TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications

 ,
,  , , and
, , and
Abstract
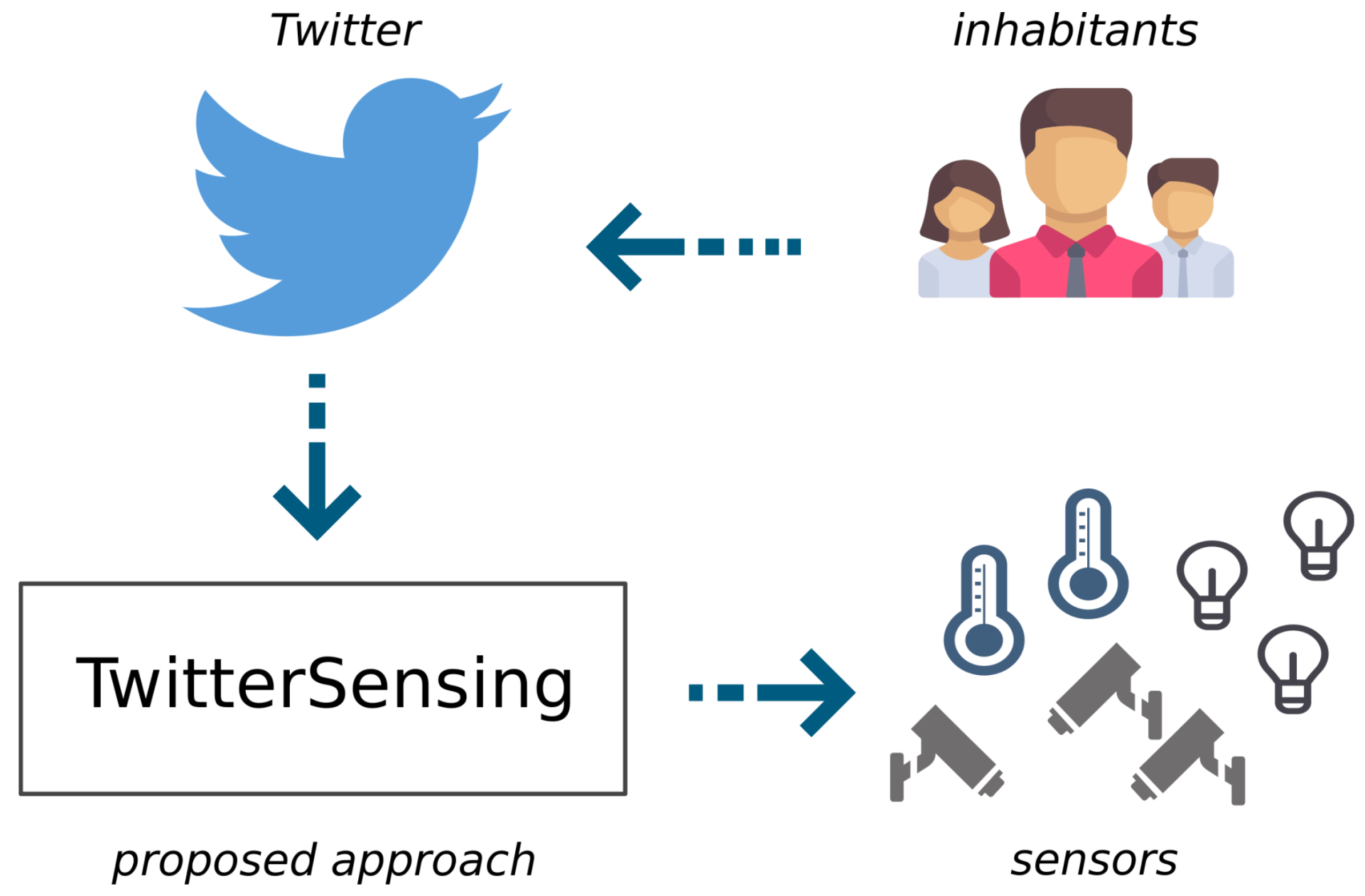
1. Introduction
2. Related Works
3. Fundamental Concepts
3.1. Sensing Prioritization
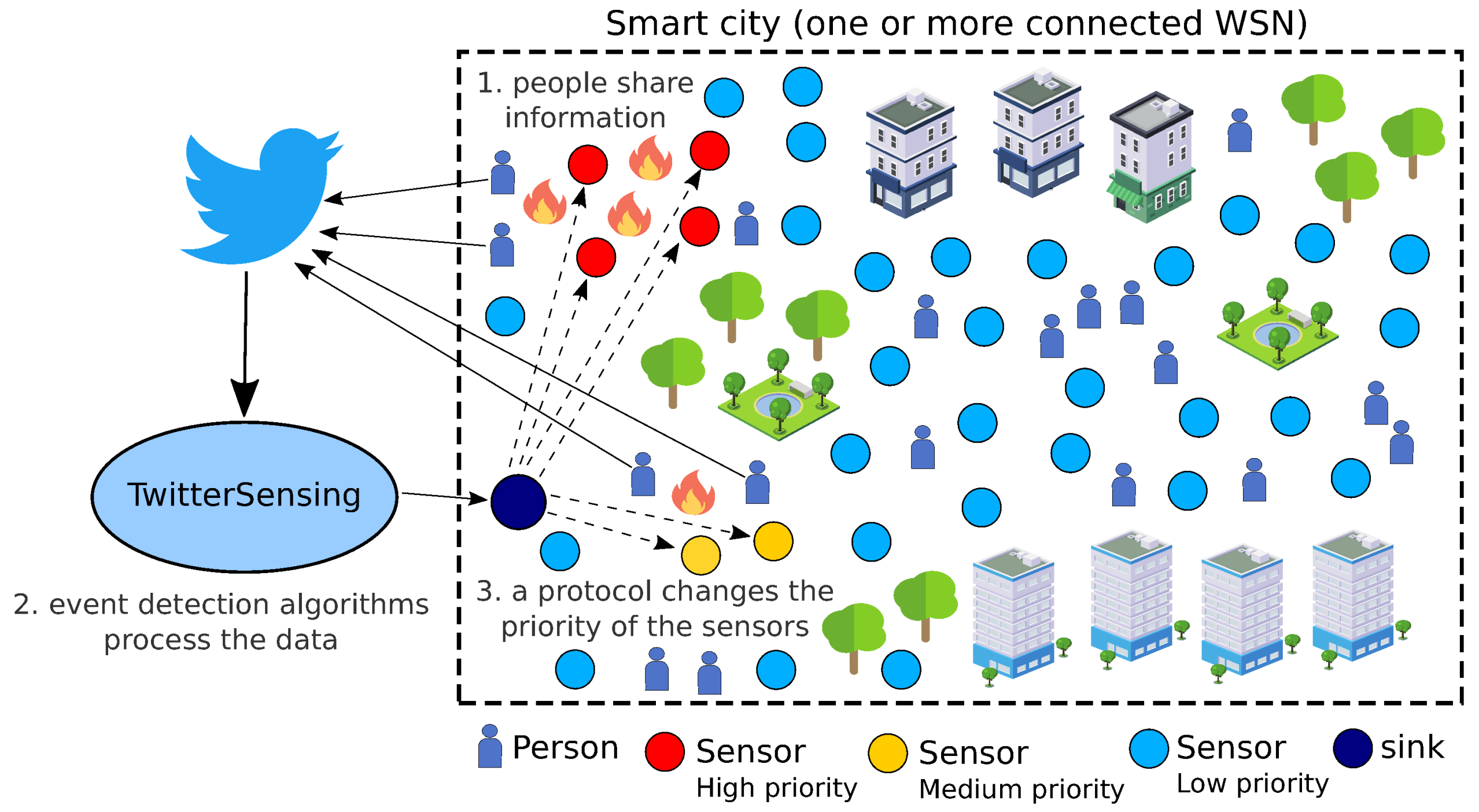
3.2. Smart City Scenario
3.3. Data Mining from Twitter
- Feature Extraction: The raw data extracted from Twitter contains features which may not be important to a given mining application (e.g., user profile image url). This cycle consists in choosing which features objects are relevant and will compose the vector of features [54]. For example, in most spatial Twitter applications [55,56,57,58], . The other features are stored and, if necessary, they can be retrieved in any step by using as identifier.
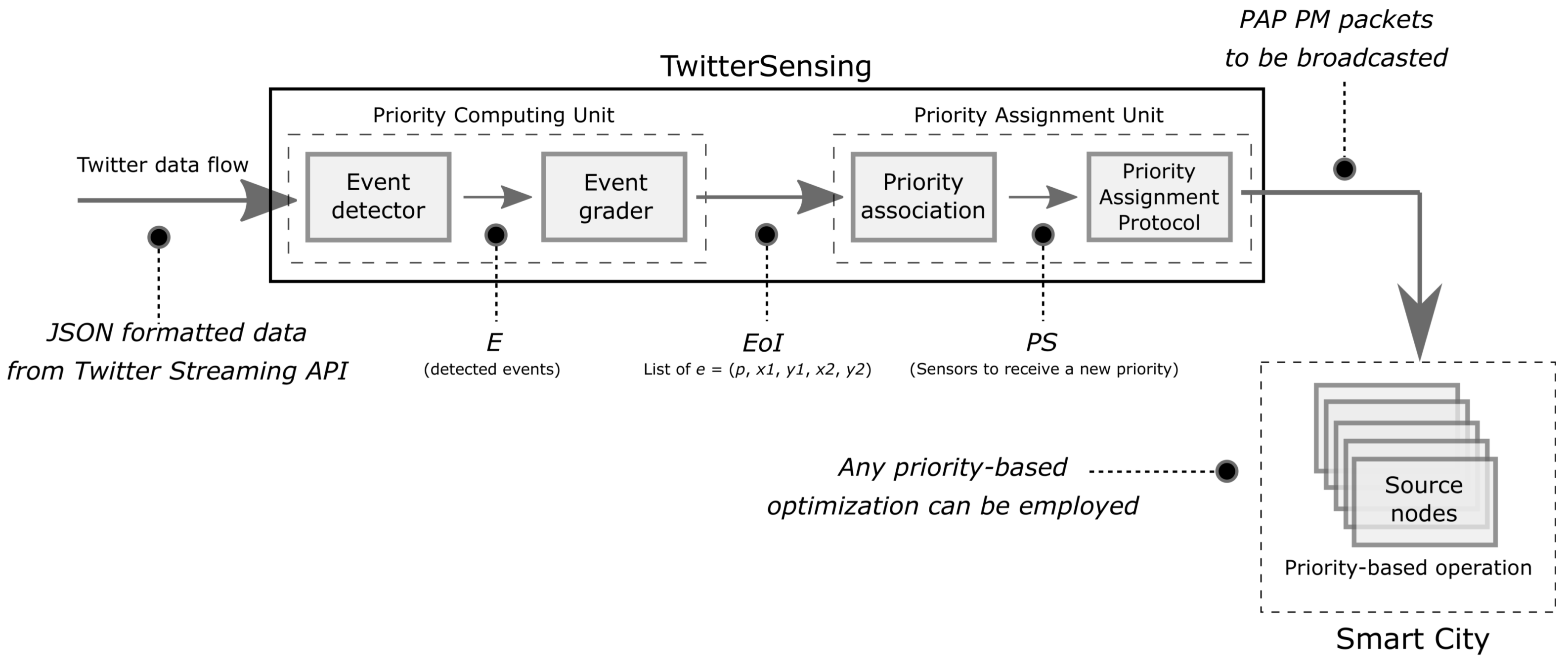
4. Proposed Approach
4.1. Events and Sensing Priorities
4.2. Priority Computing Unit
- Event Detector: This module receives a real-time data flow from Twitter and extracts information from events that are currently happening. This article focuses on Twitter, due to its aforementioned real-time nature and high volume of data, but other social media could be considered in future works.Input: JSON formatted data from Twitter Streaming API.Output: List of detected events (E).
- Event Grader: After detection, the extracted events data go to this module for classification, where the information is analyzed and, based on a set of predefined parameters (e.g., events related to natural disasters may be more important than party-related events, depending on the applications monitoring requirements), it receives a priority level within a predefined range.Input: List of detected events (E).Output: List of events associated to priorities ().
4.2.1. Event Detector Module
4.2.2. Event Grader Module
| Algorithm 1:Priority Computing Algorithm (PCA) |
 |
4.3. Priority Assignment Unit
- Priority Association: This module processes a list of detected and classified events of interest and associates the priority of those events to a subset of sensors.Input: List of events associated to priorities ().Output: List of sensors to be assigned to priorities ().
- Priority Assignment Protocol: This protocol is proposed to define how priorities will be transmitted to sensors. Initially, this protocol specifies a single message type to be broadcasted over one or more WSN.Input: List of sensors to be assigned to priorities ().Output: PAP PM messages.
4.3.1. Priority Association Module
| Algorithm 2:Priority Association Algorithm (PAA) |
 |
4.3.2. Priority Assignment Protocol
5. Results
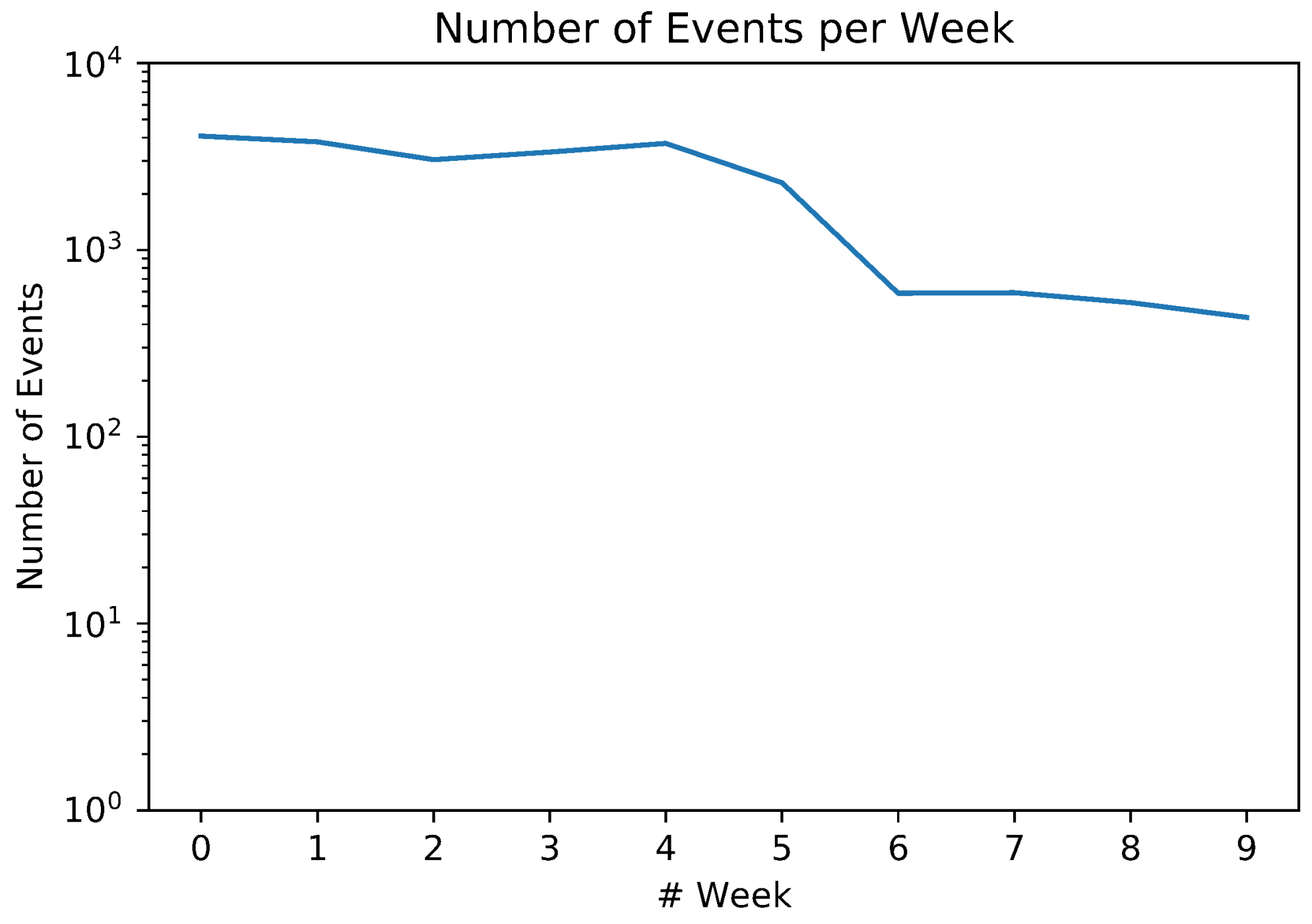
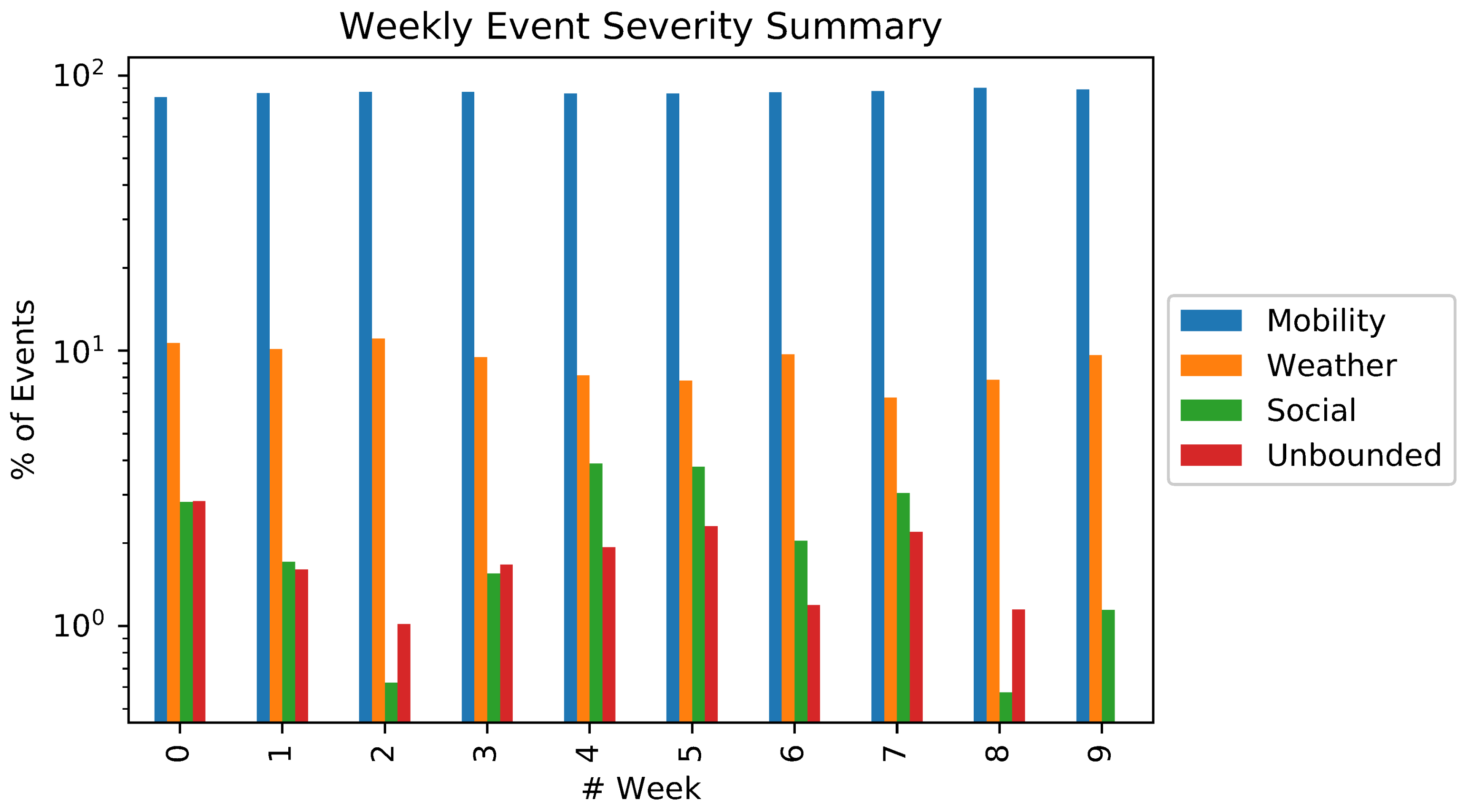
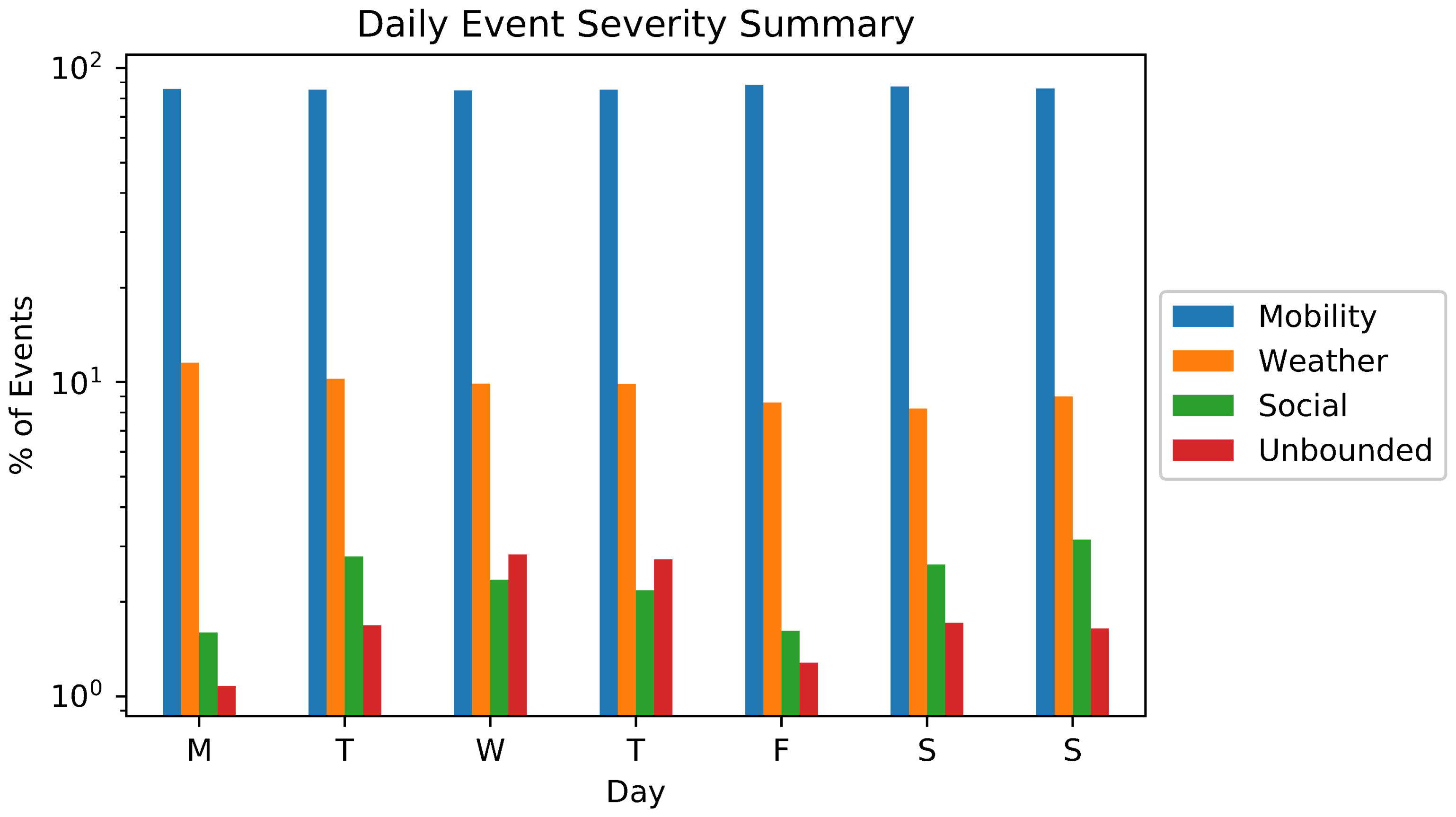
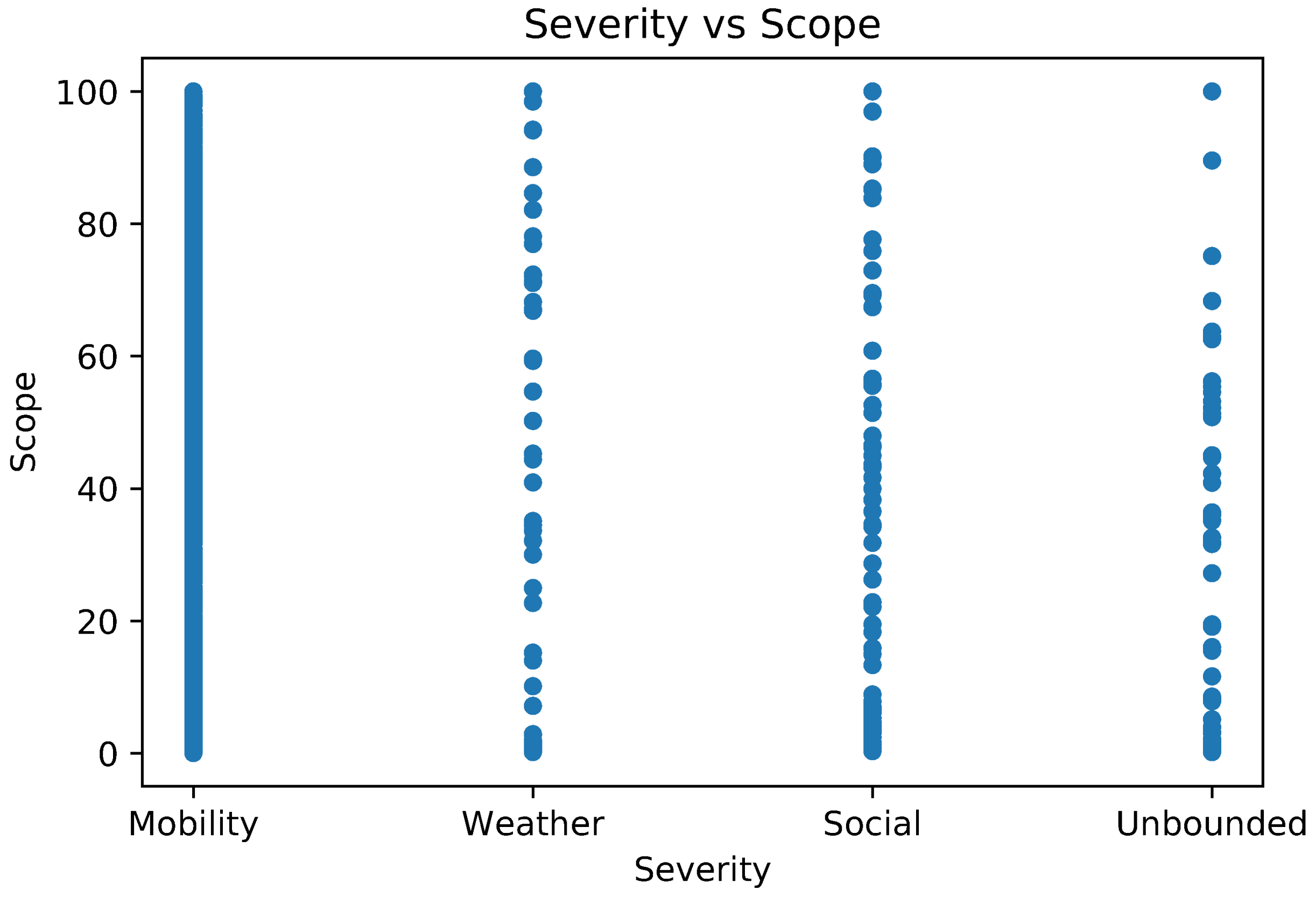
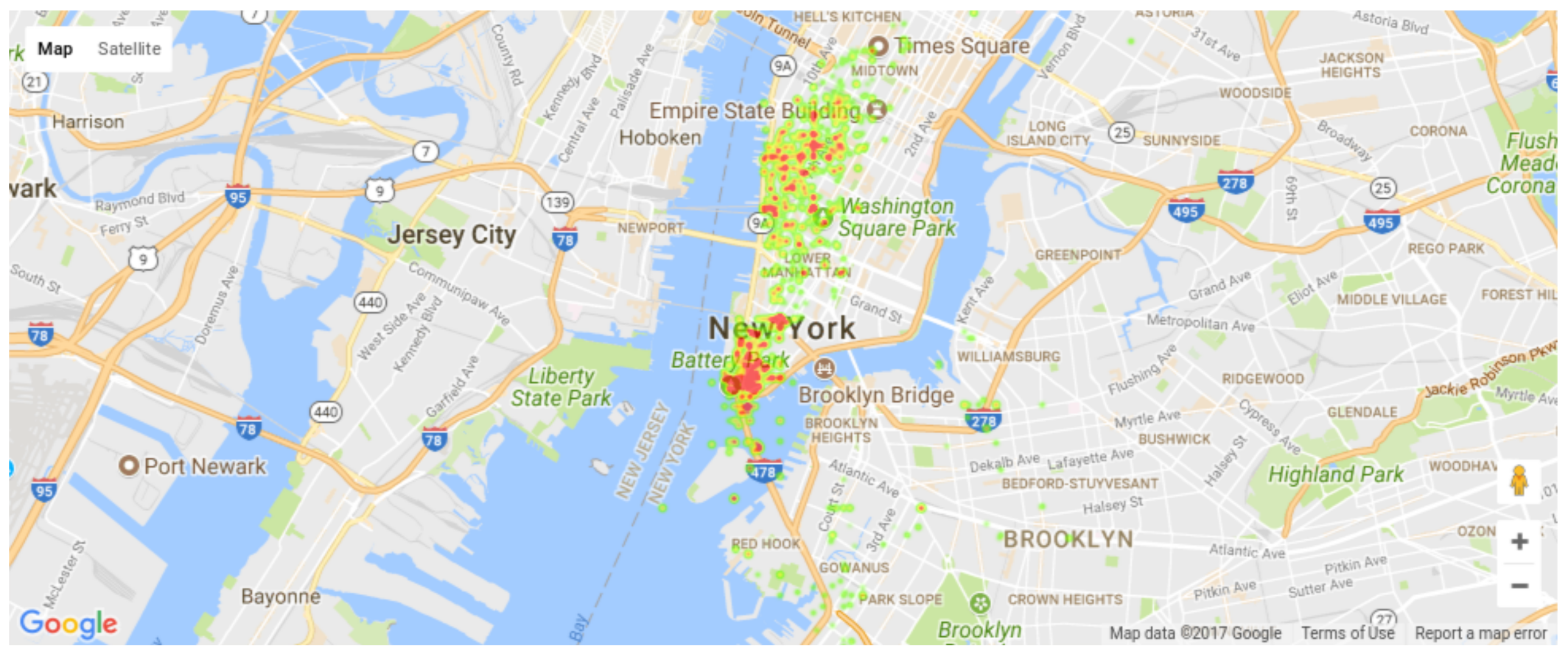
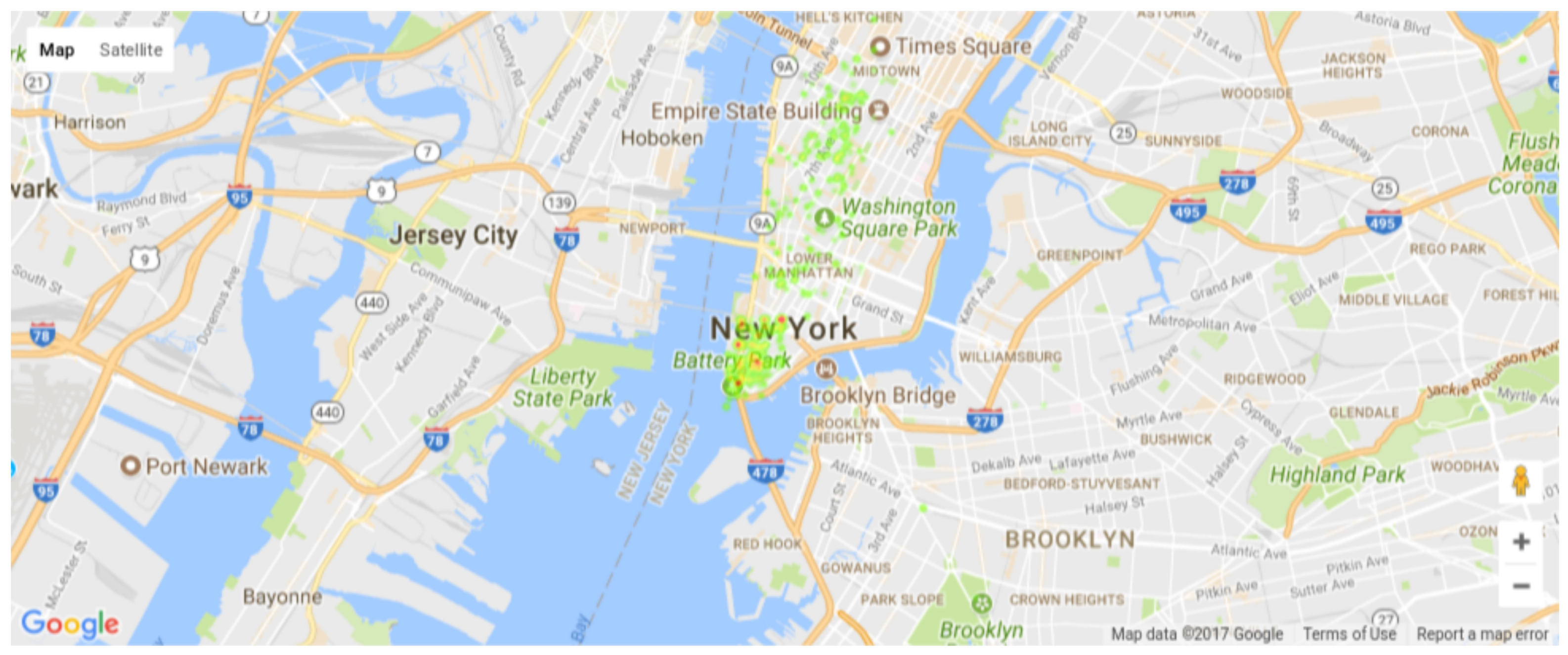
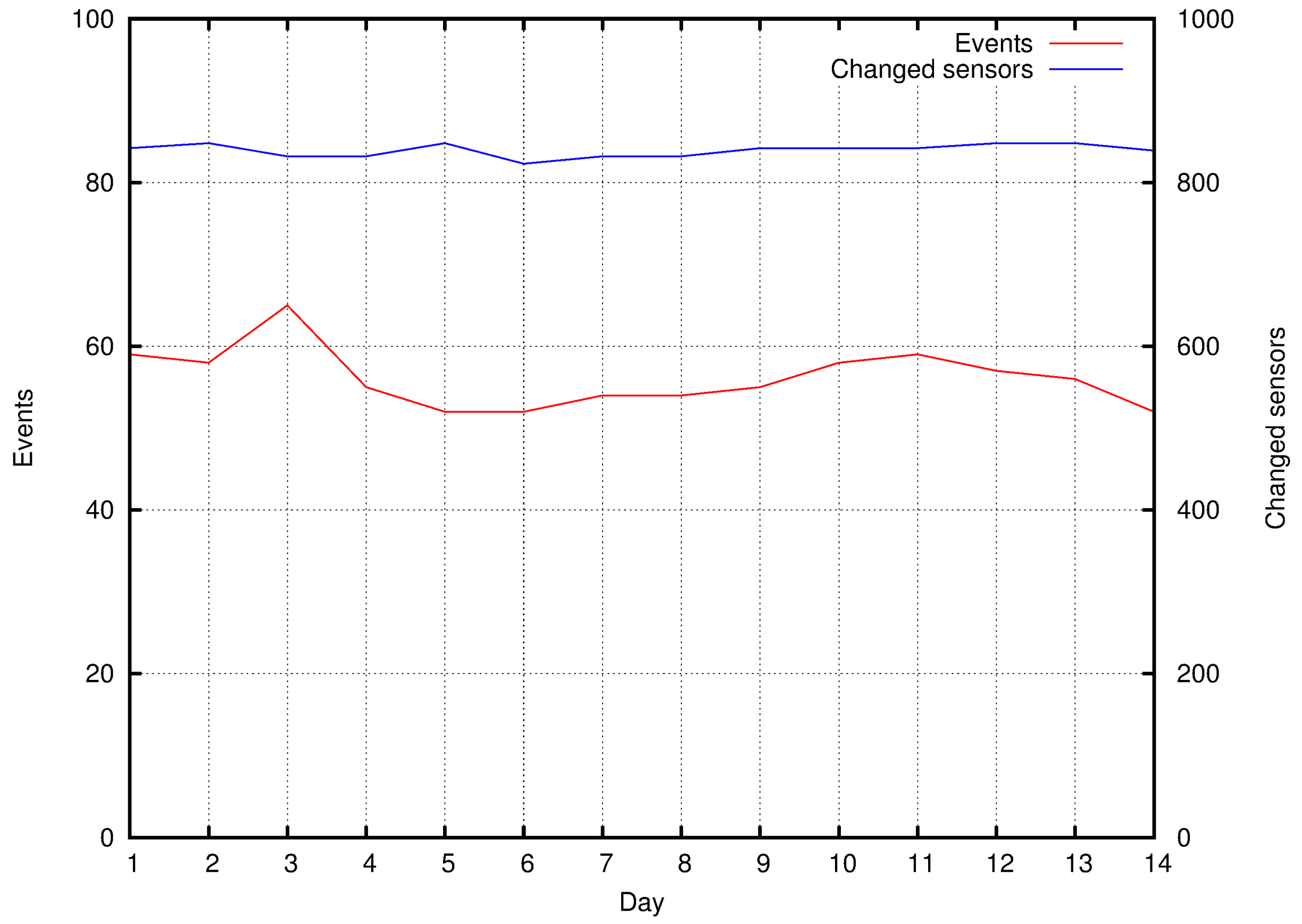
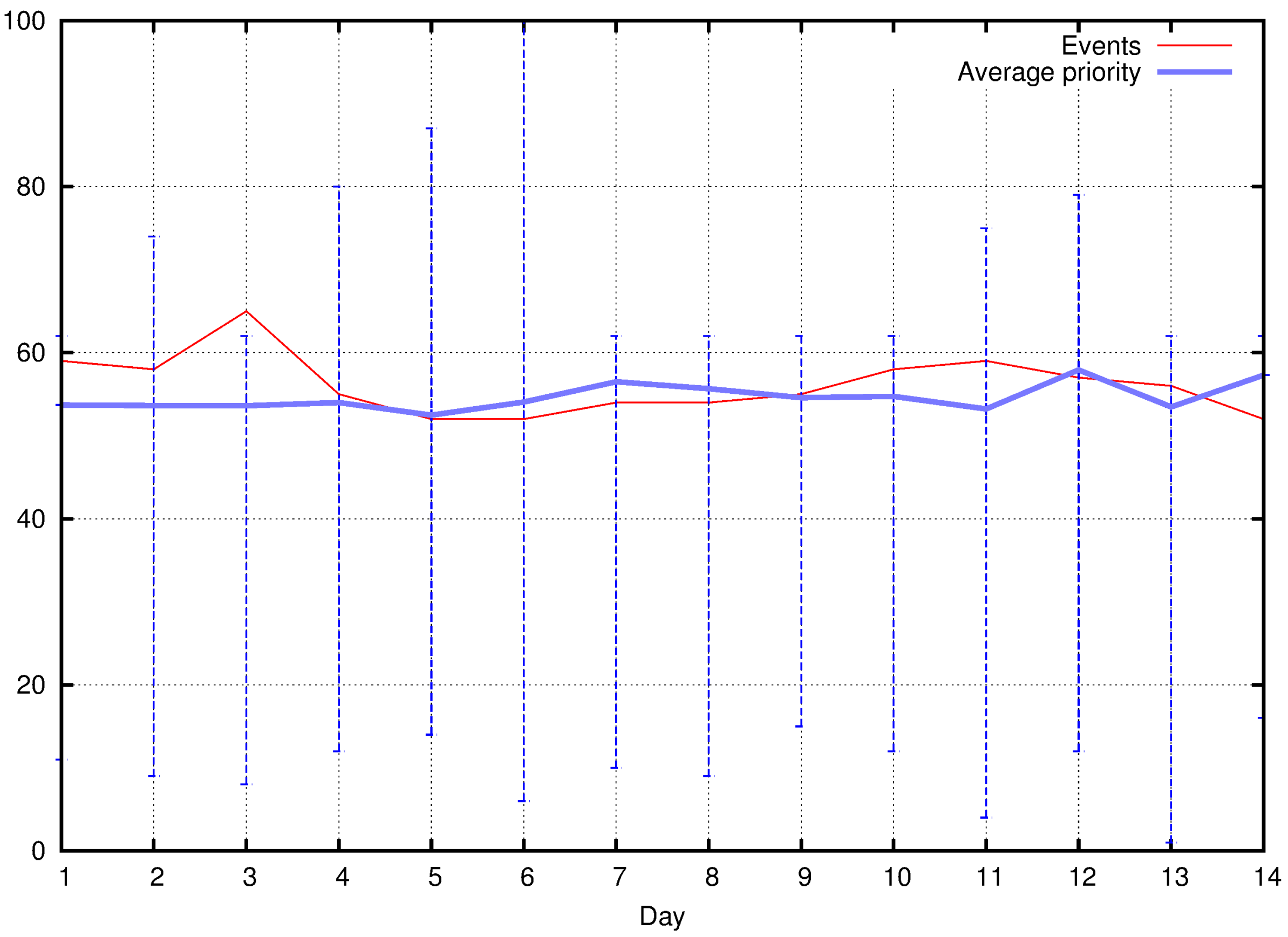
5.1. Event Detection and Classification
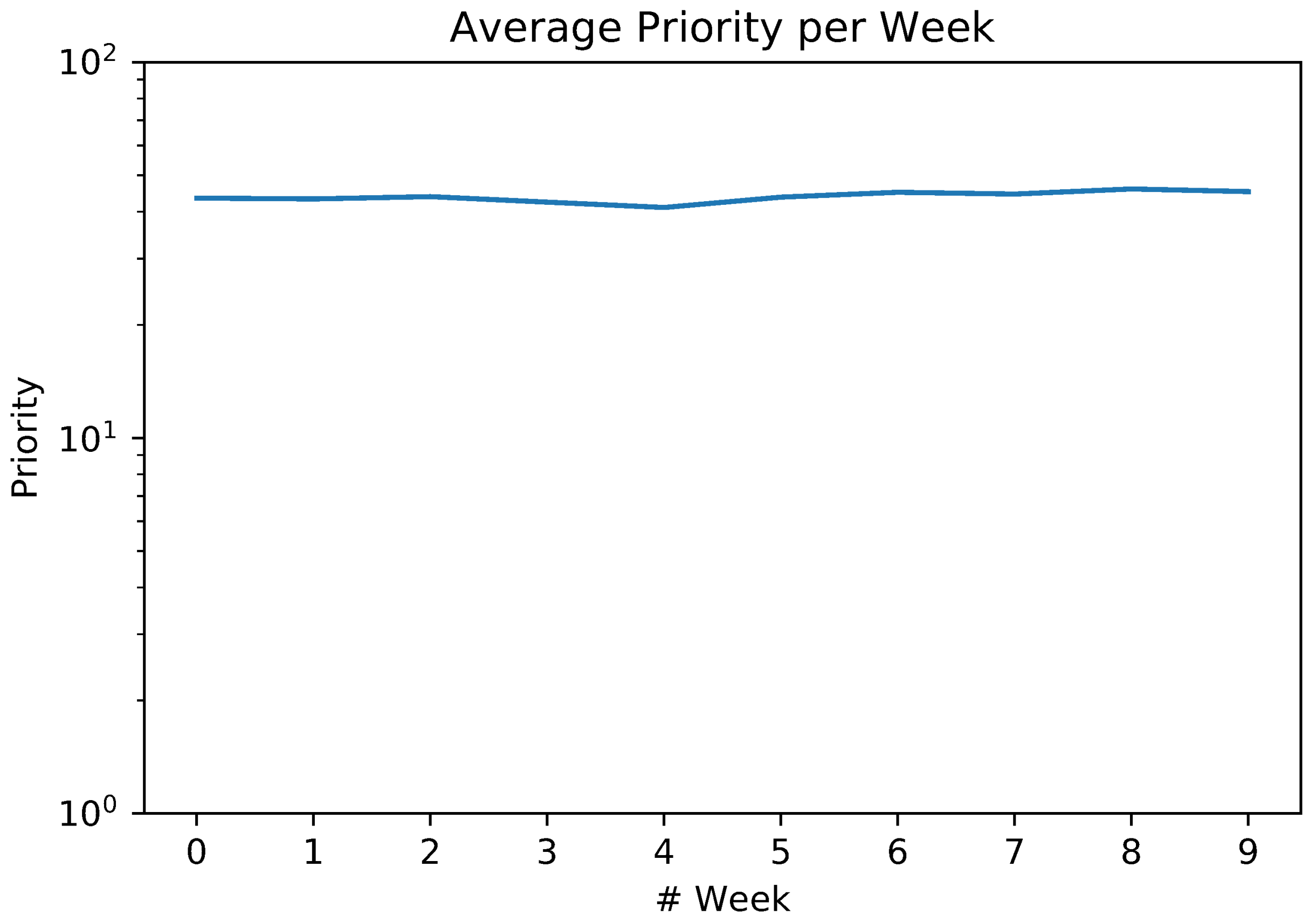
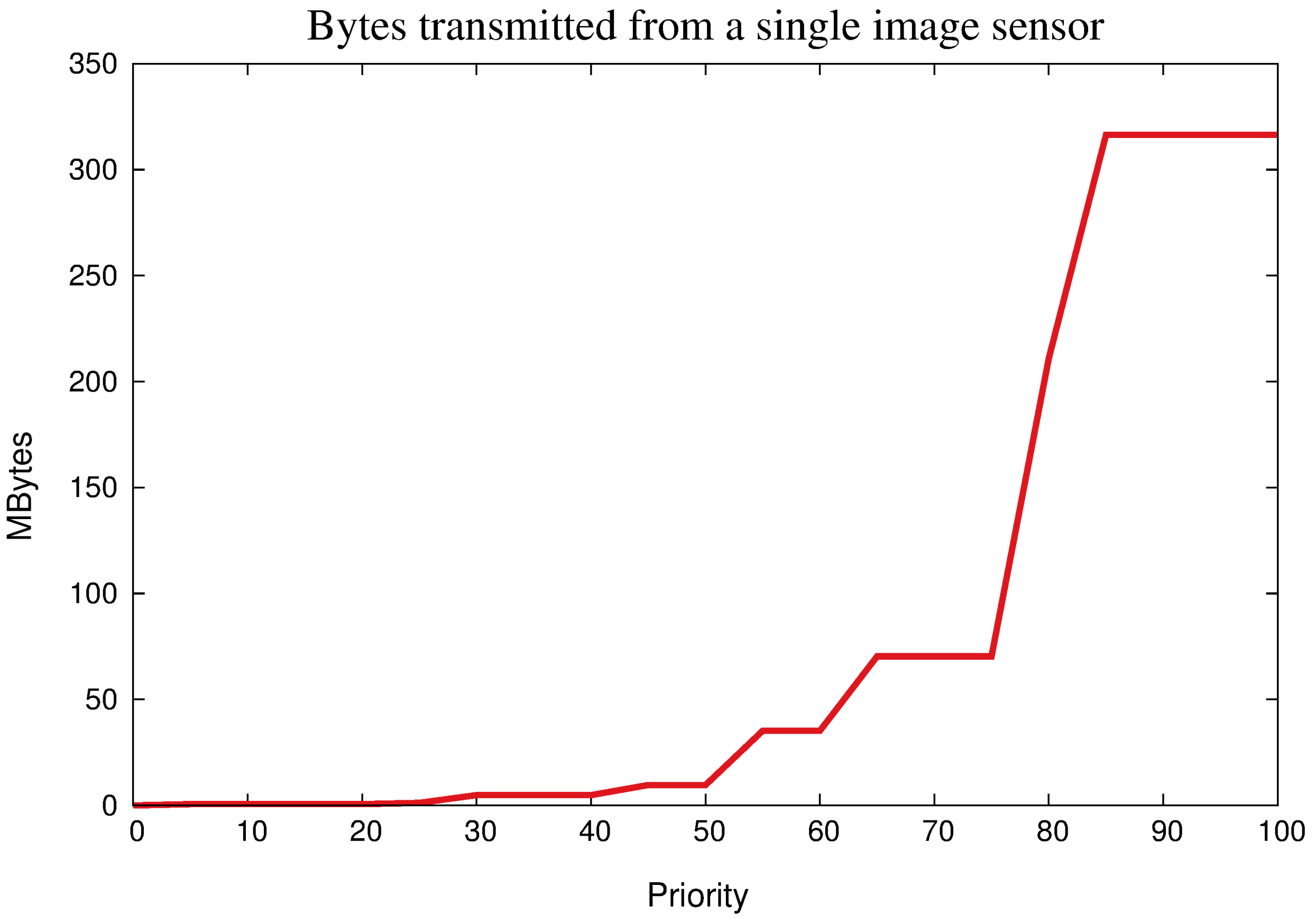
5.2. Exploiting Priority for Optimizations
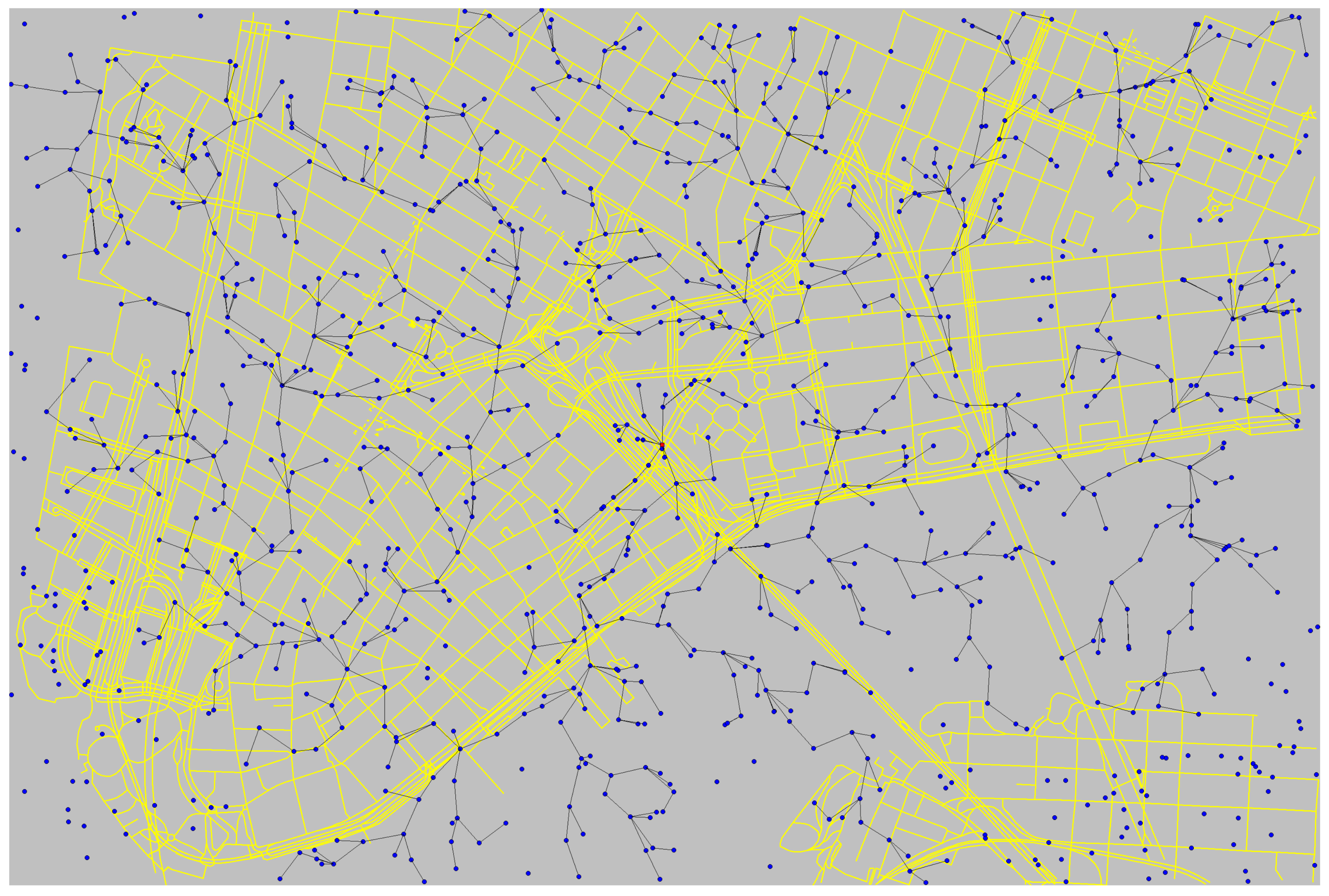
5.3. Employing TwitterSensing in a WSN
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Su, K.; Li, J.; Fu, H. Smart city and the applications. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 1028–1031. [Google Scholar]
- Batty, M.; Axhausen, K.; Giannotti, F.; Pozdnoukhov, A.; Bazzani, A.; Wachowicz, M.; Ouzounis, G.; Portugali, Y. Smart cities of the future. Eur. Phys. J. Spec. Top. 2012, 214, 481–518. [Google Scholar] [CrossRef]
- Costa, D.G.; Collotta, M.; Pau, G.; Duran-Faundez, C. A Fuzzy-Based Approach for Sensing, Coding and Transmission Configuration of Visual Sensors in Smart City Applications. Sensors 2017, 17. [Google Scholar] [CrossRef] [PubMed]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Sensing as a service model for Smart Cities supported by internet of things. Trans. Emerg. Telecommun. Technol. 2014, 25, 81–93. [Google Scholar] [CrossRef]
- Caragliu, A.; Bo, C.D.; Nijkamp, P. Smart cities in Europe. J. Urban Technol. 2011, 18, 65–82. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef]
- Mahmood, M.A.; Seah, W.K.; Welch, I. Reliability in wireless sensor networks: A survey and challenges ahead. Comput. Netw. 2015, 79, 166–187. [Google Scholar] [CrossRef]
- Costa, D.G.; Guedes, L.A.; Vasques, F.; Portugal, P. Relevance-based partial reliability in wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2014, 2014, 142. [Google Scholar] [CrossRef][Green Version]
- Costa, D.G.; Guedes, L.A. Exploiting the sensing relevancies of source nodes for optimizations in visual sensor networks. Multimed. Tools Appl. 2013, 64, 549–579. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An introduction to social network data analytics. In Social Network Data Analytics; Springer Science & Business Media: Berlin, Germany, 2011; pp. 1–15. [Google Scholar]
- Dafallah, H.A.A. Design and implementation of an accurate real time GPS tracking system. In Proceedings of the The Third International Conference on e-Technologies and Networks for Development (ICeND2014), Beirut, Lebanon, 29 April–1 May 2014; pp. 183–188. [Google Scholar]
- Chen, L.; Cong, G.; Cao, X.; Tan, K. Temporal Spatial-Keyword Top-k publish/subscribe. In Proceedings of the IEEE International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 255–266. [Google Scholar]
- Ferentinos, K.P.; Tsiligiridis, T.A. Adaptive design optimization of wireless sensor networks using genetic algorithms. Comput. Netw. 2007, 51, 1031–1051. [Google Scholar] [CrossRef]
- Costa, D.G.; Guedes, L.A.; Vasques, F.; Portugal, P. Adaptive monitoring relevance in camera networks for critical surveillance applications. Int. J. Distrib. Sens. Netw. 2013, 2013, 836721. [Google Scholar] [CrossRef]
- Hernández-Muñoz, J.M.; Vercher, J.B.; Muñoz, L.; Galache, J.A.; Presser, M.; Gómez, L.A.; Pettersson, J. Smart cities at the forefront of the future internet. In Proceedings of the the Future Internet Assembly, Budapest, Hungary, 17–19 May 2011; pp. 447–462. [Google Scholar]
- Schaffers, H.; Komninos, N.; Pallot, M.; Trousse, B.; Nilsson, M.; Oliveira, A. Smart cities and the future internet: Towards cooperation frameworks for open innovation. In Proceedings of the Future Internet Assembly, Budapest, Hungary, 17–19 May 2011; pp. 431–446. [Google Scholar]
- Peixoto, J.P.J.; Costa, D.G. Wireless visual sensor networks for Smart City applications: A relevance-based approach for multiple sinks mobility. Future Gener. Comput. Syst. 2017, 76, 51–62. [Google Scholar] [CrossRef]
- Wang, C.; Sohraby, K.; Lawrence, V.; Li, B.; Hu, Y. Priority-based congestion control in wireless sensor networks. In Proceedings of the IEEE International Conference on Sensor Networks, Ubiquitous, and Trustworthy Computing (SUTC’06), Taichung, Taiwan, 5–7 June 2006; p. 8. [Google Scholar]
- Butler, Z.; Rus, D. Event-based motion control for mobile-sensor networks. IEEE Pervasive Comput. 2003, 2, 34–42. [Google Scholar] [CrossRef]
- Costa, D.G.; Guedes, L.A. The coverage problem in video-based wireless sensor networks: A survey. Sensors 2010, 10, 8215–8247. [Google Scholar] [CrossRef] [PubMed]
- Schulz, J.; Reichenbach, F.; Blumenthal, J.; Timmermann, D. Low Cost System for Detecting Leakages along Artificial Dikes with Wireless Sensor Networks. In Proceedings of the Workshop on Real-World Wireless Sensor Networks, REALWSN, Glasgow, Scotland, 1 April 2008. [Google Scholar]
- Byun, J.; Jeon, B.; Noh, J.; Kim, Y.; Park, S. An intelligent self-adjusting sensor for smart home services based on ZigBee communications. IEEE Trans. Consum. Electron. 2012, 58, 794–802. [Google Scholar] [CrossRef]
- Arora, A.; Dutta, P.; Bapat, S.; Kulathumani, V.; Zhang, H.; Naik, V.; Mittal, V.; Cao, H.; Demirbas, M.; Gouda, M.; et al. A Line in the Sand: A Wireless Sensor Network for Targer Detection, Classification, and Tracking. IEEE Comput. Netw. 2005, 46, 605–634. [Google Scholar] [CrossRef]
- Kapitanova, K.; Son, S.H.; Kang, K.D. Using fuzzy logic for robust event detection in wireless sensor networks. Ad Hoc Netw. 2012, 10, 709–722. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Melodia, T.; Chowdhury, K.R. A survey on wireless multimedia sensor networks. Comput. Netw. 2007, 51, 921–960. [Google Scholar] [CrossRef]
- Teixeira, T.; Andreou, A.G.; Culurciello, E. Event-Based Imaging with Active Illumination in Sensor Networks. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS 2005), Kobe, Japan, 23–26 May 2005; Volume 1, pp. 644–647. [Google Scholar]
- Teixeira, T.; Culurciello, E.; Park, J.H.; Lymberopoulos, D.; Barton-Sweeney, A.; Savvides, A. Address-Event Imagers for Sensor Networks: Evaluation and Modeling. In Proceedings of the Fifth International Conference on Information Processing in Sensor Networks (IPSN), Nashville, TN, USA, 19–21 April 2006. [Google Scholar]
- Czarlinska, A.; Kundur, D. Reliable Event-Detection in Wireless Visual Sensor Networks Through Scalar Collaboration and Game-Theoretic Consideration. IEEE Trans. Multimed. 2008, 10, 675–690. [Google Scholar] [CrossRef]
- Pham, C. Fast Event Detection in Mission-Critical Surveillance with Wireless Video Sensor Networks. In Proceedings of the 2010 IEEE RIVF International Conference on Computing and Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), Hanoi, Vietnam, 1–4 November 2010; pp. 1–4. [Google Scholar]
- Varshney, P.K.; Masazade, E.; Ray, P.; Niu, R. Distributed Data Fusion for Network-Centric Operations. Chapter: Distributed Detection in Wireless Sensor Networks; CRC Press: Boca Raton, FL, USA, 2013; pp. 65–94. [Google Scholar]
- Wei, C.Y.; Chen, P.N.; Han, Y.S.; Varshney, P.K. Local Threshold Design for Target Localization Using Error Correcting Codes in Wireless Sensor Networks in the Presence of Byzantine Attacks. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1571–1584. [Google Scholar] [CrossRef]
- Wimalajeewa, T.; Varshney, P.K. Robust Detection of Random Events with Spatially Correlated Data in Wireless Sensor Networks via Distributed Compressive Sensing. arXiv, 2017; arXiv:1707.08208. [Google Scholar]
- Ciuonzo, D.; Salvo Rossi, P. Distributed Detection of a Non-cooperative Target via Generalized Locally-optimum Approaches. Inf. Fusion 2017, 36, 261–274. [Google Scholar] [CrossRef]
- Boutsis, I.; Kalogeraki, V.; Guno, D. Reliable crowdsourced event detection in smartcities. In Proceedings of the 2016 1st International Workshop on Science of Smart City Operations and Platforms Engineering (SCOPE) in partnership with Global City Teams Challenge (GCTC) (SCOPE-GCTC), Vienna, Austria, 11 April 2016; pp. 1–6. [Google Scholar]
- Domingos, P. Mining social networks for viral marketing. IEEE Intell. Syst. 2005, 20, 80–82. [Google Scholar]
- Weng, J.; Lee, B.S. Event Detection in Twitter. ICWSM 2011, 11, 401–408. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Paul, M.J.; Dredze, M. You are what you Tweet: Analyzing Twitter for public health. ICWSM 2011, 20, 265–272. [Google Scholar]
- Lee, R.; Sumiya, K. Measuring geographical regularities of crowd behaviors for Twitter-based geo-social event detection. In Proceedings of the 2nd ACM SIGSPATIAL International Workshop on Location Based Social Networks, San Jose, CA, USA, 2 November 2010; pp. 1–10. [Google Scholar]
- Bonchi, F.; Castillo, C.; Gionis, A.; Jaimes, A. Social network analysis and mining for business applications. ACM Trans. Intell. Syst. Technol. 2011, 2, 22. [Google Scholar] [CrossRef]
- Domingos, P.; Richardson, M. Mining the network value of customers. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 57–66. [Google Scholar]
- Costa, D.G.; Guedes, L.A.; Vasques, F.; Portugal, P. Research trends in wireless visual sensor networks when exploiting prioritization. Sensors 2015, 15, 1760–1784. [Google Scholar] [CrossRef] [PubMed]
- Sahoo, P.K.; Hwang, I.S. Collaborative Localization Algorithms for Wireless Sensor Networks with Reduced Localization Error. Sensors 2011, 11, 9989–10009. [Google Scholar] [CrossRef] [PubMed]
- Pescaru, D.; Curiac, D.I. Anchor Node Localization for Wireless Sensor Networks Using Video and Compass Information Fusion. Sensors 2014, 14, 4211–4224. [Google Scholar] [CrossRef] [PubMed]
- Buettner, R. Predicting user behavior in electronic markets based on personality-mining in large online social networks: A personality-based product recommender framework. Electron. Mark. 2017, 27, 247–265. [Google Scholar] [CrossRef]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 591–600. [Google Scholar]
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in Twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Tsytsarau, M.; Palpanas, T. Survey on mining subjective data on the web. Data Min. Knowl. Discov. 2012, 24, 478–514. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Balazs, J.A.; Velásquez, J.D. Opinion mining and information fusion: A survey. Inf. Fusion 2016, 27, 95–110. [Google Scholar] [CrossRef]
- Metzler, D.; Dumais, S.; Meek, C. Similarity measures for short segments of text. In Proceedings of the European Conference on Information Retrieval, Rome, Italy, 2–5 April 2007; pp. 16–27. [Google Scholar]
- Lin, B.; Chen, Y.; Chen, X.; Yu, Y. Comparison between JSON and XML in Applications Based on AJAX. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 11–13 August 2012; pp. 1174–1177. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Berlin, Germany, 2015. [Google Scholar]
- Li, R.; Lei, K.H.; Khadiwala, R.; Chang, K.C.C. Tedas: A twitter-based event detection and analysis system. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012; pp. 1273–1276. [Google Scholar]
- Zhang, C.; Zhou, G.; Yuan, Q.; Zhuang, H.; Zheng, Y.; Kaplan, L.; Wang, S.; Han, J. GeoBurst: Real-Time Local Event Detection in Geo-Tagged Tweet Streams. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 513–522. [Google Scholar]
- Andrade, D.C.; Rocha-Junior, J.B.; Costa, D.G. Efficient Processing of Spatio-Temporal-Textual Queries. In Proceedings of the 23rd Brazillian Symposium on Multimedia and the Web, Gramado, Brazil, 17–20 October 2017; pp. 165–172. [Google Scholar]
- Andrade, D.C.; Costa, D.G.; Rocha-Junior, J.B. Adaptive Sensing Relevance Exploiting Social Media Mining in Smart Cities. In Proceedings of the 23rd Brazillian Symposium on Multimedia and the Web, Gramado, Brazil, 17–20 October 2017; pp. 405–408. [Google Scholar]
- Abdelhaq, H.; Sengstock, C.; Gertz, M. Eventweet: Online localized event detection from Twitter. Proc. VLDB Endow. 2013, 6, 1326–1329. [Google Scholar] [CrossRef]
- Watanabe, K.; Ochi, M.; Okabe, M.; Onai, R. Jasmine: A real-time local-event detection system based on geolocation information propagated to microblogs. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 2541–2544. [Google Scholar]
- Forman, G.; Kirshenbaum, E. Extremely fast text feature extraction for classification and indexing. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 1221–1230. [Google Scholar]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Irfan, R.; King, C.K.; Grages, D.; Ewen, S.; Khan, S.U.; Madani, S.A.; Kolodziej, J.; Wang, L.; Chen, D.; Rayes, A.; et al. A survey on text mining in social networks. Knowl. Eng. Rev. 2015, 30, 157–170. [Google Scholar] [CrossRef]
- Ritter, A.; Etzioni, O.; Clark, S. Open domain event extraction from Twitter. In Proceedings of the 18th ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1104–1112. [Google Scholar]
- Madani, A.; Boussaid, O.; Zegour, D.E. Whats happening: A survey of tweets event detection. In Proceedings of the 3rd International Conference on Communications, Computation, Networks and Technologies, INNOV, Nice, France, 12–16 October; 2014; pp. 16–22. [Google Scholar]
- Zhao, S.; Zhong, L.; Wickramasuriya, J.; Vasudevan, V. Human as real-time sensors of social and physical events: A case study of Twitter and sports games. arXiv, 2011; arXiv:1106.4300. [Google Scholar]
- Li, C.; Sun, A.; Datta, A. Twevent: Segment-based event detection from tweets. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 155–164. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. TwitterNews: Real time event detection from the Twitter data stream. PeerJ PrePr. 2016, 4, 224–239. [Google Scholar]
- Bostrom, N. Existential risk prevention as global priority. Glob. Policy 2013, 4, 15–31. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python; O’Reilly Media: Sebastopol, CA, USA, 2009. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; pp. 133–142. [Google Scholar]
- Sankaranarayanan, J.; Samet, H.; Teitler, B.E.; Lieberman, M.D.; Sperling, J. Twitterstand: News in tweets. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 42–51. [Google Scholar]
- Bapat, S.; Arora, A. Stabilizing reconfiguration in wireless sensor networks. In Proceedings of the IEEE International Conference on Sensor Networks, Ubiquitous, and Trustworthy Computing (SUTC’06), Taichung, Taiwan, 5–7 June 2006; p. 8. [Google Scholar]
- Yong, T.; Yu, X.; Jun, Z.; Wenyong, W. A survey on broadcast in wireless sensor networks. In Proceedings of the The 2nd International Conference on Information Science and Engineering, Hangzhou, China, 4–6 Decemebr 2010; pp. 4324–4331. [Google Scholar]
- Filter Realtime Tweets-Overview-Twitter Developers. Available online: https://developer.twitter.com/en/docs/tweets/filter-realtime/overview (accessed on 7 February 2017).
- National Women’s History Project. Available online: http://www.nwhp.org (accessed on 3 November 2017).
- Google Maps APIs. Available online: https://developers.google.com/maps/ (accessed on 26 December 2012).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Proposal | Structural Content |
|---|---|---|
| EvenTweet [59] | Local event detection | Location; Start time; Keywords |
| GeoBurst [56] | Local event detection | Representative tweet; Related tweets |
| Jasmine [60] | Local event detection | Location, Start time, Keywords |
| TEDAS [55] | Global event detection | Event score; Location; Start time; Related tweets |
| Twevent [67] | Global event detection | Keywords |
| TwitterNews [68] | Global Event detection | Representative tweet |
| Contextual Severity () | Event Type | Example |
|---|---|---|
| 100 | Unbounded | City Christmas party, big show |
| 75 | Social | Movie premiere, company party |
| 50 | Weather | Rainfall, snow |
| 25 | Mobility | Visit to Central Park |
| 0 | Imperceptible | Global events |
| Priority | Transmission Pattern |
|---|---|
| Image resolution | |
| no image | |
| 0 25 | 176 × 120 (QCIF) |
| 25 50 | 352 × 240 (CIF) |
| 50 75 | 640 × 480 (VGA) |
| 75 100 | 1280 × 720 (HD) |
| Image frequency | |
| no image | |
| 0 20 | 0.25 image/s |
| 20 40 | 0.5 image/s |
| 40 60 | 1 image/s |
| 60 80 | 2 images/s |
| 80 100 | 3 images/s |
| Video transmission | |
| 0 25 | H.264 VGA 15fps |
| 25 50 | H.264 HD 15fps |
| 50 75 | H.264 VGA 30fps |
| 75 100 | H.264 HD 30fps |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costa, D.G.; Duran-Faundez, C.; Andrade, D.C.; Rocha-Junior, J.B.; Just Peixoto, J.P. TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications. Sensors 2018, 18, 1080. https://doi.org/10.3390/s18041080
Costa DG, Duran-Faundez C, Andrade DC, Rocha-Junior JB, Just Peixoto JP. TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications. Sensors. 2018; 18(4):1080. https://doi.org/10.3390/s18041080
Chicago/Turabian StyleCosta, Daniel G., Cristian Duran-Faundez, Daniel C. Andrade, João B. Rocha-Junior, and João Paulo Just Peixoto. 2018. "TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications" Sensors 18, no. 4: 1080. https://doi.org/10.3390/s18041080
APA StyleCosta, D. G., Duran-Faundez, C., Andrade, D. C., Rocha-Junior, J. B., & Just Peixoto, J. P. (2018). TwitterSensing: An Event-Based Approach for Wireless Sensor Networks Optimization Exploiting Social Media in Smart City Applications. Sensors, 18(4), 1080. https://doi.org/10.3390/s18041080