Privacy-Constrained Biometric System for Non-Cooperative Users



 ,
, 

Abstract
1. Introduction
2. Related Work
- Group 1: in which the geometric features of the hand are used for the identification. Examples of such features include the length and the width of the hand palm. Conventional methods such as General Regression Neural Network (GRN) [18], graph theory [18], or later methods like sparse learning [19] are examples of this group.
- Group 2: in which hand vein patterns are used for the identification. These patterns are unique to every individual and are not affected by aging, scars and skin color [20]. Therefore, the vascular patterns of an individual’s hand (palm, dorsal or finger) can be used as a feature for biometric recognition systems. An example of this category includes wavelet and Local binary patterns (LBP) based [21,22] or recent deep learning-based methods [23]. Such features have been used in connection with CNNs [24] and extracted using thermal imaging and Hausdorff distance based matching [20,25], and using multi-resolution filtering [26].
- Group 3: in which palm prints are used for identification. Palm prints can be extracted according to texture, appearance, orientations or lines. Besides various conventional techniques, there are dictionary and deep learning methods [27,28] reported in literature. Considering the above categories, the geometry-based hand features are robust to both rotation and translation. However, at the same time, they are not suitable to scale variations. Moreover, in order to achieve high performance for the recognition task, a huge amount of measurements is needed to extract discriminative features of each subject. This will eventually increase the computational complexity. The hand vein features, on the other hand, are robust to varying hand poses and deformation. They may also introduce computational cost if all distances between landmark points are required. Finally, for the palm-print based recognition, some methods that achieve high recognition rates exist, but, in general, acquiring high-resolution palm-print images is challenging due to setup complexities.
Footprint
- Group 1: in which the shape and geometrical information of the human foot are used for identification. Features of this category concentrate on the length, shape and area of the silhouette curve, local foot widths, lengths of toes, eigenfeet features and angles of intertoe valleys [30]. The research works in [33,34,35,35] are a few examples of this category. In general, a variety of possible features makes shape and geometric-based methods very popular. In addition, these methods are robust to various environmental conditions. The drawback of such a large number of possible features, however, can eventually result in high intrapersonal variability.
- Group 2: in which the texture-based information of the human foot are used for identification. In this group, pressure (soleprint features analogous to palm print based of the hand biometric) and generated heat can be considered as the promising features. Examples in this category can be found in [30,36]. Unlike the shape and geometrical features of feet, acquiring a fine-grained texture of feet requires a high accuracy instrument. For example, skin-texture on palm-print involves extracting rather invisible line patterns as opposed to the similar one in the hands. Similar challenges may exist in recording ridge structure with high resolution. On the other hand, the high-resolution of texture-based features will require higher computational power with respect to shape and geometrical ones.
3. Acquisition Setup
4. Experimental Results and Discussion
4.1. Evaluation Protocol
- Independent frame analysis: The final evaluation is based on frames independently. That is, frames from the same subject are uncorrelated. The maximum output probability from each frame determines its final predicted class.
- Subject sequence analysis: The final evaluation is based on grouping frames from the same sequence/subject. We average output probabilities belonging to the same subject, and we finally obtain the maximum output value as its final predicted class.
- Hand–Feet Late Fusion Analysis: Averaged output probabilities from hand and feet outputs (aka subject sequence analysis) are averaged together for each subject to finally determine the final predicted class.
4.2. Conventional Techniques Evaluation
4.2.1. Local Binary Patterns and Support Vector Machine
- Setup: To acquire the regions of interest (ROI) for the moving object in each frame (hand or foot), in this experiment, we applied simple and fast frame difference. If the difference is greater than 80 pixels for the foot and 30 pixels for the hand videos (these values were found empirically), then the resulted difference frame will be recorded as a binary mask. Figure 3a shows an example of all masks within one sequence, where the color transition from dark gray to white represents transition from the start of the video to the end of the video. For the foot sequences, the bounding box for a particular frame is created by taking that frame and then superimposing the previous 10 frames, and the next 10 frames that contain binary masks (identical to a sliding window). In other words, a binary image was formed by repeating the logical OR operation for 21 consecutive frames after which a bounding box has been found for the detected region as shown in Figure 3b. On the other hand, for the hand sequences, a fixed bounding box was created by using OR operation for all binary frames. After drawing the bounding box, the images were cropped and then resized to pixels.
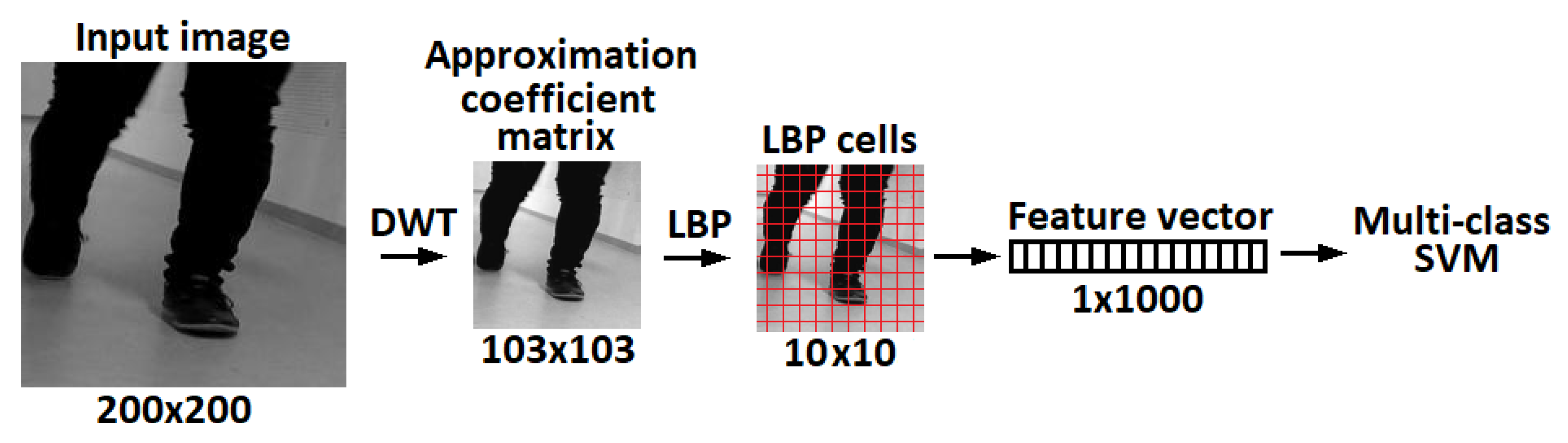
- Experiments: For the same subject, the total number of frames depend on the video length and therefore can not be fixed to a specific amount. The image features were extracted from an approximation coefficients matrix, which is one of the single-level two-dimensional wavelet decomposition method outputs. In particular, we used the Symlet wavelet to find results of the decomposition low-pass filter. Afterwards, the extracted rotation invariant local binary patterns from the output of wavelet decomposition were obtained as feature vectors to train a linear one-versus-one multi-class support vector machine. This process is shown in Figure 4. Finally, the fusion results obtained via majority voting, where a video label was determined by independent foot and hand frames. Results for single frame recognition and fusion can be found in Table 1. Note that, with a limited amount of data, taking into account that a random prediction classifier score in our problem of 77 labels is 1.3% accurate, which can be still considered as a reasonably good performance for the base line method.
4.2.2. Dictionary Learning
- Setup: As a prior step to employ the SRC method for the classifier, we select the frames where both hand and feet are visible. For this, we used the Kalman visual tracker [54], which also defines the ROI within the associated selected images. Figure 5 shows examples of extracted frames to be used in the training stage of Dictionary Learning.
- Experiments: For the dictionary learning-based method, we employ the sparse representation classifier (SRC) of [49] for independent frame analysis. We randomly selected 50 extracted frames per subject in the training phase. Therefore, we generate a dictionary of size with a patch dimension (feature size) of 100 for each subject. This value of feature size has been found experimentally to provide the best performance. Then, at the test stage, using the same feature size, we attempt to recover the sparsest solution (-minimization) to linear equation , where A is the generated dictionary and y is a test image vector, respectively. The obtained results are shown in Table 2. As it can be seen, from both Table 1 and Table 2, conventional spatial appearance models provide poor classification results in all evaluated scenarios. This suggests that a more effective feature extractor is needed in this context.
4.3. Deep Learning
- Setup: Since the dataset under study can be clearly linked to a classification problem, we have found it convenient to conduct our experiments on a standard ResNet-50 neural network architecture as shown in Figure 7. ResNet-50 has been proved to have a faster performance and lower computational cost compared to those of standard classification architectures such as VGG-16 due to its skip connection configuration [56]. For this purpose, we have constrained the input data (frames) to a image size, batch size of 32 and output classes to 77 (number of eligible subjects) during the training phase. We left the number of input channels as a degree of freedom that will be set according to the different experiments we conducted.
- Experiments: In order to utilize the network, we have arranged the input to the network in the following four fashions:
- Appearance—In this setting, the extracted frames, as before, are fed to the network for both the hand and foot datasets. Hence, input channel dimension is set to 3 due to the RGB nature of the frames. The recognition accuracy rate of this network is reported in Table 3.
- Optical Flow (OF)—OF values (u,v) are extracted for each consecutive pair of frames for both the hand and foot in the dataset. In this case, we set the input channel parameter to 2 due to the OF dimensionality. Table 4 summarizes the results of this setting.
- Appearance + OF—We apply an early fusion to the extracted frames and OF calculated values for both hand and feet datasets. That is, a 5-channel input parameter is set in order to match the RGB(3) + OF(2) new dimension. The results of this simulation are tabulated in Table 5.
- Appearance + Optical Flow (late fusion)—We finally bring appearance analysis and OF analysis, computed separately, together. From each ‘branch’ output, we apply the same principle from the late fusion modality and study its performance. The result of this mode category can be seen in Table 6.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Crisan, S. A Novel Perspective on Hand Vein Patterns for Biometric Recognition: Problems, Challenges, and Implementations. In Biometric Security and Privacy; Springer: Cham, Switzerland, 2017; pp. 21–49. [Google Scholar]
- Litvin, A.; Nasrollahi, K.; Escalera, S.; Ozcinar, C.; Moeslund, T.B.; Anbarjafari, G. A novel deep network architecture for reconstructing RGB facial images from thermal for face recognition. Multimed. Tools Appl. 2019, 78, 1–13. [Google Scholar] [CrossRef]
- Leyvand, T.; Li, J.; Meekhof, C.; Keosababian, T.; Stachniak, S.; Gunn, R.; Stuart, A.; Glaser, R.; Mays, E.; Huynh, T.; et al. Biometric recognition. U.S. Patent 9,539,500, 1 October 2017. [Google Scholar]
- Rath, A.; Spasic, B.; Boucart, N.; Thiran, P. Security Pattern for Cloud SaaS: From System and Data Security to Privacy Case Study in AWS and Azure. Computers 2019, 8, 34. [Google Scholar] [CrossRef]
- Campisi, P. Security and Privacy in Biometrics; Springer: Cham, Switzerland, 2013. [Google Scholar]
- Regulation Protection. Regulation (EU) 2016/679 of the European Parliament and of the Council, April 2016. Available online: http://www.gkdm.co.il/wp-content/uploads/2018/02/GDPR-Israel.pdf (accessed on 23 October 2019).
- Ofodile, I.; Helmi, A.; Clapés, A.; Avots, E.; Peensoo, K.M.; Valdma, S.M.; Valdmann, A.; Valtna-Lukner, H.; Omelkov, S.; Escalera, S.; et al. Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy 2019, 21, 414. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Anbarjafari, G. Emotion recognition from skeletal movements. Entropy 2019, 21, 646. [Google Scholar] [CrossRef]
- Sabet Jahromi, M.N.; Bonderup, M.B.; Asadi, M.; Avots, E.; Nasrollahi, K.; Escalera, S.; Kasaei, S.; Moeslund, T.; Anbarjafari, G. Automatic Access Control Based on Face and Hand Biometrics in A Non-Cooperative Context. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision - Cross Domain Biometric Recognition Workshop, Hawaii, HI, USA, 7 January 2018; pp. 1–9. [Google Scholar]
- Ishihara, T.; Kitani, K.M.; Ma, W.C.; Takagi, H.; Asakawa, C. Recognizing hand-object interactions in wearable camera videos. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1349–1353. [Google Scholar]
- Cheng, H.; Yang, L.; Liu, Z. Survey on 3D hand gesture recognition. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1659–1673. [Google Scholar] [CrossRef]
- Duta, N. A survey of biometric technology based on hand shape. Pattern Recognit. 2001, 42, 2797–2806. [Google Scholar] [CrossRef]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Kumar, A.; Wong, D.C.; Shen, H.C.; Jain, A.K. Personal authentication using hand images. Pattern Recognit. Lett. 2006, 27, 1478–1486. [Google Scholar] [CrossRef]
- Amayeh, G.; Bebis, G.; Erol, A.; Nicolescu, M. Peg-free hand shape verification using high order Zernike moments. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, CVPRW’06, New York, NY, USA, 17–22 June 2006; p. 40. [Google Scholar]
- Pavešić, N.; Ribarić, S.; Ribarić, D. Personal authentication using hand-geometry and palmprint features–The state of the art. Hand 2004, 11, 12. [Google Scholar]
- Zheng, J.; Feng, Z.; Xu, C.; Hu, J.; Ge, W. Fusing shape and spatio-temporal features for depth-based dynamic hand gesture recognition. Multimed. Tools Appl. 2017, 76, 20525–20544. [Google Scholar] [CrossRef]
- Polat, Ö.; Yıldırım, T. Hand geometry identification without feature extraction by general regression neural network. Expert Syst. Appl. 2008, 34, 845–849. [Google Scholar] [CrossRef]
- Goswami, G.; Mittal, P.; Majumdar, A.; Vatsa, M.; Singh, R. Group sparse representation based classification for multi-feature multimodal biometrics. Inf. Fusion 2016, 32, 3–12. [Google Scholar] [CrossRef]
- Kumar, A.; Prathyusha, K.V. Personal authentication using hand vein triangulation and knuckle shape. IEEE Trans. Image Process. 2009, 18, 2127–2136. [Google Scholar] [CrossRef] [PubMed]
- Malutan, R.; Emerich, S.; Crisan, S.; Pop, O.; Lefkovits, L. Dorsal hand vein recognition based on Riesz Wavelet Transform and Local Line Binary Pattern. In Proceedings of the 3rd International Conference on Frontiers of Signal Processing (ICFSP), Paris, France, 6–8 September 2017; pp. 146–150. [Google Scholar]
- Anbarjafari, G.; Izadpanahi, S.; Demirel, H. Video resolution enhancement by using discrete and stationary wavelet transforms with illumination compensation. Signal Image Video Process. 2015, 9, 87–92. [Google Scholar] [CrossRef]
- Li, X.; Huang, D.; Wang, Y. Comparative study of deep learning methods on dorsal hand vein recognition. In Proceedings of the Chinese Conference on Biometric Recognition, Chengdu, China, 14–16 October 2016; pp. 296–306. [Google Scholar]
- Qin, H.; El-Yacoubi, M.A. Deep representation-based feature extraction and recovering for finger-vein verification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1816–1829. [Google Scholar] [CrossRef]
- Wang, L.; Leedham, G. A thermal hand vein pattern verification system. In Proceedings of the International Conference on Pattern Recognition and Image Analysis, Bath, UK, 22–25 August 2005; pp. 58–65. [Google Scholar]
- Wang, L.; Leedham, G.; Cho, D.S.Y. Minutiae feature analysis for infrared hand vein pattern biometrics. Pattern Recognit. 2008, 41, 920–929. [Google Scholar] [CrossRef]
- Xu, Y.; Fan, Z.; Qiu, M.; Zhang, D.; Yang, J.Y. A sparse representation method of bimodal biometrics and palmprint recognition experiments. Neurocomputing 2013, 103, 164–171. [Google Scholar] [CrossRef]
- Wan, H.; Chen, L.; Song, H.; Yang, J. Dorsal hand vein recognition based on convolutional neural networks. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1215–1221. [Google Scholar]
- Kennedy, R.B. Uniqueness of bare feet and its use as a possible means of identification. Forensic Sci. Int. 1996, 82, 81–87. [Google Scholar] [CrossRef]
- Uhl, A. Footprint-based biometric verification. J. Electron. Imaging 2008, 17, 011016. [Google Scholar] [CrossRef][Green Version]
- Nakajima, K.; Mizukami, Y.; Tanaka, K.; Tamura, T. Footprint-based personal recognition. IEEE Trans. Biomed. Eng. 2000, 47, 1534–1537. [Google Scholar] [CrossRef]
- Jung, J.W.; Bien, Z.; Lee, S.W.; Sato, T. Dynamic-footprint based person identification using mat-type pressure sensor. In Proceedings of the 25th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (IEEE Cat. No. 03CH37439), Cancun, Mexico, 17–21 September 2003; pp. 2937–2940. [Google Scholar]
- Kumar, V.A.; Ramakrishan, M. Employment of footprint recognition system. Indian J. Comput. Sci. Eng. (IJCSE) 2013, 3, 774–778. [Google Scholar]
- Barker, S.; Scheuer, J. Predictive value of human footprints in a forensic context. Med. Sci. Law 1998, 38, 341–346. [Google Scholar] [CrossRef] [PubMed]
- Kumar, V.A.; Ramakrishnan, M. Manifold feature extraction for foot print image. Indian J. Bioinform. Biotechnol. 2012, 1, 28–31. [Google Scholar]
- Kushwaha, R.; Nain, N.; Singal, G. Detailed analysis of footprint geometry for person identification. In Proceedings of the 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 229–236. [Google Scholar]
- Rohit Khokher, R.C.S. Footprint-based personal recognition using scanning technique. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Boyd, J.E.; Little, J.J. Biometric gait recognition. Advanced Studies in Biometrics; Springer: Cham, Switzerland, 2005; pp. 19–42. [Google Scholar]
- MathWorks. Single Camera Calibrator App. 2018. Available online: https://www.mathworks.com/help/vision/ug/single-camera-calibrator-app.html (accessed on 23 October 2019).
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face recognition with local binary patterns. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 469–481. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar]
- Demirel, H.; Anbarjafari, G. Data fusion boosted face recognition based on probability distribution functions in different colour channels. EURASIP J. Adv. Signal Process. 2009, 2009, 25. [Google Scholar] [CrossRef]
- Benzaoui, A.; Boukrouche, A.; Doghmane, H.; Bourouba, H. Face recognition using 1DLBP, DWT and SVM. In Proceedings of the 3rd International Conference on Control, Engineering & Information Technology (CEIT), Tlemcen, Algeria, 25–27 May 2015; pp. 1–6. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Proceedings of the 9th International Conference on Neural Information Processing Systems, Denver, CO, USA, 3–5 December 1997; pp. 155–161. [Google Scholar]
- Schölkopf, B.; Burges, C.; Vapnik, V. Incorporating invariances in support vector learning machines. In Proceedings of the International Conference on Artificial Neural Networks, Bochum, Germany, 16–19 July 1996; pp. 47–52. [Google Scholar]
- Elshatoury, H.; Avots, E.; Anbarjafari, G.; Initiative, A.D.N. Volumetric Histogram-Based Alzheimer’s Disease Detection Using Support Vector Machine. Available online: https://content.iospress.com/articles/journal-of-alzheimers-disease/jad190704 (accessed on 23 October 2019).
- Cherifi, D.; Cherfaoui, F.; Yacini, S.N.; Nait-Ali, A. Fusion of face recognition methods at score level. In Proceedings of the International Conference on Bio-engineering for Smart Technologies (BioSMART), Dubai, UAE, 4–7 December 2016; pp. 1–5. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Li, X.; Jia, T.; Zhang, H. Expression-insensitive 3D face recognition using sparse representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2575–2582. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Discriminative Learned Dictionaries for Local Image Analysis; Minnesota Univ. Minneapolis Inst. for Mathematics and Its Applications: Minneapolis, MN, USA, 2008. [Google Scholar]
- Cai, J.F.; Ji, H.; Liu, C.; Shen, Z. Blind motion deblurring from a single image using sparse approximation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 104–111. [Google Scholar]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Azarbayejani, A.; Pentland, A.P. Recursive estimation of motion, structure, and focal length. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 6, 562–575. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | |
|---|---|
| Modality | Independent frames DWT-LBP-SVM |
| Hand | 37.78% |
| Foot | 34.12% |
| Hand+Foot (late fusion) | 57.14% |
| Accuracy (Dictionary Learning) | |
|---|---|
| Modality | Independent frames SRC |
| Hand | 49.1% |
| Foot | 41.3% |
| Hand+Foot (late fusion) | 54.1% |
| Accuracy (Deep Learning) | |||
|---|---|---|---|
| No. of Samples | Modality | Independent Frames (appearance) | Subject Sequence (appearance) |
| 2889 | Hand | 70.0% | 80.5% |
| 10195 | Foot | 58.6% | 70.1% |
| Hand+Foot (late fusion) | — | 84.4% | |
| Accuracy (Deep Learning) | |||
|---|---|---|---|
| No. of Samples | Modality | Independent Frames (Optical Flow) | Subject Sequence (Optical Flow) |
| 2812 | Hand | 32.6% | 62.3% |
| 10118 | Foot | 35.1% | 48.1% |
| Hand+Foot (late fusion) | — | 59.7% | |
| Accuracy (Deep Learning) | |||
|---|---|---|---|
| No. of Samples | Modality | Independent frames (appearance+ OF) | Subject Sequence (appearance+ OF) |
| 2812 | Hand | 34.7% | 62.3% |
| 10118 | Foot | 54.8% | 71.4% |
| Hand+Foot (late fusion) | — | 71.4% | |
| Accuracy (Deep Learning) | |
|---|---|
| Modality | Subject Sequence |
| Appearance+OF/ Late Fusion | |
| Hand+Foot | 83.1% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
S. Jahromi, M.N.; Buch-Cardona, P.; Avots, E.; Nasrollahi, K.; Escalera, S.; Moeslund, T.B.; Anbarjafari, G. Privacy-Constrained Biometric System for Non-Cooperative Users. Entropy 2019, 21, 1033. https://doi.org/10.3390/e21111033
S. Jahromi MN, Buch-Cardona P, Avots E, Nasrollahi K, Escalera S, Moeslund TB, Anbarjafari G. Privacy-Constrained Biometric System for Non-Cooperative Users. Entropy. 2019; 21(11):1033. https://doi.org/10.3390/e21111033
Chicago/Turabian StyleS. Jahromi, Mohammad N., Pau Buch-Cardona, Egils Avots, Kamal Nasrollahi, Sergio Escalera, Thomas B. Moeslund, and Gholamreza Anbarjafari. 2019. "Privacy-Constrained Biometric System for Non-Cooperative Users" Entropy 21, no. 11: 1033. https://doi.org/10.3390/e21111033
APA StyleS. Jahromi, M. N., Buch-Cardona, P., Avots, E., Nasrollahi, K., Escalera, S., Moeslund, T. B., & Anbarjafari, G. (2019). Privacy-Constrained Biometric System for Non-Cooperative Users. Entropy, 21(11), 1033. https://doi.org/10.3390/e21111033