A Mobile Application for Smart Computer-Aided Self-Administered Testing of Cognition, Speech, and Motor Impairment



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Methodology
3.2. Mobile Application
3.3. Tasks
3.3.1. T1–T3: Finger-Tapping Tasks
3.3.2. T4: Archimedean Spiral
3.3.3. T5–T7: SAGE Cognitive Tests
3.3.4. T8: Similarities Calculation
3.3.5. T9: 3D Construction
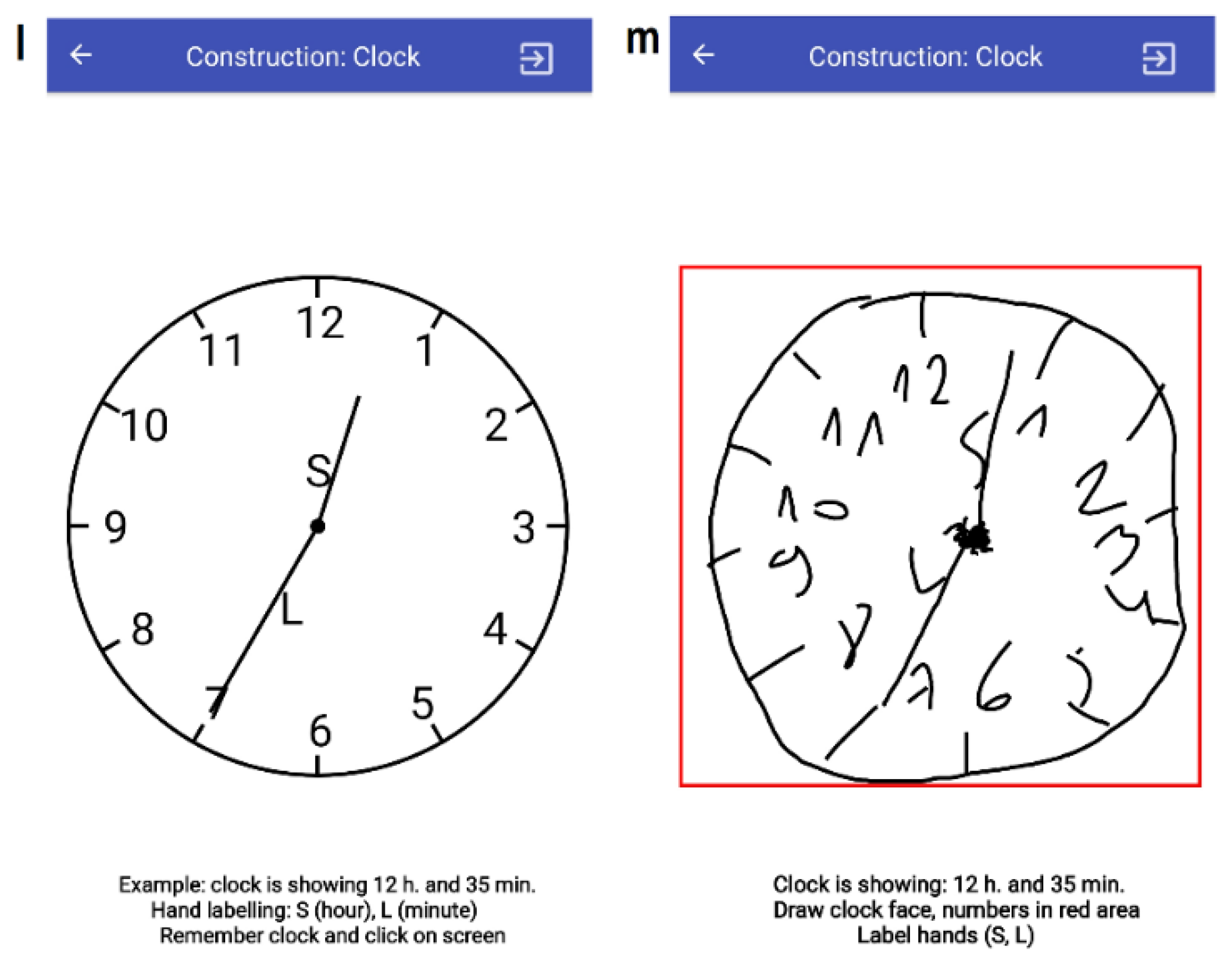
3.3.6. T10: Construction (Clock)
3.3.7. T11: Verbal Fluency
3.3.8. T12: Executive (Modified Trials)
3.3.9. T13: Executive (Problem Solving)
3.3.10. T14: Voice Recorder
3.3.11. T15: Total Daily Energy Expenditure (TDEE)
3.3.12. T0: Memory
3.4. Hybrid Classification Model for Decision Support
3.5. Hardware
3.6. Data Collection
3.7. Subjects
3.8. Dataset
4. Experiments and Results
4.1. Outline
- Experiment 1 (E1): the feature set is distributed using individual tasks only (14 different classifiers).
- Experiment 2 (E2): all 238 features were combined (integrated) and fed into a classifier, were combinations of classifiers were used to propose a hybrid model.
- Experiment 3 (E3): audio files (from task T14) were used for further processing to extract features using a combination of methods (pitch, MFCC, GTCC, and spectral skewness) and to classify samples with deep learning networks (in particular, bidirectional long short-term memory (BiLSTM)).
- Experiment 4 (E4): audio files (from T14) were used for further processing to extract features using the WST method and to classify samples with an SVM.
4.2. Cross-Validation
4.3. E1: Sick vs. Healthy Classification Models for the Individual Tasks
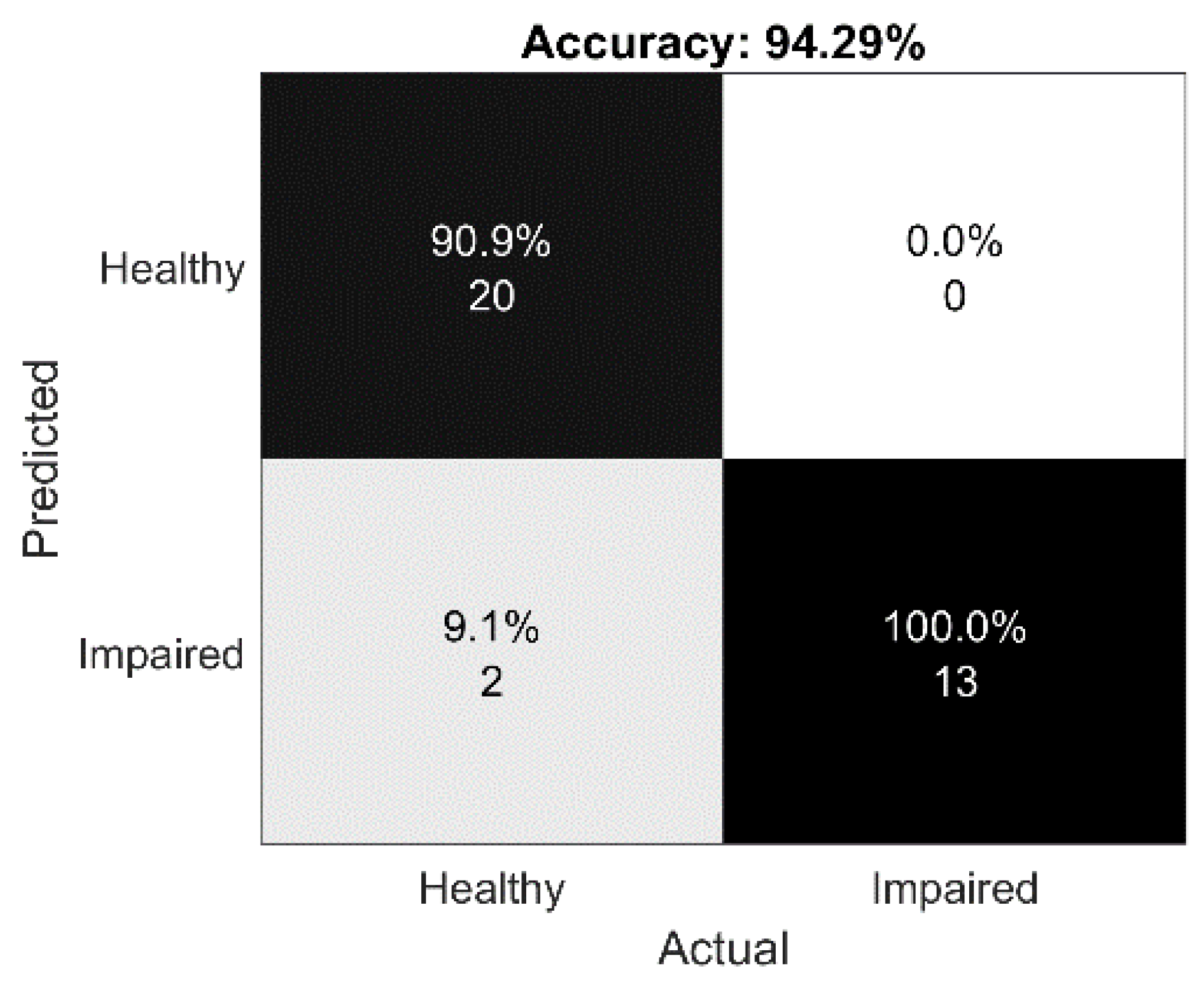
4.4. E2: Impaired vs. Healthy Classification Models for the Integrated Feature Set
4.5. E3: Speech Impairment Detection Using BiLSTM
4.6. E4: Sick vs. Healthy Classification Using the Wavelet Scattering Transform Method (WST)
4.7. Limitations
5. Discussion and Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Ethical Statement
References
- Mack, J.; Marsh, L. Parkinson’s Disease: Cognitive Impairment. Focus 2017, 15, 42–54. [Google Scholar] [CrossRef] [PubMed]
- Ludlow, C.L.; Connor, N.P.; Bassich, C.J. Speech timing in Parkinson’s and Huntington’s disease. Brain Lang. 1987, 32, 195–214. [Google Scholar] [CrossRef]
- Marder, K.; Zhao, H.; Eberly, S.; Tanner, C.M.; Oakes, D.; Shoulson, I.; Huntington Study Group. Dietary intake in adults at risk for Huntington disease: Analysis of PHAROS research participants. Neurology 2009, 73, 385–392. [Google Scholar] [CrossRef] [PubMed]
- Louis, E.D. Essential tremors: A family of neurodegenerative disorders? Arch. Neurol. 2009, 66, 1202–1208. [Google Scholar] [CrossRef]
- Pereira, C.R.; Pereira, D.R.; Weber, S.A.T.; Hook, C.; de Albuquerque, V.H.C.; Papa, J.P. A survey on computer-assisted Parkinson’s Disease diagnosis. Artif. Intell. Med. 2019, 95, 48–63. [Google Scholar] [CrossRef]
- Scharre, D.W.; Chang, S.-I.; Murden, R.A.; Lamb, J.; Beversdorf, D.Q.; Kataki, M.; Nagaraja, H.N.; Bornstein, R.A. Self-administered gerocognitive examination (SAGE). Alzheimer Dis. Assoc. Disord. 2010, 4, 64–71. [Google Scholar] [CrossRef]
- Athilingam, P.; Visovsky, C.; Elliott, A.F.; Rogal, P.J. Cognitive Screening in Persons with Chronic Diseases in Primary Care. Am. J. Alzheimer Dis. Other Dement. 2015, 30, 547–558. [Google Scholar] [CrossRef]
- Aghanavesi, S.; Nyholm, D.; Senek, M.; Bergquist, F.; Memedi, M. A smartphone-based system to quantify dexterity in parkinson’s disease patients. Inform. Med. Unlocked 2017, 9, 11–17. [Google Scholar] [CrossRef]
- Sisti, J.A.; Christophe, B.; Seville, A.R.; Garton, A.L.A.; Gupta, V.P.; Bandin, A.J.; Pullman, S.L. Computerized spiral analysis using the iPad. J. Neurosci. Methods 2017, 275, 50–54. [Google Scholar] [CrossRef]
- Solé-Casals, J.; Anchustegui-Echearte, I.; Marti-Puig, P.; Calvo, P.M.; Bergareche, A.; Sánchez-Méndez, J.I.; Lopez-de-Ipina, K. Discrete cosine transform for the analysis of essential tremor. Front. Physiol. 2019, 9, 1947. [Google Scholar] [CrossRef]
- Aghanavesi, S.; Memedi, M.; Dougherty, M.; Nyholm, D.; Westin, J. Verification of a method for measuring Parkinson’s disease related temporal irregularity in spiral drawings. Sensors 2017, 17, 2341. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Lin, P.; Yang, B.; Chen, Y. The difference in visuomotor feedback velocity control during spiral drawing between Parkinson’s disease and essential tremor. Neurol. Sci. 2018, 39, 1057–1063. [Google Scholar] [CrossRef] [PubMed]
- Lopez-de-Ipina, K.; Solé-Casals, J.; Faúndez-Zanuy, M.; Calvo, P.M.; Sesa, E.; Roure, J.; Bergareche, A. Automatic analysis of archimedes′ spiral for characterization of genetic essential tremor based on shannon’s entropy and fractal dimension. Entropy 2018, 20, 531. [Google Scholar] [CrossRef]
- Sadikov, A.; Groznik, V.; Možina, M.; Žabkar, J.; Nyholm, D.; Memedi, M.; Georgiev, D. Feasibility of spirography features for objective assessment of motor function in parkinson’s disease. Artif. Intell. Med. 2017, 81, 54–62. [Google Scholar] [CrossRef]
- San Luciano, M.; Wang, C.; Ortega, R.A.; Yu, Q.; Boschung, S.; Soto-Valencia, J.; Saunders-Pullman, R. Digitized spiral drawing: A possible biomarker for early parkinson’s disease. PLoS ONE 2016, 11, e0162799. [Google Scholar] [CrossRef]
- Zham, P.; Arjunan, S.P.; Raghav, S.; Kumar, D.K. Efficacy of guided spiral drawing in the classification of parkinson’s disease. IEEE J. Biomed. Health Inform. 2018, 22, 1648–1652. [Google Scholar] [CrossRef]
- Lin, P.; Chen, K.; Yang, B.; Chen, Y. A digital assessment system for evaluating kinetic tremor in essential tremor and parkinson’s disease. BMC Neurol. 2018, 18, 25. [Google Scholar] [CrossRef]
- Engin, M.; Demirag, S.; Engin, Z.E.; Celebi, G.; Ersan, F.; Asena, F.; Colakoglu, Z. The classification of human tremor signals using artificial neural network. Expert Syst. Appl. 2007, 33, 754–761. [Google Scholar] [CrossRef]
- Wu, D.; Warwick, K.; Ma, Z.; Gasson, M.N.; Burgess, J.G.; Pan, S.; Aziz, T.Z. Prediction of Parkinson’s disease tremor onset using a radial basis function neural network based on particle swarm optimization. Int. J. Neur. Syst. 2010, 20, 109. [Google Scholar] [CrossRef]
- Cole, B.T.; Roy, S.H.; De Luca, C.J.; Nawab, S.H. Dynamic neural network detection of tremor and dyskinesia from wearable sensor data. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010. [Google Scholar]
- Chandrashekhar, A.; Jain, S.; Kumar Jha, V. Design and Analysis of Data Mining Based Prediction Model for Parkinson’s disease. Int. J. Comput. Sci. Eng. 2014, 3, 181–189. [Google Scholar]
- Geman, O. Parkinson’s disease Assessment using Fuzzy Expert System and Nonlinear Dynamic. Adv. Electr. Comput. Eng. 2013, 13, 41–46. [Google Scholar] [CrossRef]
- Obi, J.C.; Imainvan, A.A. Decision Support System for the Intelligent Identification of Alzheimer Using Neuro Fuzzy logic. Int. J. Soft Comput. 2011, 2, 25–38. [Google Scholar]
- Iram, S.; Fergus, P.; Al-Jumeily, D.; Hussain, A.; Randles, M. A classifier fusion strategy to improve the early detection of neurodegenerative diseases. Int. J. Artif. Intell. Soft Comput. 2015, 5, 23–44. [Google Scholar] [CrossRef]
- Yang, G.; Lin, Y.; Bhattacharya, P. Multimodality inferring of human cognitive states based on integration of neuro-fuzzy network and information fusion techniques. EURASIP J. Adv. Signal Process. 2008, 2008, 371621. [Google Scholar] [CrossRef]
- Vaiciukynas, E.; Verikas, A.; Gelzinis, A.; Bacauskiene, M. Detecting Parkinson’s disease from sustained phonation and speech signals. PLoS ONE 2017, 12, e0185613. [Google Scholar] [CrossRef] [PubMed]
- Khan, T.; Westin, J.; Dougherty, M. Cepstral separation difference: A novel approach for speech impairment quantification in Parkinson’s disease. Biocybern. Biomed. Eng. 2014, 34, 25–34. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; Fox, C.; Ramig, L.O. Objective Automatic Assessment of Rehabilitative Speech Treatment in Parkinson’s Disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 181–190. [Google Scholar] [CrossRef]
- An, G.; Brizan, D.G.; Ma, M.; Morales, M.; Syed, A.R.; Rosenberg, A. Automatic Recognition of Unified Parkinson’s Disease Rating from Speech with Acoustic, i-Vector and Phonotactic Features. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Caesarendra, W.; Putri, F.T.; Ariyanto, M.; Setiawan, J.D. Pattern Recognition Methods for Multi Stage Classification of Parkinson’s Disease Utilizing Voice Features. In Proceedings of the 2015 IEEE International Conference on Advanced Intelligent Mechatronics (AIM), Busan, Korea, 7–11 July 2015; pp. 802–807. [Google Scholar]
- Goodman, A.O.; Murgatroyd, P.R.; Medina-Gomez, G.; Wood, N.I.; Finer, N.; Vidal-Puig, A.J.; Morton, A.J.; Barker, R.A. The metabolic profile of early Huntington’s disease—A combined human and transgenic mouse study. Exp. Neurol. 2008, 210, 691–698. [Google Scholar] [CrossRef]
- Gaba, A.M.; Zhang, K.; Marder, K.; Moskowitz, C.B.; Werner, P.; Boozer, C.N. Energy balance in early-stage Huntington disease. Am. J. Clin. Nutr. 2005, 81, 1335–1341. [Google Scholar] [CrossRef]
- Bernardo, L.S.; Quezada, A.; Munoz, R.; Maia, F.M.; Pereira, C.R.; Wu, W.; de Albuquerque, V.H.C. Handwritten pattern recognition for early Parkinson’s disease diagnosis. Pattern Recognit. Lett. 2019, 125, 78–84. [Google Scholar] [CrossRef]
- Eiter, T.; Mannila, H. Computing Discrete Frechet Distance; Technische Universitat Wien: Vienna, Austria, 1994. [Google Scholar]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods; American Statistical Association: New Orleans, LA, USA, 1990; pp. 354–359. [Google Scholar]
- Atal, B.S. Automatic Speaker Recognition Based on Pitch Contours. J. Acoust. Soc. Am. 1972, 52, 1687–1697. [Google Scholar] [CrossRef]
- Gonzalez, S.; Brookes, M. A Pitch Estimation Filter robust to high levels of noise (PEFAC). In Proceedings of the 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; pp. 451–455. [Google Scholar]
- Noll, M.A. Cepstrum Pitch Determination. J. Acoust. Soc. Am. 1967, 31, 293–309. [Google Scholar] [CrossRef] [PubMed]
- Hermes, D.J. Measurement of Pitch by Subharmonic Summation. J. Acoust. Soc. Am. 1988, 83, 257–264. [Google Scholar] [CrossRef] [PubMed]
- Drugman, T.; Abeer, A. Joint Robust Voicing Detection and Pitch Estimation Based on Residual Harmonics. arXiv 2019, arXiv:2001.00459. [Google Scholar]
- Rabiner, L.R.; Schafer, R.W. Theory and Applications of Digital Speech Processing; Pearson: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Valero, X.; Alias, F. Gammatone Cepstral Coefficients: Biologically Inspired Features for Non-Speech Audio Classification. IEEE Trans. Multimed. 2012, 14, 1684–1689. [Google Scholar] [CrossRef]
- Andén, J.; Mallat, S. Deep Scattering Spectrum. IEEE Trans. Signal Process. 2014, 62, 4114–4128. [Google Scholar] [CrossRef]
- Lerch, A. An Introduction to Audio Content Analysis Applications in Signal Processing and Music Informatics; IEEE Press: Piscataway, NJ, USA, 2012. [Google Scholar]
- Peeters, G. A Large Set of Audio Features for Sound Description (Similarity and Classification) in the CUIDADO Project; Technical Report; IRCAM: Paris, France, 2004. [Google Scholar]
- Scheirer, E.; Slaney, M. Construction and Evaluation of a Robust Multifeature Speech/Music Discriminator. IEEE Int. Conf. Acoust. Speech Signal Process. 1997, 2, 1221–1224. [Google Scholar]
- Johnston, J.D. Transform Coding of Audio Signals Using Perceptual Noise Criteria. IEEE J. Sel. Areas Commun. 1988, 6, 314–323. [Google Scholar] [CrossRef]
- Misra, H.; Ikbal, S.; Bourlard, H.; Hermansky, H. Spectral Entropy Based Feature for Robust ASR. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Cananda, 17–21 May 2004. [Google Scholar]
- Amirkalali, B.; Hosseini, S.; Heshmat, R.; Larijani, B. Comparison of Harris Benedict and Mifflin-ST Jeor equations with indirect calorimetry in evaluating resting energy expenditure. Indian J. Med. Sci. 2008, 62, 283–290. [Google Scholar]
- National Cancer Institute. Metabolic Equivalent of Task Values for Activities in American Time Use Survey and 2002 Census Occupational Classification System. Available online: https://epi.grants.cancer.gov/atus-met/met.php (accessed on 5 June 2020).
- Platt, J. Fast Training of Support Vector Machines using Sequential Minimal Optimization. In Advances in Kernel Methods—Support Vector Learning; Schoelkopf, B., Burges, C., Smola, A., Eds.; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Mika, S.; Rätsch, G.; Weston, J.; Schölkopf, B.; Müller, K.R. Fisher discriminant analysis with kernels. Neural Netw. Signal Process. 1999, IX, 41–48. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ben Gal, I. Bayesian Networks. In Encyclopedia of Statistics in Quality and Reliability; Ruggeri, F., Kennett, R.S., Faltin, F.W., Eds.; John Wiley Sons: Hoboken, NJ, USA, 2007. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QU, Canada, 18–20 August 1995; pp. 338–345. [Google Scholar]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1993. [Google Scholar]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700. [Google Scholar]
- Landwehr, N.; Hall, M.; Frank, E. Logistic Model Trees. Mach. Learn. 2005, 95, 161–205. [Google Scholar] [CrossRef]
- Iba, W.; Langley, P. Induction of One-Level Decision Trees. In Proceedings of the ML92: Ninth International Conference on Machine Learning, Aberdeen, UK, 1–3 July 1992; pp. 233–240. [Google Scholar]
- Freund, Y.; Schapire, R.E. Large margin classification using the perceptron algorithm. In Proceedings of the 11th Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 209–217. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on Machine Learning, San Francisco, CA, USA, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Dietterich, T.G. Ensemble methods in machine learning. In Multiple Classifier Systems; Kittler, J., Roli, F., Eds.; Lecture Notes in Computer Science; Springer: Cagliari, Italy, 2000; Volume 1857, pp. 1–15. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer Topics in Signal Processing; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 2nd ed.; Morgan Kaufman: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 2004. [Google Scholar]
- Shoulson, I.; Fahn, S. Huntington disease: Clinical care and evaluation. Neurology 1979, 29, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Al-Tashi, Q.; Abdul Kadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary Optimization Using Hybrid Grey Wolf Optimization for Feature Selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Lauraitis, A.; Maskeliunas, R.; Damasevicius, R.; Krilavicius, T. Detection of Speech Impairments Using Cepstrum, Auditory Spectrogram and Wavelet Time Scattering Domain Features. IEEE Access 2020, 8, 96162–96172. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Lee, T.S. Image Representation Using 2D Gabor wavelets. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 959–971. [Google Scholar] [CrossRef]
- Rusz, J.; Novotný, M.; Hlavnička, J.; Tykalová, T.; Růžička, E. High-accuracy voice-based classification between patients with Parkinson’s disease and other neurological diseases may be an easy task with inappropriate experimental design. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 1319–1321. [Google Scholar] [CrossRef]
- Smale, S.; Zhou, D.-X. Learning Theory Estimates via Integral Operators and Their Approximations. Constr. Approx. 2007, 26, 153–172. [Google Scholar] [CrossRef]
- Dahmen, J.; Cook, D.; Fellows, R.; Schmitter-Edgecombe, M. An analysis of a digital variant of the Trail Making Test using machine learning techniques. Technol. Health Care Off. J. Eur. Soc. Eng. Med. 2017, 25, 251–264. [Google Scholar] [CrossRef] [PubMed]
- Impedovo, D.; Pirlo, G.; Vessio, G.; Angelilo, M.T. A Handwriting-Based Protocol for Assessing Neurodegenerative Dementia. Cogn. Comput. 2019, 11, 576–586. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Task Name | Impairment to be Addressed |
|---|---|---|
| T1 | Sequential Touch | Tremor, Cognitive |
| T2 | Rainbow Color Touch | Tremor, Cognitive |
| T3 | Multi-Touch | Tremor, Cognitive |
| T4 | Archimedean Spiral | Tremor, Cognitive |
| T5 | Insights | Cognitive |
| T6 | Orientation (current date) | Cognitive |
| T7 | Picture Naming | Cognitive |
| T8 | Similarities, Calculation | Cognitive |
| T9 | Construction (3D figure) | Cognitive, Tremor |
| T10 | Construction (clock) | Cognitive, Tremor |
| T11 | Verbal Fluency | Cognitive |
| T12 | Executive: Modified Trials | Cognitive, Tremor |
| T13 | Executive: Problem Solving | Cognitive, Tremor |
| T14 | Voice Recorder | Speech |
| T15 | Total Daily Energy Expenditure (TDEE) | Energy Expenditure |
| T0 | Memory | Cognitive |
| Task: Features | Attribute Selection | Accuracy (10-Fold Cross-Validation) | Speed (s) |
|---|---|---|---|
| T1: 9 | PCA (VC = 0.85) | J48:84.90%, SVM (RBF): 84.90% | Instant |
| T2: 10 | WSE (VC = 0.60) | J48 (NBM): 81.13% | 0.07 |
| T3: 28 | WSE | RF (KNN): 77.35% | 1.72 |
| T4 (spiral following): 22 | WSE | LR (LDA): 84.90%, | 1.49 |
| ANN (RF): 82.07% | 36.06 | ||
| T4 (spiral drawing): 22 | WSE | ANN (KNN): 87.73% | 2.16 |
| RF (FLDA): 86.79% | 1.24 | ||
| T9: 30 | PCA (VC = 0.75) CAE | LMT: 91.50% | 0.04, |
| ANN: 90.56% | 0.07 | ||
| RF: 90.56% | 0.02 | ||
| T10: 24 | CAE WSE | KNN: 90.56% | Instant |
| ANN (KNN): 89.62% | 2.36 | ||
| T11: 2 | CAE | RF: 74.52% | 0.02 |
| T12: 33 | CAE WSE | RF: 83.09% | 0.03 |
| ANN (KNN): 82.07% | 5.84 | ||
| T13: 25 | WSE | J48 (FLDA): 83.96% | 0.50 |
| T15: 4 | CAE | SVM (RBF): 78.3% | Instant |
| Spelling (T7, T8, T11): 3 | WSE | LMT (RF): 74.52% | 2.76 |
| SAGE (T6, T7, T8, T9, T10, T11, T12, T13, T0): 10 | PCA (VC = 0.50) CAE | LMT: 84.90% | 0.01 |
| SMO: 84.90% | 0.03 | ||
| Duration (all tests): 16 | WSE | FLDA (FLDA): 89.62% | 0.66 |
| Classifier | Accuracy (%) | TPR (Sensi-Tivity) | TNR (Speci-Ficity) | Precision | F1 | MCC | ROC | PRC | Speed (s) |
|---|---|---|---|---|---|---|---|---|---|
| AdaBoostM1 (decision stump) | 93.02 | 0.930 | 0.919 | 0.930 | 0.930 | 0.850 | 0.986 | 0.987 | 0.11 |
| AdaBoostM1 (random forest) | 94.57 | 0.946 | 0.922 | 0.948 | 0.945 | 0.887 | 0.990 | 0.990 | 0.13 |
| AdaBoostM1 (MLP) | 92.48 | 0.922 | 0.914 | 0.922 | 0.922 | 0.837 | 0.971 | 0.971 | 19.46 |
| AdaBoostM1 (SMO) | 92.24 | 0.922 | 0.922 | 0.923 | 0.923 | 0.838 | 0.967 | 0.967 | 0.36 |
| AdaBoostM1 (kNN) | 94.57 | 0.946 | 0.929 | 0.946 | 0.945 | 0.886 | 0.933 | 0.918 | 0.03 |
| AdaBoostM1 (LWL) | 91.47 | 0.915 | 0.909 | 0.915 | 0.915 | 0.821 | 0.972 | 0.973 | 13.62 |
| AdaBoostM1 (Bayes net) | 93.79 | 0.938 | 0.917 | 0.939 | 0.937 | 0.869 | 0.958 | 0.962 | 0.31 |
| SVM (sigmoid) + PCA | 91.47 | 0.915 | 0.909 | 0.915 | 0.915 | 0.821 | 0.912 | 0.881 | 0.24 |
| SVM (linear) + PCA | 92.24 | 0.922 | 0.914 | 0.922 | 0.922 | 0.837 | 0.918 | 0.890 | 0.23 |
| FLDA | 92.24 | 0.922 | 0.900 | 0.923 | 0.922 | 0.836 | 0.976 | 0.978 | 2.94 |
| DNN (LSTM) | 94.57 | 0.946 | 0.944 | 0.946 | 0.946 | 0.886 | 0.987 | 0.987 | 2.80 |
| Voted perceptron + PCA | 93.02 | 0.930 | 0.919 | 0.930 | 0.930 | 0.853 | 0.937 | 0.92 | 0.30 |
| Hybrid (proposed by authors) | 96.12 | 0.961 | 0.953 | 0.961 | 0.961 | 0.918 | 0.983 | 0.984 | 0.59 |
| Classifier | PrC_0 | PrC_1 | EC_0 | EC_1 |
|---|---|---|---|---|
| AdaBoostM1 (decision stump) | 1 | 0.934 | 1 | 1 |
| AdaBoostM1 (random forest) | 0.902 | 0.736 | 1 | 0 |
| AdaBoostM1 (LMT) | 1 | 1 | 1 | 0 |
| AdaBoostM1 (ANN-MLP) | 0.999 | 0.997 | 1 | 0 |
| AdaBoostM1 (SMO) | 1 | 0.996 | 1 | 0 |
| AdaBoostM1 (kNN) | 0.992 | 0.992 | 1 | 0 |
| AdaBoostM1 (LWL) | 1 | 0.972 | 1 | 1 |
| AdaBoostM1 (Bayes net) | 1 | 0.995 | 1 | 1 |
| SVM (sigmoid) + PCA | 1 | 1 | 1 | 2 |
| SVM (linear) + PCA | 1 | 1 | 1 | 0 |
| FLDA | 0.523 | 0.523 | 1 | 0 |
| DNN (LSTM) | 0.998 | 0.996 | 1 | 0 |
| Voted perceptron + PCA | 1 | 1 | 2 | 0 |
| Hybrid (proposed) | 0.991 | 0.931 | 1 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lauraitis, A.; Maskeliūnas, R.; Damaševičius, R.; Krilavičius, T. A Mobile Application for Smart Computer-Aided Self-Administered Testing of Cognition, Speech, and Motor Impairment. Sensors 2020, 20, 3236. https://doi.org/10.3390/s20113236
Lauraitis A, Maskeliūnas R, Damaševičius R, Krilavičius T. A Mobile Application for Smart Computer-Aided Self-Administered Testing of Cognition, Speech, and Motor Impairment. Sensors. 2020; 20(11):3236. https://doi.org/10.3390/s20113236
Chicago/Turabian StyleLauraitis, Andrius, Rytis Maskeliūnas, Robertas Damaševičius, and Tomas Krilavičius. 2020. "A Mobile Application for Smart Computer-Aided Self-Administered Testing of Cognition, Speech, and Motor Impairment" Sensors 20, no. 11: 3236. https://doi.org/10.3390/s20113236
APA StyleLauraitis, A., Maskeliūnas, R., Damaševičius, R., & Krilavičius, T. (2020). A Mobile Application for Smart Computer-Aided Self-Administered Testing of Cognition, Speech, and Motor Impairment. Sensors, 20(11), 3236. https://doi.org/10.3390/s20113236