1. Introduction
In the age of the coronavirus, various testing has become enormously widespread. Unfortunately, what has not become widespread is the understanding of the test results. The most common PCR test is used for the detection of the virus (more precisely its particular fragments) in a sample collected by a nasopharyngeal swab. The number of PCR positive cases can be used to assess the Case Fatality Rate (CFR) of the infection. CFR is the proportion of COVID-19 deaths in the diagnosed (i.e., PCR positive) population. However, CFR depends heavily on the testing strategy–any infection may reach the CFR of if only the deceased are tested. Thus, it is more sensible to estimate the Infection Fatality Rate (IFR) which is the proportion of COVID-19 deaths in the infected population, regardless whether the infection was detected or not. The IFR is always lower than CFR and it does not depend on the testing strategy. However, apart from the virus itself, IFR also depends on the characteristics of the population, state of health care, etc. To estimate the IFR, one must infer what proportion of the population has already met the virus.
One option to find the proportion of so far infected people is to test for the presence of antibodies against the coronavirus in a representative sample of the population. Many seroprevalence studies have been performed and their results helped to estimate the IFR of COVID-19, e.g., [
1,
2,
3]. The meta-study by Ioannides [
4] combined 61 larger sero-prevalence studies and reported the median IFR of
. In people under 70 years, the median IFR reached
. Both the numbers are likely to be overestimated because an unknown proportion of population defeats the virus on the level of cellular immunity (and probably even become immune) without producing antibodies at all [
5]. This seems to be the case especially for children [
6].
Despite the fundamental importance of various forms of testing, not enough attention has been paid to the correct interpretation of the test results. In this paper, we want to explain this issue in three successive steps of an increasing level of complexity. We use the example of antibody tests here, but the same logic should be used for any test, the results of which are converted to a binary answer (positive–negative). This applies to all antibody tests (laboratory or rapid tests), all PCR tests (full RT-qPCR, antigen testing, etc.), and many more coronavirus unrelated medical tests, or even health unrelated tests (such as AB testing [
7]).
2. Antibody Primer
Some explanation of the mechanism of antibodies testing is needed. We use the example of the standard Enzyme-Linked Immunosorbent Assay (ELISA). This is a semiquantitative method which measures the amount of SARS-CoV-2 antibodies in a sample by detecting a color change of the sample resulting from a reaction. The color change is quantified by the optical density of the sample. The optical density is then divided by the optical density of a calibration sample (provided in each kit by the manufacturer) which contains a borderline concentration of the antibodies. The sample is considered positive, if the resulting Optical Density Ratio (OD Ratio) exceeds a threshold set by the manufacturer ( in the case of Euroimmun ELISA kits) and negative, if the OD Ratio falls below a threshold ( in the case of Euroimmun ELISA kits). OD Ratio values between the two thresholds are deemed inconclusive. ELISA assays are usually performed in batches of 96-well plates. Each plate contains one or two calibration samples and a few positive and negative controls.
There are several types of antibodies, each with a specific role in fighting the disease and thus each with specific dynamics. The most commonly measured antibodies are immunoglobulins A (IgA) and immunoglobulins G (IgG). The production of IgA antibodies starts 1–2 weeks from the infection and they last for at least several weeks. IgG are produced somewhat later but usually last for several months after the infection. There is considerable debate about the protective role of the antibodies and the possibility of a reinfection [
8,
9,
10]. It is probable that some (possibly most) of reported reinfections are due to the false positivity or false negativity of one of the PCR tests. This provides further motivation for thinking clearly about the test results.
3. A Binary Test Primer
Each test with a binary outcome has a certain accuracy which is never perfect. Let us fix ideas by considering a single test with a binary outcome (positive or negative) for the presence of a specific antibody. In each tested subject, the antibody is either present () or absent (), which we do not know. For each subject, the test may come out either positive () or negative (), which is the observed result. The performance of the test may be significantly different for the subjects and for the subjects. Therefore, two numbers are needed to characterize the performance of any binary test. The sensitivity of the test is the accuracy on the population, i.e., the probability that the test comes out positive provided the antibodies are, in fact, present. In terms of conditional probability, we can write . On the other hand, the accuracy on the population is called the specificity of the test. The specificity of the test is the probability that the test comes out negative provided the antibodies are absent. Thus, . The prevalence of antibodies in the population is denoted by prev. It can be interpreted as the probability that the antibodies are present in a randomly chosen subject, i.e.,
In practice, we test a subject and observe the test result, say
. Since neither
sens nor
spec are perfect, a positive test result does not necessarily imply that the antibodies are presents (it may be a false positive). Thus, we want to make
inference about the probability that the antibodies are present, provided the test came out positive. We use the Bayes’ Theorem to obtain
It is important to realize that the posterior probability , i.e., the probability that a positively tested subject indeed has the antibodies, depends not only on the parameters of the test (sens and spec) but also on the prevalence. For example, the Euroimmun ELISA test for IgA anti-SARS-CoV-2 antibodies has a declared sensitivity of and specificity of . If the prevalence is assumed to be around (as it was the case at the very beginning of the pandemic), a positive test result yields the posterior probability of approximately . Thus, about 9 out of 10 positive test results are false positives! If the prevalence rises to (a sensible figure after the first wave of the pandemic), the posterior increases to about . Once prevalence reaches (only the hardest hit regions may have reached this figure), the posterior grows further to .
This example represents the step zero in understanding seroprevalence studies and suggests a careful way of interpreting binary test results is needed: A positive test does not necessarily imply that antibodies are present in the tested subject, it merely increases the probability that it is so. The posterior probability is given by the Bayes’ Theorem and it depends on the sensitivity and specificity of the test but also on the prevalence of the antibodies.
4. A Single Test Study
In a typical seroprevalence study, the question is how widespread a certain antibody is in a given population. Thus, we want to make inference on the prevalence. A test of known parameters is used and a random sample of
N subjects is drawn from the population. The study yields data which consist of
K positive test results and
negative test results. The Bayes’ Theorem–this time written in terms of
probability densities [
11]–states that
The proportional sign (∝) means that the
posterior density must be normalized to a unit area. The posterior density represents a degree of belief about the prevalence, taking into account all the available data. Some assumption must be made about the prevalence that we want to estimate. This is the first principle of Bayesian inference–
you cannot make inference without assumptions. It is sensible to model the prior density
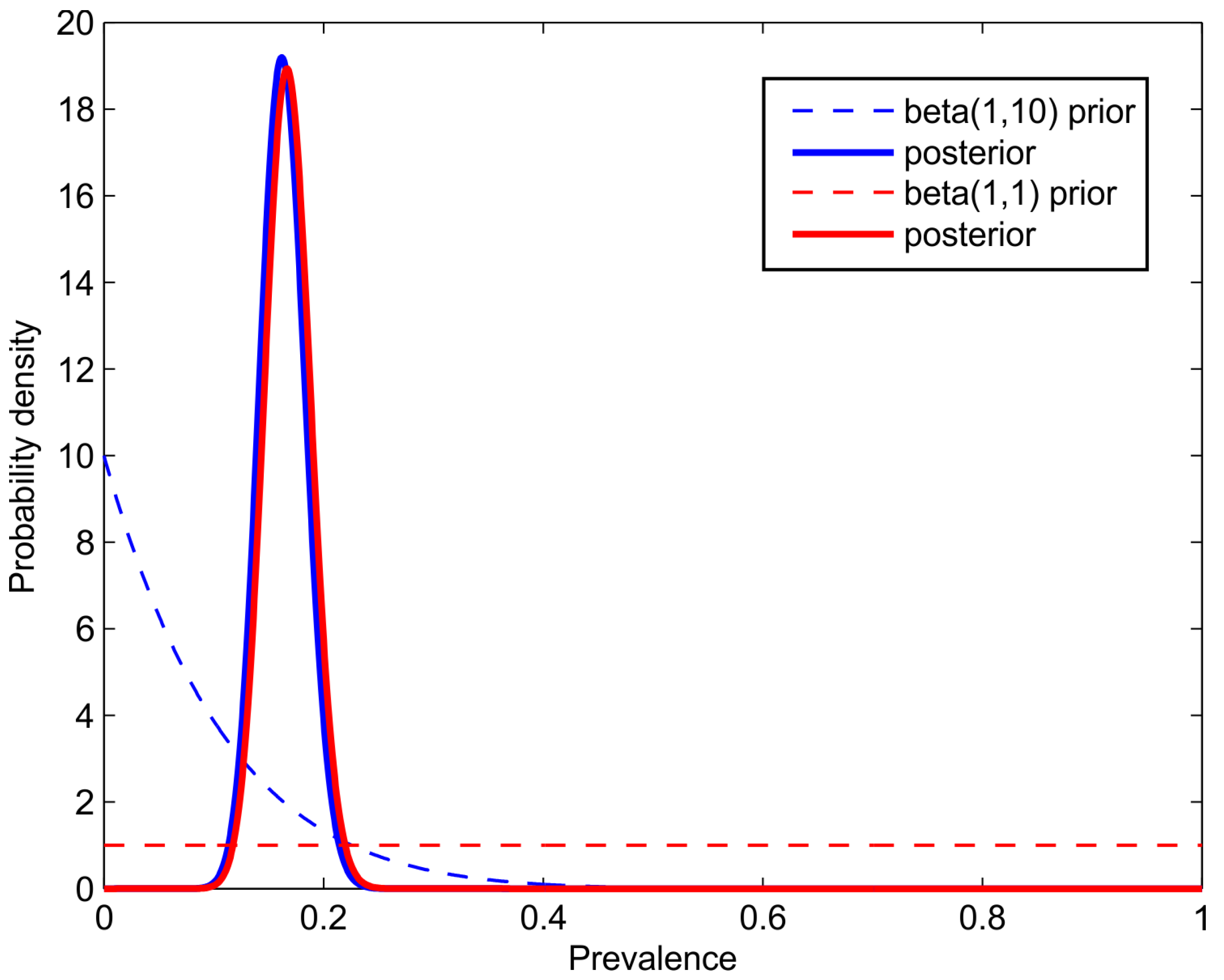
as a beta distribution centered around our prior beliefs. For example, if the study is performed at the very beginning of the pandemic, the prevalence is almost certainly very low, and so
may be a sensible prior (see
Figure 1).
Now let us evaluate the
likelihood, i.e.,
. The likelihood is interpreted as the probability of obtaining the observed data if the true prevalence was known and equal to
prev. This is a rather simple calculation because
Both the terms are easy to evaluate:
Combining all the above, the likelihood becomes
This is an explicit expression that can directly be evaluated. In practice, the logarithm of the likelihood is evaluated to avoid the problem of multiplying small numbers.
Figure 1 shows the results of an artificial example with
and
for a test with the parameters
and
.
Now consider the realistic setting of and for the anti-SARS-CoV-2 IgA ELISA assay. Let us assume that in a sample of subjects, we obtained positive results. A careless estimate of the seroprevalence would yield . However, the correct computation (with the prior) reveals that the mean of the posterior is –an almost five times lower number. The probability that the true prevalence exceeds is less than , and the probability that the true prevalence exceeds is i.e., the careless seroprevalence estimate is all but impossible! This is consistent with the observation of the previous section that in the environment of low prevalence, most of the positive test results are false positives. This shows that seroprevalence studies must be evaluated correctly because the careless estimate of the prevalence by the fraction of positive test results () is usually completely meaningless.
5. Conclusions
We have shown how to use the framework of Bayesian inference to produce reasonable estimates of seroprevalence from studies that use a single binary test. Although the Bayes’ Theorem represents only a formalization of the common sense, it sometimes produces results that seem counter-intuitive at first sight. It is important to realize that the reality may be different from its image represented by test results. The extent to which these two worlds differ depends on the performance of the test (i.e., its sensitivity and specificity), and the prevalence of the tested condition. The Bayes’ Theorem provides a logically consistent framework for combining our prior beliefs with all the information obtained from the data.
Author Contributions
Conceptualization, Z.K., T.F., O.V., and J.S.; Methodology, Z.K., T.F., J.F., J.S., and O.V.; Software, T.F.; Validation, O.V., J.F., Z.K., and J.S.; Formal Analysis, T.F., and O.V.; Resources, Z.K., and T.F.; Data Curation, Z.K., T.F., and O.V.; Writing—Original Draft Preparation, J.F. and T.F.; Writing—Review and Editing, O.V., Z.K., and J.S.; Visualization, T.F., and J.F.; Supervision, O.V.; Funding Acquisition, T.F., and J.S. All authors have read and agreed to the published version of the manuscript.
Funding
The authors acknowledge the support of the Grant Agency of the Czech Republic, GA19-17474S, “Bayesian Reasoning as a Tool for Efficient Expert Testimonies in Civil Proceedings”.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the institutions of Nemocnice Strakonice and Nemocnice Pisek, the personal data are part of the medical documentation kept by the provider according to Act No. 372/2011 Coll.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are not openly available as they are personal medical data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pollan, M.; Perez-Gomez, B.; Pastor-Barriuso, R.; Oteo, J.; Hernán, M.A.; Pérez-Olmeda, M.; Sanmartín, J.L.; Fernández-García, A.; Cruz, I.; de Larrea, N.F.; et al. Prevalence of SARS-CoV-2 in Spain (ENE-COVID): A nationwide, population-based seroepidemiological study. Lancet 2020, 396, 535–544. [Google Scholar] [CrossRef]
- Stringhini, S.; Wisniak, A.; Piumatti, G.; Azman, A.S.; Lauer, S.A.; Baysson, H.; De Ridder, D.; Petrovic, D.; Schrempft, S.; Marcus, K.; et al. Seroprevalence of anti-SARS-CoV-2 IgG antibodies in Geneva, Switzerland (SEROCoV-POP): A population-based Study. Lancet 2020, 396, 313–319. [Google Scholar] [CrossRef]
- Streeck, H.; Schulte, B.; Kuemmerer, B.; Richter, E.; Hoeller, T.; Fuhrmann, C.; Bartok, E.; Dolscheid-Pommerich, R.; Berger, M.; Wessendorf, L.; et al. Infection fatality rate of SARSCoV2 in a super-spreading event in Germany. Nat. Commun. 2020, 11, 5829. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J. The infection fatality rate of COVID-19 inferred from seroprevalence data. Bull. World Health Organ. 2020. Available online: https://www.who.int/bulletin/online_first/BLT.20.265892.pdf (accessed on 5 March 2021).
- Sewell, H.F.; Agius, R.M.; Stewart, M.; Kendrick, D. Cellular immune responses to Covid-19. BMJ 2020, 370, 3018. [Google Scholar] [CrossRef] [PubMed]
- Weisberg, S.P.; Connors, T.J.; Zhu, Y.; Baldwin, M.R.; Lin, W.H.; Wontakal, S.; Szabo, P.A.; Wells, S.B.; Dogra, P.; Gray, J.; et al. Distinct antibody responses to SARS-CoV-2 in children and adults across the COVID-19 clinical spectrum. Nat. Immunol. 2021, 22, 25–31. [Google Scholar] [CrossRef] [PubMed]
- Kohavi, R.; Longbotham, R. Online Controlled Experiments and A/B Testing. Encycl. Mach. Learn. Data Min. 2017, 7, 922–929. [Google Scholar]
- Iwasaki, A. What reinfections mean for COVID-19. Lancet Infect. Dis. 2020. [Google Scholar] [CrossRef]
- Edridge, A.W.; Kaczorowska, J.; Hoste, A.C.; Bakker, M.; Klein, M.; Loens, K.; Jebbink, M.F.; Matser, A.; Kinsella, C.M.; Rueda, P.; et al. Seasonal coronavirus protective immunity is short-lasting. Nat. Med. 2020. [Google Scholar] [CrossRef] [PubMed]
- Tillett, R.L.; Sevinsky, J.R.; Hartley, P.D.; Kerwin, H.; Crawford, N.; Gorzalski, A.; Laverdure, C.; Verma, S.C.; Rossetto, C.C.; Jackson, D.; et al. Genomic evidence for reinfection with SARS-CoV-2: A case study. Lancet Infect. Dis. 2020. Available online: https://doi.org/S1473-3099(20)30764-7 (accessed on 5 March 2021). [CrossRef]
- MacKay, D.J. Information theory, inference and learning algorithms. In Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}