
Knowledge Integration in Smart Factories





Definition
:1. Introduction
2. Smart Factory
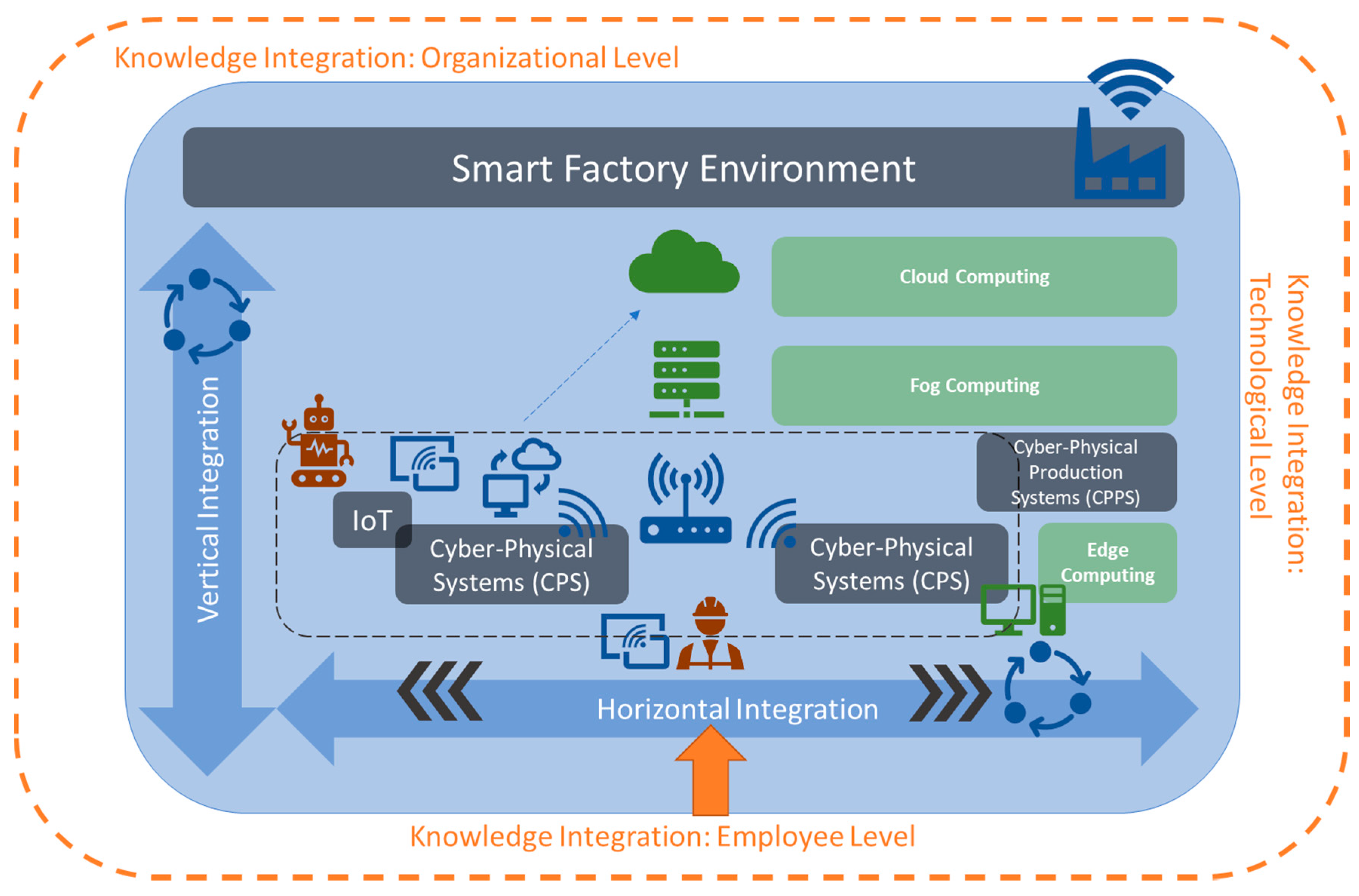
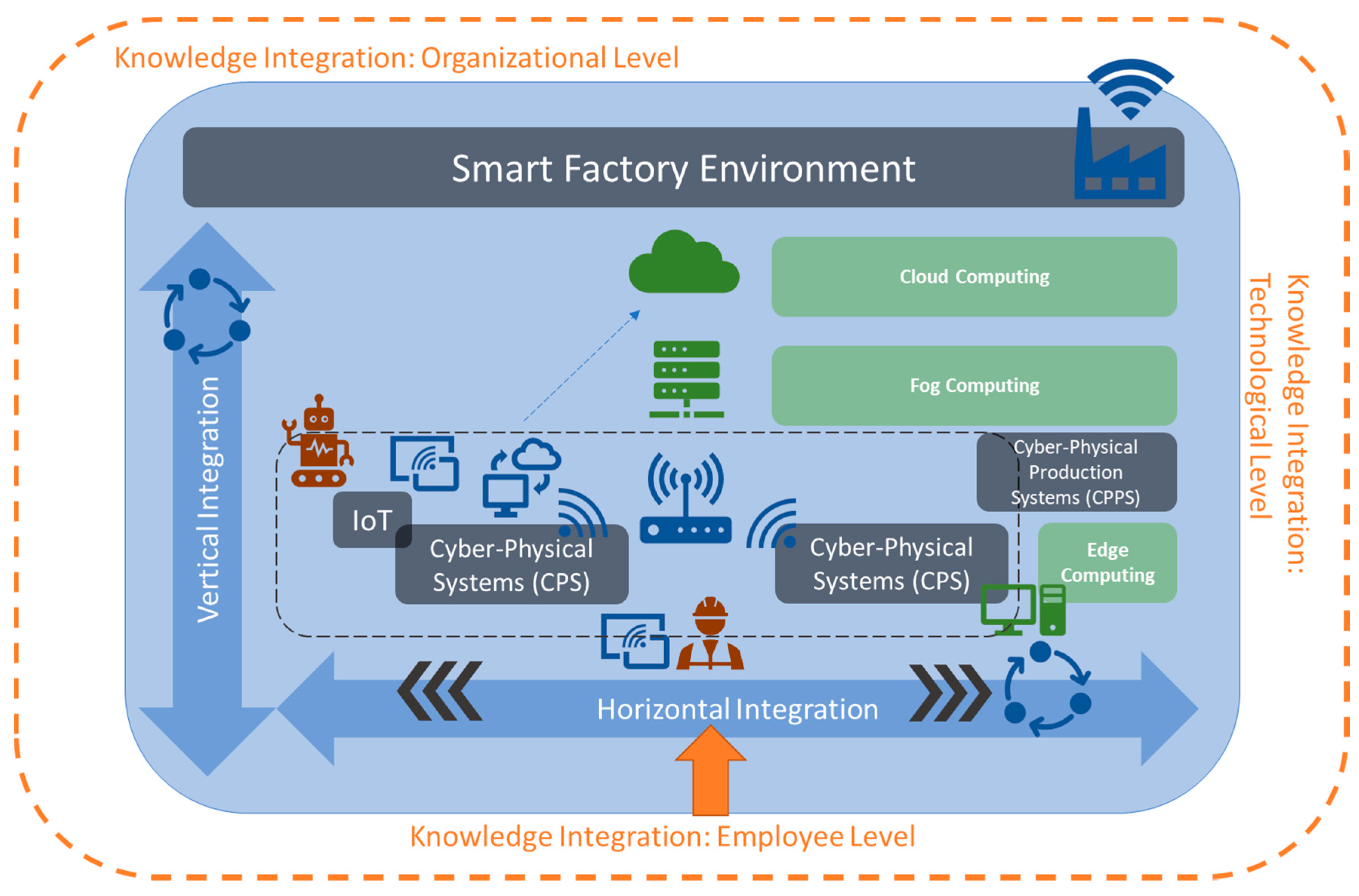
2.1. Smart Factory Environment
2.2. Multi-Dimensional Knowledge Integration in Smart Factories
3. Knowledge Integration
3.1. Knowledge Integration on Organizational Level: Horizontal and Vertical Integration
3.2. Knowledge Integration: Employee Level
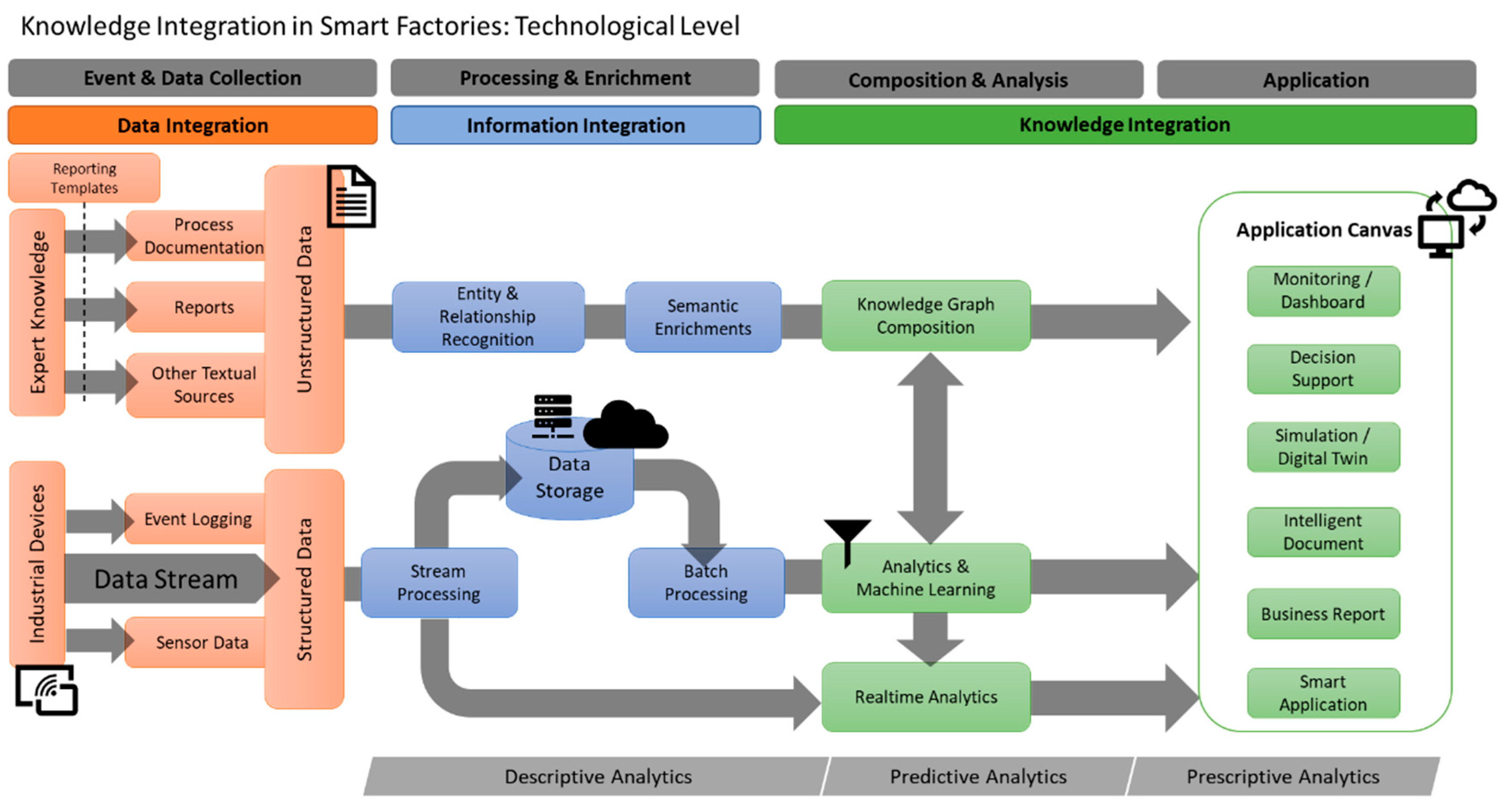
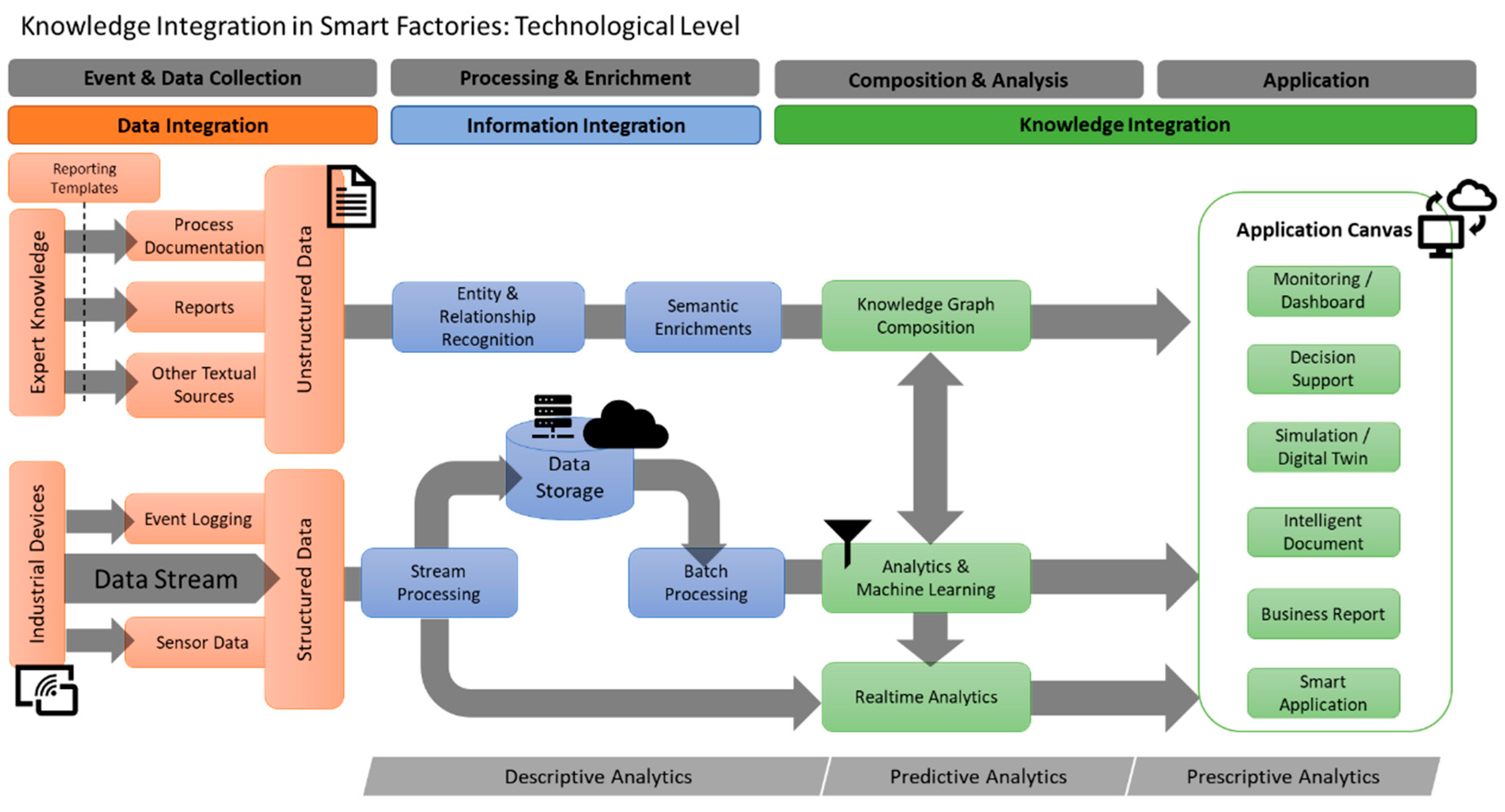
3.3. Knowledge Integration: Technological Level
3.3.1. Data Computing/Processing in Smart Factories
3.3.2. Types of Data Analytics in Smart Factories
3.3.3. Simulation and Decision Making in Smart Factories Using Digital Twins
3.3.4. Semi- and Unstructured Data Integration
Application of Text Mining and Text Generation in Smart Factories
- Information extraction and retrieval: The information extraction process can be described as turning the unstructured textual data into structured and usable information. Since textual data are prone to including inconsistencies and human errors or potentially irrelevant data, a pre-processing phase takes place before the information extraction. After the raw text is pre-processed, several approaches have been addressed in the literature for the extraction of knowledge from the text, including Named Entity Recognition (NER) [53] and Relation Extraction (RE) [54]. Both methods are directly relevant for a semantic representation of data, since entities and relations can be identified in a meaningful way to define and populate the nodes and edges, in graph based representations of texts, as, e.g., knowledge graphs, while utilizing additional pre-existing domain knowledge [55].
- Classification, clustering and topic modelling: Classification is one of the important methods that allow creating a connection between a document and a search query. It is utilized in several applications, including the medical, commercial and industrial design processes. In the latter, Jiang et al. (2017) have developed an algorithm that predicts the importance of a product feature based on written user reviews [56]. Traditional text classification methods include Naïve Bayes, Support Vector Machines (SVM), and k-Nearest Neighbor. All those algorithms depend on the features of a document and the predefined labels that classify this document into a certain category. Unlike traditional approaches, which use Term Frequency–Inverse Document Frequency (TF-IDF), cosine similarities or probability functions, machine and deep learning algorithms learn to map document features to the available labels through creating a matching function that enables the system of categorizing a new document to one or more of the predefined classes based on its features.
- Acquisition and pre-indexing: In the acquisition and indexing phase, all relevant knowledge assets—including experts and extracted content from the knowledge base —are considered for extraction. Domain specific information such as textual information from design and process documentation is considered and subsequently identified through text analysis.
- Initialization: In the initialization phase, relevant knowledge sources are collected on the basis of the acquisition and indexing results, and metadata is assigned to documents. To sustain the extraction context and metadata of extraction algorithms, such results are stored using a graph-based knowledge representation concept, called Multidimensional Knowledge Representation (MKR) [59]. Based on the graph-based MKR of each document, other entities and semantically related content from other documents can be referenced [59]. Each extracted document is processed using text mining techniques to feed into the meta-structure of the MKR.
- Process Enrichment: In the process enrichment phase, relevant content is collected from the MKR structure, based on the relationships between elements and the underlying texts, and put into the format of an intelligent document. Each generated, intelligent document is a composition of identified knowledge assets. Based on the interaction of users, links to further resources can be followed and the document can be modified on demand and further enriched by additional asset recommendations.
- Automated Update Cycle: The automatic enrichment of the intelligent documents runs iteratively and continuously and modifies documents or adds content to new assets when new or changed source texts or extraction results are available (e.g., new metadata such as keywords, entity links, related process contexts, new incident reports).
Semantic Knowledge Representation in Smart Factories
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Entry Link on the Encyclopedia Platform
References
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Alcácer, V.; Machado, V. Scanning the Industry 4.0: A Literature Review on Technologies for Manufacturing Systems. Eng. Sci. Technol. Int. J. 2019, 22, 899–919. [Google Scholar] [CrossRef]
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2020, 31, 127–182. [Google Scholar] [CrossRef]
- Zhong, R.Y.; Xu, X.; Klotz, E.; Newman, S.T. Intelligent Manufacturing in the Context of Industry 4.0: A Review. Engineering 2017, 3, 616–630. [Google Scholar] [CrossRef]
- Neumann, W.P.; Winkelhaus, S.; Grosse, E.H.; Glock, C.H. Industry 4.0 and the human factor—A systems framework and analysis methodology for successful development. Int. J. Prod. Econ. 2021, 233, 107992. [Google Scholar] [CrossRef]
- Roth, A. (Ed.) Einführung und Umsetzung von Industrie 4.0: Grundlagen, Vorgehensmodell und Use Cases aus der Praxis; Springer Gabler: Berlin, Germany, 2016; ISBN 978-3-662-48504-0. [Google Scholar]
- Shi, Z.; Xie, Y.; Xue, W.; Chen, Y.; Fu, L.; Xu, X. Smart factory in Industry 4.0. Syst. Res. Behav. Sci. 2020, 37, 607–617. [Google Scholar] [CrossRef]
- Strozzi, F.; Colicchia, C.; Creazza, A.; Noè, C. Literature review on the ‘Smart Factory’ concept using bibliometric tools. Int. J. Prod. Res. 2017, 55, 6572–6591. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Wang, L.; Nee, A. Digital Twins and Cyber–Physical Systems toward Smart Manufacturing and Industry 4.0: Correlation and Comparison. Engineering 2019, 5, 653–661. [Google Scholar] [CrossRef]
- Frey-Luxemburger, M. (Ed.) Wissensmanagement-Grundlagen und Praktische Anwendung: Eine Einführung in das IT-Gestützte Management der Ressource Wissen, 2nd ed.; IT im Unternehmen; Springer Vieweg: Wiesbaden, Germany, 2014; ISBN 978-3-658-04752-8. [Google Scholar]
- Capestro, M.; Kinkel, S. Industry 4.0 and Knowledge Management: A Review of Empirical Studies. In Knowledge Management and Industry 4.0: New Paradigms for Value Creation; Bettiol, M., Di Maria, E., Micelli, S., Eds.; Knowledge Management and Organizational Learning; Springer International Publishing: Cham, Switzerland, 2020; pp. 19–52. ISBN 978-3-030-43589-9. [Google Scholar]
- Brauckmann, O. Smart Production: Wertschöpfung durch Geschäftsmodelle; Springer Vieweg: Berlin, Germany, 2015; ISBN 978-3-662-45301-8. [Google Scholar]
- Bettiol, M.; Maria, E.D.; Micelli, S. (Eds.) Knowledge Management and Industry 4.0: New Paradigms for Value Creation; Knowledge Management and Organizational Learning; Springer International Publishing: Cham, Switzerland, 2020; ISBN 978-3-030-43588-2. [Google Scholar]
- Ansari, F.; Erol, S.; Sihn, W. Rethinking Human-Machine Learning in Industry 4.0: How Does the Paradigm Shift Treat the Role of Human Learning? Procedia Manuf. 2018, 23, 117–122. [Google Scholar] [CrossRef]
- Seeber, I.; Bittner, E.; Briggs, R.O.; de Vreede, T.; de Vreede, G.-J.; Elkins, A.; Maier, R.; Merz, A.B.; Oeste-Reiß, S.; Randrup, N.; et al. Machines as teammates: A research agenda on AI in team collaboration. Inf. Manag. 2020, 57, 103174. [Google Scholar] [CrossRef]
- Industrial Internet Consortium (IIC). The Industrial Internet of Things Volume T3: Analytics Framework. Available online: https://iiconsortium.org/pdf/IIC_Industrial_Analytics_Framework_Oct_2017.pdf (accessed on 6 August 2021).
- Plattform-i4.0 Referenzarchitekturmodell (RAMI) 4.0 (Reference Architecture Model). Available online: https://www.plattform-i40.de/PI40/Redaktion/DE/Infografiken/referenzarchitekturmodell-4-0.html (accessed on 6 August 2021).
- Bagheri, B.; Yang, S.; Kao, H.-A.; Lee, J. Cyber-physical Systems Architecture for Self-Aware Machines in Industry 4.0 Environment. IFAC-PapersOnLine 2015, 48, 1622–1627. [Google Scholar] [CrossRef]
- Karnouskos, S.; Ribeiro, L.; Leitão, P.; Luder, A.; Vogel-Heuser, B. Key Directions for Industrial Agent Based Cyber-Physical Production Systems. In Proceedings of the 2019 IEEE International Conference on Industrial Cyber Physical Systems (ICPS), Taipei, Taiwan, 6–9 May 2019; pp. 17–22. [Google Scholar]
- Dornhöfer, M.; Sack, S.; Zenkert, J.; Fathi, M. Simulation of Smart Factory Processes Applying Multi-Agent-Systems—A Knowledge Management Perspective. J. Manuf. Mater. Process. 2020, 4, 89. [Google Scholar] [CrossRef]
- Soic, R.; Vukovic, M.; Skocir, P.; Jezic, G. Context-Aware Service Orchestration in Smart Environments. In Agents and Multi-agent Systems: Technologies and Applications 2019; Jezic, G., Chen-Burger, Y.-H.J., Kusek, M., Šperka, R., Howlett, R.J., Jain, L.C., Eds.; Springer: Singapore, 2020; pp. 35–45. [Google Scholar]
- Fei, X.; Shah, N.; Verba, N.; Chao, K.-M.; Sanchez-Anguix, V.; Lewandowski, J.; James, A.; Usman, Z. CPS data streams analytics based on machine learning for Cloud and Fog Computing: A survey. Futur. Gener. Comput. Syst. 2019, 90, 435–450. [Google Scholar] [CrossRef]
- Gorodetsky, V.I.; Kozhevnikov, S.S.; Novichkov, D.; Skobelev, P.O. The Framework for Designing Autonomous Cyber-Physical Multi-Agent Systems for Adaptive Resource Management. In Industrial Applications of Holonic and Multi-Agent Systems; Mařík, V., Kadera, P., Rzevski, G., Zoitl, A., Anderst-Kotsis, G., Tjoa, A.M., Khalil, I., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 52–64. [Google Scholar]
- Industrial Internet Consortium (IIC). The Industrial Internet of Things Volume G1: Reference Architecture. Available online: https://www.iiconsortium.org/pdf/IIRA-v1.9.pdf (accessed on 6 August 2021).
- Bullinger, H.-J.; Wörner, K.; Prieto, J. Wissensmanagement—Modelle und Strategien für die Praxis. In Wissensmanagement: Schritte zum Intelligenten Unternehmen; Bürgel, H.D., Ed.; Edition Alcatel SEL Stiftung; Springer: Berlin/Heidelberg, Germany, 1998; pp. 21–39. ISBN 978-3-642-71995-0. [Google Scholar]
- Zenkert, J.; Weber, C.; Klahold, A.; Fathi, M.; Hahn, K. Knowledge-Based Production Documentation Analysis: An Integrat-ed Text Mining Architecture. In Proceedings of the 2018 IEEE 61st International Midwest Symposium on Circuits and Sys-tems (MWSCAS), Windsor, ON, Canada, 5–8 August 2018; pp. 717–720. [Google Scholar]
- Plattform-i4.0 Infographic about Hierarchy in Industry 3.0. Available online: https://www.plattform-i40.de/PI40/Redaktion/DE/Infografiken/hierarchie-in-der-industrie-3-0.html (accessed on 6 August 2021).
- Plattform-i4.0 Infographic about Hierarchy in Industry 4.0. Available online: https://www.plattform-i40.de/PI40/Redaktion/DE/Infografiken/hierarchie-in-der-industrie-4-0.html (accessed on 6 August 2021).
- Vogel-Heuser, B.; Bauernhansl, T.; Hompel, M. (Eds.) Handbuch Industrie 4.0 Bd.4: Allgemeine Grundlagen, 2nd ed.; VDI Springer Reference; Springer Vieweg: Berlin, Germany, 2017; ISBN 978-3-662-53253-9. [Google Scholar]
- North, K.; Maier, R.; Haas, O. Value Creation in the Digitally Enabled Knowledge Economy. In Progress in IS; Springer International Publishing: Berlin, Germany, 2018; pp. 1–29. [Google Scholar]
- Gillespie, R.B.; Colgate, J.E.; Peshkin, M.A. A General Framework for Cobot Control. IEEE Trans. Robot. Autom. 2001, 17, 391–401. [Google Scholar] [CrossRef]
- Hu, P.; Dhelim, S.; Ning, H.; Qiu, T. Survey on fog computing: Architecture, key technologies, applications and open issues. J. Netw. Comput. Appl. 2017, 98, 27–42. [Google Scholar] [CrossRef]
- OpenFog Consortium OpenFog Reference Architecture for Fog Computing. Available online: https://www.iiconsortium.org/pdf/OpenFog_Reference_Architecture_2_09_17.pdf (accessed on 6 August 2021).
- Sittón-Candanedo, I.; Alonso, R.S.; Rodríguez-González, S.; García Coria, J.A.; De La Prieta, F. Edge Computing Architec-tures in Industry 4.0: A General Survey and Comparison. In International Workshop on Soft Computing Models in Industrial and Environmental Applications; Martínez Álvarez, F., Troncoso Lora, A., Sáez Muñoz, J.A., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 121–131. [Google Scholar]
- Industrial Internet Consortium Edge Computing Task Group Introduction to Edge Computing. Available online: https://hub.iiconsortium.org/intro-edge-computing (accessed on 6 August 2021).
- Lim, K.Y.H.; Zheng, P.; Chen, C.-H. A state-of-the-art survey of Digital Twin: Techniques, engineering product lifecycle management and business innovation perspectives. J. Intell. Manuf. 2020, 31, 1313–1337. [Google Scholar] [CrossRef]
- Papadimitriou, S.; Sun, J.; Faloutsos, C.; Yu, P.S. Dimensionality Reduction and Filtering on Time Series Sensor Streams. In Managing and Mining Sensor Data; Springer: Boston, MA, USA, 2012; pp. 103–141. [Google Scholar]
- Enders, C.K. Applied Missing Data Analysis, 1st ed.; Guilford Publications: New York, NY, USA, 2010; ISBN 978-1-60623-639-0. [Google Scholar]
- Aggarwal, C.C. Mining Sensor Data Streams. In Managing and Mining Sensor Data; Springer: Boston, MA, USA, 2012; pp. 143–171. [Google Scholar]
- Turaga, D.S.; Van Der Schaar, M. Distributed Online Learning and Stream Processing for a Smarter Planet. In Fog for 5G and IoT; Chiang, M., Balasubramanian, B., Bonomi, F., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2017; pp. 234–260. ISBN 978-1-119-18720-2. [Google Scholar]
- Zhang, Q.; Yang, L.-T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in manufacturing: A categorical literature review and classification. IFAC-PapersOnLine 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Harrison, R.; Vera, D.A.; Ahmad, B. A Connective Framework to Support the Lifecycle of Cyber-Physical Production Systems. Proc. IEEE 2021, 109, 568–581. [Google Scholar] [CrossRef]
- Jacoby, M.; Usländer, T. Digital Twin and Internet of Things—Current Standards Landscape. Appl. Sci. 2020, 10, 6519. [Google Scholar] [CrossRef]
- Industrial Internet Consortium and Plattform Industrie 4.0 Digital Twin and Asset Administration Shell Concepts and Ap-plication in the Industrial Internet and Industrie 4.0: An Industrial Internet Consortium and Plattform Industrie 4.0 Joint Whitepaper. Available online: https://www.iiconsortium.org/pdf/Digital-Twin-and-Asset-Administration-Shell-Concepts-and-Application-Joint-Whitepaper.pdf (accessed on 6 August 2021).
- Schluse, M.; Priggemeyer, M.; Atorf, L.; Rossmann, J. Experimentable Digital Twins—Streamlining Simulation-Based Systems Engineering for Industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 1722–1731. [Google Scholar] [CrossRef]
- Martinez, E.; Ponce, P.; Macias, I.; Molina, A. Automation Pyramid as Constructor for a Complete Digital Twin, Case Study: A Didactic Manufacturing System. Sensors 2021, 21, 4656. [Google Scholar] [CrossRef]
- Hänel, A.; Seidel, A.; Frieß, U.; Teicher, U.; Wiemer, H.; Wang, D.; Wenkler, E.; Penter, L.; Hellmich, A.; Ihlenfeldt, S. Digital Twins for High-Tech Machining Applications—A Model-Based Analytics-Ready Approach. J. Manuf. Mater. Process. 2021, 5, 80. [Google Scholar] [CrossRef]
- Autiosalo, J.; Ala-Laurinaho, R.; Mattila, J.; Valtonen, M.; Peltoranta, V.; Tammi, K. Towards Integrated Digital Twins for Industrial Products: Case Study on an Overhead Crane. Appl. Sci. 2021, 11, 683. [Google Scholar] [CrossRef]
- Rathore, M.M.; Shah, S.A.; Shukla, D.; Bentafat, E.; Bakiras, S. The Role of AI, Machine Learning, and Big Data in Digital Twinning: A Systematic Literature Review, Challenges, and Opportunities. IEEE Access 2021, 9, 32030–32052. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. A Brief Survey of Text Mining: Clas-sification, Clustering and Extraction Techniques. arXiv 2017, arXiv:1707.02919. [Google Scholar]
- Shi, F.; Chen, L.; Han, J.; Childs, P. A Data-Driven Text Mining and Semantic Network Analysis for Design Information Retrieval. J. Mech. Des. 2017, 139, 111402. [Google Scholar] [CrossRef]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Pawar, S.; Palshikar, G.K.; Bhattacharyya, P. Relation Extraction: A Survey. arXiv 2017, arXiv:1712.05191. [Google Scholar]
- Abu Rasheed, H.; Weber, C.; Zenkert, J.; Czerner, P.; Krumm, R.; Fathi, M. A Text Extraction-Based Smart Knowledge Graph Composition for Integrating Lessons Learned during the Microchip Design. In Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; pp. 594–610. [Google Scholar]
- Jiang, H.; Kwong, C.K.; Yung, K.L. Predicting Future Importance of Product Features Based on Online Customer Reviews. J. Mech. Des. 2017, 139, 111413. [Google Scholar] [CrossRef]
- Grieco, A.; Pacella, M.; Blaco, M. On the Application of Text Clustering in Engineering Change Process. Procedia CIRP 2017, 62, 187–192. [Google Scholar] [CrossRef]
- Klahold, A.; Fathi, M. Computer Aided Writing; Springer International Publishing: Berlin, Germany, 2020. [Google Scholar]
- Zenkert, J.; Klahold, A.; Fathi, M. Knowledge Discovery in Multidimensional Knowledge Representation Framework: An Integrative Approach for the Visualization of Text Analytics Results. Iran J. Comput. Sci. 2018, 1, 199–216. [Google Scholar] [CrossRef]
- Yahya, M.; Breslin, J.; Ali, M. Semantic Web and Knowledge Graphs for Industry 4.0. Appl. Sci. 2021, 11, 5110. [Google Scholar] [CrossRef]
- Beden, S.; Cao, Q.; Beckmann, A. Semantic Asset Administration Shells in Industry 4.0: A Survey. In Proceedings of the 2021 4th IEEE International Conference on Industrial Cyber-Physical Systems (ICPS), Victoria, BC, Canada, 10–12 May 2021; pp. 31–38. [Google Scholar]
- Heling, L.; Acosta, M.; Maleshkova, M.; Sure-Vetter, Y. Querying Large Knowledge Graphs over Triple Pattern Fragments: An Empirical Study. In The Semantic Web-ISWC 2018; Vrandečić, D., Bontcheva, K., Suárez-Figueroa, M.C., Presutti, V., Ce-lino, I., Sabou, M., Kaffee, L.-A., Simperl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11137, pp. 86–102. ISBN 978-3-030-00667-9. [Google Scholar]
- Jayaram, N.; Khan, A.; Li, C.; Yan, X.; Elmasri, R. Querying Knowledge Graphs by Example Entity Tuples. IEEE Trans. Knowl. Data Eng. 2015, 27, 2797–2811. [Google Scholar] [CrossRef]
- Dietz, L.; Kotov, A.; Meij, E. Utilizing Knowledge Graphs for Text-Centric Information Retrieval. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1387–1390. [Google Scholar]
- Li, H.; Xiong, C.; Callan, J. Natural Language Supported Relation Matching for Question Answering with Knowledge Graphs. In The First Workshop on Knowledge Graphs and Semantics for Text Retrieval and Analysis (KG4IR 2017); CEUR: Tokyo, Japan, 2017. [Google Scholar]
- Shekarpour, S.; Marx, E.; Auer, S.; Sheth, A. RQUERY: Rewriting Natural Language Queries on Knowledge Graphs to Alle-viate the Vocabulary Mismatch Problem. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2018, 30, 824–837. [Google Scholar] [CrossRef]
- Tiwari, A.; Rajesh, K.; Srujana, P. Semantically Enriched Knowledge Extraction With Data Mining. Int. J. Comput. Appl. Technol. Res. 2015, 4, 7–10. [Google Scholar] [CrossRef]
- Abu-Rasheed, H.; Weber, C.; Zenkert, J.; Krumm, R.; Fathi, M. Explainable Graph-Based Search for Lessons-Learned Docu-ments in the Semiconductor Industry. In Intelligent Computing; Arai, K., Ed.; Springer International Publishing: Cham, Switzerland, 2022; pp. 1097–1106. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 2015, 104, 11–33. [Google Scholar] [CrossRef]
- Liu, Z.; Han, X. Deep Learning in Knowledge Graph. In Deep Learning in Natural Language Processing; Deng, L., Liu, Y., Eds.; Springer: Singapore, 2018; pp. 117–145. ISBN 978-981-10-5208-8. [Google Scholar]
- Qin, Z.; Cen, C.; Jie, W.; Gee, T.S.; Chandrasekhar, V.R.; Peng, Z.; Zeng, Z. Knowledge-Graph Based Multi-Target Deep-Learning Models for Train Anomaly Detection. In Proceedings of the 2018 International Conference on Intelligent Rail Transportation (ICIRT), Singapore, 12–14 December 2018; pp. 1–5. [Google Scholar]

{kind=link}
{kind=link}
| Knowledge Processing | Realization in Smart Factory | Benefits | Exemplary Technologies 1 |
|---|---|---|---|
| Data Computing/ Processing | Cloud Computing | Software as a Service (SaaS), central software applications without local installation | Amazon AWS, Microsoft Azure |
| Fog Computing | Enhance low-latency, mobility, network bandwidth, security and privacy | Cisco IOx | |
| Edge Computing | Offload network bandwidth, shorter delay time (latency) | Cisco IOx, Intel IOT solutions, Nvidia EGX | |
| Data Analytics | Descriptive Analytics | Status and usage monitoring, reporting, anomaly detection and diagnosis, modeling, or training | RapidMiner, RStudio Server, Tableau |
| Stream Analytics: Real-Time Analysis | Apache Kafka/Flink, Elasticsearch and Kibana | ||
| Batch Analytics: Monitoring/Reporting | Apache Spark/Zeppelin, Cassandra, Tensorflow, Keras | ||
| Predictive Analytics | Predicting capacity needs and utilization, material and energy consumption, predicting component and system wear and failures | RapidMiner, RStudio Server, Tensorflow, Keras, AutoKeras, Google AutoML | |
| Prescriptive Analytics | Guidance to recommend operational changes to optimize processes, avoid failures and associated downtime | RapidMiner, RStudio Server, Tensorflow, Keras, AutoKeras, Google AutoML | |
| Simulation | Digital Twin Concept | Real-time analysis, simulation of scalable products and product changes, wear and tear projection | MATLAB Simulink, Azure Digital Twins, Ansys Twin Builder |
| Semantic Knowledge Representation | Knowledge Graphs | Contextualization of multi-source data, Semantic relational learning | Neo4j, Grakn, Ontotext GraphDB, Eccenca corporate memory, Protégé |
| Text Mining | Intelligent Documents | Integration of lessons learned from reporting and failure logs in new design or production cycles | tm (R), nltk (Python), RapidMiner, Text Analytics Toolbox (MATLAB), Apache OpenNLP, Stanford CoreNLP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zenkert, J.; Weber, C.; Dornhöfer, M.; Abu-Rasheed, H.; Fathi, M. Knowledge Integration in Smart Factories. Encyclopedia 2021, 1, 792-811. https://doi.org/10.3390/encyclopedia1030061
Zenkert J, Weber C, Dornhöfer M, Abu-Rasheed H, Fathi M. Knowledge Integration in Smart Factories. Encyclopedia. 2021; 1(3):792-811. https://doi.org/10.3390/encyclopedia1030061
Chicago/Turabian StyleZenkert, Johannes, Christian Weber, Mareike Dornhöfer, Hasan Abu-Rasheed, and Madjid Fathi. 2021. "Knowledge Integration in Smart Factories" Encyclopedia 1, no. 3: 792-811. https://doi.org/10.3390/encyclopedia1030061
APA StyleZenkert, J., Weber, C., Dornhöfer, M., Abu-Rasheed, H., & Fathi, M. (2021). Knowledge Integration in Smart Factories. Encyclopedia, 1(3), 792-811. https://doi.org/10.3390/encyclopedia1030061