
An Improved Temporal Fusion Transformers Model for Predicting Supply Air Temperature in High-Speed Railway Carriages


Abstract
:1. Introduction
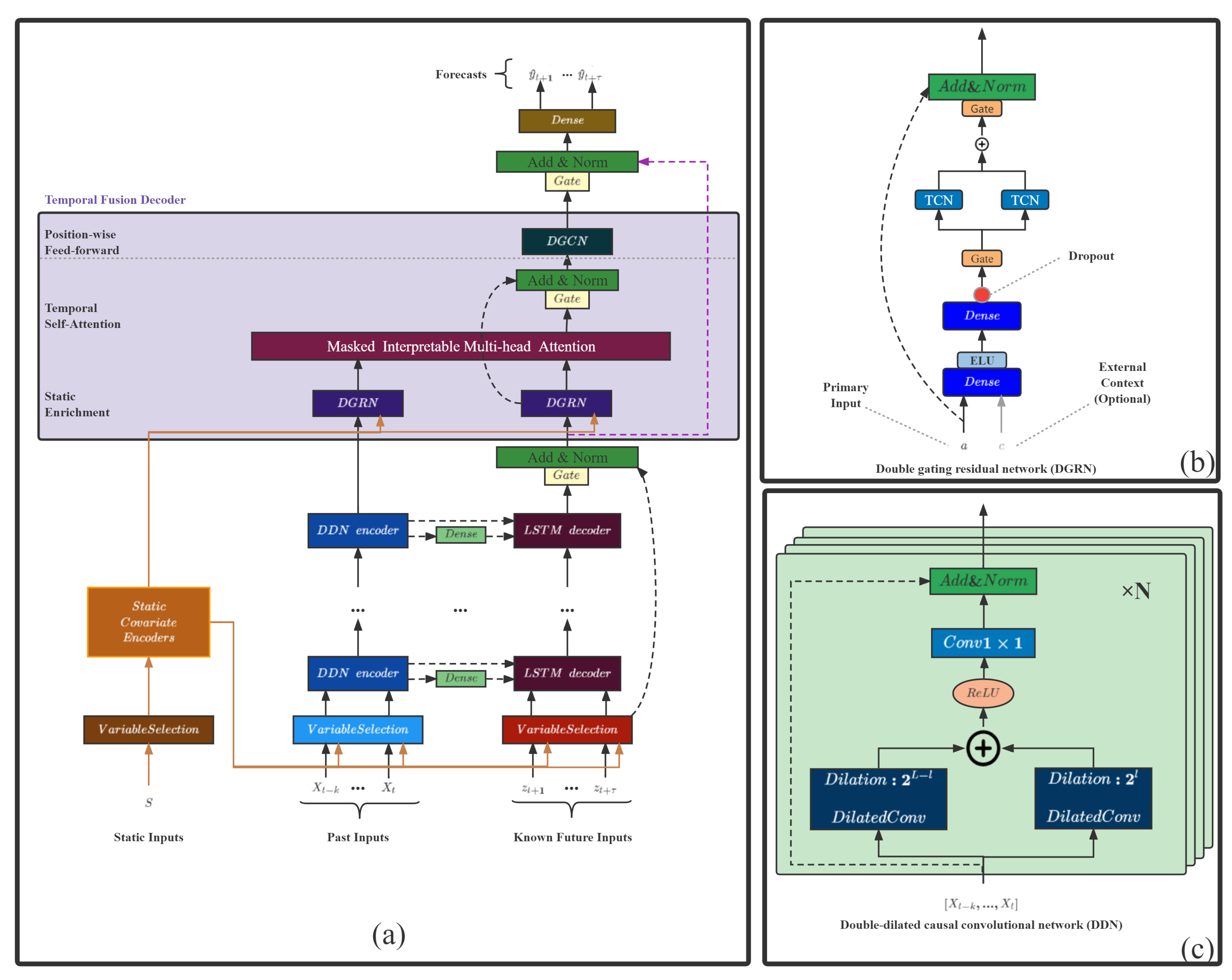
- Double-dilated causal convolutional network (DDN), two causal convolutions with different dilation factor sizes, forms a layer of DDN. A multi-layer DDN structure includes a new known variable encoder component to replace the LSTM encoder structure;
- Double gating residual network (DGRN), a temporal convolution structure, is added to the original gated residual network to minimize the influence of irrelevant variables and variable moments.
2. Methodology
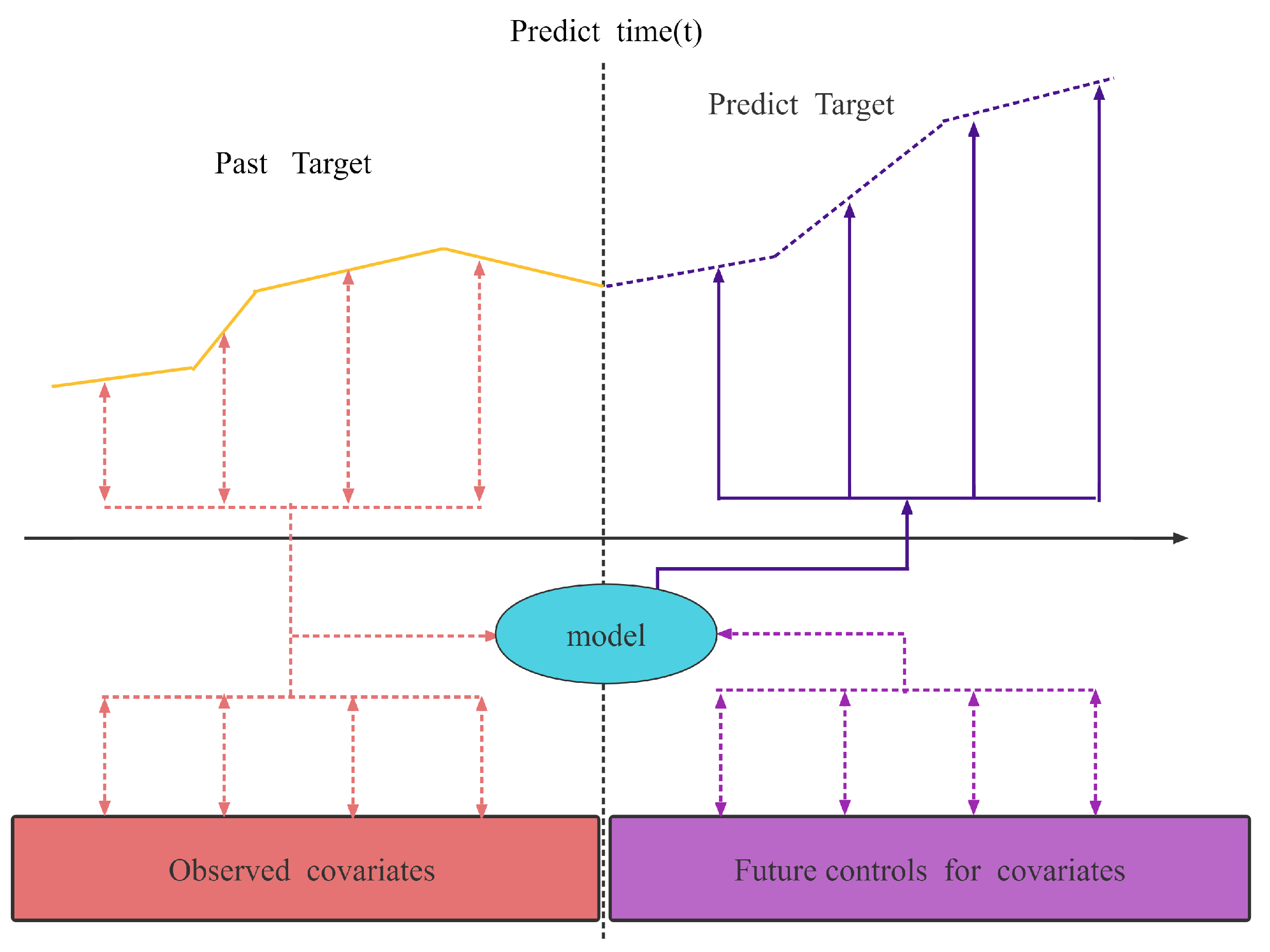
2.1. Time Series Forecasting Problem
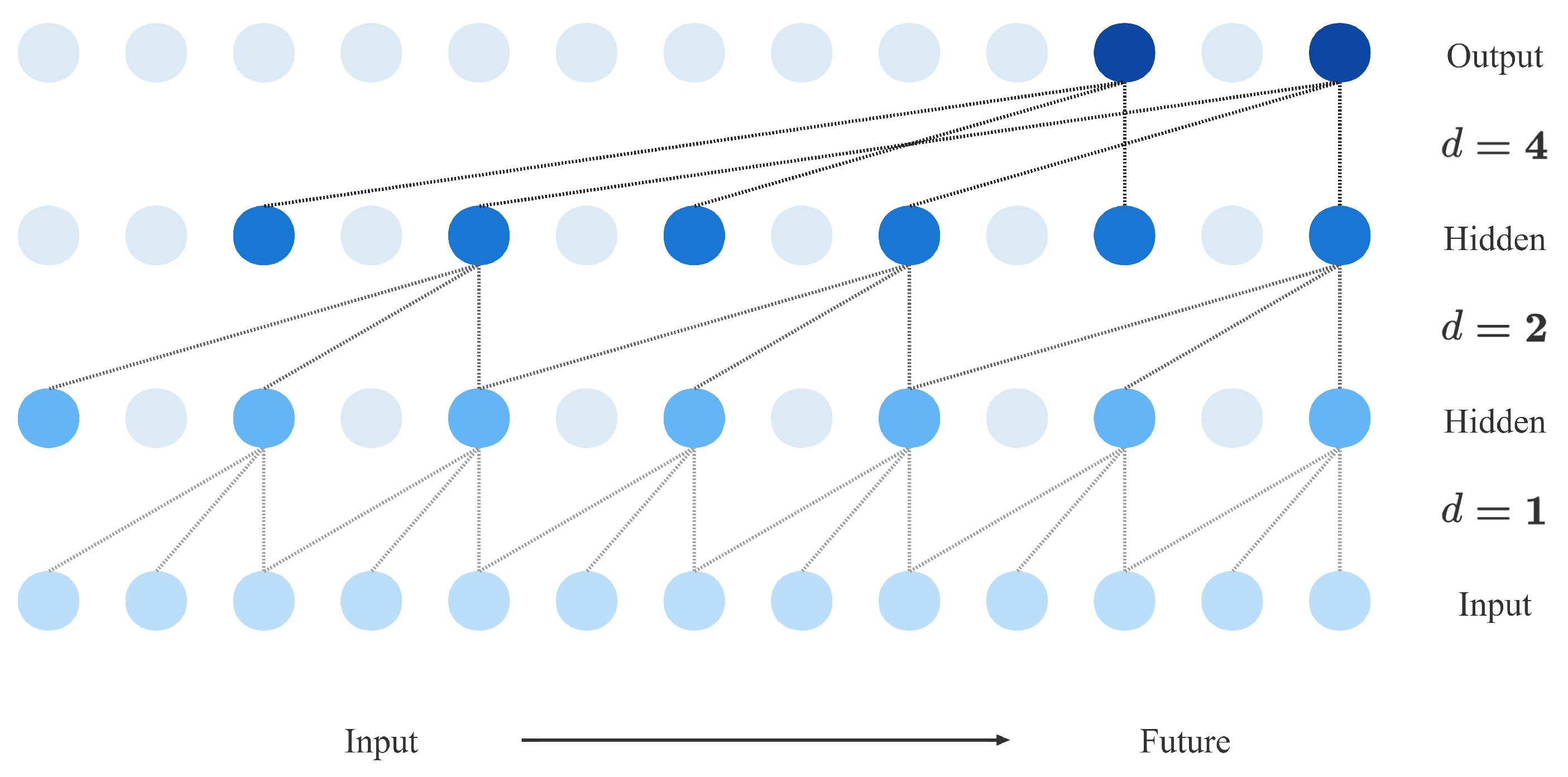
2.2. Temporal Convolutional Neural Network
2.3. Interpretable Multi-Head Attention
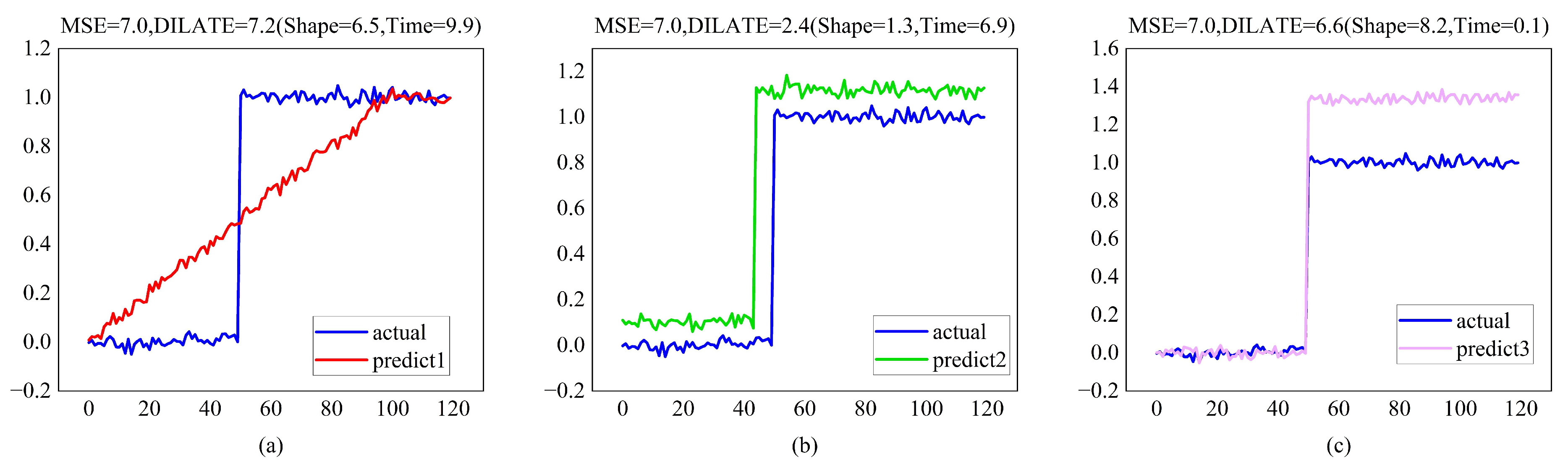
2.4. Shape and Time Distortion Loss Function
- Shape loss:where is the set of calibration matrices for two sequences of length n, which represent the range from to all paths. is a path in . is the cost matrix composed of two sequences, and is the cost of the corresponding position. Equations (15) and (16) are the “optimal” paths for solving the two sequences, where is a hyperparameter, and when it is zero, the solution process is non-differentiable.
- Temporal loss:where is a square matrix of size penalizing each element being associated with an , for . is the “optimal” path obtained by computing . For , the purpose is to penalize the matching with excessive delay in the DTW algorithm.
3. Improved Temporal Fusion Transformers Model
- Double-dilated causal convolutional network (DDN): a double-convolutional residual encoder structure based on dilated causal convolution, which has a flexible receptive field; the double-convolutional structure enables shallow layers to capture local and distant information; and its residual structure solves the problem of gradient explosion in deep networks.
- Double gating residual network (DGRN): The spatio-temporal double-gated structure based on Gated Linear Units aims to select items related to the target from the spatial and temporal dimensions and eliminate the influence of noise in the data. The time-gated structure is based on two TCN structures, and the space-gated structure is based on the gated residual network in TFT.
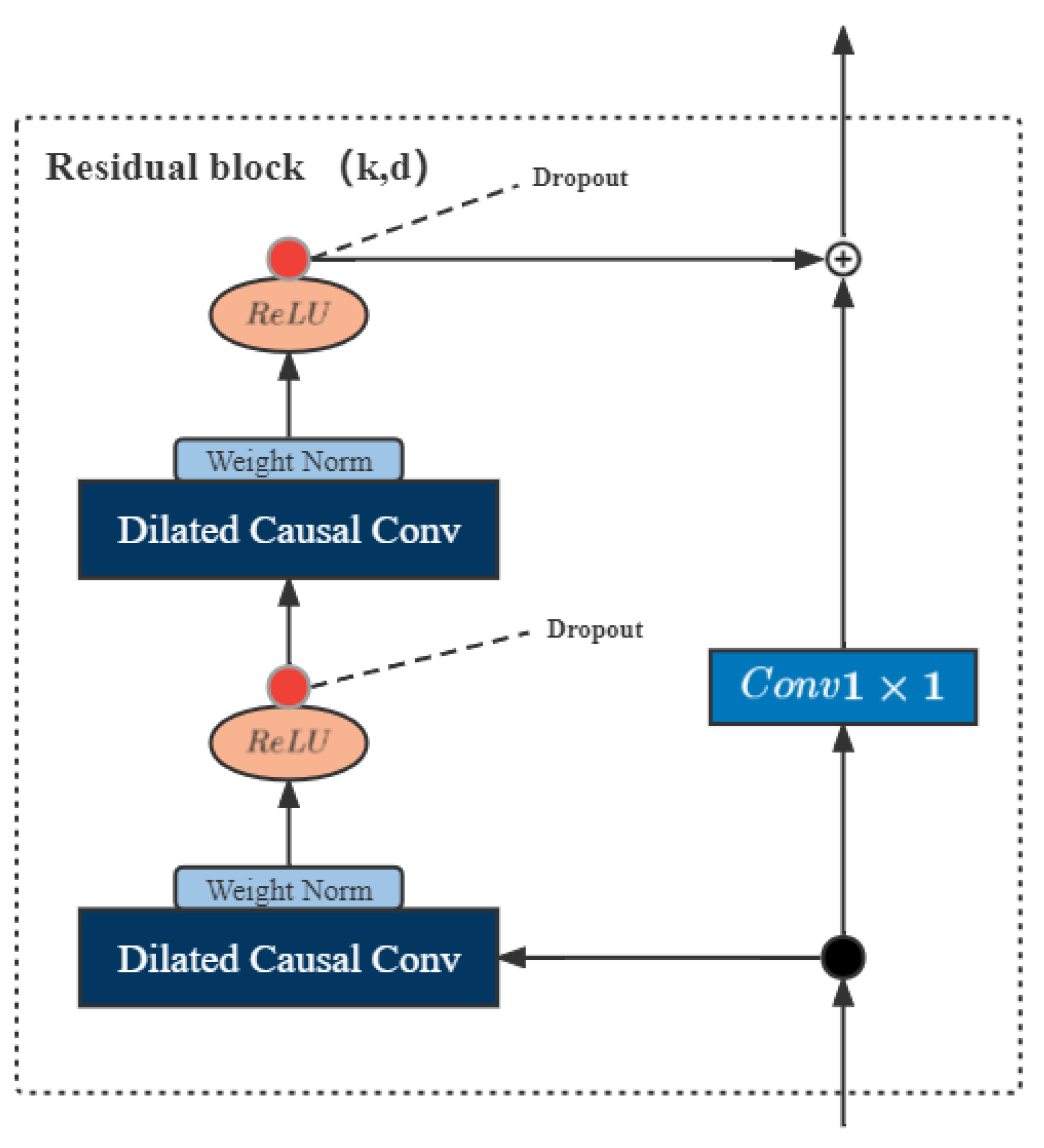
3.1. Double-Dilated Causal Convolutional Network
3.2. Double Gating Residual Network
3.3. Improved TFT Model
- Variable selection networks:The variable selection network based on the GRN gated residual network can offer insights into which variables are the most critical to the prediction problem.
- Static covariate encoders:The static covariate encoder network integrates static feature variables into the network, through the encoding of context vectors to condition temporal dynamics.
- Interpretable multi-head attention:Interpretable multi-head attention is an interpretable multi-head attention mechanism that learns long-term relationships between different time steps.
4. Loss Function
5. Experimental Results and Discussion
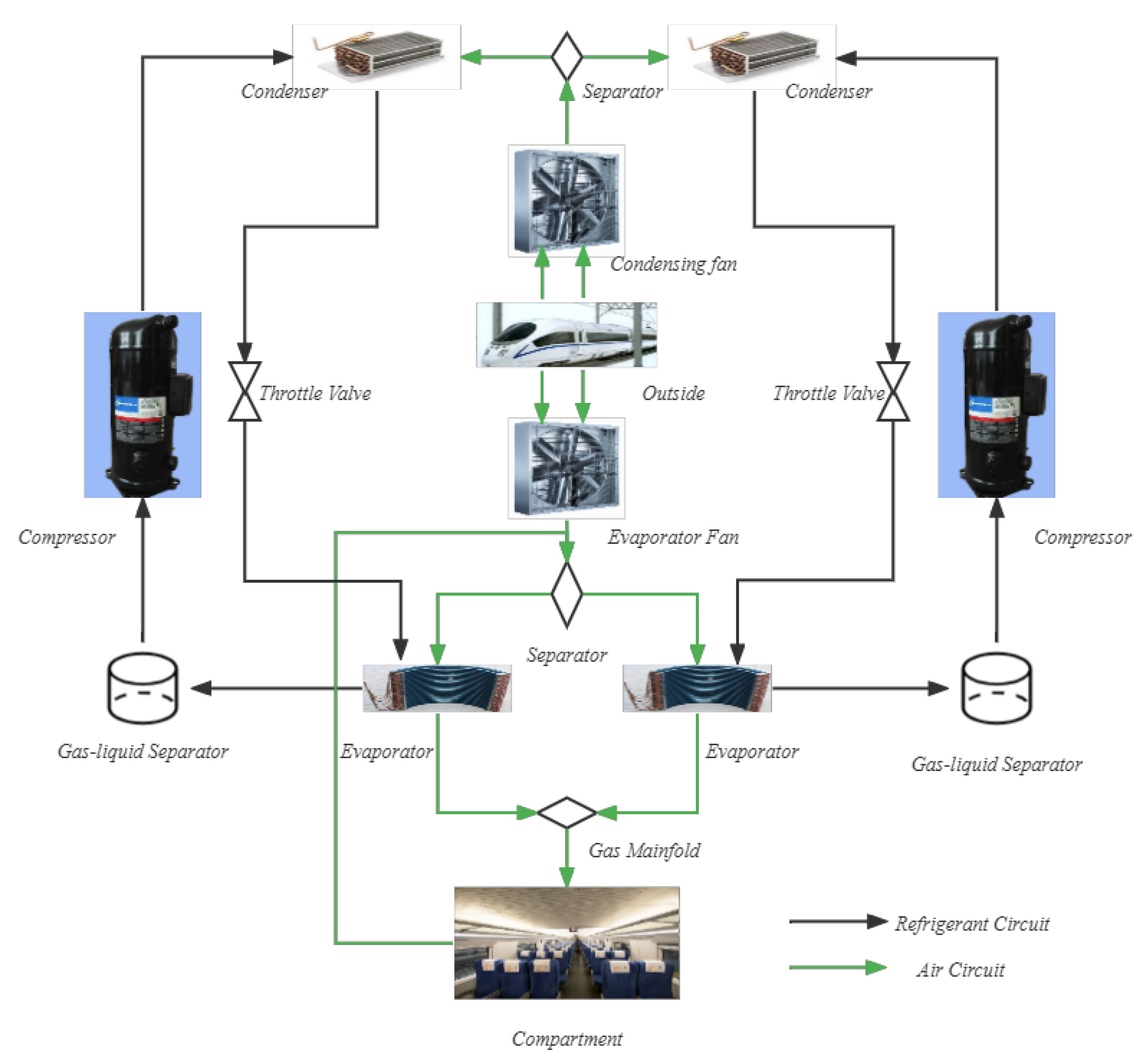
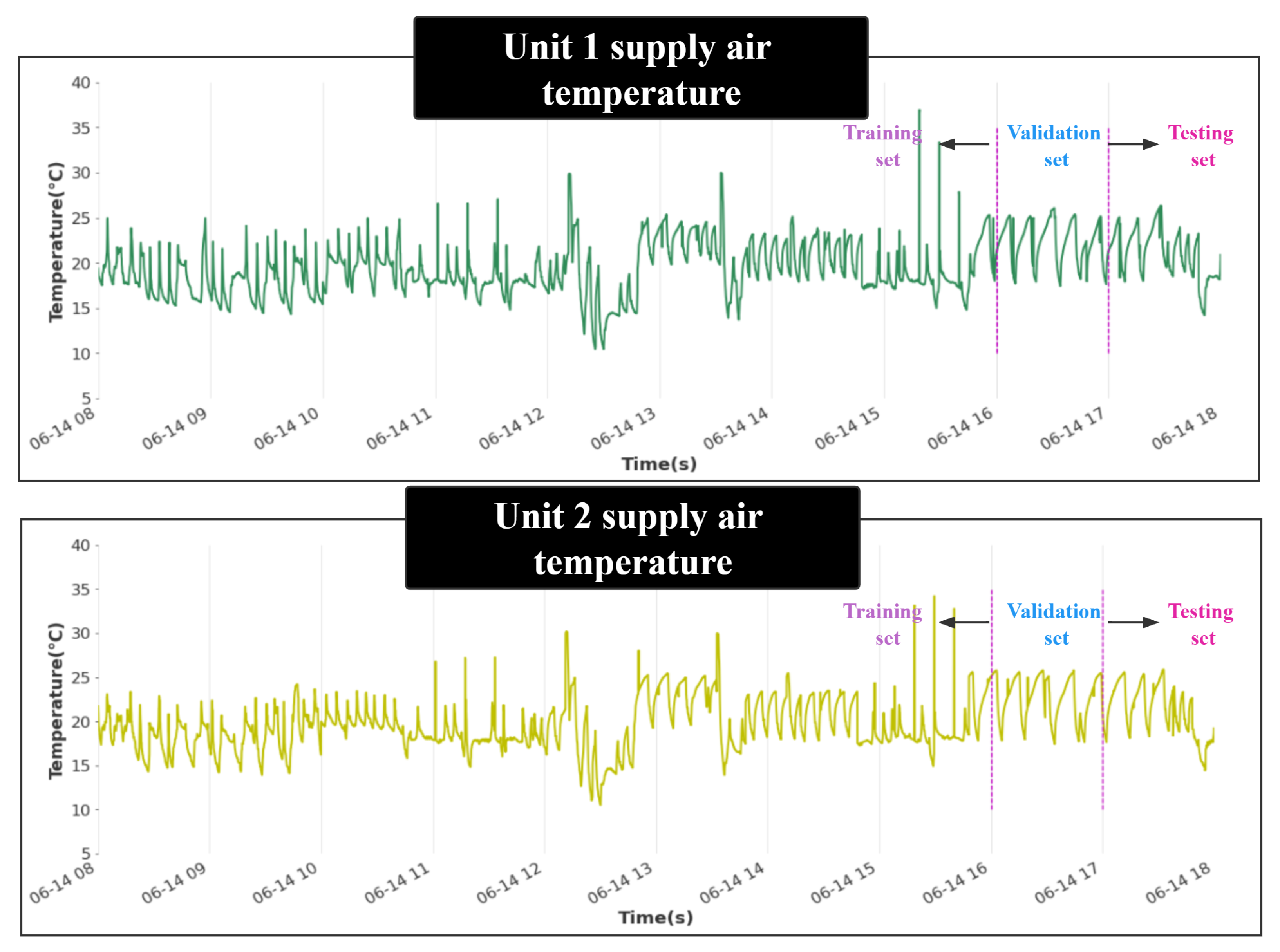
5.1. Data Descriptions and Pre-Processing
5.2. Parameter Setting
5.3. Evaluation Metrics
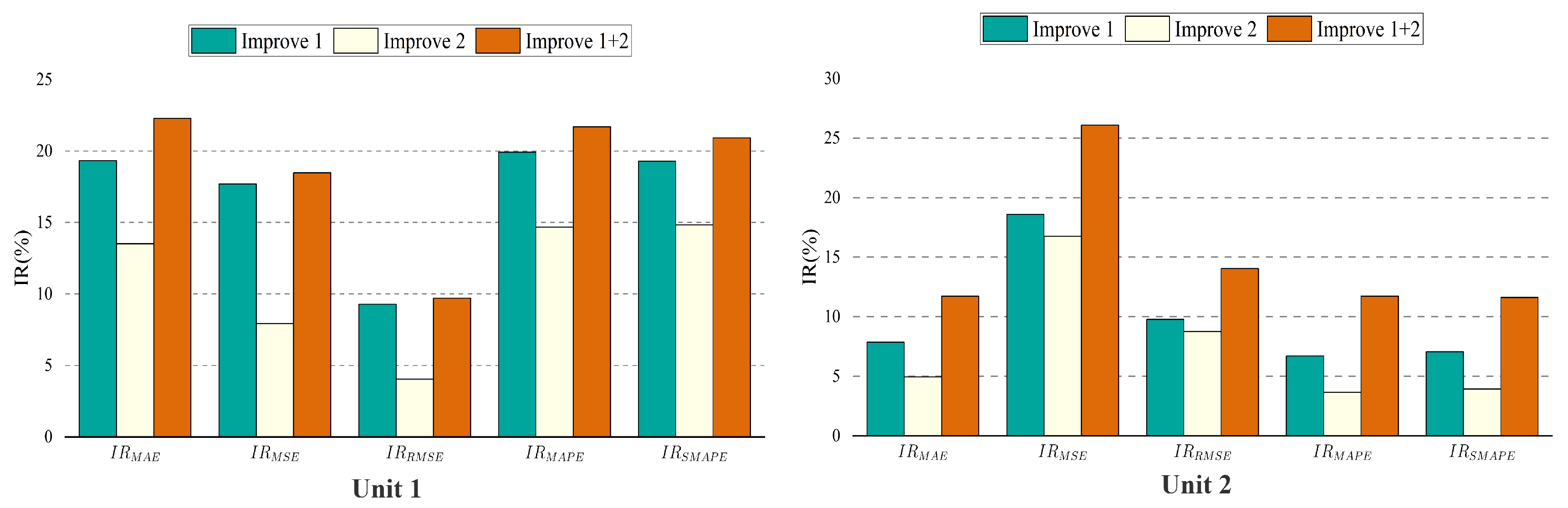
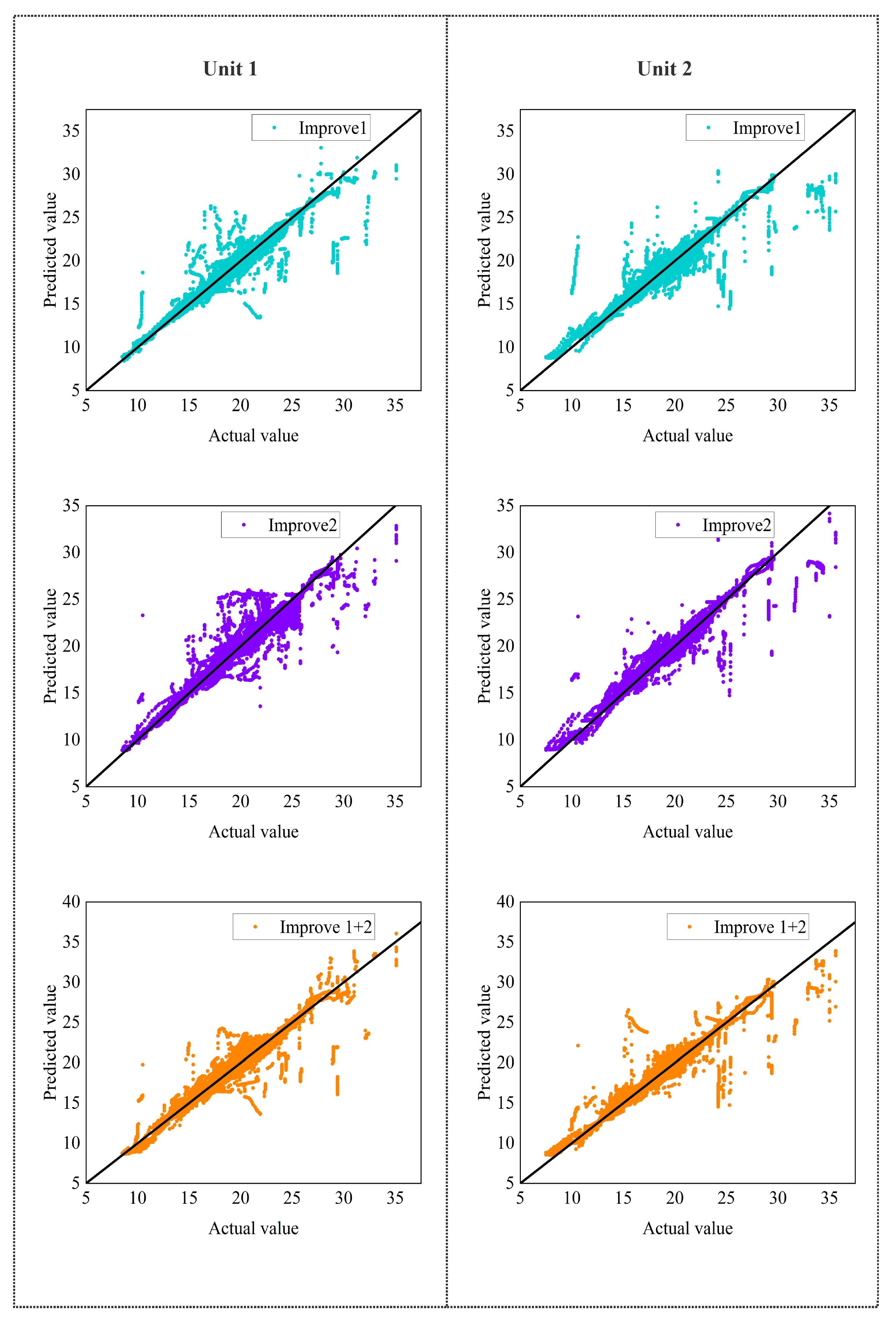
5.4. Ablation Analysis
- (1)
- (2)
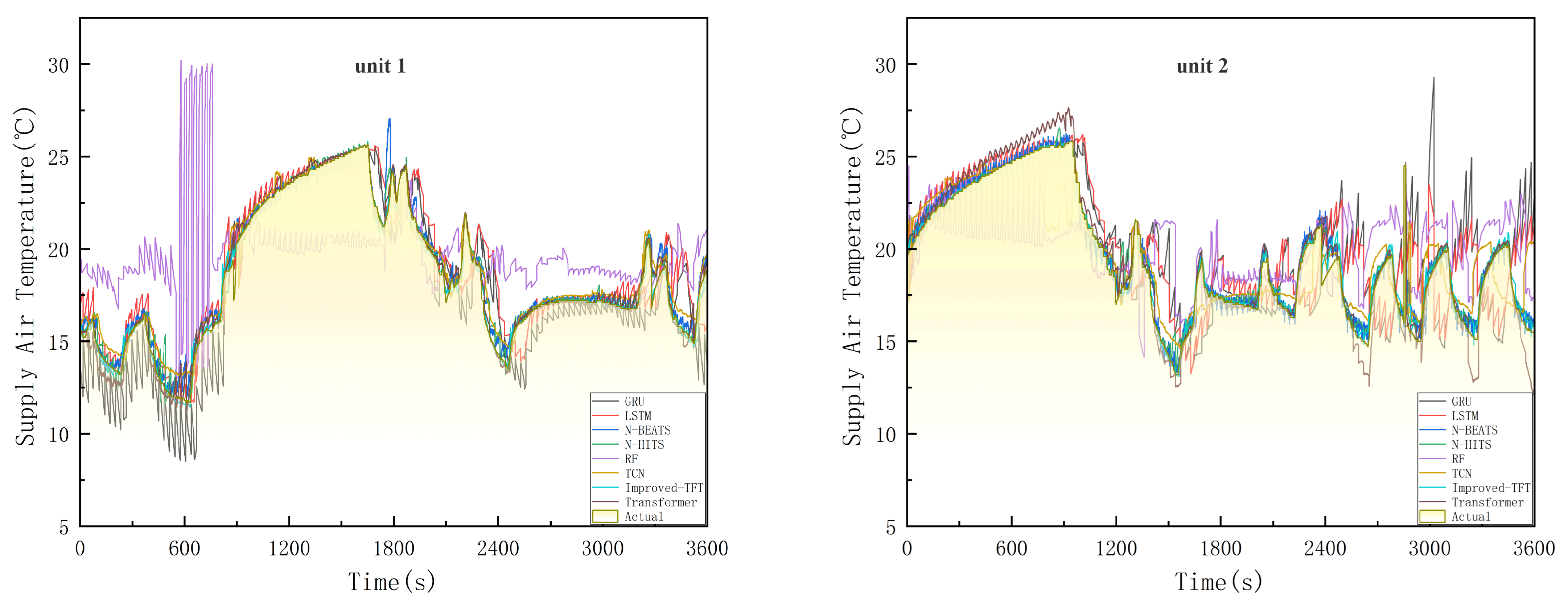
5.5. Results and Discussion
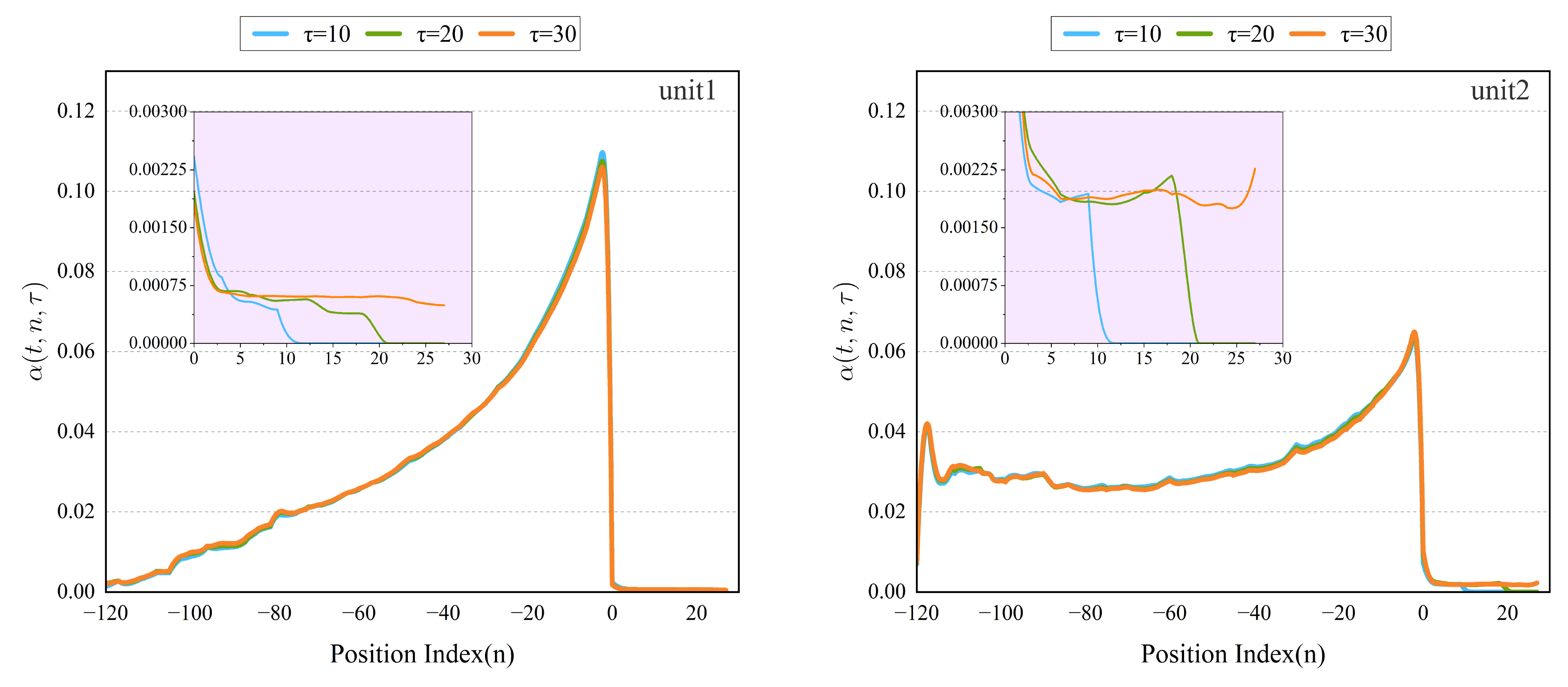
5.6. Interpretability Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lawrence, M.; Bullock, R.; Liu, Z.M. China’s High-Speed Rail Development; World Bank Publications: Washington, DC, USA, 2019. [Google Scholar]
- Ding, T.; Lin, J.; Chen, X. Comfort evaluation and analysis of high-speed train. J. Phys. Conf. Ser. 2021, 1986, 012089. [Google Scholar] [CrossRef]
- Yin, M.; Li, K.; Cheng, X. A review on artificial intelligence in high-speed rail. J. Transp. Saf. Secur. 2020, 2, 247–259. [Google Scholar] [CrossRef]
- Filipa Pinheiro da Silva, P.; Mendes, J. Passengers Comfort Perception and Demands on Railway Vehicles: A Review. KEG 2020, 5, 257–270. [Google Scholar] [CrossRef]
- Li, W. Simplified steady-state modeling for variable speed compressor. Appl. Therm. Eng. 2013, 50, 318–326. [Google Scholar] [CrossRef]
- Mbamalu, G.A.N.; El-Hawary, M.E. Load forecasting via suboptimal seasonal autoregressive models and iteratively reweighted least squares estimation. IEEE Trans. Power Syst. 1993, 8, 343–348. [Google Scholar] [CrossRef]
- Xu, T.; Xu, X.; Hu, Y.; Li, X. An Entropy-Based Approach for Evaluating Travel Time Predictability Based on Vehicle Trajectory Data. Entropy 2017, 19, 165. [Google Scholar] [CrossRef]
- Chang, H.; Zhang, Y.; Chen, L. Gray forecast of Diesel engine performance based on wear. Appl. Therm. Eng. 2003, 23, 2285–2292. [Google Scholar] [CrossRef]
- Chiang, C.J.; Yang, J.L.; Cheng, W.C. Temperature and state-of-charge estimation in ultracapacitors based on extended Kalman filter. J. Power Sour. 2013, 234, 234–243. [Google Scholar] [CrossRef]
- Maatallah, O.A.; Achuthan, A.; Janoyan, K.; Marzocca, P. Recursive wind speed forecasting based on Hammerstein Auto-Regressive model. Appl. Energy 2015, 145, 191–197. [Google Scholar] [CrossRef]
- Lee, S.; Kim, C.K.; Kim, D. Monitoring Volatility Change for Time Series Based on Support Vector Regression. Entropy 2020, 22, 1312. [Google Scholar] [CrossRef] [PubMed]
- Dudek, G. Short-term load forecasting using random forests. In Proceedings of the 7th IEEE International Conference Intelligent Systems IS’2014 (Advances in Intelligent Systems and Computing), Warsaw, Poland, 24–26 September 2014; Filev, D., Jabłkowski, J., Kacprzyk, J., Krawczak, M., Popchev, I., Rutkowski, L., Sgurev, V., Sotirova, E., Szynkarczyk, P., Zadrozny, S., Eds.; Springer: Cham, Switzerland, 2015; Volume 323, pp. 821–828. [Google Scholar]
- Gumus, M.; Kiran, M.S. Crude oil price forecasting using XGBoost. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–7 October 2017; pp. 1100–1103. [Google Scholar]
- Hotait, H.; Chiementin, X.; Rasolofondraibe, L. Intelligent Online Monitoring of Rolling Bearing: Diagnosis and Prognosis. Entropy 2021, 23, 791. [Google Scholar] [CrossRef] [PubMed]
- Muzaffar, S.; Afshari, A. Short-term load forecasts using LSTM networks. Energy Procedia 2019, 158, 2922–2927. [Google Scholar] [CrossRef]
- Jiang, Q.; Tang, C.; Chen, C.; Wang, X.; Huang, Q. Stock price forecast based on LSTM neural network. In Proceedings of the Twelfth International Conference on Management Science and Engineering Management, Melbourne, Australia, 1–4 August 2018; pp. 393–408. [Google Scholar]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef]
- Yang, Y.; Lu, J. A Fusion Transformer for Multivariable Time Series Forecasting: The Mooney Viscosity Prediction Case. Entropy 2022, 24, 528. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. arXiv 2019, arXiv:1907.00235. [Google Scholar]
- Lim, B.; Arik, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Guen, V.L.; Thome, N. Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models. arXiv 2019, arXiv:1909.09020. [Google Scholar]
- Bai, S.J.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Li, S.J.; AbuFarha, Y.; Liu, Y.; Cheng, M.M.; Gall, J. Ms-tcn++: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Zhang, S.; Fang, W. Multifractal Behaviors of Stock Indices and Their Ability to Improve Forecasting in a Volatility Clustering Period. Entropy 2021, 23, 1018. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Challu, C.; Olivares, K.G.; Oreshkin, B.N.; Garza, F.; Mergenthaler, M.; Dubrawski, A. N-hits: Neural hierarchical interpolation for time series forecasting. arXiv 2022, arXiv:2201.12886. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariates | Unit 1 Supply Air Temperature | Unit 2 Supply Air Temperature | |||
|---|---|---|---|---|---|
| Pearson | Spearman | Pearson | Spearman | ||
| Unit 1 | Condensing Inlet Air Temperature | −0.466 | −0.478 | −0.493 | −0.518 |
| Outdoor fan frequency | −0.527 | −0.568 | −0.329 | −0.369 | |
| Compressor 1 inverter frequency | −0.438 | −0.420 | −0.282 | −0.267 | |
| Compressor 2 inverter frequency | −0.427 | −0.395 | −0.297 | −0.294 | |
| Electronic expansion valve 1 | −0.337 | −0.333 | −0.265 | −0.225 | |
| Electronic expansion valve 2 | −0.392 | −0.411 | −0.335 | −0.341 | |
| Suction temperature 1 | 0.523 | 0.538 | 0.458 | 0.457 | |
| Suction temperature 2 | 0.466 | 0.504 | 0.432 | 0.475 | |
| Unit 2 | Condensing Inlet Air Temperature | −0.463 | −0.490 | −0.470 | −0.510 |
| Outdoor fan frequency | −0.426 | −0.452 | −0.566 | −0.593 | |
| Compressor 1 inverter frequency | −0.317 | −0.295 | −0.454 | −0.417 | |
| Compressor 2 inverter frequency | −0.344 | −0.331 | −0.444 | −0.408 | |
| Electronic expansion valve 1 | −0.186 | −0.099 | −0.221 | −0.197 | |
| Electronic expansion valve 2 | −0.316 | −0.294 | −0.366 | −0.363 | |
| Suction temperature 1 | 0.389 | 0.383 | 0.507 | 0.559 | |
| Suction temperature 2 | 0.451 | 0.447 | 0.548 | 0.569 | |
| Parameter | Unit 1 | Unit 2 |
|---|---|---|
| Number of time steps | 30 | 30 |
| Number of DDN encoder layers | 4 | 4 |
| Number of batch sizes | 64 | 256 |
| State size | 64 | 64 |
| Learning rates | 0.01 | 0.01 |
| Number of attention heads | 4 | 4 |
| Dropout rate | 0.2 | 0.2 |
| Loss Function | 0.8 | 0.9 |
| Loss Function | 0.01 | 0.01 |
| Loss Function | 0.1 | 0.05 |
| Model | Unit 1 | Unit 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | RMSE | MAPE | SMAPE | MAE | MSE | RMSE | MAPE | SMAPE | |
| RF | 1.54 | 5.42 | 2.33 | 8.64% | 8.18% | 1.51 | 5.73 | 2.39 | 8.71% | 8.07% |
| LSTM | 2.33 | 11.48 | 3.39 | 13.00% | 12.31% | 2.66 | 15.34 | 3.92 | 15.06% | 13.87% |
| GRU | 2.38 | 11.52 | 3.39 | 13.10% | 12.89% | 2.68 | 15.29 | 3.91 | 15.03% | 14.21% |
| TCN | 0.59 | 1.32 | 1.15 | 3.19% | 3.18% | 0.62 | 1.50 | 1.23 | 3.34% | 3.31% |
| Transformer | 0.36 | 0.84 | 0.91 | 1.91% | 1.93% | 0.48 | 1.42 | 1.19 | 2.53% | 2.57% |
| N-BEATS | 0.39 | 0.93 | 0.97 | 2.09% | 2.10% | 0.45 | 1.35 | 1.16 | 2.33% | 2.35% |
| N-HITS | 0.39 | 0.96 | 0.98 | 2.11% | 2.12% | 0.43 | 1.36 | 1.17 | 2.35% | 2.33% |
| OURS | 0.23 | 0.37 | 0.60 | 1.20% | 1.21% | 0.24 | 0.48 | 0.69 | 1.31% | 1.30% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, G.; Zhang, L.; Ai, F.; Zhang, Y.; Hou, Y. An Improved Temporal Fusion Transformers Model for Predicting Supply Air Temperature in High-Speed Railway Carriages. Entropy 2022, 24, 1111. https://doi.org/10.3390/e24081111
Feng G, Zhang L, Ai F, Zhang Y, Hou Y. An Improved Temporal Fusion Transformers Model for Predicting Supply Air Temperature in High-Speed Railway Carriages. Entropy. 2022; 24(8):1111. https://doi.org/10.3390/e24081111
Chicago/Turabian StyleFeng, Guoce, Lei Zhang, Feifan Ai, Yirui Zhang, and Yupeng Hou. 2022. "An Improved Temporal Fusion Transformers Model for Predicting Supply Air Temperature in High-Speed Railway Carriages" Entropy 24, no. 8: 1111. https://doi.org/10.3390/e24081111
APA StyleFeng, G., Zhang, L., Ai, F., Zhang, Y., & Hou, Y. (2022). An Improved Temporal Fusion Transformers Model for Predicting Supply Air Temperature in High-Speed Railway Carriages. Entropy, 24(8), 1111. https://doi.org/10.3390/e24081111