2.1.1. Classification and Clusters for Occupancy Pattern Analysis
Occupancy behaviour was analysed using the REFIT Smart Home dataset’s appliance-level and aggregate energy consumption data. A binary occupancy label was created based on a predefined energy consumption threshold, where aggregate energy consumption exceeding 300 Watts was classified as occupied (111) and lower values as unoccupied (000). In the residential building energy consumption cases, 300 W is a reasonable benchmark to distinguish between active occupancy (e.g., cooking and heating) and background energy use like fridge and other standby loads [
41]. Further statistics analysis for Building 01 are conducted, shown in
Figure 1 and
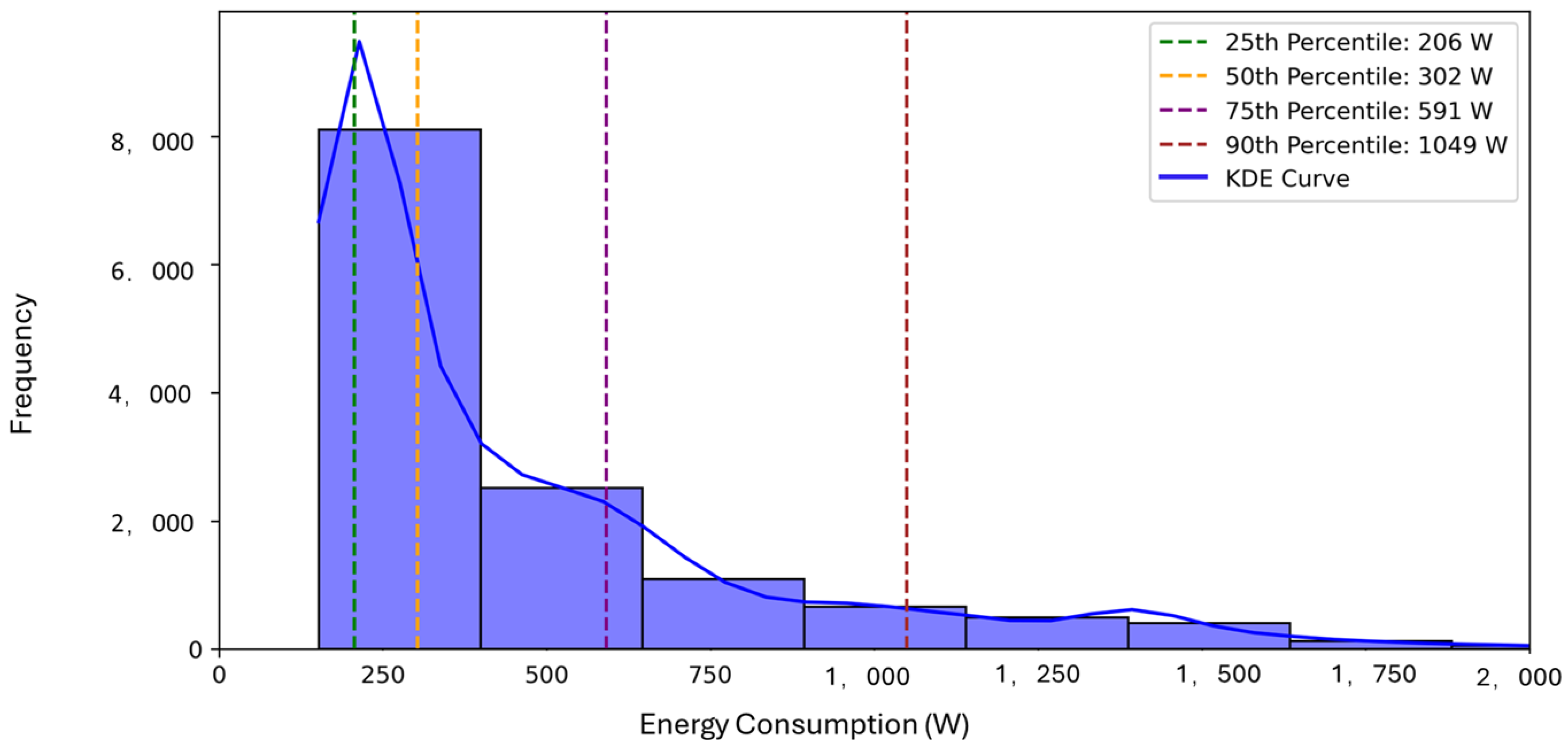
Figure 2. The blue bars in the histogram shows the frequency of different energy consumption levels. The histogram reveals a sharp peak at very low power consumption values (below 300 W), highlighting a dominant category of low-energy consumption periods. Beyond 300 W, the frequency of occurrences decreases significantly, suggesting that higher energy consumption levels are associated with different occupancy patterns or appliance usage behaviours. The Sturges method (red) and Freedman–Diaconis method (green) confirm the presence of a distinct peak in low power consumption ranges, which helps validate that 300 W falls at a natural cut-off between background energy use and higher consumption patterns. In
Figure 2 the median value (50th percentile) is 302 W, indicating that half of the recorded energy usage values are below this level. This analysis confirms that 300 W serves as a threshold, guaranteeing that low-power background loads are not misclassified as occupancy.
A Random Forest Classifier was implemented to predict occupancy. Random Forest was chosen for occupancy classification due to its robustness in handling high-dimensional, nonlinear energy usage data. It provides strong predictive accuracy while maintaining computational efficiency, making it ideal for classifying occupancy states based on appliance usage patterns. Additionally, Random Forest offers built-in feature importance ranking, allowing for deeper insights into which appliances contribute most to occupancy prediction. This interpretability is particularly valuable for energy management applications, where understanding the key drivers of occupancy is critical for optimising energy efficiency. In the random forest classifier training, two feature sets were considered: one including aggregate energy consumption and another excluding it to evaluate the predictive power of appliance-level and contextual features alone. The model was evaluated using accuracy, precision, recall, and F1-score, and 5-fold cross-validation was applied to ensure robustness. In addition, the grid search method was applied to optimise the hyperparameters, like the number of trees, maximum depth, and minimum samples per leaf.
A feature ablation study was conducted to assess the contribution of individual appliances to occupancy prediction. Each appliance feature was removed one at a time, and the resulting drop in model accuracy was recorded. This analysis quantified the predictive power of specific appliances, identifying the appliances as key contributors to occupancy classification.
To further explore occupancy behaviour, K-means clustering and Gaussian Mixture Models (GMM) were applied to appliance-level energy consumption due to their effectiveness in segmenting energy consumption behaviours. K-means provides a fast and scalable method for identifying distinct occupancy groups based on energy usage, making it well-suited for high-dimensional appliance-level data. GMM complements K-means by allowing probabilistic membership assignments, which is particularly useful for households exhibiting transitional occupancy behaviours. The combination of these two methods ensures a comprehensive clustering approach that captures both rigid and flexible occupancy patterns. Hyperparameter selection for clustering models was guided by the Elbow Method and Silhouette Score analysis. The optimal number of clusters for K-means was determined by identifying the inflection point in the within-cluster sum of squares plot, where additional clusters provided marginal improvement. For GMM, the Bayesian Information Criterion (BIC) was optimised to balance model complexity and likelihood estimation, ensuring the best probabilistic representation of occupancy states.
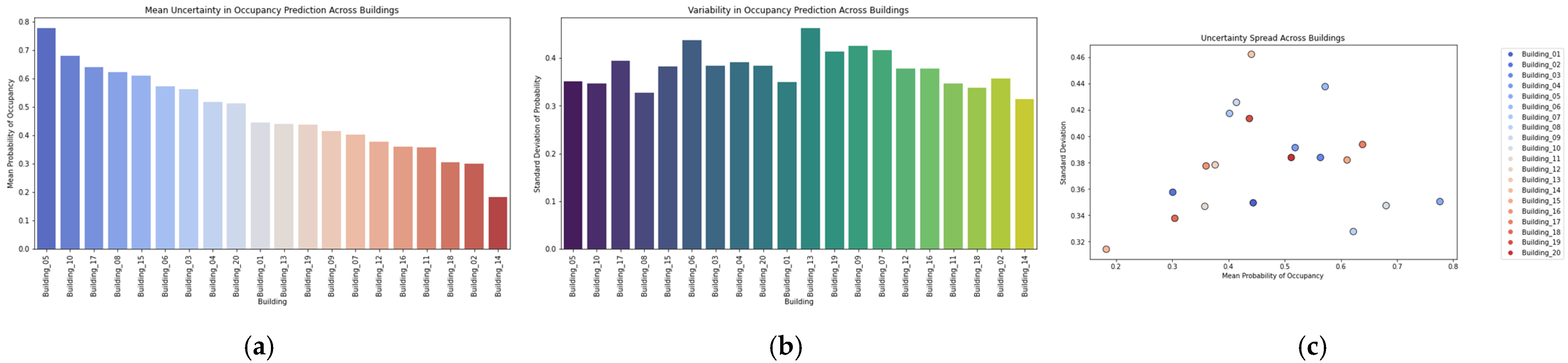
The optimal number of clusters was determined using the Elbow Method, identifying distinct patterns in household energy usage. Clustering provided additional insights into occupancy-driven appliance usage behaviours. For GMM, the Bayesian Information Criterion (BIC) was optimised to balance model complexity and likelihood estimation, ensuring the best probabilistic representation of occupancy states.
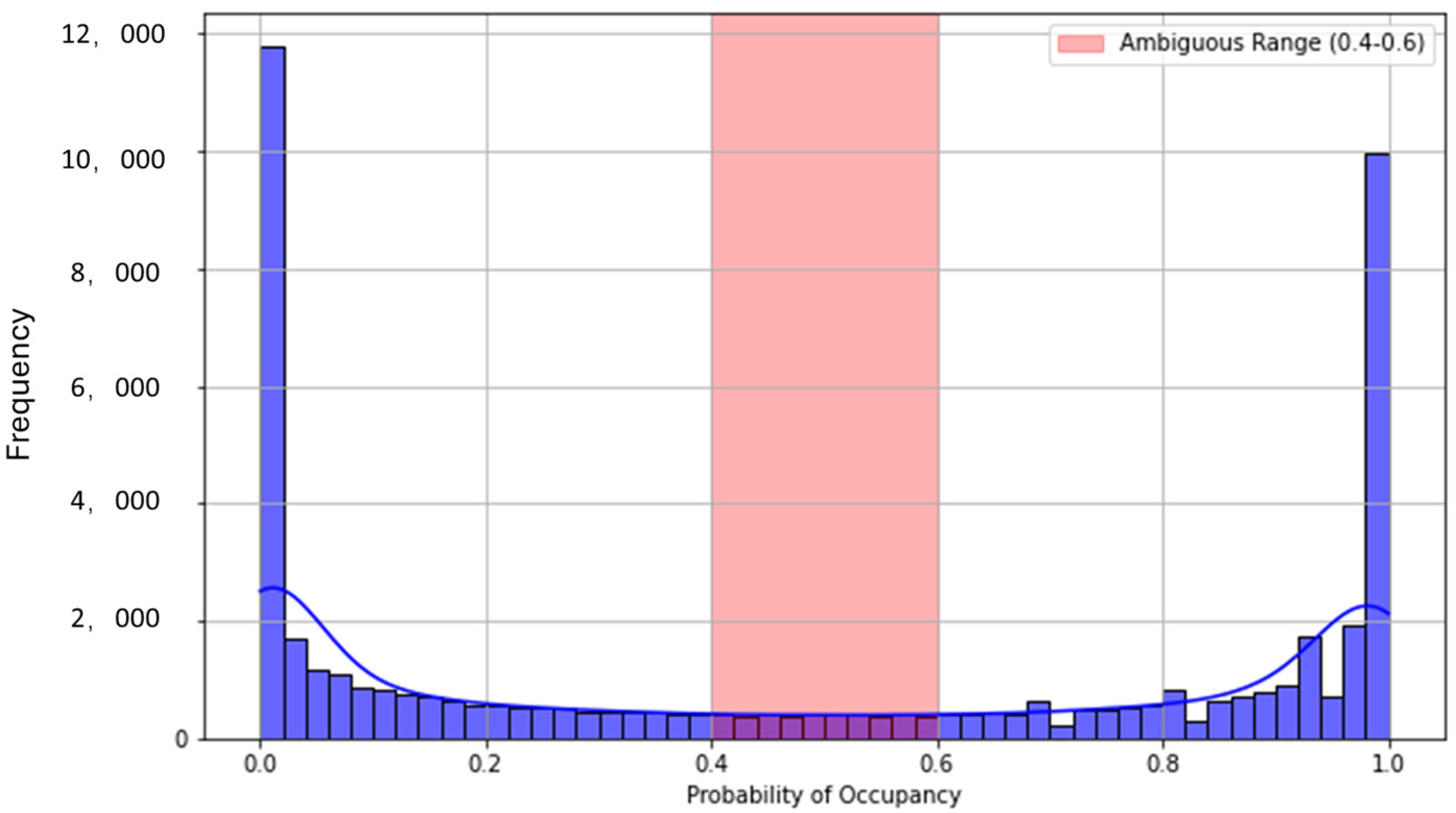
Probabilistic outputs from the classifier were analysed to quantify prediction uncertainty. Prediction probabilities between 0.4 and 0.6 were flagged as ambiguous cases, highlighting uncertain occupancy states. This uncertainty analysis informed further model refinements and decision boundary adjustments.
2.1.2. Single and Multi-Feature Time-Series Prediction
Time-series forecasting was conducted to predict aggregate energy consumption using both single and multiple features. The dataset was divided into 80% training and 20% testing, maintaining temporal continuity to prevent data leakage. Predictions were generated using various machine learning and deep learning models, ensuring a comprehensive evaluation of their performance in forecasting residential energy consumption. The selected models included LSTM, Transformer, NARMAX, SVM, ANN, XGBoost, and Random Forest. These models were chosen based on their ability to capture sequential dependencies, nonlinear relationships, and interpretability.
For single-feature prediction, models were trained using only time-related inputs, including hours of the day and day of the week, to predict aggregate energy consumption. The input data were transformed into a sequence format using a sliding window approach, where each training sample consisted of 24 consecutive hourly observations used to predict the next hour’s aggregate consumption.
A Long Short-Term Memory (LSTM) network was implemented for sequential modelling due to its proven effectiveness in capturing long-range dependencies in time-series data. The architecture consisted of two stacked LSTM layers, each with 50 units, followed by a dense output layer. Dropout regularisation with a rate of 0.2 was applied after each LSTM layer to prevent overfitting. The model was compiled using the Adam optimiser and trained with a Mean Squared Error (MSE) loss function. Hyperparameters such as the number of layers, units per layer, dropout rate, and learning rate were optimised using Bayesian optimisation with the Tree-structured Parzen Estimator (TPE), ensuring efficient tuning without excessive computational cost. Early stopping was implemented to monitor validation loss and prevent unnecessary training iterations. Predictions were de-normalised to restore the original scale of energy consumption.
A Transformer-based model was also employed as an alternative to LSTM, leveraging a self-attention mechanism to capture long-range dependencies in sequential data. Unlike recurrent networks, Transformers can dynamically assign different weights to different time steps using Multi-Head Self-Attention, improving model interpretability and efficiency. Positional encoding was introduced to provide the model with temporal awareness, and the final encoding of each time step was passed through a fully connected output layer to generate predictions. Similar to the LSTM model, the Transformer was trained using the Adam optimiser with an MSE loss function. Hyperparameters—including the number of attention heads, hidden dimensions, and feed-forward network size—were fine-tuned using Bayesian optimisation and early stopping to optimise generalisation.
NARMAX was introduced as an interpretable alternative to deep learning models. While LSTMs and Transformers provide high accuracy, they lack transparency in understanding the influence of input variables on predictions. NARMAX, in contrast, offers an explicit mathematical representation of system dynamics, making it valuable for energy managers seeking to understand causal dependencies in energy consumption. The general NARMAX model is defined as:
where
,
, and
represent the system output, input and noise,
is the general representation of some typical nonlinear model forms, like a polynomial model, neural network, and other kinds of nonlinear forms;
,
, and
are the maximum time lags for the system output, input and noise. In the NARMAX modelling, the key procedure involves applying the Forward Regression Orthogonal Least Square (FROLS) algorithm to detect the model structure and estimate the parameters. This approach ensures that only the most significant variables are retained, enhancing interpretability while maintaining predictive power. Unlike deep learning models, which often act as black boxes, NARMAX allows energy managers to identify which factors most influence consumption patterns and develop targeted efficiency strategies based on these insights.
Beyond its interpretability, NARMAX supports predictive control applications in energy management. By analysing its explicit equations, energy managers can optimise HVAC systems, lighting, and appliance scheduling based on forecasted energy demands. Moreover, regulatory compliance and reporting benefit from NARMAX’s transparency, as the model provides a structured way to demonstrate how different variables impact energy consumption. This capability is particularly valuable in settings where decision-makers require explainable and audit-friendly models for policy enforcement and sustainability reporting.
The model complexity was controlled using the Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC), ensuring an optimal balance between interpretability and predictive power.
To improve forecasting accuracy, multiple contextual features—including temperature, humidity, brightness, and climate conditions—were incorporated alongside time-series data. These additional inputs allowed models to capture environmental influences on energy consumption. Data preprocessing involved merging external feature datasets with aggregate energy consumption data based on timestamps. Mean imputation was applied to handle missing values, and all features were normalised to ensure stable training. The sliding window method was extended to include both past energy consumption and contextual variables as input sequences.
A deep learning-based multi-feature LSTM model was developed to process these inputs. The architecture followed a similar structure to the single-feature LSTM but with an expanded input space to accommodate external variables. The network consisted of two LSTM layers with 50 units each, followed by a dense output layer. The ReLU activation function was used for non-linear transformations, and dropout layers (rate = 0.2) were included to prevent overfitting. The training was conducted using the Adam optimiser, and the MSE loss function was minimised over 50 epochs with early stopping. Hyperparameter tuning, including batch size and learning rate adjustments, was conducted using a combination of grid search and Bayesian optimisation.
A Transformer model was also employed for multi-feature prediction. The input feature set was passed through multiple self-attention layers, allowing the model to adjust the importance of different inputs over time dynamically. The final encoding of each time step was used to generate predictions, similar to the single-feature Transformer setup. Model hyperparameters—including the number of attention heads and feed-forward network dimensions—were tuned for optimal performance.
To benchmark forecasting performance across different modelling approaches, additional machine learning models—including Support Vector Machines (SVM), Artificial Neural Networks (ANN), Extreme Gradient Boosting (XGBoost), and Random Forest—were evaluated. These models were chosen based on their ability to capture nonlinear relationships and generalise well across diverse datasets. Each model was trained on the same dataset split and evaluated using Root Mean Squared Error (RMSE) and Coefficient of Variation (CV) to assess prediction accuracy. Hyperparameter tuning for SVM involved optimising the kernel function (RBF vs. polynomial) and regularisation parameter (C) using grid search. For ANN, the number of hidden layers, activation functions, and dropout rates were fine-tuned through random search and cross-validation. The XGBoost model was optimised using learning rate tuning, tree depth adjustments, and feature importance analysis. Random Forest hyperparameters, including the number of estimators and tree depth, were selected based on grid search and k-fold cross-validation.
Each model was selected based on its suitability for time-series forecasting and its ability to capture different characteristics of energy consumption. LSTM and Transformer models were chosen for their ability to learn long-range dependencies, NARMAX for its interpretability, and ensemble models like Random Forest and XGBoost for their robustness in feature-driven forecasting. A structured hyperparameter tuning process, incorporating grid search, random search, Bayesian optimisation, and cross-validation, was applied across all models to ensure optimal predictive performance in diverse energy datasets.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}