
Algebraic Combinatorics in Financial Data Analysis: Modeling Sovereign Credit Ratings for Greece and the Athens Stock Exchange General Index



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Description and Preprocessing
2.2. Poset Representation of Rating Hierarchy
2.3. Credit Rating Transition Graph
2.4. Rolling Correlation Analysis
2.5. Granger Causality Tests
2.6. Event Study of Rating Shocks
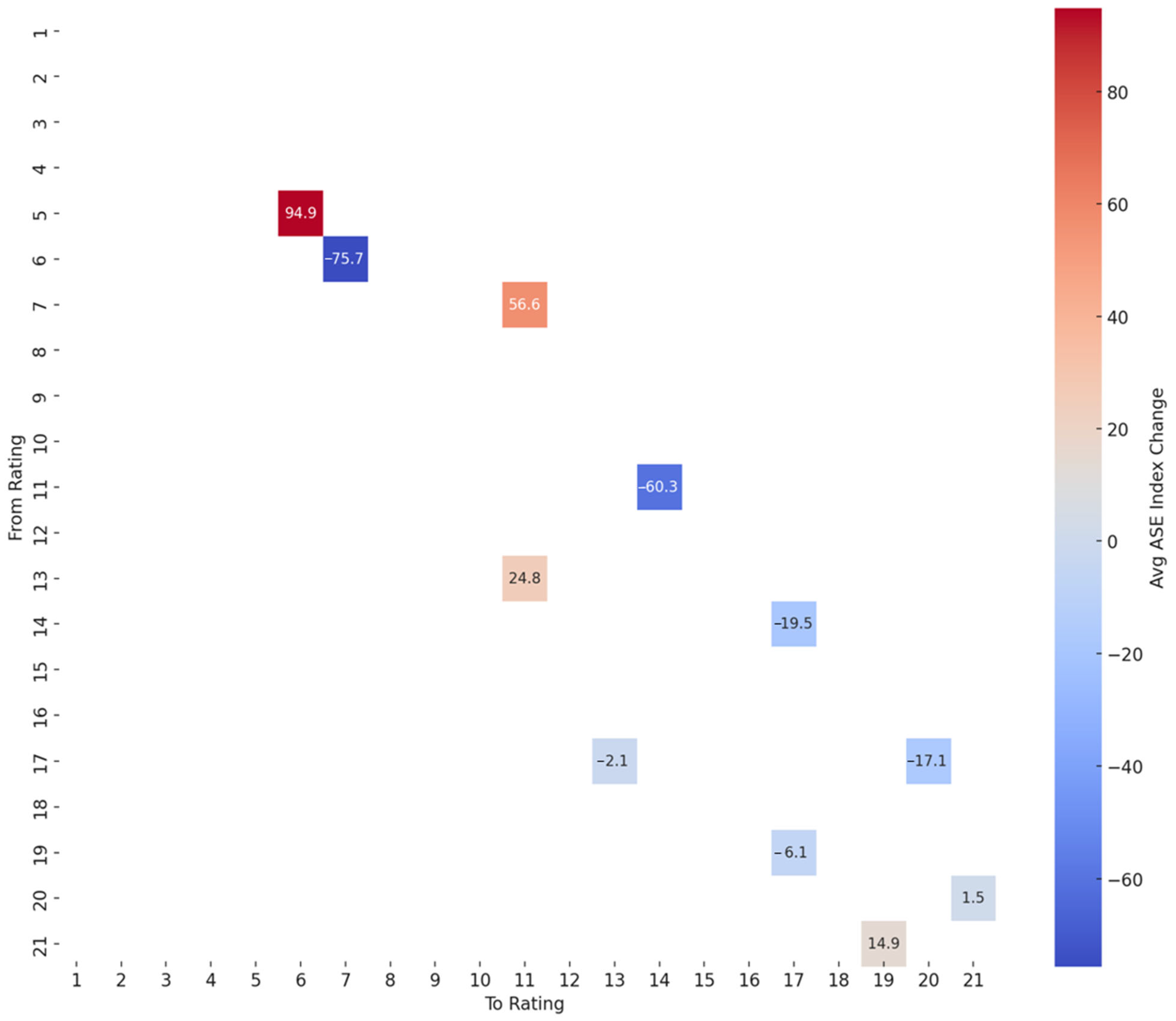
2.7. Reward Matrix Construction
2.8. Optimal Rating Path Optimization
3. Results
3.1. Data Preprocessing
3.2. Poset Representation of Rating Hierarchy
3.3. Credit Rating Transition Graph
3.4. Rolling Correlation Analysis
3.5. Granger Causality Tests
3.6. Event Study of Rating Shocks
3.7. Reward Matrix
3.8. Optimal Rating Path Optimization
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Python Script “Data Loading and Preprocessing”
- import pandas as pd
- # Load the Excel file
- excel_path = “/mnt/data/moodys_ase_data.xlsx”
- xls = pd.ExcelFile(excel_path)
- # Display the sheet names to understand the structure
- sheet_names = xls.sheet_names
- sheet_names
- # Load the relevant sheet
- df = xls.parse(‘moodys_ase_data’)
- # Display the first few rows to understand the structure of the data
- df.head()
- import numpy as np
- # Define the mapping from ratings to integers (based on the hierarchy provided)
- rating_order = [
- “Aaa”, “Aa1”, “Aa2”, “Aa3”, “A1”, “A2”, “A3”, “Baa1”, “Baa2”, “Baa3”,
- “Ba1”, “Ba2”, “Ba3”, “B1”, “B2”, “B3”, “Caa1”, “Caa2”, “Caa3”, “Ca”, “C”
- ]
- rating_to_int = {rating: i + 1 for i, rating in enumerate(rating_order)}
- # Add the encoded numerical rating
- df[‘Rating_Int’] = df[‘Rating_Scale’].map(rating_to_int)
- # Drop rows with missing values if any
- df.dropna(subset = [‘Rating_Int’, ‘ASE_Index’], inplace = True)
- # Sort by date to ensure chronological order
- df[‘Date’] = pd.to_datetime(df[‘Date’])
- df.sort_values(‘Date’, inplace = True)
- df.reset_index(drop = True, inplace = True)
- # Show processed data
- import ace_tools as tools; tools.display_dataframe_to_user(name = “Processed Moody’s and ASE Data”, dataframe = df)
Appendix A.2. Python Script “Poset Representation”
- # Build the Poset representation of the Moody’s credit rating hierarchy
- # This is a simple total order based on credit quality (1 = Aaa to 21 = C)
- poset_edges = [(i, i + 1) for i in range(1, 21)] # 21 ratings, so 20 edges
- # Create a directed graph for visualization
- G_poset = nx.DiGraph()
- G_poset.add_edges_from(poset_edges)
- # Generate labels from integers to rating names
- labels = {i: int_to_rating[i] for i in range(1, 22)}
- # Plot the poset
- plt.figure(figsize = (8, 12))
- pos = nx.spring_layout(G_poset, seed = 42)
- nx.draw(G_poset, pos, with_labels = True, labels = labels, node_size = 800, node_color = ‘lightgreen’, font_size = 10, arrows = True)
- plt.title(“Poset Representation of Moody’s Credit Rating Hierarchy”)
- plt.tight_layout()
- plt.show()
- # Create an academic-style Hasse diagram for the full Moody’s rating hierarchy
- full_ratings = list(range(1, 22)) # Ratings from Aaa (1) to C (21)
- poset_edges_full = [(i, i + 1) for i in full_ratings if i + 1 in full_ratings]
- # Create graph
- G_poset_full = nx.DiGraph()
- G_poset_full.add_edges_from(poset_edges_full)
- labels_full = {i: int_to_rating[i] for i in full_ratings}
- # Academic-style layout: vertical hierarchy (highest quality at top)
- pos_hierarchy_full = {node: (0, −i) for i, node in enumerate(full_ratings)}
- # Save as PDF
- output_pdf_full_path = “/mnt/data/Poset_Moodys_Full_Hasse_Diagram.pdf”
- plt.figure(figsize = (5, 14))
- nx.draw(G_poset_full, pos = pos_hierarchy_full, with_labels = True,
- labels = labels_full, node_size = 1200, node_color = ‘white’,
- edge_color = ‘black’, font_size = 12, font_weight = ‘bold’,
- linewidths = 1.5, edgecolors = ‘black’)
- plt.title(“Hasse Diagram: Moody’s Full Credit Rating Hierarchy”, fontsize = 13)
- plt.axis(‘off’)
- plt.tight_layout()
- plt.savefig(output_pdf_full_path)
- plt.close()
- output_pdf_full_path
Appendix A.3. Python Script “Poset Representation (Greece, 2004–2024)”
- # Extract the unique ratings observed for Greece during the period
- unique_ratings_greece = sorted(df[‘Rating_Int’].unique())
- # Build the poset edges only for Greece’s observed ratings
- poset_edges_greece = [(i, j) for i in unique_ratings_greece for j in unique_ratings_greece if j == i + 1]
- # Create graph
- G_poset_greece = nx.DiGraph()
- G_poset_greece.add_edges_from(poset_edges_greece)
- # Create labels from observed ratings
- labels_greece = {i: int_to_rating[i] for i in unique_ratings_greece}
- # Plot the poset
- plt.figure(figsize = (6, 10))
- pos = nx.spring_layout(G_poset_greece, seed = 42)
- nx.draw(G_poset_greece, pos, with_labels = True, labels = labels_greece, node_size = 800, node_color = ‘lightcoral’, font_size = 10, arrows = True)
- plt.title(“Moody’s Credit Rating Poset for Greece (2004–2024)”)
- plt.tight_layout()
- plt.show()
- # Recalculate the poset graph with proper node set
- G_poset_greece = nx.DiGraph()
- G_poset_greece.add_nodes_from(unique_ratings_greece)
- G_poset_greece.add_edges_from(poset_edges_greece)
- # Create labels again
- labels_greece = {i: int_to_rating[i] for i in unique_ratings_greece}
- # Plot the poset for Greece
- plt.figure(figsize = (6, 10))
- pos = nx.spring_layout(G_poset_greece, seed = 42)
- nx.draw(G_poset_greece, pos, with_labels = True, labels = labels_greece, node_size = 800, node_color = ‘lightcoral’, font_size = 10, arrows = True)
- plt.title(“Moody’s Credit Rating Poset for Greece (2004–2024)”)
- plt.tight_layout()
- plt.show()
- # Use a hierarchical layout to give a cleaner representation
- pos_hierarchy = {node: (0, −i) for i, node in enumerate(sorted(unique_ratings_greece))}
- plt.figure(figsize = (5, 10))
- nx.draw(G_poset_greece, pos = pos_hierarchy, with_labels = True,
- labels = labels_greece, node_size = 1200, node_color = ‘white’,
- edge_color = ‘black’, font_size = 12, font_weight = ‘bold’,
- linewidths = 1.5, edgecolors = ‘black’)
- plt.title(“Hasse Diagram: Moody’s Credit Rating Hierarchy for Greece (2004–2024)”, fontsize = 13)
- plt.axis(‘off’)
- plt.tight_layout()
- plt.show()
Appendix A.4. Python Script “Credit Rating Transition Graph”
- import networkx as nx
- import matplotlib.pyplot as plt
- from collections import Counter
- # Create transitions from consecutive days
- transitions = list(zip(df[‘Rating_Int’][:−1], df[‘Rating_Int’][1:]))
- # Count transition frequencies
- transition_counts = Counter(transitions)
- # Create a directed graph
- G = nx.DiGraph()
- for (src, dst), weight in transition_counts.items():
- if src != dst: # Exclude self-transitions for clarity
- G.add_edge(src, dst, weight = weight)
- # Set node labels from rating integers back to rating names
- int_to_rating = {v: k for k, v in rating_to_int.items()}
- labels = {node: int_to_rating[node] for node in G.nodes()}
- # Draw the graph
- plt.figure(figsize = (12, 8))
- pos = nx.spring_layout(G, seed = 42)
- nx.draw(G, pos, with_labels = True, labels = labels, node_size = 1000, node_color = ‘lightblue’, font_size = 10, arrows = True)
- edge_labels = nx.get_edge_attributes(G, ‘weight’)
- nx.draw_networkx_edge_labels(G, pos, edge_labels = edge_labels)
- plt.title(“Moody’s Credit Rating Transition Graph (2004–2024)”)
- plt.tight_layout()
- plt.show()
- # Display the current column names to debug the issue
- df.columns
- # Re-map rating scale to integer again in case it wasn’t saved
- df[‘Rating_Int’] = df[‘Rating_Scale’].map(rating_to_int)
- # Re-run the transition graph code
- transitions = list(zip(df[‘Rating_Int’][:−1], df[‘Rating_Int’][1:]))
- transition_counts = Counter(transitions)
- G = nx.DiGraph()
- for (src, dst), weight in transition_counts.items():
- if src != dst:
- G.add_edge(src, dst, weight = weight)
- int_to_rating = {v: k for k, v in rating_to_int.items()}
- labels = {node: int_to_rating[node] for node in G.nodes()}
- plt.figure(figsize = (12, 8))
- pos = nx.spring_layout(G, seed = 42)
- nx.draw(G, pos, with_labels = True, labels = labels, node_size = 1000, node_color = ‘lightblue’, font_size = 10, arrows = True)
- edge_labels = nx.get_edge_attributes(G, ‘weight’)
- nx.draw_networkx_edge_labels(G, pos, edge_labels = edge_labels)
- plt.title(“Moody’s Credit Rating Transition Graph (2004–2024)”)
- plt.tight_layout()
- plt.show()
- # Redefine the mapping since the environment reset
- rating_order = [
- “Aaa”, “Aa1”, “Aa2”, “Aa3”, “A1”, “A2”, “A3”, “Baa1”, “Baa2”, “Baa3”,
- “Ba1”, “Ba2”, “Ba3”, “B1”, “B2”, “B3”, “Caa1”, “Caa2”, “Caa3”, “Ca”, “C”
- ]
- rating_to_int = {rating: i + 1 for i, rating in enumerate(rating_order)}
- # Apply the mapping again
- df[‘Rating_Int’] = df[‘Rating_Scale’].map(rating_to_int)
- # Build the transition graph
- transitions = list(zip(df[‘Rating_Int’][:−1], df[‘Rating_Int’][1:]))
- transition_counts = Counter(transitions)
- G = nx.DiGraph()
- for (src, dst), weight in transition_counts.items():
- if src != dst:
- G.add_edge(src, dst, weight = weight)
- int_to_rating = {v: k for k, v in rating_to_int.items()}
- labels = {node: int_to_rating[node] for node in G.nodes()}
- # Plot the graph
- plt.figure(figsize = (12, 8))
- pos = nx.spring_layout(G, seed = 42)
- nx.draw(G, pos, with_labels = True, labels = labels, node_size = 1000, node_color = ‘lightblue’, font_size = 10, arrows = True)
- edge_labels = nx.get_edge_attributes(G, ‘weight’)
- nx.draw_networkx_edge_labels(G, pos, edge_labels = edge_labels)
- plt.title(“Moody’s Credit Rating Transition Graph (2004–2024)”)
- plt.tight_layout()
- plt.show()
Appendix A.5. Python Script “Rolling Correlation Analysis”
- # Compute rolling Pearson correlation between Rating_Int and ASE_Index
- window_size = 90
- # Calculate rolling means
- rating_roll = df[‘Rating_Int’].rolling(window = window_size)
- ase_roll = df[‘ASE_Index’].rolling(window = window_size)
- # Calculate rolling correlation
- rolling_corr = rating_roll.corr(ase_roll)
- # Attach to dataframe for plotting
- df[‘Rolling_Corr’] = rolling_corr
- # Plot the correlation over time
- plt.figure(figsize = (14, 6))
- plt.plot(df[‘Date’], df[‘Rolling_Corr’], label = ‘Rolling 90-Day Pearson Correlation’)
- plt.axhline(0, color = ‘gray’, linestyle = ‘--’)
- plt.title(“Rolling 90-Day Correlation between Moody’s Rating and ASE Index”)
- plt.xlabel(“Date”)
- plt.ylabel(“Correlation Coefficient”)
- plt.legend()
- plt.grid(True)
- plt.tight_layout()
- plt.show()
- # Compute rolling correlation using explicit loop as workaround
- rolling_corr_values = []
- for i in range(window_size, len(df)):
- window_df = df.iloc[i-window_size:i]
- corr = window_df[‘Rating_Int’].corr(window_df[‘ASE_Index’])
- rolling_corr_values.append(corr)
- # Fill with NaN at the start to match original DataFrame length
- df[‘Rolling_Corr’] = [np.nan]*window_size + rolling_corr_values
- # Plot the correlation over time
- plt.figure(figsize = (14, 6))
- plt.plot(df[‘Date’], df[‘Rolling_Corr’], label = ‘Rolling 90-Day Pearson Correlation’, color = ‘blue’)
- plt.axhline(0, color = ‘gray’, linestyle = ‘--’)
- plt.title(“Rolling 90-Day Correlation between Moody’s Rating and ASE Index”)
- plt.xlabel(“Date”)
- plt.ylabel(“Correlation Coefficient”)
- plt.legend()
- plt.grid(True)
- plt.tight_layout()
- plt.show()
- # Re-import numpy
- import numpy as np
- # Re-run correlation analysis
- rolling_corr_values = []
- for i in range(window_size, len(df)):
- window_df = df.iloc[i-window_size:i]
- corr = window_df[‘Rating_Int’].corr(window_df[‘ASE_Index’])
- rolling_corr_values.append(corr)
- df[‘Rolling_Corr’] = [np.nan]*window_size + rolling_corr_values
- # Plot the result
- plt.figure(figsize = (14, 6))
- plt.plot(df[‘Date’], df[‘Rolling_Corr’], label = ‘Rolling 90-Day Pearson Correlation’, color = ‘blue’)
- plt.axhline(0, color = ‘gray’, linestyle = ‘--’)
- plt.title(“Rolling 90-Day Correlation between Moody’s Rating and ASE Index”)
- plt.xlabel(“Date”)
- plt.ylabel(“Correlation Coefficient”)
- plt.legend()
- plt.grid(True)
- plt.tight_layout()
- plt.show()
Appendix A.6. Python Script “Granger Causality Tests”
- from statsmodels.tsa.stattools import grangercausalitytests
- # Prepare the dataset for Granger causality
- # Drop NA values and keep only relevant columns
- granger_df = df[[‘Rating_Int’, ‘ASE_Index’]].dropna()
- # Run Granger causality test for lags up to 10
- max_lag = 10
- granger_result = grangercausalitytests(granger_df, maxlag = max_lag, verbose = True)
Appendix A.7. Python Script “Granger Causality Tests (Reverse)”
- # Reverse the direction: test if ASE Index Granger-causes Rating_Int
- reversed_df = granger_df[[‘ASE_Index’, ‘Rating_Int’]] # switch column order
- # Run Granger causality test
- reversed_granger_result = grangercausalitytests(reversed_df, maxlag = max_lag, verbose = True)
Appendix A.8. Python Script “Event Study of Rating Shocks”
- # Identify rating change events
- rating_changes = df[df[‘Rating_Int’].diff() != 0].copy()
- rating_changes[‘Prev_Rating_Int’] = df[‘Rating_Int’].shift(1)
- rating_changes.dropna(inplace = True)
- # Select large rating change events (e.g., change >= 2 levels)
- rating_changes[‘Change_Magnitude’] = (rating_changes[‘Rating_Int’] - rating_changes[‘Prev_Rating_Int’]).abs()
- major_events = rating_changes[rating_changes[‘Change_Magnitude’] >= 2]
- # Set event window (e.g., ±5 days around the event)
- window = 5
- event_windows = []
- # Collect ASE Index values around each major event
- for _, row in major_events.iterrows():
- event_date = row[‘Date’]
- window_df = df[(df[‘Date’] >= event_date - pd.Timedelta(days = window*2)) &
- (df[‘Date’] <= event_date + pd.Timedelta(days = window*2))].copy()
- window_df = window_df.reset_index(drop = True)
- event_windows.append(window_df)
- # Compute average ASE Index movement relative to event day (t = 0)
- # Align all windows by relative time
- relative_index_changes = []
- for window_df in event_windows:
- event_day_index = window_df[‘ASE_Index’][window//2] # middle day is event
- changes = (window_df[‘ASE_Index’] - event_day_index)/event_day_index * 100
- relative_index_changes.append(changes.values)
- # Compute average across events
- average_effect = np.nanmean(relative_index_changes, axis = 0)
- time_axis = np.arange(-window*2, window*2 + 1)
- # Plot event study results
- plt.figure(figsize = (10, 5))
- plt.plot(time_axis, average_effect, marker = ‘o’)
- plt.axvline(0, color = ‘red’, linestyle = ‘--’, label = ‘Rating Change Day’)
- plt.title(“Event Study: ASE Index Response to Major Moody’s Rating Changes”)
- plt.xlabel(“Days from Rating Change”)
- plt.ylabel(“Average % Change in ASE Index”)
- plt.grid(True)
- plt.legend()
- plt.tight_layout()
- plt.show()
- # Check lengths of time axis and average effect for alignment
- len(time_axis), len(average_effect)
- # Fix time axis to match average_effect
- adjusted_time_axis = np.linspace(-window, window, len(average_effect))
- # Plot again with corrected axis
- plt.figure(figsize = (10, 5))
- plt.plot(adjusted_time_axis, average_effect, marker = ‘o’)
- plt.axvline(0, color = ‘red’, linestyle = ‘--’, label = ‘Rating Change Day’)
- plt.title(“Event Study: ASE Index Response to Major Moody’s Rating Changes”)
- plt.xlabel(“Days from Rating Change”)
- plt.ylabel(“Average % Change in ASE Index”)
- plt.grid(True)
- plt.legend()
- plt.tight_layout()
- plt.show()
Appendix A.9. Python Script “Reward Matrix Construction”
- # Inspect reward matrix to see which transitions have valid (non-NaN) rewards
- non_empty_transitions = reward_matrix.stack().index.tolist()
- nodes_in_graph = set(i for i, j in non_empty_transitions).union(j for i, j in non_empty_transitions)
- # Create graph again only with valid transitions
- G_reward = nx.DiGraph()
- for i, j in non_empty_transitions:
- reward = reward_matrix.loc[i, j]
- cost = -reward
- G_reward.add_edge(i, j, weight = cost)
Appendix A.10. Python Script Optimal Rating Downgrade Path (A1 to Ba1)
- # Attempt shortest path from A1 (5) to Ba1 (11)
- start_node = 5 # A1
- end_node = 11 # Ba1
- if start_node in G_reward and end_node in G_reward:
- try:
- shortest_path = nx.dijkstra_path(G_reward, source = start_node, target = end_node, weight = ‘weight’)
- path_labels = [int_to_rating[r] for r in shortest_path]
- total_reward = -sum(G_reward[u][v][‘weight’] for u, v in zip(shortest_path[:−1], shortest_path [1:]))
- print(“Optimal Rating Downgrade Path (A1 to Ba1):”)
- print(“ -> “.join(path_labels))
- print(f”Total Expected ASE Index Gain (Loss): {total_reward:.2f}”)
- except nx.NetworkXNoPath:
- print(“No downgrade path found from A1 to Ba1 based on available transitions.”)
- else:
- print(“Start or end rating not in graph due to missing data.”)
- # Print all available nodes (ratings) in the reward graph for reference
- available_ratings = [int_to_rating[n] for n in G_reward.nodes]
- available_ratings.sort(key = lambda r: rating_to_int[r]) # sort by credit quality
- available_ratings
- # Recalculate the reward matrix correctly by accumulating lists first
- # Initialize structure to collect ASE changes per transition
- reward_data = {(i, j): [] for i in range(1, 22) for j in range(1, 22)}
- # Populate reward data with actual ASE changes
- for i in range(1, len(df)):
- prev_rating = df.loc[i − 1, ‘Rating_Int’]
- curr_rating = df.loc[i, ‘Rating_Int’]
- if prev_rating != curr_rating:
- ase_change = df.loc[i, ‘ASE_Index’] - df.loc[i-1, ‘ASE_Index’]
- reward_data[(prev_rating, curr_rating)].append(ase_change)
- # Compute average reward matrix
- reward_matrix = pd.DataFrame(index = range(1, 22), columns = range(1, 22), dtype = float)
- for (i, j), changes in reward_data.items():
- if changes:
- reward_matrix.loc[i, j] = np.mean(changes)
- # Build graph from non-empty entries
- G_reward = nx.DiGraph()
- for (i, j), changes in reward_data.items():
- if changes:
- avg_reward = np.mean(changes)
- G_reward.add_edge(i, j, weight = -avg_reward) # negate for shortest path
- # Retry A1 (5) to Ba1 (11)
- start_node = 5
- end_node = 11
- if start_node in G_reward and end_node in G_reward:
- try:
- shortest_path = nx.dijkstra_path(G_reward, source = start_node, target = end_node, weight = ‘weight’)
- path_labels = [int_to_rating[r] for r in shortest_path]
- total_reward = -sum(G_reward[u][v][‘weight’] for u, v in zip(shortest_path[:-1], shortest_path [1:]))
- print(“Optimal Rating Downgrade Path (A1 to Ba1):”)
- print(“ -> “.join(path_labels))
- print(f”Total Expected ASE Index Gain (Loss): {total_reward:.2f}”)
- except nx.NetworkXNoPath:
- print(“No downgrade path found from A1 to Ba1 based on available transitions.”)
- else:
- print(“Start or end rating not in graph due to missing data.”)
Appendix A.11. Python Script Optimal Rating Upgrade Path (C to Ba1)
- # Define new start and end nodes: From C (21) to Ba1 (11)
- start_node = 21 # C
- end_node = 11 # Ba1
- if start_node in G_reward and end_node in G_reward:
- try:
- shortest_path = nx.dijkstra_path(G_reward, source = start_node, target = end_node, weight = ‘weight’)
- path_labels = [int_to_rating[r] for r in shortest_path]
- total_reward = -sum(G_reward[u][v][‘weight’] for u, v in zip(shortest_path[:-1], shortest_path [1:]))
- print(“Optimal Rating Upgrade Path (C to Ba1):”)
- print(“ -> “.join(path_labels))
- print(f”Total Expected ASE Index Gain: {total_reward:.2f}”)
- except nx.NetworkXNoPath:
- print(“No upgrade path found from C to Ba1 based on available transitions.”)
- else:
- print(“Start or end rating not in graph due to missing data.”)
Appendix A.12. Python Script “Optimal Rating Path Optimization (All Reachable Paths)”
- # Collect all reachable upgrade paths and their expected ASE Index gains
- results = []
- for start in G_reward.nodes:
- for end in G_reward.nodes:
- if start != end:
- try:
- path = nx.dijkstra_path(G_reward, source = start, target = end, weight = ‘weight’)
- total_reward = -sum(G_reward[u][v][‘weight’] for u, v in zip(path[:-1], path [1:]))
- path_labels = “ -> “.join(int_to_rating[r] for r in path)
- results.append({
- “From”: int_to_rating[start],
- “To”: int_to_rating[end],
- “Path”: path_labels,
- “Expected ASE Index Gain”: round(total_reward, 2)
- })
- except nx.NetworkXNoPath:
- continue
- # Convert to DataFrame and display
- paths_df = pd.DataFrame(results)
- import ace_tools as tools; tools.display_dataframe_to_user(name = “All Reachable Rating Paths”, dataframe = paths_df)
References
- Griffith, D.A. Some comments about zero and non-zero eigenvalues from connected undirected planar graph adjacency matrices. AppliedMath 2023, 3, 771–798. [Google Scholar] [CrossRef]
- Dutta, A.; Kumar, S.; Munjal, D.; Kumar, P.K. The Search-o-Sort Theory. AppliedMath 2025, 5, 64. [Google Scholar] [CrossRef]
- Cerný, A. Mathematical Techniques in Finance: Tools for Incomplete Markets; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar] [CrossRef]
- Sandfeld, S. Combinatorics and probabilities. In Materials Data Science: Introduction to Data Mining, Machine Learning, and Data-Driven Predictions for Materials Science and Engineering; Springer International Publishing: Cham, Switzerland, 2023; pp. 69–102. [Google Scholar] [CrossRef]
- Caldarelli, G.; Battiston, S.; Garlaschelli, D.; Catanzaro, M. Emergence of complexity in financial networks. Complex Netw. 2004, 1, 399–423. [Google Scholar] [CrossRef]
- Battiston, S.; Puliga, M.; Kaushik, R.; Tasca, P.; Caldarelli, G. Debtrank: Too central to fail? Financial networks, the Fed and systemic risk. Sci. Rep. 2012, 2, 541. [Google Scholar] [CrossRef] [PubMed]
- Hajizadeh, E.; Mahootchi, M. Optimized radial basis function neural network for improving approximate dynamic programming in pricing high dimensional options. Neural Comput. Appl. 2018, 30, 1783–1794. [Google Scholar] [CrossRef]
- Brandão, L.E.; Dyer, J.S.; Hahn, W.J. Using binomial decision trees to solve real-option valuation problems. Decis. Anal. 2005, 2, 69–88. [Google Scholar] [CrossRef]
- Li, Y.; Gu, C.; Dullien, T.; Vinyals, O.; Kohli, P. Graph matching networks for learning the similarity of graph structured objects. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 3835–3845. Available online: https://proceedings.mlr.press/v97/li19d/li19d.pdf (accessed on 6 June 2025).
- Lando, D. Credit risk modeling. In Handbook of Financial Time Series; Andersen, T.G., Davis, R.A., Kreiss, J.-P., Mikosch, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 787–798. [Google Scholar] [CrossRef]
- Xu, J.; Wickramarathne, T.L.; Chawla, N.V. Representing higher-order dependencies in networks. Sci. Adv. 2016, 2, e1600028. [Google Scholar] [CrossRef] [PubMed]
- Trotter, W.T. Combinatorics and Partially Ordered Sets; Johns Hopkins University Press: Baltimore, MD, USA, 1992. [Google Scholar]
- Avery, J.E.; Moyen, J.Y.; Růžička, P.; Simonsen, J.G. Chains, antichains, and complements in infinite partition lattices. Algebra Univ. 2018, 79, 37. [Google Scholar] [CrossRef]
- Yue, L.; Lv, Y. VIKOR optimization decision model based on poset. J. Intell. Fuzzy Syst. 2025, 48, 673–689. [Google Scholar] [CrossRef]
- White, L.J. The credit rating industry: An industrial organization analysis. In Ratings, Rating Agencies and the Global Financial System; Levich, R.M., Majnoni, G., Reinhart, C.M., Eds.; Springer: Boston, MA, USA, 2002; pp. 41–63. [Google Scholar] [CrossRef]
- Gonzalez, F.; Haas, F.; Johannes, R.; Persson, M.; Toledo, L.; Violi, R.; Zins, C. Market Dynamics Associated with Credit Ratings—A Literature Review; European Central Bank: Frankfurt, Germany, 2004; Available online: https://www.econstor.eu/bitstream/10419/154469/1/ecbop016.pdf (accessed on 6 June 2025).
- Alogoskoufis, G. Greece’s Sovereign Debt Crisis: Retrospect and Prospect; LSE Hellenic Observatory: London, UK, 2012; Available online: https://eprints.lse.ac.uk/42848/1/GreeSE%20No54.pdf (accessed on 6 June 2025).
- Moody’s Investors Service. Sovereign Bond Ratings. Moody’s Ratings Methodology. Available online: https://www.moodys.com/researchdocumentcontentpage.aspx?docid=PBC_151479 (accessed on 6 June 2025).
- Bratis, T.; Kouretas, G.P.; Laopodis, N.T.; Vlamis, P. Sovereign credit and geopolitical risks during and after the EMU crisis. Int. J. Financ. Econ. 2024, 29, 3692–3712. [Google Scholar] [CrossRef]
- Lee Rodgers, J.; Nicewander, W.A. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Kaminsky, G.; Schmukler, S.L. Emerging market instability: Do sovereign ratings affect country risk and stock returns? World Bank Econ. Rev. 2002, 16, 171–195. [Google Scholar] [CrossRef]
- Afonso, A.; Furceri, D.; Gomes, P. Sovereign credit ratings and financial markets linkages: Application to European data. J. Int. Money Financ. 2012, 31, 606–638. [Google Scholar] [CrossRef]
- Hill, P.; Faff, R. The market impact of relative agency activity in the sovereign ratings market. J. Bus. Financ. Account. 2010, 37, 1309–1347. [Google Scholar] [CrossRef]
- Gande, A.; Parsley, D.C. News spillovers in the sovereign debt market. J. Financ. Econ. 2005, 75, 691–734. [Google Scholar] [CrossRef]
- Ferreira, M.A.; Gama, P.M. Does sovereign debt ratings news spill over to international stock markets? J. Bank. Financ. 2007, 31, 3162–3182. [Google Scholar] [CrossRef]
- Cantor, R.; Packer, F. Determinants and impact of sovereign credit ratings. Econ. Policy Rev. 1996, 2, 37–53. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Rating | Meaning |
|---|---|---|
| 1 | Aaa | Highest quality, minimal credit risk |
| 2 | Aa1 | High quality, very low credit risk (upper end of Aa) |
| 3 | Aa2 | High quality, very low credit risk (mid-range of Aa) |
| 4 | Aa3 | High quality, very low credit risk (lower end of Aa) |
| 5 | A1 | Upper-medium grade, low credit risk (upper end of A) |
| 6 | A2 | Upper-medium grade, low credit risk (mid-range of A) |
| 7 | A3 | Upper-medium grade, low credit risk (lower end of A) |
| 8 | Baa1 | Medium grade, moderate credit risk (upper end of Baa)—lowest investment grade |
| 9 | Baa2 | Medium grade, moderate credit risk (mid-range of Baa) |
| 10 | Baa3 | Medium grade, moderate credit risk (lower end of Baa)—borderline investment grade |
| 11 | Ba1 | Speculative, substantial credit risk (upper end of Ba) |
| 12 | Ba2 | Speculative, substantial credit risk (mid-range of Ba) |
| 13 | Ba3 | Speculative, substantial credit risk (lower end of Ba) |
| 14 | B1 | Highly speculative, high credit risk (upper end of B) |
| 15 | B2 | Highly speculative, high credit risk (mid-range of B) |
| 16 | B3 | Highly speculative, high credit risk (lower end of B) |
| 17 | Caa1 | Poor standing, very high credit risk (upper end of Caa) |
| 18 | Caa2 | Poor standing, very high credit risk (mid-range of Caa) |
| 19 | Caa3 | Poor standing, very high credit risk (lower end of Caa) |
| 20 | Ca | Highly speculative, likely in or near default |
| 21 | C | Lowest rating, typically in default with little prospect for recovery |
| Date | Rating | Outlook |
|---|---|---|
| 4 November 2002 | A1 | Stable |
| 25 February 2009 | A1 | Stable |
| 29 October 2009 | A1 | Negative Watch |
| 22 December 2009 | A2 | Negative |
| 22 April 2010 | A3 | Negative |
| 14 June 2010 | Ba1 | Stable |
| 16 December 2010 | Ba1 | Negative Watch |
| 7 March 2011 | B1 | Negative Watch |
| 1 June 2011 | Caa1 | Negative |
| 25 July 2011 | Ca | Negative |
| 2 March 2012 | C | Negative |
| 29 November 2013 | Caa3 | Stable |
| 1 August 2014 | Caa1 | Stable |
| 6 November 2020 | Ba3 | Stable |
| 17 March 2023 | Ba3 | Positive |
| 15 September 2023 | Ba1 | Stable |
| 14 September 2024 | Ba1 | Positive |
| Direction: Moody’s Rating → ASE Index | Direction: ASE Index → Moody’s Rating | ||||
|---|---|---|---|---|---|
| Lag | F-Statistic | p-Value | Lag | F-Statistic | p-Value |
| 1 | 1.5785 | 0.2090 | 1 | 1.2617 | 0.2614 |
| 2 | 2.1484 | 0.1168 | 2 | 2.3130 | 0.0991 |
| 3 | 1.4660 | 0.2217 | 3 | 1.8638 | 0.1334 |
| 4 | 1.1412 | 0.3351 | 4 | 1.4015 | 0.2307 |
| 5 | 0.9182 | 0.4679 | 5 | 1.5578 | 0.1685 |
| 6 | 1.4510 | 0.1911 | 6 | 1.2980 | 0.2543 |
| 7 | 1.3839 | 0.2073 | 7 | 1.3286 | 0.2321 |
| 8 | 1.2392 | 0.2714 | 8 | 1.3690 | 0.2047 |
| 9 | 1.1370 | 0.3322 | 9 | 1.5315 | 0.1306 |
| 10 | 1.0724 | 0.3796 | 10 | 1.3685 | 0.1882 |
| From | To | Path | Expected ASE Index Gain/Loss |
|---|---|---|---|
| A1 | A2 | A1 → A2 | 94.87 |
| A1 | A3 | A1 → A2 → A3 | 19.2 |
| A1 | Ba1 | A1 → A2 → A3 → Ba1 | 75.76 |
| A1 | B1 | A1 → A2 → A3 → Ba1 → B1 | 15.41 |
| A1 | Ba3 | A1 → A2 → A3 → Ba1 → B1 → Caa1 → Ba3 | −6.12 |
| A1 | Caa1 | A1 → A2 → A3 → Ba1 → B1 → Caa1 | −4.06 |
| A1 | Ca | A1 → A2 → A3 → Ba1 → B1 → Caa1 → Ca | −21.17 |
| A1 | Caa3 | A1 → A2 → A3 → Ba1 → B1 → Caa1 → Ca → C → Caa3 | −4.79 |
| A1 | C | A1 → A2 → A3 → Ba1 → B1 → Caa1 → Ca → C | −19.7 |
| A2 | A3 | A2 → A3 | −75.67 |
| A2 | Ba1 | A2 → A3 → Ba1 | −19.11 |
| A2 | B1 | A2 → A3 → Ba1 → B1 | −79.46 |
| A2 | Ba3 | A2 → A3 → Ba1 → B1 → Caa1 → Ba3 | −100.99 |
| A2 | Caa1 | A2 → A3 → Ba1 → B1 → Caa1 | −98.93 |
| A2 | Ca | A2 → A3 → Ba1 → B1 → Caa1 → Ca | −116.04 |
| A2 | Caa3 | A2 → A3 → Ba1 → B1 → Caa1 → Ca → C → Caa3 | −99.66 |
| A2 | C | A2 → A3 → Ba1 → B1 → Caa1 → Ca → C | −114.57 |
| A3 | Ba1 | A3 → Ba1 | 56.56 |
| A3 | B1 | A3 → Ba1 → B1 | −3.79 |
| A3 | Ba3 | A3 → Ba1 → B1 → Caa1 → Ba3 | −25.32 |
| A3 | Caa1 | A3 → Ba1 → B1 → Caa1 | −23.26 |
| A3 | Ca | A3 → Ba1 → B1 → Caa1 → Ca | −40.37 |
| A3 | Caa3 | A3 → Ba1 → B1 → Caa1 → Ca → C → Caa3 | −23.99 |
| A3 | C | A3 → Ba1 → B1 → Caa1 → Ca → C | −38.9 |
| Ba1 | B1 | Ba1 → B1 | −60.35 |
| Ba1 | Ba3 | Ba1 → B1 → Caa1 → Ba3 | −81.88 |
| Ba1 | Caa1 | Ba1 → B1 → Caa1 | −79.82 |
| Ba1 | Ca | Ba1 → B1 → Caa1 → Ca | −96.93 |
| Ba1 | Caa3 | Ba1 → B1 → Caa1 → Ca → C → Caa3 | −80.55 |
| Ba1 | C | Ba1 → B1 → Caa1 → Ca → C | −95.46 |
| B1 | Ba1 | B1 → Caa1 → Ba3 → Ba1 | 3.24 |
| B1 | Ba3 | B1 → Caa1 → Ba3 | −21.53 |
| B1 | Caa1 | B1 → Caa1 | −19.47 |
| B1 | Ca | B1 → Caa1 → Ca | −36.58 |
| B1 | Caa3 | B1 → Caa1 → Ca → C → Caa3 | −20.2 |
| B1 | C | B1 → Caa1 → Ca → C | −35.11 |
| Ba3 | Ba1 | Ba3 → Ba1 | 24.77 |
| Ba3 | B1 | Ba3 → Ba1 → B1 | −35.58 |
| Ba3 | Caa1 | Ba3 → Ba1 → B1 → Caa1 | −55.05 |
| Ba3 | Ca | Ba3 → Ba1 → B1 → Caa1 → Ca | −72.16 |
| Ba3 | Caa3 | Ba3 → Ba1 → B1 → Caa1 → Ca → C → Caa3 | −55.78 |
| Ba3 | C | Ba3 → Ba1 → B1 → Caa1 → Ca → C | −70.69 |
| Caa1 | Ba1 | Caa1 → Ba3 → Ba1 | 22.71 |
| Caa1 | B1 | Caa1 → Ba3 → Ba1 → B1 | −37.64 |
| Caa1 | Ba3 | Caa1 → Ba3 | −2.06 |
| Caa1 | Ca | Caa1 → Ca | −17.11 |
| Caa1 | Caa3 | Caa1 → Ca → C → Caa3 | −0.73 |
| Caa1 | C | Caa1 → Ca → C | −15.64 |
| Ca | Ba1 | Ca → C → Caa3 → Caa1 → Ba3 → Ba1 | 32.97 |
| Ca | B1 | Ca → C → Caa3 → Caa1 → Ba3 → Ba1 → B1 | −27.38 |
| Ca | Ba3 | Ca → C → Caa3 → Caa1 → Ba3 | 8.2 |
| Ca | Caa1 | Ca → C → Caa3 → Caa1 | 10.26 |
| Ca | Caa3 | Ca → C → Caa3 | 16.38 |
| Ca | C | Ca → C | 1.47 |
| Caa3 | Ba1 | Caa3 → Caa1 → Ba3 → Ba1 | 16.59 |
| Caa3 | B1 | Caa3 → Caa1 → Ba3 → Ba1 → B1 | −43.76 |
| Caa3 | Ba3 | Caa3 → Caa1 → Ba3 | −8.18 |
| Caa3 | Caa1 | Caa3 → Caa1 | −6.12 |
| Caa3 | Ca | Caa3 → Caa1 → Ca | −23.23 |
| Caa3 | C | Caa3 → Caa1 → Ca → C | −21.76 |
| C | Ba1 | C → Caa3 → Caa1 → Ba3 → Ba1 | 31.5 |
| C | B1 | C → Caa3 → Caa1 → Ba3 → Ba1 → B1 | −28.85 |
| C | Ba3 | C → Caa3 → Caa1 → Ba3 | 6.73 |
| C | Caa1 | C → Caa3 → Caa1 | 8.79 |
| C | Ca | C → Caa3 → Caa1 → Ca | −8.32 |
| C | Caa3 | C → Caa3 | 14.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Angelidis, G.; Margaris, V. Algebraic Combinatorics in Financial Data Analysis: Modeling Sovereign Credit Ratings for Greece and the Athens Stock Exchange General Index. AppliedMath 2025, 5, 90. https://doi.org/10.3390/appliedmath5030090
Angelidis G, Margaris V. Algebraic Combinatorics in Financial Data Analysis: Modeling Sovereign Credit Ratings for Greece and the Athens Stock Exchange General Index. AppliedMath. 2025; 5(3):90. https://doi.org/10.3390/appliedmath5030090
Chicago/Turabian StyleAngelidis, Georgios, and Vasilios Margaris. 2025. "Algebraic Combinatorics in Financial Data Analysis: Modeling Sovereign Credit Ratings for Greece and the Athens Stock Exchange General Index" AppliedMath 5, no. 3: 90. https://doi.org/10.3390/appliedmath5030090
APA StyleAngelidis, G., & Margaris, V. (2025). Algebraic Combinatorics in Financial Data Analysis: Modeling Sovereign Credit Ratings for Greece and the Athens Stock Exchange General Index. AppliedMath, 5(3), 90. https://doi.org/10.3390/appliedmath5030090