A Novel Strategy for Very-Large-Scale Cash-Crop Mapping in the Context of Weather-Related Risk Assessment, Combining Global Satellite Multispectral Datasets, Environmental Constraints, and In Situ Acquisition of Geospatial Data


Abstract
:1. Introduction
- excess rainfall, and consequent floods and damage to crops;
- hail, destroying growing plants;
- extreme drought, leading to death of plants.
- avoidance of local datasets; local datasets, such as municipality-level records of crop seeding, or surveying results from local authorities, are obviously not reusable out of their own geographical scope, but especially they may be severely inhomogeneous across different countries or regions. Global datasets were to be used, albeit at the cost of lower precision, accuracy, or resolution.
- leveling of expected quality; highly-refined components of the risk equation are of little use where they have to be forcibly combined with much coarser ones in the same risk computation.
2. General Context: Global Exposure Data for Risk Assessment
- the general model used for overall risk assessment, and
- the accuracy level of the other datasets incorporated in our production.
- it was important to balance the different components of the risk model in order to avoid mixing datasets that score too differently in terms of accuracy and precision; in this case, finer data or finer models would indeed be underused;
- our goal was to hit the optimal trade-off between data availability and the specific needs of the vulnerability component in order to capture the main factors affecting risk.
3. Aims
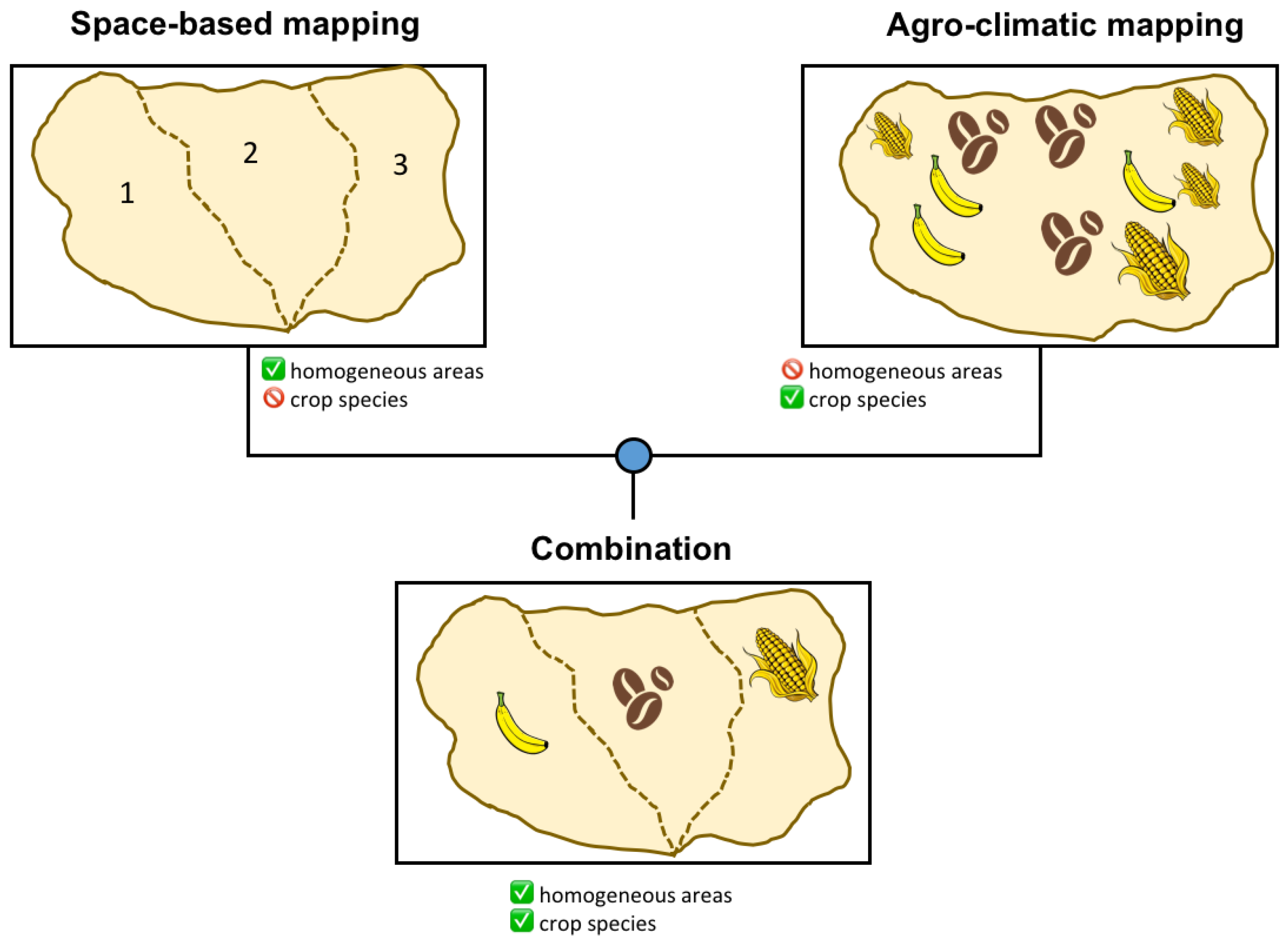
4. Space-Based Crop Mapping
4.1. Scientific Background
4.2. Our Approach
- open availability;
- high temporal frequency (roughly every second day in the equatorial band, daily elsewhere).
- lower temporal frequency; 5-days revisit time may appear very short, but in areas where cloud coverage is frequent such as the predominantly tropical Caribbean areas, the daily revisit time of Terra/Aqua can be crucial in preventing data gaps;
- higher spatial resolution, while unnecessary to the foreseen application, results in gigantic files to be stored and processed. This is only worthwhile when the additional data makes a difference in terms of separability of relevant land cover classes.
5. Agro-Climatic Mapping
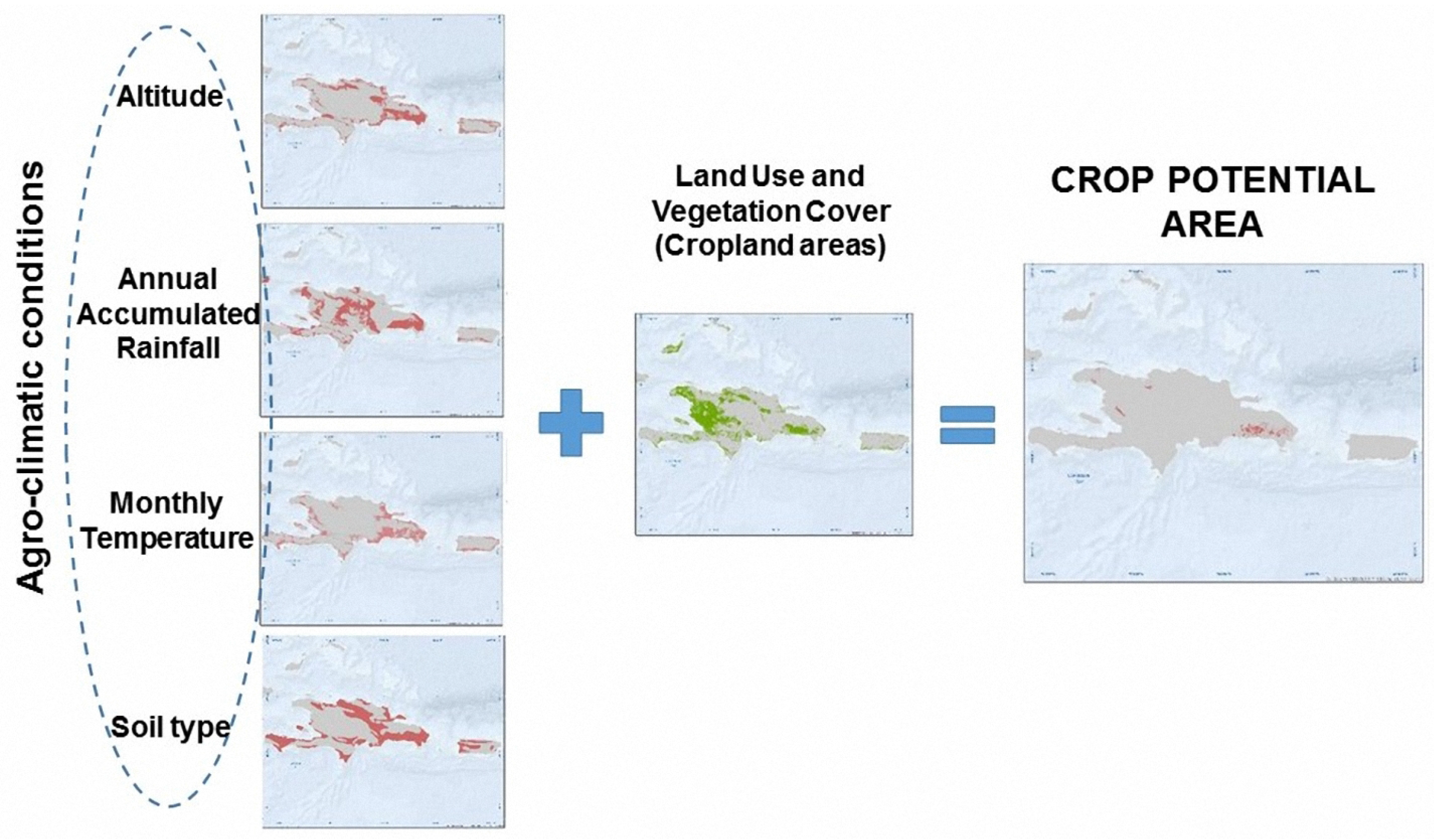
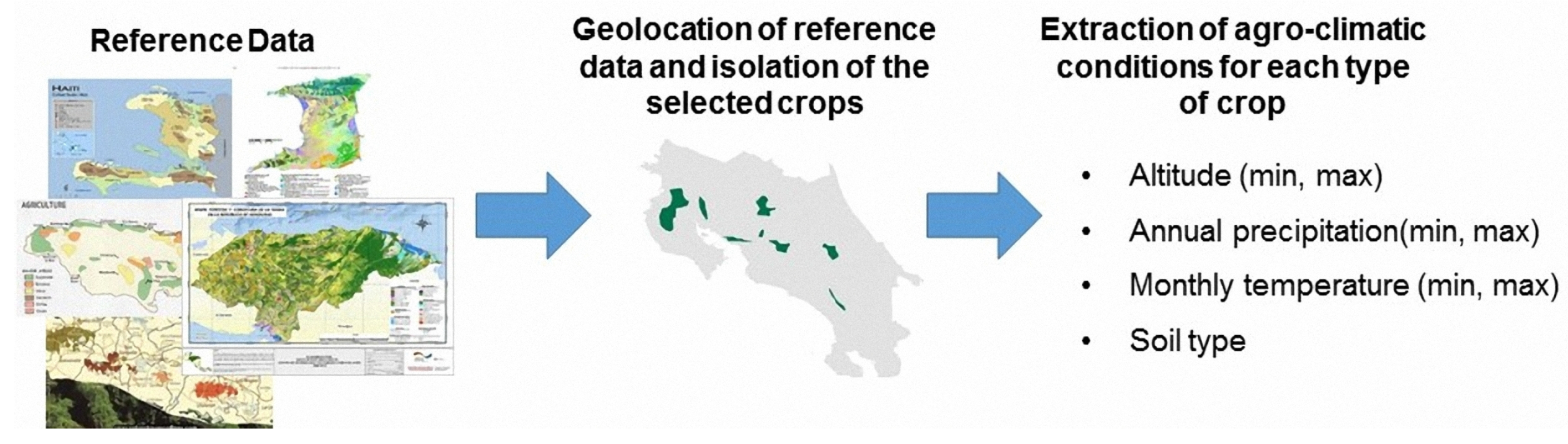
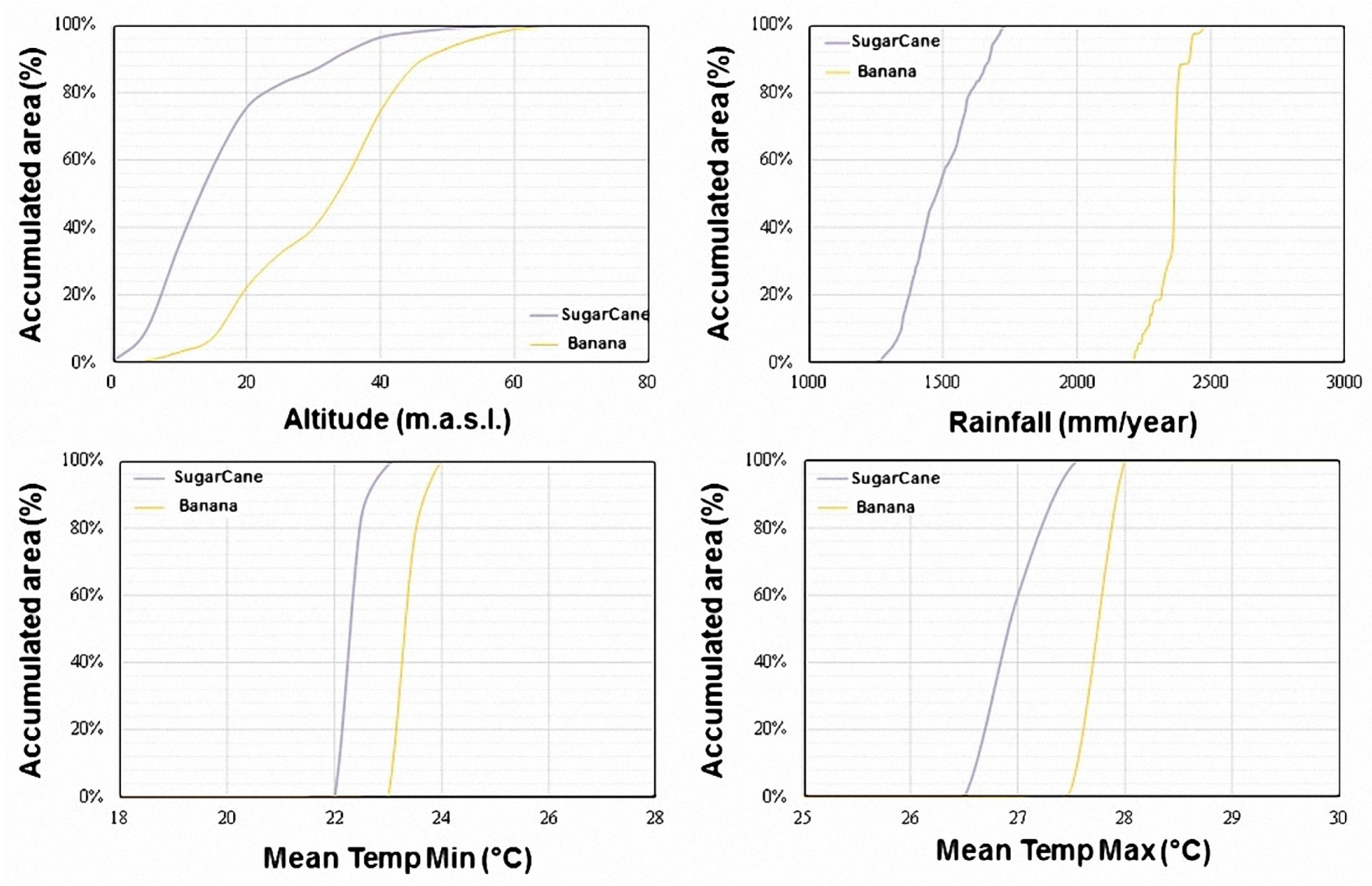
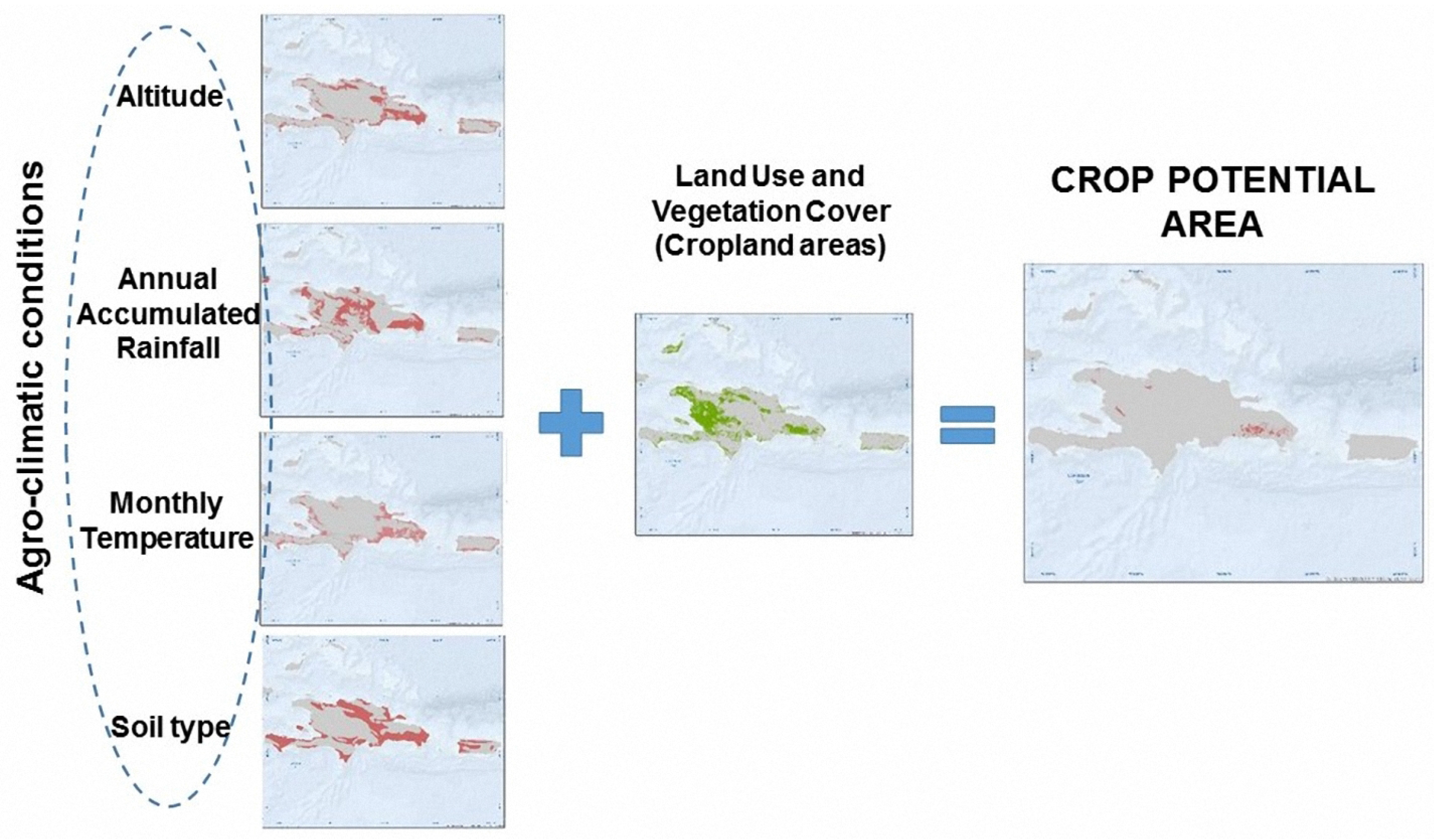
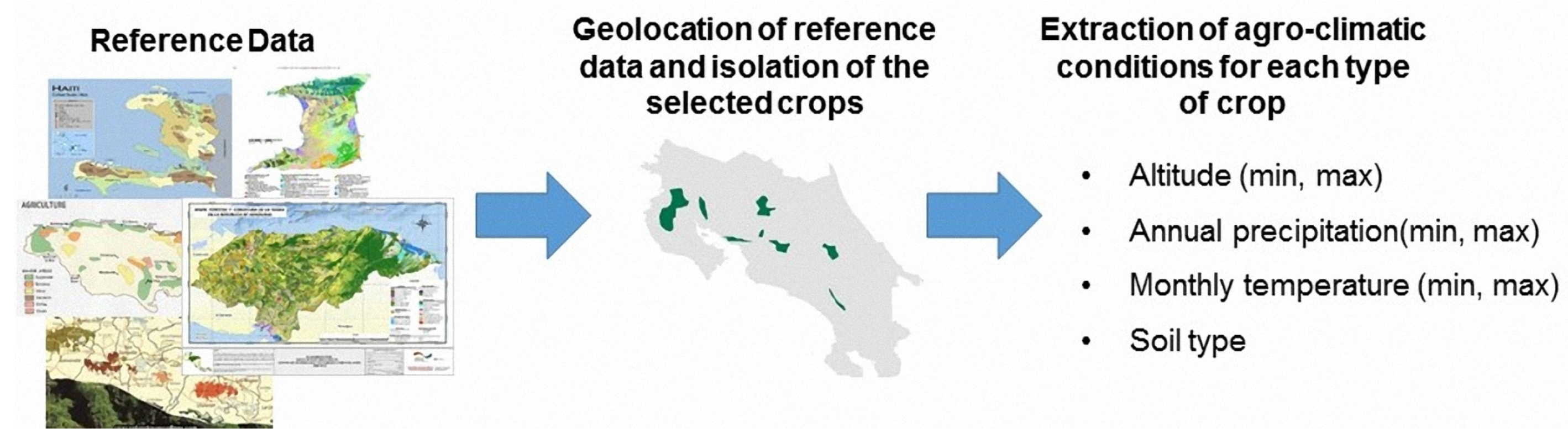
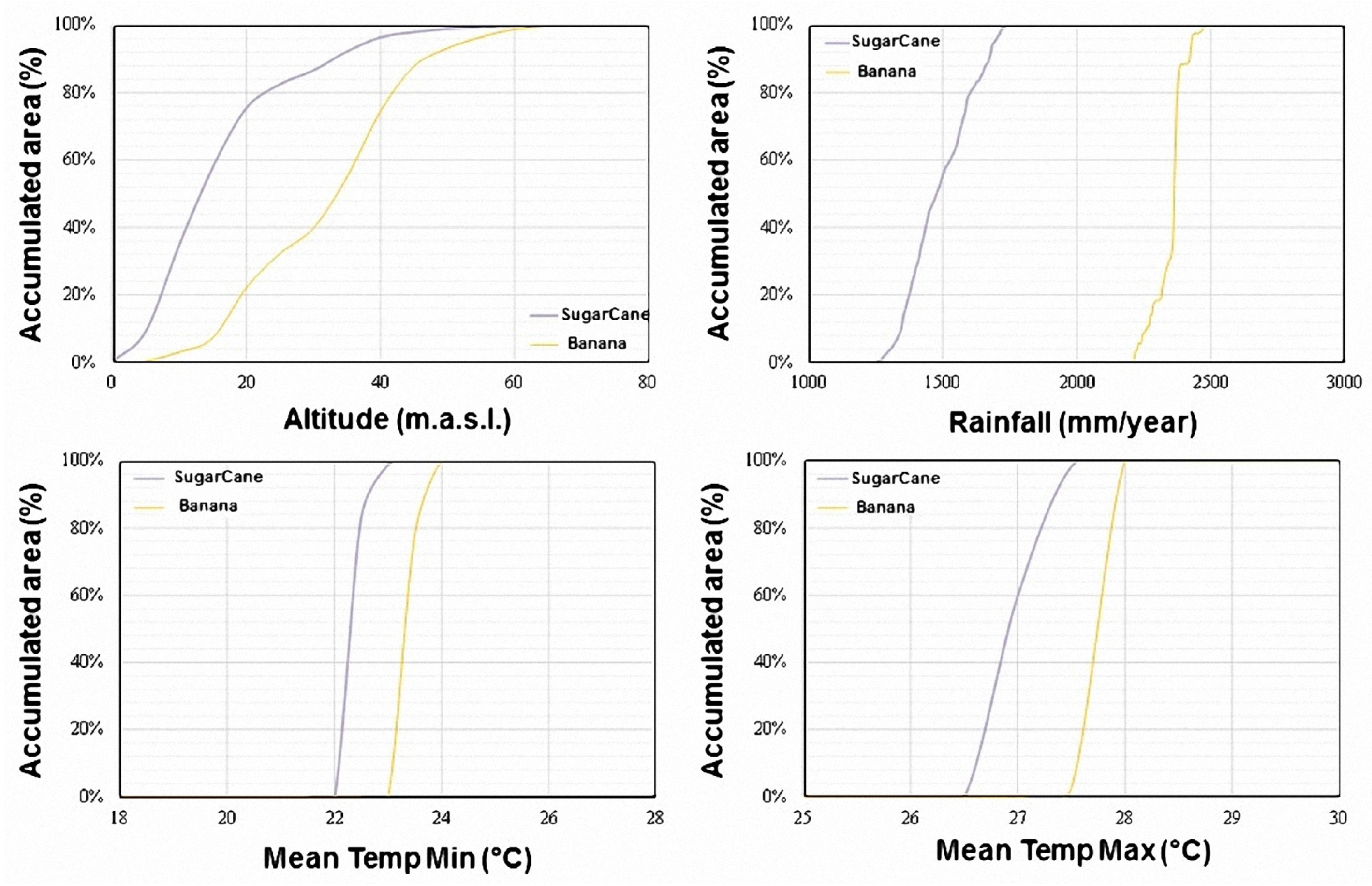
- Definition of the agro-climatic conditions required for each crop to achieve its potential production through the regression analysis of reference data from public sources. The parameters that define the agro-climatic conditions are: (1) annual precipitation, (2) monthly temperature (minimum and maximum), (3) elevation over sea level, and (4) edaphology.
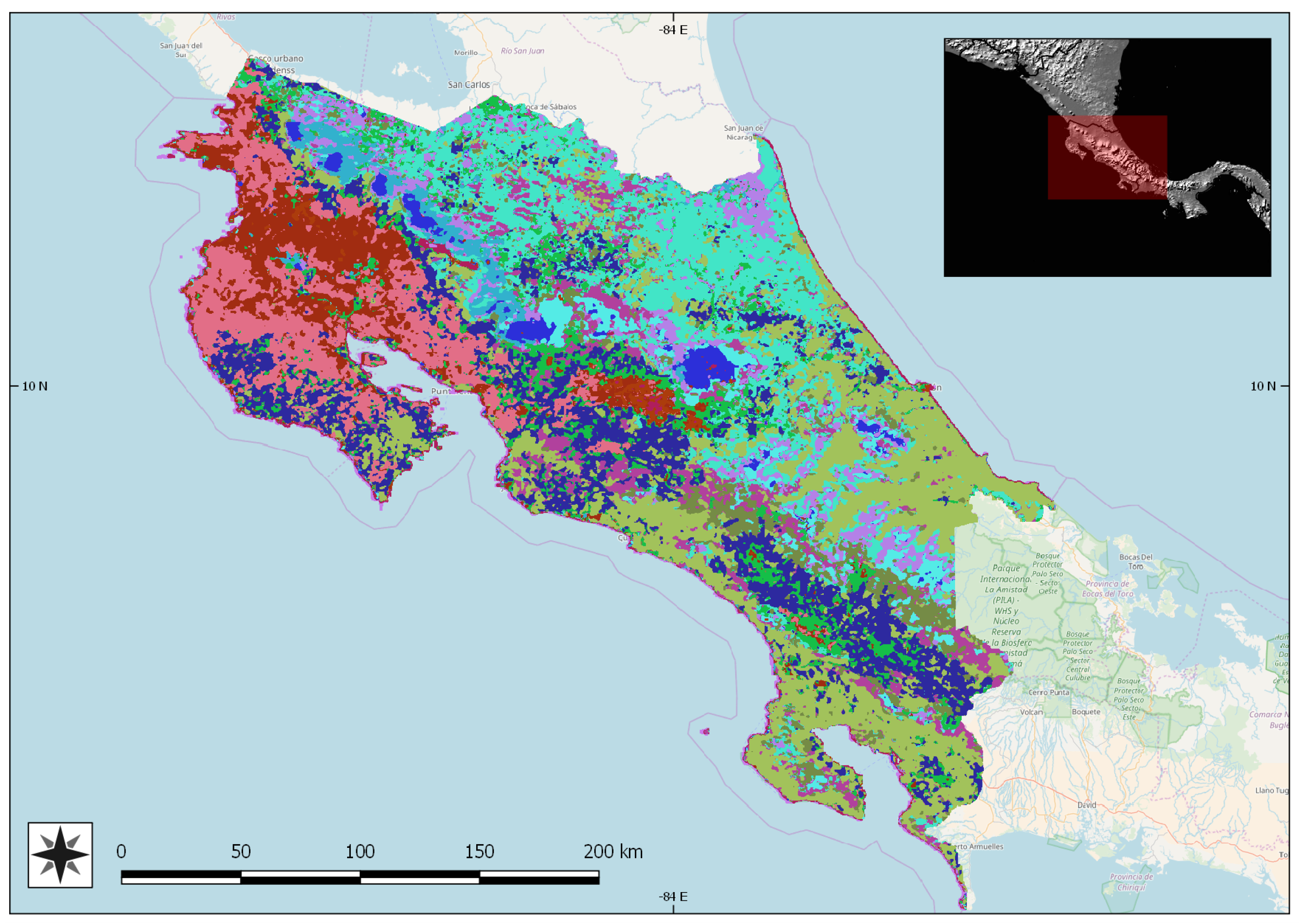
- Estimation of crop potential areas that are those cropland areas where all the ranges of agro-climatic conditions are fulfilled. In this step, the agro-climatic parameters defined previously and the cropland classification are contained in different layers that are spatially crossed to unify all in a single element [33].
5.1. Input Data
5.2. Definition of Agro-Climatic Conditions
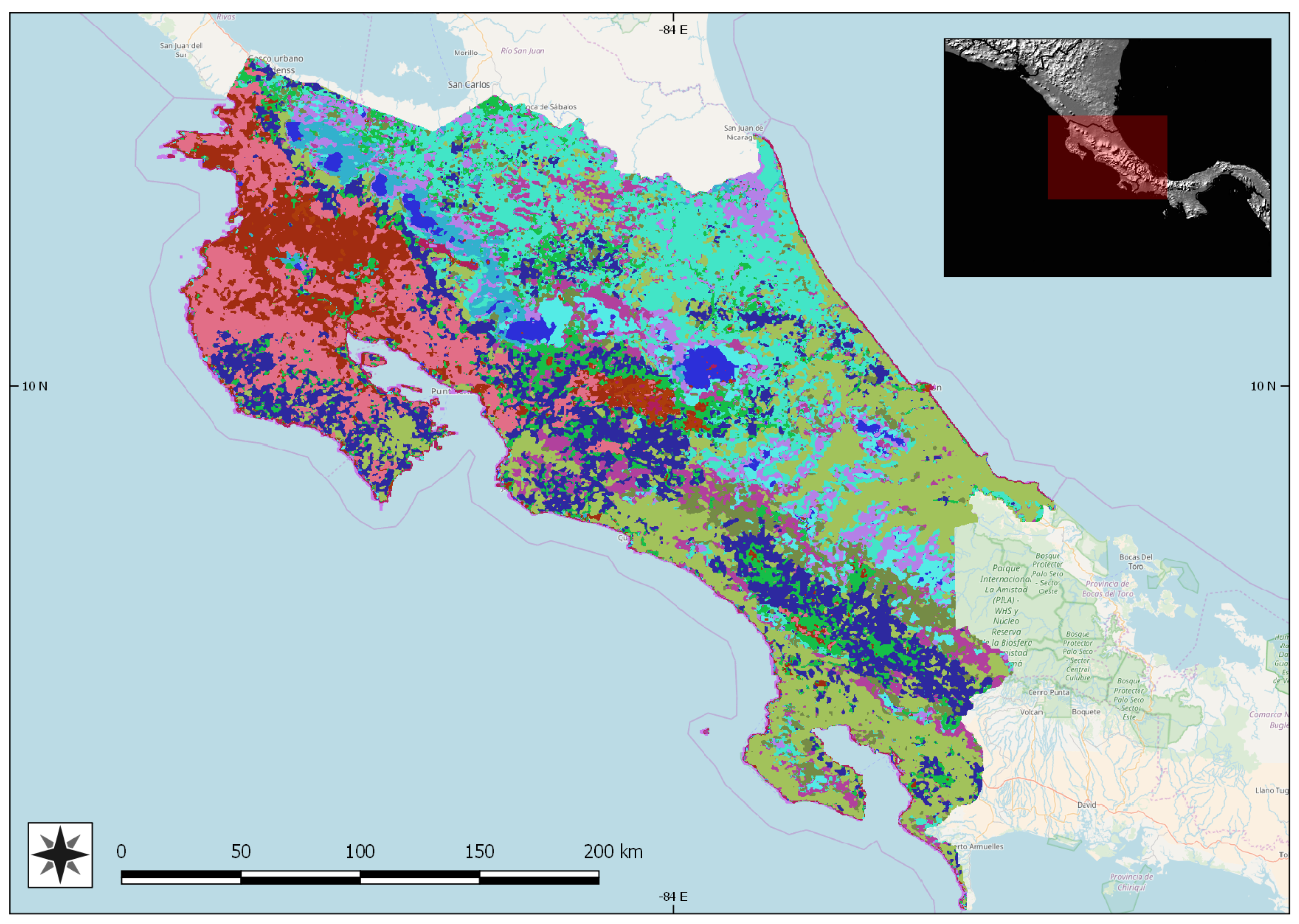
5.3. Estimation of Crop Potential Areas
- The International Geosphere Biosphere Programme (IGBP) scheme, in which seventeen land covers were identified, eleven of them being vegetation, three terrain classes and three more vegetation-free classes. Their stated objective was to provide a global land cover dataset that was more up-to-date, of known accuracy and with higher spatial resolution and greater internal consistency than any other existing dataset. The scheme is based on definitions of three canopy components: above-ground biomass, leaf longevity, and leaf type process. The land-cover categories identified by the IGBP are related to the needs of gas exchange studies; vegetation attributes for modeling Net Primary Production (NPP); burn emissions and gas exchange; wetlands cover and wetland water regimes; changes in vegetation/land-cover over time; biological attributes; physical attributes, and landscape characteristics [38,39,40,41].
- The University of Maryland land cover classification (UMD) dataset, with fourteen classes, two of which have no vegetation. The approach taken involved a hierarchy of pairwise class trees where a logic based on vegetation form was applied until all classes were depicted. Minimum annual red reflectance, peak annual Normalized Difference Vegetation Index (NDVI), and minimum channel three brightness temperature were among the most used multitemporal metrics. Depictions of forests and woodlands, and areas of mechanized agriculture are in general agreement with other sources of information, while classes such as low biomass agriculture and high-latitude broadleaf forest are not [8].
- The LAI/FPAR scheme, with nine vegetation classes and two vegetation- free ones. This scheme uses a method for the estimation of global leaf area index (LAI) and fraction of photosynthetically active radiation absorbed by the vegetation (FPAR) from atmospherically corrected Normalized Difference Vegetation Index (NDVI) observations. LAI is defined as the one-sided green leaf area per unit ground area in broadleaf canopies and as one half of the total needle surface area per unit ground area in coniferous canopies. FPAR is defined as the fraction of incident photo-synthetically active radiation (400–700nm) absorbed by the green elements of a vegetation canopy. The method requires stratification of global vegetation into cover types that are compatible with the radiative transfer model [42].
- The Net Primary Production scheme (NPP) with nine vegetation classes and two vegetation-free ones. NPP defines the rate at which all plants in an ecosystem produce net useful chemical energy. In other words, NPP equals the difference between the rate at which plants in an ecosystem produce useful chemical energy (or GPP, Gross Primary Production), and the rate at which they expend some of that energy for respiration. The Primary Production products are designed to provide an accurate regular measure of the growth of the terrestrial vegetation. Version-55 Terra/MODIS NPP products are validated to Stage-3; this means that its accuracy was assessed and uncertainties in the product were well-established via independent measurements made in a systematic and statistically robust way that represents global conditions. These data are deemed ready for use in science applications [43].
- The Functional Type Plant scheme (FTP) with nine vegetation classes, two vegetation-free and one ice-water class. While most land models developed for use with climate models represent vegetation as discrete biomes, this is, at least for mixed life-form biomes, inconsistent with the leaf-level and whole-plant physiological parameterizations needed to couple these bio-geophysical models with bio-geochemical and ecosystem dynamics models. In the calculation of this scheme, the authors present simulations with the National Center for Atmospheric Research land surface model (NCAR LSM) that examined the effect of representing vegetation as patches of plant functional types (PFTs) that coexist within a model grid cell. This approach is consistent with ecological theory and models and allows for unified treatment of vegetation in climate and ecosystem models [44].
6. Information Fusion Strategy
7. Results and Validation
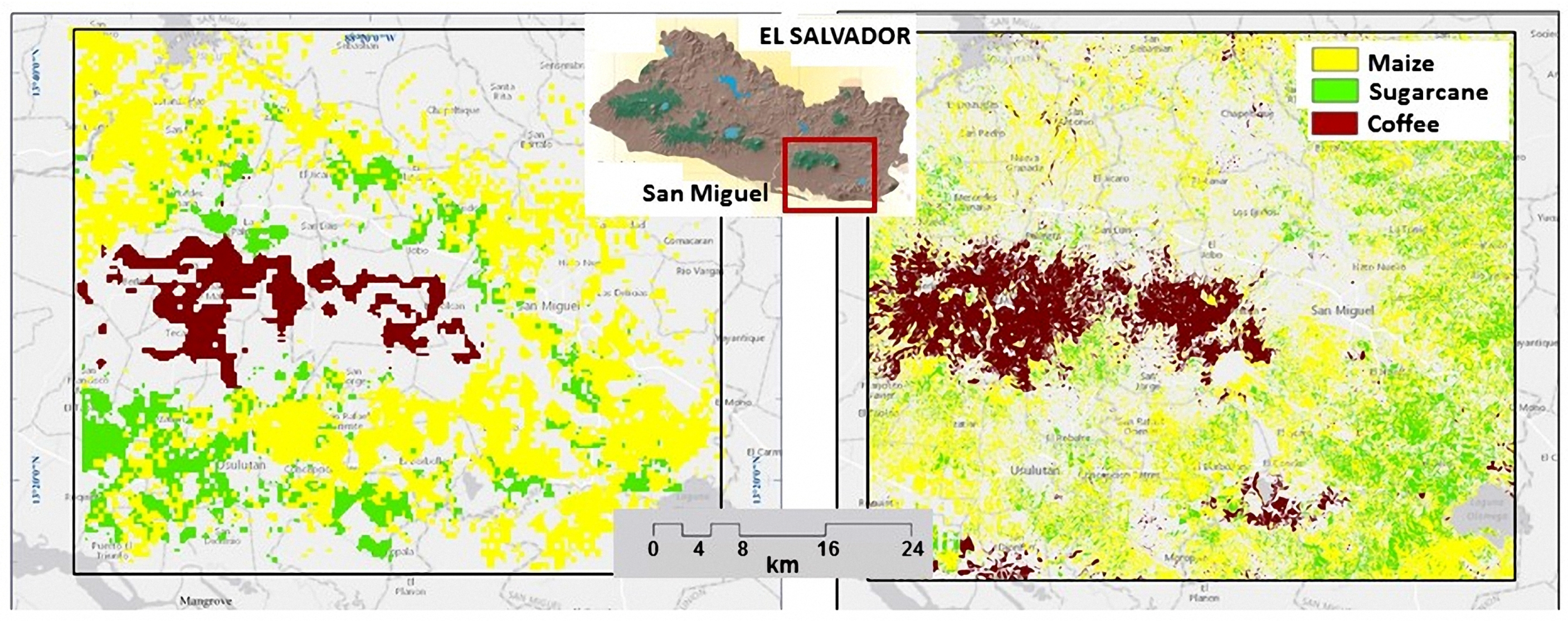
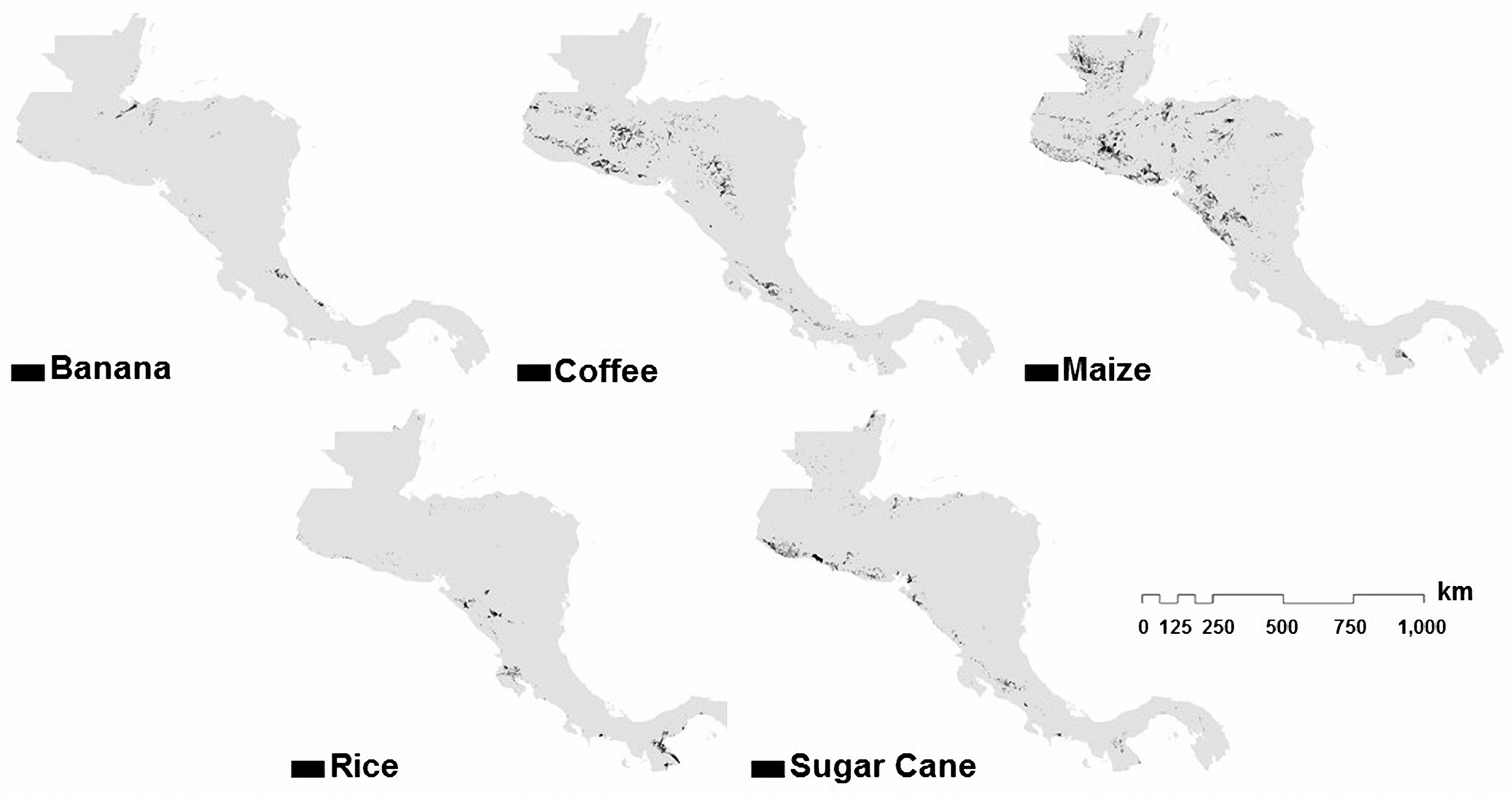
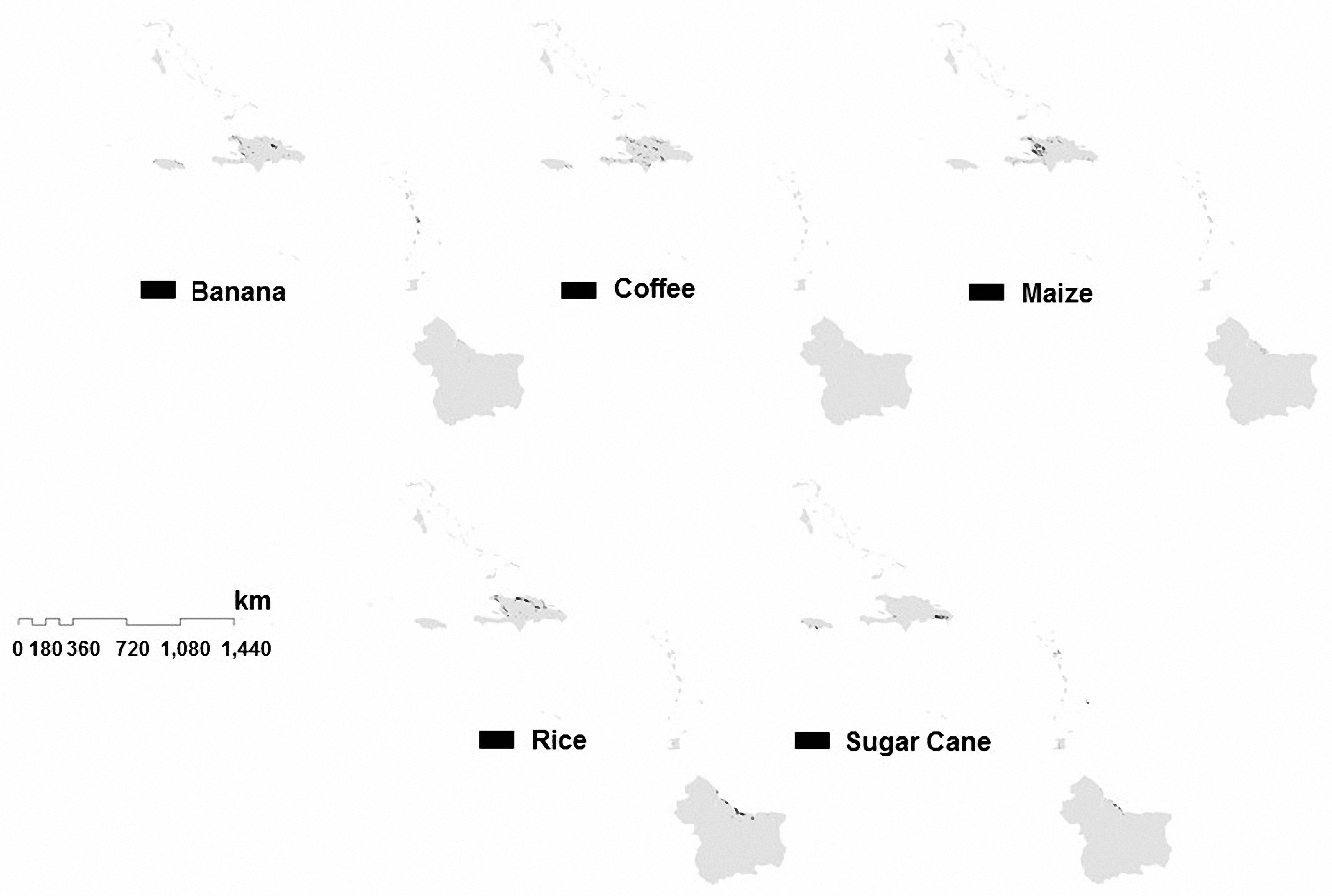
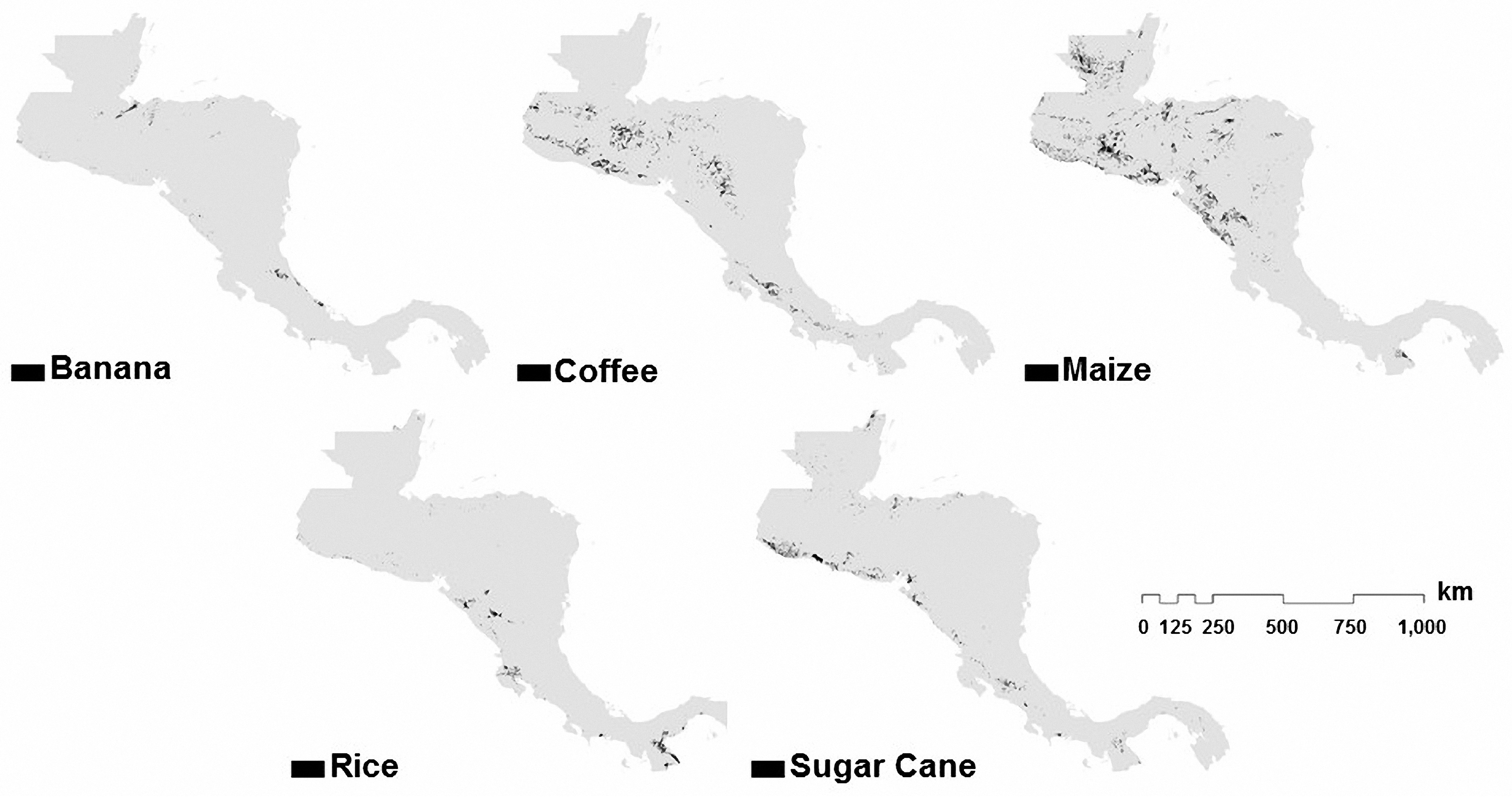
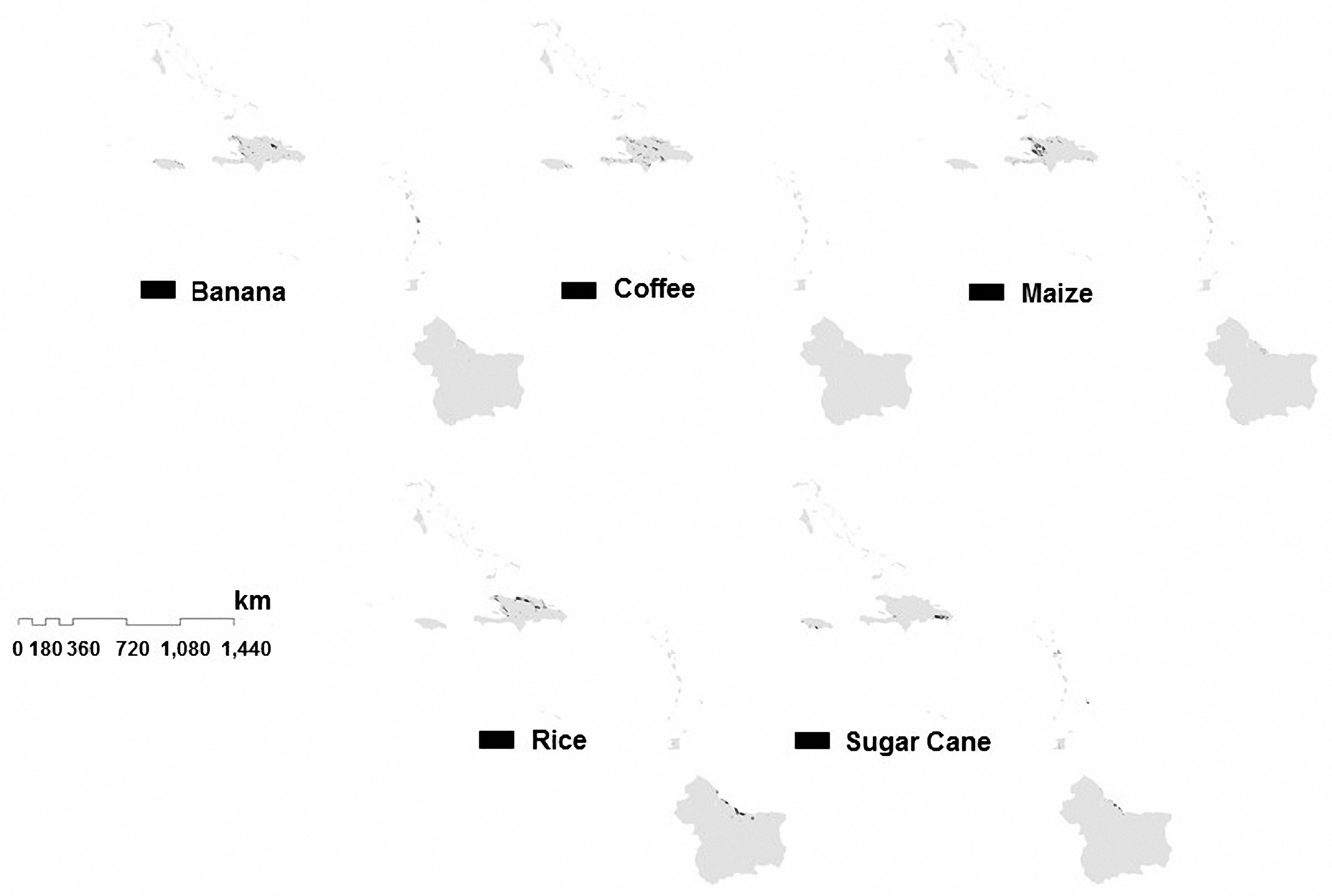
7.1. Results of Estimated Areas
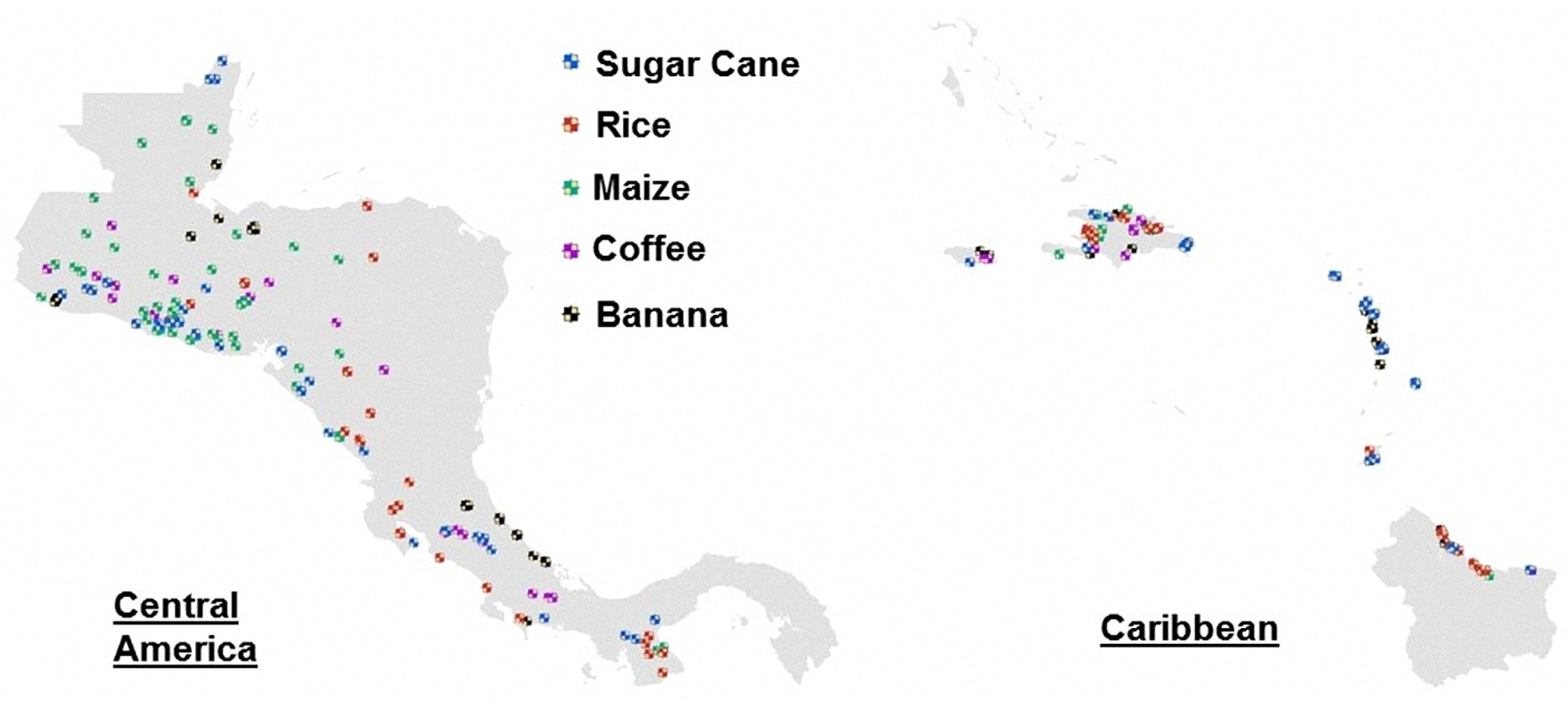
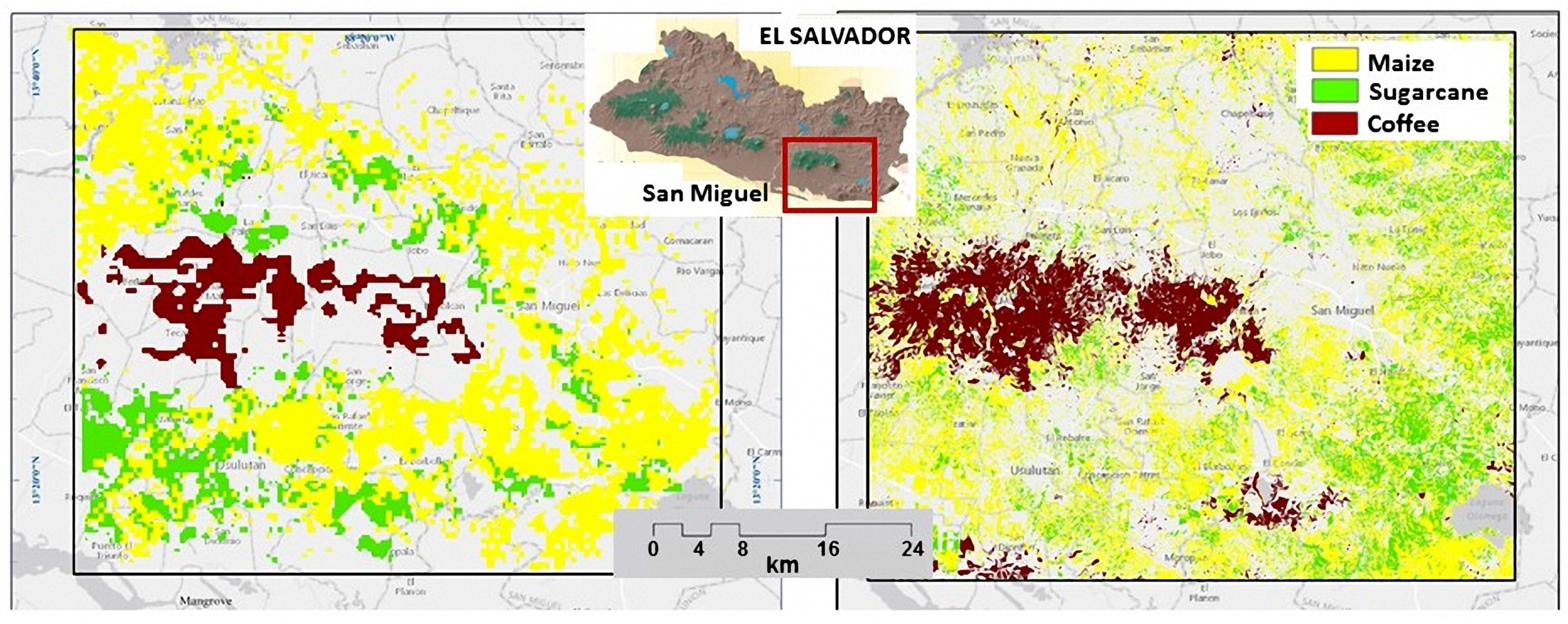
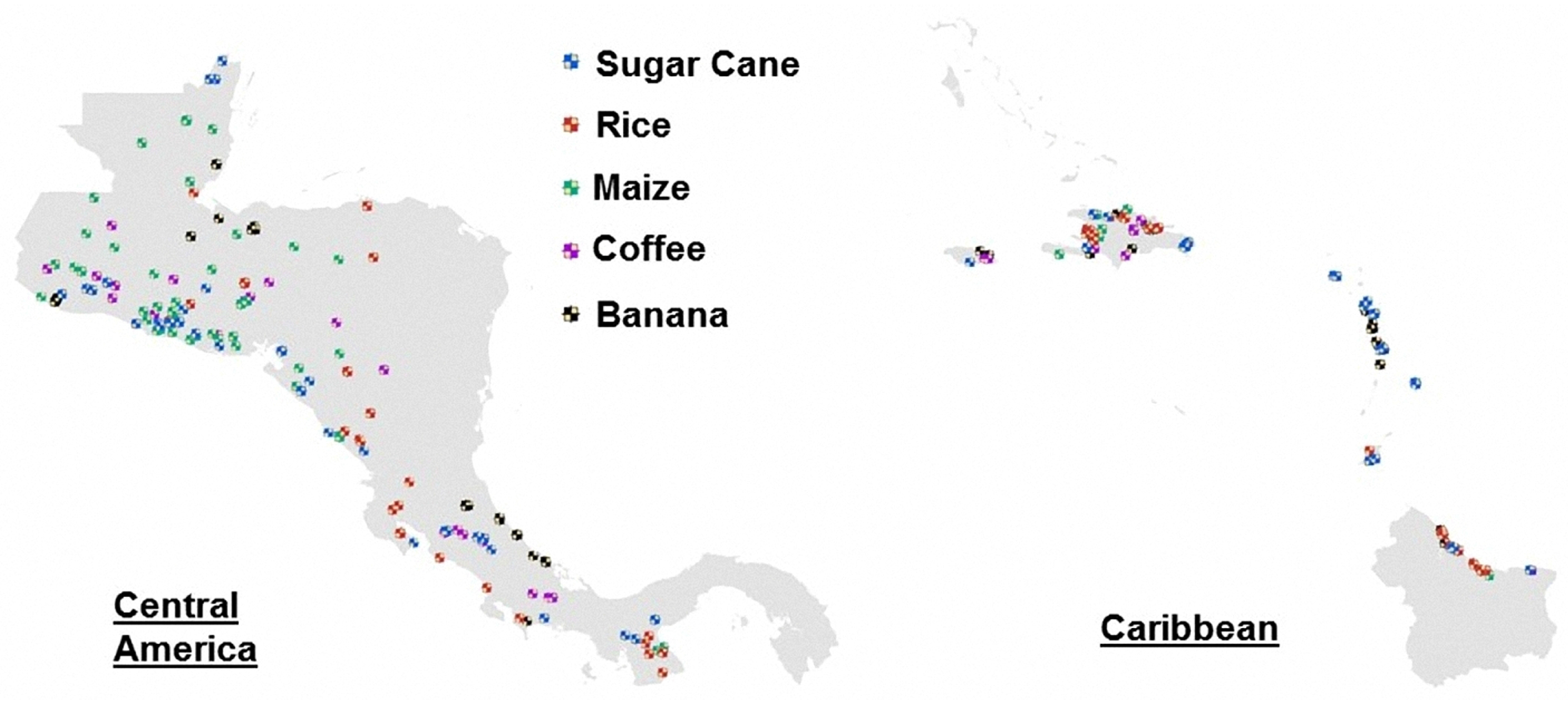
7.2. Verification with Checkpoints
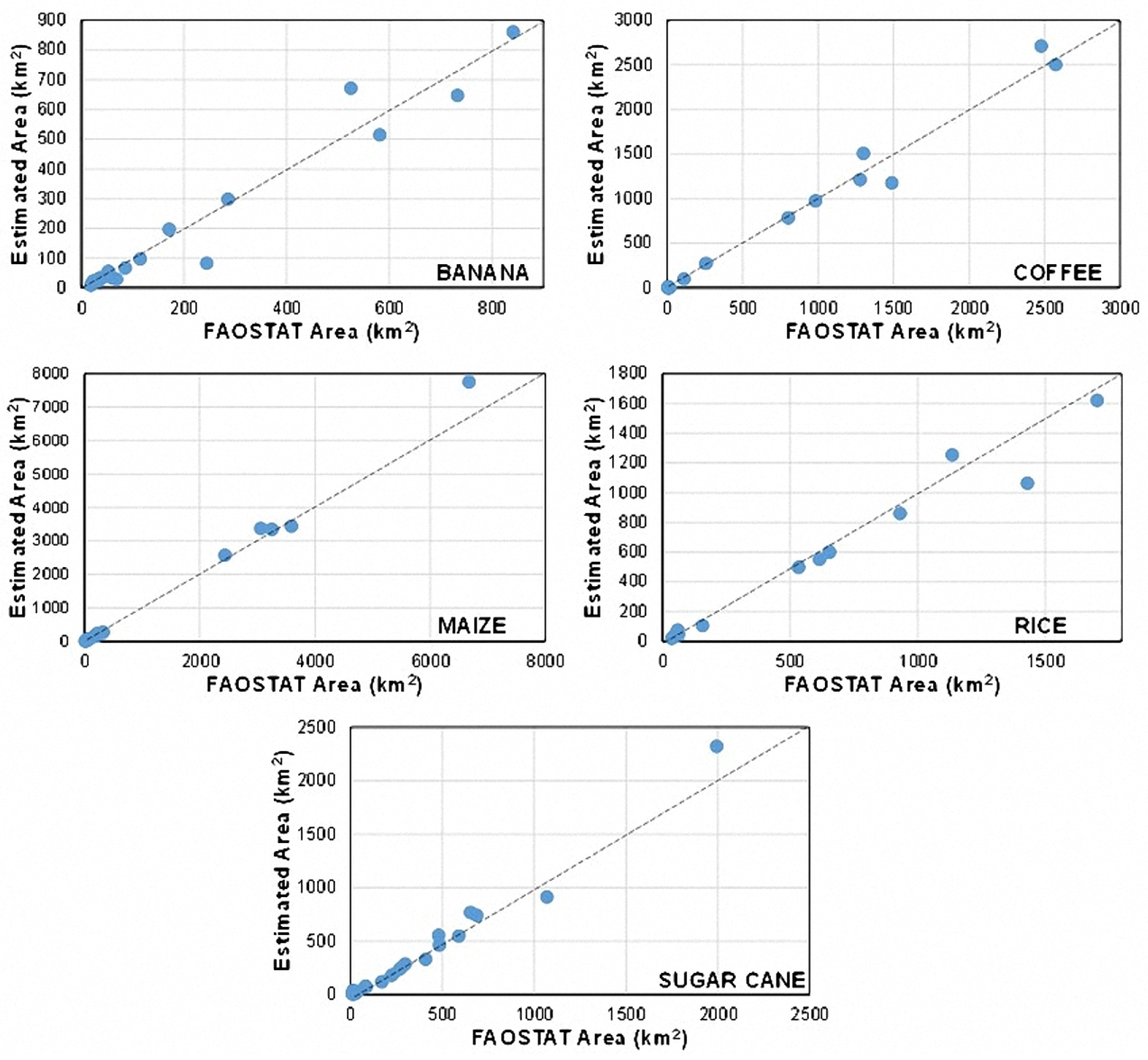
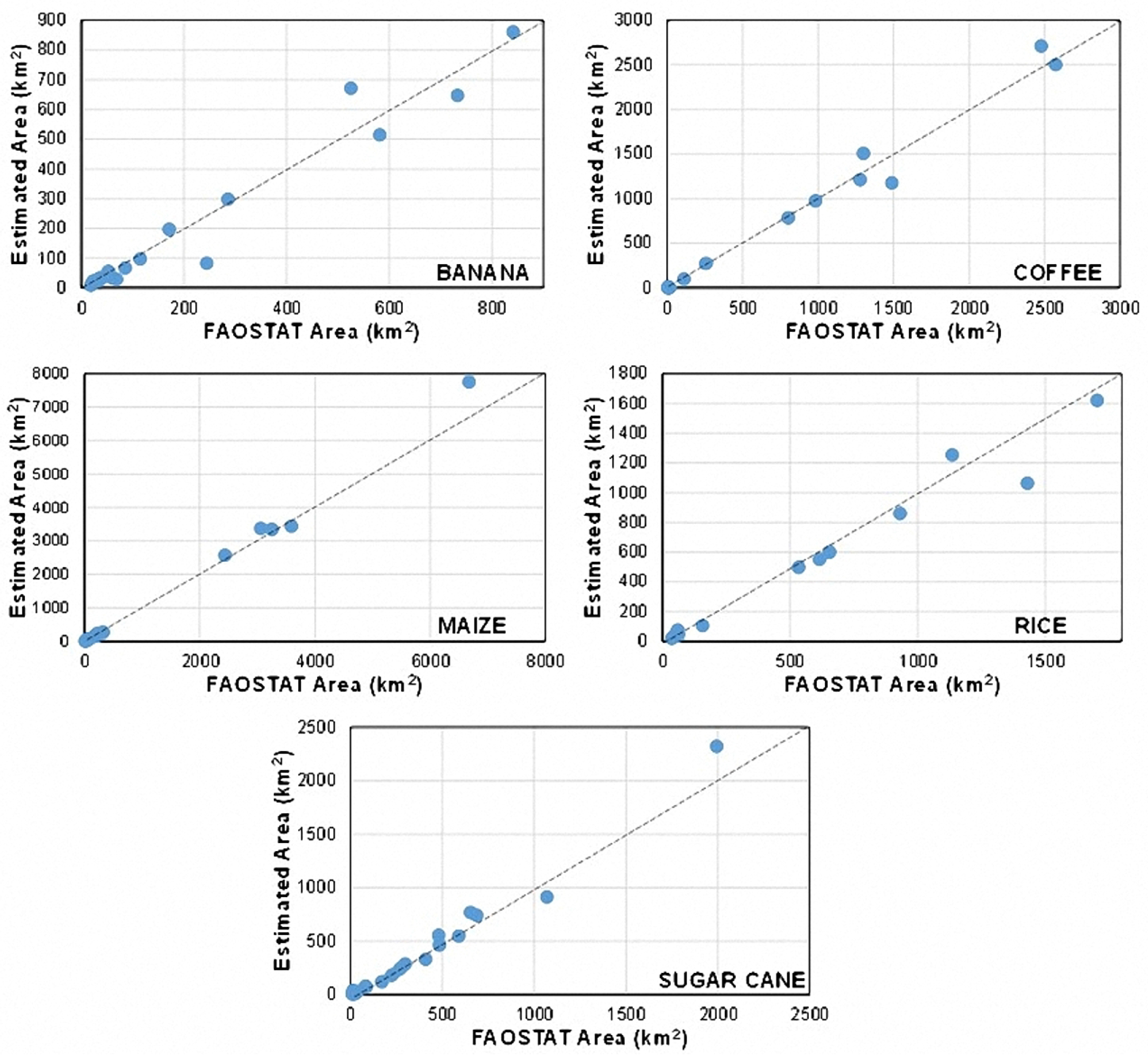
7.3. Comparison of Estimated Areas vs. FAO’s Statistics
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DAAC | Distributed Active Archive Center |
| EOS | Corine Land Cover |
| EOS | Earth Observing System |
| EOSDIS | Earth Observing System Data and Information System |
| FAO | Food and Agriculture Organization |
| FTP | Functional Type Plant |
| GIS | Geographic Information System |
| GMES | Global Monitoring for Environment and Security |
| IGBP | International Geosphere-Biosphere Programme |
| LAADS | Level-1 and Atmosphere Archive and Distribution System |
| LAI | Leaf Area Index |
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| NASA | National Aeronautics and Space Administration |
| NDVI | Normalized Differential Vegetation Index |
| SIFT | Scale-Invariant Feature Transform |
| SPOT | Système Pour l’Observation de la Terre (System for Earth Observation, in French) |
| SRTM | Shuttle Radar Topography Mission |
| UMD | University of Maryland Department of Geography |
References
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Thenkabail, P.; Lyon, J.; Huete, A. Advances in Hyperspectral Remote Sensing of Vegetation and Agricultural Croplands; CRC Press: Boca Raton, FL, USA, 2011; pp. 3–36. [Google Scholar]
- Gurenko, E.N. Climate Change and Insurance: Disaster Risk Financing in Developing Countries; Routledge: Abingdon, UK, 2015. [Google Scholar]
- Joyette, A.R.; Nurse, L.A.; Pulwarty, R.S. Disaster risk insurance and catastrophe models in risk-prone small Caribbean islands. Disasters 2015, 39, 467–492. [Google Scholar] [CrossRef] [PubMed]
- Jongman, B.; Hochrainer-Stigler, S.; Feyen, L.; Aerts, J.C.; Mechler, R.; Botzen, W.W.; Bouwer, L.M.; Pflug, G.; Rojas, R.; Ward, P.J. Increasing stress on disaster-risk finance due to large floods. Nat. Clim. Chang. 2014, 4, 264–268. [Google Scholar] [CrossRef]
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Hansen, M.C.; Defries, R.S.; Townshend, J.R.G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens. 2000, 21, 1331–1364. [Google Scholar] [CrossRef]
- Bartholomé, E.; Belward, A. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar] [CrossRef]
- Büttner, G. CORINE Land Cover and Land Cover Change Products. In Land Use and Land Cover Mapping in Europe: Practices & Trends; Manakos, I., Braun, M., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 55–74. [Google Scholar]
- Corine Land Cover. Available online: http://land.copernicus.eu/pan-european/corine-land-cover/view (accessed on 30 August 2017).
- Townshend, J.R.; Masek, J.G.; Huang, C.; Vermote, E.F.; Gao, F.; Channan, S.; Sexton, J.O.; Feng, M.; Narasimhan, R.; Kim, D.; et al. Global characterization and monitoring of forest cover using Landsat data: opportunities and challenges. Int. J. Digit. Earth 2012, 5, 373–397. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an Operational System for Crop Type Map Production Using High Temporal and Spatial Resolution Satellite Optical Imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Simonetti, D.; Simonetti, E.; Szantoi, Z.; Lupi, A.; Eva, H. First results from the phenology-based synthesis classifier using Landsat 8 imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1496–1500. [Google Scholar] [CrossRef]
- Badhwar, G. Classification of corn and soybeans using multitemporal thematic mapper data. Remote Sens. Environ. 1984, 16, 175–181. [Google Scholar] [CrossRef]
- Murthy, C.S.; Raju, P.V.; Badrinath, K.V.S. Classification of wheat crop with multi-temporal images: Performance of maximum likelihood and artificial neural networks. Int. J. Remote Sens. 2003, 24, 4871–4890. [Google Scholar] [CrossRef]
- Brown, J.C.; Kastens, J.H.; Coutinho, A.C.; de Castro Victoria, D.; Bishop, C.R. Classifying multiyear agricultural land use data from Mato Grosso using time-series MODIS vegetation index data. Remote Sens. Environ. 2013, 130, 39–50. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asner, G.P. Cropland distributions from temporal unmixing of MODIS data. Remote Sens. Environ. 2004, 93, 412–422. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Ozdogan, M. The spatial distribution of crop types from MODIS data: Temporal unmixing using Independent Component Analysis. Remote Sens. Environ. 2010, 114, 1190–1204. [Google Scholar] [CrossRef]
- Verbeiren, S.; Eerens, H.; Piccard, I.; Bauwens, I.; van Orshoven, J. Sub-pixel classification of SPOT-VEGETATION time series for the assessment of regional crop areas in Belgium. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 486–497. [Google Scholar] [CrossRef]
- USGS/NASA Land Processes Distributed Active Archive Center. 2002. Available online: https://earthdata.nasa.gov/about/daacs/daac-lpdaac (accessed on 15 January 2018).
- Copernicus Open Access Hub. 2017. Available online: https://scihub.copernicus.eu/ (accessed on 15 January 2018).
- Sedaghat, A.; Ebadi, H. Remote Sensing Image Matching Based on Adaptive Binning SIFT Descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Aldrighi, M.; Dell’Acqua, F. Mode-based method for matching of pre-and postevent remotely sensed images. IEEE Geosci. Remote Sens. Lett. 2009, 6, 317–321. [Google Scholar] [CrossRef]
- Tahoun, M.; Shabayek, A.E.R.; Nassar, H.; Giovenco, M.M.; Reulke, R.; Emary, E.; Hassanien, A.E. Satellite Image Matching and Registration: A Comparative Study Using Invariant Local Features. In Image Feature Detectors and Descriptors: Foundations and Applications; Awad, A.I., Hassaballah, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 135–171. [Google Scholar]
- De Vecchi, D.; Harb, M.; Iannelli, G.C.; Gamba, P.; Dell’Acqua, F.; Feitosa, R.Q. A feature-based approach to register CBERS CCD and HRC imagery for built-up area extraction purposes. In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Harb, M.; Gamba, P.; Dell’Acqua, F. Automatic Delineation of Clouds and Their Shadows in Landsat and CBERS (HRCC) Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1532–1542. [Google Scholar] [CrossRef]
- Harb, M.; Vecchi, D.D.; Gamba, P.; Dell’Acqua, F.; Feitosa, R. Automatic clouds/shadows extraction method from CBERS-2 CCD and LANDSAT data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4594–4597. [Google Scholar]
- Harb, M.; De Vecchi, D.; Dell’Acqua, F. Automatic hybrid-based built-up area extraction from Landsat 5, 7, and 8 data sets. In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Carroll, M.; Townshend, J.; DiMiceli, C.; Noojipady, P.; Sohlberg, R. A new global raster water mask at 250 m resolution. Int. J. Digit. Earth 2009, 2, 291–308. [Google Scholar] [CrossRef]
- FAO. Agro-Ecological Zoning: Guidelines; Number 73; Food & Agriculture Organization: Rome, Italy, 1996. [Google Scholar]
- Potencial Productivo de Especies Agrícolas de Importancia Socioeconómica en México. Available online: http://www.cmdrs.gob.mx/sesiones/Documents/2012/5_sesion/inifap_estudio.pdf (accessed on 12 February 2018). (In Spanish).
- Hijmans, R.J.; Cameron, S.E.; Parra, J.L.; Jones, P.G.; Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Int. J. Climatol. 2005, 25, 1965–1978. [Google Scholar] [CrossRef]
- Fick, S.E.; Hijmans, R.J. Worldclim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The shuttle radar topography mission. Rev. Geophys. 2007, 45. [Google Scholar] [CrossRef]
- LPDAAC. Land Processes Distributed Active Archive Center. 2016. Available online: https://lpdaac.usgs.gov/ (accessed on 15 January 2018).
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Belward, A.S.; Estes, J.E.; Kline, K.D. The IGBP-DIS Global 1-km LandCover Data Set DISCover: A Project Overview. Photogramm. Eng. Remote Sens. 1999, 65, 1013–1020. [Google Scholar]
- Scepan, J. Thematic validation of high-resolution global land-cover data sets. Photogramm. Eng. Remote Sens. 1999, 65, 1051–1060. [Google Scholar]
- Friedl, M.A.; McIver, D.K.; Hodges, J.C.F.; Zhang, X.Y.; Muchoney, D.; Strahler, A.H.; Woodcock, C.E.; Gopal, S.; Schneider, A.; Cooper, A.; et al. Global land cover mapping from MODIS: algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Myneni, R.B.; Ramakrishna, R.; Nemani, R.; Running, S.W. Estimation of global leaf area index and absorbed par using radiative transfer models. IEEE Trans. Geosci. Remote Sens. 1997, 35, 1380–1393. [Google Scholar] [CrossRef]
- Running, S.W.; Loveland, T.R.; Pierce, L.L. A vegetation classification logic-based on remote-sensing for use in global biogeochemical models. Ambio 1994, 23, 77–81. [Google Scholar]
- Bonan, G.B.; Levis, S.; Kergoat, L.; Oleson, K.W. Landscapes as patches of plant functional types: An integrating concept for climate and ecosystem models. Glob. Biogeochem. Cycles 2002, 16, 5-1–5-23. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spaceborne EO System | Ground Resolution (m) | Swath Width (km) | Revisit Time (days) | Usage in Project |
|---|---|---|---|---|
| MODIS | 250–1000 | 2330 | 6 | baseline |
| Sentinel-2 | 10–60 | 290 | 2–3 | occasional |
| Database | Variables | Ground Resolution | Scale/Applicability | Period |
|---|---|---|---|---|
| WORLD CLIM | monthly minimum, mean and maximum temperature, precipitation, solar radiation, wind speed and water vapour pressure | 30 s (∼1 km2) to 10 min (∼340 km2) | Global, Regional, National, Sub-national, Province/District, Watershed/Basin, Landscape | Average monthly for 1970–2000 |
| SRTM | elevation data | 1 s (∼30 m) | Global, Regional, National, Sub-national, Province/District, Watershed/Basin, Landscape | 2000 |
| DSMW | soil data | 5 min (∼170 km2) | Global, Regional, National | Since 1961 |
| Crop | Altitude (m.a.s.l.) | Temperature (°C) | Precipitation (mm/year) | Dominant Soil | |||
|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | ||
| Banana | 2 | 130 | 24.0 | 28.0 | 2800 | 4900 | Vitric Andosols, Eutric Nitosols, Mollic Andosols |
| Coffee | 550 | 1950 | 15.1 | 25.0 | 1800 | 4100 | Vitric Andosols, Mollic Andosols, Eutric Nitosols |
| Maize | 20 | 985 | 22.5 | 28.0 | 1790 | 3190 | Eutric Nitosols, Dystric Cambisols, Eutric Gleysols |
| Rice | 6 | 800 | 25.3 | 28.6 | 1550 | 4700 | Eutric Nitosols, Pellic Vertisols, Dystric Ambisols |
| Sugar Cane | 550 | 1800 | 17.5 | 29 | 1550 | 3500 | Eutric Nitosols, Vitric Andosols, Eutric Gleysols |
| Temporal coverage (V051) | 2001–2013 |
| Earth-gridded tile area | ∼1200 × 1200 km (∼10 × 10 at the equator) |
| Image dimensions | 2400 × 2400 rows/columns |
| File size | ∼88 MB |
| Resolution | 500 meters |
| Projection | Sinusoidal |
| Data type | 8-bit unsigned integer |
| Data format | HDF-EOS |
| Science Data Set (SDS) layers | 16 |
| IGBP | UMD | LAI/FPAR | NPP | PFT | |
|---|---|---|---|---|---|
| 0 | Water | Water | Water | Water | Water |
| 1 | Evergreen Needleleaf forest | Evergreen Needleleaf forest | Grasses/Cereal crops | Evergreen Needleleaf vegetation | Evergreen Needleleaf trees |
| 2 | Evergreen Broadleaf forest | Evergreen Broadleaf forest | Shrubs | Evergreen Broadleaf vegetation | Evergreen Broadleaf trees |
| 3 | Deciduous Needleleaf forest | Deciduous Needleleaf forest | Broadleaf crops | Deciduous Needleleaf vegetation | Deciduous Needleleaf trees |
| 4 | Deciduous Broadleaf forest | Deciduous Broadleaf forest | Savanna | Deciduous Broadleaf vegetation | Deciduous Broadleaf trees |
| 5 | Mixed forest | Mixed forest | Evergreen Broadleaf forest | Annual Broadleaf vegetation | Shrub |
| 6 | Closed shrublands | Closed shrublands | Deciduous Broadleaf forest | Annual grass vegetation | Grass |
| 7 | Open shrublands | Open shrublands | Evergreen Needleleaf forest | Non-vegetated land | Cereal crops |
| 8 | Woody savannas | Woody savannas | Deciduous Needleleaf forest | Urban | Broad-leaf crops |
| 9 | Savannas | Savannas | Non-vegetated | Urban and built-up | |
| 10 | Grasslands | Grasslands | Urban | Snow and ice | |
| 11 | Permanent wetlands | Barren or sparse vegetation | |||
| 12 | Croplands | Croplands | |||
| 13 | Urban and built-up | Urban and built-up | |||
| 14 | Cropland/Natural vegetation mosaic | ||||
| 15 | Snow and ice | ||||
| 16 | Barren or sparsely vegetated | Barren or sparsely vegetated |
| Crop | IGBP | UMD | LAI/FPAR | FTP |
|---|---|---|---|---|
| Maize, Rice | Croplands, Cropland/Natural vegetation mosaic | Croplands | Cereal crops, Broadleaf crops | Cereal crops, Broadleaf crops |
| Banana, Sugar Cane | Croplands | Croplands | Broadleaf crops | Broadleaf crops |
| Coffee | Evergreen Broadleaf forest, Cropland/Natural vegetation mosaic, Woody savannas | Evergreen Broadleaf forest, Woody savannas | Evergreen Broadleaf forest, Savanna | Evergreen Broadleaf trees, Deciduous Broadleaf trees |
| Crop | Estimated (2) | FAOSTAT (2) | Error (%) |
|---|---|---|---|
| Banana | 3974.38 | 3736.30 | 6.37 |
| Coffee | 11,300.73 | 11,295.11 | 0.05 |
| Maize | 19,888.6 | 21,347.7 | 6.84 |
| Rice | 7354.98 | 6744.94 | 9.04 |
| Sugar Cane | 6656.3 | 6914.6 | 3.74 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dell’Acqua, F.; Iannelli, G.C.; Torres, M.A.; Martina, M.L.V. A Novel Strategy for Very-Large-Scale Cash-Crop Mapping in the Context of Weather-Related Risk Assessment, Combining Global Satellite Multispectral Datasets, Environmental Constraints, and In Situ Acquisition of Geospatial Data. Sensors 2018, 18, 591. https://doi.org/10.3390/s18020591
Dell’Acqua F, Iannelli GC, Torres MA, Martina MLV. A Novel Strategy for Very-Large-Scale Cash-Crop Mapping in the Context of Weather-Related Risk Assessment, Combining Global Satellite Multispectral Datasets, Environmental Constraints, and In Situ Acquisition of Geospatial Data. Sensors. 2018; 18(2):591. https://doi.org/10.3390/s18020591
Chicago/Turabian StyleDell’Acqua, Fabio, Gianni Cristian Iannelli, Marco A. Torres, and Mario L.V. Martina. 2018. "A Novel Strategy for Very-Large-Scale Cash-Crop Mapping in the Context of Weather-Related Risk Assessment, Combining Global Satellite Multispectral Datasets, Environmental Constraints, and In Situ Acquisition of Geospatial Data" Sensors 18, no. 2: 591. https://doi.org/10.3390/s18020591
APA StyleDell’Acqua, F., Iannelli, G. C., Torres, M. A., & Martina, M. L. V. (2018). A Novel Strategy for Very-Large-Scale Cash-Crop Mapping in the Context of Weather-Related Risk Assessment, Combining Global Satellite Multispectral Datasets, Environmental Constraints, and In Situ Acquisition of Geospatial Data. Sensors, 18(2), 591. https://doi.org/10.3390/s18020591