E2mC: Improving Emergency Management Service Practice through Social Media and Crowdsourcing Analysis in Near Real Time

 ,
,  , , ,
, , ,
Abstract
1. Introduction
2. Related Work
2.1. Social Media and Crowdsourcing Platforms in Disaster Management
2.2. Topic Modelling of Short Texts
2.3. Geospatial Analysis of Social Media Data for Disaster Management
2.4. Geolocating and Classifying Images
2.5. 3D Reconstruction from Videos
3. Scenarios
3.1. Early Activation
3.2. Improvement of Social Media Data Usage
3.3. Leveraging the Crowd for Social Media Filtering
3.4. Leveraging the Crowd for Micro-Mapping
3.5. Crowd Engagement
4. Architecture for Leveraging User-Generated Data in Event Detection and Disaster Management
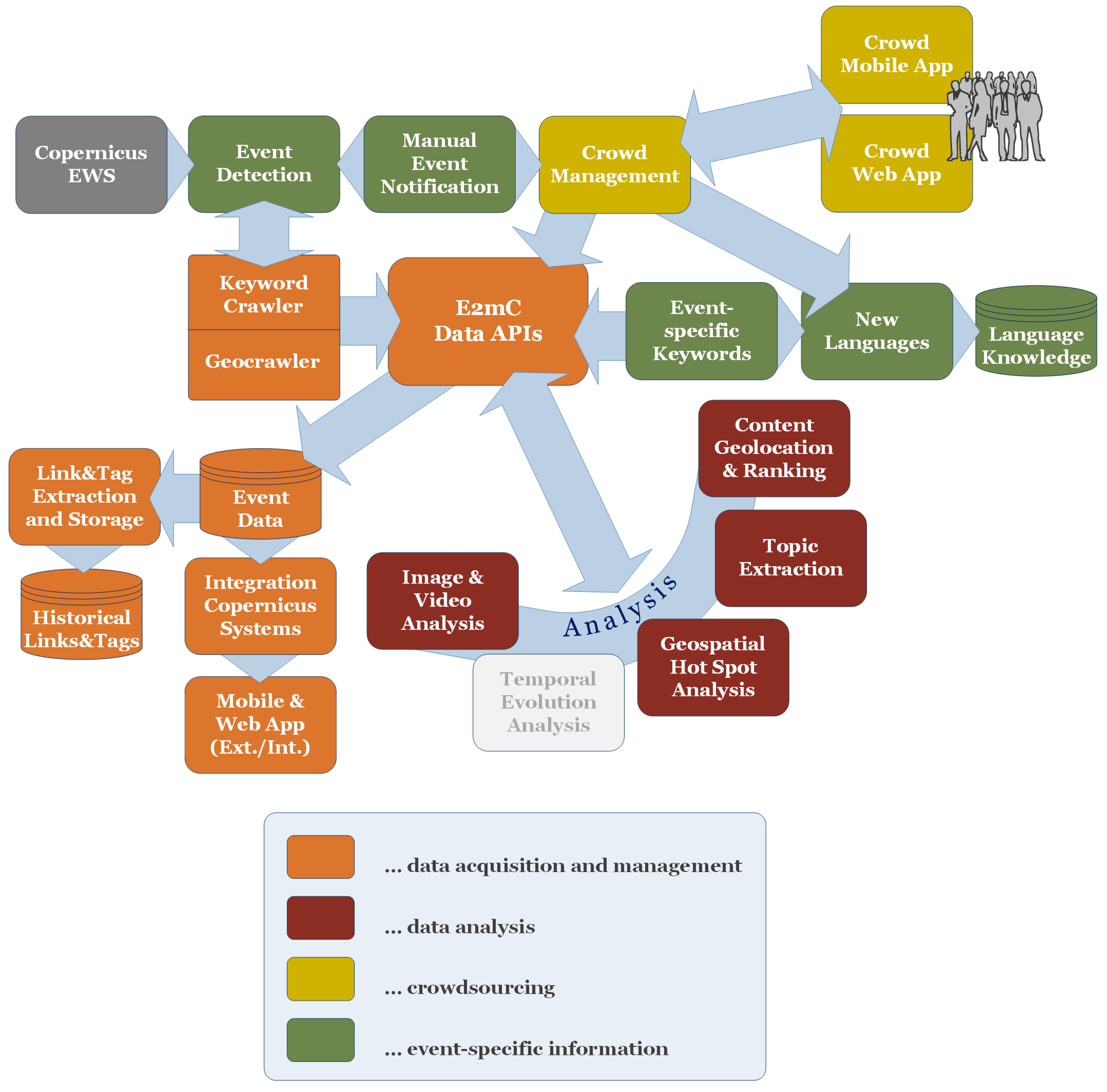
4.1. Overall Architecture
4.2. Early Warning: Alert of an Event
4.3. Text-Based and Geospatial Crawling of Social Media Posts
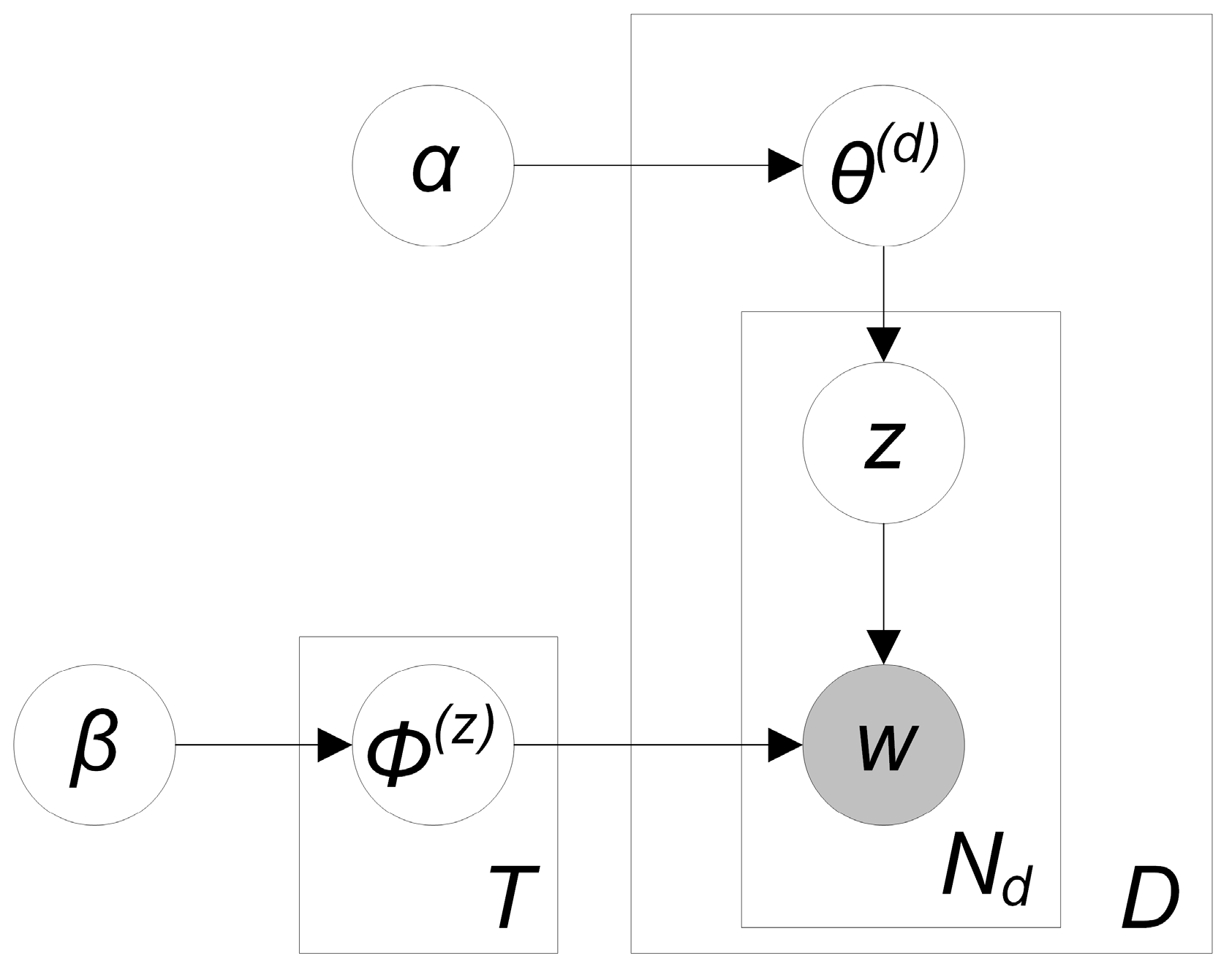
4.4. Semi-Supervised Topic Modelling
4.5. Language-Independent and Language-Specific Topic Modelling and Information Extraction
4.6. Content Geolocation and Ranking
4.7. Image Classification and 3D Reconstruction from Videos
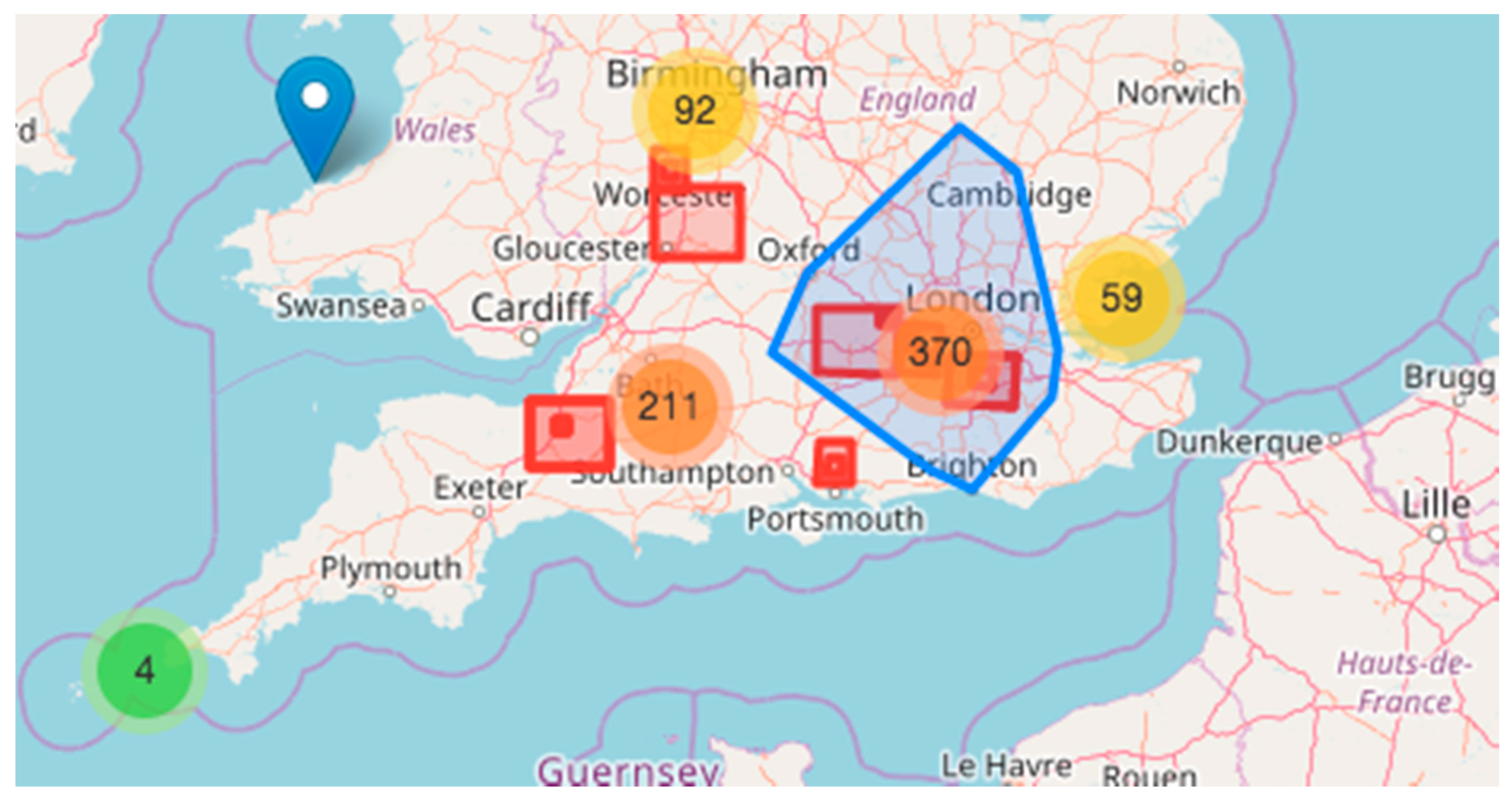
4.8. Geospatial and Hot Spot Analysis
4.9. Crowdsourcing: Integrating User-Generated Content from Volunteers and Experts
4.9.1. Novice and Expert Crowdsourcing Nodes
4.9.2. Enriching Social Media Content
4.10. Accuracy Assessment of Extracted Semantic Topics
4.11. Result Visualisation
5. Preliminary Results
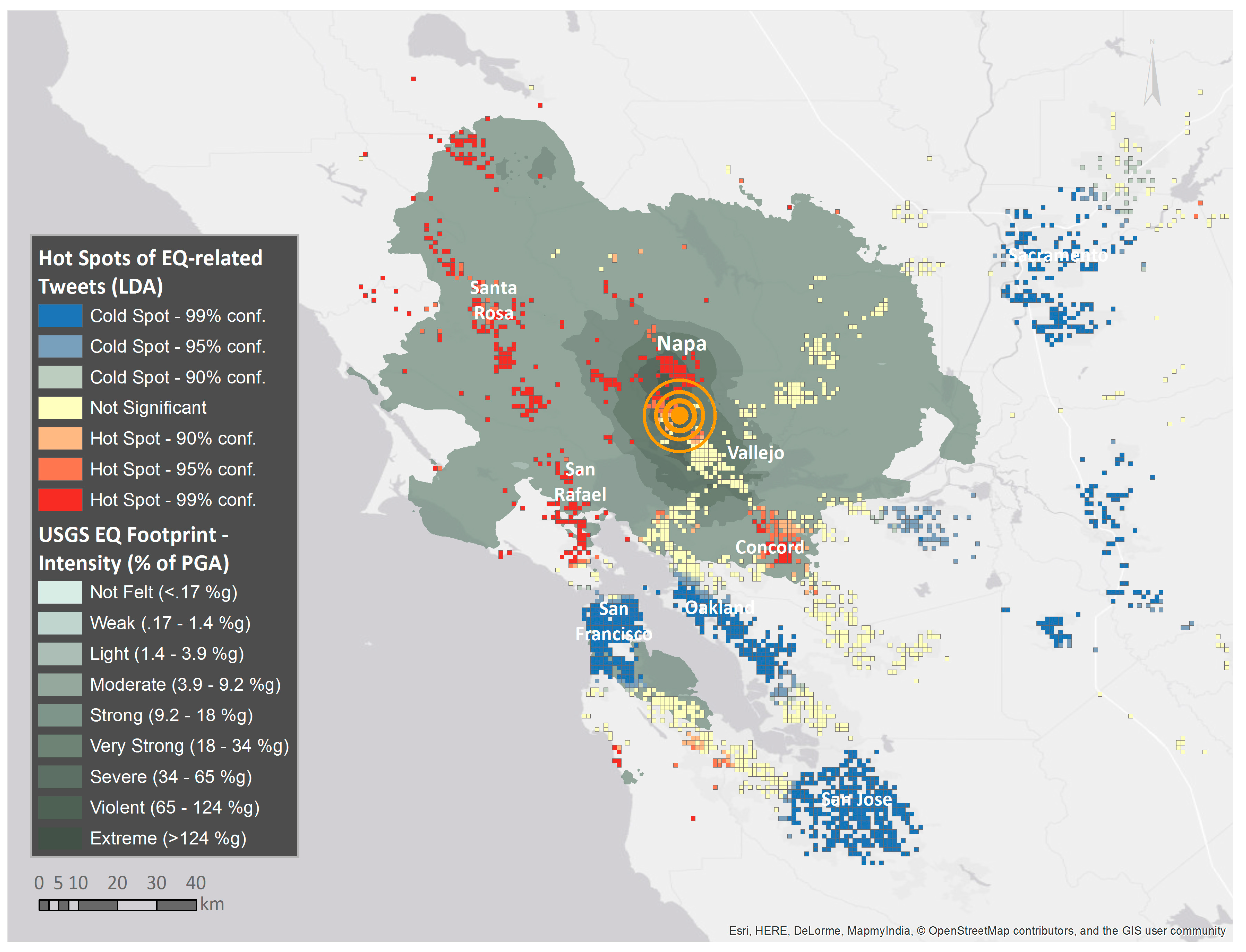
5.1. Combining Machine-Learning Topic Models and Spatiotemporal Analysis
5.2. Damage Assessment Based on User-Generated Data
5.3. Geolocating Social Media Posts
6. Discussion and Limitations
6.1. Limitations of Social Media Data
6.2. Spatial Hot Spot Analysis
6.3. Crowd Management
6.4. Crowdsourced Data Quality
6.5. Integration with Remote Sensing Based Information
7. Conclusions and Outlook
Acknowledgments
Author Contributions
Conflicts of Interest
Disclaimer
References
- Copernicus—The European Earth Observation Programme Emergency Management Service. Available online: http://www.copernicus.eu/sites/default/files/documents/Copernicus_Factsheets/Copernicus_EmergencyMonitoring_Feb2017.pdf (accessed on 10 September 2017).
- Huyck, C.K.; Adams, B.J. Emergency Response in the Wake of the World Trade Center Attack: The Remote Sensing Perspective; MCEER: Buffalo, NY, USA, 2002. [Google Scholar]
- Schnebele, E.; Cervone, G. Improving remote sensing flood assessment using volunteered geographical data. Nat. Hazards Earth Syst. Sci. 2013, 13, 669–677. [Google Scholar] [CrossRef]
- Panagiota, M.; Jocelyn, C.; Erwan, P. State of the Art on Remote Sensing for Vulnerability and Damage Assessment on Urban Context; URBASIS Consort: Grenoble, France, 2011. [Google Scholar]
- Dell’Acqua, F.; Gamba, P. Remote sensing and earthquake damage assessment: Experiences, limits, and perspectives. Proc. IEEE 2012, 100, 2876–2890. [Google Scholar] [CrossRef]
- Mason, D.C.; Speck, R.; Devereux, B.; Schumann, G.J.-P.; Neal, J.C.; Bates, P.D. Flood detection in urban areas using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 48, 882–894. [Google Scholar] [CrossRef]
- Starbird, K. Digital volunteerism during disaster: Crowdsourcing information processing. In Proceedings of the Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 7–12. [Google Scholar]
- PSCE Evolution of Emergency Copernicus Services (E2mC) Project. Available online: https://www.e2mc-project.eu/ (accessed on 29 September 2017).
- Haworth, B.T. Implications of volunteered geographic information for disaster management and GIScience: A more complex world of volunteered geography. Ann. Am. Assoc. Geogr. 2017, 1–15. [Google Scholar] [CrossRef]
- Haworth, B. Emergency management perspectives on volunteered geographic information: Opportunities, challenges and change. Comput. Environ. Urban Syst. 2016, 57, 189–198. [Google Scholar] [CrossRef]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. Crowdsourcing roles, methods and tools for data-intensive disaster management. Inf. Syst. Front. 2017, 1–17. [Google Scholar] [CrossRef]
- Starbird, K.; Stamberger, J. Tweak the tweet: Leveraging microblogging proliferation with a prescriptive syntax to support citizen reporting. In Proceedings of the 7th International ISCRAM Conference, Seattle, WA, USA, 2–5 May 2010; p. 1. [Google Scholar]
- Okolloh, O. Ushahidi, or “testimony”: Web 2.0 tools for crowdsourcing crisis information. Particip. Learn. Action 2009, 59, 65–70. [Google Scholar]
- PYBOSSA. Available online: http://pybossa.com/ (accessed on 22 June 2017).
- Meier, P. Digital Humanitarian Response: Moving from Crowdsourcing to Microtasking. Available online: https://irevolutions.org/2013/01/20/digital-humanitarian-micro-tasking/ (accessed on 22 June 2017).
- Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: New York, NY, USA, 2012; pp. 163–222. [Google Scholar]
- Cormack, G.V.; Gómez Hidalgo, J.M.; Sánz, E.P. Spam filtering for short messages. In Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 313–320. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Beyond trending topics: Real-world event identification on Twitter. ICWSM 2011, 11, 438–441. [Google Scholar]
- Caragea, C.; McNeese, N.; Jaiswal, A.; Traylor, G.; Kim, H.-W.; Mitra, P.; Wu, D.; Tapia, A.H.; Giles, L.; Jansen, B.J.; et al. Classifying text messages for the haiti earthquake. In Proceedings of the 8th International Conference on Information Systems for Crisis Response and Management (ISCRAM2011), Lisbon, Portugal, 8–11 May 2011. [Google Scholar]
- Bermingham, A.; Smeaton, A.F. Classifying sentiment in microblogs: Is brevity an advantage? In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1833–1836. [Google Scholar]
- Figueiredo, F.; Rocha, L.; Couto, T.; Salles, T.; Gonçalves, M.A.; Meira, W., Jr. Word co-occurrence features for text classification. Inf. Syst. 2011, 36, 843–858. [Google Scholar] [CrossRef]
- Saleh, M.R.; Martín-Valdivia, M.T.; Montejo-Ráez, A.; Ureña-López, L.A. Experiments with SVM to classify opinions in different domains. Expert Syst. Appl. 2011, 38, 14799–14804. [Google Scholar] [CrossRef]
- Nigam, K.; McCallum, A.K.; Thrun, S.; Mitchell, T. Text classification from labeled and unlabeled documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Steinbach, M.; Karypis, G.; Kumar, V. A comparison of document clustering techniques. In Proceedings of the KDD Workshop on Text Mining, Boston, MA, USA, 20–23 August 2000; Volume 400, pp. 525–526. [Google Scholar]
- Blei, D.M.; Edu, B.B.; Ng, A.Y.; Edu, A.S.; Jordan, M.I.; Edu, J.B. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar]
- Weng, J.; Lim, E.-P.; Jiang, J.; He, Q. Twitterrank: Finding topic-sensitive influential twitterers. In Proceedings of the Third ACM WSDM 2010, New York, NY, USA, 3–6 February 2010. [Google Scholar] [CrossRef]
- Hong, L.; Davison, B. Empirical study of topic modeling in twitter. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; pp. 80–88. [Google Scholar] [CrossRef]
- Rosen-Zvi, M.; Chemudugunta, C.; Griffiths, T.; Smyth, P.; Steyvers, M. Learning author-topic models from text corpora. ACM Trans. Inf. Syst. 2010, 28, 1–38. [Google Scholar] [CrossRef]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A biterm topic model for short texts. In Proceedings of the WWW’13 22nd International Conference on World Wide Web 2013, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1445–1456. [Google Scholar] [CrossRef]
- Lim, K.W.; Chen, C.; Buntine, W. Twitter-network topic model: A full bayesian treatment for social network and text modeling. arXiv, 2013; arXiv:1609.06791. [Google Scholar]
- Anselin, L. Local indicators of spatial association: LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Cliff, A.D.; Ord, J.K. Spatial Processes: Models & Applications; Taylor & Francis: Abingdon, UK, 1981. [Google Scholar]
- Cliff, A.; Ord, J.K. Spatial Autocorrelation; Pion: London, UK, 1973. [Google Scholar]
- Geary, R.C. The contiguity ratio and statistical mapping. Inc. Stat. 1954, 5, 115–146. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Nelson, T.A.; Boots, B. Detecting spatial hot spots in landscape ecology. Ecography 2008, 31, 556–566. [Google Scholar] [CrossRef]
- Prasannakumar, V.; Vijith, H.; Charutha, R.; Geetha, N. Spatio-temporal clustering of road accidents: GIS based analysis and assessment. Procedia 2011, 21, 317–325. [Google Scholar] [CrossRef]
- Nie, K.; Wang, Z.; Du, Q.; Ren, F.; Tian, Q. A network-constrained integrated method for detecting spatial cluster and risk location of traffic crash: A case study from Wuhan, China. Sustainability 2015, 7, 2662–2677. [Google Scholar] [CrossRef]
- Braithwaite, A.; Li, Q. Transnational terrorism hot spots: Identification and impact evaluation. Confl. Manag. Peace Sci. 2007, 24, 281–296. [Google Scholar] [CrossRef]
- Ratcliffe, J.H. The hotspot matrix: A framework for the spatio-temporal targeting of crime reduction. Police Pract. Res. 2004, 5, 5–23. [Google Scholar] [CrossRef]
- Anselin, L.; Griffiths, E.; Tita, G. Crime mapping and hot spot analysis. In Environmental Criminology and Crime Analysis; Routledge: Abingdon, UK, 2008; pp. 97–116. [Google Scholar]
- Townsley, M. Visualising space time patterns in crime: The hotspot plot. Crime Patterns Anal. 2008, 1, 61–74. [Google Scholar]
- García-Palomares, J.C.; Gutiérrez, J.; Mínguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Kent, J.D.; Capello, H.T., Jr. Spatial patterns and demographic indicators of effective social media content during theHorsethief Canyon fire of 2012. Cartogr. Geogr. Inf. Sci. 2013, 40, 78–89. [Google Scholar] [CrossRef]
- Malleson, N.; Andresen, M.A. The impact of using social media data in crime rate calculations: Shifting hot spots and changing spatial patterns. Cartogr. Geogr. Inf. Sci. 2015, 42, 112–121. [Google Scholar] [CrossRef]
- Houston, J.B.; Hawthorne, J.; Perreault, M.F.; Park, E.H.; Goldstein Hode, M.; Halliwell, M.R.; Turner McGowen, S.E.; Davis, R.; Vaid, S.; McElderry, J.A.; et al. Social media and disasters: A functional framework for social media use in disaster planning, response, and research. Disasters 2015, 39, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Middleton, S.E.; Middleton, L.; Modafferi, S. Real-time crisis mapping of natural disasters using social media. IEEE Intell. Syst. 2014, 29, 9–17. [Google Scholar] [CrossRef]
- De Albuquerque, J.P.; Herfort, B.; Brenning, A.; Zipf, A. A geographic approach for combining social media and authoritative data towards identifying useful information for disaster management. Int. J. Geogr. Inf. Sci. 2015, 29, 667–689. [Google Scholar] [CrossRef]
- Huang, Q.; Xiao, Y. Geographic situational awareness: Mining tweets for disaster preparedness, emergency response, impact, and recovery. ISPRS Int. J. Geo-Inf. 2015, 4, 1549–1568. [Google Scholar] [CrossRef]
- Schnebele, E.; Waters, N. Road assessment after flood events using non-authoritative data. Nat. Hazards Earth Syst. Sci. 2014, 14, 1007–1015. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Chae, J.; Thom, D.; Jang, Y.; Kim, S.; Ertl, T.; Ebert, D.S. Public behavior response analysis in disaster events utilizing visual analytics of microblog data. Comput. Graph. 2014, 38, 51–60. [Google Scholar] [CrossRef]
- Horita, F.E.A.; de Albuquerque, J.P.; Degrossi, L.C.; Mendiondo, E.M.; Ueyama, J. Development of a spatial decision support system for flood risk management in Brazil that combines volunteered geographic information with wireless sensor networks. Comput. Geosci. 2015, 80, 84–94. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, D.; Lu, G.; Ma, W.-Y. A survey of content-based image retrieval with high-level semantics. Pattern Recognit. 2007, 40, 262–282. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; M. Kaufmann Publishers: Burlington, MA, USA, 2012; pp. 1–9. [Google Scholar] [CrossRef]
- Steidl, M.; Riecks, D. IPTC Releases Results of 2016 Social Media Sites Photo Metadata Test. Available online: https://iptc.org/news/many-social-media-sites-still-remove-image-rights-information-from-photos/ (accessed on 18 September 2017).
- Serdyukov, P.; Murdock, V.; Van Zwol, R. Placing flickr photos on a map. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 484–491. [Google Scholar]
- Hays, J.; Efros, A.A. IM2GPS: Estimating geographic information from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Hauff, C.; Houben, G.-J. Geo-Location estimation of flickr images: Social web based enrichment. In Proceedings of the European Conference on Information Retrieval, Barcelona, Spain, 1–5 April 2012; pp. 85–96. [Google Scholar]
- Li, Y.; Crandall, D.J.; Huttenlocher, D.P. Landmark classification in large-scale image collections. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1957–1964. [Google Scholar]
- Francalanci, C.; Guglielmino, P.; Montalcini, M.; Scalia, G.; Pernici, B. IMEXT: A method and system to extract geolocated images from Tweets—Analysis of a case study. In Proceedings of the IEEE RCIS’17, Brighton, UK, 10–12 May 2017. [Google Scholar]
- Inkpen, D.; Liu, J.; Farzindar, A.; Kazemi, F.; Ghazi, D. Detecting and disambiguating locations mentioned in Twitter messages. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 321–332. [Google Scholar]
- Sagl, G.; Resch, B.; Blaschke, T. Contextual sensing: Integrating contextual information with human and technical geo-sensor information for smart cities. Sensors 2015, 15, 17013–17035. [Google Scholar] [CrossRef] [PubMed]
- Scalia, G. Network-Based Content Geolocation on Social Media for Emergency Management. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2017. [Google Scholar]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. “Structure-from-Motion” photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Modeling the world from internet photo collections. Int. J. Comput. Vis. 2008, 80, 189–210. [Google Scholar] [CrossRef]
- Agarwal, S.; Furukawa, Y.; Snavely, N.; Curless, B.; Seitz, S.M.; Szeliski, R. Reconstructing rome. Computer (Long Beach Calif.) 2010, 43, 40–47. [Google Scholar] [CrossRef]
- Steiger, E.; Westerholt, R.; Resch, B.; Zipf, A. Twitter as an indicator for whereabouts of people Correlating Twitter. Comput. Environ. Urban Syst. 2015, 54, 255–265. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartogr. Geogr. Inf. Sci. 2017, 1–15. [Google Scholar] [CrossRef]
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Porter, M.F. Snowball: A Language for Stemming Algorithms. Available online: http://snowball.tartarus.org/texts/introduction.html (accessed on 19 September 2017).
- Steyvers, M.; Griffiths, T. Probabilistic topic models. In Handbook of Latent Semantic Analysis; Psychology Press: Hove, UK, 2007; Volume 427, pp. 424–440. [Google Scholar]
- Hollink, V.; Kamps, J.; Monz, C.; de Rijke, M. Monolingual document retrieval for European languages. Inf. Retr. 2004, 7, 33–52. [Google Scholar] [CrossRef]
- Wallach, H.M.; Mimno, D.; Mccallum, A. Rethinking LDA: Why priors matter. In Advances in Neural Information Processing Systems; M. Kaufmann Publishers: Burlington, MA, USA, 2009; Volume 22, pp. 1973–1981. [Google Scholar] [CrossRef]
- Olteanu, A.; Castillo, C.; Diaz, F.; Vieweg, S. CrisisLex: A lexicon for collecting and filtering microblogged communications in crises. In Proceedings of the 8th International Conference Weblogs Social Media, Ann Arbor, MI, USA, 1–4 June 2014; p. 376. [Google Scholar]
- Hu, Y.; Boyd-Graber, J.; Satinoff, B. Interactive topic modeling. Mach. Learn. 2014, 95, 423–469. [Google Scholar] [CrossRef]
- Wang, S.; Chen, Z.; Fei, G.; Liu, B.; Emery, S. Targeted Topic Modeling for Focused Analysis. In Proceedings of the 22nd ACM Conference on Knowledge Discovery and Data Mining—KDD ‘16, San Francisco, CA, USA, 13–17 August 2016; pp. 1235–1244. [Google Scholar] [CrossRef]
- Wallach, H.M.; Murray, I.; Salakhutdinov, R.; Mimno, D. Evaluation Methods for Topic Models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1105–1112. [Google Scholar] [CrossRef]
- Newman, D.; Lau, J.; Grieser, K.; Baldwin, T. Automatic evaluation of topic coherence. Poceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 1–6 June 2010; pp. 100–108. [Google Scholar]
- Chang, J.; Gerrish, S.; Wang, C.; Blei, D.M. Reading tea leaves: How humans interpret topic models. In Proceedings of the 23rd Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6 December 2010; pp. 288–296. [Google Scholar]
- Lau, J.H.; Newman, D.; Baldwin, T. Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. Poceedings of the EACL, Gothenburg, Sweden, 26–30 April 2014; pp. 530–539. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The stanford corenlp natural language processing toolkit. Poceedings of the ACL (System Demonstrations), Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Al-Rfou, R.; Kulkarni, V.; Perozzi, B.; Skiena, S. Polyglot-NER: Massive multilingual named entity recognition. In Proceedings of the 2015 SIAM International Conference on Data Mining, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 586–594. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Tweet analysis for real-time event detection and earthquake reporting system development. IEEE Trans. Knowl. Data Eng. 2013, 25, 919–931. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- GeoNames. Available online: http://www.geonames.org/ (accessed on 19 September 2017).
- Castillo, C. Big Crisis Data: Social Media in DISASTERs and Time-Critical Situations; Cambridge University Press: New York, NY, USA, 2016. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Resch, B.; Wohlfahrt, R.; Wosniok, C. Web-based 4D visualization of marine geo-data using WebGL. Cartogr. Geogr. Inf. Sci. 2014, 41, 235–247. [Google Scholar] [CrossRef]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. IT enabled crowds: Leveraging the geomobile revolution for disaster management. In Proceedings of the Sintelnet WG5 Workshop on Crowd Intelligence: Foundations, Methods and Practices, Barcelona, Spain, 8–9 January 2014; pp. 16–23. [Google Scholar]
- Geotag-X. Available online: https://geotagx.org/ (accessed on 20 September 2017).
- Schneider, D.; Fernandez-Marquez, J.L.; Da Costa, J. Data analytics in citizen cyberscience: Evaluating participant learning and engagement with analytics. Hum. Comput. 2016, 3, 69–97. [Google Scholar]
- Citizen Cyberlab. Available online: http://archive.citizencyberlab.org/ (accessed on 20 September 2017).
- OSM Tasking Manager. Available online: http://tasks.hotosm.org/ (accessed on 20 September 2017).
- Brugghemans, B.; Van Achte, T. Crisis Intelligence Manual. Available online: http://crisisintelligence.org (accessed on 20 September 2017).
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Lewis, D.D. Evaluating and optimizing autonomous text classification systems. In Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 9–13 July 1995; pp. 246–254. [Google Scholar]
- GovEd Ltd. Crowd4S. Available online: http://www.crowd4sat.org/ (accessed on 29 September 2017).
- Ord, J.K.; Getis, A. Local spatial autocorrelation statistics: Distributional issues and an application. Geogr. Anal. 1995, 27, 286–306. [Google Scholar] [CrossRef]
- Haiti: Hurricane Matthew—Situation Report No. 10 (14 October 2016). Available online: http://reliefweb.int/report/haiti/haiti-hurricane-matthew-situation-report-no-10-14-october-2016 (accessed on 19 September 2017).
- Haiti: Hurricane Matthew—Situation Report No. 17 (28 October 2016). Available online: https://reliefweb.int/report/haiti/haiti-hurricane-matthew-situation-report-no-17-28-october-2016 (accessed on 19 September 2017).
- EMSR185: Tropical Cyclone in Haiti. Available online: http://emergency.copernicus.eu/mapping/list-of-components/EMSR185 (accessed on 19 September 2017).
- Copernicus—The European Earth Observation Programme EMSR185: Tropical cyclone in Haiti–Jeremie. Available online: http://emergency.copernicus.eu/mapping/list-of-components/EMSR185/ALL/EMSR185_11JEREMIE (accessed on 19 September 2017).
- Sui, D.; Goodchild, M. The convergence of GIS and social media: Challenges for GIScience. Int. J. Geogr. Inf. Sci. 2011, 25, 1737–1748. [Google Scholar] [CrossRef]
- Steiger, E.; Resch, B.; Zipf, A. Exploration of spatiotemporal and semantic clusters of Twitter data using unsupervised neural networks. Int. J. Geogr. Inf. Sci. 2016, 30, 1694–1716. [Google Scholar] [CrossRef]
- Resch, B. People as sensors and collective sensing-contextual observations complementing geo-sensor network measurements. In Progress in Location-Based Services; Springer: Berlin, Germany, 2013; pp. 391–406. [Google Scholar]
- Leson, H. How Is Social Media Helping Disaster Response? Available online: https://www.weforum.org/agenda/2016/04/how-is-social-media-helping-disaster-response/ (accessed on 28 September 2017).
- Phillips, J.; Verity, A. Guidance for Developing a Local Digital Response Network. Available online: http://thegovlab.org/guidance-for-developing-a-local-digital-response-network/ (accessed on 28 August 2017).
- Capelo, L.; Chang, N.; Verity, A. Guidance for Collaborating with Volunteer and Technical Communities. Available online: http://digitalhumanitarians.com/content/guidance-collaborating-volunteer-technical-communities (accessed on 28 September 2017).
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2017, 31, 139–167. [Google Scholar] [CrossRef]
- Antoniou, V.; Skopeliti, A. Measures and indicators of VGI quality: An overview. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 1, 345–351. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Bird, T.J.; Bates, A.E.; Lefcheck, J.S.; Hill, N.A.; Thomson, R.J.; Edgar, G.J.; Stuart-Smith, R.D.; Wotherspoon, S.; Krkosek, M.; Stuart-Smith, J.F.; et al. Statistical solutions for error and bias in global citizen science datasets. Biol. Conserv. 2014, 173, 144–154. [Google Scholar] [CrossRef]
- Bonney, R.; Shirk, J.L.; Phillips, T.B.; Wiggins, A.; Ballard, H.L.; Miller-Rushing, A.J.; Parrish, J.K. Next steps for citizen science. Science 2014, 343, 1436–1437. [Google Scholar] [CrossRef] [PubMed]
- Tulloch, A.I.T.; Possingham, H.P.; Joseph, L.N.; Szabo, J.; Martin, T.G. Realising the full potential of citizen science monitoring programs. Biol. Conserv. 2013, 165, 128–138. [Google Scholar] [CrossRef]
- Bonter, D.N.; Cooper, C.B. Data validation in citizen science: A case study from Project FeederWatch. Front. Ecol. Environ. 2012, 10, 305–307. [Google Scholar] [CrossRef]
- Dickinson, J.L.; Zuckerberg, B.; Bonter, D.N. Citizen science as an ecological research tool: Challenges and benefits. Annu. Rev. Ecol. Evol. Syst. 2010, 41, 149–172. [Google Scholar] [CrossRef]
- Silvertown, J. A new dawn for citizen science. Trends Ecol. Evol. 2009, 24, 467–471. [Google Scholar] [CrossRef] [PubMed]
- Holt, B.G.; Rioja-Nieto, R.; Aaron MacNeil, M.; Lupton, J.; Rahbek, C. Comparing diversity data collected using a protocol designed for volunteers with results from a professional alternative. Methods Ecol. Evol. 2013, 4, 383–392. [Google Scholar] [CrossRef]
- Trumbull, D.J.; Bonney, R.; Bascom, D.; Cabral, A. Thinking scientifically during participation in a citizen-science project. Sci. Educ. 2000, 84, 265–275. [Google Scholar] [CrossRef]
- Gouveia, C.; Fonseca, A.; Câmara, A.; Ferreira, F. Promoting the use of environmental data collected by concerned citizens through information and communication technologies. J. Environ. Manag. 2004, 71, 135–154. [Google Scholar] [CrossRef] [PubMed]
- Gillett, D.J.; Pondella, D.J.; Freiwald, J.; Schiff, K.C.; Caselle, J.E.; Shuman, C.; Weisberg, S.B. Comparing volunteer and professionally collected monitoring data from the rocky subtidal reefs of Southern California, USA. Environ. Monit. Assess. 2012, 184, 3239–3257. [Google Scholar] [CrossRef] [PubMed]
- Jordan, R.C.; Brooks, W.R.; Howe, D.V.; Ehrenfeld, J.G. Evaluating the performance of volunteers in mapping invasive plants in public conservation lands. Environ. Manag. 2012, 49, 425–434. [Google Scholar] [CrossRef] [PubMed]
- Yanenko, O.; Schlieder, C. Game principles for enhancing the quality of user-generated data collections. In Proceedings of the AGILE on Workshop Geogames Geoplay, Castellón, Spain, 3 June 2014; pp. 1–5. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location Precision | Value |
|---|---|
| Street level or exact position of POI | 1 |
| Georeferenced social media post | 0.7 |
| Locality level | 0.67 |
| Trust of Source | Value |
|---|---|
| Public officer | 1 |
| Newspaper or journalist | 0.8 |
| Any user | 0.6 |
| Usefulness | Value |
|---|---|
| Possibly useful (even if not certain) | 1 |
| Not useful | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Havas, C.; Resch, B.; Francalanci, C.; Pernici, B.; Scalia, G.; Fernandez-Marquez, J.L.; Van Achte, T.; Zeug, G.; Mondardini, M.R.; Grandoni, D.; et al. E2mC: Improving Emergency Management Service Practice through Social Media and Crowdsourcing Analysis in Near Real Time. Sensors 2017, 17, 2766. https://doi.org/10.3390/s17122766
Havas C, Resch B, Francalanci C, Pernici B, Scalia G, Fernandez-Marquez JL, Van Achte T, Zeug G, Mondardini MR, Grandoni D, et al. E2mC: Improving Emergency Management Service Practice through Social Media and Crowdsourcing Analysis in Near Real Time. Sensors. 2017; 17(12):2766. https://doi.org/10.3390/s17122766
Chicago/Turabian StyleHavas, Clemens, Bernd Resch, Chiara Francalanci, Barbara Pernici, Gabriele Scalia, Jose Luis Fernandez-Marquez, Tim Van Achte, Gunter Zeug, Maria Rosa (Rosy) Mondardini, Domenico Grandoni, and et al. 2017. "E2mC: Improving Emergency Management Service Practice through Social Media and Crowdsourcing Analysis in Near Real Time" Sensors 17, no. 12: 2766. https://doi.org/10.3390/s17122766
APA StyleHavas, C., Resch, B., Francalanci, C., Pernici, B., Scalia, G., Fernandez-Marquez, J. L., Van Achte, T., Zeug, G., Mondardini, M. R., Grandoni, D., Kirsch, B., Kalas, M., Lorini, V., & Rüping, S. (2017). E2mC: Improving Emergency Management Service Practice through Social Media and Crowdsourcing Analysis in Near Real Time. Sensors, 17(12), 2766. https://doi.org/10.3390/s17122766