Anomaly Detection for Individual Sequences with Applications in Identifying Malicious Tools †



Abstract
1. Introduction
1.1. Related Work
1.1.1. Information–Measures–Based Anomaly Detection
1.1.2. Parameter Estimation
1.1.3. Non-Parametric Models
1.1.4. Deep Learning for Anomaly Detection
1.2. Main Contributions
2. Universal Anomaly Detection for Individual Sequences
2.1. Classification and Anomaly Detection
2.2. Universal Probability Assignment for Individual Sequences
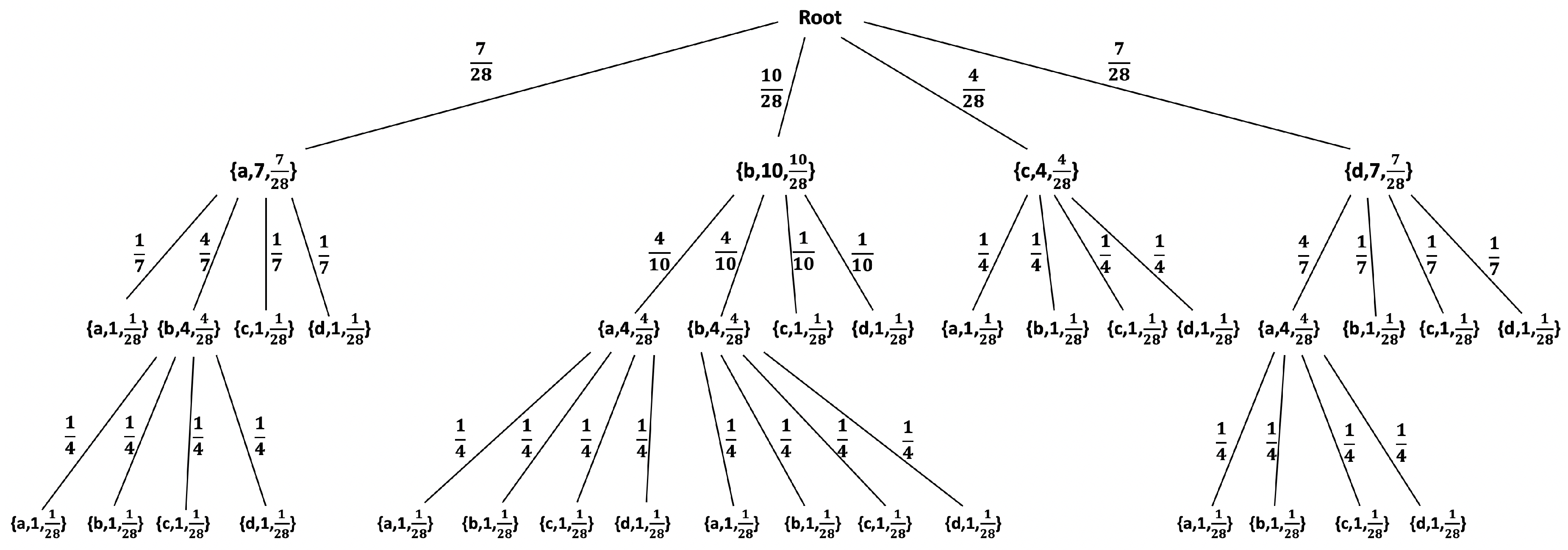
2.2.1. The LZ78 Compression Algorithm
2.2.2. Statistical Model for Individual Sequences
2.3. An Anomaly Detection System Via Universal Probability Assignment
2.3.1. Preprocessing and Quantization
2.3.2. Learning and Testing
2.3.3. Performance Evaluation and Practical Constraints
3. Botnets Identification
3.1. Botnets: Architecture and Existing Detection Mechanisms
3.2. Data Set and Pre-Processing
Preprocessing of Flows before Learning and Testing
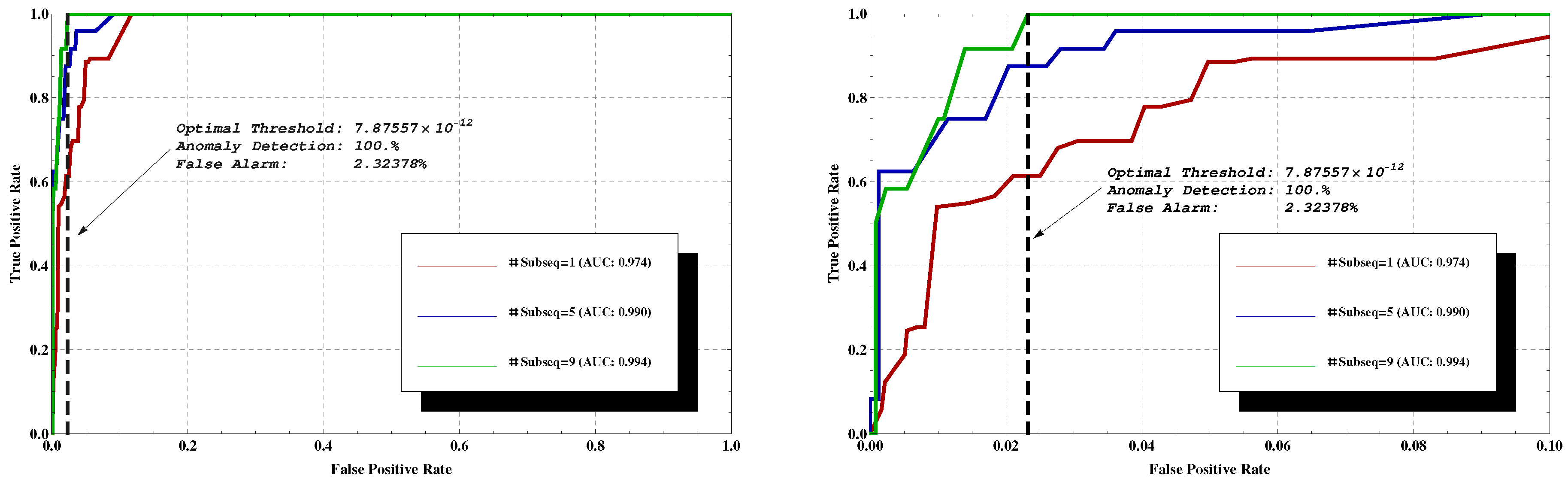
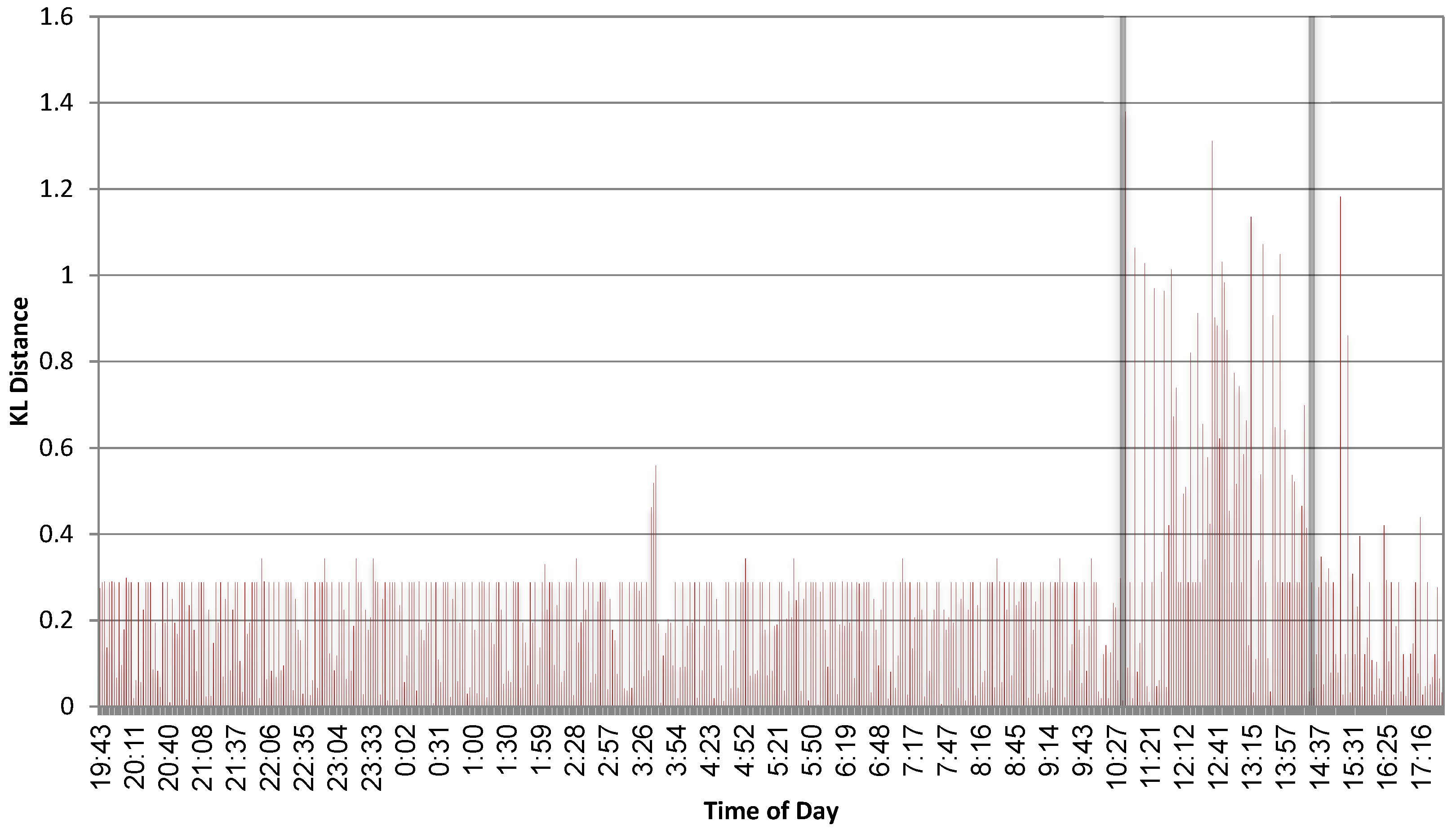
3.3. Experimental Results
3.4. Threshold Analysis
4. Monitoring the Context of System Calls for Anomalous Behaviour
4.1. An Extreme Value Theory Based Threshold Analysis
5. Identifying Data Leakage
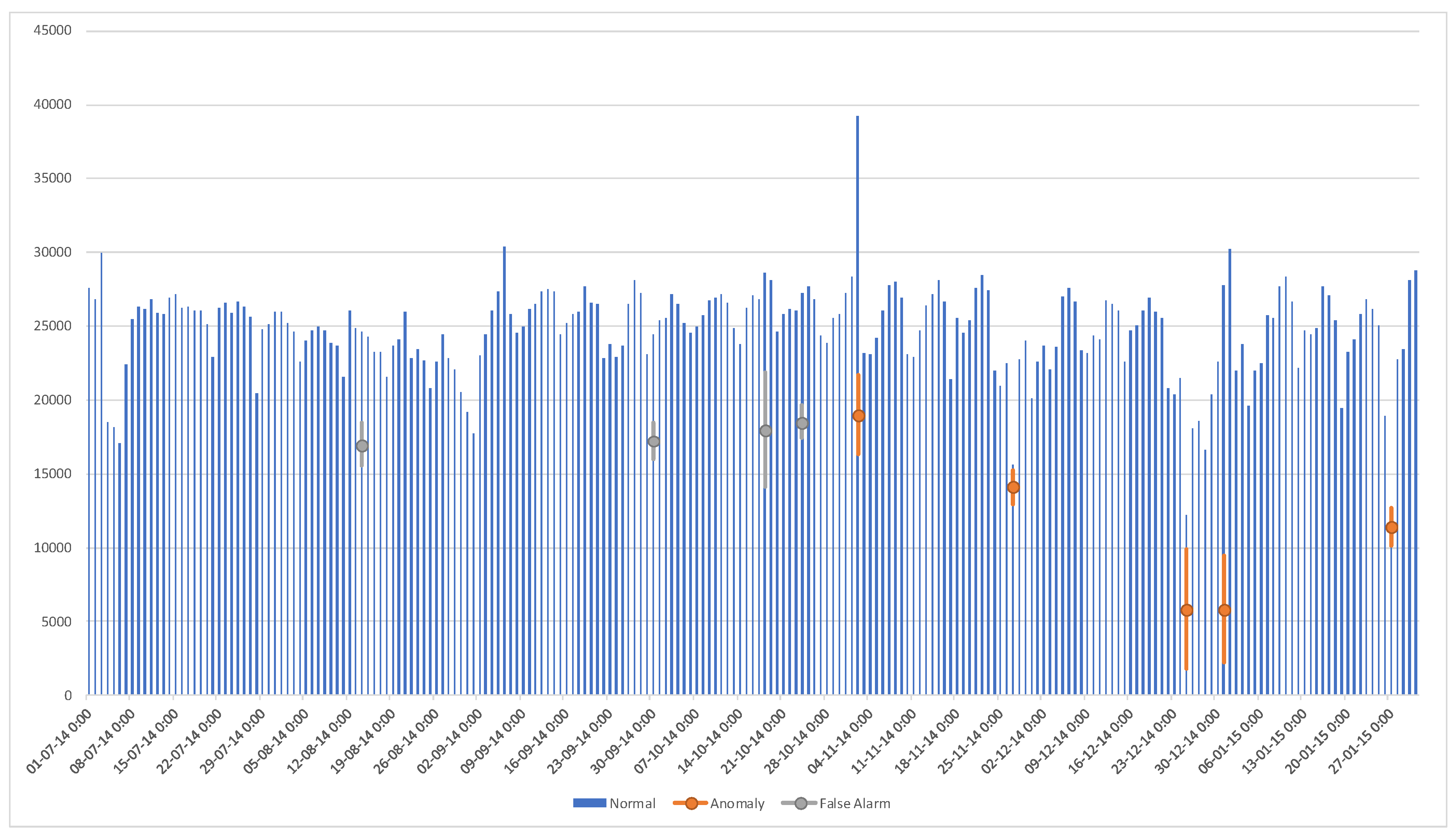
6. Results and Comparisons on Benchmark Trip Record Data
6.1. Threshold Computation
6.2. Results and Comparisons
7. Attack Strategies and Their Consequences
7.1. The Consequences of an Incorrect Model
7.2. Using True Data
7.3. Accessing the True Model
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LZ | Lempel-Ziv |
| C&C | Command and Control |
| NYC | New York City |
| DDoS | Distributed Denial-of-Service |
| ARMA | Auto Regressive Moving Average |
| KL | Kullback-Leibler |
| E-NIDS | Entropy-based Network Intrusion Detection Systems |
| FSM | Finite State Machine |
| TD | Time Difference |
| TT | Time Taken |
| CSB | Client-Server-Bytes |
| SCB | Server-Client-Bytes |
| CID | Client ID (Identification) |
| HID | Host ID (Identification) |
| FP | False Positive |
| TP | True Positive |
| FN | False Negative |
| TN | True Negative |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under Curve |
| MSE | Mean Square Error |
References
- Strayer, W.T.; Lapsely, D.; Walsh, R.; Livadas, C. Botnet detection based on network behavior. In Botnet Detection; Springer: Boston, MA, USA, 2008; pp. 1–24. [Google Scholar]
- Gu, G.; Zhang, J.; Lee, W. BotSniffer: Detecting botnet command and control channels in network traffic. In Proceedings of the 15th Annual Network and Distributed System Security Symposium, San Diego, CA, USA, 10–13 February 2008. [Google Scholar]
- Chang, S.; Daniels, T.E. P2P botnet detection using behavior clustering & statistical tests. In Proceedings of the 2nd ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 9 November 2009; ACM: New York, NY, USA, 2009; pp. 23–30. [Google Scholar]
- Noh, S.K.; Oh, J.H.; Lee, J.S.; Noh, B.N.; Jeong, H.C. Detecting P2P botnets using a multi-phased flow model. In Proceedings of the 2009 Third International Conference on Digital Society, ICDS’09, Cancun, Mexico, 1–7 February 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 247–253. [Google Scholar]
- Francois, J.; Wang, S.; Bronzi, W.; State, R.; Engel, T. BotCloud: Detecting botnets using MapReduce. In Proceedings of the 2011 IEEE International Workshop on Information Forensics and Security, Iguacu Falls, Brazil, 29 November–2 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Villamarín-Salomón, R.; Brustoloni, J.C. Identifying botnets using anomaly detection techniques applied to DNS traffic. In Proceedings of the 2008 5th IEEE Consumer Communications and Networking Conference, Las Vegas, NV, USA, 10–12 January 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 476–481. [Google Scholar]
- Burghouwt, P.; Spruit, M.; Sips, H. Towards detection of botnet communication through social media by monitoring user activity. In Information Systems Security; Springer: Berlin/Heidelberg, Germany, 2011; pp. 131–143. [Google Scholar]
- Silva, S.S.; Silva, R.M.; Pinto, R.C.; Salles, R.M. Botnets: A survey. Comput. Netw. 2013, 57, 378–403. [Google Scholar] [CrossRef]
- Sun, B.; Yu, F.; Wu, K.; Xiao, Y.; Leung, V.C.M. Enhancing security using mobility-based anomaly detection in cellular mobile networks. IEEE Trans. Veh. Technol. 2006, 55, 1385–1396. [Google Scholar] [CrossRef]
- Celenk, M.; Conley, T.; Willis, J.; Graham, J. Predictive network anomaly detection and visualization. IEEE Trans. Inf. Forensics Secur. 2010, 5, 288–299. [Google Scholar] [CrossRef]
- Jia, C.; Chen, D.; Lin, K. The application of the relative entropy density divergence in intrusion detection models. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; IEEE: Piscataway, NJ, USA, 2008; Volume 3, pp. 951–954. [Google Scholar]
- Eimann, R.E. Network Event Detection with Entropy Measures. Ph.D. Thesis, ResearchSpace@Auckland, University of Auckland, Auckland, New Zealand, 2008. [Google Scholar]
- Callegari, C.; Giordano, S.; Pagano, M. On the use of compression algorithms for network anomaly detection. In Proceedings of the 2009 IEEE International Conference on Communications, Dresden, Germany, 14–18 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–5. [Google Scholar]
- Abasolo, D.; James, C.J.; Hornero, R. Non-linear Analysis of Intracranial Electroencephalogram Recordings with Approximate Entropy and Lempel-Ziv Complexity for Epileptic Seizure Detection. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; pp. 1953–1956. [Google Scholar]
- Høst-Madsen, A.; Sabeti, E.; Walton, C.; Lim, S.J. Universal data discovery using atypicality. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3474–3483. [Google Scholar]
- Lee, W.; Xiang, D. Information-theoretic measures for anomaly detection. In Proceedings of the 2001 IEEE Symposium on Security and Privacy, S&P 2001, Oakland, CA, USA, 14–16 May 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 130–143. [Google Scholar]
- Bereziński, P.; Jasiul, B.; Szpyrka, M. An entropy-based network anomaly detection method. Entropy 2015, 17, 2367–2408. [Google Scholar] [CrossRef]
- Santiago-Paz, J.; Torres-Roman, D.; Figueroa-Ypiña, A.; Argaez-Xool, J. Using generalized entropies and OC-SVM with Mahalanobis kernel for detection and classification of anomalies in network traffic. Entropy 2015, 17, 6239–6257. [Google Scholar] [CrossRef]
- Santiago-Paz, J.; Torres-Roman, D. On entropy in network traffic anomaly detection. In Proceedings of the 2nd International Electronic Conference on Entropy and Its Applications, (online), 15–30 November 2015. [Google Scholar]
- Kowalik, B.; Szpyrka, M. An Entropy-Based Car Failure Detection Method Based on Data Acquisition Pipeline. Entropy 2019, 21, 426. [Google Scholar] [CrossRef]
- Greyling, S.; Marais, H.; van Schoor, G.; Uren, K.R. Application of Energy-Based Fault Detection in a Gas-To-Liquids Process Plant. Entropy 2019, 21, 565. [Google Scholar] [CrossRef]
- Liu, L.; Zhi, Z.; Zhang, H.; Guo, Q.; Peng, Y.; Liu, D. Related Entropy Theories Application in Condition Monitoring of Rotating Machineries. Entropy 2019, 21, 1061. [Google Scholar] [CrossRef]
- Bernikova, O.; Granichin, O.; Lemberg, D.; Redkin, O.; Volkovich, Z. Entropy-Based Approach for the Detection of Changes in Arabic Newspapers’ Content. Entropy 2020, 22, 441. [Google Scholar] [CrossRef]
- Rettig, L.; Khayati, M.; Cudre-Mauroux, P.; Piorkowski, M. Online Anomaly Detection over Big Data Streams. In Applied Data Science; Braschler, M., Stadelmann, T., Stockinger, K., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zhang, X.; Lin, D.; Zheng, J.; Tang, X.; Fang, Y.; Yu, H. Detection of Salient Crowd Motion Based on Repulsive Force Network and Direction Entropy. Entropy 2019, 21, 608. [Google Scholar] [CrossRef]
- She, R.; Liu, S.; Fan, P. Attention to the Variation of Probabilistic Events: Information Processing with Message Importance Measure. Entropy 2019, 21, 439. [Google Scholar] [CrossRef]
- Ki-Soon, Y.; Sung-Hyun, K.; Lim, D.-W.; Kim, Y.-S. A Multiple Rènyi Entropy Based Intrusion Detection System for Connected Vehicles. Entropy 2020, 22, 186. [Google Scholar]
- Li, T.; Jianfeng, M.; Yulong, S.; Qingqi, P. Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning. Entropy 2020, 22, 734. [Google Scholar] [CrossRef]
- Martos, G.; Hernández, N.; Muñoz, A.; Moguerza, J. Entropy measures for stochastic processes with applications in functional anomaly detection. Entropy 2018, 20, 33. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data set for Network Intrusion Detection systems. In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Moustafa, N.; Creech, G.; Slay, J. Big Data Analytics for Intrusion Detection System: Statistical Decision-Making Using Finite Dirichlet Mixture Models. In Data Analytics and Decision Support for Cybersecurity; Palomares Carrascosa, I., Kalutarage, H., Huang, Y., Eds.; Springer: Cham, Switzerland, 2017; pp. 127–156. [Google Scholar]
- Moustafa, N.; Creech, G.; Slay, J. Anomaly detection system using beta mixture models and outlier detection. Prog. Comput. Anal. Netw. 2018, 125–135. [Google Scholar]
- Moustafa, N.; Slay, J.; Creech, G. Novel Geometric Area Analysis Technique for Anomaly Detection Using Trapezoidal Area Estimation on Large-Scale Networks. IEEE Trans. Big Data 2019, 5, 481–494. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. A Two-Level Flow-Based Anomalous Activity Detection System for IoT Networks. Electronics 2020, 9, 530. [Google Scholar] [CrossRef]
- Babazadeh, M. Edge analytics for anomaly detection in water networks by an Arduino101-LoRa based WSN. ISA Trans. 2019, 92, 273–285. [Google Scholar] [CrossRef]
- Resende, J.S.; Martins, R.; Antunes, L. A Survey on Using Kolmogorov Complexity in Cybersecurity. Entropy 2019, 21, 1196. [Google Scholar] [CrossRef]
- Sabeti, E.; Høst-Madsen, A. Data discovery and anomaly detection using atypicality for real-valued data. Entropy 2019, 21, 219. [Google Scholar] [CrossRef]
- Høst-Madsen, A.; Sabeti, E.; Walton, C. Data discovery and anomaly detection using atypicality: Theory. IEEE Trans. Inf. Theory 2019, 65, 5302–5322. [Google Scholar] [CrossRef]
- Siboni, S.; Cohen, A. Botnet identification via universal anomaly detection. In Proceedings of the 2014 IEEE International Workshop on Information Forensics and Security (WIFS), Atlanta, GA, USA, 3–5 December 2014; pp. 101–106. [Google Scholar] [CrossRef]
- AL-Hawawreh, M.; Moustafa, N.; Sitnikova, E. Identification of malicious activities in industrial internet of things based on deep learning models. J. Inf. Secur. Appl. 2018, 41, 1–11. [Google Scholar] [CrossRef]
- Roy, B.; Cheung, H. A Deep Learning Approach for Intrusion Detection in Internet of Things using Bi-Directional Long Short-Term Memory Recurrent Neural Network. In Proceedings of the 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, NSW, Australia, 21–23 November 2018; pp. 1–6. [Google Scholar]
- Zhiqiang, L.; Mohi-Ud-Din, G.; Bing, L.; Jianchao, L.; Ye, Z.; Zhijun, L. Modeling Network Intrusion Detection System Using Feed-Forward Neural Network Using UNSW-NB15 Dataset. In Proceedings of the IEEE 7th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2019; pp. 299–303. [Google Scholar]
- Hafsa, M.; Jemili, F. Comparative Study between Big Data Analysis Techniques in Intrusion Detection. Big Data Cogn. Comput. 2019, 3, 1. [Google Scholar] [CrossRef]
- Morfino, V.; Rampone, S. Towards Near-Real-Time Intrusion Detection for IoT Devices using Supervised Learning and Apache Spark. Electronics 2020, 9, 444. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Yang, Y. Improving the Classification Effectiveness of Intrusion Detection by Using Improved Conditional Variational AutoEncoder and Deep Neural Network. Sensor 2019, 8, 2528. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an Effective Intrusion Detection System Using the Modified Density Peak Clustering Algorithm and Deep Belief Networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Lee, J.; Park, K. AE-CGAN Model based High Performance Network Intrusion Detection System. Appl. Sci. 2019, 9, 4221. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Magán-Carrión, R.; Urda, D.; Díaz-Cano, I.; Dorronsoro, B. Towards a Reliable Comparison and Evaluation of Network Intrusion Detection Systems Based on Machine Learning Approaches. Appl. Sci. 2020, 10, 1775. [Google Scholar] [CrossRef]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, R.; Sakurai, K. Towards a Lightweight Detection System for Cyber Attacks in the IoT Environment Using Corresponding Features. Electronics 2020, 9, 144. [Google Scholar] [CrossRef]
- Golrang, A.; Golrang, A.M.; Yildirim Yayilgan, S.; Elezaj, O. A Novel Hybrid IDS Based on Modified NSGAII-ANN and Random Forest. Electronics 2020, 9, 577. [Google Scholar] [CrossRef]
- Garland, J.; Jones, T.; Neuder, M.; Morris, V.; White, J.; Bradley, E. Anomaly detection in paleoclimate records using permutation entropy. Entropy 2018, 20, 931. [Google Scholar] [CrossRef]
- Cao, Y.; Xie, L.; Xie, Y.; Xu, H. Sequential change-point detection via online convex optimization. Entropy 2018, 20, 108. [Google Scholar] [CrossRef]
- Lapidoth, A. A Foundation in Digital Communication; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Neyman, J.; Pearson, E.S. On the Problem of the Most Efficient Tests of Statistical Hypotheses. Philos. Trans. R. Soc. A 1933, 231, 289–337. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. CSUR 2009, 41, 15. [Google Scholar] [CrossRef]
- Feder, M.; Merhav, N.; Gutman, M. Universal prediction of individual sequences. IEEE Trans. Inf. Theory 1992, 38, 1258–1270. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Nisenson, M.; Yariv, I.; El-Yaniv, R.; Meir, R. Towards behaviometric security systems: Learning to identify a typist. In Knowledge Discovery in Databases: PKDD 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–374. [Google Scholar]
- Begleiter, R.; El-Yaniv, R.; Yona, G. On prediction using variable order Markov models. J. Artif. Intell. Res. JAIR 2004, 22, 385–421. [Google Scholar] [CrossRef]
- Seroussi, G.; Lempel, A. Lempel-Ziv Compression Scheme with Enhanced Adapation. US Patent 5,243,341, 7 September 1993. [Google Scholar]
- Klein, S.T.; Wiseman, Y. Parallel lempel ziv coding. Discret. Appl. Math. 2005, 146, 180–191. [Google Scholar] [CrossRef]
- Lu, W.; Tavallaee, M.; Rammidi, G.; Ghorbani, A.A. BotCop: An online botnet traffic classifier. In Proceedings of the 2009 Seventh Annual Communication Networks and Services Research Conference, Moncton, NB, Canada, 11–13 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 70–77. [Google Scholar]
- Mazzariello, C.; Sansone, C. Anomaly-based detection of IRC botnets by means of one-class support vector classifiers. In Image Analysis and Processing—ICIAP 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 883–892. [Google Scholar]
- Este, A.; Gringoli, F.; Salgarelli, L. Support Vector Machines for TCP traffic classification. Comput. Netw. 2009, 53, 2476–2490. [Google Scholar] [CrossRef]
- Gu, G.; Perdisci, R.; Zhang, J.; Lee, W. BotMiner: Clustering Analysis of Network Traffic for Protocol-and Structure-Independent Botnet Detection. In Proceedings of the 17th USENIX Security Symposium, San Jose, CA, USA, 28 July–1 August 2008; pp. 139–154. [Google Scholar]
- AsSadhan, B.; Moura, J.M.; Lapsley, D.; Jones, C.; Strayer, W.T. Detecting botnets using command and control traffic. In Proceedings of the 2009 Eighth IEEE International Symposium on Network Computing and Applications, Cambridge, MA, USA, 9–11 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 156–162. [Google Scholar]
- Tegeler, F.; Fu, X.; Vigna, G.; Kruegel, C. Botfinder: Finding bots in network traffic without deep packet inspection. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Nice, France, 10–13 December 2012; ACM: New York, NY, USA, 2012; pp. 349–360. [Google Scholar]
- Dataset. Available online: https://drive.google.com/open?id=1cj3dE82Cb0-FrsJwUmpY4zGb8Zw3cy2t (accessed on 19 March 2020).
- Mařík, R. Threshold Selection Based on Extreme Value Theory. In Mechatronics 2017; Březina, T., Jabłoński, R., Eds.; Springer: Cham, Germany, 2018. [Google Scholar]
- Yuanyan, L.; Xuehui, D.; Yi, S. Data Streams Anomaly Detection Algorithm Based on Self-Set Threshold. In Proceedings of the 4th International Conference on Communication and Information Processing; Association for Computing Machinery: New York, NY, USA, 2018; pp. 18–26. [Google Scholar] [CrossRef]
- Fava, D.S.; Byers, S.R.; Yang, S.J. Projecting cyberattacks through variable-length markov models. IEEE Trans. Infor. Forensics Secur. 2008, 3, 359–369. [Google Scholar] [CrossRef]
- NtTrace—Native API Tracing for Windows. Available online: http://rogerorr.github.io/NtTrace/ (accessed on 19 March 2020).
- Wireshark. Available online: https://www.wireshark.org/ (accessed on 19 March 2020).
- Ncat. Available online: http://nmap.org/ncat/guide/ (accessed on 19 March 2020).
- Outlier Detection DataSets. Available online: http://odds.cs.stonybrook.edu (accessed on 25 May 2020).
- The Numenta Anomaly Benchmark—NYC Taxi Data. Available online: https://github.com/numenta/NAB/blob/master/data/realKnownCause/nyc_taxi.csv (accessed on 26 May 2020).
- TLC Trip Record Data. Available online: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page (accessed on 25 May 2020).
- Coughlin, J.; Perrone, G. Multi-scale Anomaly Detection with Wavelets. In Proceedings of the International Conference on Big Data and Internet of Thing (BDIOT 2017), London, UK, 2017; pp. 102–108. [Google Scholar] [CrossRef]
- Lomonaco, V. A Machine Learning Guide to HTM (Hierarchical Temporal Memory). Available online: https://numenta.com/blog/2019/10/24/machine-learning-guide-to-htm (accessed on 2 June 2020).
- Anomaly Detection for RealKnownCause/nyc_taxi.cvs. Available online: https://chart-studio.plotly.com/~sjd171/2354.embed (accessed on 26 May 2020).
- Prelert, Automated Anomaly Detection Analytics. Available online: http://www.prelert.com/anomaly-detective.html (accessed on 2 June 2020).
- Ahmad, S.; Lavin, A.; Purdy, S.; Agha, Z. Unsupervised real-time anomaly detection for streaming data. Neurocomputing 2017, 262, 134–147. [Google Scholar] [CrossRef]
- Feremans, L.; Vercruyssen, V.; Cule, B.; Meert, W.; Goethals, B. Pattern-based anomaly detection in mixed-type time series. In Proceedings of the Lecture Notes in Artificial Intelligence (2019), Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; pp. 240–257. [Google Scholar]
- Burnaev, E.; Ishimtsev, V. Conformalized density-and distance-based anomaly detection in time-series data. arXiv 2016, arXiv:1608.04585. [Google Scholar]
- Kejariwal, A. Introducing Practical and Robust Anomaly Detection in a Time Series. Available online: https://blog.twitter.com/engineering/en_us/a/2015/introducing-practical-and-robust-anomaly-detection-in-a-time-series.html (accessed on 2 June 2020).
- Hasani, Z. Robust anomaly detection algorithms for real-time big data: Comparison of algorithms. In Proceedings of the IEEE 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 1–6. [Google Scholar]
- Rached, Z.; Alajaji, F.; Campbell, L.L. The Kullback-Leibler divergence rate between Markov sources. IEEE Trans. Inf. Theory 2004, 50, 917–921. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Merhav, N.; Weinberger, M.J. On universal simulation of information sources using training data. IEEE Trans. Inf. Theory 2004, 50, 5–20. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Time-Taken | Cs-Bytes | Sc-Bytes | Mime-Type | Cat | Hid | Cid |
|---|---|---|---|---|---|---|---|
| 05:52:37 | 40 | 803 | 360 | image/gif | good | 49 | 9 |
| 05:52:37 | 74 | 734 | 277 | text/html | good | 102 | 15 |
| 05:52:37 | 27 | 578 | 507 | image/gif | good | 52 | 486 |
| 05:52:37 | 27 | 578 | 507 | image/gif | good | 75,526 | 486 |
| 05:52:37 | 25 | 655 | 4196 | image/jpeg | good | 52 | 4 |
| 05:52:37 | 25 | 655 | 4196 | image/jpeg | good | 75,526 | 4 |
| 05:52:37 | 26 | 577 | 505 | image/gif | good | 52 | 486 |
| 05:52:37 | 26 | 577 | 505 | image/gif | good | 75,526 | 486 |
| 05:52:37 | 31 | 624 | 960 | image/gif | good | 52 | 6 |
| 05:52:37 | 1 | 812 | 22,672 | application/octet-stream | good | 75,526 | 6 |
| 05:52:37 | 30 | 707 | 4368 | image/jpeg | good | 52 | 2 |
| 05:52:37 | 28 | 667 | 2639 | image/jpeg | good | 75,526 | 4 |
| 05:52:37 | 180 | 434 | 1451 | text/html;%20charset=iso-8859-1 | hostile | 3 | 6 |
| 05:52:37 | 34 | 710 | 4270 | image/jpeg | good | 52 | 2 |
| 05:52:37 | 69 | 697 | 334 | text/css | good | 49 | 9 |
| Ncat | Ncat | Normal | Normal | Normal | Normal | Normal | Normal | |
|---|---|---|---|---|---|---|---|---|
| MSE | 0.962 | 1.262 | 0.044 | 0.153 | 0.143 | 0.43 | 0.142 | 0.017 |
| KL | 2.05 | 17.163 | 1.353 | 1.228 | 2.026 | 4.12 | 2.121 | 1.396 |
| Normal | Normal + 1.3 MB | Normal + 10 MB | Normal + 200 MB | |
|---|---|---|---|---|
| Normal | 0.906 | 0.843 | 0.583 | 0.72 |
| Using Ncat | 19.05 | 0.787 | 0.733 | 0.353 |
| Algorithm | True Positive | False Alarm | Miss Detection | Precision | Recall |
|---|---|---|---|---|---|
| Numenta [80,83] | 5 | 2 | 0 | 0.714 | 1 |
| The suggested LZ-based algorithm | 5 | 4 | 0 | 0.556 | 1 |
| KNN-CAD [85] | 3 | 4 | 2 | 0.429 | 0.6 |
| Wavelets–based [79] | 4 | 6 | 1 | 0.4 | 0.8 |
| Prelert [82] | 5 | 9 | 0 | 0.357 | 1 |
| TwitterADVec [86], results reported in [87] | 4 | 19 | 3 * | 0.174 | 0.571 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siboni, S.; Cohen, A. Anomaly Detection for Individual Sequences with Applications in Identifying Malicious Tools. Entropy 2020, 22, 649. https://doi.org/10.3390/e22060649
Siboni S, Cohen A. Anomaly Detection for Individual Sequences with Applications in Identifying Malicious Tools. Entropy. 2020; 22(6):649. https://doi.org/10.3390/e22060649
Chicago/Turabian StyleSiboni, Shachar, and Asaf Cohen. 2020. "Anomaly Detection for Individual Sequences with Applications in Identifying Malicious Tools" Entropy 22, no. 6: 649. https://doi.org/10.3390/e22060649
APA StyleSiboni, S., & Cohen, A. (2020). Anomaly Detection for Individual Sequences with Applications in Identifying Malicious Tools. Entropy, 22(6), 649. https://doi.org/10.3390/e22060649