Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition


Abstract
:1. Introduction
- The proposed CDBN method integrates a new competitive learning mechanism into deep-belief networks to learn more robust and discriminative features for underwater acoustic target recognition.
- The proposed CDBN method can make use of unlabeled samples to solve the small-sample-size problem of underwater acoustic target recognition.
- Compared with traditional hand-engineered feature-extraction methods, the proposed method can learn features from datasets automatically, and does not require prior knowledge.
- The experimental results demonstrated that the proposed CDBN method is effective for underwater acoustic target recognition. It can significantly reduce the random noise and enhance the line-spectrum characteristics of ship noises, and the CDBN features have better classification performance than other hand-engineered features.
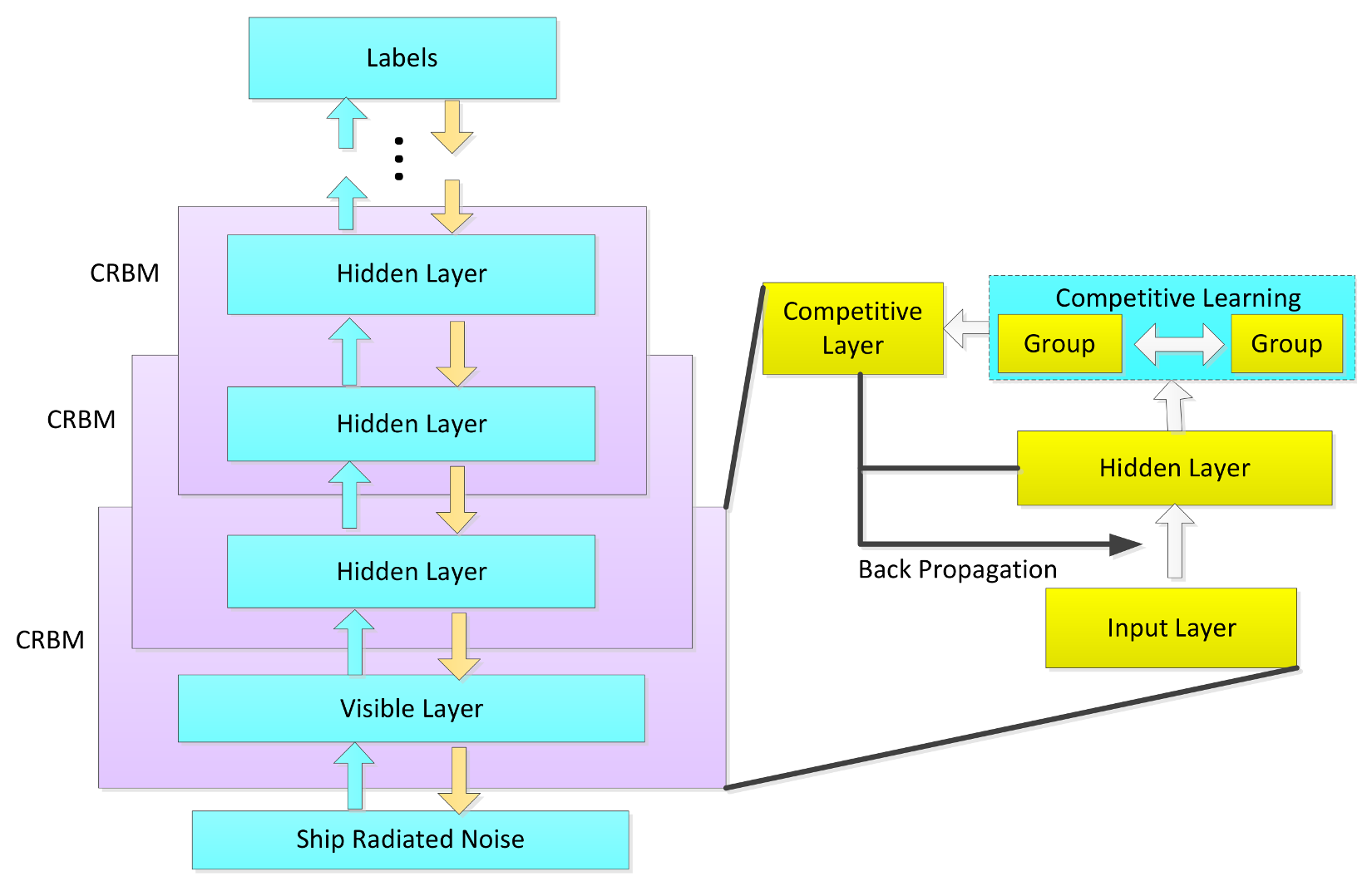
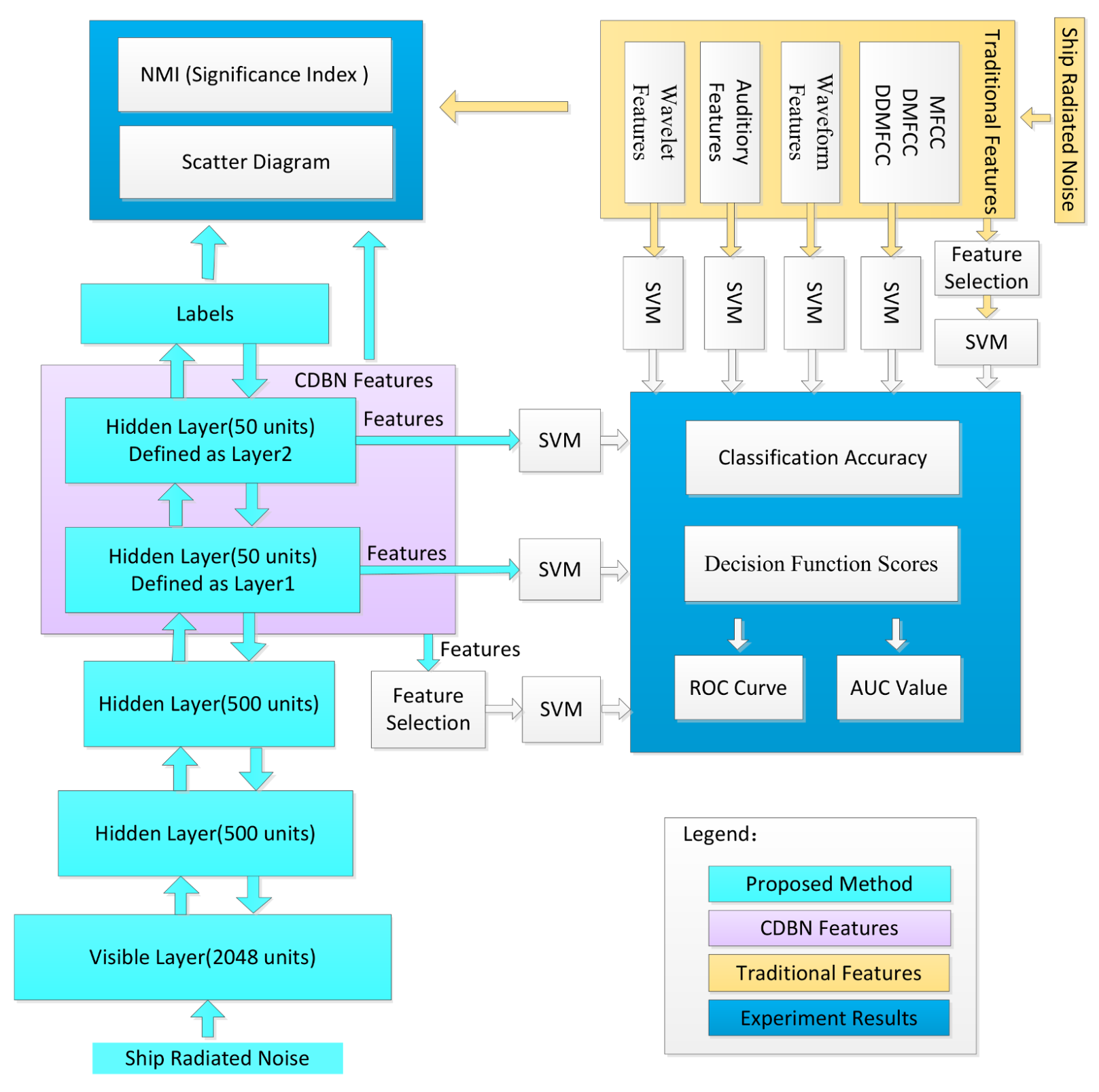
2. Competitive Deep-Belief Networks
3. Competitive Deep-Belief Network Design
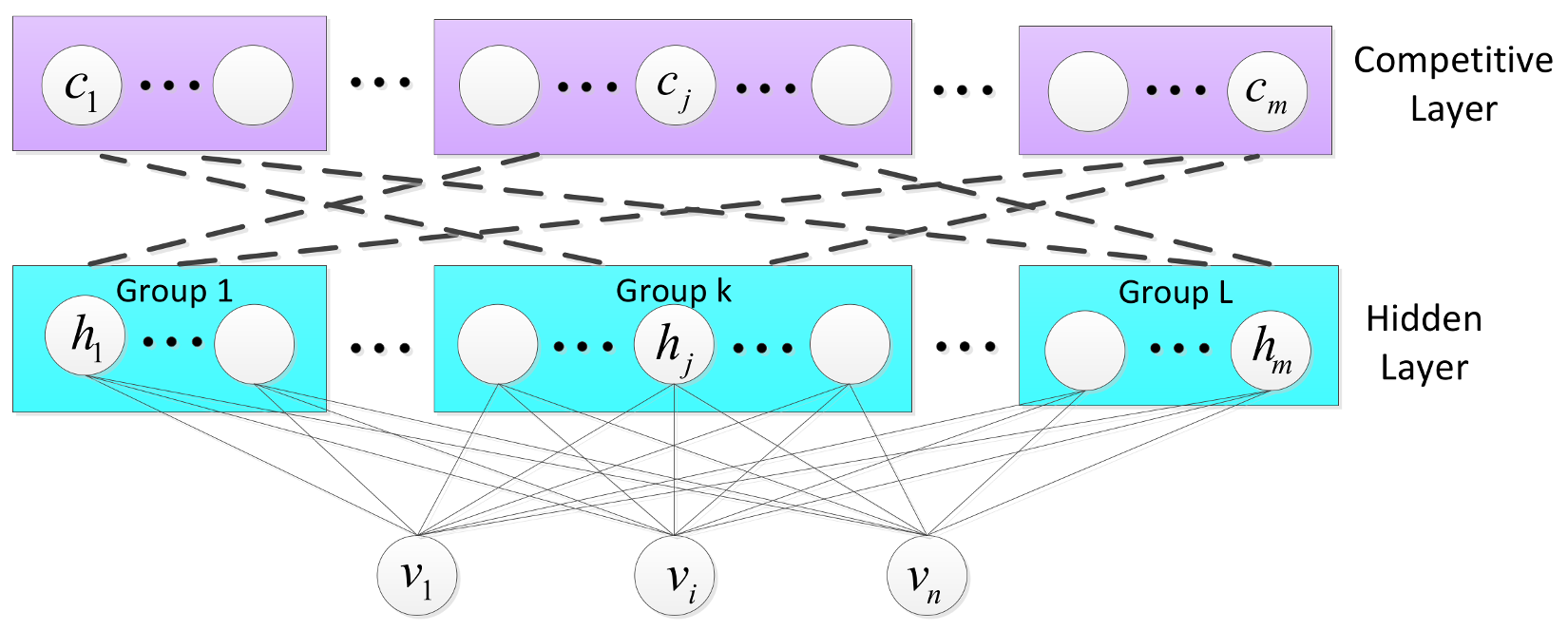
3.1. Restricted Boltzmann Machine
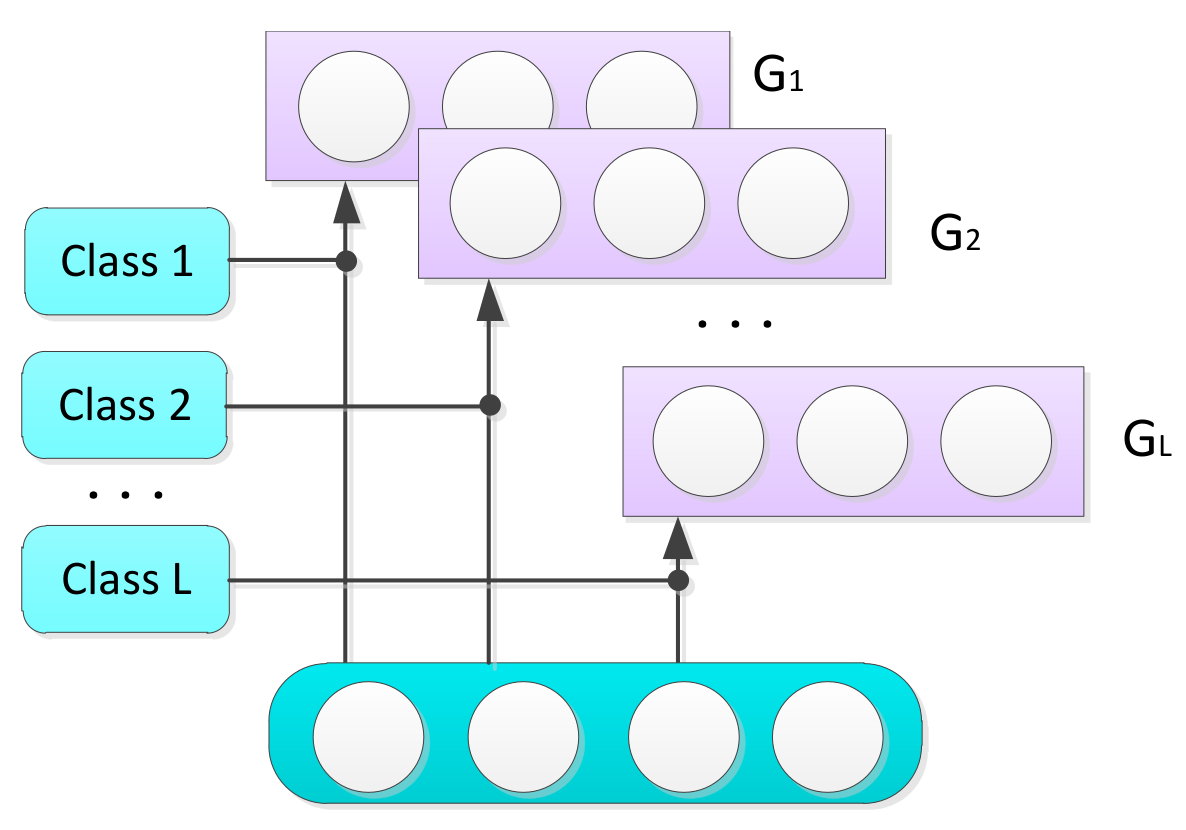
3.2. Competitive Groups
3.3. Competitive Layer
3.4. Deep Architecture
4. Experiments and Discussion
4.1. Experimental Dataset and Procedure
- RBM was pretrained with 20,000 unlabeled datapoints in an unsupervised manner.
- The hidden units of RBM were grouped using 2800 labeled training datapoints.
- Competitive learning was conducted to construct a CRBM.
- A 2048-500-500-50-50 CDBN was constructed by greedy layer-wise training and supervised fine-tuning to obtain CDBN features.
- SVM was used to evaluate the classification performance of CDBN features.
- The classification performance of CDBN features was compared with four widely used traditional hand-engineered feature sets.
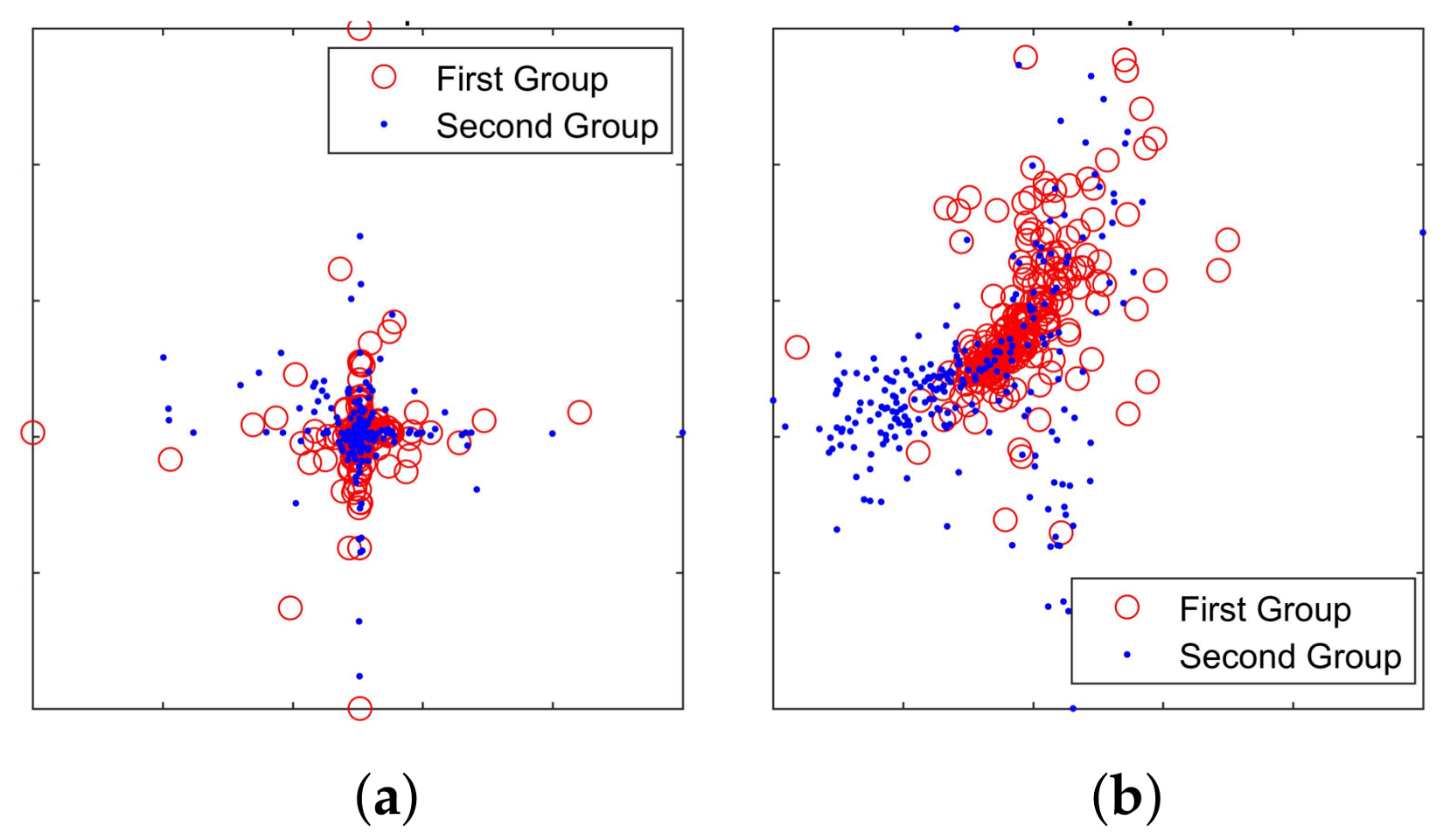
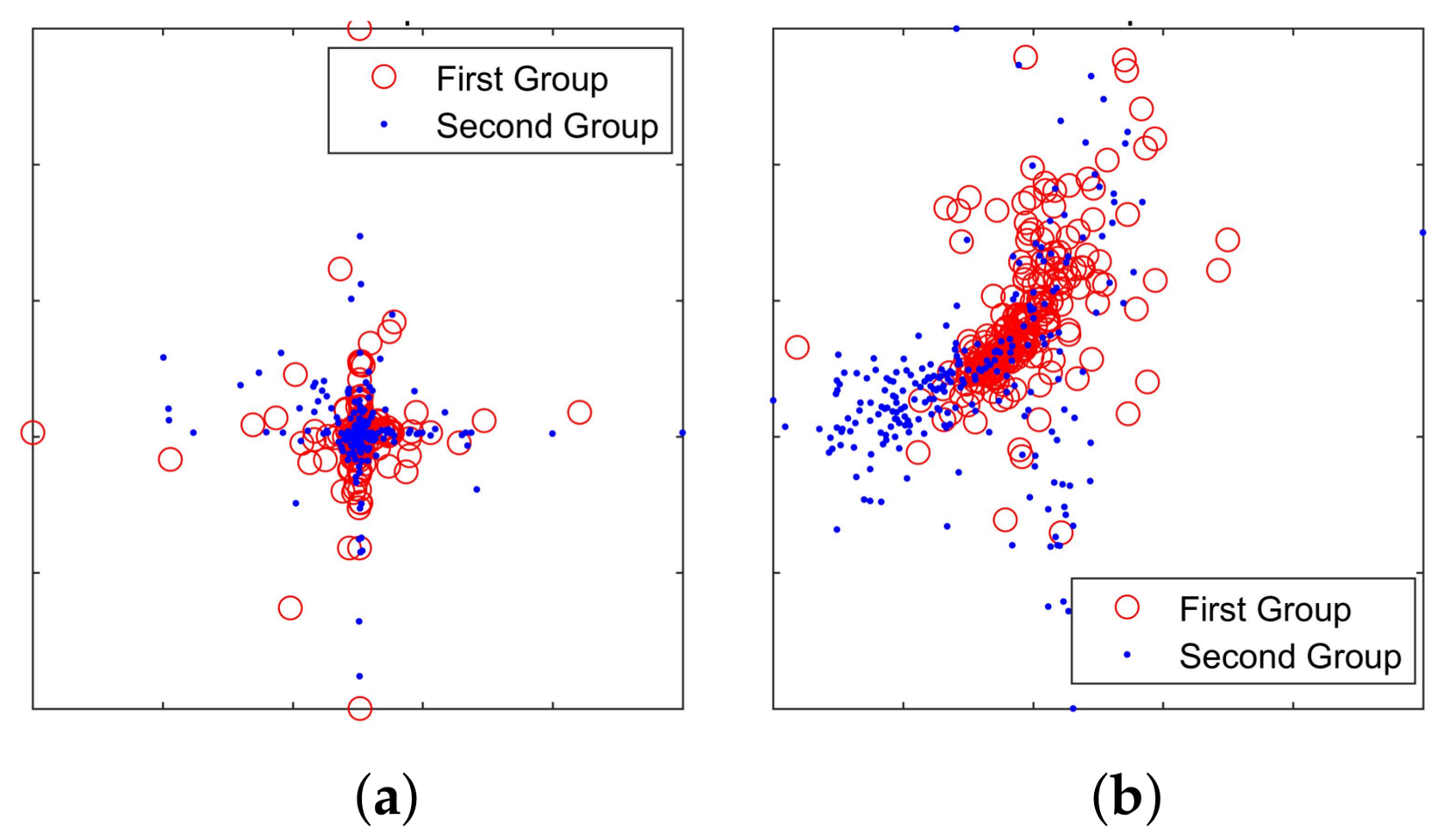
4.2. Grouping Experiment
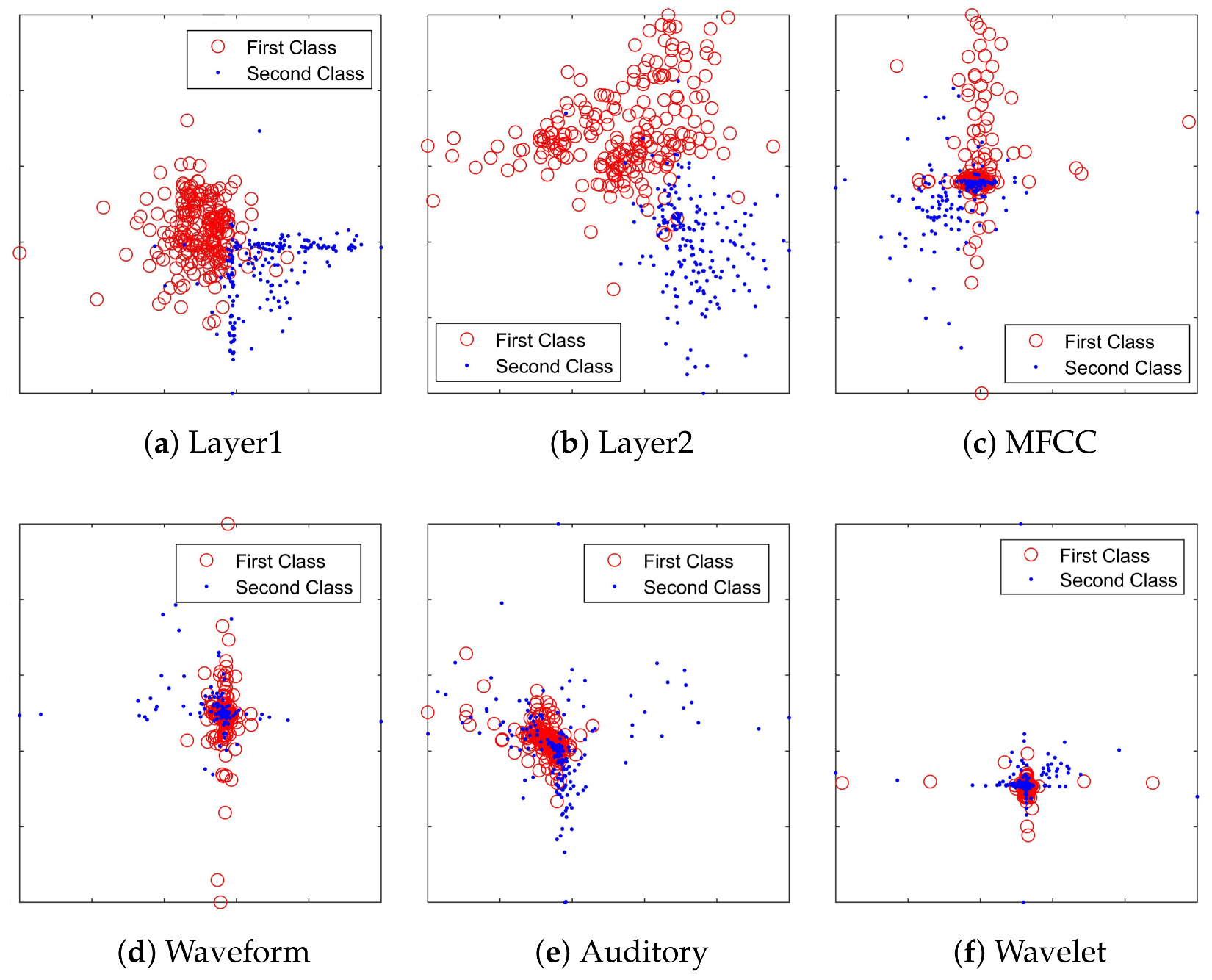
4.3. Feature Visualization
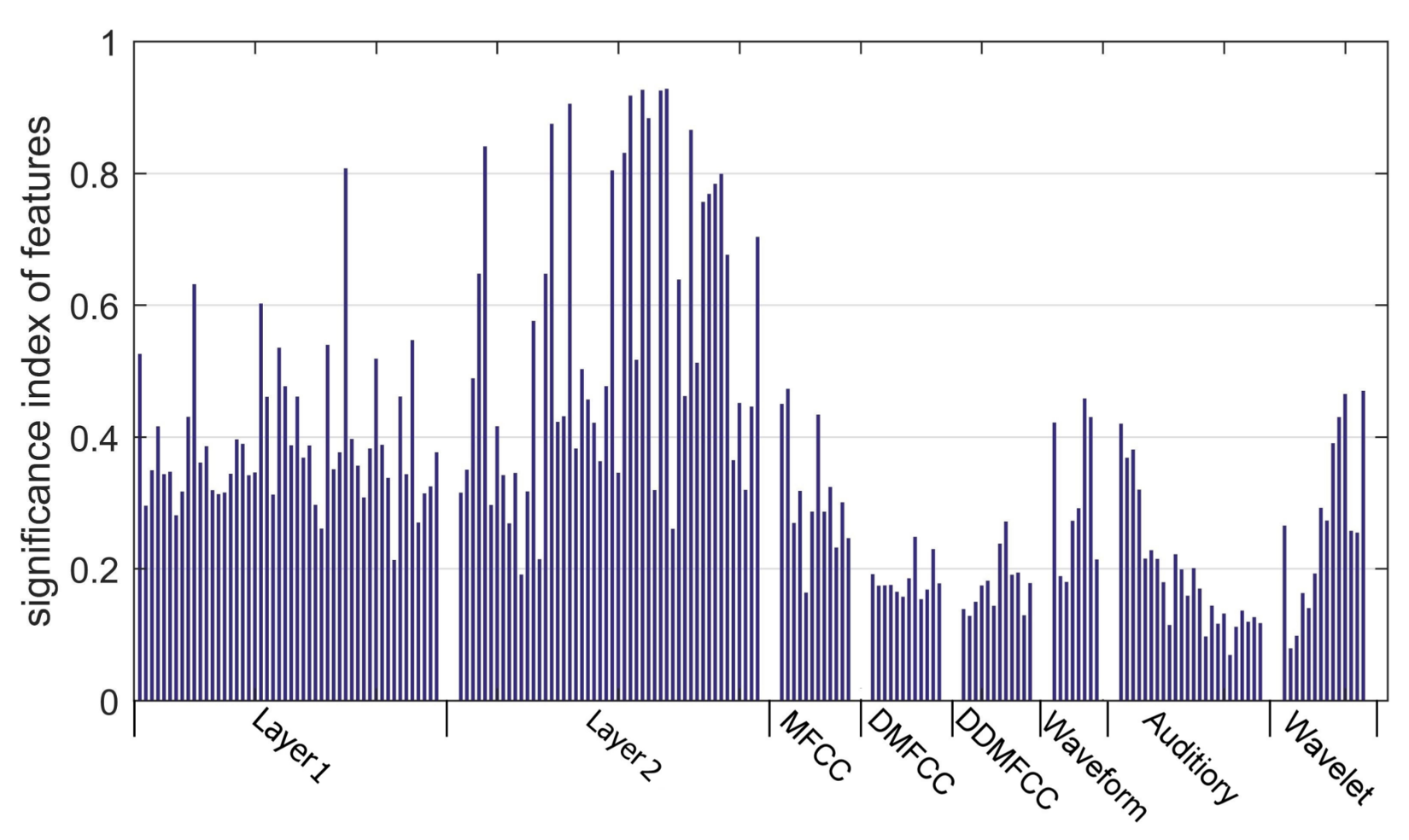
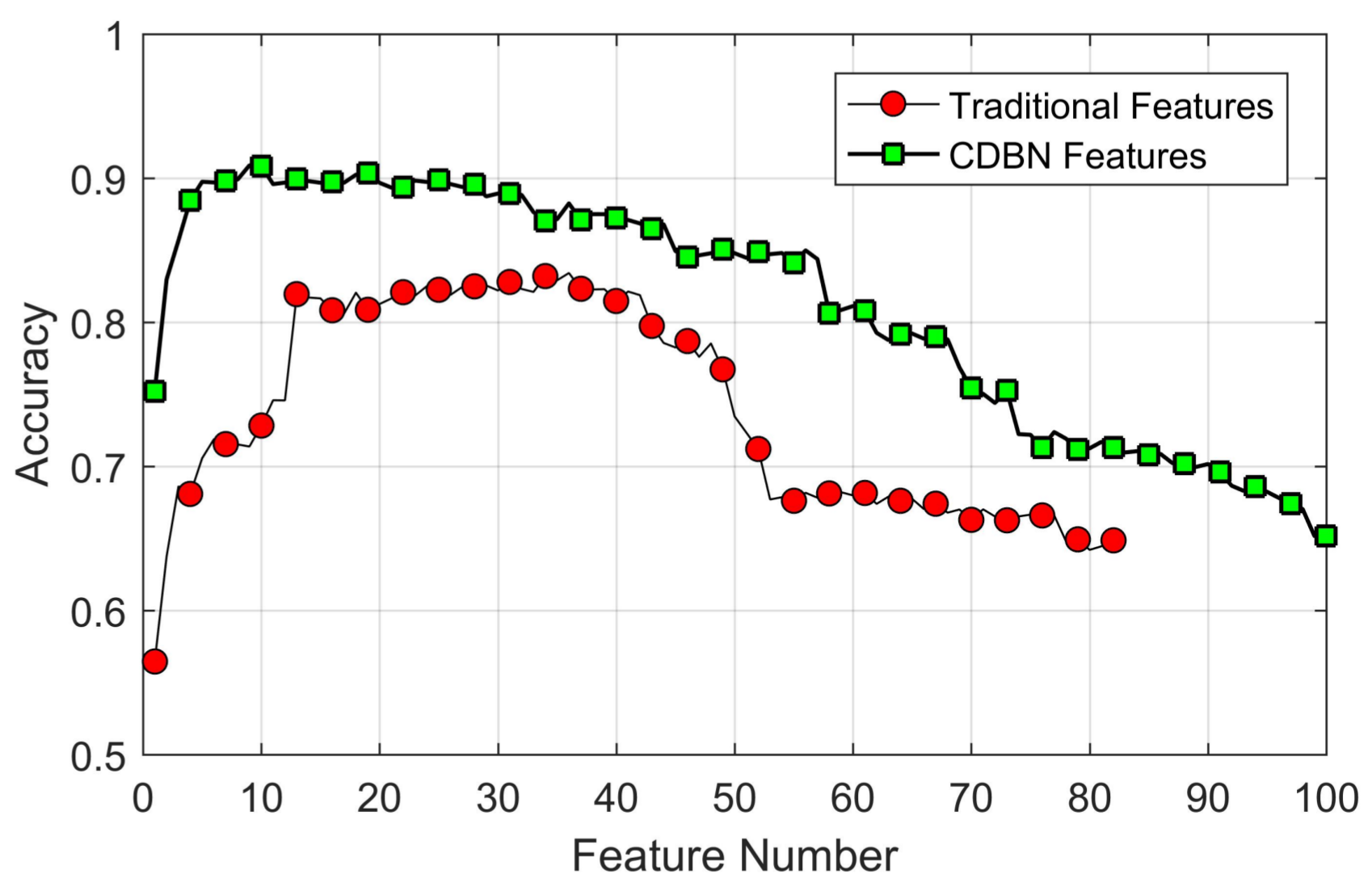
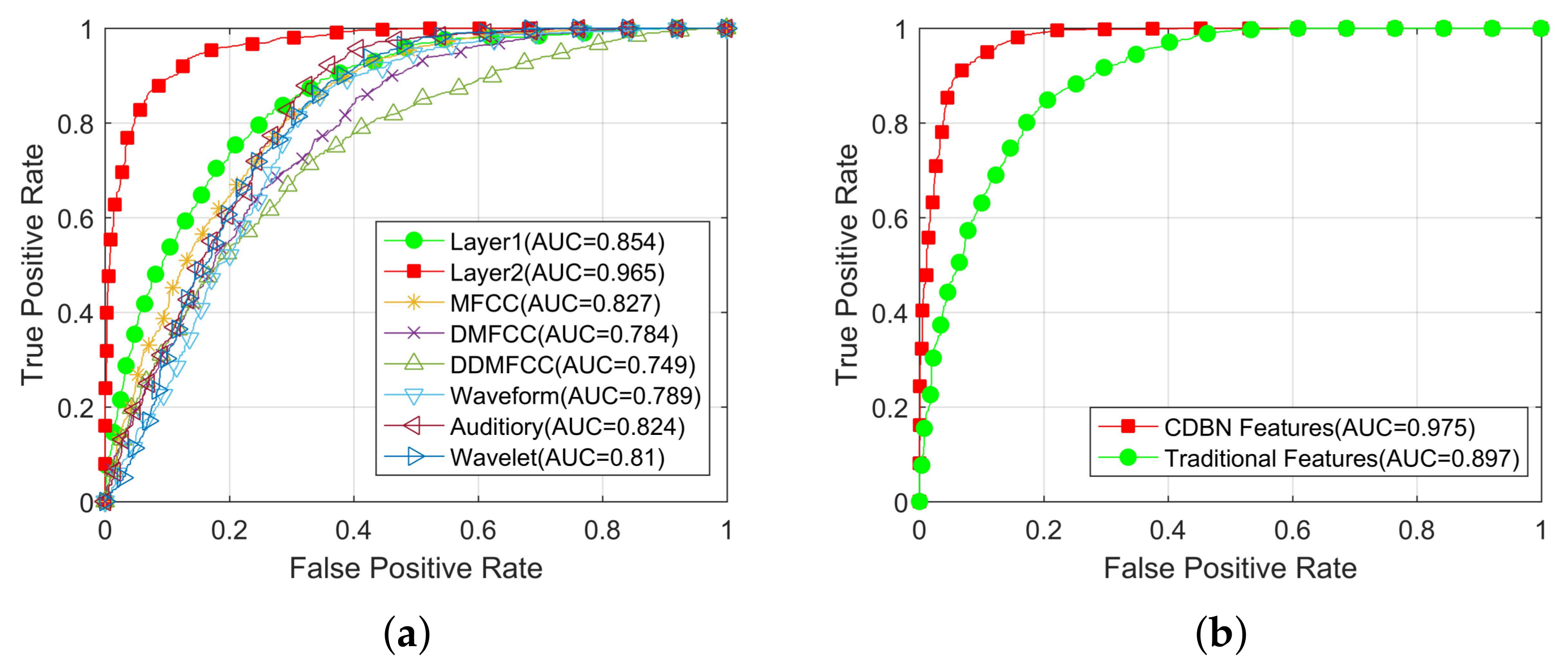
4.4. Features Evaluation
4.5. Classification Experiment
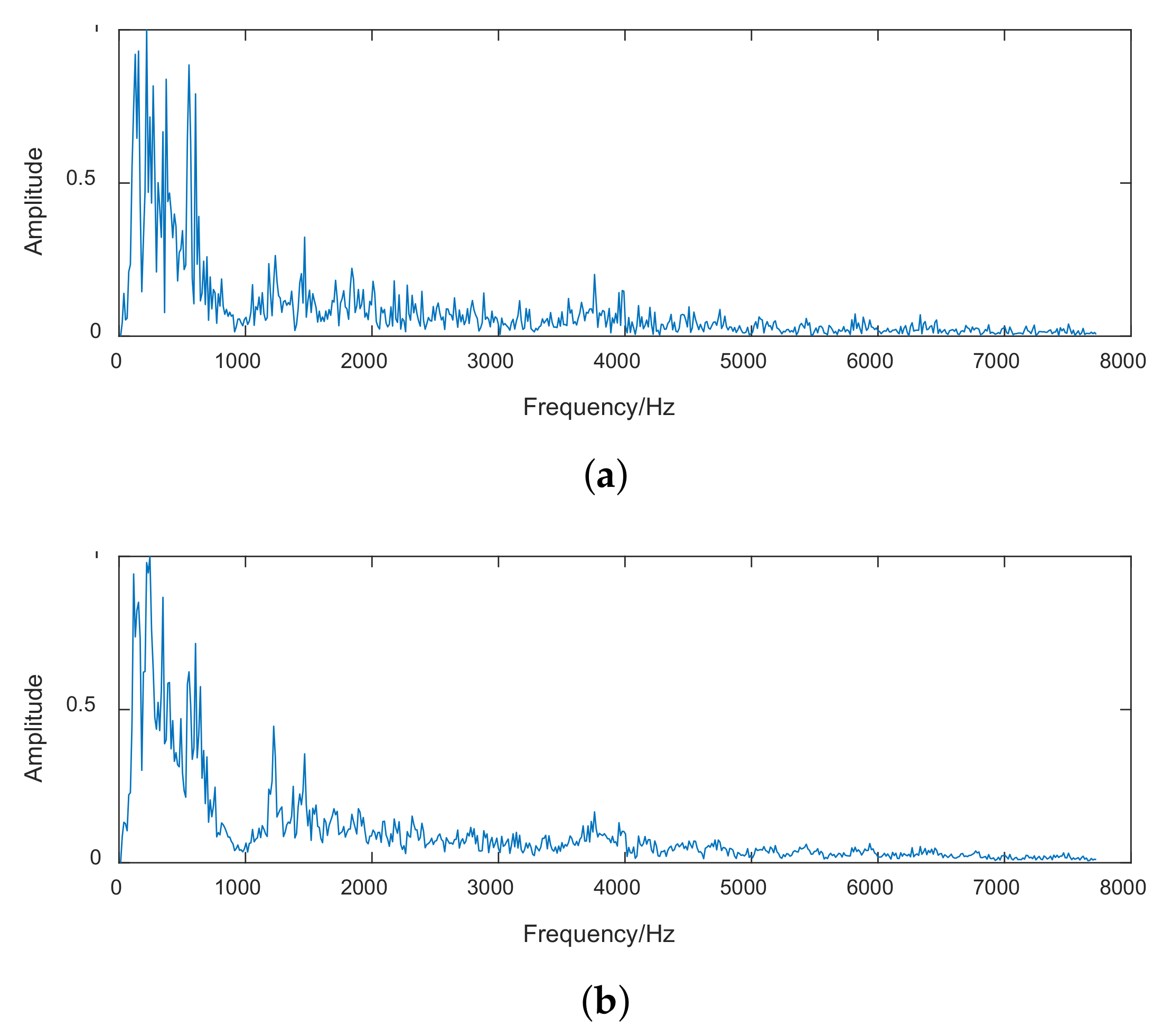
4.6. Spectrum Reconstruction of Ship-Radiated Noise with CDBN
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| RBM | restricted Boltzmann machine |
| DBN | deep-belief networks |
| CRBM | competitive restricted Boltzmann machine |
| CDBN | competitive deep-belief networks |
| SVM | support vector machine |
| MFCC | Mel-frequency cepstral coefficients |
| DMFCC | first-order differential Mel-frequency cepstrum coefficients |
| DDMFCC | second-order differential Mel-frequency cepstrum coefficients |
| DFT | discrete Fourier transforms |
| NMI | normalized mutual information |
| ROC | receivers operating characteristic |
| AUC | area under ROC curve |
References
- Meng, Q.; Yang, S. A wave structure based method for recognition of marine acoustic target signals. J. Acoust. Soc. Am. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.R.; Yao, D.; Huang, Q.; Dobeck, G.J. Underwater target classification using wavelet packets and neural networks. IEEE Trans. Neural Netw. 2000, 11, 784–794. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Gang-Hu, L.I.; Wang, Z.Q. Underwater Target Recognition Based on Wavelet Packet and Principal Component Analysis. Comput. Simul. 2011, 28, 8–290. [Google Scholar]
- Yang, L.X.; Chen, K.A.; Zhang, B.R.; Liang, Y. Underwater acoustic target classification and auditory feature identification based on dissimilarity evaluation. Acta Phys. Sin. 2014, 63, 134304. [Google Scholar]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sens. 2016. [Google Scholar] [CrossRef]
- Tuma, M.; Rørbech, V.; Prior, M.K.; Igel, C. Integrated Optimization of Long-Range Underwater Signal Detection, Feature Extraction, and Classification for Nuclear Treaty Monitoring. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3649–3659. [Google Scholar] [CrossRef]
- Yang, H.; Gan, A.; Chen, H.; Pan, Y. Underwater acoustic target recognition using SVM ensemble via weighted sample and feature selection. In Proceedings of the International Bhurban Conference on Applied Sciences and Technology, Islamabad, Pakistan, 12–16 January 2016; pp. 522–527. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yang, H.; Shen, S.; Yao, X.; Han, Z. Underwater Acoustic Target Feature Learning and Recognition using Hybrid Regularization Deep Belief Network. Xibei Gongye Daxue Xuebao/J. Northwest. Polytech. Univ. 2017, 35, 220–225. [Google Scholar]
- Shen, S.; Yang, H.; Han, Z.; Shi, J.; Xiong, J.; Zhang, X. Learning robust features from underwater ship-radiated noise with mutual information group sparse DBN. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference, Hamburg, Germany, 21–24 August 2016; pp. 4855–5847. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. Momentum 2012, 9, 599–619. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sarikaya, R.; Hinton, G.E.; Deoras, A. Application of Deep Belief Networks for natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 778–784. [Google Scholar] [CrossRef]
- Raina, R.; Battle, A.; Lee, H. Self-taught Learning Transfer Learning from Unlabeled Data. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 759–766. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why Does Unsupervised Pre-training Help Deep Learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines; Pearson: Upper Saddle River, NJ, USA, 2009; pp. 32–41. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network; University of Montreal: Montreal, QC, Canada, 2009. [Google Scholar]
- Das, A.; Kumar, A.; Bahl, R. Marine vessel classification based on passive sonar data: the cepstrum-based approach. IET Radar Sonar Navig. 2013, 7, 87–93. [Google Scholar] [CrossRef]
- Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. Vigil. Christ. 2008, 9, 2579–2605. [Google Scholar]
- Yang, H.; Shen, S. The Feature Selection of Pattern Recognition; Publishing House of Electronics Industry: Beijing, China, 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Features | Dimension | NMI | Accuracy/% | Variance/×10−3 |
|---|---|---|---|---|---|
| Traditional | MFCC [6] | 12 | 0.315 | 78.9 | 5.1 |
| DMFCC [6] | 12 | 0.184 | 73.1 | 5.8 | |
| DDMFCC [6] | 12 | 0.177 | 71.8 | 5.6 | |
| Waveform [1,2] | 8 | 0.307 | 73.9 | 9.2 | |
| Auditory [5] | 24 | 0.190 | 75.2 | 8.3 | |
| Wavelet [3,4] | 14 | 0.269 | 76.3 | 7.4 | |
| CDBN | Layer1 | 50 | 0.392 | 80.6 | 3.9 |
| Layer2 | 50 | 0.554 | 86.7 | 3.7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Shen, S.; Yao, X.; Sheng, M.; Wang, C. Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition. Sensors 2018, 18, 952. https://doi.org/10.3390/s18040952
Yang H, Shen S, Yao X, Sheng M, Wang C. Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition. Sensors. 2018; 18(4):952. https://doi.org/10.3390/s18040952
Chicago/Turabian StyleYang, Honghui, Sheng Shen, Xiaohui Yao, Meiping Sheng, and Chen Wang. 2018. "Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition" Sensors 18, no. 4: 952. https://doi.org/10.3390/s18040952
APA StyleYang, H., Shen, S., Yao, X., Sheng, M., & Wang, C. (2018). Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition. Sensors, 18(4), 952. https://doi.org/10.3390/s18040952