
Study of Visualization Modalities on Industrial Robot Teleoperation for Inspection in a Virtual Co-Existence Space


Abstract
1. Introduction
2. State of the Art
2.1. Limitations of Conventional Teleoperation Visualization
2.2. Immersive Visualization and Virtual Co-Existence Spaces
2.3. User Interface Paradigms for Immersive Teleoperation
2.4. Environment Representation and Data Handling in VR
2.5. Research Gap
3. Materials and Methods
3.1. Proposed VR-Based Teleoperation System
3.1.1. System Architecture
- Physical System: This represents the robot’s actual operational environment.
- ○
- Environmental Components: Includes the physical Work Area, any Task Objects the robot interacts with (e.g., inspection targets), and Environmental Constraints (e.g., obstacles, safety zones).Robot: The physical industrial robot (a FANUC M-20iA in this study) comprises sensing elements: cameras (two Azure Kinects on the end-effector) providing visual data for 2D feeds and 3D point cloud generation, and other robot sensors (e.g., force, proximity) capturing interaction data. This raw data is the physical system’s output to the cyber realm.
- Operator Space: This is where the human operator performs the teleoperation task.
- ○
- Human Operator: Provides high-level commands and utilizes Domain-Specific Knowledge for the inspection task.
- ○
- Human-Machine Interface (HMI): The means through which the operator interacts. This includes Haptic Controllers (HTC VIVE) for command input and tactile feedback, and a Virtual Reality Headset (VARJO XR-3) for immersive visualization. It has a resolution of 2880 x 2720 pixels per eye, a 90 Hz refresh rate, and a 115-degree field of view. The interface logic and display are managed by a Unity 3D application running on the following system: an AMD Ryzen PRO 3975WX 32-Cores, an Nvidia Quadro RTX 8000, and 64 GB DDR4 RAM.
- Cyber System: The core digital infrastructure connects, processes, and synchronizes information between the physical and operator spaces.
- ○
- Gateways: The Gateway Physical System (a C# application using FANUC PC Developer’s Kit (PCDK) and Azure Kinect SDK APIs) is the bridge, collecting data from the physical robot/sensors and translating commands to the robot controller. The Gateway Operator Space similarly connects the HMI hardware/software to the cyber system, sending operator inputs and receiving data for visualization.
- ○
- DDS Databus: Central to the Cyber System is the DDS Databus (using RTI Connext DDS). It functions as a real-time ‘data highway’ employing a publish-subscribe mechanism. System components (Gateways, Data Management, etc.) publish data on specific topics (e.g., Robot_State, Operator_Teleop_Target) and subscribe to the topics they need, ensuring efficient communication (see Section 3.1.2 for data structures).
- ○
- Core Modules: Several specialized modules operate on the data flowing through the DDS bus to perform key functions. The Data Management module stores and retrieves critical information like real-time robot poses and joint angles. Data Analytics processes incoming data, for example, performing Collision Detection based on robot pose and environmental sensor readings. The Digital Twin Viewer, implemented in Unity 3D, subscribes to relevant data streams (robot state, point clouds) to render the dynamic virtual representation of the robot and its environment for the operator, including Status Visualization and a Shadow Model Display for planned movements. Operator commands received via DDS are processed by the Control and Interaction module, which calculates necessary joint movements (Inverse Kinematics), generates robot control commands, manages the Virtual Camera perspective, and provides Manual Override capabilities. Additionally, an Expert Support System can analyze the operational context to provide Contextual Assistance through the HMI, and a Data Logging module records operational data for subsequent analysis and playback.
- Interaction Flows (Arrows): The arrows in Figure 1 indicate the direction and type of interaction.
- ○
- Information Flow (Blue Arrows): Represents the flow of sensor data, system states, and processed information between components, primarily published/subscribed via the DDS Databus (e.g., sensor data flowing from Gateway Physical System to DDS, then consumed by Digital Twin Viewer).
- ○
- Feedback Flow (Green Arrows): Indicates responsive data, such as command acknowledgments, status updates resulting from actions, collision warnings from Data Analytics, or guidance from the Expert System flowing back towards the operator or control modules.
- ○
- Primary Control (Black Arrows): Shows the direct command path originating from the operator’s input, processed by the Control and Interaction module, and ultimately actuating the physical robot.

3.1.2. Data Synchronization with DDS
3.2. Visualization Modalities and Experimental Task
- 2D Camera Feed (2D): Alongside the robot’s digital twin, this modality presented participants solely with the conventional live 2D video stream captured from the camera mounted on the real robot’s end-effector, displayed on a virtual screen within the VR environment.
- 3D Point Cloud (3D): In this modality, the environment surrounding the robot’s digital twin was visualized using only a live 3D point cloud reconstruction streamed into the VR headset. The 2D camera feed was omitted.
- Combined Feed (2D3D): This modality provided participants with the 2D live camera feed (displayed as in modality 1) and the 3D live point cloud environmental representation simultaneously, in addition to the robot’s digital twin.
- Augmented Virtuality (AV): This modality integrated the 2D live camera feed and enhanced the virtual scene with registered information overlays linked to OpenCV markers placed within the physical workspace.

- Task 1 (t1): The inspection area was located directly in front of the robot’s starting position and was visible without requiring significant robot or camera reorientation (Figure 4, green arrow).
- Task 2 (t2): The inspection area was visible from the start position but required substantial rotation of the robot-mounted camera (towards the ground relative to the participant’s initial view) for successful inspection (Figure 4, blue arrow).
- Task 3 (t3): The inspection area was positioned such that it was not visible from the robot’s starting orientation (located on the left side). This required participants to actively navigate or reorient the robot arm and camera to locate and inspect the target (Figure 4, red arrow).
3.3. User Evaluation
3.3.1. Participants
3.3.2. Data Collection
3.3.3. Procedure
- Arrival and Consent (Approx. 2 min): Upon arrival, participants were welcomed and received a detailed information sheet outlining the study’s purpose, procedures, duration, and potential risks. Participants provided written informed consent before proceeding. All procedures adhered to the Cranfield University Research Ethics System guidelines (reference CURES/17958/2023 and project ID 20805).
- Pre-Test Questionnaires (Approx. 2 min): Participants completed a questionnaire gathering demographic information (age, gender) and self-reported experience levels with robotics and VR to characterize the sample.
- Introduction and Familiarization (Approx. 4 min): Participants received a standardized presentation explaining the VR teleoperation interface, the robot control mechanisms, the objectives of the inspection tasks (t1, t2, t3), and the overall experiment flow. They were then assisted in fitting the VR headset with an integrated eye-tracker.
- Eye-Tracker Calibration (Approx. 2 min): A manual eye calibration procedure was conducted for each participant. This step, requiring experimenter oversight, ensured the eye-tracking system was accurately calibrated for the individual, guaranteeing reliable pupillometry data.
- Baseline Pupillometry (Approx. 3 min): A baseline measure of the participant’s pupil diameter was recorded while they remained in a quiet, resting state within the VR environment for one minute. This provided a reference point for task-induced cognitive load measurements.
- Robot Manipulation Practice (Approx. 5 min): Participants engaged in a practice session within a neutral VR environment (distinct from the experimental task layouts) to become comfortable with controlling the robot’s digital twin using the provided VR controllers.
- Experimental Conditions (Within-Subjects, Counterbalanced) (Approx. 24 min total):
- Design: The core of the experiment used a within-subjects design, where each participant experienced all four experimental conditions (each pairing a specific visualization modality with its unique physical layout).
- Counterbalancing: To mitigate potential learning or fatigue-related order effects, the presentation sequence of the four conditions was counterbalanced across participants using four predefined Latin square sequences:
- ○
- Sequence 1: 2D → 3D → AV → 2D3D
- ○
- Sequence 2: 3D → AV → 2D3D → 2D
- ○
- Sequence 3: AV → 2D3D → 2D → 3D
- ○
- Sequence 4: 2D3D → 2D → 3D → AV
The control system automatically assigned participants to one of these sequences. - Per-Condition Loop (Repeated 4 times): For each condition within their assigned sequence, participants underwent the following automated steps:
- ○
- Task Performance (Approx. 3 min): The system presented the appropriate visualization modality, and the researcher set up the corresponding physical task environment. The participant then performed the three inspection tasks (t1, t2, t3) in a predetermined order. Pupillometry data and relevant task performance metrics were automatically recorded throughout this phase.
- ○
- Workload Assessment (Approx. 3 min): Immediately after completing the tasks for the condition, the participant responded to a subjective cognitive workload questionnaire (NASA-TLX) presented within the VR interface. Responses were logged automatically. During this phase, the physical task environment was set up for the next modality.
- Debriefing (Approx. 3 min): After completing all four conditions, participants were debriefed. They had the opportunity to ask questions and provide open-ended feedback regarding their experience with the different modalities and the overall experiment.
4. Results
4.1. Cognitive Workload
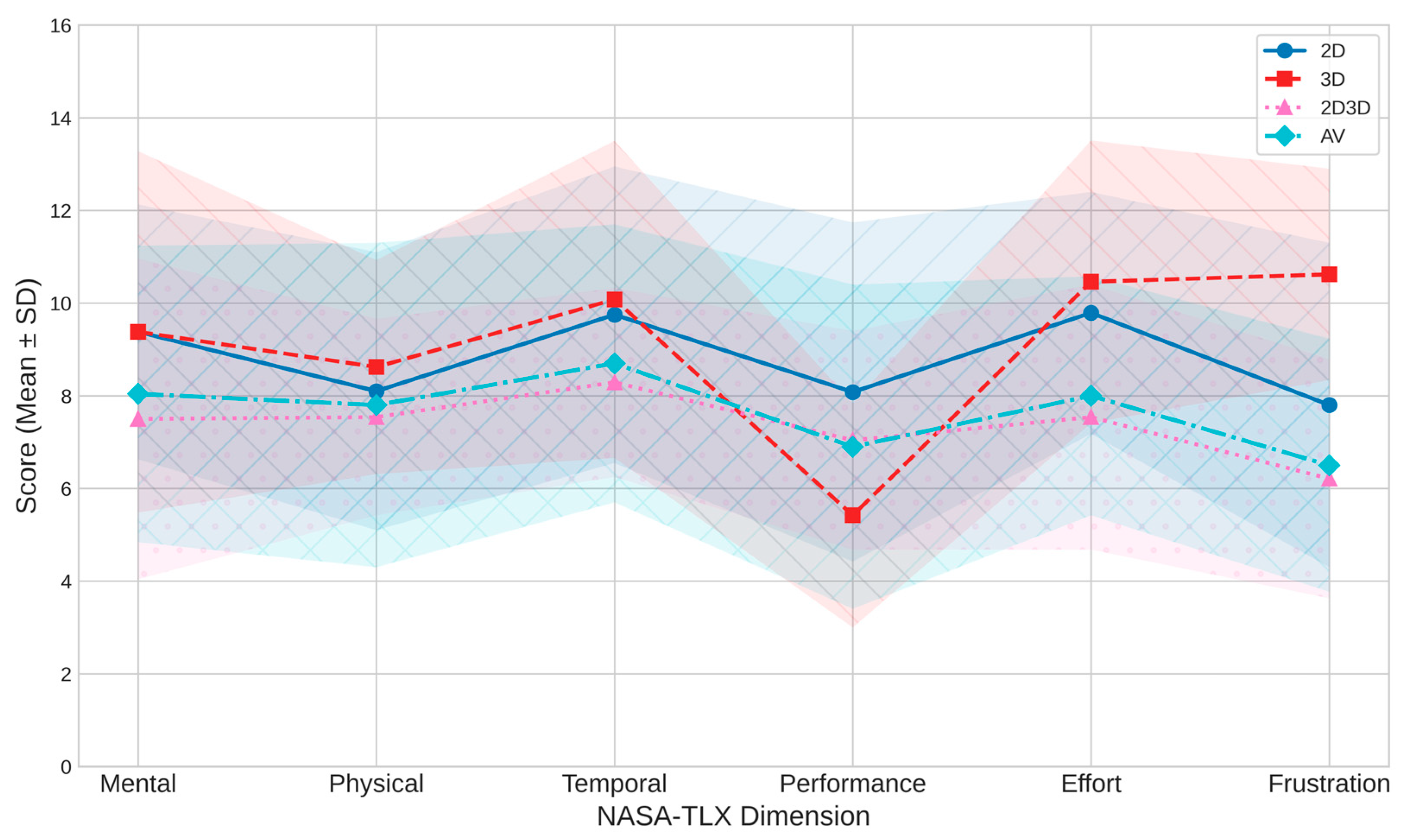
- 2D Modality: This modality was tied for the highest perceived Mental Demand (M = 9.38, SD = 2.75). Participants also reported the highest perceived Performance (M = 8.08, SD = 3.66), indicating they felt most successful completing the task using 2D. Its scores for Effort (M = 9.79, SD = 2.61) and Temporal Demand (M = 9.75, SD = 3.20) were also notably high.
- 3D Modality: This modality generally imposed the highest cognitive load. It yielded the highest mean scores for Physical Demand (M = 8.62, SD = 2.31), Temporal Demand (M = 10.08, SD = 3.42), Effort (M = 10.46, SD = 3.05), and Frustration (M = 10.62, SD = 2.28). It was also tied for the highest Mental Demand (M = 9.38, SD = 3.90). Crucially, participants reported the lowest perceived Performance (M = 5.42, SD = 2.42) in this modality.
- 2D3D Modality: This modality was generally associated with the lowest perceived workload based on mean scores. It showed the lowest means for Mental Demand (M = 7.50, SD = 3.46), Physical Demand (M = 7.54, SD = 2.12), Temporal Demand (M = 8.29, SD = 2.04), Effort (M = 7.54, SD = 2.86), and Frustration (M = 6.21, SD = 2.58). Perceived Performance (M = 7.04, SD = 2.36) was second highest.
- AV Modality: This modality typically presented mean scores falling between the extremes of the other modalities across most dimensions (e.g., Mental M = 8.04, SD = 3.20; Effort M = 8.00, SD = 2.58; Frustration M = 6.50, SD = 2.73).
4.2. Performance
4.3. Qualitative Results
5. Discussion
5.1. Impact of Visualization Modalities on Cognitive Workload
- The 3D modality emerged as the most cognitively demanding. It elicited the highest scores across multiple NASA-TLX dimensions (Physical Demand, Temporal Demand, Effort, Frustration, tied Mental Demand) and induced the most significant increase in pupil dilation. This aligns with qualitative feedback, where participants described it as imposing a high workload, frustrating, and visually demanding. While offering rich spatial information, processing and interacting with the 3D point cloud likely required substantial cognitive resources.
- Conversely, the 2D3D modality was associated with the lowest cognitive load. It garnered the lowest scores on most NASA-TLX dimensions, resulting in low pupil dilation comparable to the 2D view. This quantitative finding was strongly supported by qualitative feedback, with most participants describing it as the easiest, most comfortable, and least effortful interface. This suggests providing both an overview (2D) and detailed immersive (3D) views simultaneously, allowing users to switch focus as needed, effectively mitigating the high load associated with the 3D view alone.
- The AV modality presented an intermediate cognitive load profile subjectively via NASA-TLX and objectively via pupil dilation. While qualitatively perceived as engaging and novel, the cognitive benefits of the augmented information seemed offset by potential confusion or interaction challenges, preventing it from being as low-load as 2D3D.
- The 2D modality presented an intriguing divergence between subjective and objective measures. Participants rated it highly demanding regarding mental demand and effort, which aligned with qualitative comments about requiring high concentration. However, its associated pupil dilation was low, like the easy 2D3D condition. This might suggest that while the task felt effortful and perhaps tedious in 2D, the familiar representation and clear view (as noted in qualitative feedback) did not overload cognitive processing resources to the same extent as the more complex 3D or AV interfaces. Alternatively, pupil dilation might be less sensitive to the specific type of sustained mental effort required by the 2D condition compared to the spatial processing demands of 3D/AV.
5.2. Impact of Visualization Modalities on Performance
- Task Completion Time: Although descriptive statistics suggested that 2D was slowest and AV/3D was the fastest, the overall ANOVA found no significant difference between modalities. This statistical outcome aligns somewhat with qualitative feedback, where 2D felt slow. However, it also indicates that any speed advantages of 3D/AV might have been counteracted by their increased complexity or cognitive load, leading to comparable overall times when variability is considered.
- Collision Count: This metric showed a clear and statistically significant difference. The AV modality with the highest collision rate stood out, strongly supported by qualitative feedback highlighting navigation difficulties and confusing overlays. This suggests a critical usability issue with the AV implementation in this study for tasks requiring precise maneuvering. Conversely, the 3D modality resulted in very few collisions, echoed in qualitative feedback by comments on possible precise navigation, suggesting reasonable spatial control despite the high cognitive load. The 2D and 2D3D modalities also had very low collision rates, indicating safe navigation.
- Accuracy & Quality: No statistically significant differences were found for Distance Accuracy or Photo Quality. However, descriptive trends and qualitative comments suggested advantages for specific modalities (e.g., 2D for distance accuracy, 2D3D for photo quality). The consistently high performance on Shape/Color accuracy across all modalities suggests this aspect of the task was relatively straightforward, regardless of the view. As reflected in qualitative comments, the lack of significant difference in Photo Quality might indicate that participants could generally achieve acceptable photos across modalities, even if some felt easier (2D3D) than others (3D/AV).
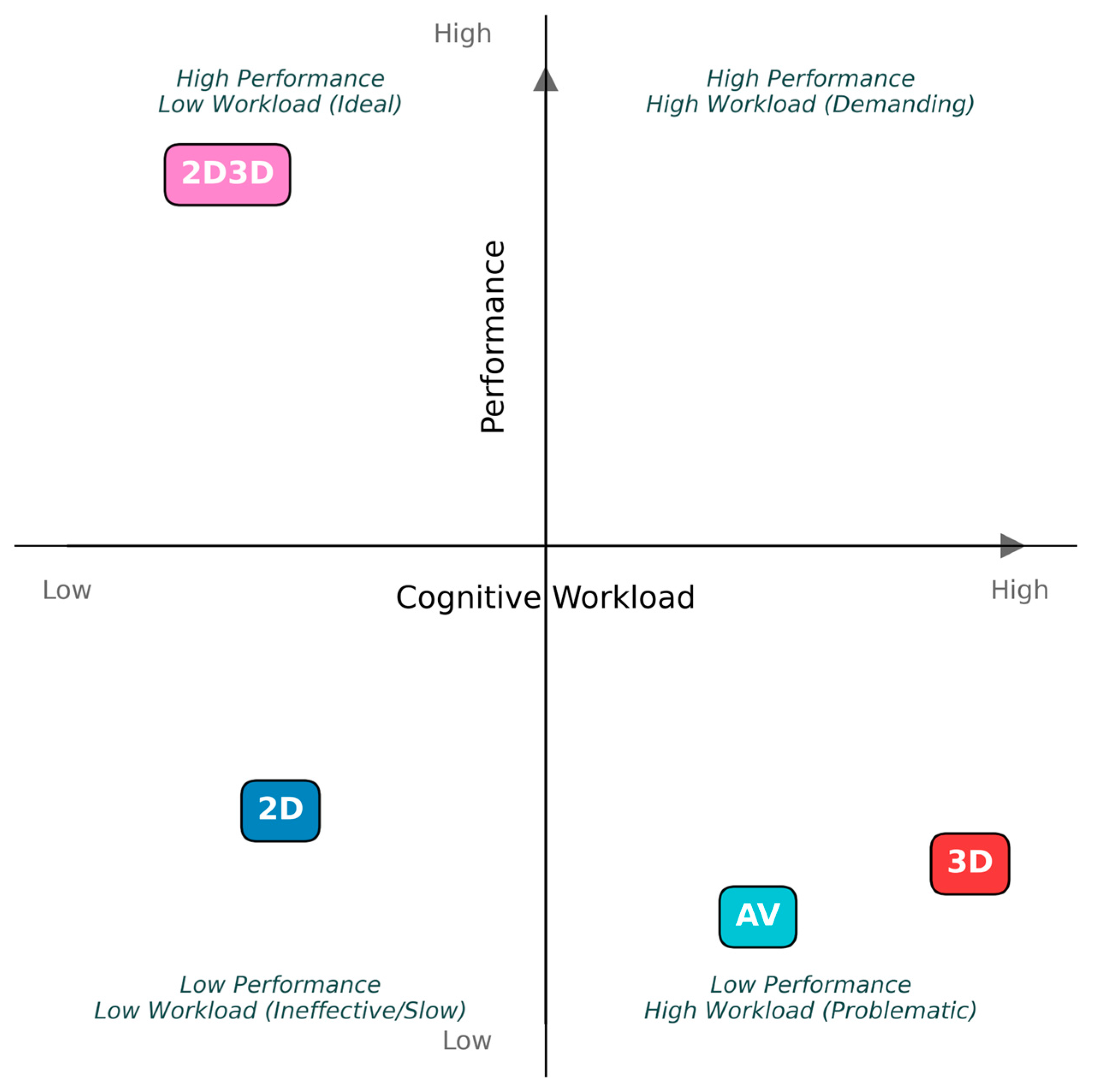
5.3. Answering the Research Question
- 2D: Reliable and accurate (distance judgement, perceived performance), but subjectively demanding (effort, mental load) and descriptively slowest. Low physiological load. Familiar but potentially inefficient/tedious.
- 3D: Allows precise navigation (low collisions) but imposes a very high cognitive load (subjective & objective), is perceived as frustrating and challenging, and leads to poor perceived performance.
- 2D3D: It offers the lowest cognitive load and highest user comfort/ease-of-use, with good photo quality. However, it suffers in precise distance estimation. Overall, it appears to be the most user-friendly, but it has a specific performance limitation.
- AV: Engaging and novel, with intermediate cognitive load and fast descriptive task completion. However, this modality was marred by significant navigation issues (the highest collision rate) and potential information confusion, indicating usability challenges in its current form.
- *
- If minimizing cognitive load and maximizing user comfort is key, 2D3D appears favorable, provided precise distance judgement is not critical.
- *
- If collision avoidance during navigation is paramount, 3D (or 2D/2D3D) might be safer than AV, despite 3D’s high workload.
- *
- If precise distance estimation is crucial, 2D remains a strong contender, requiring more effort.
- *
- While potentially engaging, the AV modality requires significant refinement to address its navigation and information presentation issues before it can be recommended based on this study’s findings.
5.4. Practical Implications and Beneficiaries
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- González, C.; Solanes, J.E.; Muñoz, A.; Gracia, L.; Girbés-Juan, V.; Tornero, J. Advanced Teleoperation and Control System for Industrial Robots Based on Augmented Virtuality and Haptic Feedback. J. Manuf. Syst. 2021, 59, 283–298. [Google Scholar] [CrossRef]
- Livatino, S.; Guastella, D.C.; Muscato, G.; Rinaldi, V.; Cantelli, L.; Melita, C.D.; Caniglia, A.; Mazza, R.; Padula, G. Intuitive Robot Teleoperation Through Multi-Sensor Informed Mixed Reality Visual Aids. IEEE Access 2021, 9, 25795–25808. [Google Scholar] [CrossRef]
- Moniruzzaman, M.; Rassau, A.; Chai, D.; Islam, S.M.S. Teleoperation Methods and Enhancement Techniques for Mobile Robots: A Comprehensive Survey. Rob. Auton. Syst. 2022, 150, 103973. [Google Scholar] [CrossRef]
- Rea, D.J.; Seo, S.H. Still Not Solved: A Call for Renewed Focus on User-Centered Teleoperation Interfaces. Front. Robot. AI 2022, 9, 704225. [Google Scholar] [CrossRef]
- Lathan, C.E.; Tracey, M. The Effects of Operator Spatial Perception and Sensory Feedback on Human-Robot Teleoperation Performance. Presence Teleoperators Virtual Environ. 2002, 11, 368–377. [Google Scholar] [CrossRef]
- Slezaka, R.J.; Keren, N.; Gilbert, S.B.; Harvey, M.E.; Ryan, S.J.; Wiley, A.J. Examining Virtual Reality as a Platform for Developing Mental Models of Industrial Systems. J. Comput. Assist. Learn. 2023, 39, 113–124. [Google Scholar] [CrossRef]
- Alexandropoulou, V.; Johansson, T.; Kontaxaki, K.; Pastra, A.; Dalaklis, D. Maritime Remote Inspection Technology in Hull Survey & Inspection: A Synopsis of Liability Issues from a European Union Context. J. Int. Marit. Saf. Environ. Aff. Shipp. 2021, 5, 184–195. [Google Scholar] [CrossRef]
- Einizinab, S.; Khoshelham, K.; Winter, S.; Christopher, P.; Fang, Y.; Windholz, E.; Radanovic, M.; Hu, S. Enabling Technologies for Remote and Virtual Inspection of Building Work. Autom. Constr. 2023, 156, 105096. [Google Scholar] [CrossRef]
- Tokatli, O.; Das, P.; Nath, R.; Pangione, L.; Altobelli, A.; Burroughes, G.; Jonasson, E.T.; Turner, M.F.; Skilton, R. Robot-Assisted Glovebox Teleoperation for Nuclear Industry. Robotics 2021, 10, 85. [Google Scholar] [CrossRef]
- Walker, M.; Phung, T.; Chakraborti, T.; Williams, T.; Szafir, D. Virtual, Augmented, and Mixed Reality for Human-Robot Interaction: A Survey and Virtual Design Element Taxonomy. ACM Trans. Hum. Robot Interact. 2023, 12, 1–39. [Google Scholar] [CrossRef]
- Martín-Barrio, A.; Roldán-Gómez, J.J.; Rodríguez, I.; del Cerro, J.; Barrientos, A. Design of a Hyper-Redundant Robot and Teleoperation Using Mixed Reality for Inspection Tasks. Sensors 2020, 20, 2181. [Google Scholar] [CrossRef]
- Kamran-Pishhesari, A.; Moniri-Morad, A.; Sattarvand, J. Applications of 3D Reconstruction in Virtual Reality-Based Teleoperation: A Review in the Mining Industry. Technologies 2024, 12, 40. [Google Scholar] [CrossRef]
- Nenna, F.; Zanardi, D.; Gamberini, L. Enhanced Interactivity in VR-Based Telerobotics: An Eye-Tracking Investigation of Human Performance and Workload. Int. J. Hum. Comput. Stud. 2023, 177, 103079. [Google Scholar] [CrossRef]
- Zhou, T.; Zhu, Q.; Du, J. Intuitive Robot Teleoperation for Civil Engineering Operations with Virtual Reality and Deep Learning Scene Reconstruction. Adv. Eng. Inform. 2020, 46, 101170. [Google Scholar] [CrossRef]
- Müller, A.; Petru, R.; Seitz, L.; Englmann, I.; Angerer, P. The Relation of Cognitive Load and Pupillary Unrest. Int. Arch. Occup. Env. Health 2011, 84, 561–567. [Google Scholar] [CrossRef] [PubMed]
- Hart, S.G. Nasa-Task Load Index (NASA-TLX); 20 Years Later. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2006, 50, 904–908. [Google Scholar] [CrossRef]
- Bejczy, B.; Bozyil, R.; Vaičekauskas, E.; Krogh Petersen, S.B.; Bøgh, S.; Hjorth, S.S.; Hansen, E.B. Mixed Reality Interface for Improving Mobile Manipulator Teleoperation in Contamination Critical Applications. Procedia Manuf. 2020, 51, 620–626. [Google Scholar] [CrossRef]
- Wibowo, S.; Siradjuddin, I.; Ronilaya, F.; Hidayat, M.N. Improving Teleoperation Robots Performance by Eliminating View Limit Using 360 Camera and Enhancing the Immersive Experience Utilizing VR Headset. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1073, 012037. [Google Scholar] [CrossRef]
- Su, Y.; Chen, X.; Zhou, T.; Pretty, C.; Chase, G. Mixed Reality-Integrated 3D/2D Vision Mapping for Intuitive Teleoperation of Mobile Manipulator. Robot. Comput. Integr. Manuf. 2022, 77, 102332. [Google Scholar] [CrossRef]
- Tachi, S. Telexistence: Past, present, and future. In Virtual Realities: International Dagstuhl Seminar, Dagstuhl Castle, Germany, 9–14 June 2013, Revised Selected Papers; Springer: Berlin/Heidelberg, Germany, 2015; pp. 229–259. [Google Scholar]
- Stoakley, R.; Conway, M.J.; Pausch, R. Virtual Reality on a WIM. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems—CHI ’95, Denver, CO, USA, 7–11 May 1995; ACM Press: New York, NY, USA, 1995; pp. 265–272. [Google Scholar]
- Gray, S.; Chevalier, R.; Kotfis, D.; Caimano, B.; Chaney, K.; Rubin, A.; Fregene, K.; Danko, T. An Architecture for Human-Guided Autonomy: Team TROOPER at the DARPA Robotics Challenge Finals. J. Field Robot. 2017, 34, 852–873. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D Is Here: Point Cloud Library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Whitney, D.; Rosen, E.; Ullman, D.; Phillips, E.; Tellex, S. ROS Reality: A Virtual Reality Framework Using Consumer-Grade Hardware for ROS-Enabled Robots. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Kohn, S.; Blank, A.; Puljiz, D.; Zenkel, L.; Bieber, O.; Hein, B.; Franke, J. Towards a Real-Time Environment Reconstruction for VR-Based Teleoperation Through Model Segmentation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Okura, F.; Ueda, Y.; Sato, T.; Yokoya, N. Free-Viewpoint Mobile Robot Teleoperation Interface Using View-Dependent Geometry and Texture. ITE Trans. Media Technol. Appl. 2014, 2, 82–93. [Google Scholar] [CrossRef]
- Wei, D.; Huang, B.; Li, Q. Multi-View Merging for Robot Teleoperation With Virtual Reality. IEEE Robot. Autom. Lett. 2021, 6, 8537–8544. [Google Scholar] [CrossRef]
- Kazanzides, P.; Vagvolgyi, B.P.; Pryor, W.; Deguet, A.; Leonard, S.; Whitcomb, L.L. Teleoperation and Visualization Interfaces for Remote Intervention in Space. Front. Robot. AI 2021, 8, 747917. [Google Scholar] [CrossRef]
- Bell, S.; Upchurch, P.; Snavely, N.; Bala, K. Material Recognition in the Wild with the Materials in Context Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- de Boissieu, F.; Godin, C.; Guilhamat, B.; David, D.; Serviere, C.; Baudois, D. Tactile Texture Recognition with a 3-Axial Force MEMS Integrated Artificial Finger. In Robotics; The MIT Press: Cambridge, MA, USA, 2010; pp. 49–56. [Google Scholar]
- Bradley, J.V. Complete Counterbalancing of Immediate Sequential Effects in a Latin Square Design. J. Am. Stat. Assoc. 1958, 53, 525–528. [Google Scholar] [CrossRef]
- Jackson, I.; Sirois, S. Infant Cognition: Going Full Factorial with Pupil Dilation. Dev. Sci. 2009, 12, 670–679. [Google Scholar] [CrossRef]
- Kret, M.E.; Sjak-Shie, E.E. Preprocessing Pupil Size Data: Guidelines and Code. Behav. Res. Methods 2019, 51, 1336–1342. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Flow Direction | Data Structure/Topic Name | Primary Content/Purpose |
|---|---|---|
| Physical System → Operator | Robot_State | Time-stamped robot joint angles (J1-J6) and calculated world pose (X, Y, Z, W, P, R). |
| Physical System → Operator | Robot_Point_Cloud | Time-stamped sequence of 3D points and color data from environmental sensors (e.g., Kinect). |
| Physical System → Operator | Robot_Image | Time-stamped, compressed (MPEG) image data from the robot’s end-effector camera. |
| Physical System → Operator | Robot_Alarm | Time-stamped status or error messages generated by the robot controller. |
| Physical System → Operator | Robot_Reachability_State | Time-stamped boolean flag indicating if a target pose is reachable. |
| Operator → Physical System | Operator_Teleop_Target | Time-stamped desired target pose (X, Y, Z, W, P, R) for the robot end-effector from operator input. |
| Operator → Physical System | Operator_Request | Time-stamped discrete commands initiated by the operator (e.g., RESET, ABORT, HOME). |
| Operator → Physical System | Operator_Path_Point | Time-stamped data for creating/modifying robot path waypoints (ID, Add/Update/Delete flags, Pose). |
| Cyber → Operator | Expert_Guidance | Time-stamped instructions, suggestions, or context information from the Expert Support System for the UI. |
| Cyber → Operator/Physical | Collision_Alert | Time-stamped warning/status from collision detection module (e.g., proximity level, collision imminent). |
| Cyber/Physical → Operator | Haptic_Command | Time-stamped command to trigger specific haptic feedback on the operator’s controllers. |
| Physical/Cyber → Operator/Cyber | Processed_Perception_Data | Time-stamped results of perception processing (e.g., detected ArUco tag poses) |
| Characteristics | Number of Participants (n = 24) | Percentage (%) | |
|---|---|---|---|
| Gender | Male | 19 | 79.17% |
| Female | 5 | 20.83% | |
| Previous exposure to VR | Yes | 17 | 70.80% |
| No | 7 | 29.20% | |
| Familiar with robotics | Yes | 15 | 62.50% |
| No | 9 | 37.5% | |
| Confidence in using new technologies | High | 8 | 33.30% |
| Moderate | 15 | 62.5% | |
| Low | 1 | 4.2% | |
| Metric | 2D | 3D | 2D3D | AV | ANOVA (Main Effect of Modality) F(3, 69) |
|---|---|---|---|---|---|
| Completion Time (s) | 248.75 (±85) | 201.88 (±65) | 218.29 (±75) | 200.46 (±70) | F = 2.13, p = 0.102 |
| Collision Count (%) | 1.39 (±1.0) | 2.31 (±1.53) | 1.39 (±0.85) | 5.56 (±3.1) | F = 4.50, p = 0.006 |
| Distance Accuracy (%) | 84.72 (±10) | 79.17 (±12) | 76.39 (±13) | 80.56 (±12) | F = 1.50, p = 0.222 |
| Photo Quality (%) | 94.44 (±5.0) | 93.06 (±5.5) | 97.22 (±3.0) | 93.06 (±4.0) | F = 2.20, p = 0.096 |
| Aspect | Feedback Theme | Number of Participants (%) |
|---|---|---|
| 2D INTERFACE | ||
| Positive | Clear, easy to judge distances accurately | 7 (29.2%) |
| Felt successful | 5 (20.8%) | |
| Simple, straightforward | 4 (16.7%) | |
| Negative | Required high mental effort/concentration | 9 (37.5%) |
| Felt slower | 6 (25.0%) | |
| Less engaging/detached from environment | 3 (12.5%) | |
| 3D INTERFACE | ||
| Positive | Precise navigation possible | 5 (20.8%) |
| Good for identifying shape | 3 (12.5%) | |
| Negative | High overall workload | 5 (20.8%) |
| Frustrating/Difficult to control precisely | 11 (45.8%) | |
| Felt performance was poor | 7 (29.2%) | |
| Can feel tiring/visually demanding | 4 (16.7%) | |
| 2D3D INTERFACE | ||
| Positive | Easiest/Most comfortable/Least effort required | 13 (54.2%) |
| Efficient because both 2D and 3D can be used together | 8 (33.3%) | |
| Negative | Visually demanding | 3 (12.5%) |
| AV INTERFACE | ||
| Positive | Augmented information is occasionally helpful | 5 (20.8%) |
| Negative | Difficult to navigate/Prone to collisions | 11 (45.8%) |
| Information overlay sometimes confusing/Obscuring | 13 (54.2%) | |
| Control felt imprecise at times | 3 (12.5%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazeas, D.; Namoano, B. Study of Visualization Modalities on Industrial Robot Teleoperation for Inspection in a Virtual Co-Existence Space. Virtual Worlds 2025, 4, 17. https://doi.org/10.3390/virtualworlds4020017
Mazeas D, Namoano B. Study of Visualization Modalities on Industrial Robot Teleoperation for Inspection in a Virtual Co-Existence Space. Virtual Worlds. 2025; 4(2):17. https://doi.org/10.3390/virtualworlds4020017
Chicago/Turabian StyleMazeas, Damien, and Bernadin Namoano. 2025. "Study of Visualization Modalities on Industrial Robot Teleoperation for Inspection in a Virtual Co-Existence Space" Virtual Worlds 4, no. 2: 17. https://doi.org/10.3390/virtualworlds4020017
APA StyleMazeas, D., & Namoano, B. (2025). Study of Visualization Modalities on Industrial Robot Teleoperation for Inspection in a Virtual Co-Existence Space. Virtual Worlds, 4(2), 17. https://doi.org/10.3390/virtualworlds4020017