1. Introduction
Public opinion is the embodiment of the opinions, attitudes, and emotions expressed by the public, which affects multiple fields, such as human interactions, political orientation, financial policy, and even the military. Therefore, predicting the evolution trend of public opinion and providing valid explanations for its causes is a significant problem, both in theory and practice. Researchers have solved this problem by building opinion dynamics models. They simulate the interaction between individuals in society and changes in people’s opinions, which can effectively reveal the generation, diffusion, and aggregation of public opinion.
Faced with the problem of public opinion prediction and explanation, researchers have attempted to reveal and analyze the laws of the public opinion system by establishing opinion dynamics models. Earlier research in this field can be traced back to the French model proposed in 1956 and its subsequent French–Degroot model [
1]. Since then, multiple opinion dynamics models have been proposed, which can be divided into two categories: discrete and continuous. Typical discrete opinion dynamics models include the Voter [
2], the majority rule [
3], and the Sznajd [
4] models. The study of discrete opinion dynamics has become popular in recent years [
5,
6]. In these models, agent opinions have only two values: mostly “1” represents support and “−1” represents against. This makes them suitable for depicting either/or cases; for example, political election prediction [
7,
8]. However, they cannot distinguish between neutral and extreme opinions or situations that are more complicated. Continuous opinion dynamic models have solved this problem. The most famous among them are the Hegselmann–Krause (HK) model [
9] and the Deffuant–Weisbuch (DW) model [
10]. These two models also introduced an important concept of opinion dynamics, that is, the bounded confidence rule: individuals’ opinions are affected by others only when the difference between their own opinions and others’ opinions is less than a threshold [
11]. Based on this research, researchers have proposed multiple extended models [
12,
13,
14,
15,
16].
However, it is still difficult to predict public opinion using only dynamic opinion models. On the one hand, public opinion may be disturbed by unpredictable external factors, such as emergent public events or the speaking of Internet celebrities. On the other hand, because models are not the same as real systems, the result of model prediction will inevitably fail owing to the accumulation of random and systematic errors over time. Therefore, in addition to model construction, two questions need to be answered to use the opinion dynamics model to predict the evolution of public opinion.
Problem 1 How to determine the initial values of the model parameters?
To solve this problem, the proposed framework determines the initial model parameters based on the genetic algorithm. We design a fitness function according to the characteristics of opinion dynamics and public opinion, which enables the framework to calibrate the parameters of the opinion dynamics models. Through selection, crossover, and mutation operations, we search for the parameters that best match the initial observation.
Problem 2 How can parameters be adjusted dynamically when public opinion changes owing to external factors or errors?
One feasible way to solve the above problem is to include empirical observation in opinion dynamics research to predict public opinion more accurately.
Machine learning is a popular data-driven method in multiple fields. Many studies have tried to predict the evolution of public opinion through machine learning methods [
17,
18,
19,
20,
21,
22,
23]. However, compared with agent-based opinion dynamics models, machine learning cannot explain the inner mechanism of the system; it lacks interpretability and requires too much data to gain accuracy.
Traditional opinion dynamics models are mainly based on theoretical self-consistent and deductive analyses, which cannot be directly applied to predict public opinion. Recently, researchers have begun to import real social networks to test their models. Wang et al. [
24] proposed an opinion dynamics analysis framework for a weighted directed complex network and imported a real email network to test their method. Zhu et al. [
25] proposed an opinion dynamics model based on individuals’ attitude-hiding behaviors and simulated their model on real Epinions networks, which can well explain Duncan’s online social experiments [
26]. However, these models are not yet associated with real observations; thus, they can only explain part of the public opinion phenomena and cannot calibrate the parameters of the models through simulation.
Currently, some researchers attempt to introduce data obtained from real social networks to correlate theoretical models with empirical data. In most of their studies, a part of the data was selected as the training set to learn the parameters of the model, and the rest of the data were used as the test set to verify the prediction accuracy of the model. De et al. [
27] used the spectral projected gradient method to maximize the likelihood function of the model parameters, thus realizing parameter calibration of their model. Xion [
28,
29] collected data from the product review websites Epinions and Ciao, randomly selected X% of the data as a training set to learn model parameters, obtain individual opinions, and model-related topic vectors. The remaining data were used as a test set to evaluate the accuracy of their model prediction. Moreover, Xiong gathered a large amount of data from Twitter and conducted sentiment analysis using part of the early data for parameter calibration and curve fitting; they then used the model to predict the remaining opinion dynamics and compared the results with the rest of the real data [
30]. Johnson et al. [
31,
32] proposed an adapted genetic algorithm for modeling opinion diffusion and tested the method using the Degroot model with limited data. Kotisz [
33] proposed a minimal opinion formation model that is flexible and can reproduce a wide variety of existing micro-influence assumptions and models. The model was calibrated using datasets gathered from real social networks [
34,
35]. Lu [
36] collected large-scale data from Douban.com and expanded the Ising model to explore how individuals behave and the evolutionary mechanisms of their life cycles. The above studies introduced real data from social networks to fit their model parameters, but their calibration work was static; they did not calibrate their models with new observations. Monti et al. [
37] proposed an inference mechanism that can fit the opinion dynamics model to the social trajectory in the real world, thereby increasing the ability to fit real data. However, in different social networks, user interaction behaviors and social trajectories may not be the same. Thus, it may not be suitable to apply the mechanism to other online social networks with different structures. In addition, compared to observing public opinion, collecting the social trajectories of users is more complicated.
In summary, the field of opinion dynamics requires a dynamic calibration method that can be widely applied to all types of online social networks according to successive observations.
Dynamic calibration is an important issue in the field of modeling and simulation. Recently, many researchers have explored dynamic calibration methods [
38,
39,
40,
41,
42,
43,
44]. However, few have aimed at the field of opinion dynamics [
45]. Thus, combining the advantages of the theoretical model and data-driven method to predict public opinion is a direction for future opinion dynamics research [
46], and one way to achieve this is to introduce a data assimilation method. Common data assimilation algorithms include the Kalman filter, optimal interpolation, and the extended Kalman filter [
47]. However, neither the Kalman filter nor the optimal interpolation method can deal with non-normally distributed and nonlinear systems. Furthermore, the extended Kalman filter requires that the probability distribution of the system be expressed by simple parameters, which is also not suitable for dealing with cases in opinion dynamics systems. Compared with other methods, a particle filter can be applied to nonlinear systems [
48,
49]. Moreover, the use of particle filters to realize data assimilation in discrete event simulation has also been proposed by researchers in recent years [
50,
51]. This indicates that a particle filter has the potential to be used in the prediction calibration of opinion dynamics.
Inspired by data assimilation methods, to predict the state of the changing opinion dynamic system, the framework uses a particle filter algorithm to calibrate the parameters of the models dynamically with successive observations. In the framework, we initialize the particles according to the results of the initial parameter calibration and determine the particle weights with successive observations. By continuously resampling the particles and updating the particle weights, the framework enables models to track the changing state of the opinion dynamic system by the average distribution of particles that hold the largest weights.
We test the framework with four typical opinion dynamics models based on synthetic data, which simulate the changing public opinion systems. The results show that the framework can effectively determine the initial parameters of the models and dynamically calibrate the parameters of the opinion dynamics models over time, thus predicting public opinion more accurately.
As illustrated above, in this study, the main contributions to the fields of opinion dynamics are as follows:
- (1)
We propose a framework that can dynamically calibrate the parameters of the opinion dynamics model to predict public opinion more accurately.
- (2)
We combine model prediction and empirical data into opinion dynamics research.
- (3)
We verified the effectiveness of the framework by simulation experiments.
The remainder of this paper is organized as follows.
Section 2 provides the basis for our proposal.
Section 3 describes the proposed framework in detail.
Section 4 presents the simulation testing analysis.
Section 5 provides a summary of this study.
3. Dynamic Framework to Calibrate Opinion Dynamics Models
In this section, we introduce a detailed dynamic calibration framework for the prediction of opinion dynamics. Let the opinions of agents in the models be variables ranging from (0,1) and divide the opinion interval to K intervals uniformly. In this framework, we suppose that the observation of public opinion at time t is a vector with K dimensions , where is the distribution of all the opinions in the ith opinion interval. Let be the vector containing all parameters in opinion dynamics models and let the public opinion corresponding to the opinion dynamics system with at time t be a vector with K dimensions , where is the distribution of all agents’ opinions in the ith opinion interval.
Upon importing opinion dynamics models and initial observations into the framework, we first calibrate the model parameters based on the genetic algorithm, searching for a set of parameters with high adaptability to the initial data. Second, we conduct a particle filter based on the initial parameters obtained in the previous step and dynamically calibrate the model parameters with successive observations. The overall process of the framework is shown in Algorithm 1.
| Algorithm 1 Framework of calibrating the prediction for opinion dynamics models |
- 1:
Initialize population; Population codes parameters of opinion dynamics models - 2:
- 3:
while the genetic algorithm method is searching do - 4:
Select population that best matches the observation; - 5:
Crossover to generate new population, so as to search more efficiently; - 6:
Mutate to realize local random search, and avoid unmature convergence; - 7:
; - 8:
end while - 9:
; Particles correspond to parameters of opinion dynamics models - 10:
If obtain new observation then do - 11:
Simulate opinion dynamics models according to the particles; - 12:
Update particle weights; - 13:
Estimate new system state through the average distribution of particles with the largest weights; - 14:
Resample particles; - 15:
end if
|
3.1. Initial Parameter Calibration Based on Genetic Algorithm
The genetic algorithm is a global search algorithm that is conducted through selection, crossover, and mutation operations to its generation during iterations, and evaluates its generation by calculating the fitness function. The proposed framework calibrates the initial parameters for the model based on the genetic algorithm and uses the results in the next step.
In this section, we introduce details of the method used in the framework.
3.1.1. Fitness Function
In this framework, individuals in the genetic algorithm correspond to a set of parameters of the opinion dynamics model. The smaller the deviation between the model output and initial data, the higher the fitness of the individual with the corresponding parameters. Let the fitness function
f be the reciprocal of the total deviation between the model output and initial data as follows:
3.1.2. Selection
Individuals in the current population are selected with a certain probability for the next generation; this process is called selection. The probability of selection for the next generation depends on the fitness of the individual. The higher the fitness value, the higher the probability. In the proposed framework, we use one of the most popular selection methods, the roulette wheel selection method. In this method, the selection probability of each individual is proportional to its fitness value; the greater the fitness value, the greater the selection probability. Therefore, individuals with a large fitness value have a greater probability to be selected as a parent to generate a new individual. Let the probability of an individual
be selected as
, the fitness value of
be
, and the sum of all individuals’ fitness values be
; the roulette wheel selection method can be presented as follows:
3.1.3. Crossover
The genetic algorithm maintains the diversity of the population through a crossover operator, which includes three steps. First, the number of individuals to be crossed is set according to the crossover probability, and then randomly select individuals to be exchanged. Second, the intersection position was randomly selected. Third, paired individuals exchange their corresponding attribute strings at the crossing position, thus forming new individuals. In this study, single-point crossing with a fixed crossover probability is used for the replication operation, which is performed by taking two chromosomes, dividing them at a randomly selected location, and swapping the right part, resulting in two different daughter chromosomes. For cases where selecting an intersection location has a certain meaning, single point crossover will cause less damage to the chromosomes.
3.1.4. Mutation
In a genetic algorithm, the diversity of the population can be guaranteed by a mutation operation, which also prevents premature convergence. The mutation probability is small. In the mutation operation, first, the number of genes to be mutated is determined by the mutation probability, and then alleles to be reversed or replaced are randomly selected.
We code the parameter values in binary form in the chromosomes, as shown below:
Let the variable X to be optimized within the interval
, the number of genes be
and the coding length be
also the coding method is accurate to
decimal places, then:
Therefore, the mutation is to select a certain location of the chromosome according to a fixed mutation probability and invert its value (0 becomes 1, 1 becomes 0), so as to enhance the random search ability of the genetic algorithm. Because the genetic algorithm can only search for one set of data and cannot retain historical information, the method introduced in
Section 3.1 is a calibration method for determining initial parameters. We then combined more observations and used the data assimilation method to calibrate the models dynamically.
3.2. Dynamic Calibration Based on Particle Filters
In this step, we first express the probability distribution of the system state as a particle set. Particles are simulated to predict the prior distribution of the system state using the Monte Carlo method. We then merged real-time observations to calibrate the posterior distribution of the system state to ensure accurate analysis and prediction of the evolution of public opinion in social networks.
Let each particle have a set of parameters corresponding to the opinion dynamics model and let the state of the particle at time t be . After parameter calibration, we obtained a set of optimal parameters for the initial observation, .
For a particle, let particle ’s initial parameter state be sampled from a Gaussian distribution, , where is the preset sampling deviation. Simultaneously, because of the nonlinear relationship between the opinion dynamics system and the output of the model with different parameters, we retain some of the particles whose initial state is sampled from a random distribution, . However, we assume that public opinion is in a steady state before being disturbed. Therefore, before obtaining the latest observation, the states of the particles remain the same, that is, .
Let the state at time
t be
, and the observation be
. According to the Chapman–Kolmogorov equation, the prior probability density of
,
can be calculated as
where
represents the probability function of the state transition, which corresponds to the opinion dynamics model. Because we assume that the observed public opinion is in a steady state before
is obtained, the models also output the results after they have evolved to a steady state. Therefore,
before a new observation was obtained. The posterior probability density of
can be formulated as:
where
is the normalization coefficient, and the above equation represents the calibration process, which uses the likelihood
between the state and observation to obtain the posterior distribution of states at the next moment
.
Because it is difficult to obtain analytical solutions for nonlinear and non-Gaussian opinion dynamic systems, particle filters represent the posterior probability distribution of
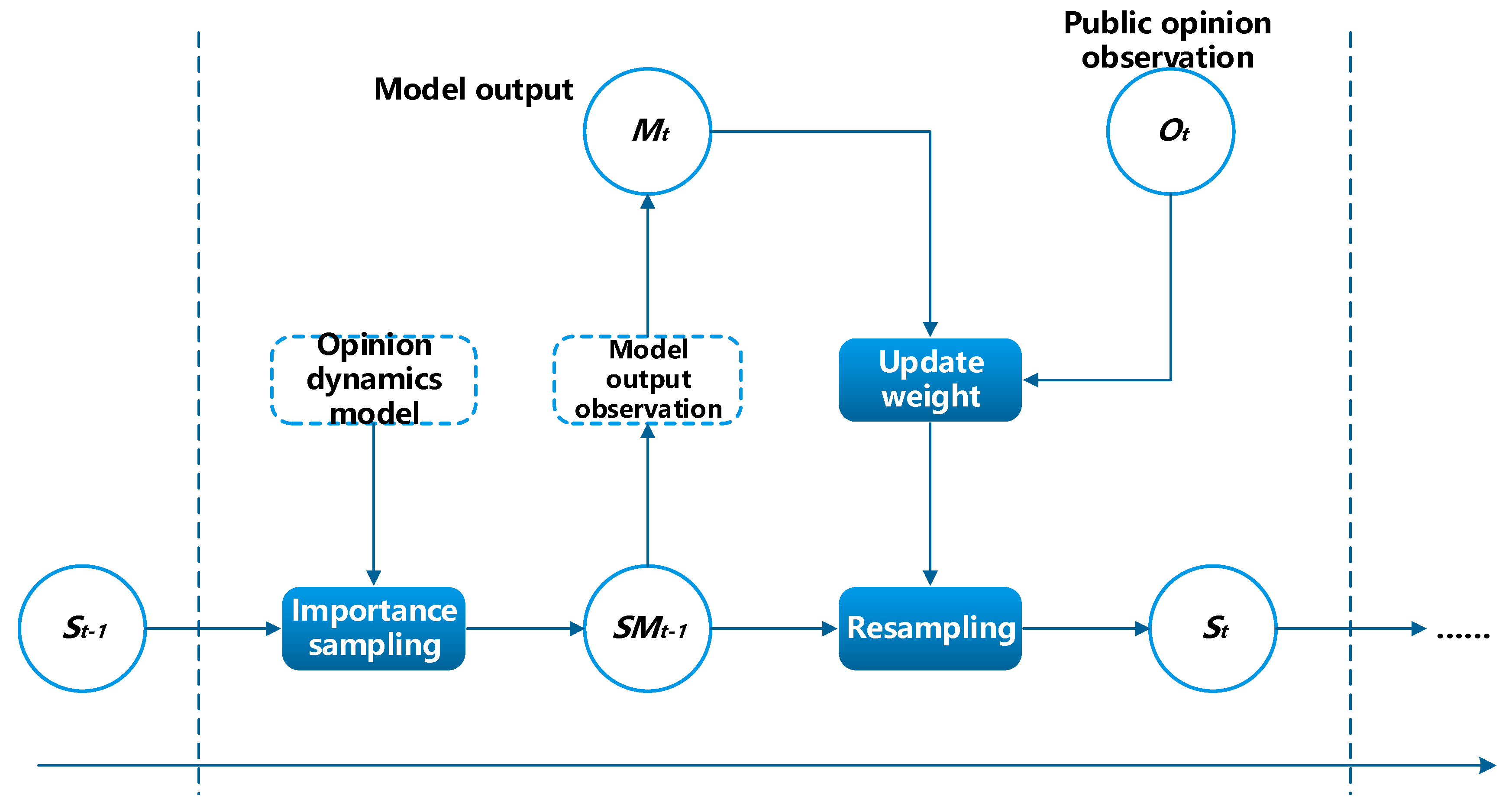
with a group of random samples (particles). When the number of particles is sufficiently large, the posterior probability of the system can be approximated sufficiently. The process of the proposed data assimilation method in the framework is illustrated in
Figure 2.
In the particle filter, the posterior distribution is approximated by a set of particles
. Here,
represents the state of the
particle and
is the model output when evolving to a steady state under the corresponding settings of each particle.
is the weight of the
particle. Each particle is a possible realization of a state; thus, the posterior distribution of the opinion dynamics system at time
t can be represented as:
In the proposed framework, particles are a configuration set of the model, including the parameter setting and structure of the social interaction graph. Suppose
is known; then, the possible state at time
t can be inferred based on the opinion dynamics model; thus, newly generated sets of particles can be regarded as the particle representation of the prior distribution. Subsequently, each particle can calculate and update its weight according to the following observation:
In detail, according to the calculation of the fitness function in
Section 4.1, the closer the model output with parameters that correspond to a particle is to the observation, the greater the particle weight; thus, we have
After several iterations, the estimated variance of the particle weight gradually increases, resulting in particle degradation; that is, the weight of most particles is too small for the particle set to effectively express the posterior probability distribution of the system state, and the simulation of these low-weight particles is not sufficiently meaningful. To this end, the method resamples the particles from the particle sets . Generally, the probability of selecting a particle is determined by its corresponding weight. Particles with high confidence are sampled more, which ensures that the particles converge to a state with high confidence and can obtain the posterior particle set . After outputting the results, the framework continues to resample the particles. It retains the particles with the highest weights. Let the average state of those particles be , and the new states of other particles be sampled from a Gaussian distribution Meanwhile, some particles are still selected, and their new states are sampled from the random distribution .
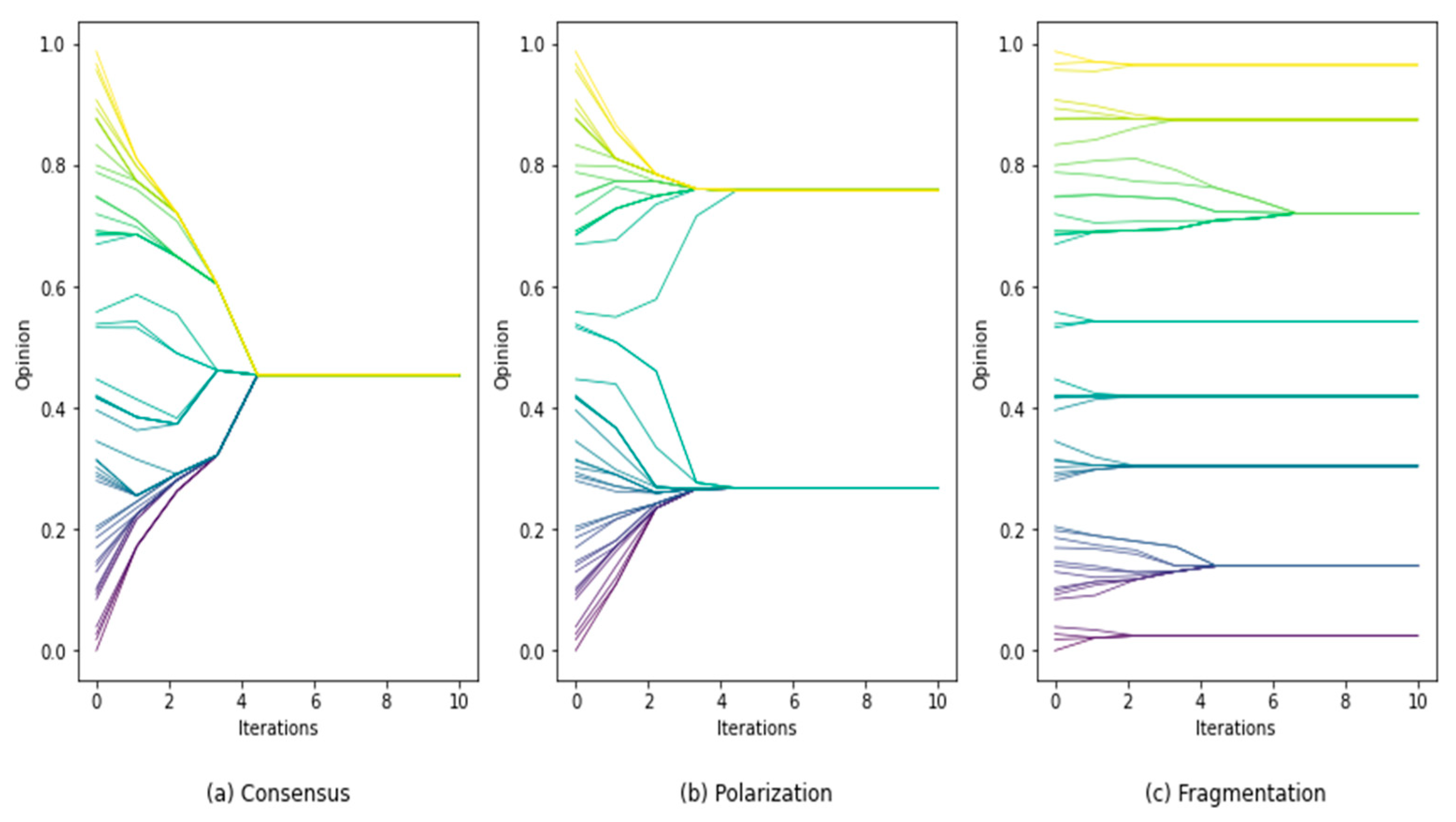
4. Simulation Tests and Analysis
In this section, we use the AH, ADW, EPO, and HK models to test the proposed dynamic calibration framework and solve the two problems. In
Section 4.1, we calibrated the initial parameters of the four models based on synthetic datasets to verify the feasibility of the method proposed in
Section 3.1. In
Section 4.2, we solve the second problem, that is, assuming that the model is correct, how to calibrate the model as public opinion changes owing to external factors. Based on the results in
Section 4.1, we initialized the particles and dynamically calibrated the four models using the particle filter method. The reason to use synthetic data is that the proposed framework is designed to solve the problem that, assume the opinion dynamics model is correct, how to dynamically calibrate the parameters with a new observation, so as to achieve more accurate model predictions. Whether the model can evolve specific real public opinion is not what this study considered. Compared with real public opinion data, synthetic data generated from opinion dynamics models fit better with corresponding models, which is easier to demonstrate whether the framework can dynamically calibrate model parameters to achieve more accurate predictions.
To quantitatively express the accuracy of the prediction and calibration, we propose the concept of deviation distance:
Let a node in the parameter space have an N-dimensional coordinate
, and the coordinates of the node that correspond to the actual parameters in the data are
. Then, the deviation distance was.
4.1. Calibration to Determine Initial Parameters
In this section, we search for the optimal initial parameters of the AH, ADW, EPO, and HK models using the parameter calibration method in the framework. For the initial observation, we set a combination of parameters for the four models and took the model output under these parameters as the synthetic initial observation.
For the AH model, we set , , , , and to generate synthetic data. For the ADW model, we set , , and . For the EPO model, we set and . For the HK model, we set . The number of agents in the above models is 1000, and for those models that include a social network structure, we import a scale-free network with 1000 nodes. The initial opinions of the agents in the models were randomly sampled.
As shown in the tables, as the number of iterations increased, the deviation in the results for each model decreased. This indicates that the parameter calibration method in the proposed framework can infer the initial parameters of opinion dynamics models, thus answering Problem 1. The above results demonstrate the feasibility of the parameter calibration method and the reliability of the initial parameters for the models.
Note that the genetic algorithm may still obtain a local optimal solution instead of a global optimal solution. For example, in the results of the EPO model, the deviation with 100 iterations was greater than that with 50 iterations. A solution to this problem is to calibrate the model multiple times to avoid such situations.
Because prior knowledge cannot be fully used by the genetic algorithm to calibrate the model parameters with more observations, we then use the particle filter in the framework to dynamically calibrate the above models.
4.2. Dynamic Calibration with Successive Observation
First, we initialized the particles based on the results presented in
Section 4.1. In the following experimental results, we present the particles with the largest weight in the parameter space.
In the experiments, synthetic data were generated after the models had evolved to a steady state under the preset parameters. The first group of data was the initial synthetic data used in
Section 4.1. For the AH model, we changed
,
, and the remaining groups of data were generated with
,
and
. For the ADW model, we changed
,
, and the remaining data were generated with
and
. For the EPO model, we changed
and
, and the remaining data were generated with
and
. For the HK model, the data were generated with
and 0.05. The other parameters and configurations of the four models were the same as those in
Section 4.1. Five hundred particles were used for the calibration of each model.
First, we present the results of the HK model. The results is shown in
Table 5,
Table 6 and
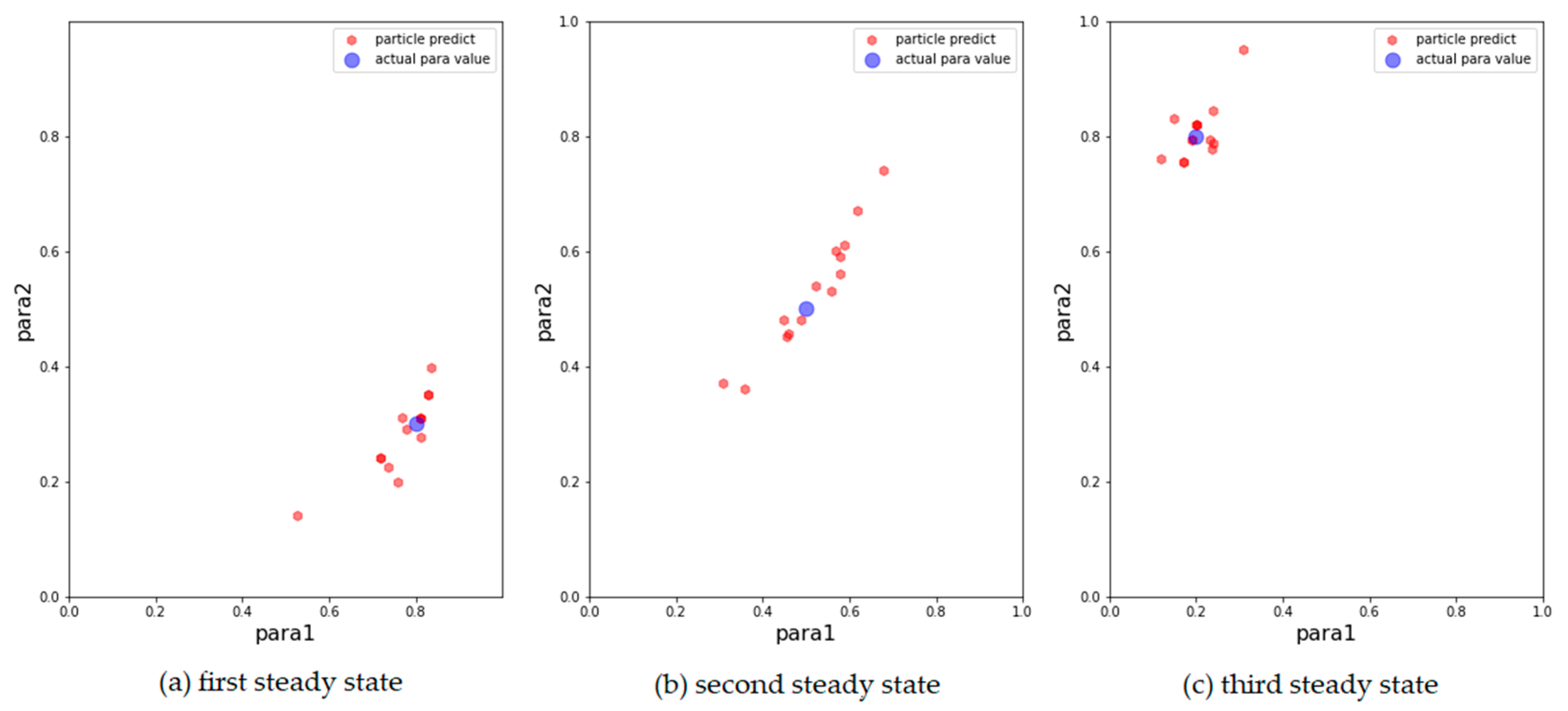
Table 7. We selected 10 particles with the greatest weight as the results (the top 10 particle weights have been normalized), and it can be observed from the tables that, with the change in observed data, the parameters of the optimal particle can always be around the position corresponding to the real parameter.
However, note that the original HK model is mainly used to analyze the dynamic changes in opinion dynamics caused by different bounded confidence thresholds; the model is not built to fuse observations. Although the data assimilation algorithm proposed in this framework can be used to track and forecast self-generated synthetic data, the HK model may not be able to evolve some situations in public opinion due to the social network structure, other attributes of individuals, and even external influences.
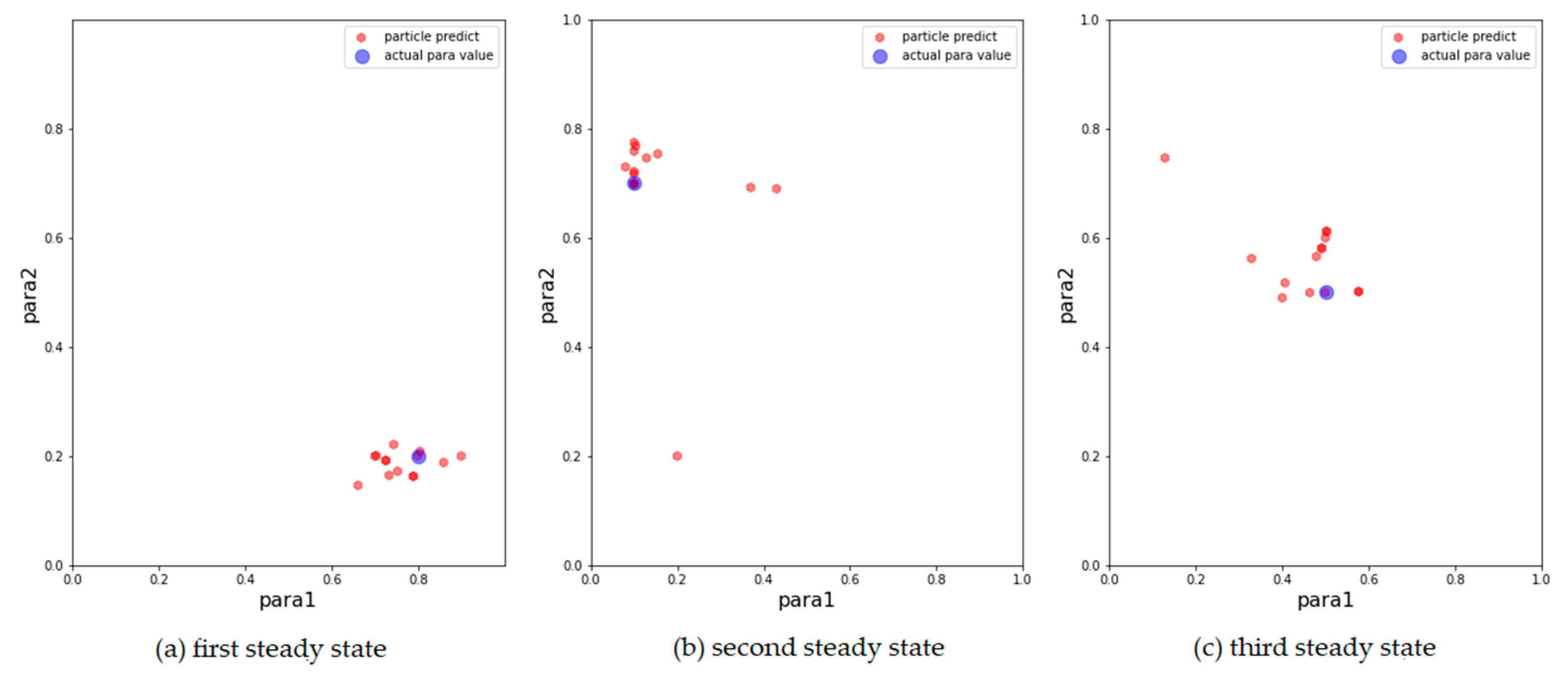
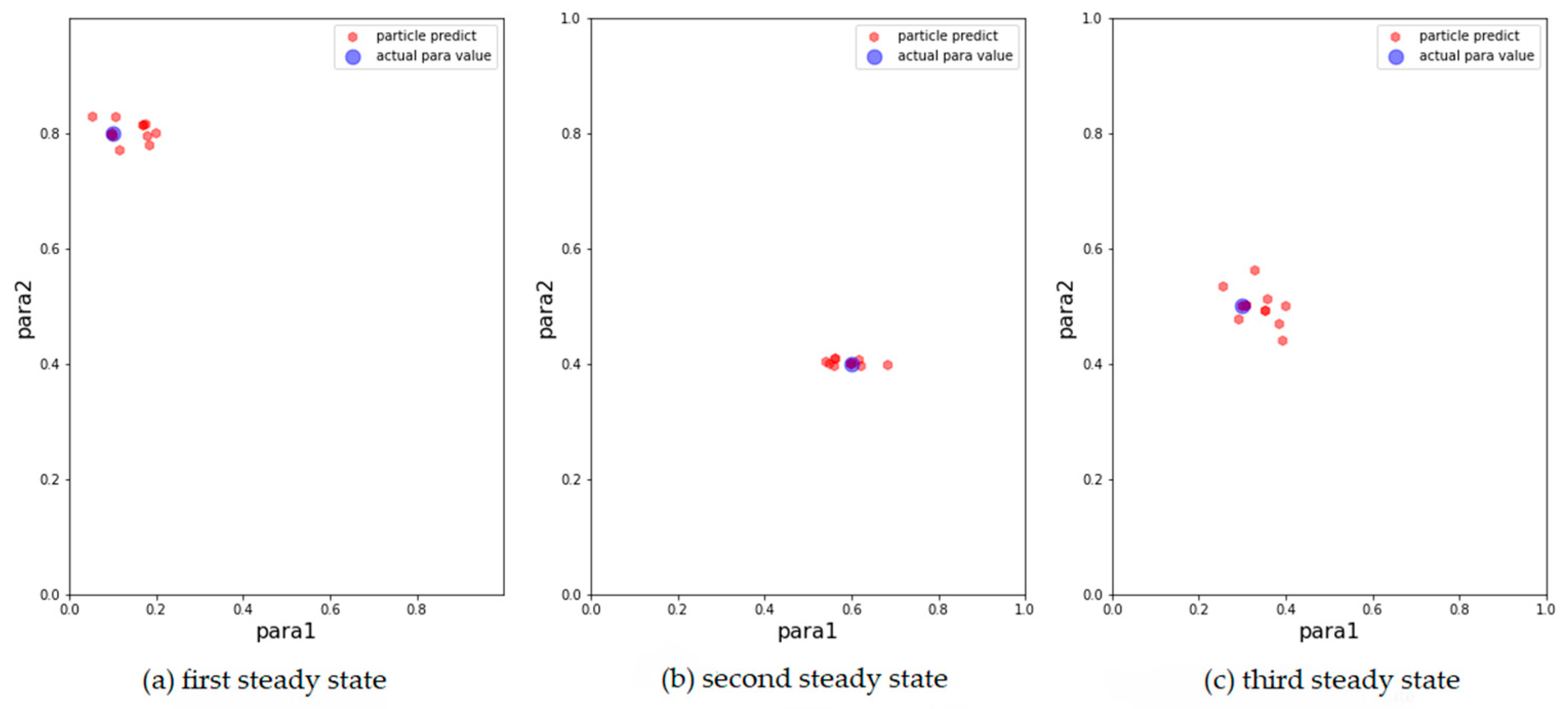
We then show the results of the AH, ADW, and EPO models in
Figure 3,
Figure 4 and
Figure 5, respectively, on scatter plots in the parameter space.
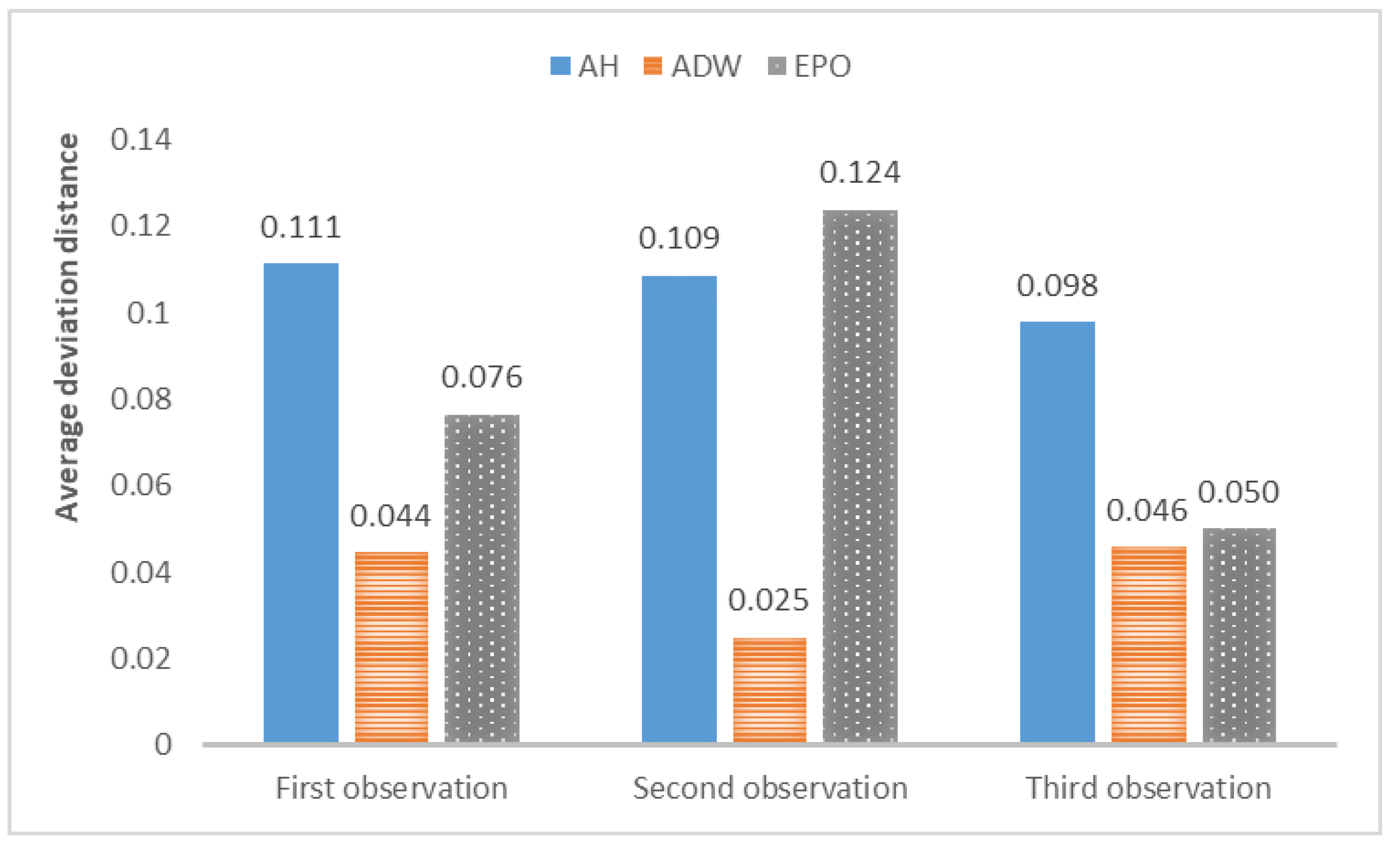
The average deviation of the above results is shown in
Figure 6.
From the above results, it can be concluded that the above models can track changes in the observations and dynamically calibrate the model prediction under the proposed framework. The positions of the calibrated particles in the parameter space can be approximately the positions of the parameters for the synthetic data. The results prove that the framework can dynamically calibrate the parameters of opinion dynamics models as public opinion changes and track the system through successive observations. Among the above models, the ADW model has the highest precision for calibration on synthetic datasets, whereas the distribution of particles of the EPO model for the second observation in
Figure 5b is relatively dispersed. This may be because the ADW model is affected less by random factors than the EPO or the AH model. In addition, the results of the AH model are less accurate than the others, which may be due to its complexity. The AH model is built to predict real public opinion, and its mechanism is more complicated than that of the other models. Furthermore, a different set of parameters in the AH model may derive similar opinion dynamics, making particles that actually deviate from the real location significantly increase in weight, thus affecting the accuracy of the results. Nevertheless, opinion dynamics models with different parameters might show similar output results, leading to situations in which some particles in the above three experiments deviated more from the synthetic values. In future work, we will attempt to avoid this problem by improving the weight update rules.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}