Enhanced Approach Using Reduced SBTFD Features and Modified Individual Behavior Estimation for Crowd Condition Prediction



Abstract
1. Introduction
2. Current Approaches in Crowd Monitoring System
2.1. Time Domain (TD)
2.2. Frequency Domain (FD)
2.3. Related Works on Feature Reduction, Context-Aware Framework (CAF), and Activity Recognition (AR)
- (1)
- Context acquisition, modeling, inference, and sensing.
- (2)
- Determination of appropriate sensors and the nature of contexts to be acquired.
- (3)
- Real-time management of sensors and context-based action generation.
3. Materials and Methods
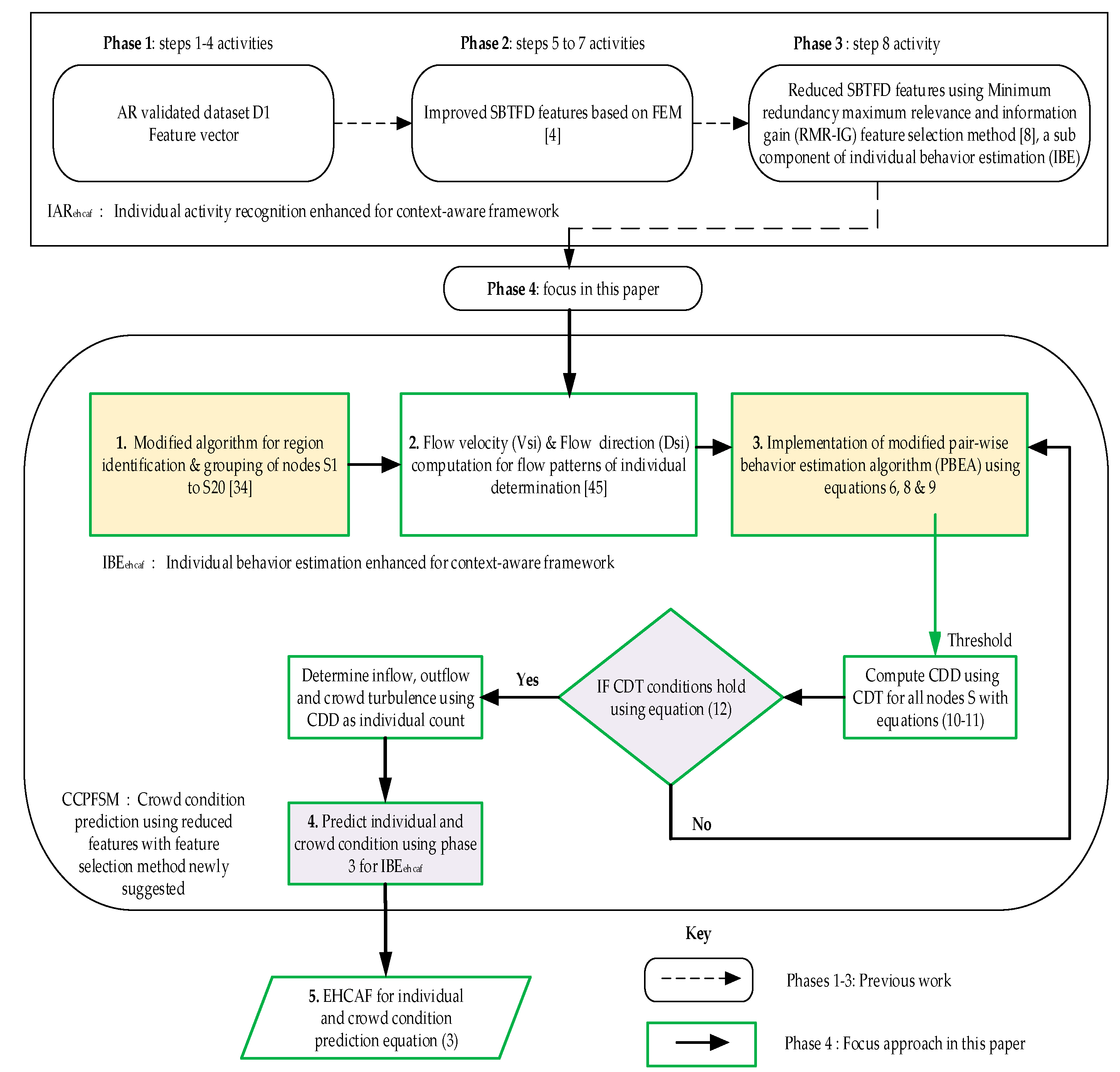
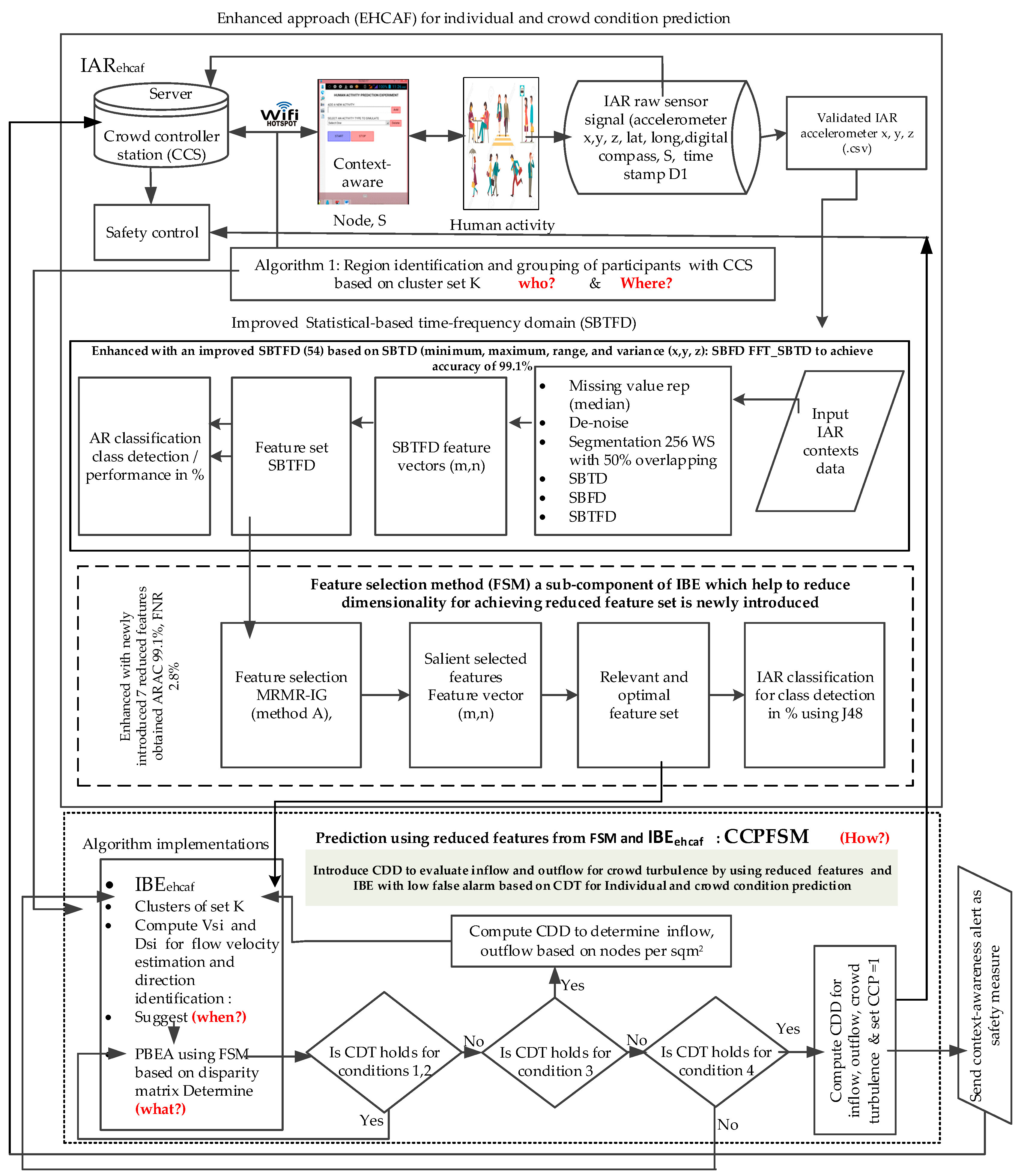
3.1. Methodology for the Proposed Enhanced Approach
3.2. D1 Validation of Sensor Signals apart from Accelerometer Data
3.2.1. Reduced Features from Improved Statistical-Based Time-Frequency Domain (SBTFD)
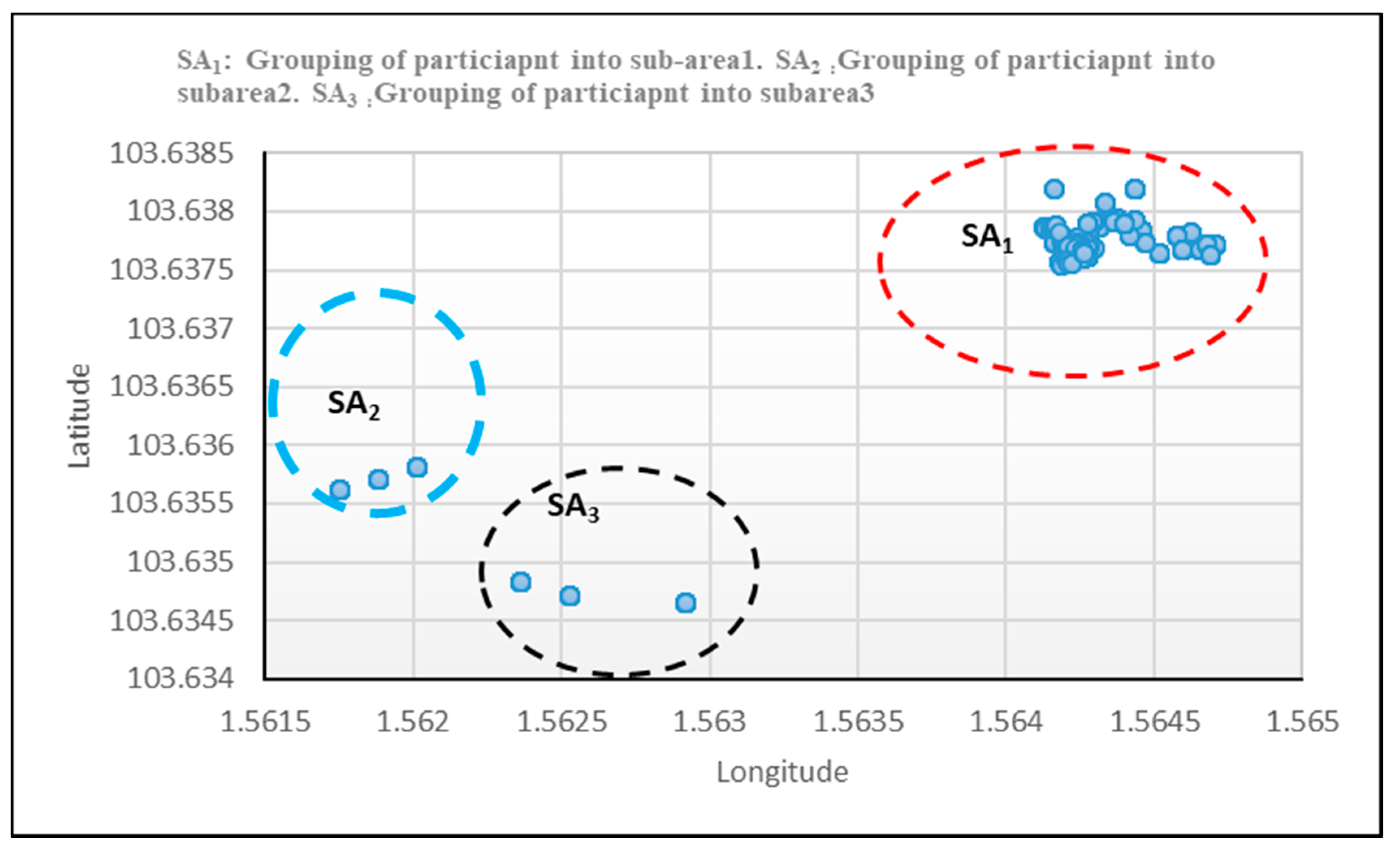
3.2.2. Modified Algorithm for Region Identification and Grouping of Nodes S
3.2.3. Flow Velocity Estimation and Flow Direction Identification Based on Activity Recognition
3.2.4. Implementation of Modified PBEA Algorithm
3.2.5. Crowd Density Threshold Condition
4. Experimental Results
4.1. Result on the Classification of Raw Dataset D1
4.2. Results of Region Identification and Grouping of Nodes Using Clusters
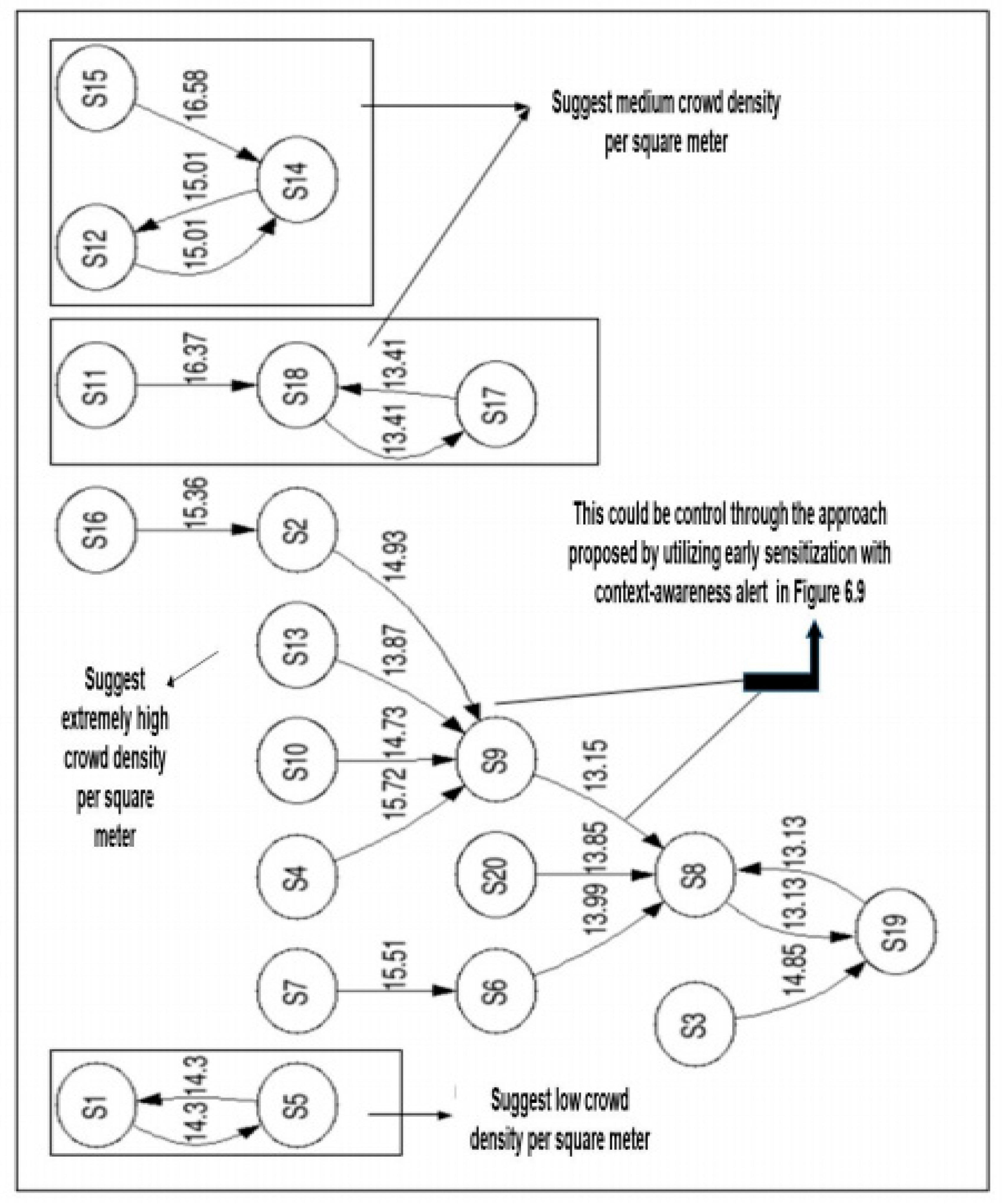
4.3. Results on the Algorithm Implemented for Flow Velocity and Flow Direction
4.4. Modified PBEA Using Reduced Features and Enhanced Individual Behavior Estimation
4.4.1. Crowd Condition Prediction Using Individual Behaviour Estimation
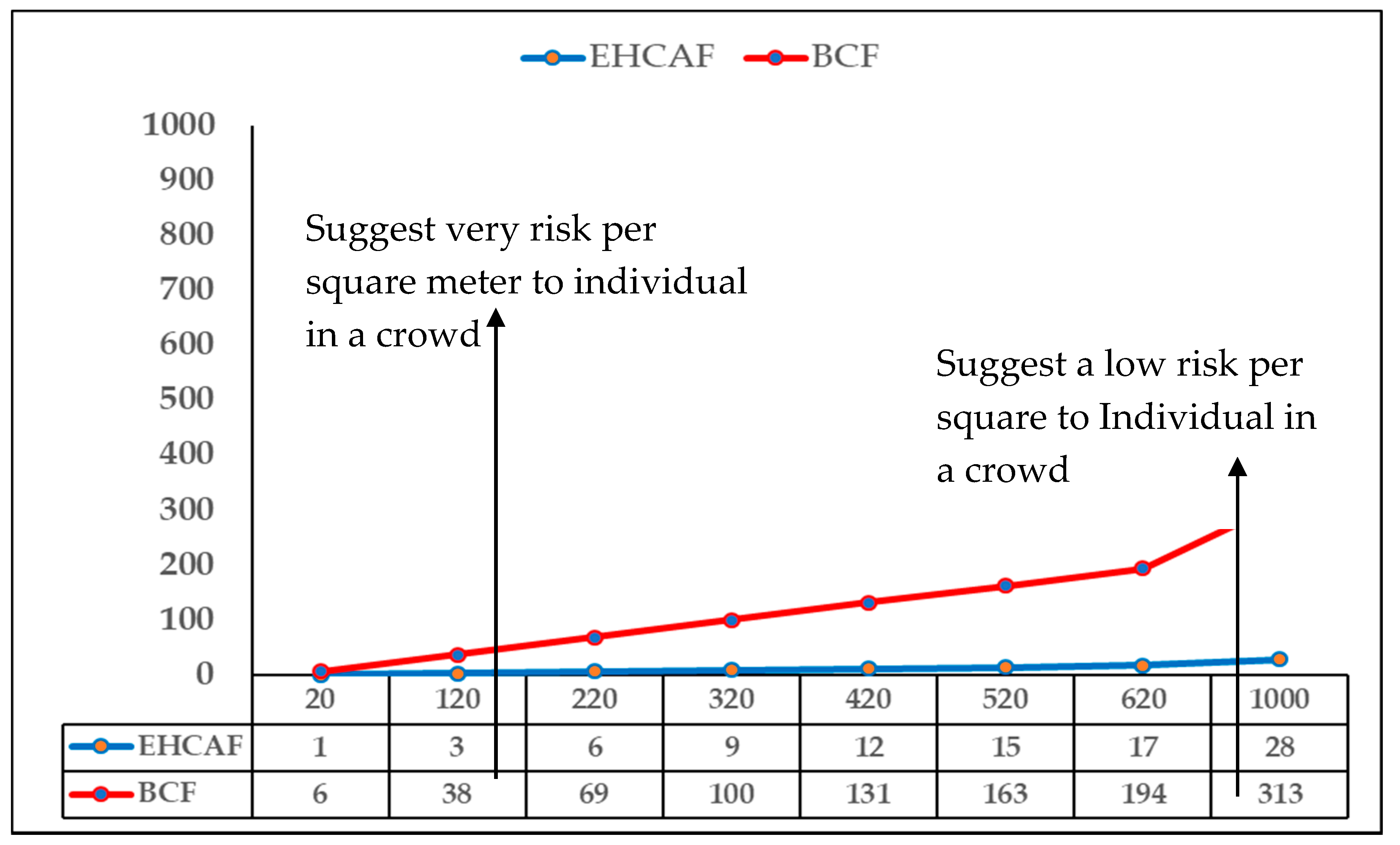
4.4.2. Implication of Low False Negative Alarm on the Enhanced Approach Based on PBEA Experiment
5. Discussion of Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1. Modified algorithm for region identification and grouping of participants based on clusters using K-means with node S |
| 1. Set S: node for participant’s smartphone |
| 2. Set Lat: Latitude |
| 3. Set Long: Longitude |
| 4. Set T: Time |
| 5. Set SA: Sub-arealist = [SA1, SA2, SA3,…, SAn] |
| 6. Set Dist: Distance |
| 7. K: Clusters of nodes into sub-areas |
| 8. TWindow: Time T, set for the location of nodes a threshold |
| 9. Start |
| 10. Input S: Output (Lat, Long, Time) |
| 11. Input Sub-area list [SA1, SA2, SA3,…, SAn, Lat, long, T] |
| 12. Output S clusters in Sub-areas, SAn |
| 13. While S is ready do |
| 14. For each S for participant in Sub-Arealist do |
| 15. Set locationUpdateWindow |
| 16. Set minT i.e., for location manager minimum power consumption with minT |
| Milliseconds between location update to reserve power |
| 17. Set minDist: as location transmission in case device moves using minDistance |
| meters |
| 18. TDifference = location.getT( )- currentbestlocation.getT( ) |
| If TDifference > TWindow then participant (node) have moved and transmit |
| the new location into a Crowd Controller Station (CCS) based on timestamp |
| change |
| 19. If (Lat, Long) in location context with Sub-arealist SAn are the same, |
| clusters set K using Dist between the nodes S |
| 20. Group S into SA1, SA2, SA3,…, SAn clusters |
| 21. Crowdcount = S + 1 |
| 22. End If |
| 23. End If |
| 24. End For |
| 25. End While |
| 26. End |
Appendix B
| Algorithm A2: Enhanced approach for individual and crowd condition prediction proposed to extend BCF |
| 1. IARehcaf Module |
| 2. Set S: as node for a participant using a smartphone |
| 3. Set CCS: crowd controller station: stakeholder as STHD |
| 4. Set IAR: Individual activity recognition |
| 5. Set SBTFD: Improved feature extraction method |
| 6. Set Vsi and Dsi: Flow velocity and flow direction |
| 7. Set PBE: Pairwise behavior estimation |
| 8. Set CCP: crowd condition prediction = 0 for all nodes using S |
| 9. Set CCP as threshold using equation (11) |
| 10. Input IAR sensor signals dataset D1 from CCS |
| 11. Execute IAR for S using improved SBTFD |
| 12. Execute dimensionality reduction using reduced features based on FSM |
| 13. IBEehcaf Module |
| 14. Cluster node S using set K based on Algorithm 1 |
| 15. Compute Vsi and Dsi for each S based on Section 3.2.3 |
| 16. Execute PBEA using lines 12 and 15 for each class based on Figure 4 |
| 17. CCP Module |
| 18. Compute CDD using equations 9 and 10 |
| 19. If the threshold satisfies condition 1, then |
| 20. Terminate the PBE testing |
| 21. Else |
| 22. If the threshold satisfies condition 2, then |
| 23. Terminate the PBE testing |
| 24. Else |
| 25. If the threshold satisfies condition 3, then |
| 26. Evaluate CDD inflow, outflow and crowd turbulence |
| 27. Else |
| 28. If the threshold satisfies condition 4, then |
| 29. Evaluate line 26 and set CCP = 1 |
| 30. (Send context-aware alert to S and STHD for safety measure) |
| 31. Output context-aware alert for CCP based on line 29 using EHCAF |
| 32. End if |
| 33. Else |
| 34. Execute line 14 to 31 |
| 35. End if |
| 36. End if |
| 37. End if |
| 38. End |
Appendix C

Appendix D

References
- Duives, D.C.; Wang, G.; Kim, J. Forecasting pedestrian movements using recurrent neural networks: An application of crowd monitoring data. Sensors 2019, 19, 382. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Al-Qaness, M.; Zhang, Y.; Zhao, B.; Luan, X. A robust and device-free system for the recognition and classification of elderly activities. Sensors 2016, 16, 2043. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, H.; Haibin, Y.; Lu, Y. Crowd abnormal behavior detection based on machine learning. Inf. Technol. J. 2013, 12, 1199–1205. [Google Scholar] [CrossRef][Green Version]
- Sadiq, F.I.; Selamat, A.; Ibrahim, R.; Ondrej, K. Improved feature extraction method with statistical based time frequency domain for classification oindividual activity recognition in a crowd scenario. Available online: www.news.unimas.my/conference/eventdetail/4309/-/- (accessed on 1 September 2018).
- Mshali, H.; Lemlouma, T.; Magoni, D. Adaptive monitoring system for e-health smart homes. Pervasive Mob. Comput. 2018, 43, 1–19. [Google Scholar] [CrossRef]
- Ramesh, M.V.; Shanmughan, A.; Prabha, R. Context aware ad hoc network for mitigation of crowd disasters. Ad Hoc Netw. 2014, 18, 55–70. [Google Scholar] [CrossRef]
- Franke, T.; Lukowicz, P.; Blanke, U. Smart crowds in smart cities: Real life, city scale deployments of a smartphone based participatory crowd management platform. JISA 2015, 6, 1–19. [Google Scholar] [CrossRef]
- Sadiq, F.I.; Selamat, A.; Ondrej, K.; Ibrahim, R. Impacts of feature selection on classification of individual activity recognitions for prediction of crowd disasters. Int. J. Intell. Inf. Database Syst. in press.
- Yaseen, S.; Al-Habaibeh, A.; Su, D.; Otham, F. Real-time crowd density mapping using a novel sensory fusion model of infrared and visual systems. Saf. Sci. 2013, 57, 313–325. [Google Scholar] [CrossRef]
- Ngo, M.Q.; Haghighi, P.D.; Burstein, F. A crowd monitoring framework using emotion analysis of social media for emergency management in mass gatherings. Available online: https://arxiv.org/abs/1606.00751 (accessed on 8 May 2019).
- Lara, O.D.; Labrador, M. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Pressac. Benefits of smart Sensor Technology. Available online: https://www.pressac.com/insights/benefits-of-smart-sensor-technology/ (accessed on 12 April 2019).
- Otebolaku, A.M.; Andrade, M.T. User context recognition using smartphone sensors and classification models. J. Netw. Comput. Appl. 2016, 66, 33–51. [Google Scholar] [CrossRef]
- Holgersson, P.; Åkerberg, F. Analysis of Activity Recognition and the Influence of Feature Extraction and Selection in an Android Based Device. Master’s Theses, Lund University, Lund, Sweden, 2015.
- Khan, A.M.; Tufail, A.; Khattak, A.M.; Laine, T.H. Activity recognition on smartphones via sensor-fusion and KDA-based SVMs. Int. J. Distrib. Sens. Netw. 2014, 10, 503291. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical human activity recognition using wearable sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M.P. Preprocessing techniques for context recognition from accelerometer data. Pers. Ubiquit. Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Reiss, A.; Hendeby, G.; Stricker, D. A Competitive approach for human activity recognition on smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2013), Bruges, Belgium, 24–26 April 2013; pp. 1–7. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN. 201, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Kumari, S.; Mitra, S.K. Human action recognition using DFT. In Proceedings of the 2011 Third National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics, Hubli, India, 15–17 December 2011. [Google Scholar]
- Rahman, M. Applications of Fourier Transforms to Generalized Functions; WIT Press: Southampton, UK; Boston, MA, USA, 2011; pp. 1–168. [Google Scholar]
- Phan, T. Improving activity recognition via automatic decision tree pruning. In Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; pp. 827–832. [Google Scholar]
- Cao, L.; Wang, Y.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient group-based context–aware human activity recognition on smartphone. J. Parallel Distr. Comput. 2017, in press. [Google Scholar] [CrossRef]
- Zhenyu, H.; Lianwen, J. Activity Recognition from acceleration data Based on Discrete Consine Transform and SVM. In Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics, San Antonio, TX, USA, 11–14 October 2009. [Google Scholar]
- Roggen, D.; Wirz, M.; Tröster, G.; Helbing, D. Recognition of crowd behavior from mobile sensors with pattern analysis and graph clustering methods. Available online: https://arxiv.org/abs/1109.1664 (accessed on 8 May 2019).
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart Devices are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015. [Google Scholar]
- Chen, Y.; Shen, C. Performance analysis of smartphone-sensor behavior for human activity recognition. IEEE Access 2017, 5, 3095–3110. [Google Scholar] [CrossRef]
- Sukor, A.A.; Zakaria, A.; Rahim, N.A. Activity recognition using accelerometer sensor and machine learning classifiers. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), Batu Feringghi, Malaysia, 9–10 March 2018. [Google Scholar]
- Haritha, V. Physical Human Activity Recognition Using Machine Learning Algorithms. Available online: https://arrow.dit.ie/cgi/viewcontent.cgi?article=1117&context=scschcomdis (accessed on 8 May 2019).
- Zainuddin, Z.; Lai, K.H.; Ong, P. An enhanced harmony search based algorithm for feature selection: Applications in epileptic seizure detection and prediction. Comput. Electr. Eng. 2016, 2016, 1–20. [Google Scholar] [CrossRef]
- Chernbumroong, S.; Cang, S.; Yu, H. Maximum relevancy maximum complementary feature selection for multi-sensor activity recognition. Expert Syst. Appl. 2015, 42, 573–583. [Google Scholar] [CrossRef]
- Ji, Y.; Yang, Y.; Xu, X.; Tao, H. One-shot learning based pattern transition map for action early recognition. Signal Process. 2018, 143, 364–370. [Google Scholar] [CrossRef]
- Yasser, E.-M.; Hsieh, T.-Y.; Shivakumar, M.; Kim, D.; Honavar, V. Min-redundancy and max-relevance multi-view feature selection for predicting ovarian cancer survival using multi-omics data. BMC Med. Genom. 2018, 11, 71. [Google Scholar]
- Chang, H.; Kang, Y.; Ahn, H.; Jang, C.; Choi, E. Context-aware Mobile platform for intellectual disaster alerts system. Energy Procedia 2012, 16, 1318–1323. [Google Scholar] [CrossRef]
- Ravindran, R.; Suchdev, R.; Tanna, Y.; Swamy, S. Context aware and pattern oriented machine learning framework (CAPOMF) for Android. In Proceedings of the Advances in Engineering and Technology Research (ICAETR), Unnao, India, 1–2 August 2014. [Google Scholar]
- Baldauf, M.; Dustdar, S.; Rosenberg, F. A survey on context-aware systems. Int. J. Ad Hoc Ubiquit. Comput. 2007, 2, 263–277. [Google Scholar] [CrossRef]
- Otebolaku, A.; Lee, G.M. A framework for exploiting internet of things for context-aware trust-based personalized services. Mob. Inf. Syst. 2018, 2018. [Google Scholar] [CrossRef]
- Bouguessa, A.; Mebarki, L.A.; Boudaa, B. Context-aware adaptation for sustaining disaster management. In Proceedings of the 12th International Symposium on Programming and Systems (ISPS), Algiers, Algeria, 28–30 April 2015. [Google Scholar]
- Markets, A.M. Context-Aware Computing Market Worth $120 Billion by 2018. Available online: https://www.marketsandmarkets.com/PressReleases/context-aware-computing.asp (accessed on 8 May 2019).
- Kayes, A.; Han, J.; Rahayu, W.; Islam, M.; Colman, A. A policy model and framework for context-aware access control to information resources. Comput. J. 2019, 62, 670–705. [Google Scholar] [CrossRef]
- Suto, J.; Oniga, S.; Sitar, P.P. Feature analysis to human activity recognition. Int. J. Comput. Commun. Contr. 2017, 12, 116–130. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Smartphone-based construction workers’ activity recognition and classification. Automat. Constr. 2016, 71, 198–209. [Google Scholar] [CrossRef]
- Sadiq, F.I.; Selamat, A.; Ibrahim, R.; Selamat, M.H.; Krejcar, O. Stampede prediction based on individual activity recognition for context-aware framework using sensor-fusion in a crowd scenarios. SoMeT 2017, 297, 385–396. [Google Scholar]
- Vermeesch, P. Multi-sample comparison of detrital age distributions. Chem. Geol. 2013, 341, 140–146. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Fruin, J.J. The causes and prevention of crowd disasters. Eng. Crowd Saf. 1993, 99–108. [Google Scholar]
- Helbing, D.; Johansson, A.; Al-Abideen, H.Z. Crowd turbulence: The physics of crowd disasters. Available online: https://arxiv.org/abs/0708.3339 (accessed on 8 May 2019).
- Rodrigues Leal Moitinho de Almeida, M. Human stampedes: A scoping review. Available online: http://digibuo.uniovi.es/dspace/bitstream/10651/39115/6/TFM_MariaRodriguesLMdeAlmeida.pdf (accessed on 8 May 2019).
- Zheng, Y. Human activity recognition based on the hierarchical feature selection and classification framework. J. Electr. Comput. Eng. 2015, 2015, 34. [Google Scholar] [CrossRef]
- Erdaş, Ç.B.; Atasoy, I.; Açıcı, K.; Oğul, H. Integrating features for accelerometer-based activity recognition. Procedia Comput. Sci. 2016, 98, 522–527. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Domain | Feature Extraction Methods | Merits | Demerits |
|---|---|---|---|
| TD | Mean | Is a good discriminator of individual characteristics calculated with small computational cost and a small memory requirement, is commonly used a feature in activity recognition (AR) research [12,16,22] | Does not produce a good result when isolated from other measures. |
| Standard deviation | Derived through the use of mean to reveal any deviation in AR sensor data [6] | Frequency domain absence hinders its performance | |
| Correlation | Help to determine the correlation between one individual’s characteristic feature and the other to express [6]. | Failure to produce the FD along the corresponding axis affects the performance of AR accuracy. | |
| Root Mean Square | Quality of sensor’s data may dictate its tendency to reveal the actual location for individual in the prediction of crowd disaster [6]. | Could not work in isolation from other measures. | |
| FD | FFT_RMS | Good tool for stationary signal processing [6,18]. | Weakness in analysing non-stationary signals from sensor data. |
| TDFD | Time domain -frequency domain | Produce an efficient performance for individual’s representation in the crowd [6,14]. | The use of FFT_RMS as the only FD may not assume the performance of other TD features. |
| Feature Extracted Methods in Activity Recognition | Application Domain | Features That Have Been Used in a Crowd | Reference |
|---|---|---|---|
| DD: Discrete cosine transform (DCT) 48 coefficients DCT features extracted | Daily activity | N/A | [25] |
| Variance (Var.) ax, ay, and az; number is not specified | Crowd behavior | Var. along x, y, and z | [26] |
| TD: Mean; std.; mad; max; min; sma; interquartile range (Iqr); entropy; arCoeff; cor.; maxfreq.; meanfreq.; FD: Max; min; sma; interquartile (iqr); skewness; kurtosis, energy band; angle; TDFD: 561 features | Daily living activity | Mean, Std, along x, y, and z | [18] |
| TD: mean, std., correlation (corr.), rms ax ay az. FD: FFT_rms ax ay az; TDFD: 15 features | Crowd abnormality monitor (CAM) | Features in the baseline study Known as BCF | [6] |
| TD: all time domain features in Table 1; FD: spectral coefficient; max. frequency; entropy of coefficient; dominating frequency; discrete coefficient; empirical cumulative distribution function (ECDF): with the setting of parameter value based on bin used for inverse computation; number is not specified | Motion sensing in daily life | Mean, Std, along x, y, and z | [27] |
| TD: mean, max, min, std., zero cross, median, range, sum of square, rms and var. TD: 30 features | Individual activity contexts | Mean, Std, along x, y, and z | [11] |
| TD: Mean; std.; max.; min.; corr.; Iqr.; DD: Dynamic time warping distance discrete time wavelet (DTW). FD: FFT coefficients as frequency domain features; except the first FFT coefficient. WD: wavelet energy TDFD and WD: 89 features | Motion sensor for daily activity | Mean, Std, along x, y, and z | [28] |
| TD: min, max, mean, STD, signal magnitude area (SMA), signal vector magnitude (SVM), tilt angle, FD: power spectral density (PSD), signal entropy, special energy: 60 features | User’s daily detection of abnormality | Mean, Std, along x, y, and z | [29] |
| Improved SBTFD features presented in our previous work | Individual and crowd condition prediction | 15 features are newly suggested as improved TD for SBTD, and 24 features as improved FD for SBFD | [4] |
| Context-Aware Framework/AR | ARAC | FSM | CCP | Features Used | Why the Features Are Not Enough |
|---|---|---|---|---|---|
| CAM-BCF [6,42] | 92% based on TDFD | N/A | A high false negative rate | TD: mean x, y, z, std. x, y, z; cor. xy, yz, xz; rms. x, y, z; FD: FFT rms along x, y, z-axes as TDFD features | Salient TD and FD features with better result commonly used in literature were overlooked |
| IDAS [36] | N/A | N/A | N/A | N/A | N/A |
| Context recognition [11] | 55–98% based on TD | N/A | N/A | TD: Mean, STD.; Med. Min., Max., Zero Crossing, (ZC), Sum of Squares (SOS), rms, Range, Var | Attention paid to the only TD without giving consideration to FD that compliments TD features |
| Feature analysis [42] | 86–93% based on FSM | CFS, CHI, MRMR | N/A | 75th Percentile (PE): PE_y, min-max: mm_x, mm_y, PE_x, mm_z, PE_z | Negligence of FD features in selected features and 86.6% reported for MRMR |
| Coupling HAR [43] | 86–91% based on TDFD | N/A | N/A | Not specified | The detail was not given |
| Attribute | Dataset 1 (D1) [4] | Class | Activity/Sensors Name |
|---|---|---|---|
| Age | 25–51 years | V1 | Climb down |
| Activity count | 8 | V2 | Climb up |
| No of instances | 22,350 | V3 | Fall |
| No of participants | 20 | V4 | Jogging |
| Sensor type | Accelerometer x, y, and z digital compass (DC), longitude, latitude, timestamp | V5 | Peak shake while standing |
| Position placement | Hand | V6 | Standing |
| No. of devices | 20 smartphone | V7 | Still |
| Dataset gathering | Crowd controller as a server | V8 | Walking |
| V12 | Latitude | ||
| V13 | Longitude | ||
| V14 | Speed | ||
| V15 | Altitude | ||
| V16 | Timestamp | ||
| V17 | Digital compass | ||
| V18 | Accuracy |
| Class Label | Predicted Class | Actual Class | |||||||
|---|---|---|---|---|---|---|---|---|---|
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | TP + FN | |
| Climb down: V1 | 591 | 425 | 228 | 147 | 106 | 137 | 41 | 300 | 1975 |
| Climb up: V2 | 405 | 705 | 292 | 178 | 161 | 186 | 57 | 426 | 2410 |
| Fall: V3 | 188 | 273 | 778 | 325 | 858 | 254 | 99 | 384 | 3159 |
| Jogging: V4 | 147 | 163 | 269 | 1698 | 190 | 131 | 42 | 312 | 2952 |
| Peak shake_wst: V5 | 113 | 161 | 854 | 233 | 767 | 101 | 24 | 144 | 2397 |
| Standing: V6 | 106 | 142 | 210 | 110 | 70 | 1813 | 85 | 221 | 2757 |
| Still: V7 | 40 | 67 | 112 | 49 | 47 | 110 | 2733 | 72 | 3230 |
| Walking: V8 | 273 | 380 | 418 | 312 | 159 | 255 | 66 | 1607 | 3470 |
| Total | 22350 | ||||||||
| Components | EHCAF | Justification |
|---|---|---|
| IARehcaf | ||
| AR dataset | Validation of D1 performed with ANOVA is significant | Explain the suitability of the D1 in line with the literature. Quality of data is very important for crowd monitoring and accurate prediction |
| Accuracy | 99.1%, 98.0%, and 99.0% were achieved | An improvement over BCF with enhanced accuracy performance is achieved |
| Feature selection method (FSM) | Minimum Redundancy Maximum Relevance with Information Gain (MRMR-IG) with SBTFD provided seven reduced features (Corr_xz-fft, y_fft_mean, z_fft_mean, z_fft_min, y_fft_min, z_fft_std, and y_fft_std) | Reduces the dimensionality of features space on the monitoring devices. Lower computational task. Facilitates early recognition and utilizes less time for classification |
| Classifier | J48, Random forest (RF) | Compatible with an Android device and widely used in AR |
| Accuracy & FNR | 99.1%; 2.8% | Improvement of 7.1% accuracy and 28.5% FNR over BCF |
| Individual Behavior Estimation | IBEehcaf | Provide accurate prediction to enhanced the safety of human lives |
| Region identification | Modified algorithm using k-means to implement Algorithms 1 and 2 with D1 to identify the region, cluster nodes S, and group into sub-areas | Potential to reveal susceptible clusters nodes in sub-areas that are prone to danger. Ascertain threshold with the specify coverage of nodes |
| Grouping of node S into Sub-area | ||
| Flow velocity and flow direction | Adopted and implemented using D1 | Serve as informative features to extract individual context behavior not possible for IAR in phases 1 to 3 |
| IBE | Modified PBEA using flow velocity (Vsi), flow direction (Dsi), and seven reduced features for IBE | Estimation of nodes per m2 and analysis within coverage areas experimented with volunteers |
| Threshold | Threshold > two per m2 | An efficient method should measure accurately the number of volunteers (node) within per m2 to prevent abnormality occurrence in a crowd. |
| Inflow, outflow & crowd turbulence | Compute and evaluated using CDD based on individual count | Potential to identify person prone to danger early using context-awareness alert |
| Crowd condition | Crowd abnormality behavior | To enhanced the safety of human lives in a crowded area |
| Prediction | Crowd condition prediction using modified PBEA with reduced features (CCPFSM) | Enhanced approach with improved accuracy and FNR performance |
| Validation | Inferential statistics and paired sample statistics test was used to validate all the three methods employed for the enhanced approach | Improved SBTFD with 0.002; reduced features with 0.003 and 0.021 of p < 0.05 are statistically significant |
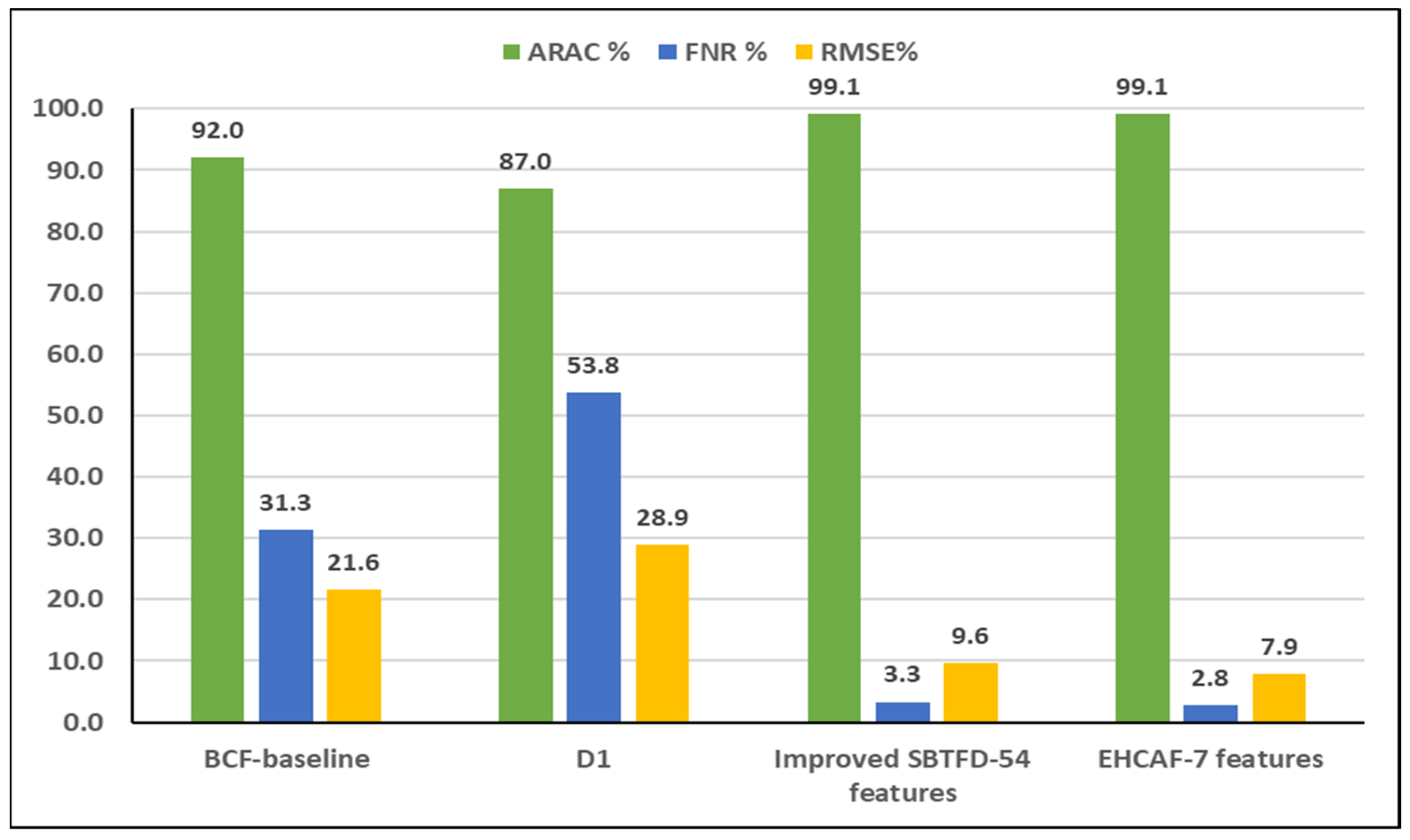
| Context-Aware Frameworks | SCI | ARAC | FEM | FSM | CCP | RMSE |
|---|---|---|---|---|---|---|
| BCF-baseline [5] | ✓ | 92.0% | TDFD-15 | N/A | High FNR (31.3%) | 21.6% |
| [11] | ✓ | 55% to 98.0% | TD-30 | N/A | N/A | N/A |
| [40] | N/A | N/A | TDFD Wavelet | MRMR 86.6% | High FNR (56.5%) | 31.0% |
| Proposed approach (EHCAF) | ✓ | 99.1% | Improved SBTFD-54 | 7 reduced features using MRMR-IG (method A)-99.1% | Low FNR (2.8%) | 7.9% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadiq, F.I.; Selamat, A.; Ibrahim, R.; Krejcar, O. Enhanced Approach Using Reduced SBTFD Features and Modified Individual Behavior Estimation for Crowd Condition Prediction. Entropy 2019, 21, 487. https://doi.org/10.3390/e21050487
Sadiq FI, Selamat A, Ibrahim R, Krejcar O. Enhanced Approach Using Reduced SBTFD Features and Modified Individual Behavior Estimation for Crowd Condition Prediction. Entropy. 2019; 21(5):487. https://doi.org/10.3390/e21050487
Chicago/Turabian StyleSadiq, Fatai Idowu, Ali Selamat, Roliana Ibrahim, and Ondrej Krejcar. 2019. "Enhanced Approach Using Reduced SBTFD Features and Modified Individual Behavior Estimation for Crowd Condition Prediction" Entropy 21, no. 5: 487. https://doi.org/10.3390/e21050487
APA StyleSadiq, F. I., Selamat, A., Ibrahim, R., & Krejcar, O. (2019). Enhanced Approach Using Reduced SBTFD Features and Modified Individual Behavior Estimation for Crowd Condition Prediction. Entropy, 21(5), 487. https://doi.org/10.3390/e21050487