
Monte Carlo Simulation of Stochastic Differential Equation to Study Information Geometry



Abstract
:1. Introduction
2. Methods
2.1. SDE Simulation
2.2. Estimating
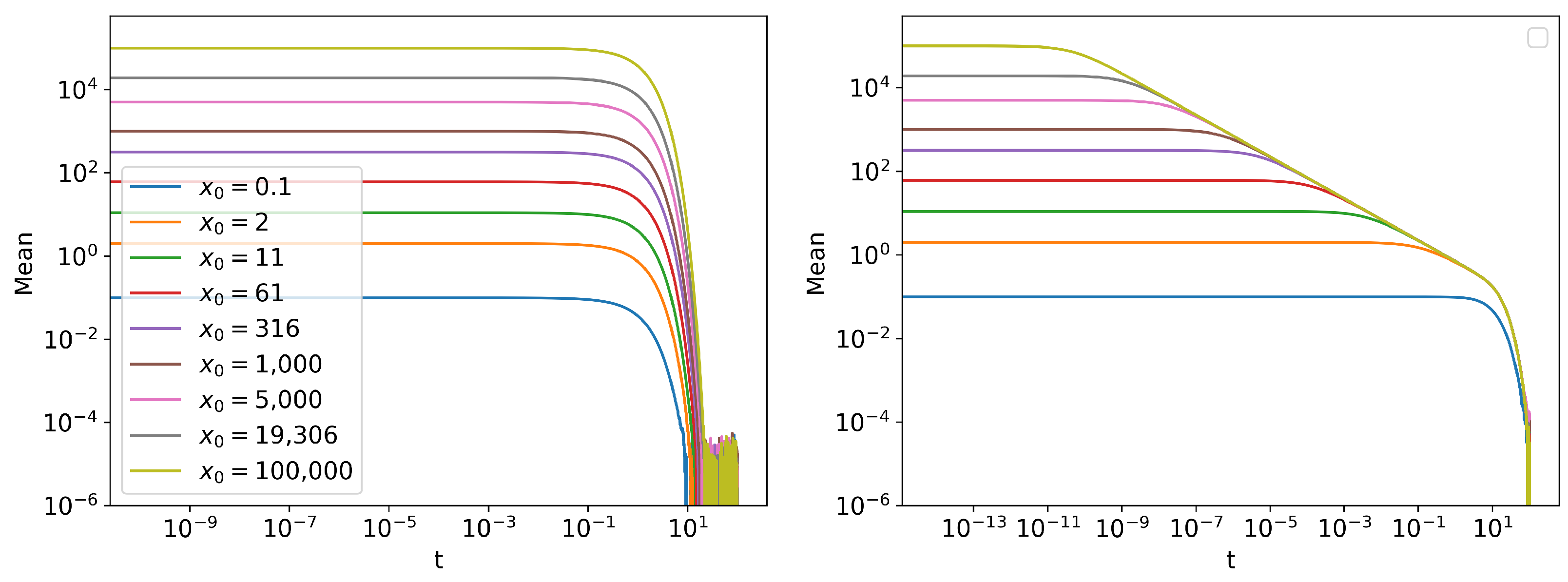
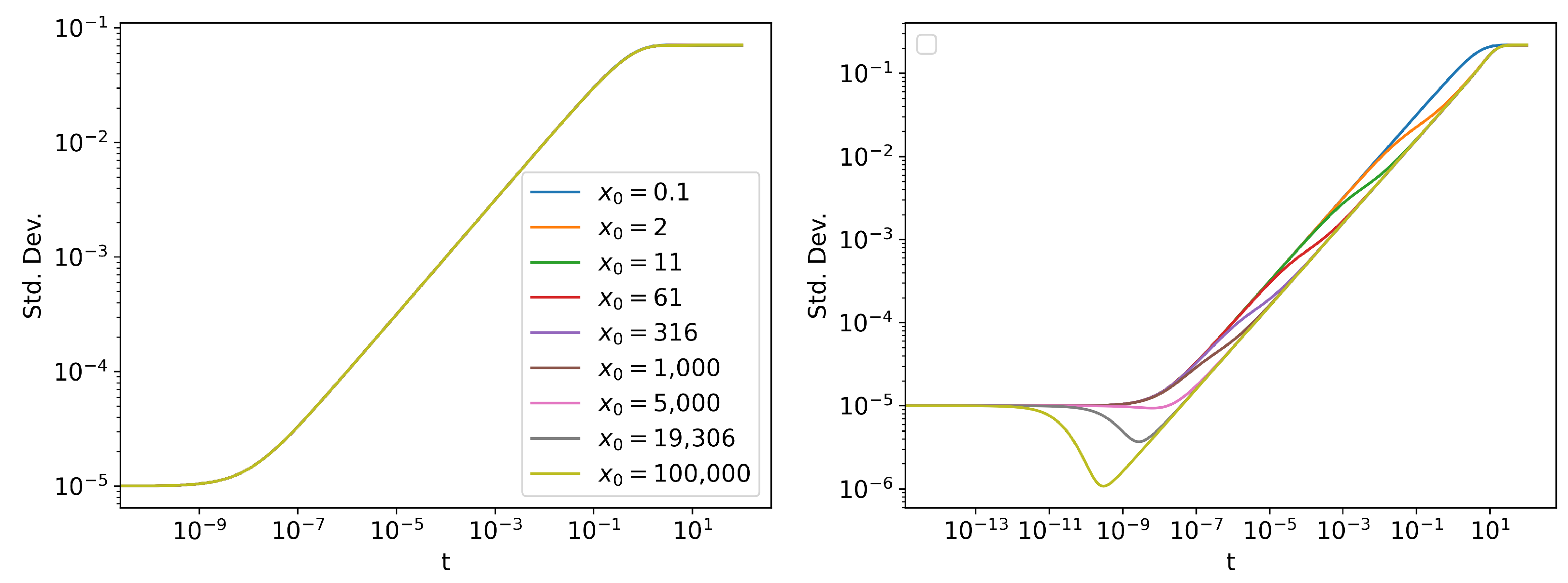
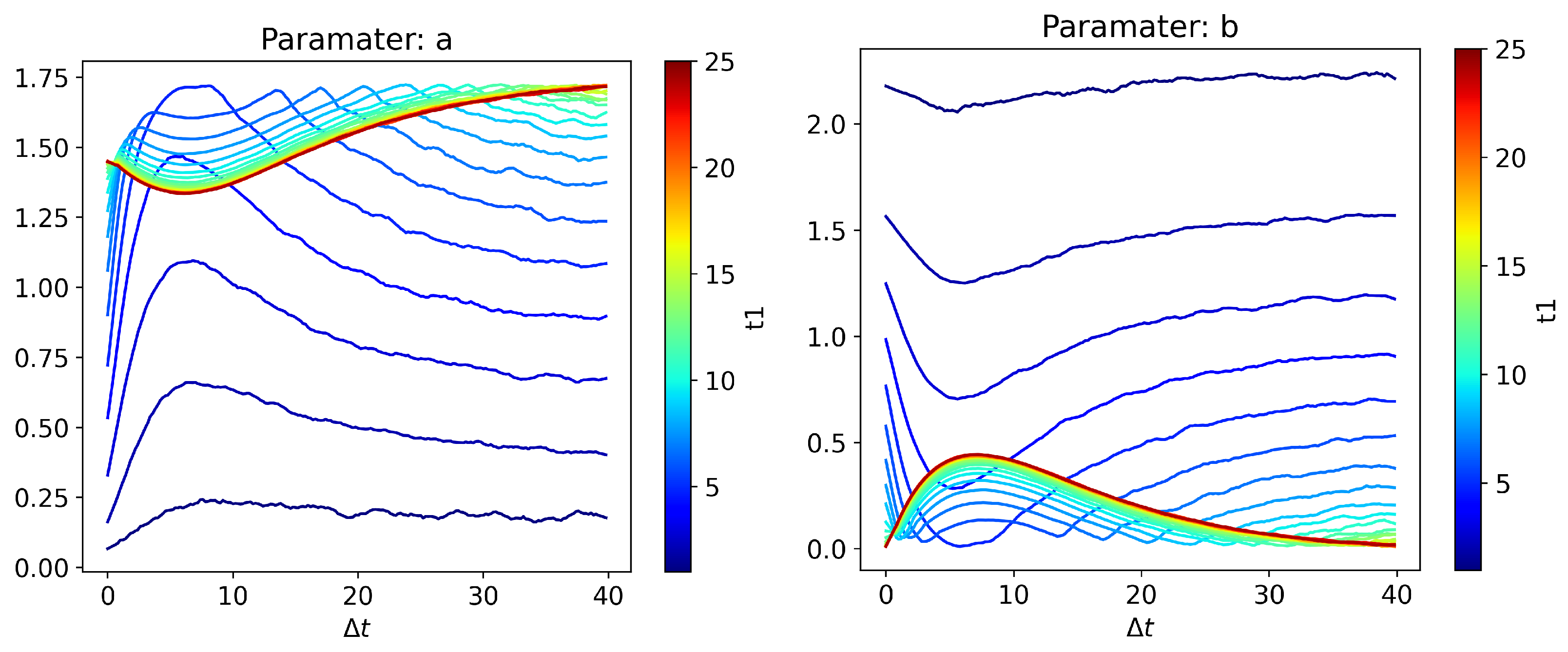
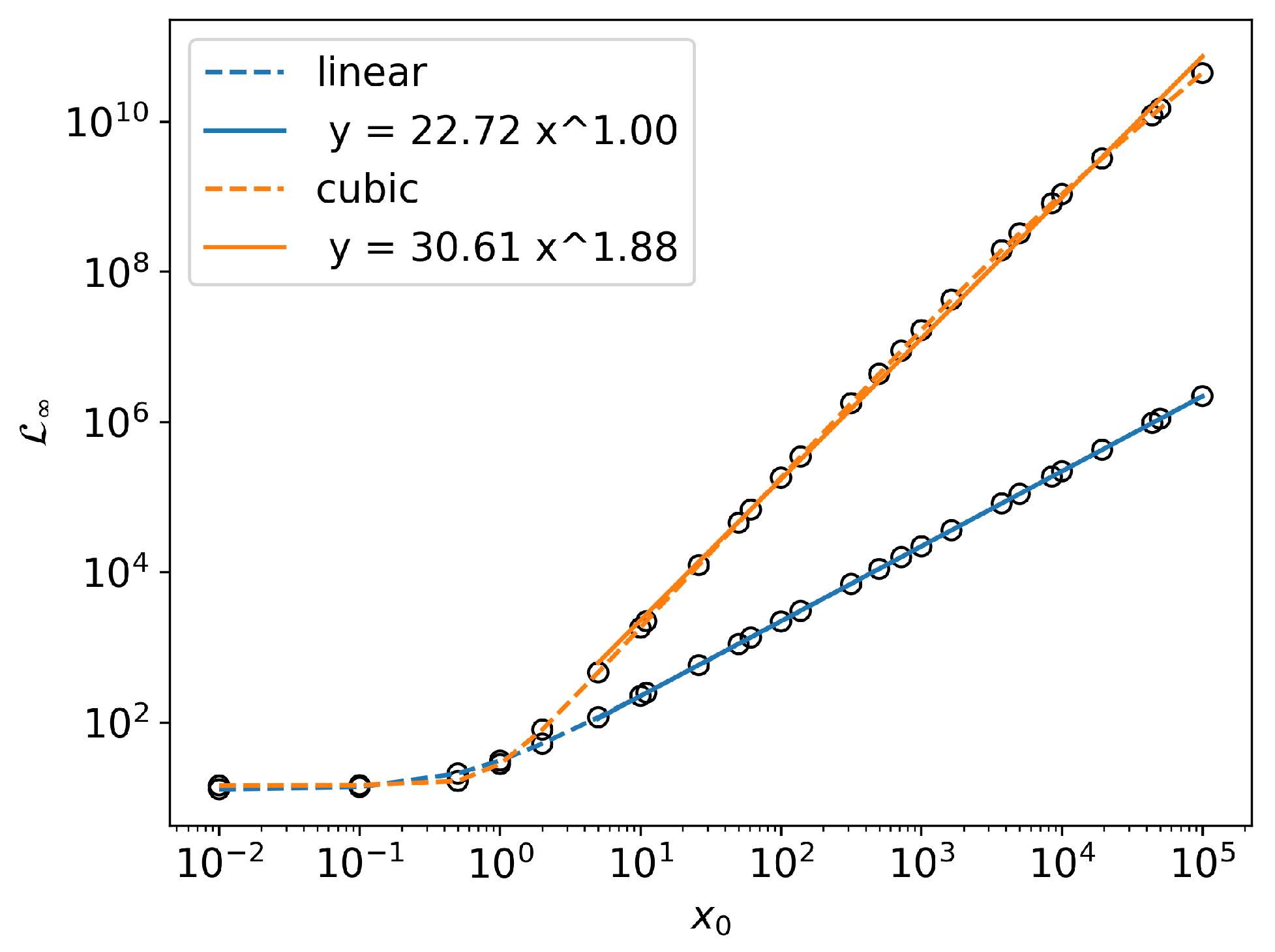
3. Linear vs. Cubic Statistics
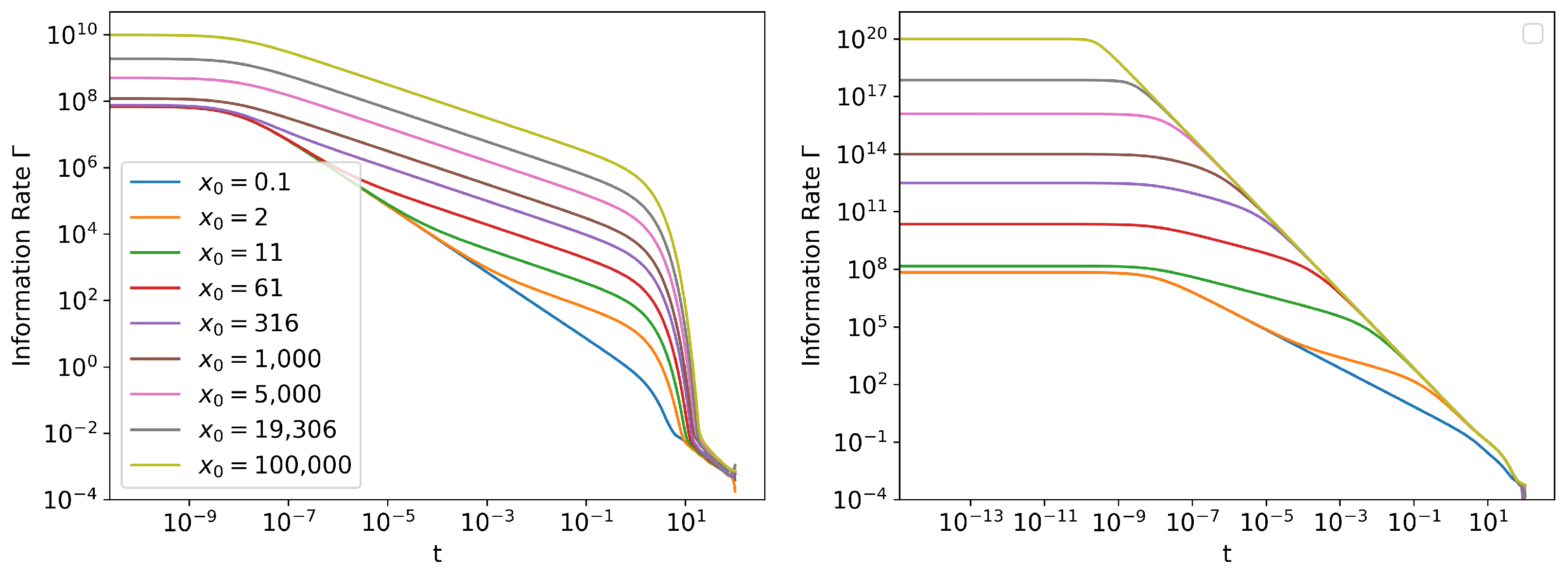
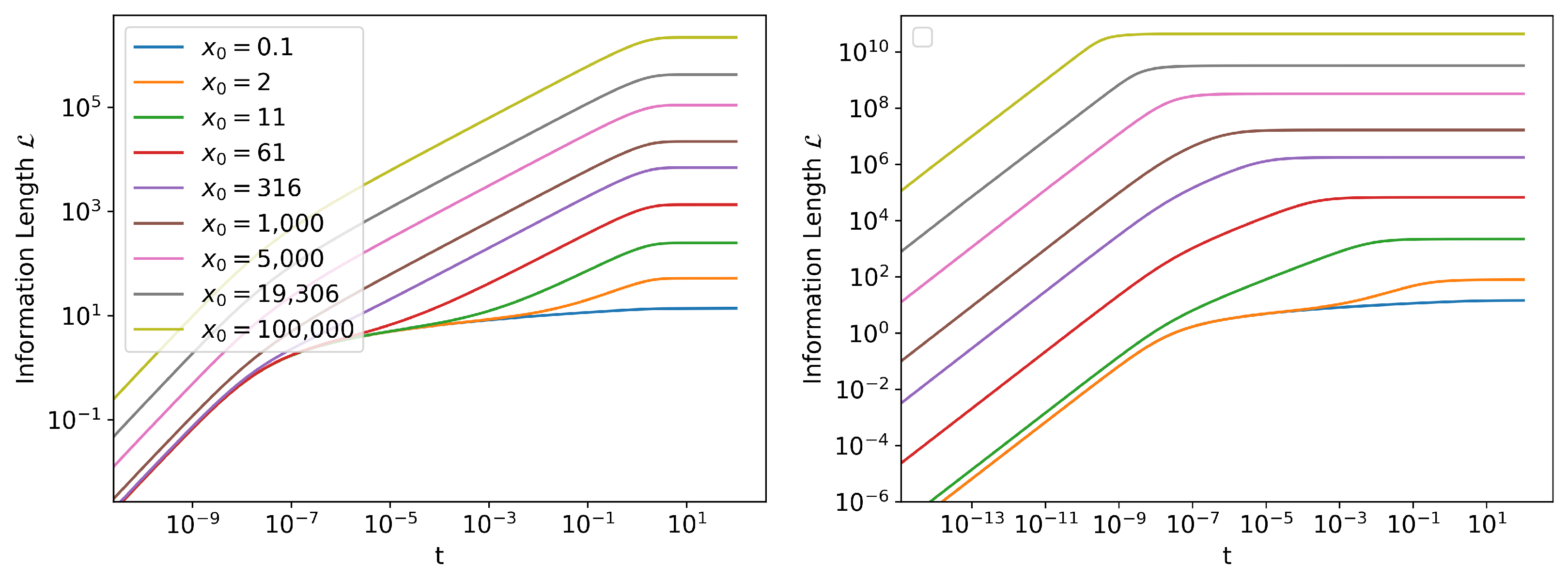
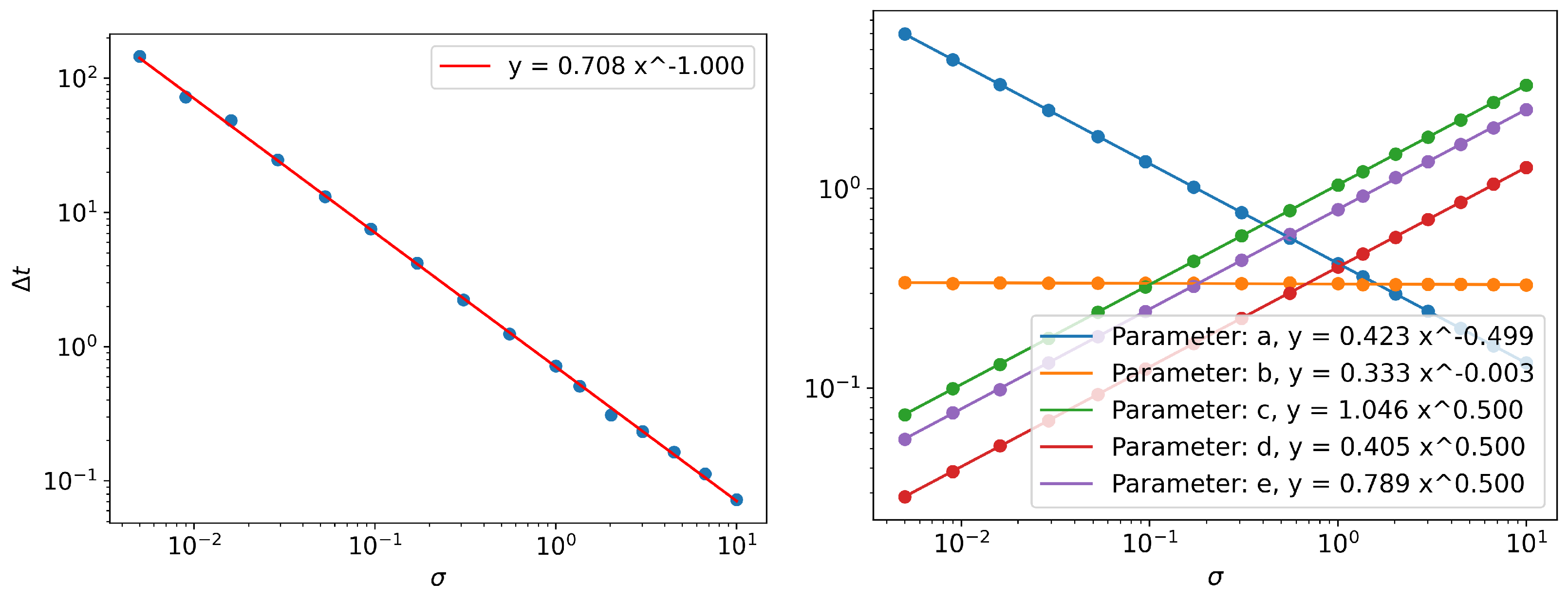
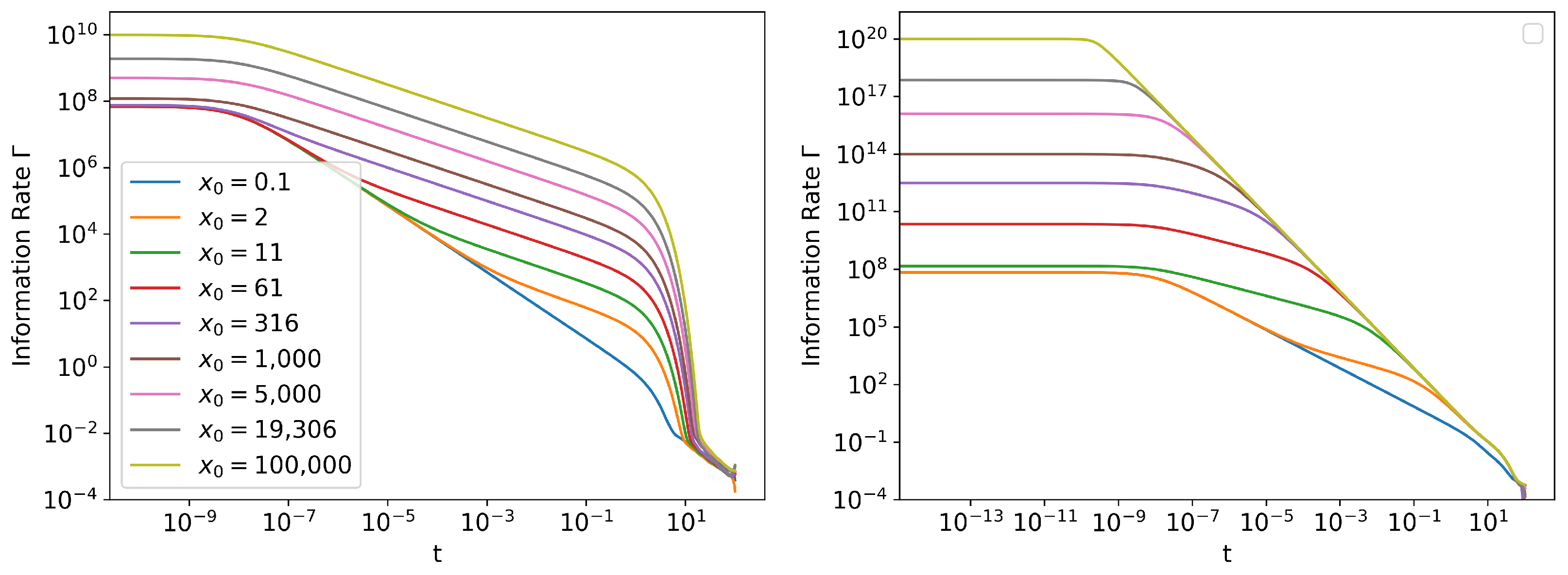
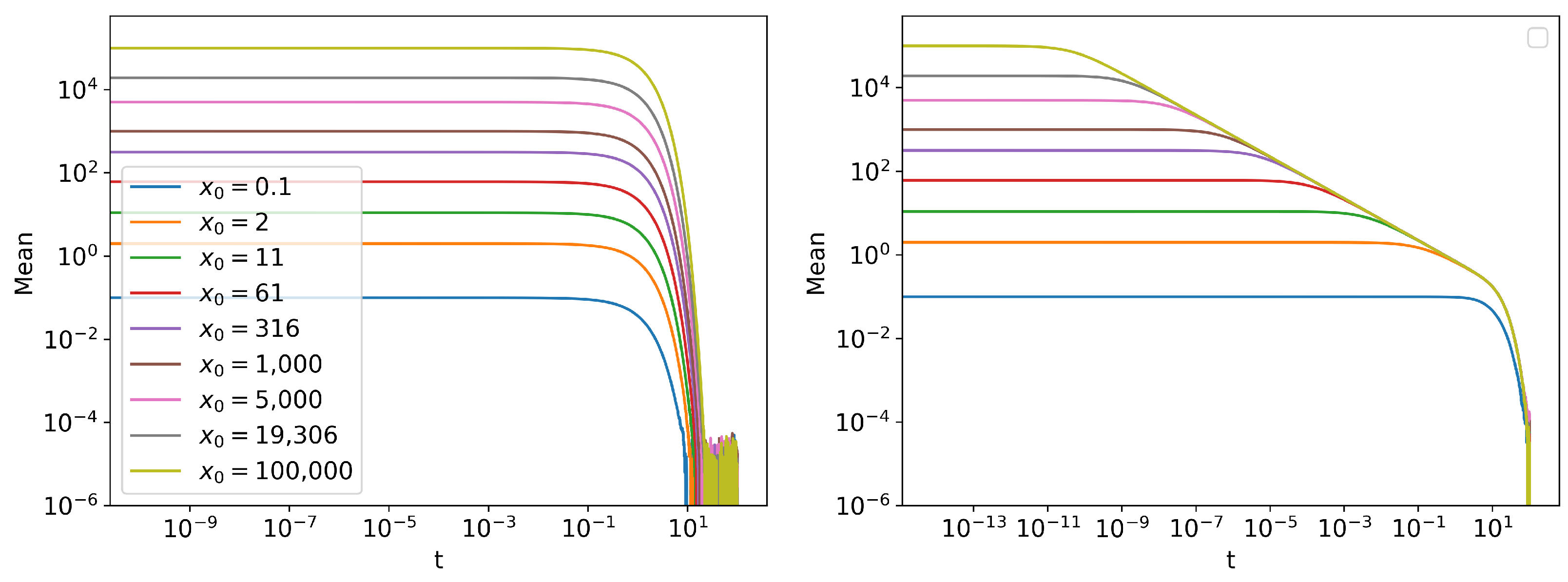
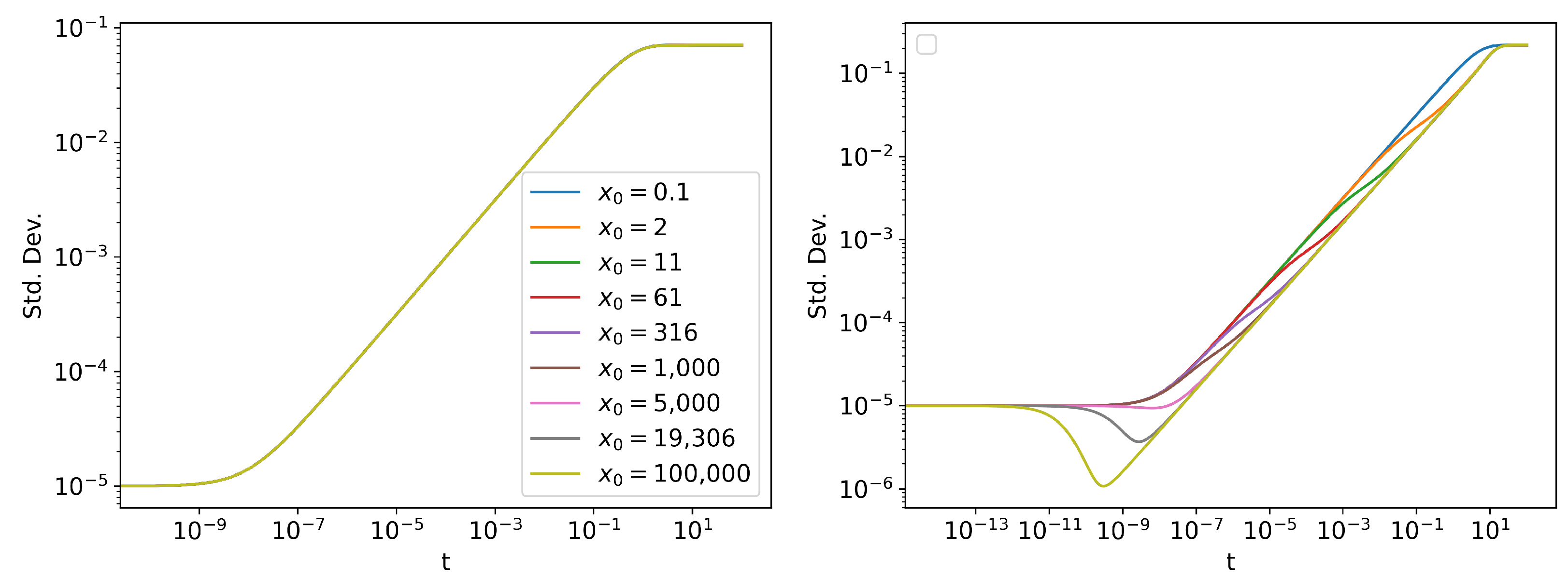
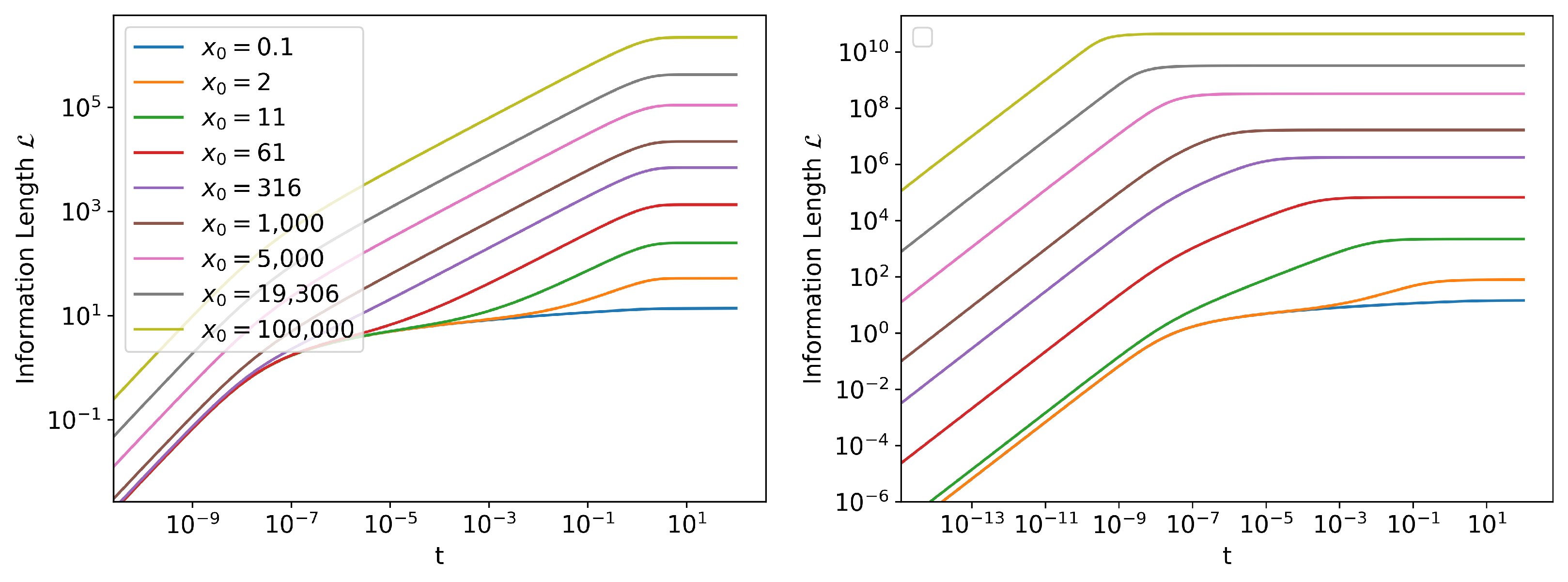
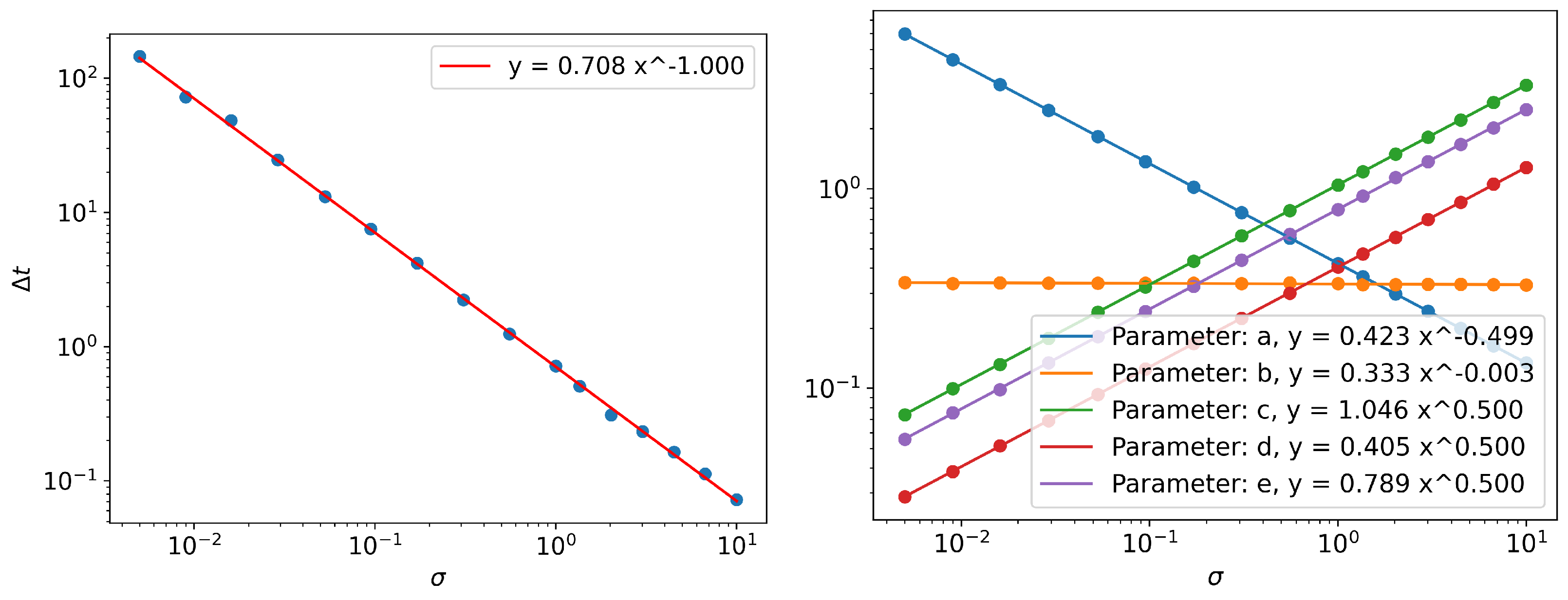
Information Length Scaling
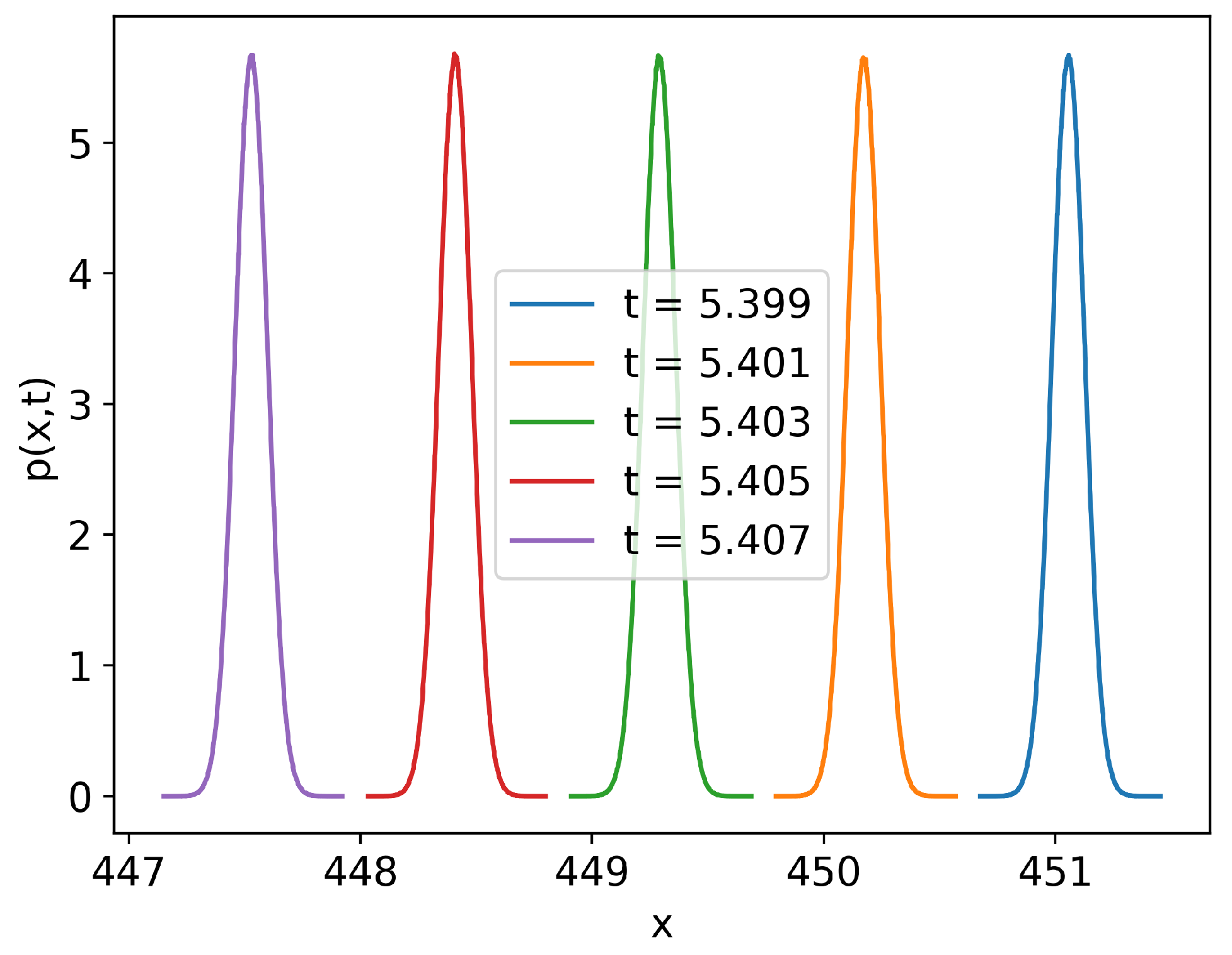
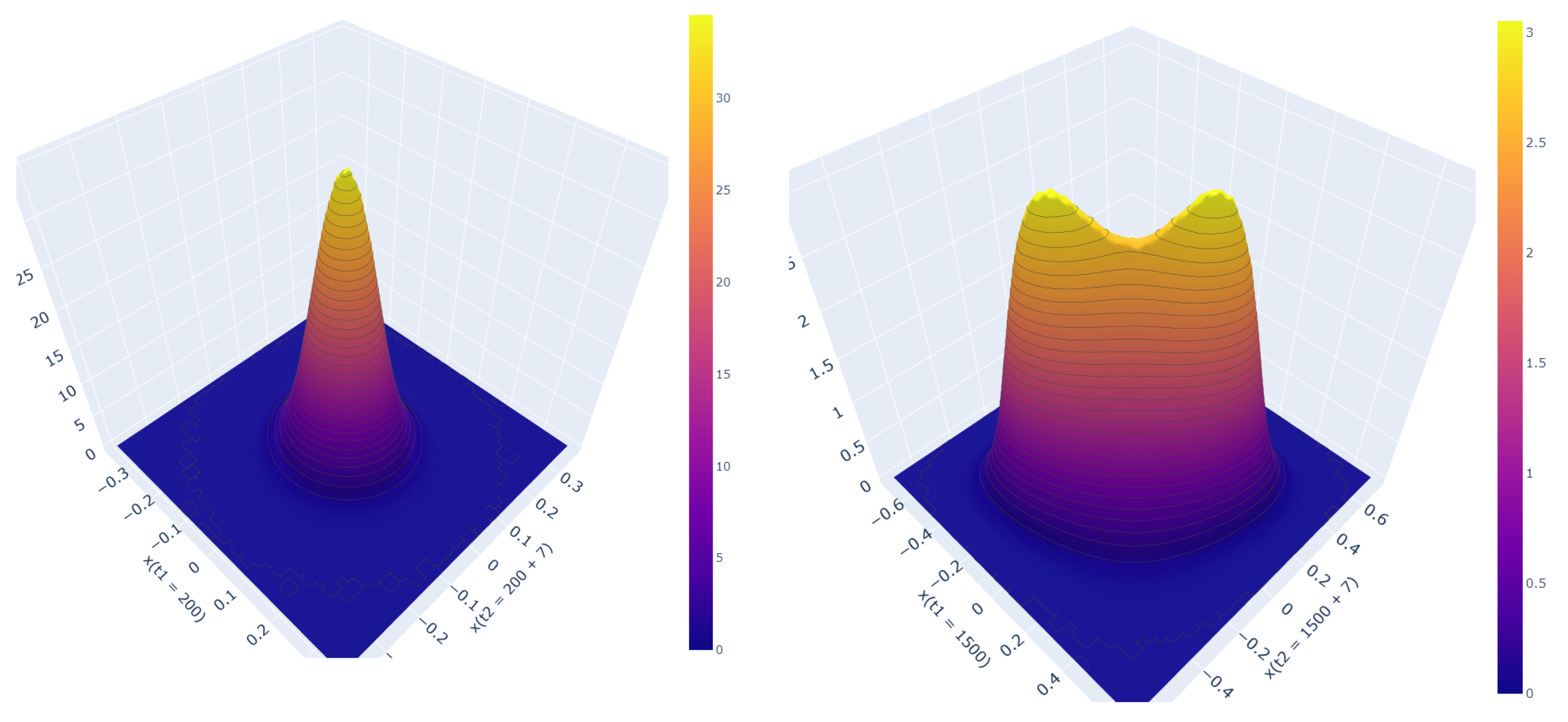
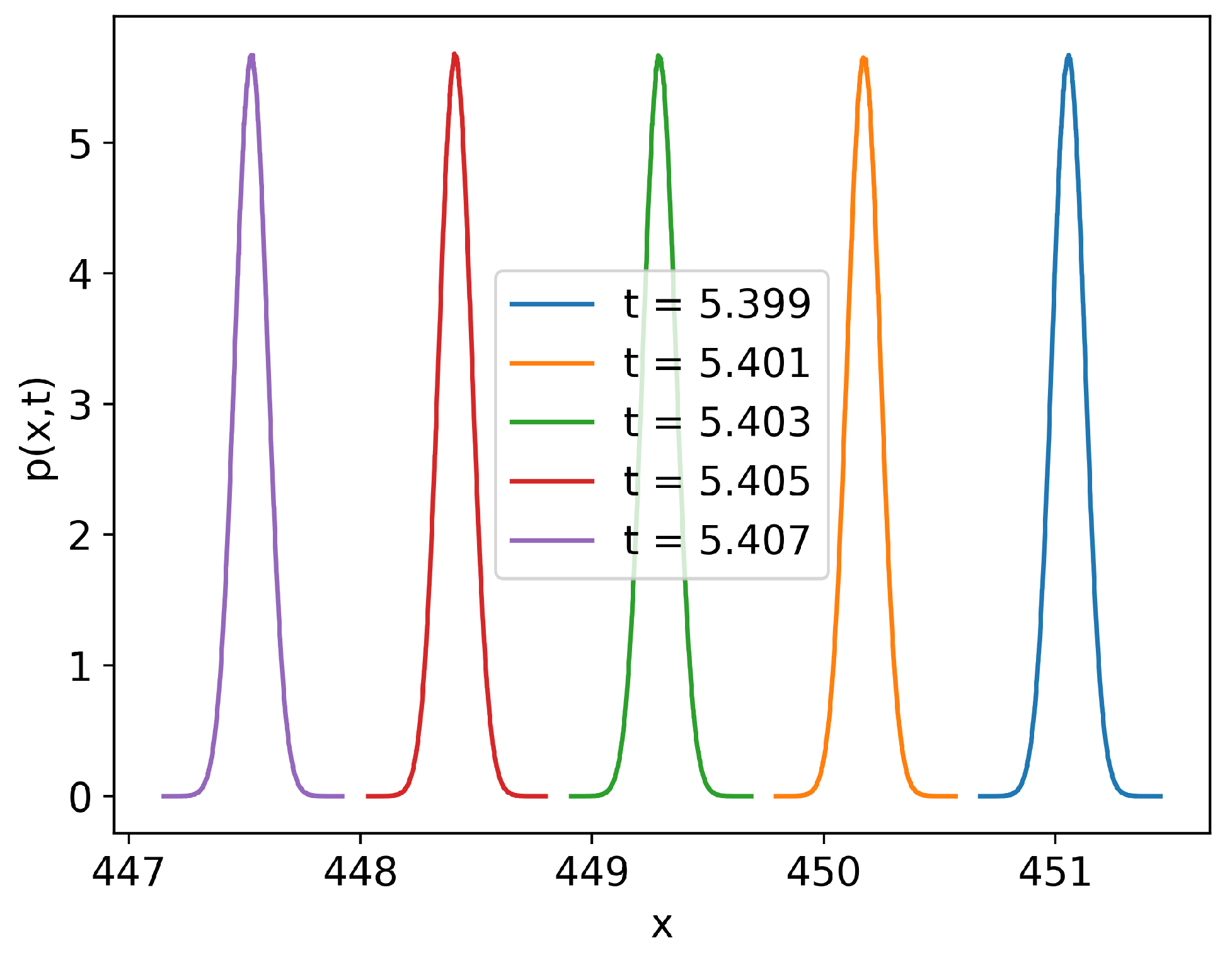
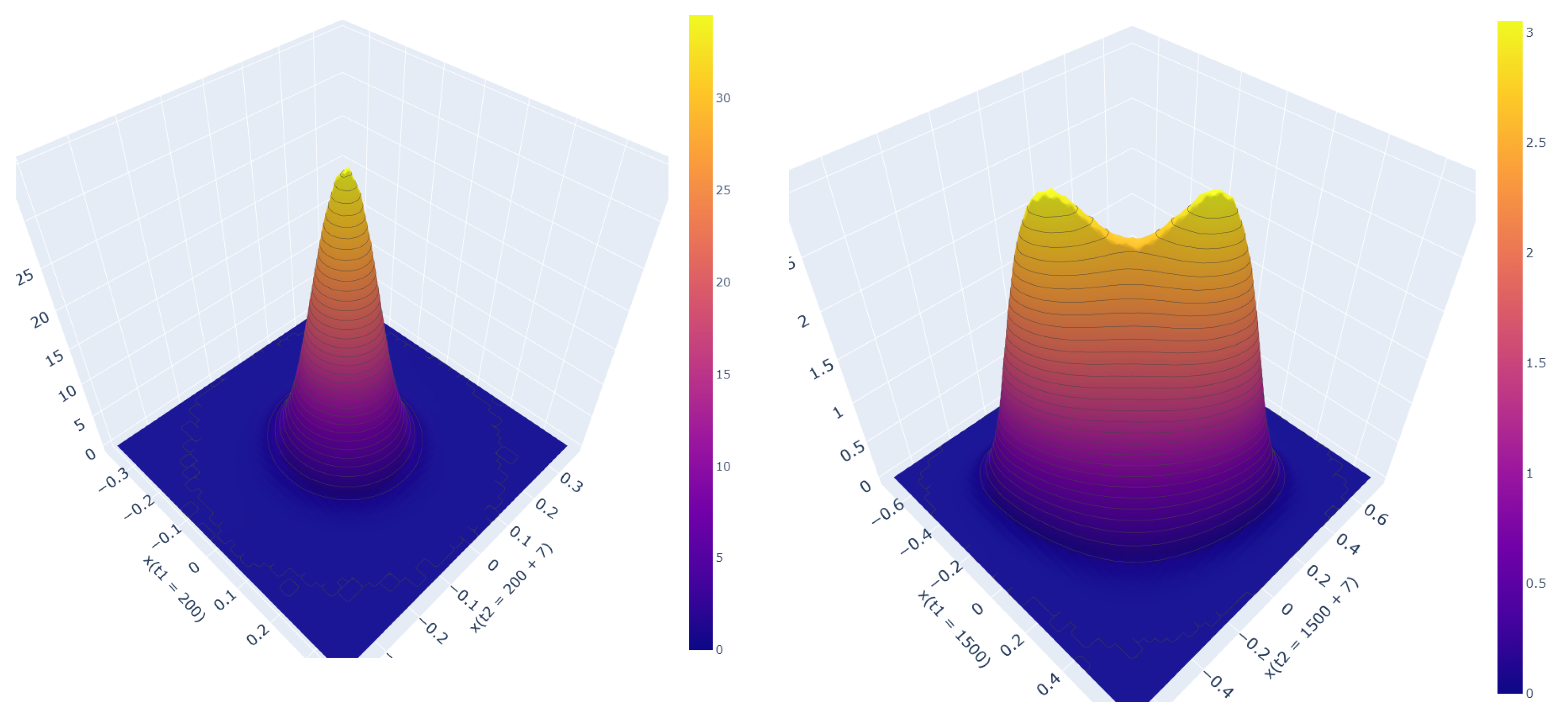
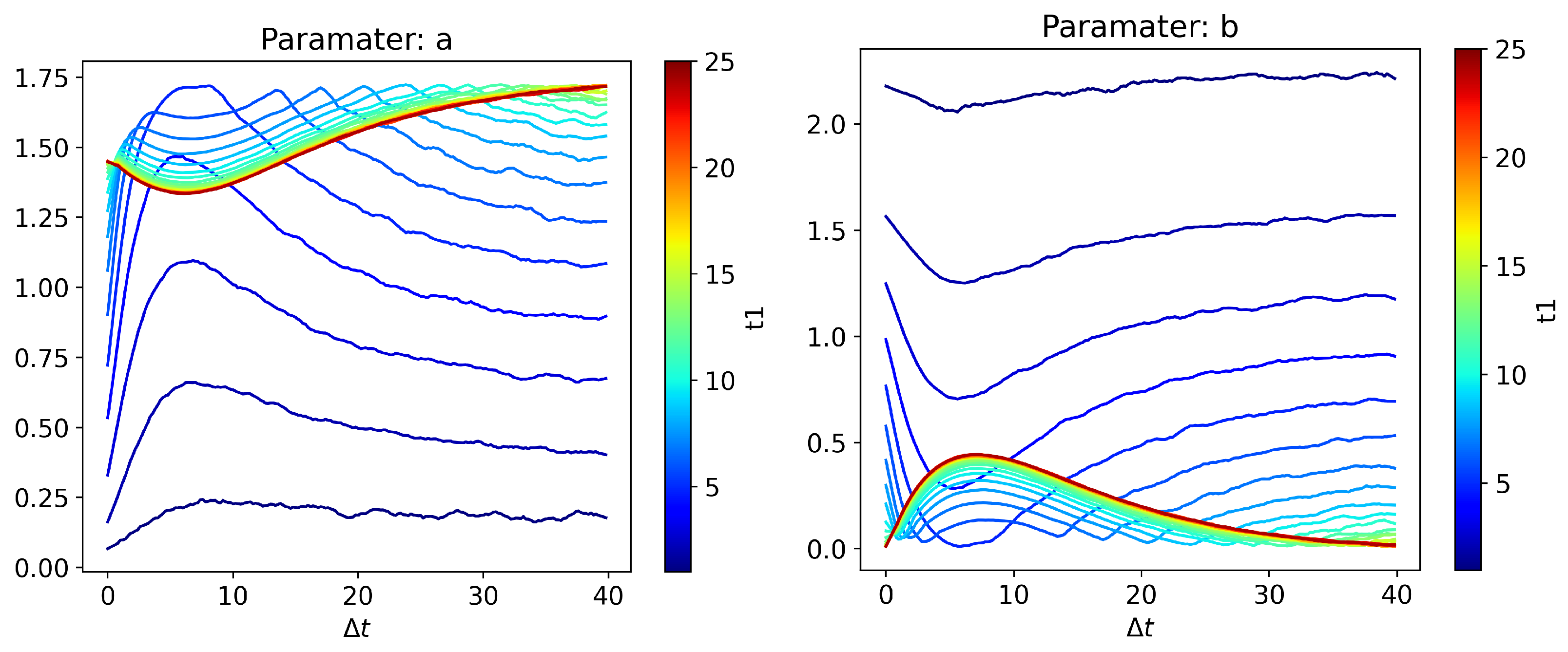
4. Unequal Time Joint PDF: Bimodality for Cubic Force
4.1. Unequal Time PDFs in the Stationary State
4.2. Evolution of Bimodality in the Non-Stationary State
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SDE | Stochastic Differential Equation. |
| FPE | Fokker–Planck Equation. |
| Probability Density Function. | |
| MC | Monte Carlo. |
| GPU | Graphics Processing Unit. |
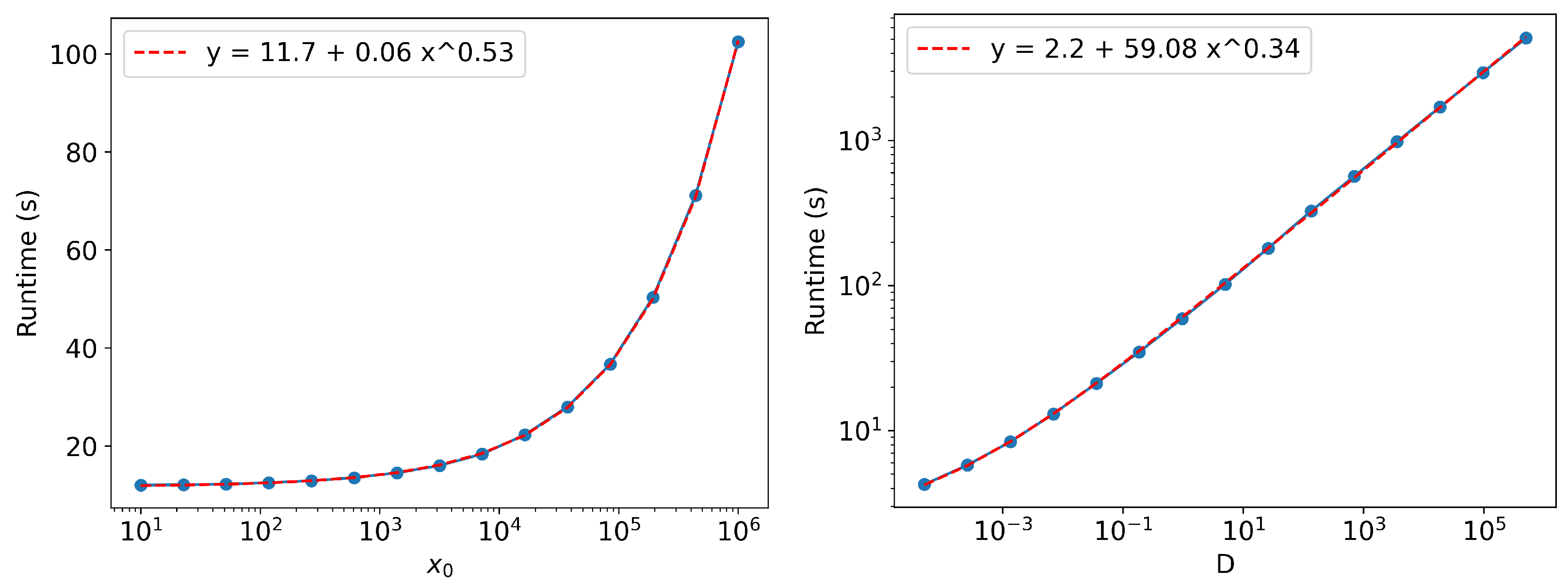
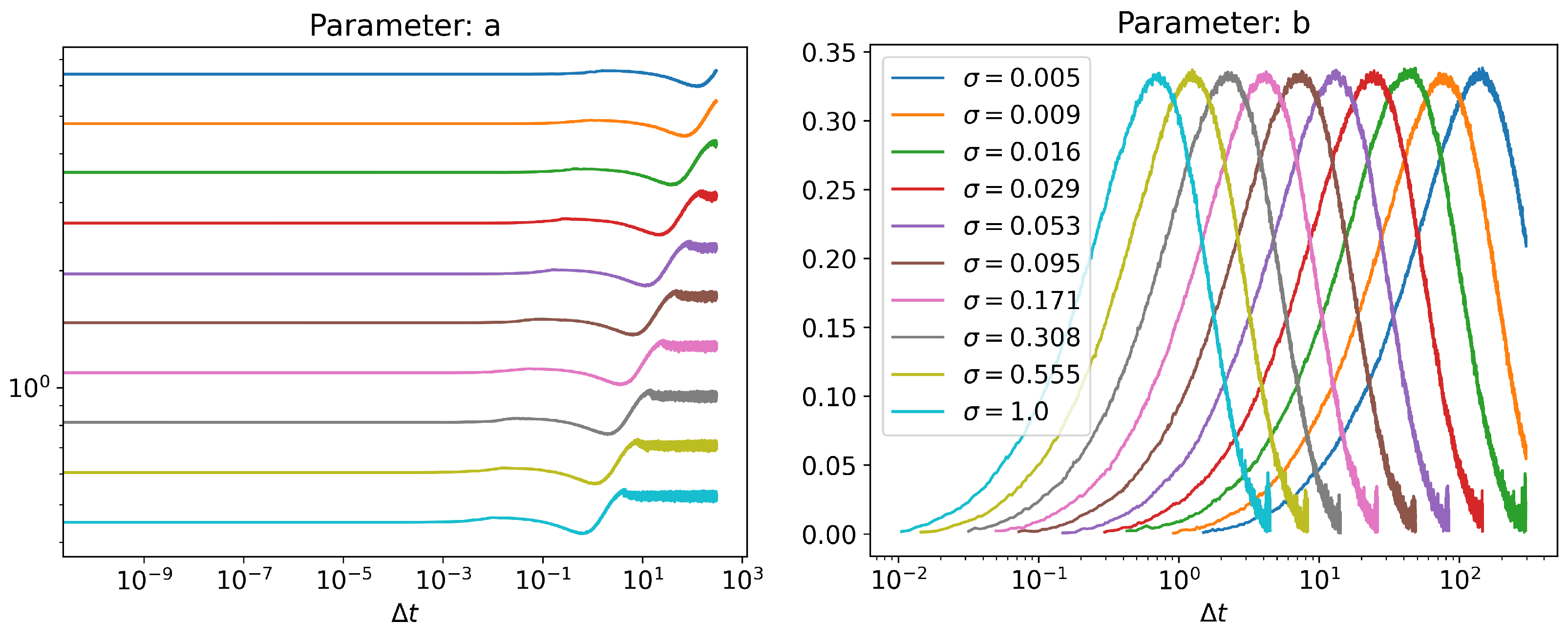
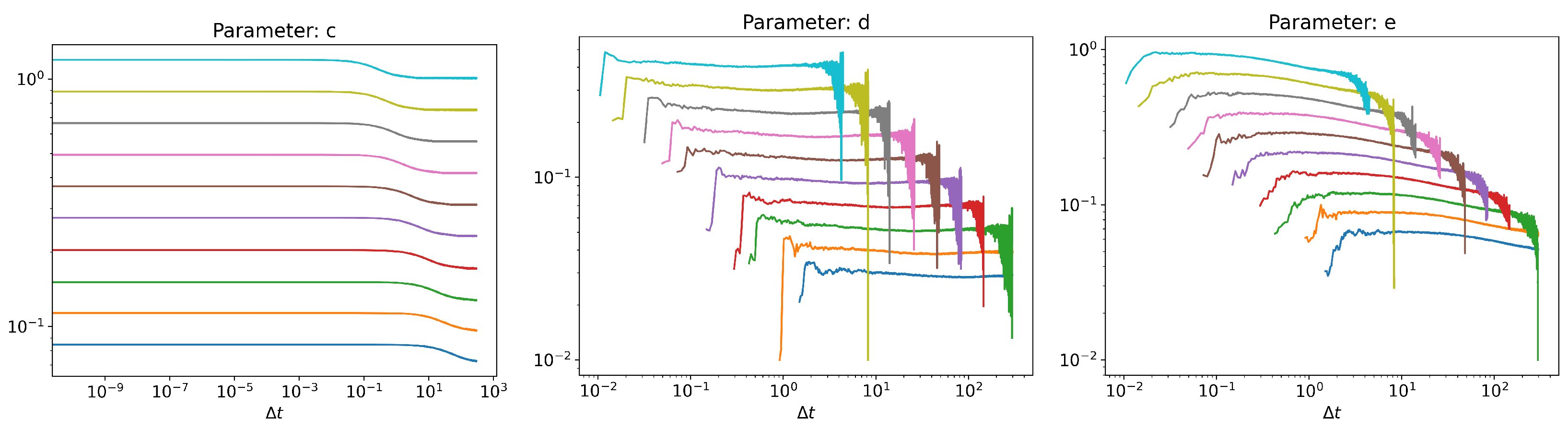
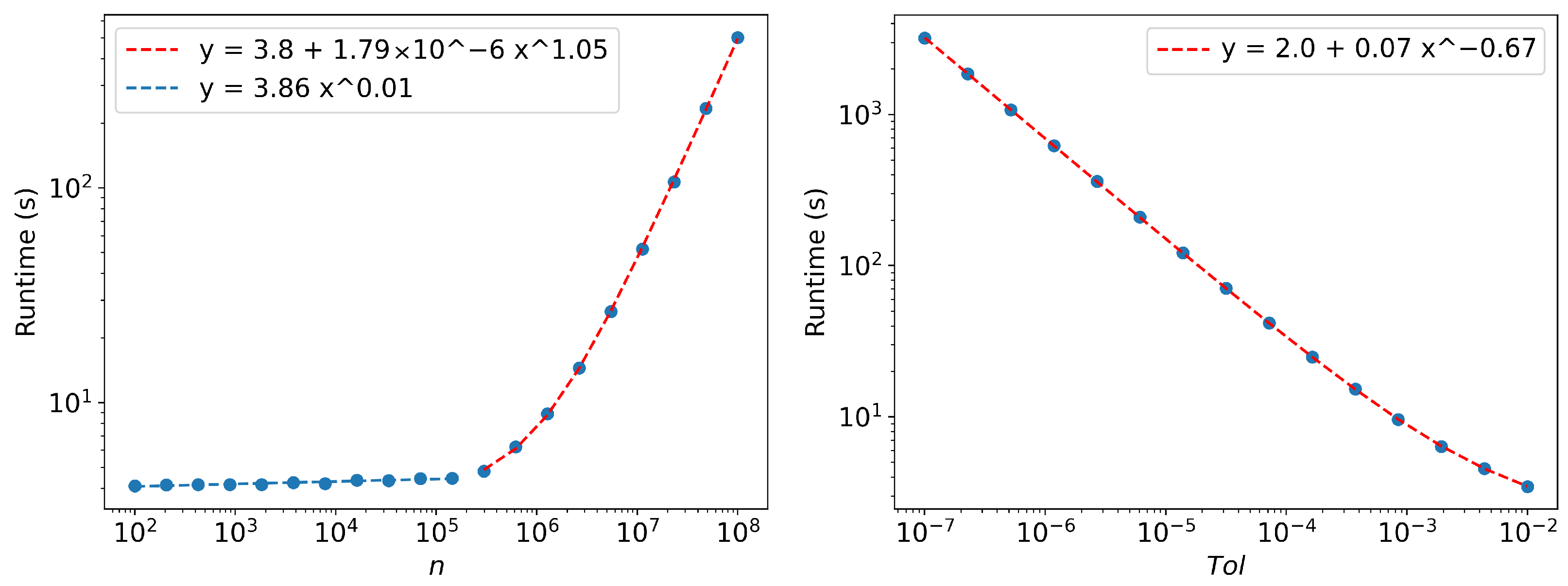
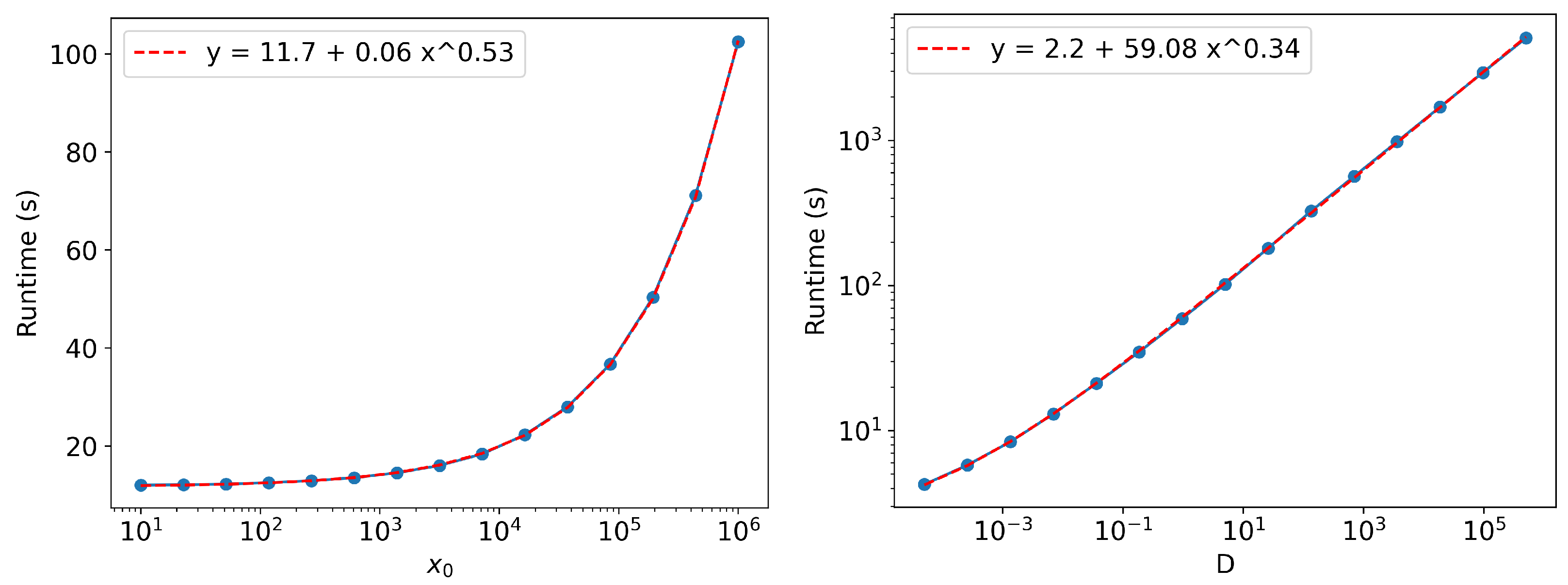
Appendix A. Runtime Scaling

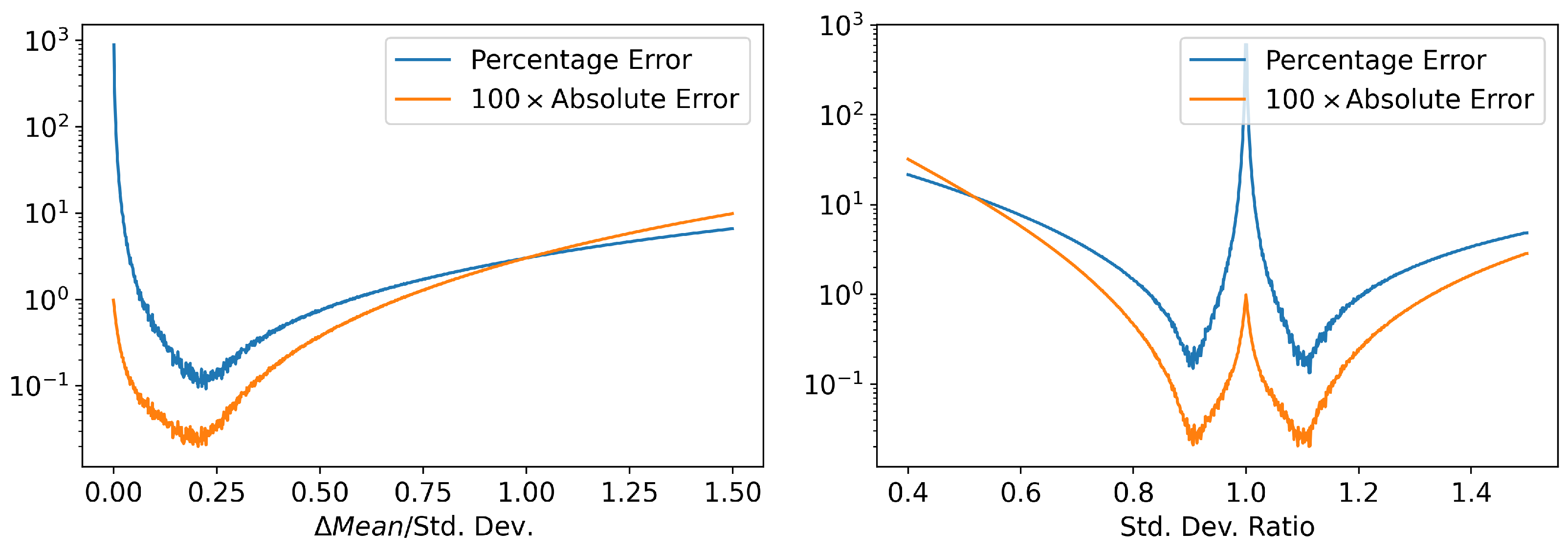
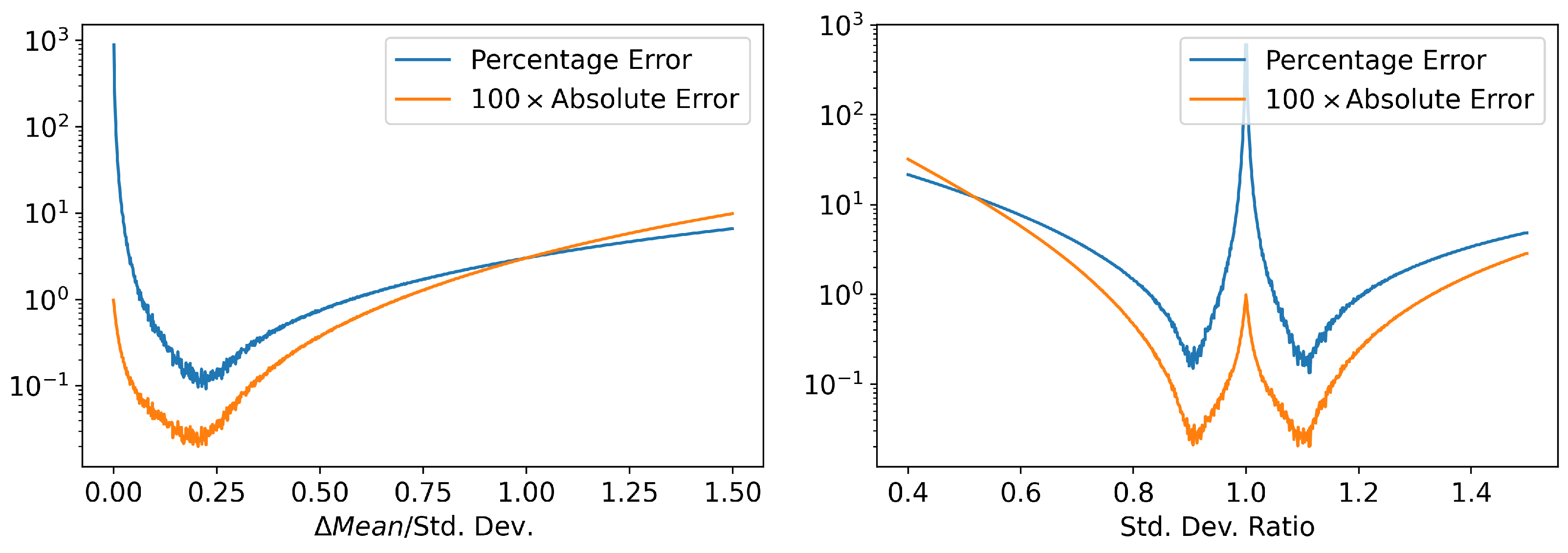
Appendix B. Discretization Error
Appendix C. Jensen’s Equality
Appendix D. OU Process Exact Solution
Appendix E. Γ from KL Divergence
References
- Oksendal, B. Stochastic Differential Equations: An Introduction with Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Sauer, T. Numerical solution of stochastic differential equations in finance. In Handbook of Computational Finance; Springer: Cham, Switzerland, 2012; pp. 529–550. [Google Scholar]
- Panik, M.J. Stochastic Differential Equations: An Introduction with Applications in Population Dynamics Modeling; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Kareem, A.M.; Al-Azzawi, S.N. A stochastic differential equations model for internal COVID-19 dynamics. In Proceedings of the Journal of Physics: Conference Series, Babylon, Iraq, 5–6 December 2020; IOP Publishing: Bristol, UK, 2021; Volume 1818, p. 012121. [Google Scholar]
- Mahrouf, M.; Boukhouima, A.; Zine, H.; Lotfi, E.M.; Torres, D.F.; Yousfi, N. Modeling and forecasting of COVID-19 spreading by delayed stochastic differential equations. Axioms 2021, 10, 18. [Google Scholar] [CrossRef]
- El Koufi, A.; El Koufi, N. Stochastic differential equation model of COVID-19: Case study of Pakistan. Results Phys. 2022, 34, 105218. [Google Scholar] [CrossRef] [PubMed]
- Risken, H. Fokker-planck equation. In The Fokker-Planck Equation; Springer: Cham, Switzerland, 1996; pp. 63–95. [Google Scholar]
- Guel-Cortez, A.J.; Kim, E.j. Information geometric theory in the prediction of abrupt changes in system dynamics. Entropy 2021, 23, 694. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Boston, MA, USA, 2000; Volume 191. [Google Scholar]
- Gibbs, A.L.; Su, F.E. On choosing and bounding probability metrics. Int. Stat. Rev. 2002, 70, 419–435. [Google Scholar] [CrossRef]
- Majtey, A.; Lamberti, P.W.; Martin, M.T.; Plastino, A. Wootters’ distance revisited: A new distinguishability criterium. Eur. Phys. J. At. Mol. Opt. Plasma Phys. 2005, 32, 413–419. [Google Scholar] [CrossRef]
- Diosi, L.; Kulacsy, K.; Lukacs, B.; Racz, A. Thermodynamic length, time, speed, and optimum path to minimize entropy production. J. Chem. Phys. 1996, 105, 11220–11225. [Google Scholar] [CrossRef]
- Ruppeiner, G. Thermodynamics: A Riemannian geometric model. Phys. Rev. A 1979, 20, 1608. [Google Scholar] [CrossRef]
- Gangbo, W.; McCann, R.J. The geometry of optimal transportation. Acta Math. 1996, 177, 113–161. [Google Scholar] [CrossRef]
- Frieden, B.R. Science from Fisher Information; Cambridge University Press: Cambridge, UK, 2004; Volume 974. [Google Scholar]
- Facchi, P.; Kulkarni, R.; Man’ko, V.; Marmo, G.; Sudarshan, E.; Ventriglia, F. Classical and quantum Fisher information in the geometrical formulation of quantum mechanics. Phys. Lett. A 2010, 374, 4801–4803. [Google Scholar] [CrossRef]
- Itoh, M.; Shishido, Y. Fisher information metric and Poisson kernels. Differ. Geom. Appl. 2008, 26, 347–356. [Google Scholar] [CrossRef]
- Wootters, W.K. Statistical distance and Hilbert space. Phys. Rev. D 1981, 23, 357. [Google Scholar] [CrossRef]
- Braunstein, S.L.; Caves, C.M. Statistical distance and the geometry of quantum states. Phys. Rev. Lett. 1994, 72, 3439. [Google Scholar] [CrossRef] [PubMed]
- Cafaro, C.; Alsing, P.M. Information geometry aspects of minimum entropy production paths from quantum mechanical evolutions. Phys. Rev. E 2020, 101, 022110. [Google Scholar] [CrossRef] [PubMed]
- Hollerbach, R.; Kim, E.j.; Schmitz, L. Time-dependent probability density functions and information diagnostics in forward and backward processes in a stochastic prey–predator model of fusion plasmas. Phys. Plasmas 2020, 27, 102301. [Google Scholar] [CrossRef]
- Kim, E.J.; Hollerbach, R. Time-dependent probability density functions and information geometry of the low-to-high confinement transition in fusion plasma. Phys. Rev. Res. 2020, 2, 023077. [Google Scholar] [CrossRef]
- Kim, E.J. Investigating information geometry in classical and quantum systems through information length. Entropy 2018, 20, 574. [Google Scholar] [CrossRef]
- Kim, E.J.; Hollerbach, R. Geometric structure and information change in phase transitions. Phys. Rev. E 2017, 95, 062107. [Google Scholar] [CrossRef]
- Heseltine, J.; Kim, E.j. Comparing information metrics for a coupled Ornstein–Uhlenbeck process. Entropy 2019, 21, 775. [Google Scholar] [CrossRef]
- Kim, E.J.; Heseltine, J.; Liu, H. Information length as a useful index to understand variability in the global circulation. Mathematics 2020, 8, 299. [Google Scholar] [CrossRef]
- Crooks, G.E. Measuring thermodynamic length. Phys. Rev. Lett. 2007, 99, 100602. [Google Scholar] [CrossRef]
- Feng, E.H.; Crooks, G.E. Far-from-equilibrium measurements of thermodynamic length. Phys. Rev. E 2009, 79, 012104. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.J.; Guel-Cortez, A.J. Causal Information Rate. Entropy 2021, 23, 1087. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.J. Information geometry and non-equilibrium thermodynamic relations in the over-damped stochastic processes. J. Stat. Mech. Theory Exp. 2021, 2021, 093406. [Google Scholar] [CrossRef]
- Kim, E.J. Information Geometry, Fluctuations, Non-Equilibrium Thermodynamics, and Geodesics in Complex Systems. Entropy 2021, 23, 1393. [Google Scholar] [CrossRef]
- Brillouin, L. Science and Information Theory; Courier Corporation: Chelmsford, MA, USA, 2013. [Google Scholar]
- Kelly, J.L., Jr. A new interpretation of information rate. In The Kelly Capital Growth Investment Criterion: Theory and Practice; World Scientific: Singapore, 2011; pp. 25–34. [Google Scholar]
- Kim, E.J.; Hollerbach, R. Signature of nonlinear damping in geometric structure of a nonequilibrium process. Phys. Rev. E 2017, 95, 022137. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.j.; Lee, U.; Heseltine, J.; Hollerbach, R. Geometric structure and geodesic in a solvable model of nonequilibrium process. Phys. Rev. E 2016, 93, 062127. [Google Scholar] [CrossRef]
- Scott, D.W.; Sain, S.R. Multidimensional density estimation. Handb. Stat. 2005, 24, 229–261. [Google Scholar]
- Durrett, R. Probability: Theory and Examples; Cambridge University Press: Cambridge, UK, 2019; Volume 49. [Google Scholar]
- Kloeden, P.E.; Platen, E. Stochastic differential equations. In Numerical Solution of Stochastic Differential Equations; Springer: Cham, Switzerland, 1992; pp. 103–160. [Google Scholar]
- Mil’shtejn, G. Approximate integration of stochastic differential equations. Theory Probab. Appl. 1975, 19, 557–562. [Google Scholar] [CrossRef]
- Ilie, S.; Jackson, K.R.; Enright, W.H. Adaptive time-stepping for the strong numerical solution of stochastic differential equations. Numer. Algorithms 2015, 68, 791–812. [Google Scholar] [CrossRef]
- Farber, R. CUDA Application Design and Development; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Thiruthummal, A.A. CUDA Parallel SDE Simulation. 2022. Available online: https://github.com/keygenx/SDE-Sim (accessed on 6 June 2022).
- Chen, Y.C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the Brownian motion. Phys. Rev. 1930, 36, 823. [Google Scholar] [CrossRef]
- Gutiérrez, R.; Gutiérrez-Sánchez, R.; Nafidi, A.; Ramos, E. A diffusion model with cubic drift: Statistical and computational aspects and application to modelling of the global CO2 emission in Spain. Environ. Off. Int. Environ. Soc. 2007, 18, 55–69. [Google Scholar] [CrossRef]
- Newton, A.P.; Kim, E.J.; Liu, H.L. On the self-organizing process of large scale shear flows. Phys. Plasmas 2013, 20, 092306. [Google Scholar] [CrossRef]
- Kim, E.J.; Hollerbach, R. Time-dependent probability density function in cubic stochastic processes. Phys. Rev. E 2016, 94, 052118. [Google Scholar] [CrossRef]
- Heer, J. Fast & accurate gaussian kernel density estimation. In Proceedings of the 2021 IEEE Visualization Conference (VIS) IEEE, New Orleans, LA, USA, 24–29 October 2021; pp. 11–15. [Google Scholar]
- Silverman, B.W. Algorithm AS 176: Kernel density estimation using the fast Fourier transform. J. R. Stat. Soc. Ser. (Appl. Stat.) 1982, 31, 93–99. [Google Scholar] [CrossRef]
- Cruz-Uribe, D.; Neugebauer, C. An elementary proof of error estimates for the trapezoidal rule. Math. Mag. 2003, 76, 303–306. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid-Based FPE Solver | MC SDE Simulation | |
|---|---|---|
| Accuracy | Depends on grid size. No well-defined prescription on choosing grid-size. | Depends on number of samples(n) [36]. Typically less accurate for practical sample sizes. |
| Boundary condition | Requires carefully chosen non-trivial boundary conditions. Cannot handle discontinuous initial conditions such as Dirac delta function. | Requires only an initial distribution as boundary condition. |
| Memory Usage & Runtime | Scales exponentially with dimension d. . Here, are the number of grid points along each dimension. | Scales linearly with dimension d. . Here, n is the number of samples. |
| Correlation Study | Cannot study correlations and associated memory effects using FPE. | Can study correlations. See Section 4 for unequal time joint PDF estimates. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thiruthummal, A.A.; Kim, E.-j. Monte Carlo Simulation of Stochastic Differential Equation to Study Information Geometry. Entropy 2022, 24, 1113. https://doi.org/10.3390/e24081113
Thiruthummal AA, Kim E-j. Monte Carlo Simulation of Stochastic Differential Equation to Study Information Geometry. Entropy. 2022; 24(8):1113. https://doi.org/10.3390/e24081113
Chicago/Turabian StyleThiruthummal, Abhiram Anand, and Eun-jin Kim. 2022. "Monte Carlo Simulation of Stochastic Differential Equation to Study Information Geometry" Entropy 24, no. 8: 1113. https://doi.org/10.3390/e24081113
APA StyleThiruthummal, A. A., & Kim, E.-j. (2022). Monte Carlo Simulation of Stochastic Differential Equation to Study Information Geometry. Entropy, 24(8), 1113. https://doi.org/10.3390/e24081113