1. Introduction
The ultimate goal of sign language recognition (SLR) is to translate sign language into text or speech so as to promote the basic communication between the deaf and hearing society [
1,
2,
3,
4]. SLR can reduce the communication barrier between the deaf and hearing society, and it also plays an important role in the application of human-computer interaction systems [
5,
6] such as the controlling of a gesture-based handwritten pen, computer games, and robots in a virtual environment [
7].
Datagloves and computer vision sensors are the two main sensing technologies for gesture information collection, and SLR research based on these two technologies have been investigated widely. For instance, Francesco Camastra
et al. presented a dataglove-based real-time hand gesture recognition system and recognition rate larger than 99% was obtained in the classification of 3900 hand gestures [
8]. Dong
et al. realized American Sign Language (ASL) alphabet recognition using a depth camera and achieved the accuracy higher than 90% in the recognition of 24 static ASL alphabet signs [
9]. The disadvantage of dataglove-based SLR is that the cumbersome and expensive dataglove must be worn to capture hand gesture information and the user’s freedom of movement is greatly limited [
8,
10]. For computer vision-based SLR, some environmental factors, such as the background lighting and color, affect the recognition performance significantly [
9].
Wearable sensors including surface electromyographic (sEMG) sensors, accelerometers (ACC), and gyroscopes (GYRO) provide alternative portable and low cost sensing technologies for the realization of SLR [
11]. The sEMG can detect muscle activity patterns during the execution of hand gestures in a non-intrusive manner [
12,
13,
14]. ACC can capture the kinematic information associated with hand and arm movement based on the measurement of acceleration and orientation with respect to gravity [
15,
16]. GYRO is helpful in capturing the complementary angular velocity information of forearm rotation during hand gesture implementation. Several promising results have been obtained in the SLR based on the isolated and various combinations of sEMG, ACC, and GYRO. For instance, Li
et al. achieved 95.8% average accuracy on the recognition of 121 CSL words based on the combination of sEMG and ACC signals [
16]. Kosmidou
et al. proposed a SLR scheme based on the application of the sEMG and 3-D ACC data and a high mean recognition accuracy (>93%) was obtained in the recognition of 60 isolated Greek sign language signs [
17]. Wu
et al. presented a real-time American SLR system integrated with surface electromyography (sEMG) and a wrist-worn inertial sensor at the feature level and achieved a 95.94% recognition rate for 40 most commonly used words [
18]. Hoffman
et al. proposed a framework based on accelerometer and gyroscope sensors and recognized up to 25 gestures at over 90% accuracy with 15 training samples per gesture and up to 20 gestures at over 90% accuracy with only five training samples per gesture [
19].
Although the SLR research based on sEMG and inertial sensors mentioned above have achieved relatively good progress, this technology still has large distance from practical application. On the one hand, the size of recognizable gesture set is quite limited compared with the quantity of CSL which contains more than five thousand sign words [
1]. To enlarge the recognizable gesture set, a more advanced algorithm framework should be explored. On the other hand, the burden of training on user, which increases when the vocabulary gets larger, hinders the general application of SLR technology. Therefore, it is quite significant to explore an extensible SLR method under the condition of acceptable training burden.
Generally, gestures consist of some basic components including hand shape, location, orientation, trajectory,
etc. Since most gestures share some specific and visible components [
13,
20], a component-based approach provides feasible solutions to the recognition of large-scale gesture set. It can not only enhance the efficiency of recognition algorithm by transforming large-scale gesture set into small-scale component set, but also can pave the way to reduce the users’ training burden because only the training of components other than all gestures is needed. Component-based methods have been proposed and proven to be effective to enlarge the recognizable gesture set in related studies [
13,
16]. Based on Cybergloves, Fang
et al. proposed the concept “subwords” in [
21]. They divided signs into several segments as subwords, and 238 subwords were extracted from 5113 signs as the basic units for large vocabulary CSL recognition. Wang
et al. proposed “phoneme” of CSL, just like Bopomofo in the Chinese language, and divided the signs into the individual phonemes and trained phoneme hidden Markov models (HMMs) for the realization of large vocabulary CSL recognition [
22]. In our previous study [
16], an automatic CSL recognition framework at the component level was proposed and was proven to be effective for the recognition of 121 gestures. However, the training samples were collected at the gesture level and the problem of the training burden was not considered.
This paper aims to propose a vocabulary extensible component-based SLR framework based on data from sEMG sensor and inertial sensors, including accelerometer and gyroscope. In the proposed framework, a sign gesture is recognized based on common components, so the users’ training burden can be truly reduced by only training components other than gestures.
2. Methods
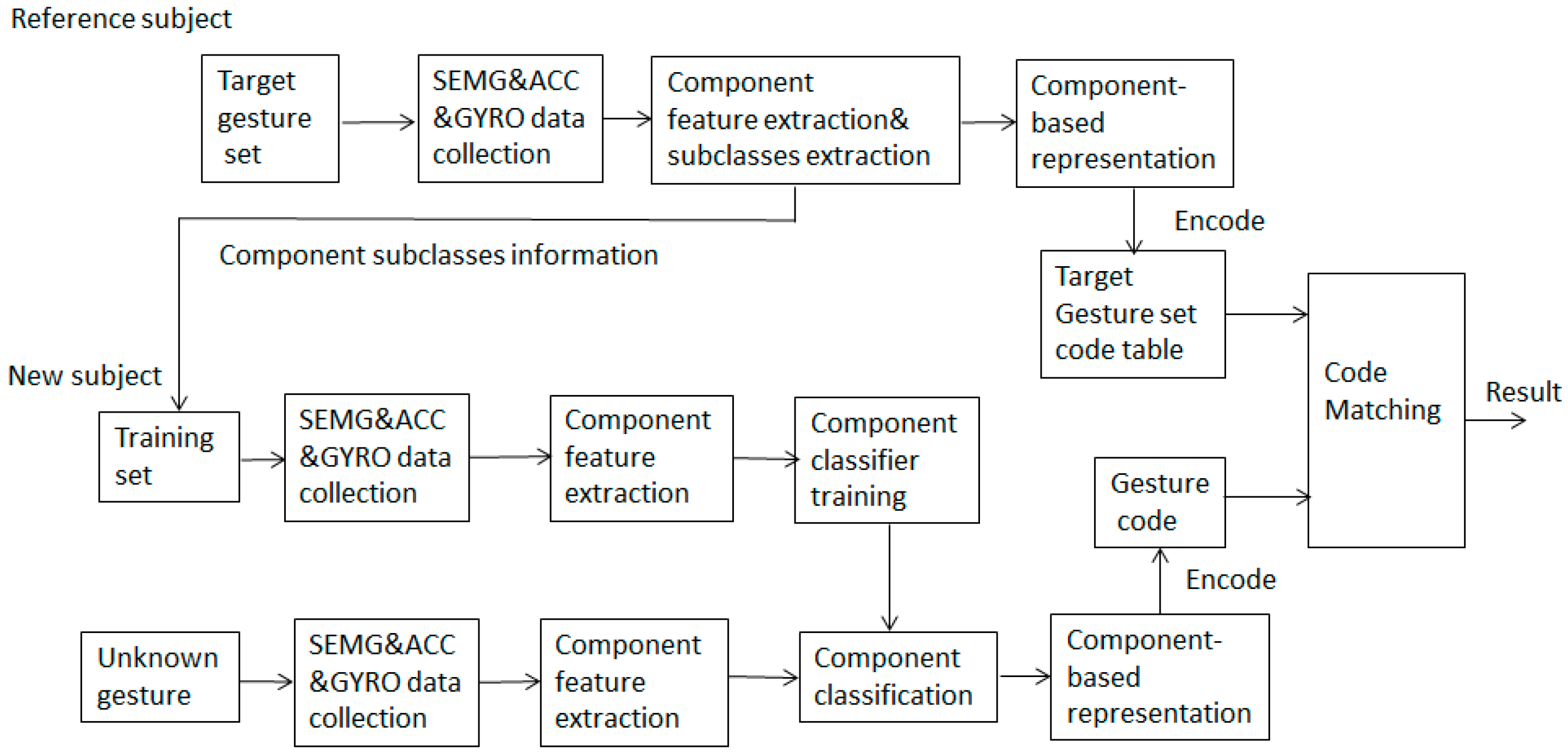
In this study, sign gesture classification is based on the recognition of five common components, including hand shape, axis, orientation, rotation, and trajectory by means of sEMG, ACC, and GYRO data. As shown in
Figure 1, the proposed SLR framework consists of two major parts. The first part is to obtain the component-based representation of sign gestures and the code table of a target sign gesture set using the data from a reference subject. In the second part, which is designed for new users, the component classifiers are trained using the training set suggested by the reference subject and the classification of unknown gestures is performed with a code matching method. The extendibility of the scheme is that, for new user, the recognition of a large-scale gesture set can be implemented based on the small-scale training set which contains all component subclasses. In order to realize the real vocabulary extensible sign gesture recognition, how to transfer a gesture into its component-based form and how to obtain the gesture code are two key problems of the proposed method.
2.1. Sign Gesture Data Collection
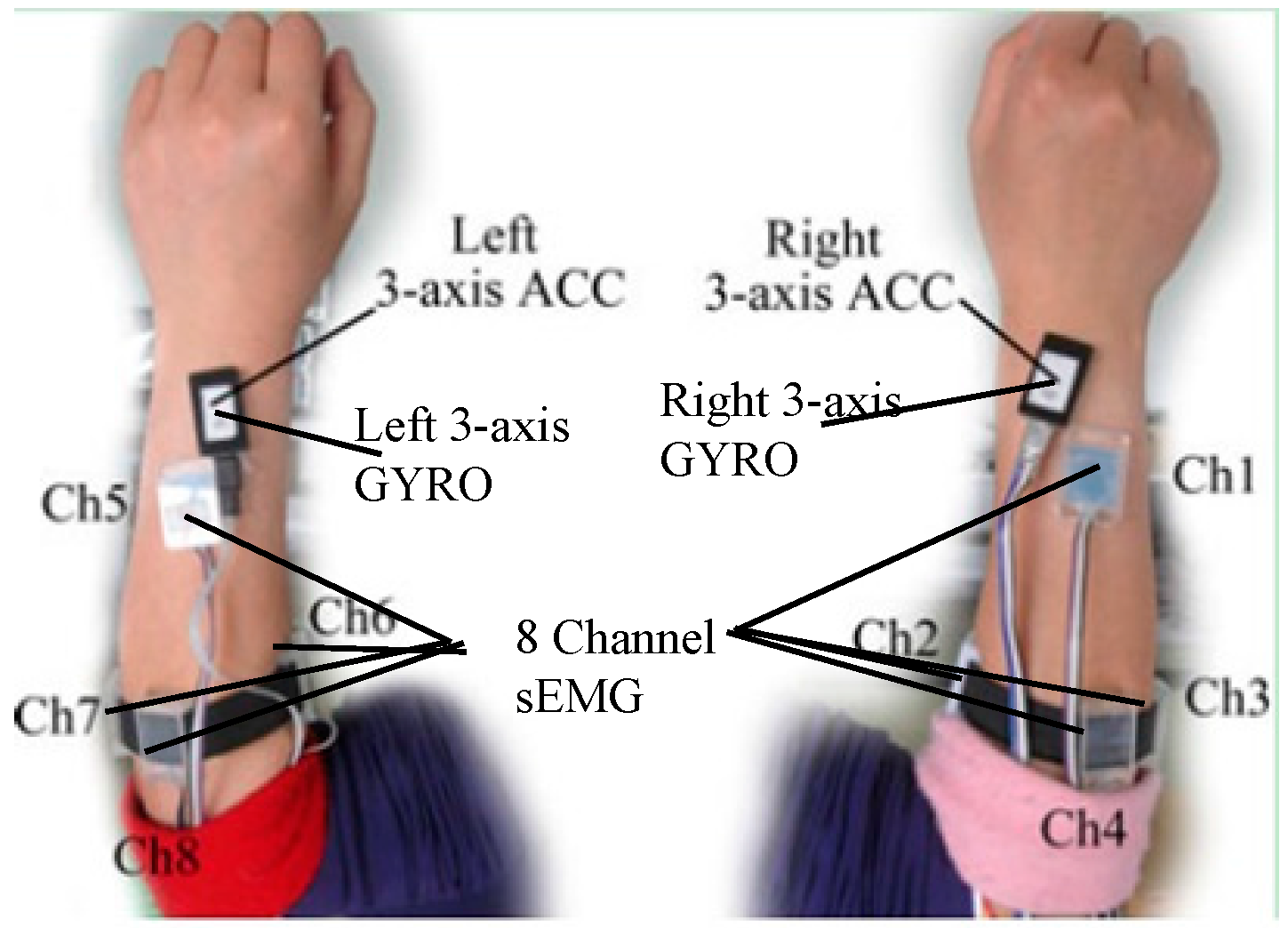
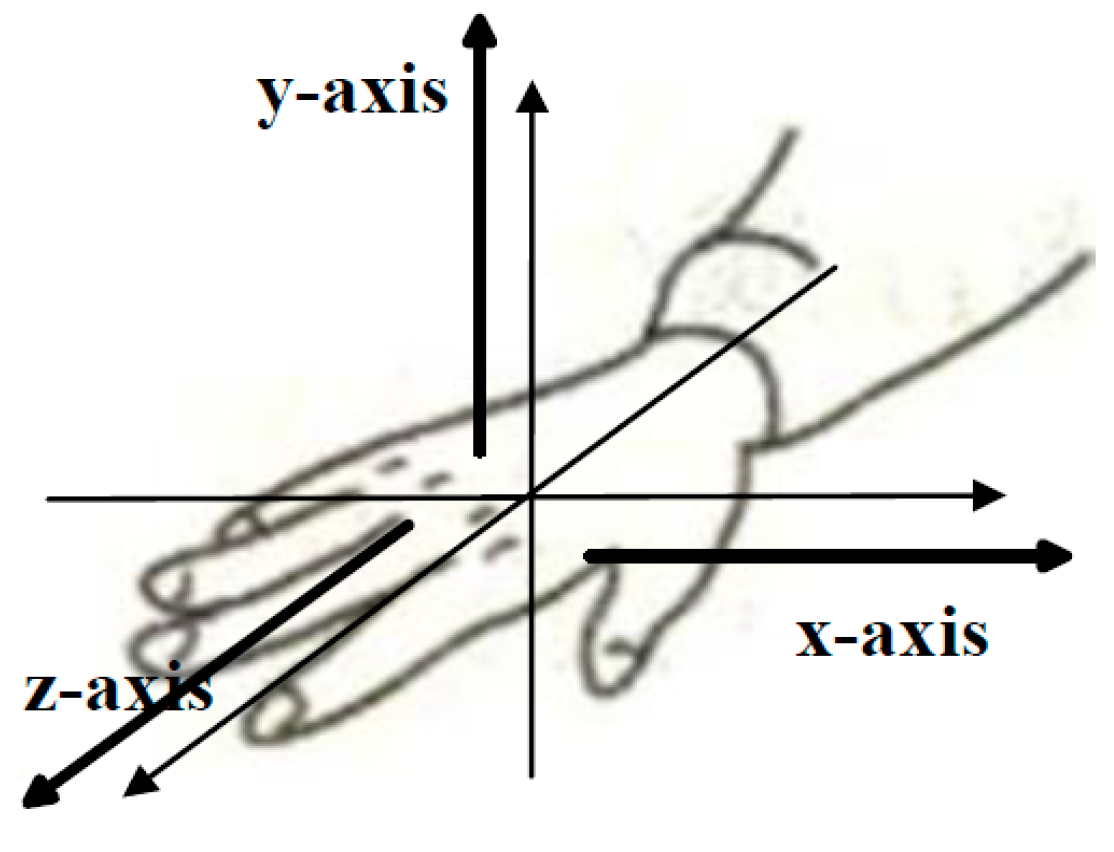
A self-made data collection system consisting of two wristbands worn on the left and right forearm, respectively, was used to capture sign gesture. Each wristband consists of four sEMG sensors and an inertial module made up of a 3-D accelerometer and 3-D gyroscope. As
Figure 2 shows, the inertial module was placed on the back of the forearm near to the wrist. The first channel sEMG was suggested to be placed near the inertial module. The remaining three channel sEMG were located near the elbow in a band form. The arrangement of the sEMG sensors and inertial module in the left hand was symmetric with those in the right hand. The sEMG signals were digitalized at a 1000 Hz sampling rate, and ACC and GYRO signals at a 100 Hz sampling rate. All of the digitalized signals were sent to a computer via Bluetooth in text form and saved for offline analysis.
2.2. Component-Based Sign Gesture Representation
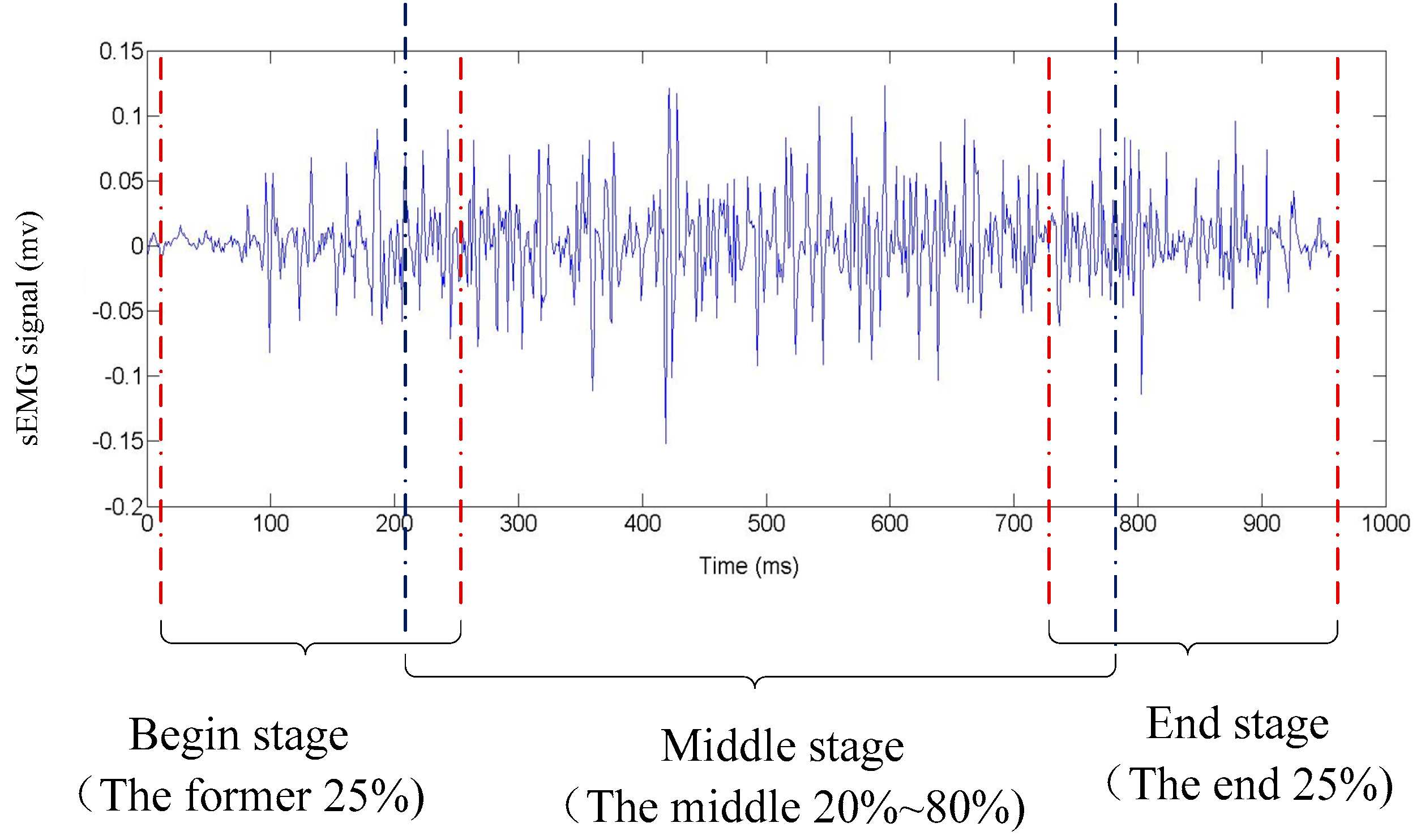
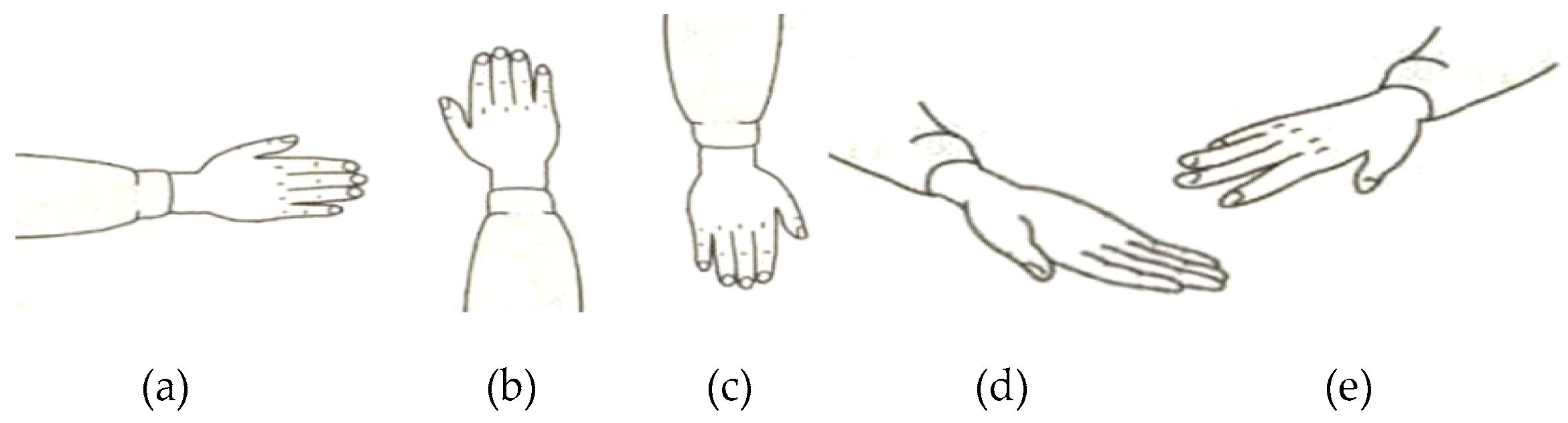
Five common sign components including hand shape, orientation, axis, rotation, and trajectory were considered in this study. As we know, the components usually change during the execution of a gesture. Take the sign word “object” as an example; the component of hand shape changes from hand clenched to index finger extension then to palm extension as shown in
Figure 3. In order to capture the changes of components during the execution precisely, the beginning stage, middle stage, and end stages of a gesture was considered separately. As shown in
Table 1, the component-based representation of a sign gesture was the component combination of the three stages.
, and
represented the handshape of the beginning stage, the middle stage, and the end stage, respectively and formed the handshape component of gesture. Similarly, orientation, axis, and rotation components also consisted of three elements (
for orientation;
for axis;
for rotation). Since the trajectory is usually continuous during a gesture execution, only one element
was used to represent the trajectory component.
2.3. Component Feature Extraction and the Determination of the Component Subclasses
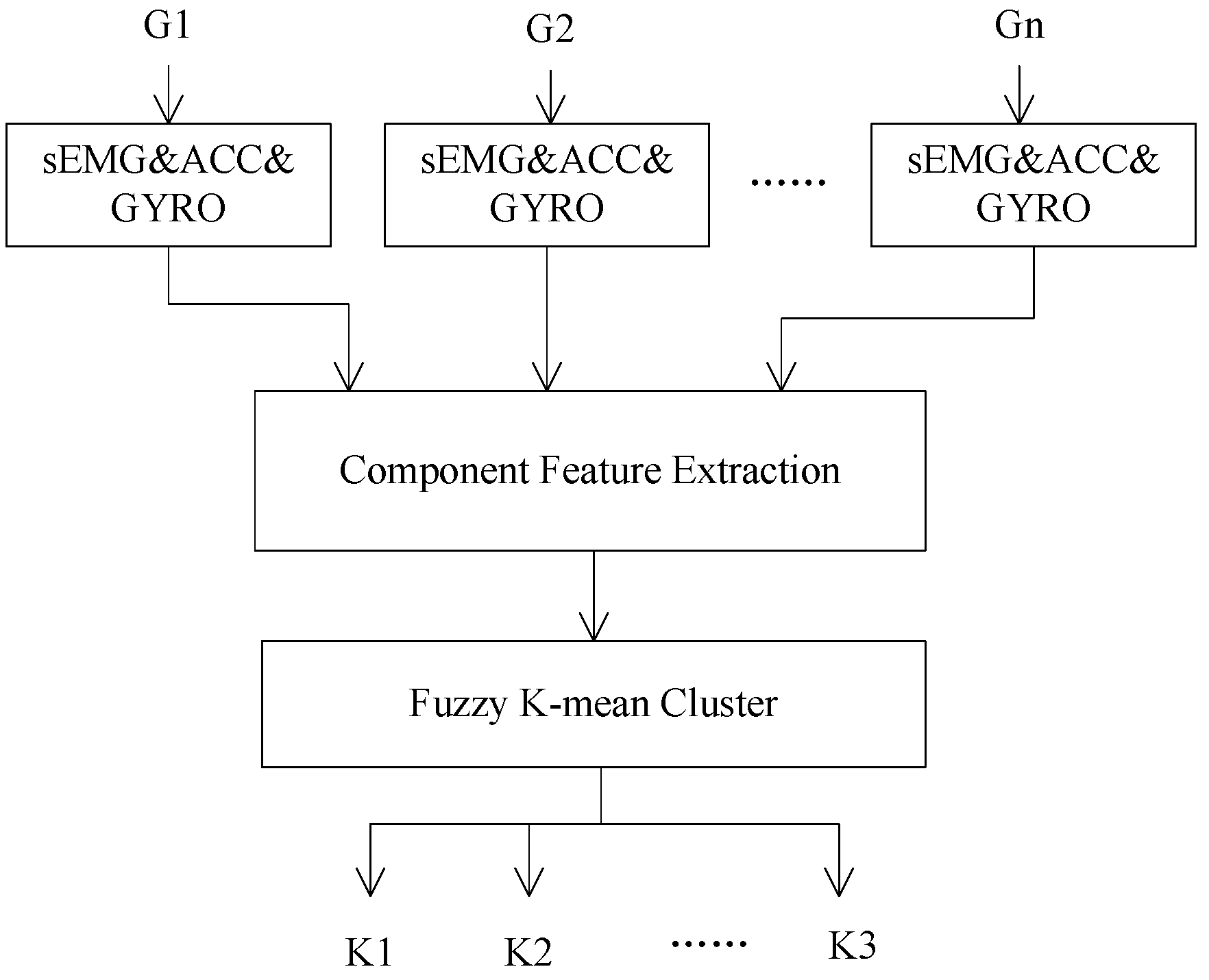
Generally, the subclasses of each component vary with the target sign gesture set. In this study, the subclasses of components relative to the target sign gesture set were determined based on the data analysis of a reference subject who can execute sign gesture in a normative way.
Figure 4 gives the extraction process of component subclasses. For a given target sign gesture set G = [G
1,G
2,…,G
n], sEMG, ACC, and GYRO data of all sign gestures were collected firstly, then the features of each component were extracted and a set of typical subclasses was determined by a fuzzy K-mean algorithm [
23]. In practice, an approximate number of clusters was firstly determined based on the analysis of the general features of each component in the target gesture set. After the clustering process, the clusters which contain too few gestures were discarded and the clusters whose centers were close to each other were merged together.
2.3.1. Handshape Component Feature
Hand shape is the hand configurations describing the state of hand palm, wrist, and finger in the execution of sign words. In this study, handshape features extraction was based on sEMG data. Mean absolute values (MAV), an Auto regressive (AR) model coefficients, zero crossing (ZC), slop sign change (SSC), and waveform length (WL), defined as Equations (1)–(5) and considered to be effective in representing the patterns of sEMG [
24], were adopted:
where
is the
kth coefficient and
p denotes the order of AR model.
where
N is the length of the signal
x, and the threshold is defined as 0.05 × std(
x).
The overlapped windowing technique [
25] was utilized to divide a gesture action sEMG signal into several frames with a fixed window length and increment size. For each frame, a 32-dimensional feature vector consisting of MAV, the coefficients of fourth-order AR model, ZC, SSC, and WL of four channel sEMG was calculated. In the classifier training phase, the feature vectors were used as the input of hand shape classifier. As mentioned above, the handshape feature samples of the beginning stage, the middle, and the end stage of a gesture action were calculated, respectively.
2.3.2. Axis Component Feature
Axis component reflects the forearm’s moving direction. Generally, if the forearm moves along x-axis strictly, the standard deviation (STD) of the x-axis ACC signal will be obviously higher than that of the y-axis and the z-axis. Thus, the STD value can represent the axis information effectively. However, because the actual moving direction of forearm is usually deviated from the standard axis, it is difficult to discriminate the axis component only based on the STD feature. Therefore, the correlation coefficient (
r value) between two different axes was calculated (as Equation (6)) and adopted additionally. In total, a six-dimension vector including three STDs and three
r values was selected as the axis component feature.
where
represent the three-axis ACC signal.
2.3.3. Orientation Component Feature
Hand orientation refers to the direction toward which the hand is pointing or the palm is facing [
16]. The mean value of the three-axis ACC signals were calculated and adopted as the orientation feature vector.
2.3.4. Rotation Component Feature
The rotation component describes the rotation direction of the forearm and three-axis GYRO signals can reflect the angular velocity information of the hand rotation directly. The features utilized to characterize the rotation component were the same as those of the axis component and the calculation approach is shown in Equation (6).
2.3.5. Trajectory Component Feature
The trajectory component describes the moving trajectory of hand which can be captured by ACC and GYRO signals. The three-axis ACC and GYRO time-series signals were linearly extrapolated to 64-point sequences along the time axis to form the feature vector of the trajectory component.
2.4. Establishment of the Code Table of a Target Sign Gesture Set
When the subclasses of each component is determined, the sign gesture can be described as the component-based representation, as
Table 1 shows. For a component with
n subclasses, the code of the
ith (
) subclass was defined to a binary string of length
n with the
ith bit set to 1 and the other bits to 0. In gesture encoding step, each gesture in the target sign gesture set is represented by the binary string combination of all elements (each corresponding to a component subclass). Suppose there are 11 subclasses for handshape, five subclasses for orientation, three classes for axes, three subclasses for rotation, and 13 subclasses for trajectory,
Table 2 gives an example of gesture encoding procedure. For the gesture whose component-based representation is {4,4,5,5,1,4,2,2,2,3,3,3,12}, the gesture code is binary string {00010000000 00010000000 00001000000 00001 10000 00010 010 010 010 001 001 001 0000000000010}. For a given target sign gesture set G = [G
1,G
2,…,G
n], when all gestures are encoded, the code table C = [C
1,C
2,…,C
n] is obtained.
2.5. Component Classifier
A hidden Markov model (HMM) was chosen as the handshape classifier as it is a powerful tool for modeling sequential data. For the
ith handshape subclass (1 <
i <
m), the sEMG feature vectors of training samples were used to train a HMM model denoted as
. The single-stream model was designed as a continuous HMM with five states and three Gaussian mixture components per state. In the testing phase, the likelihood
Pi of the observation
belonging to the
ith subclass was calculated as Equation (7) using the forward-backward algorithm [
26], and the recognition result was the class whose HMM achieved the highest likelihood.
Based on the samples of typical orientation subclasses, Gaussian distribution was utilized to model each orientation subclass as it has been proved to be an effective model in our pilot study [
16].
As shown in Equation (9), means the probability of the test sample O belonging to the multivariate Gaussian distribution Oi with a mean vector and covariance matrix . The parameters and were estimated based on the training samples of the ith orientation subclass. The final recognition result was assigned as the class with the highest likelihood.
The same classification procedure was applied for the other three components. The classifier of the trajectory component was the same as the hand shape component and the classifiers of the axis and rotation components were the same as the orientation component.
2.6. The Training of Component Classifiers and Classification of Unknown Gesture
The training set of component classifiers was determined based on the component subclasses extracted from the reference subject. For each component, sign gestures covering typical component subclasses was selected from the target set
G to compose component training set. Five component training sets, denoted as
respectively, were acquired based on the analysis of the reference subject. The whole gesture training set
T was defined as the combination of the five isolated component training sets, as shown in Equation (10). Since a certain gesture may contain several typical hand components, the size of the gesture training set
T maybe less than the sum of the five isolated training sets as Equation (11) shows:
For a new user, component classifiers were trained with their own data. For each training sample, stage segmentation and component feature extraction were implemented, as mentioned in
Section 2.2 and
Section 2.3, respectively. The handshape classifier was trained based on the feature vectors
and the other component classifiers were trained using a similar procedure as the handshape classifier. The left and right hand component classifiers were trained independently on the feature vectors from the corresponding hand. For one-handed sign gestures, only the right hand component classifiers were trained. For two-handed sign words, both right and left hands were trained.
With the trained component classifiers, the classification of an unknown gesture sample can be implemented according to the following steps:
Step 1: Divides the test sample into three stages and extracts the component features of each stage.
Step 2: Sends the features to the corresponding component classifier to get the component-based representation (as shown in
Table 1).
Step 3: Transfers the component-based representation to a gesture code x. As mentioned above, the components classifiers were trained with the training set recommended by the reference subject. However, it is common sense that there exist individual differences in users’ executive habits, which can usually make the subclasses of a sign component of new user are not exactly the same as the reference subject. Considering the deformations among users, a special gesture encoding processing is recommended. For each element of the component-based representation of the unknown sample, bits corresponding to the subclasses which obtain the maximal and submaximal probabilities are set to 1 together, which is a little different from the encoding method used in establishing the target sign gesture set code table.
Step 4: Matches the gesture code
x with the target sign gesture set code table to classify the test sample. As Equation (12) shows, the final classification result is assigned as the sign word
c* with the highest matching scores.
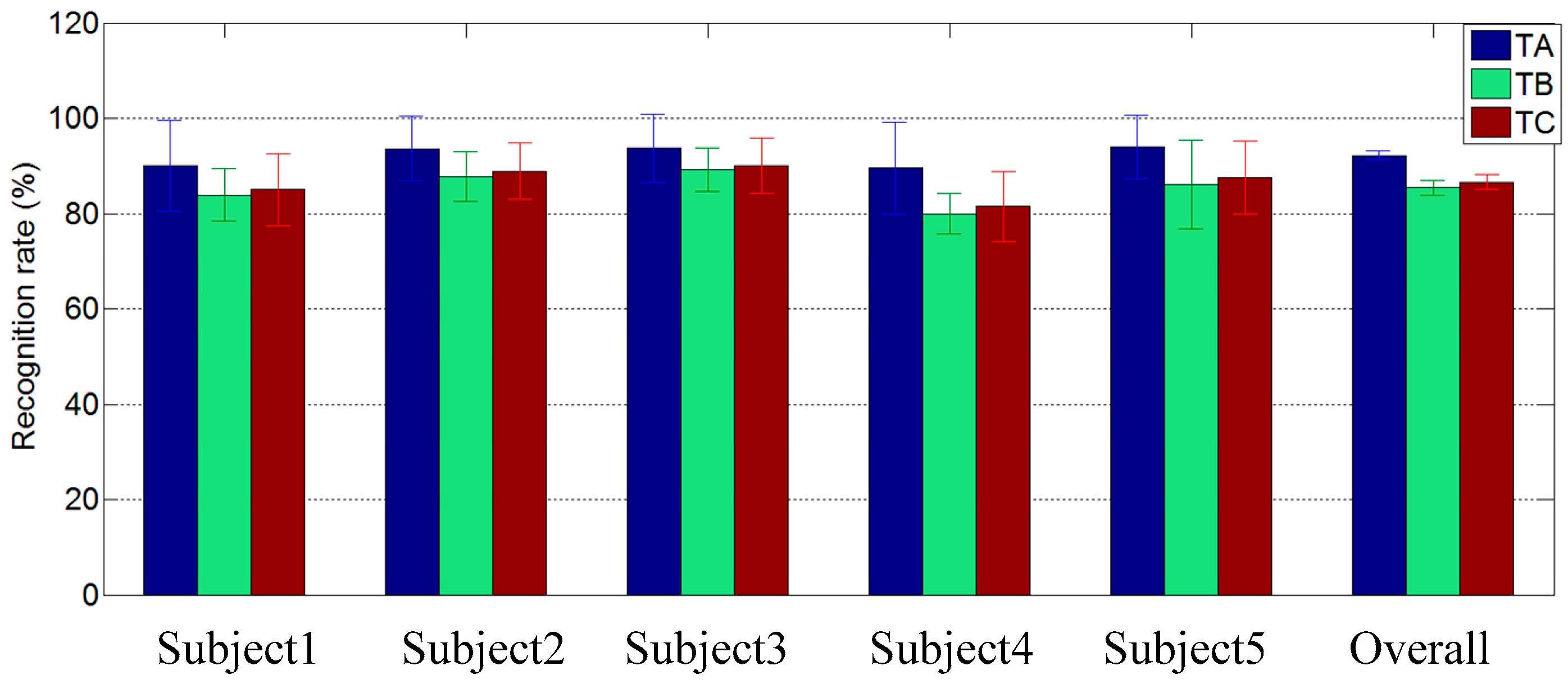
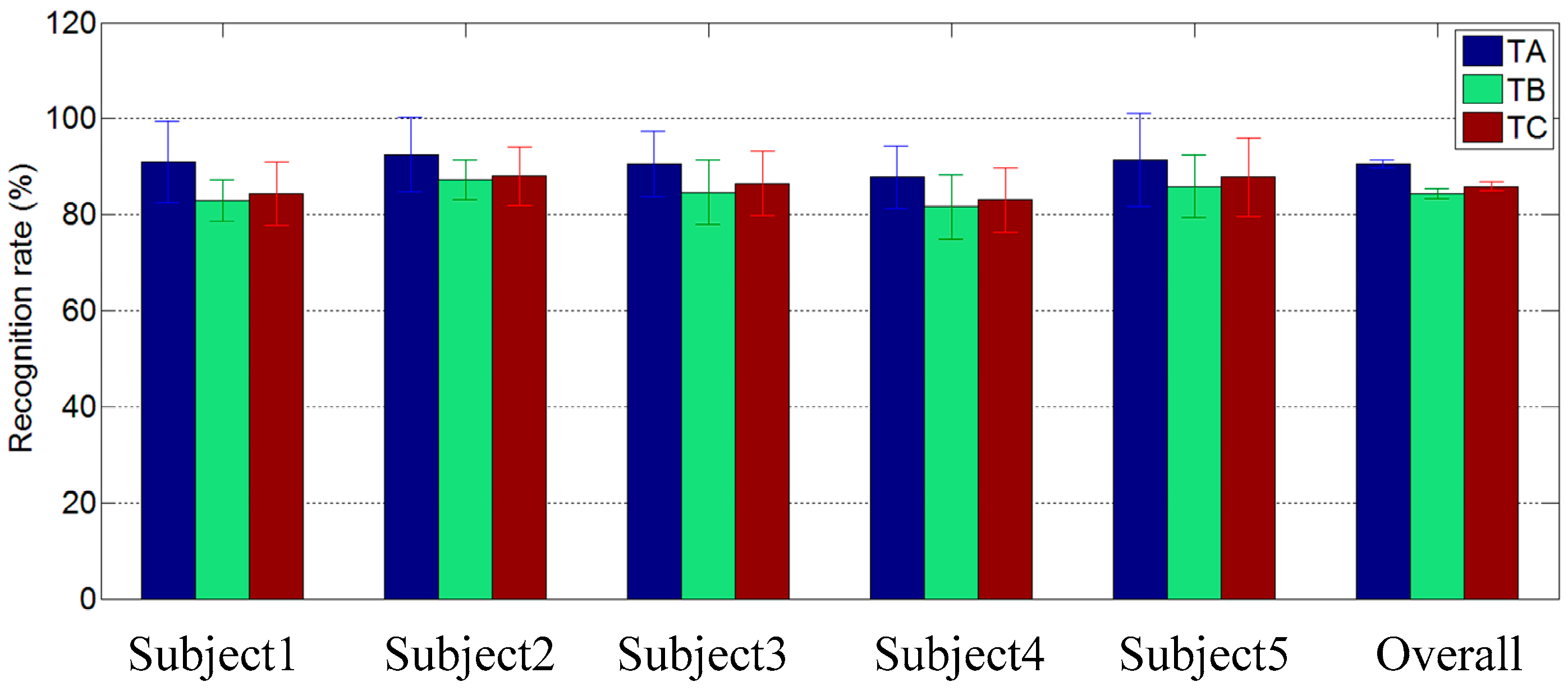
4. Discussion and Future Work
Sign component is not a novel concept and has been involved in several related SLR studies. In our previous work, Li
et al. proposed a sign-component-based framework for CSL recognition using ACC and sEMG data and achieved a 96.5% recognition rate for a vocabulary of 121 sign words [
16]. However, the concept of sign component was only utilized to improve the accuracy of large-vocabulary gesture recognition in their study, the extensibility of component-based method was not considered at all, and the training was implemented at the word level. Users must finish data collection of all gestures in the target gesture set to train their own classifiers before the actual recognition application. For a new sign word, the recognition performance could not be tested until enough data was collected to train a specific model for the new word. In our proposed framework, each sign word was encoded with a combination of five sign components and the final recognition of the sign gesture was implemented at the component level. The training burden was significantly reduced for the reason that a promising recognition result could be achieved based on the training set which contains only half of the target gesture set. In addition, the recognition of a new sign word could be performed without training as long as its components have been trained in advance.
Xie
et al. presented an ACC-based smart ring and proposed a similarity matching-based extensible hand gesture recognition algorithm in [
27]. In this work, the complex gestures were decomposed into a basic gesture sequence and recognized by comparing the similarity between the obtained basic gesture sequence and the stored templates. The overall recognition results of 98.9% and 97.2% were achieved in the classification of eight basic gestures and 12 complex gestures, respectively. The basic gesture in [
27] is similar to the concept of the sign component in our proposed framework and the two studies share the advantages of extended vocabulary and reduced training burden. However, the recognition algorithm in [
27] can only be utilized in the classification of gestures executed in 2-D space and the recognizable gestures are too limited. In our work, 110 CSL gestures have been conducted only on five sign components. Although the overall recognition performance is a bit lower than that in [
16,
27], according to our comprehensive literature investigation, this study is the first attempt to realize vocabulary-extensible gesture recognition based on sign components using sEMG, ACC, and GYRO data, which can facilitate the implementation of large-scale SLR system.
It is noteworthy that this is a preliminary attempt to explore the feasibility of component-based vocabulary extensible gesture recognition technology. As we know, there are more than five thousand CSL gestures consisting of a variety of components. In the present work, the recognition experiment were conducted on a target set composed of 110 gestures, and only five typical sign components were referred to. To realize a practical SLR system, more sign components should be explored to acquire more comprehensive description of sign word in the future to enlarge further the size of the target set and improve the recognition performance. In classification algorithm, more robust component features and classifiers should be explored and advanced fusion method should be adopted to replace the simple code matching method.





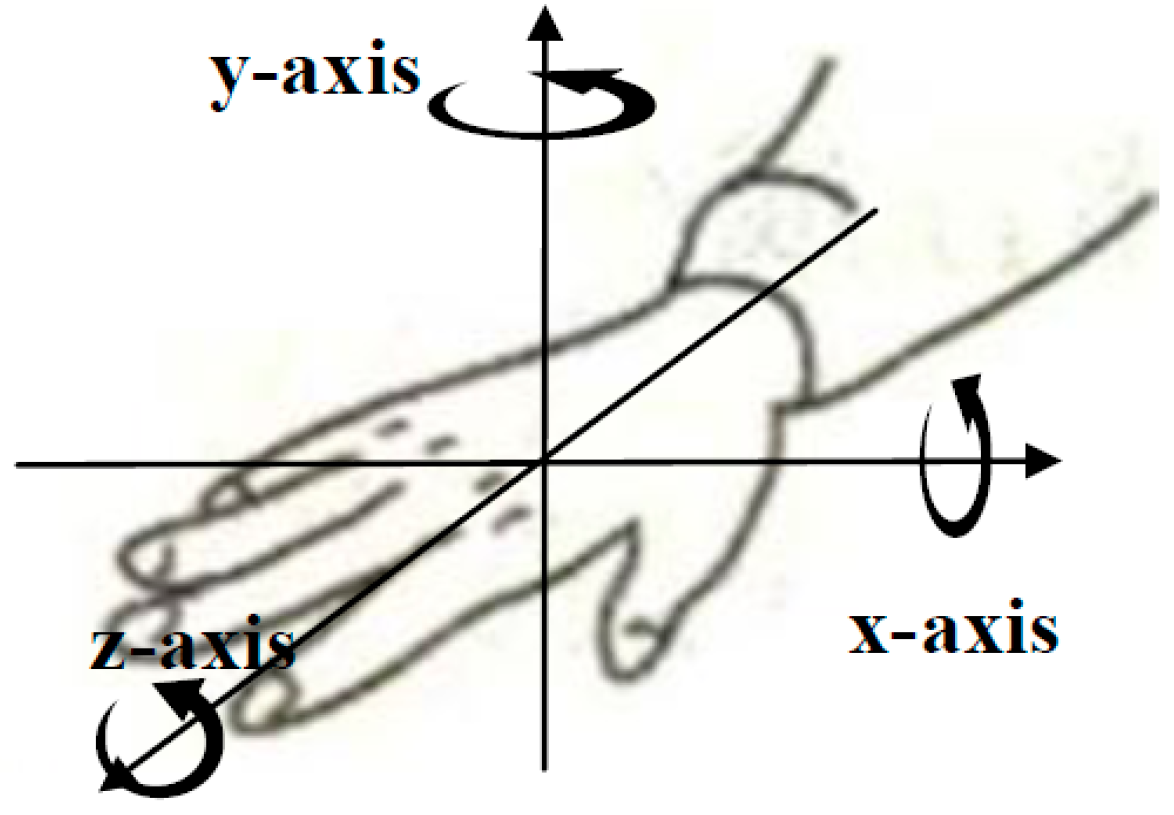

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}