1. Introduction
Designing an accurate automatic emotion recognition (ER) system is crucial and beneficial to the development of many applications such as human–computer interactive (HCI) applications [
1], computer-aided diagnosis systems, or deceit-analyzing systems. Three main models are in use for this purpose, namely acoustic, visual, and gestural. While a considerable amount of research and progress is dedicated to the visual model [
2,
3,
4,
5], speech as one of the most natural ways of communication among human beings is neglected unintentionally. Speech emotion recognition (SER) is useful for addressing HCI problems provided that it can overcome challenges such as understanding the true emotional state behind spoken words. In this context, SER can be used to improve human–machine interaction by interpreting human speech.
SER refers to the field of extracting semantics from speech signals. Applications such as pain and lie detection, computer-based tutorial systems, and movie or music recommendation systems that rely on the emotional state of the user can benefit from such an automatic system. In fact, the main goal of SER is to detect discriminative features of a speaker’s voice in different emotional situations.
Generally, a SER system extracts features of voice signal to predict the associated emotion using a classifier. A SER system needs to be robust to speaking rate and speaking style of the speaker. It means particular features such as age, gender, and culture differences should not affect the performance of the SER system. As a result, appropriate feature selection is the most important step of designing the SER system. Acoustic, linguistic, and context information are three main categories of features used in the SER research [
6]. In addition to those features, hand-engineered features including pitch, Zero-Crossing Rate (ZCR), and MFCC are widely used in many research works [
6,
7,
8,
9]. More recently, convolutional neural network (CNN) has been in use at a dramatically increasing rate to address the SER problem [
2,
10,
11,
12,
13].
Since the results from deep learning methods are more promising [
8,
14,
15], we used a 3D CNN model to predict the emotion embedded in a speech signal. One challenge in SER using multi-dimensional CNNs is the dimension of speech signal. Since the purpose of this study is to learn spectra-temporal features using a 3D CNN, one must transform the one-dimensional audio signal to an appropriate representation to be able to use it with 3D CNN. A spectrogram is a 2D visual representation of short-time Fourier transform (STFT) where the horizontal axis is the time, and the vertical axis is the frequency of signal [
16]. In the proposed framework, audio data is converted into consecutive 2D spectrograms in time. The 3D CNN is especially selected because it captures not only the spectral information but also the temporal information.
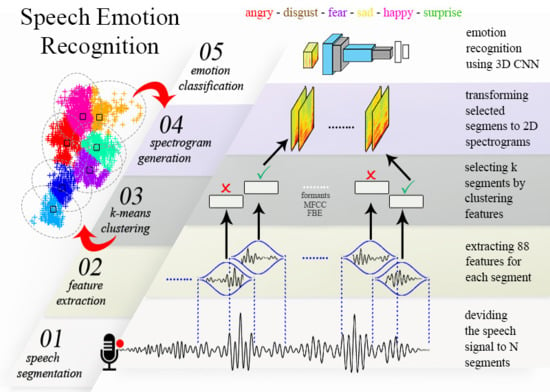
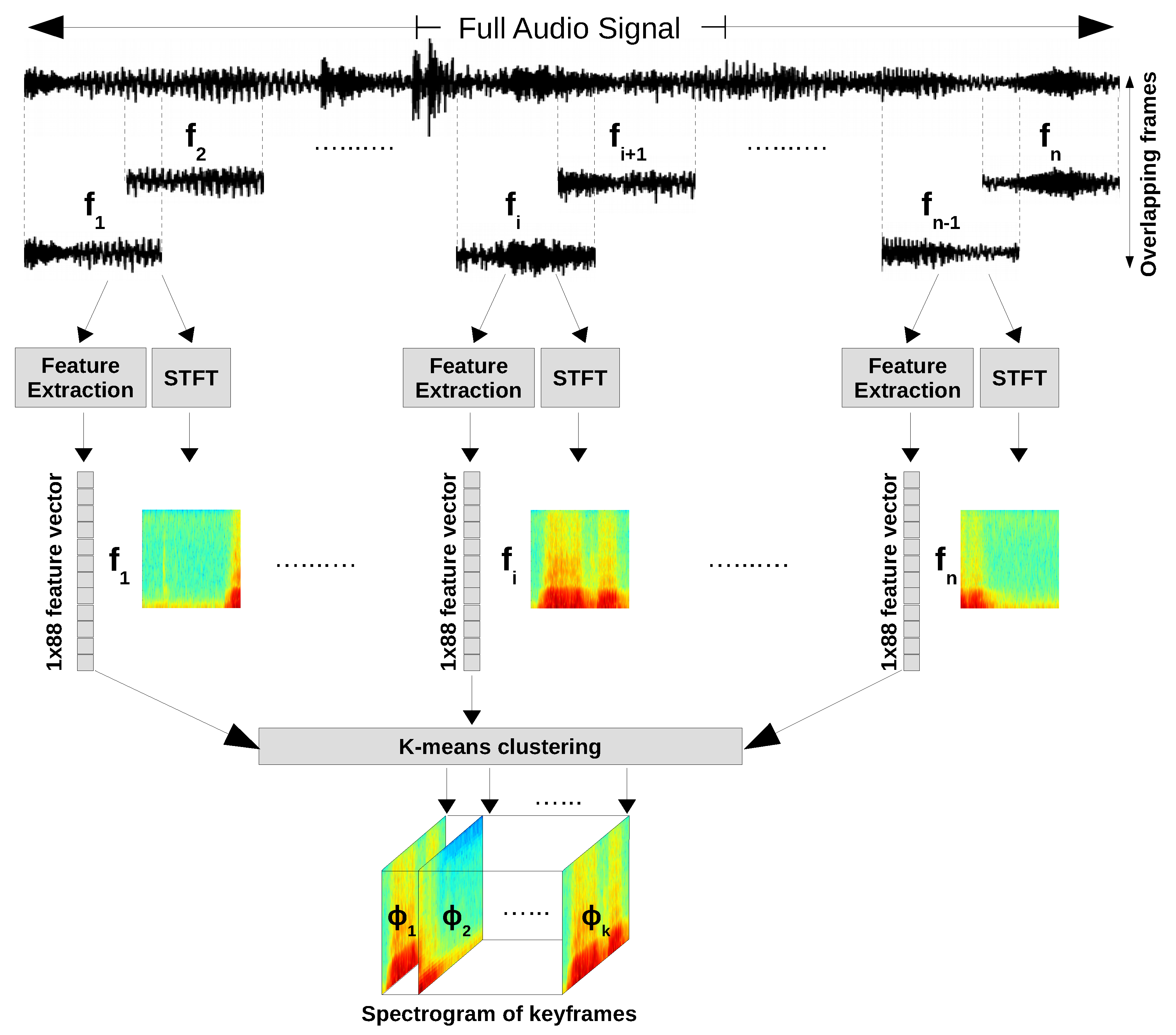
To train our 3D CNN using spectrograms, firstly, we divide each audio signal to shorter overlapping frames of equal length. Next, we extract an 88-dimensional vector of commonly known audio features for each of the corresponding frames. This means, at the end of this step, each speech signal is represented by a matrix of size
where
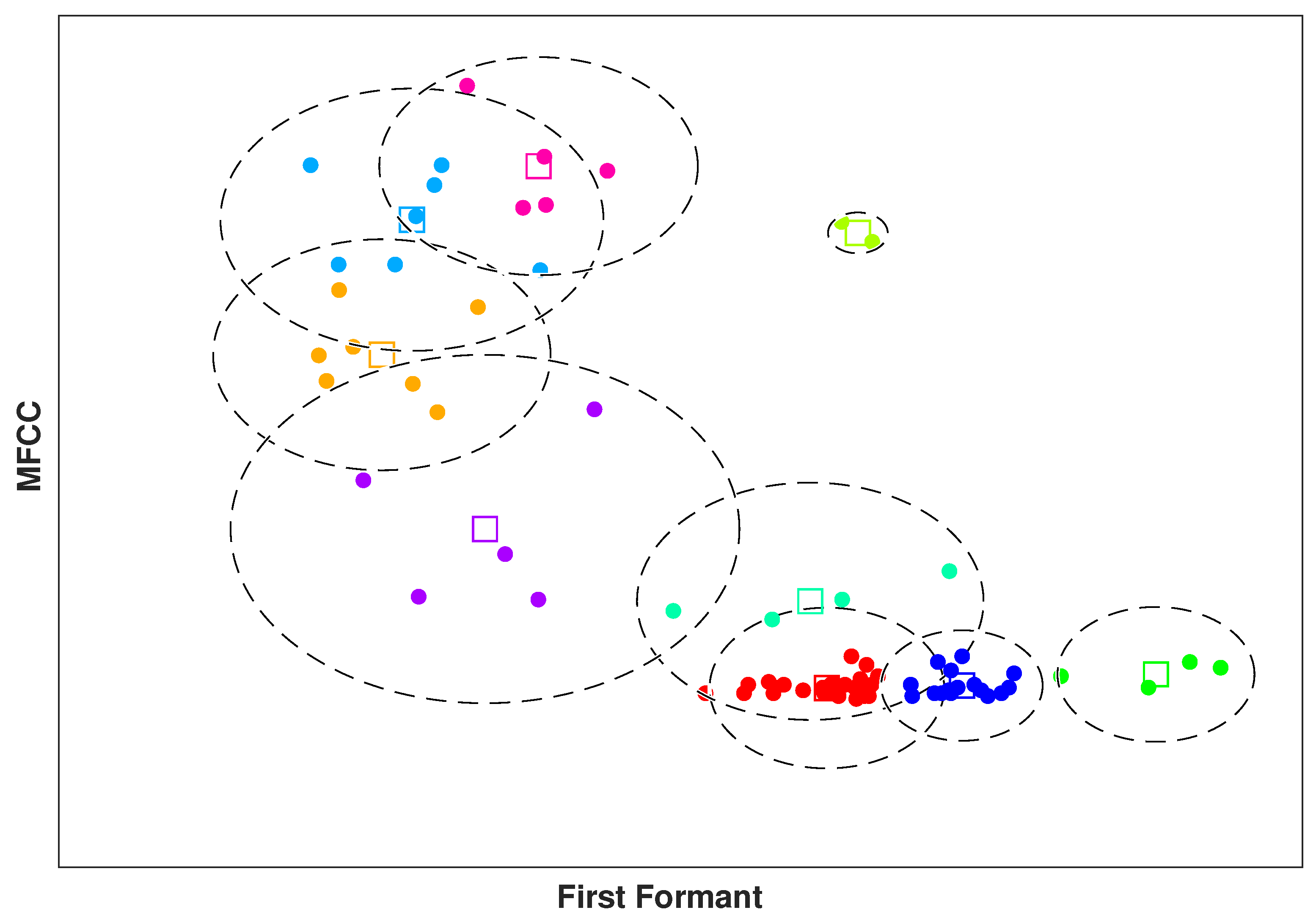
n is the total number of frames for one audio signal and 88 is the number of features extracted for each frame. In parallel, the spectrogram of each frame is generated by applying STFT. In the next step, we apply k-means clustering on the extracted features of all frames of each audio signal to select
k most discriminant frames, namely keyframes. This way, we summarize a speech signal with
k keyframes. Then, the corresponding spectrograms of the keyframes are encapsulated in a tensor of size
where
P and
Q are horizontal and vertical dimensions of the spectrograms. These tensors are used as the input samples to train and test a 3D CNN using 10-fold cross-validation approach. Each of 3D tensors is associated with the corresponding label of the original speech signal. The proposed 3D CNN model consists of two convolutional layers and a fully connected layer which extracts the discriminative spectra-temporal features of so-called tensors of spectrograms and outputs a class label for each speech signal. The experiments are performed on three different datasets, namely Ryerson Multimedia Laboratory (RML) [
17] database, Surrey Audio-Visual Expressed Emotion (SAVEE) database [
18] and eNTERFACE’05 Audio-Visual Emotion Database [
19]. We achieved recognition rate of
,
and
for SAVEE, RML and eNTERFACE’05 databases, respectively. These results improved the state-of-the-art results in the literature up to
,
and
for these datasets, respectively. In addition, the 3D CNN is trained using all spectrograms of each audio file. As a second series of experiments, we used a pre-trained 2D CNN model, say VGG-16 [
20] and performed transfer learning on the top layers. The results obtained from our proposed method is superior than the ones achieved from training VGG-16. This is mainly due to fewer parameters used in the freshly trained 3D CNN architecture. Also, VGG-16 is a 2D model and it cannot detect the temporal information of given spectrograms.
The main contributions of the current work are: (a) division of an audio signal to n frames of equal length and selecting the k most discriminant frames (keyframes) using k-means clustering algorithm where ; (b) representing each audio signal by a 3D tensor of size where k is the number of consecutive spectrograms corresponding to keyframes and P and Q are horizontal and vertical dimensions of each spectrogram; (c) Improving the ER rate for three benchmark datasets by learning spectra-temporal features of audio signal using a 3D CNN and 3D tensor inputs.
The main motivation of the proposed work is to employ 3D CNNs, which is capable of learning spectra-temporal information of audio signals. We proposed to use a subset of spectrogram frames which minimizes redundancy and maximizes the discrimination capability of the represented audio signal. The selection of such a subset provides a computationally cheaper tensor processing for comparable or improved performance.
The rest of the paper is organized as follows: In
Section 2, we review the related works and describe steps of our proposed method. In
Section 3, our experimental results are illustrated and compared with the state of the art in the literature. Finally, in
Section 4 conclusion and future work is discussed.
3. Results and Discussion
Taking into account the acquisition source of the data, three general groups of emotional databases exist: spontaneous emotions, acted emotions based on invocation and simulated emotions. Sample databases recorded in natural situations such as TV shows or movies are categorized under the first group. Usually, such databases suffer from low quality due to different sources of interference. For databases under second group, an emotional state is induced using various methods such as watching emotional video clips or reading emotional context. Although psychologists prefer this type of databases, the resulted reaction to the same stimulant may differ. Also, ethically provoking strong emotions might be harmful for the subject. eNTERFACE’05 and RML are examples of this group. The last group of databases are simulated emotions with high quality recordings and still emotional state. SAVEE database is a good example of this group.
3.1. Dataset
Three benchmark datasets were used to conduct the experiments, namely RML, SAVEE and eNTERFACE’05. All three datasets support audio-visual modals. Several reasons have been considered while choosing the datasets. We selected databases in a way covering a variation of size to show the flexibility of our model. Firstly, all three datasets are represented for same emotional states which makes them highly comparable. It is known that distinction between two emotion categories (for example disgust and happy) with large inter-class differences is easier than two emotions with small inter-class discrepancy. In addition, having the same number of emotional states prevents misinterpretation of the experimental results. Because as the number of emotional states increase the classification task becomes more challenging.
Second, since all three datasets recorded for both the audio and the visual modals, the quality of the recorded audios is almost the same (16-bit single channel format). For example, comparing databases recorded with high acoustic quality and for the specific purpose of SER (EmoDB) with databases recorded in real environments is not preferable. Extraction of speech signals from videos for all three datasets is performed using the FFmpeg framework. Third, SAVEE, RML and eNTERFACE’05 can be categorized as small-size, mid-size, and large-size databases. Thus, the proposed model is evaluated to have a stable performance in terms of number of input samples.
The data processing pipeline explained in
Section 2.2.1 is applied on each audio sample. To avoid overfitting, in all experiments, we divided the data such that
is used for training and
for test. We performed 10-fold cross-validation on the train part which means
of the train data is used for training and
for validation. Finally, the cross validated model is evaluated on the test part. The experiments are all performed for speaker-independent scenarios.
3.1.1. SAVEE
The SAVEE database has 4 male subjects who acted emotional videos for six basic emotions namely anger, disgust, fear, happiness, sadness, and surprise. A neutral category is recorded as well but since the other two datasets does not include neutral, we discard it. This dataset consists of 60 videos per category. 360 emotional audio samples extracted from the videos of this dataset.
3.1.2. RML
The RML database represented by Ryerson Multimedia Laboratory [
17] includes 120 videos in each of six basic categories mentioned above from 8 subjects spoke various languages such as English, Mandarin, and Persian. A dataset of 720 emotional audio samples is obtained from this database.
3.1.3. eNTERFACE’05
The third dataset is eNTERFACE’05 [
19] recorded from 42 subjects. All the participants spoke English and
of them are female. Each subject was asked to perform all six basic emotional states. Emotional states are exactly the same as SAVEE and RML. 210 audio samples per category is extracted from this dataset.
3.2. Experiments
To assess the proposed method, four experiments are conducted on each dataset. In the first experiment, we trained the proposed 3D CNN model using the spectrograms of selected keyframes by applying 10-fold cross-validation method. In the second experiment 3D CNN model is trained using spectrograms of all frames. In the third experiment, by means of transfer learning, we trained VGG-16 [
20] using the spectrograms of keyframes. Finally, in the last experiment we trained VGG-16 using all spectrograms generated for each audio signal. Comparing the results obtained from the second and third experiment shows that k-means clustering discarded the audio frames which convey insignificant or redundant information. This can be interpreted from the results given in
Table 3,
Table 4 and
Table 5 which does not differ notably. It is important to note that the overall accuracy results obtained from these four experiments are shown by Proposed 3D CNN
, Proposed 3D CNN
, VGG-16
and VGG-16
in those tables.
3.2.1. Training the Proposed 3D CNN
The CNN architecture illustrated in
Figure 3 was trained on a sequence of 9 consecutive spectrograms paired with the emotional label of the original speech sample. We train the network for 400 epochs with assuring that each input sample consists of a sequence of 9 successive spectrograms. Also, as a second experiment, the proposed 3D CNN was trained using all spectrograms of each audio signal.
Updates are performed using Adam optimizer [
37], categorical cross-entropy error, mini-batches of size 32 [
13] and a triangular cyclical learning rate policy by setting the initial learning rate to
, maximum learning rate to
, cycle length to 100 and step size to 50. Cycle length is the number of iterations until the learning rate returns to the initial value [
38]. Step size is set to half of the cycle length.
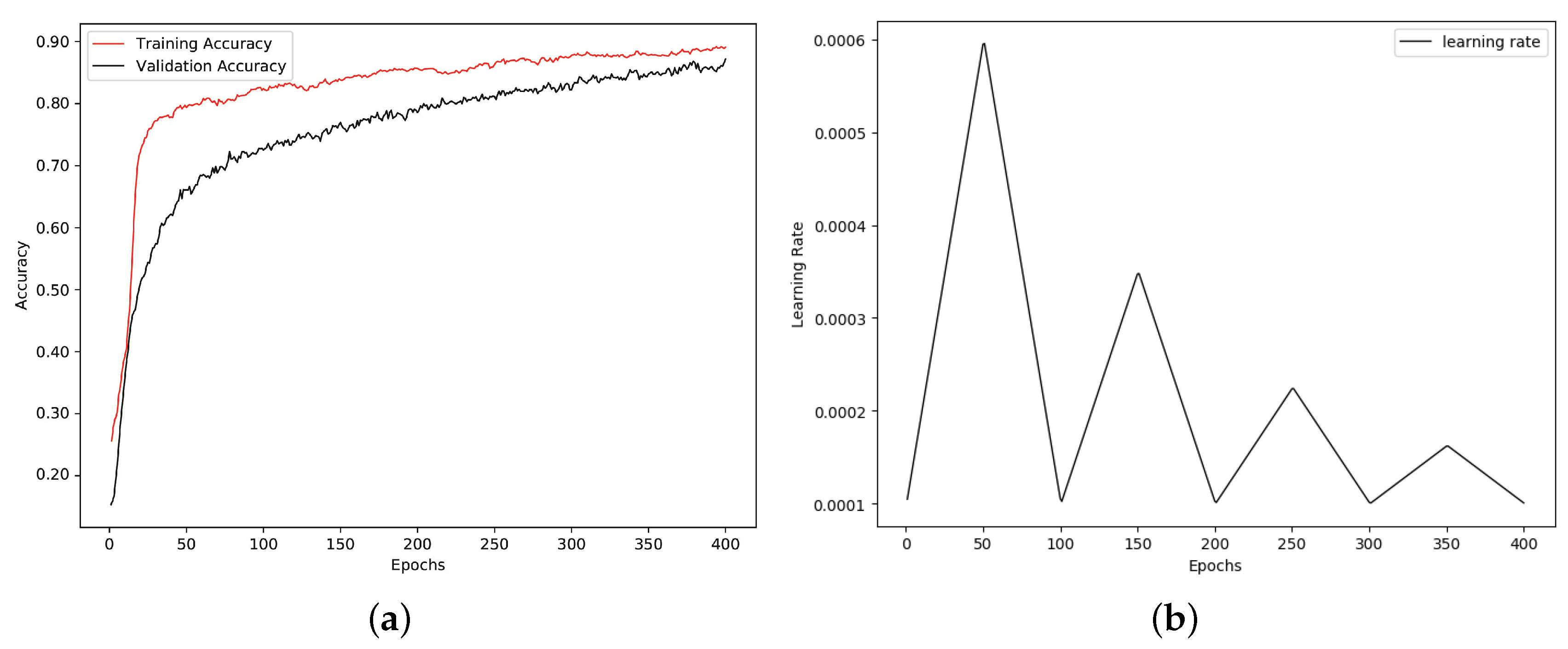
Figure 4b shows the learning rate for 400 iterations on RML dataset. As we mentioned before, to fight overfitting, we used
l2 weight regularization with factor
. In all experiments,
of the data is used for training and the rest for test. This means, the model learned spectra-temporal features by applying 10-fold cross-validation on the training part of the data. Then, the trained model is evaluated using the test data.
The average accuracy on test set of SAVEE, RML and eNTERFACE’05 databases is illustrated as a confusion matrix in
Table 6,
Table 7 and
Table 8, respectively. Clearly, the proposed method achieved superior results than the state-of-the-arts in the literature. Since the complexity of CNNs are extremely large, using discriminant input samples is of high importance especially when it comes to real-time applications. To the best of our knowledge, this is the first paper representing a whole audio signal by means of
k most discriminant spectrograms. This means, speech signal can be represented with fewer frames, yet preserving the accuracy.
Figure 4a shows the training and validation accuracy improvement for RML dataset over 400 iterations. Also,
Figure 4b shows the cyclical learning rate decay over same number of iterations and same dataset.
3.2.2. Transfer Learning of VGG-16
In the next two experiments, we selected one of the well-known 2D CNNs, VGG-16 [
20]. We applied transfer learning on the top layers to make it more suitable for the SER purpose. We trained the network for 400 weight updates. The initial learning rate is set to
.
In the first scenario, only the selected spectrograms of audio signals are given to VGG-16. In the second scenario, without applying k-means clustering algorithm, all generated spectrograms for each audio signal are used. In both cases, majority voting is used to make a final decision for each audio signal and assign a label to it. This means majority of labels predicted for the spectrograms of one audio is considered to be the final label for that audio signal. Both experiments under-performed the proposed 3D CNN.
This is mainly because VGG-16 is pre-trained on ImageNet dataset [
39] for object detection and image classification purposes. Also, it has more complexity to adjust its weight. As a result, transfer learning was not helpful. Same conclusion has been reported by [
14] and [
25] for applying transfer learning on AlexNet using spectrograms. Fewer parameters in the freshly trained 3D CNN is the main reason for achieving the higher performance. The overall accuracy obtained by these experiments is compared with the state of the art in the literature in
Table 3,
Table 4 and
Table 5 for SAVEE, RML and eNTERFACE’05 datasets, respectively.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}