
A Study of Disease Diagnosis Using Machine Learning †


Abstract
:1. Introduction
Problem Statement
2. Data, Algorithms, and Methods
2.1. Data
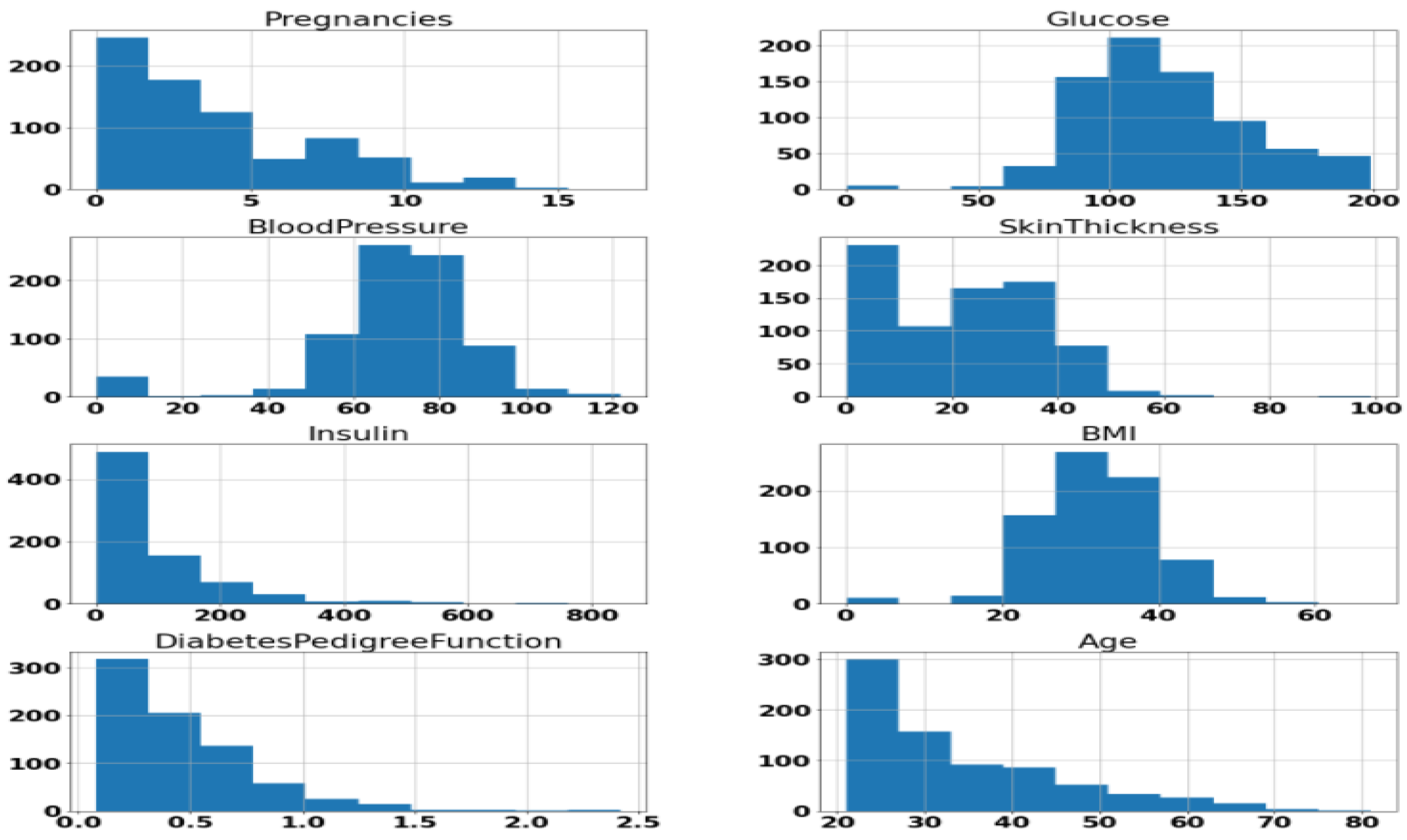
2.1.1. Data Exploration
2.1.2. Data Exploratory Visualization
2.2. Machine Learning Algorithms and Techniques
2.3. Evaluation Metric
2.4. Overview of the Methodology
2.4.1. Data Preprocessing
2.4.2. Implementation of ML Algorithms
2.4.3. Refinement
3. Result and Discussion
4. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Fatima, M.; Pasha, M. Survey of machine learning algorithms for disease diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 73781. [Google Scholar] [CrossRef]
- Machine Learning Use Cases|Neural Designer. Available online: https://www.neuraldesigner.com/solutions (accessed on 13 January 2022).
- Demystifying AI in Healthcare: Historical Perspectives and Current Considerations. Available online: https://www.physicianleaders.org/news/demystifying-ai-in-healthcare-historical-perspectives-and-current-considerations (accessed on 13 January 2022).
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Massaro, A.; Ricci, G.; Selicato, S.; Raminelli, S.; Galiano, A. Decisional Support System with Artificial Intelligence oriented on Health Prediction using a Wearable Device and Big Data. In Proceedings of the 2020 IEEE International Workshop on Metrology for Industry 4.0 & IoT, Rome, Italy, 3–5 June 2020; pp. 718–723. [Google Scholar] [CrossRef]
- Habib, M.; Faris, M.; Qaddoura, R.; Alomari, M.; Alomari, A.; Faris, H. Toward an automatic quality assessment of voice-based telemedicine consultations: A deep learning approach. Sensors 2021, 21, 3279. [Google Scholar] [CrossRef] [PubMed]
- Massaro, A.; Galiano, A.; Scarafile, D.; Vacca, A.; Frassanito, A.; Melaccio, A.; Solimando, A.; Ria, R.; Calamita, G.; Bonomo, M.; et al. Telemedicine DSS-AI Multi Level Platform for Monoclonal Gammopathy Assistance. In Proceedings of the 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 1 June–1 July 2020. [Google Scholar] [CrossRef]
- Niculescu, M.S.; Florescu, A.; Pasca, S. LabConcept—A new mobile healthcare platform for standardizing patient results in telemedicine. Appl. Sci. 2021, 11, 1935. [Google Scholar] [CrossRef]
- Massaro, A.; Maritati, V.; Savino, N.; Galiano, A. Neural Networks for Automated Smart Health Platforms oriented on Heart Predictive Diagnostic Big Data Systems. In Proceedings of the 2018 AEIT International Annual Conference, Bari, Italy, 3–5 October 2018. [Google Scholar] [CrossRef]
- Sajda, P. Machine learning for detection and diagnosis of disease. Annu. Rev. Biomed. Eng. 2006, 8, 537–565. [Google Scholar] [CrossRef] [PubMed]
- Schaefer, J.; Lehne, M.; Schepers, J.; Prasser, F.; Thun, S. The use of machine learning in rare diseases: A scoping review. Orphanet J. Rare Dis. 2020, 15, 145. [Google Scholar] [CrossRef] [PubMed]
- Béjar, L.R.; Suleiman-Martos, N.; Mhlanga, D. The Role of Artificial Intelligence and Machine Learning Amid the COVID-19 Pandemic: What Lessons Are We Learning on 4IR and the Sustainable Development Goals. Int. J. Environ. Res. Public Health 2022, 19, 1879. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Deep Learning for Disease Diagnosis Confounded by Image Labels—Physics World. Available online: https://physicsworld.com/a/deep-learning-for-disease-diagnosis-confounded-by-image-labels/ (accessed on 13 January 2022).
- Smith, J.W.; Everhart, J.E.; Dickson, W.C.; Knowler, W.C.; Johannes, R.S. Using the ADAP Learning Algorithm to Forecast the Onset of Diabetes Mellitus. In Proceedings of the Annual Symposium on Computer Application in Medical Care, Washington, DC, USA, 6–9 November 1988; p. 261. [Google Scholar]
- 10 Standard Datasets for Practicing Applied Machine Learning. Available online: https://machinelearningmastery.com/standard-machine-learning-datasets/ (accessed on 12 January 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python Gaël Varoquaux Bertrand Thirion Vincent Dubourg Alexandre Passos PEDREGOSA, VAROQUAUX, GRAMFORT ET AL. Matthieu Perrot. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Amazon SageMaker—Machine Learning—Amazon Web Services. Available online: https://aws.amazon.com/sagemaker/ (accessed on 13 January 2022).
- Amazon SageMaker: Amazon Sagemaker API Reference. Available online: https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_Search.html (accessed on 13 January 2022).
- 1. Supervised Learning—Scikit-Learn 1.0.2 Documentation. Available online: https://scikit-learn.org/stable/supervised_learning.html (accessed on 14 January 2022).
- Poudel, S. Improving Collaborative Filtering Recommendation System via Optimal Sub-Sampling and Aspect-Based Interpretability. Ph.D. Thesis, North Carolina Agricultural and Technical State University, Greensboro, NC, USA, 2022. Available online: https://www.proquest.com/dissertations-theses/improving-collaborative-filtering-recommendation/docview/2680264335/se-2 (accessed on 14 January 2022).
- Poudel, S.; Bikdash, M. Optimal dependence of performance and efficiency of collaborative filtering on random stratified subsampling. Big Data Min. Anal. 2022, 5, 192–205. [Google Scholar] [CrossRef]
- Galdi, P.; Tagliaferri, R. Data Mining: Accuracy and Error Measures for Classification and Prediction Neonatal MRI View project Computational methods for omics data View project Data Mining: Accuracy and Error Measures for Classification and Prediction. Encycl. Bioinform. Comput. Biol. 2019, 1, 431–436. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Accuracy Paradox—Wikipedia. Available online: https://en.wikipedia.org/wiki/Accuracy_paradox (accessed on 14 January 2022).
- Valverde-Albacete, F.J.; Peláez-Moreno, C. 100% Classification Accuracy Considered Harmful: The Normalized Information Transfer Factor Explains the Accuracy Paradox. PLoS ONE 2014, 9, e84217. [Google Scholar] [CrossRef] [PubMed]
- Saminsm/Disease-Diagnosis-Using-Machine-Learning. Available online: https://github.com/saminsm/Disease-Diagnosis-using-Machine-Learning (accessed on 1 February 2022).

{kind=link}
{kind=link}
| Pregnancies | Glucose | Blood Pressure | Skin Thickness | Insulin | BMI | Diabetes Pedigree Function | Age | |
|---|---|---|---|---|---|---|---|---|
| Count | 768 | 768 | 768 | 768 | 768 | 768 | 768 | 768 |
| Mean | 3.85 | 120.89 | 69.10 | 20.57 | 79.79 | 31.99 | 0.47 | 33.24 |
| std | 3.37 | 31.97 | 19.35 | 15.95 | 115.244 | 7.88 | 0.33 | 11.76 |
| min | 0 | 0 | 0 | 0 | 0 | 0 | 0.078 | 21 |
| 25% (Q1) | 1 | 99 | 62 | 0 | 0 | 27.3 | 0.24 | 24 |
| 50% (Q2) | 3 | 117 | 72 | 23 | 30.5 | 32 | 0.37 | 29 |
| 75% (Q3) | 6 | 140.25 | 80 | 32 | 127.25 | 36.6 | 0.63 | 41 |
| max | 17 | 199 | 122 | 99 | 846 | 67.1 | 2.42 | 81.0 |
| Library | ML Algorithm | Number of ML Approaches |
|---|---|---|
| Scikit-Learn | Random Forest Classifier, Decision Tree Classifier, Naïve Bayes Classifier, Perceptron, Multilayer Perceptron, Voting Classifier | 6 |
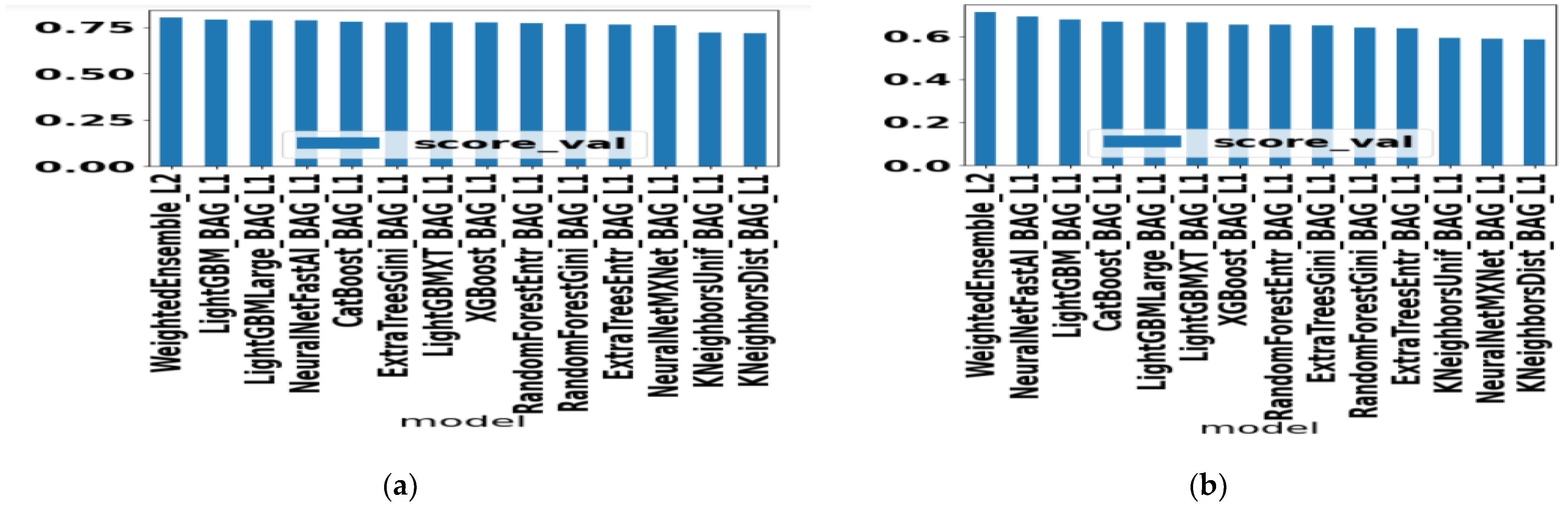
| AutoGluon | WeightedEnsemble_L2, LightGBM_BAG_L1, LightGBM_LARGE_BAG_L1, NeuralNetFastAI_BAG_L1, CATBoost_BAG_L1, ExtraTreesGini_BAG_L1, LightGBMXT_BAG_L1, XGBoost_BAG_L1, RandomForestEntr_BAG_L1, RandomForestGini_BAG_L1, ExtraTreesEntr_BAG_L1, NeuralNetMXNet_BAG_L1, KNeighborsUnif_BAG_L1, KNeighborsDist_BAG_L1 | 14 |
| S. N | ML Algorithm | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| 1 | Random Forest Classifier (Scikit-learn) | 0.74 | 0.81 | 0.78 | 0.84 |
| 2 | Decision Tree Classifier (Scikit-learn) | 0.65 | 0.73 | 0.73 | 0.73 |
| 3 | Naïve Bayes Classifier (Scikit-learn) | 0.77 | 0.83 | 0.80 | 0.86 |
| 4 | Perceptron (Scikit-learn) | 0.49 | 0.47 | 0.71 | 0.35 |
| 5 | Multilayer Perceptron (Scikit-learn) | 0.68 | 0.76 | 0.75 | 0.77 |
| 6 | Voting Classifier (Scikit-learn) | 0.72 | 0.78 | 0.79 | 0.77 |
| 7 | AutoGluon Best Performer | 0.74 | 0.82 | 0.76 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudel, S. A Study of Disease Diagnosis Using Machine Learning. Med. Sci. Forum 2022, 10, 8. https://doi.org/10.3390/IECH2022-12311
Poudel S. A Study of Disease Diagnosis Using Machine Learning. Medical Sciences Forum. 2022; 10(1):8. https://doi.org/10.3390/IECH2022-12311
Chicago/Turabian StylePoudel, Samin. 2022. "A Study of Disease Diagnosis Using Machine Learning" Medical Sciences Forum 10, no. 1: 8. https://doi.org/10.3390/IECH2022-12311
APA StylePoudel, S. (2022). A Study of Disease Diagnosis Using Machine Learning. Medical Sciences Forum, 10(1), 8. https://doi.org/10.3390/IECH2022-12311