
The Search-o-Sort Theory



{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. General Context
1.2. Motivation
1.3. Literature Review
1.4. Contribution and Scope
1.5. Document Structure
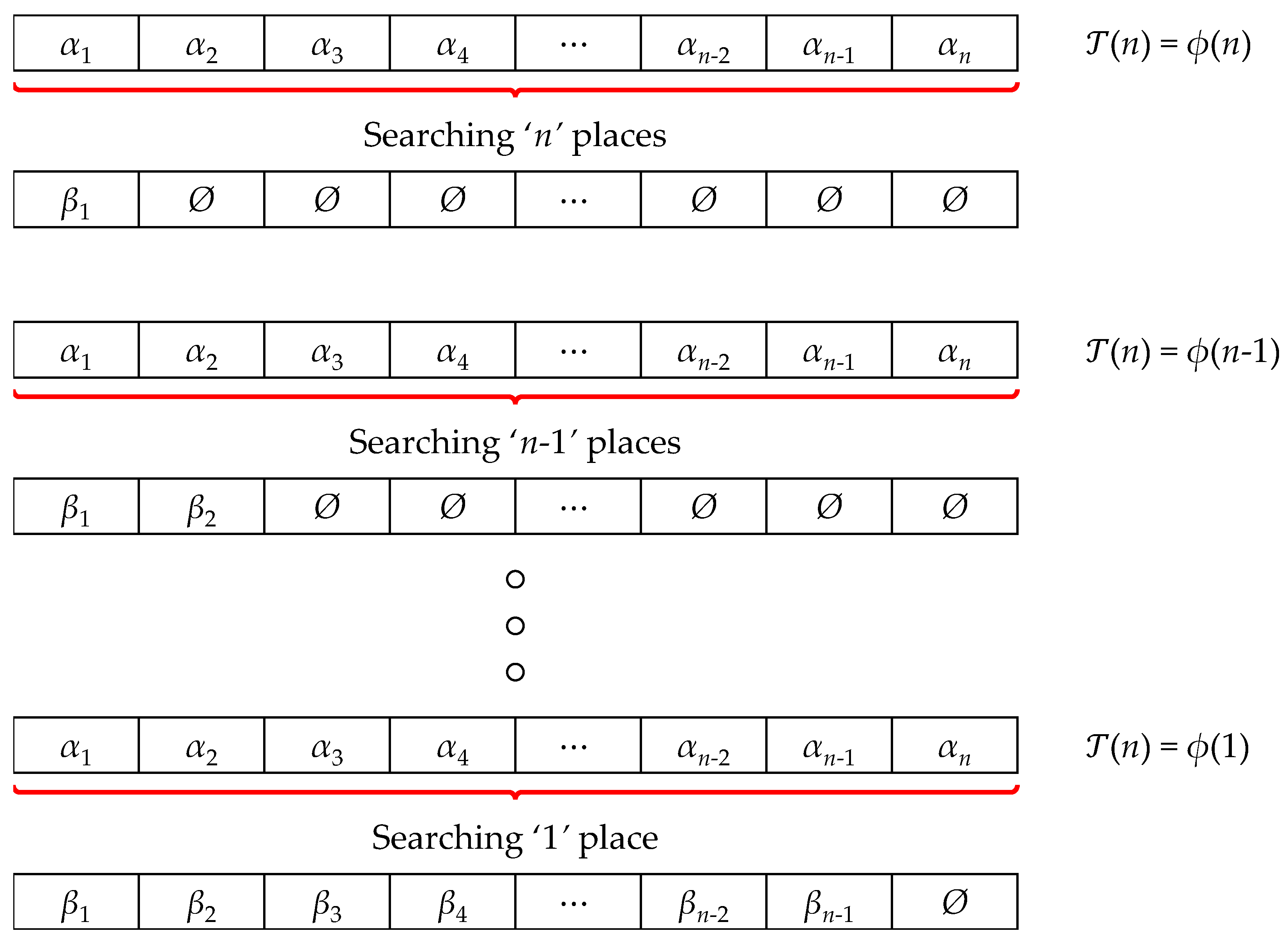
2. Search-o-Sort
2.1. The Proposition
2.2. The Realization
2.3. k-Ary Sort
| Algorithm 1 Pseudocode for the k-ary Search |
|
- The worst-case time complexity of the k-ary searching algorithm will be , which occurs if the target element is present in the indices involving bounds; that is, the starting and the ending indices.
- The best-case time complexity is , which occurs if the target element is present at any of the mid indices.
- The average-case time complexity is
2.4. Interpolation Sort
- The worst-case time complexity of the Interpolation Searching Algorithm will be , which occurs if the target element is present in the indices involving bounds; that is, the starting and the ending indices.
- The Best-Case Time Complexity is , which occurs if the target element is present at any of the mid indices.
- In the average case, both cases are considered.
- (a)
- If the key is present in the list.
- (b)
- If it is not present in the list.
| Algorithm 2 Pseudocode for the Interpolation Search |
|
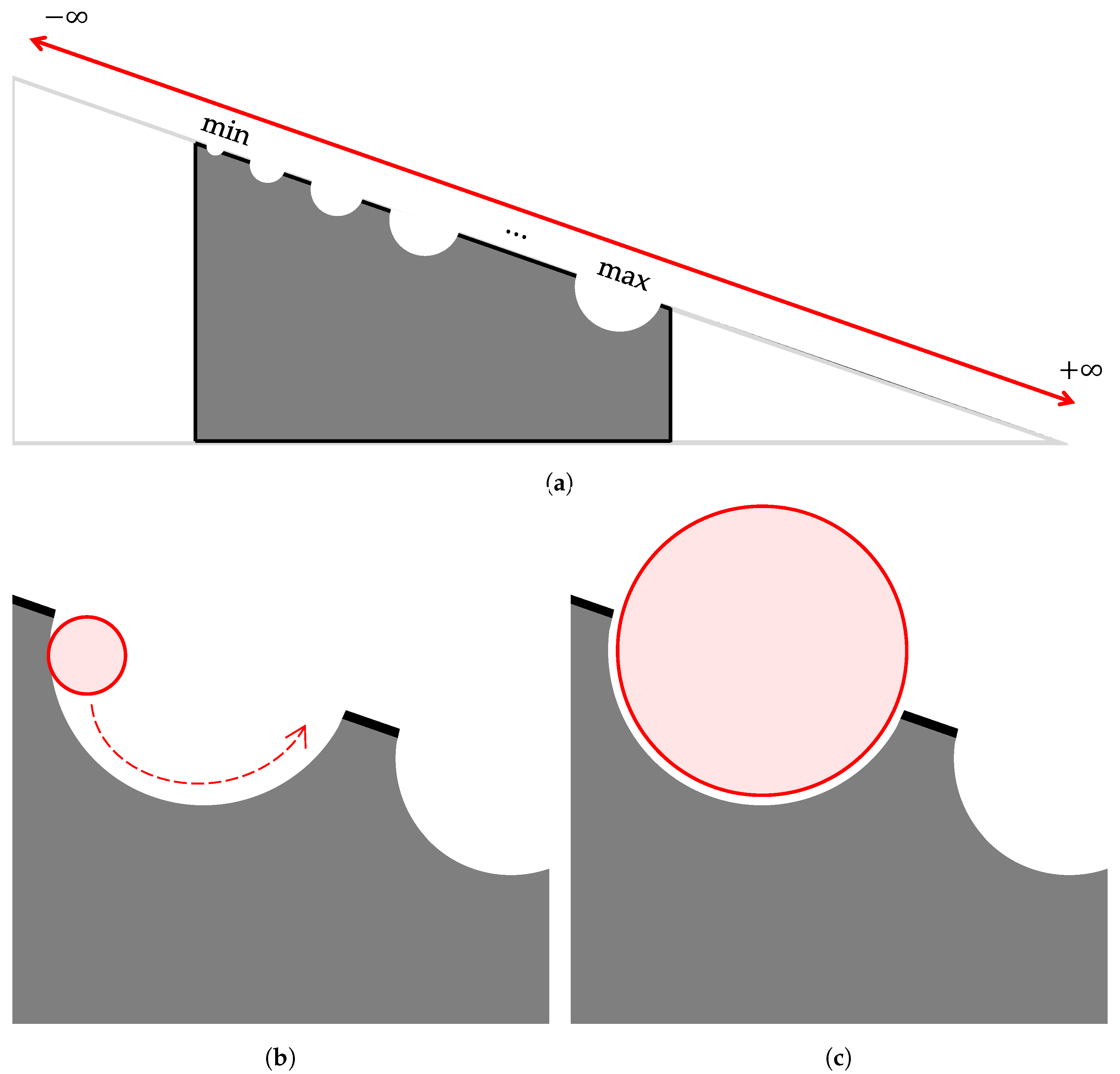
2.5. Extrapolation Sort
- The worst-case time complexity of the Extrapolation Searching Algorithm will be , which occurs if the data are highly skewed, or the extrapolated estimate repeatedly fails to converge toward the target, thus degrading to a sequential or linear-like search.
- The best-case time complexity is , which occurs if the target element lies near the extrapolated index on the first estimation and is found without any iterative refinement.
- In the average case, both conditions are considered:
- (a)
- If the key is present in the list.
- (b)
- If it is not present in the list.
| Algorithm 3 Pseudocode for the Extrapolation Search |
|
2.6. Jump Sort
| Algorithm 4 Pseudocode for the Jump Search |
|
- In the worst-case scenario, one has to complete jumps (n being the cardinality, m being the size of the block to be evicted) and if the last checked value is greater than the element to be searched for, it performs comparisons more for a linear search. Hence, on the whole, the number of comparisons in the worst case will be . So, the worst-case complexity will be .
- The best-case complexity can be obtained simply from the number of comparisons that need to be performed for supervision, . Now, . will be minimum when . With that being said, the best-case complexity becomes .
- The average-case complexity for this Searching Technique is abruptly equal to the worst-case complexity, .
3. Conclusions
- A tighter bound, if possible, could be searched for .
- An even tighter bound, if possible, could be searched for .
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Asymptotic Notations
Appendix A.1. Big Oh Notation—Upper Bound
Appendix A.2. Big Omega Notation—Lower Bound
Appendix A.3. Big Theta Notation—Tight Bound
Appendix A.4. Little Oh Notation—Strict Upper Bound
Appendix A.5. Little Omega Notation—Strict Lower Bound
Appendix B. Min-Max Algorithm
- For even n (i.e., ), one comparison is needed to initialize both the min and max. In pairwise processing, since the Algorithm starts from the third element of the list, the remaining elements are processed in pairs, and since n is even, is an integer. For each of these pairs, say three comparisons are needed, one to compare a and b; one to compare the smaller of these with the min; and another to compare the larger of these with the max. In total, for an even n, total comparisons are needed.
- For an odd n (i.e., ), no comparison is needed to initialize the min and max, as they are set to the first element of the list. In pairwise processing, since the Algorithm starts from the second element of the list, the remaining elements are processed in pairs. For each of these pairs, again, three comparisons are needed. So, in total, for odd n, total comparisons are needed.
| Algorithm A1 Pseudocode for Min-Max algorithm |
|
References
- Gonnet, G.H.; Rogers, L.D.; George, J.A. An algorithmic and complexity analysis of interpolation search. Acta Inform. 1980, 13, 39–52. [Google Scholar] [CrossRef]
- Manna, Z.; Waldinger, R. The origin of a binary-search paradigm. Sci. Comput. Program. 1987, 9, 37–83. [Google Scholar] [CrossRef]
- Chadha, A.R.; Misal, R.; Mokashi, T. Modified binary search Algorithm. arXiv 2014, arXiv:1406.1677. [Google Scholar]
- Thwe, P.P.; Kyi, L.L.W. Modified binary search Algorithm for duplicate elements. Int. J. Comput. Commun. Eng. Res. (IJCCER) 2014, 2. Available online: https://www.researchgate.net/publication/326088292_Modified_Binary_Search_Algorithm_for_Duplicate_Elements (accessed on 29 March 2025).
- Wan, Y.; Wang, M.; Ye, Z.; Lai, X. A feature selection method based on modified binary coded ant colony optimization Algorithm. Appl. Soft Comput. 2016, 49, 248–258. [Google Scholar] [CrossRef]
- Bajwa, M.S.; Agarwal, A.P.; Manchanda, S. Ternary search Algorithm: Improvement of binary search. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 1723–1725. [Google Scholar]
- Dutta, A.; Ray, S.; Kumar, P.K.; Ramamoorthy, A.; Pradeep, C.; Gayen, S. A Unified Vista and Juxtaposed Study on k-ary Search Algorithms. In Proceedings of the 2024 2nd International Conference on Networking, Embedded and Wireless Systems (ICNEWS), Bangalore, India, 22–23 August 2024; pp. 1–6. [Google Scholar]
- Perl, Y.; Reingold, E.M. Understanding the complexity of interpolation search. Inf. Process. Lett. 1977, 6, 219–222. [Google Scholar] [CrossRef]
- Shneiderman, B. Jump searching: A fast sequential search technique. Commun. ACM 1978, 21, 831–834. [Google Scholar] [CrossRef]
- Batir, N. Very accurate approximations for the factorial function. J. Math. Inequal 2010, 4, 335–344. [Google Scholar] [CrossRef]
- Olkin, I.; Pratt, J.W. A multivariate Tchebycheff inequality. Ann. Math. Stat. 1958, 29, 226–234. [Google Scholar] [CrossRef]
- Gesellschaft der Wissenschaften zu Göttingen; Georg-August-Universität Göttingen Nachrichten von der Königl. Gesellschaft der Wissenschaften und der Georg-Augusts-Universität zu Göttingen: Aus dem Jahre. 1884. Available online: https://gdz.sub.uni-goettingen.de/id/PPN252457072 (accessed on 29 March 2025).
- Jensen, J.L.W.V. Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta Math. 1906, 30, 175–193. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dutta, A.; Kumar, S.; Munjal, D.; Kumar, P.K. The Search-o-Sort Theory. AppliedMath 2025, 5, 64. https://doi.org/10.3390/appliedmath5020064
Dutta A, Kumar S, Munjal D, Kumar PK. The Search-o-Sort Theory. AppliedMath. 2025; 5(2):64. https://doi.org/10.3390/appliedmath5020064
Chicago/Turabian StyleDutta, Anurag, Sanjeev Kumar, Deepkiran Munjal, and Pijush Kanti Kumar. 2025. "The Search-o-Sort Theory" AppliedMath 5, no. 2: 64. https://doi.org/10.3390/appliedmath5020064
APA StyleDutta, A., Kumar, S., Munjal, D., & Kumar, P. K. (2025). The Search-o-Sort Theory. AppliedMath, 5(2), 64. https://doi.org/10.3390/appliedmath5020064