We can establish an equation of rotation residual as follows:
where
,
, and
is the vector part of the quaternion
. Actually, we can estimate the gyroscope bias
and the extrinsic rotation
together by solving a nonlinear least square problem with the rotation residuals constructed from all stored keyframes, if there is no temporal offset.
However, there may be a temporal misalignment between the IMU preintegrated rotation and the camera relative rotation. Assume
is calculated from the IMU measurements with timestamps between
and
.
is the relative rotation of two camera poses with the same timestamps
and
. According to the definition of the temporal offset (Equation (
3)), to align the camera poses to the IMU preintegrated rotation, the timestamps of the matched images are
and
. Therefore, the aligned relative camera rotation is
Assuming the camera rotates in a constant angular velocity between two keyframes, we can get
, where
are camera angular velocities that can be calculated from the stored keyframe poses as follows:
By substituting
of Equation (
8) into Equation (
7), we can estimate the extrinsic rotation, temporal offset and gyroscope bias jointly by minimizing the following error function:
where
is a set of all stored keyframes. We do not consider initializing the extrinsic translation since it is usually small and can be simply initialized to
in practice.
3.3. Visual-Inertial Nonlinear Optimization
After initializing the spatial and temporal parameters, we perform a loosely coupled approach proposed in [
29] to recover the velocity, gravity and metric scale. Then, we can launch a tightly coupled estimator to optimize all states jointly. For each active keyframe, we define a state vector (the transpose is ignored for states definition in Equations (
11) and (
12))
where
is the IMU state defined in
Section 2.5.
are the illumination parameters, and
is the inverse depth of the
kth point hosted in the
ith keyframe.
The full states of optimization are defined as follows:
We assume the IMU in the system is moving with a constant velocity during a short period of time. Thus, the IMU pose at any time can be extrapolated with its nearest IMU pose, linear velocity and angular velocity, which means
where
is the angular velocity of the IMU. With Equation (
13), we can calculate the IMU poses at the time when the images are captured.
Thus, considering the spatial-temporal parameters, the reprojection formula can be written as
where
is the projection function, which projects a 3D point into the pixel plane.
is the back projection function, which turns a pixel into a bearing vector using camera intrinsic parameters. With Equation (
15), we can evaluate the photometric error with IMU pose, velocity, point inverse depth and the spatial-temporal parameters.
It should be noted that we ignore the visual constraints on IMU velocity to reduce the computation complexity, and no notable effect on accuracy is observed. All states are optimized by minimizing the object function
where
and
are the IMU error and the photometric error defined in
Section 2.4 and
Section 2.5, respectively. The prior error
is evaluated from the prior information, and the prior is obtained by marginalizing past states using the Schur complement [
30] with the two-way marginalization strategy proposed in [
31]. To maintain consistency of the estimator and reduce computational complexity, we apply the “First estimate Jacobians” (FEJ) approach proposed in [
32], which means all states constrained by the prior in the sliding window are linearized at the same point as in previous marginalization. We solve the nonlinear least square problem with the Levenberg–Marquardt (L-M) method.
3.4. Criteria in Initialization and Optimization
To perform robust initialization and calibration for the spatial-temporal parameters, several criteria should be met to ensure all procedures perform properly. The initialization should end up with a convergence criteria satisfied. The online calibration is required to begin with sufficiently excited motion, otherwise the system matrix will suffer rank-deficiency due to the unobservable states.
(1) Initialization termination criteria
Successful calibration of the spatial-temporal parameters (exclude extrinsic translation) and gyroscope bias relies on the observability of these states. Under good observability, the null space of the Jacobian for Equation (
7) should be rank one. Therefore, we detect the observability of the states by checking whether the second smallest singular value of the Jacobian
is sufficiently large. If
, these states are possible to be identified.
Additionally, we check the average rotation error to make sure the states are estimated correctly. The average rotation is defined as follows:
where
M is the number of all stored keyframes used in initialization. The initialization process terminates if
and
.
(2) Sufficient excitation condition
Before performing the online calibration, we need to check whether the motion is excited enough. According to the study in [
16], under several types of degenerate motion, the spatial-temporal parameters are not able to be determined completely. Thus, we verify the excitation by checking whether the variance of the spatial-temporal parameters is sufficiently small. The covariance of full states is the inverse Hessian matrix of the states.
After the nonlinear estimator is launched, we do not optimize the spatial-temporal parameters immediately. We set three thresholds for the variance of the extrinsic rotation, translation and temporal offset, respectively. The specific parameters are only estimated after the corresponding variance is lower than its threshold. For example, if , we start to estimate in the estimator. Before that, is fixed by setting the corresponding columns of the Jacobians of the residual vector to zero.
4. Experimental Results
We verified the performance of our initialization and online calibration with the EuRoC dataset [
33]. The dataset provides stereo images (Aptina MT9V034 global shutter, 20 FPS), synchronized IMU measurements (ADIS16448, 200 Hz) and ground truth states (Leica MS50 and VICON). We only used the left camera from stereo images set. To demonstrate the capability of spatial-temporal estimation, we first set the temporal offset by manually shifting image timestamps with a constant camera delay and generated time-shifted sequences. Then, we tested the proposed algorithm and other methods on these sequences with the initial values of
set to
. All experiments were carried out on a laptop computer with Intel CPU i7-3630QM (4 cores @2.40 GHz) and 16 GB RAM. The parameters we mentioned above were set as follows:
,
,
,
,
,
,
, and
. In our experience, these parameters can be set in a wide range and have no significant impact on the performance. It should also be noted that we evaluated the orientation error and translation error using the following formulas, respectively:
4.1. Spatial-Temporal Initialization Performance
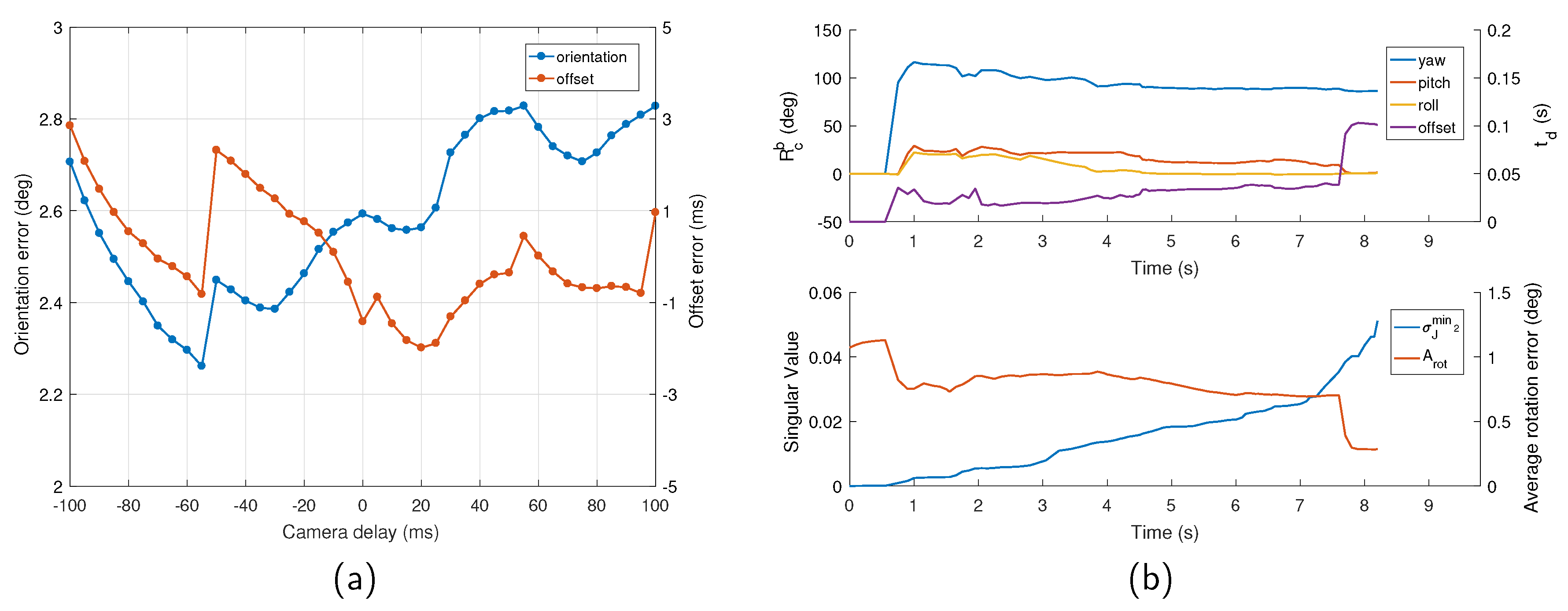
In this test, the sequence V1_02_medium was used to verify the performance of the proposed initialization. To demonstrate the capability of our approach under different temporal offsets, we set the camera delays from −100 to 100 ms manually, and tested these time-shifted sequences with our initialization method. The result is depicted in
Figure 5a. It can be seen that the initialization could obtain accurate extrinsic orientation and temporal offset for a wide range of temporal offsets, achieving a typical precision of 3 degrees for the orientation and 3 ms for the time offset, which are sufficiently fine to support the following optimization.
Typical time varied characteristic curves of the spatial-temporal parameters and the convergence criteria are shown in
Figure 5b. It is evident that, over time,
became larger due to the accumulated measurements, which indicates the growing observability of the orientation and offset. Additionally, the orientation gradually converged and could be determined well even when the offset was quite inaccurate. On the contrary, the accuracy of the time offset estimate was highly dependent on the observability of the system (i.e., whether
was sufficiently large). Only when
exceeded a certain threshold, the temporal offset was immediately estimated at high accuracy, and the average rotation error decreased instantly, which proved the necessity and feasibility of the proposed criteria.
4.2. Overall Performance
We next compared our method against VINS-Mono [
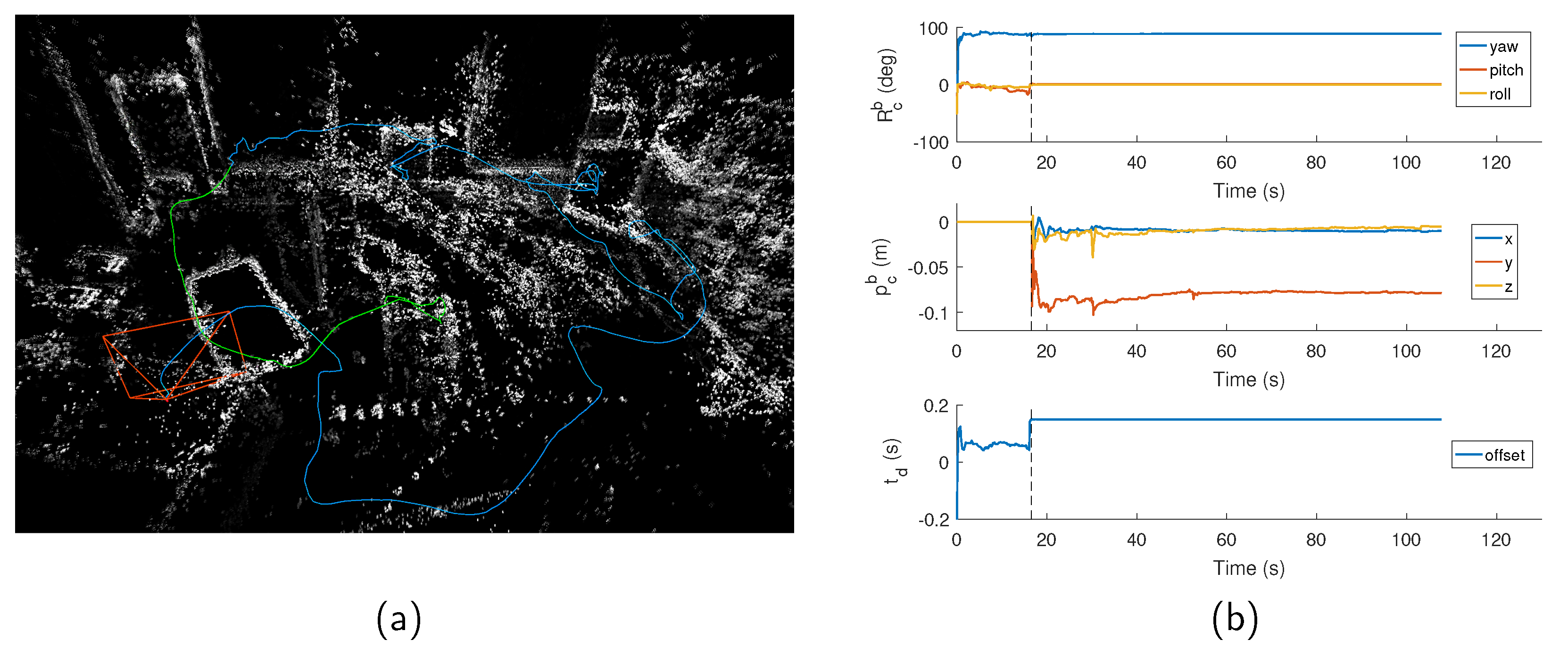
10], which is another state-of-the-art visual-inertial odometry algorithm with online spatial-temporal calibration ability. To test the performance under different time offsets, we set the camera delay to 0 ms, 50 ms and 100 ms on 11 EuRoC datasets, and launched the programs on these time-biased sequences. The VINS-Mono was launched without knowing the prior spatial-temporal parameters. The errors of the calibrated spatial-temporal parameters and the absolute translational RMSE (Root Mean Square Error) of the keyframe trajectory are shown in
Table 1. All of these results are the median over five executions in each sequence.
It can be seen that our method was more robust against large temporal offset, since we determined the offset in the initialization. The temporal offset estimated with our method achieved sub-millisecond accuracy, which was much more accurate than the offset estimated from VINS-Mono. It can be interpreted as having two reasons: (1) we initialized and obtained a accurate temporal offset before the nonlinear optimization, while VINS-Mono directly estimated the offset during the nonlinear optimization linearizing at an inaccurate time offset; and (2) to match visual measurements to IMU constraints, we extrapolated IMU pose with instant IMU state and measurement for visual point reprojection, while VINS-Mono extrapolated feature position with average camera motion. The average camera motion was of lower accuracy than instant IMU state, especially when the system was in high dynamic environments. Both VINS-Mono and our method could estimate extrinsic orientation and translation with errors of about 0.6 degrees and 0.02 m, respectively. In terms of the trajectory accuracy, most of the trajectories estimated by our method were of higher accuracy than those of VINS-Mono, especially on the MH sequences.
5. Conclusions
In this paper, we perform a direct version of monocular visual-inertial odometry, and propose a novel initialization and online calibration for the spatial-temporal parameters without any prior information. Specifically, our approach is able to automatically identify observability and convergence of the spatial-temporal parameters. We highlight that our approach is a general model, and can be easily adopted into either direct-based or feature-based VIO frameworks. Experiments demonstrated that our approach achieves competitive accuracy and robustness compared with the state-of-the-art approach, especially when the temporal offset is large.
Moreover, our approach can be extended for rolling shutter calibration. Considering most smart devices (e.g., smartphones and tablets) choose rolling shutter cameras to capture images for the cheaper price and the potentially higher frame rate and resolution than global shutter cameras, rolling shutter calibration is essential for the visual-inertial odometry using a smart device. We plan to extend our approach on rolling shutter cameras next.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}