

Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones





Abstract
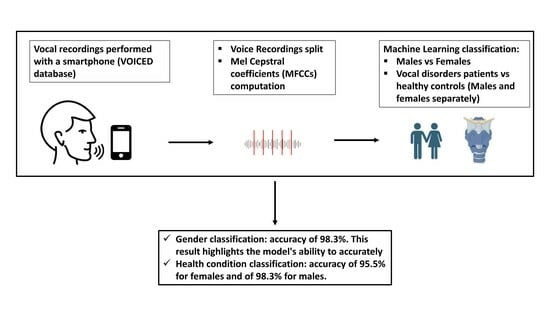
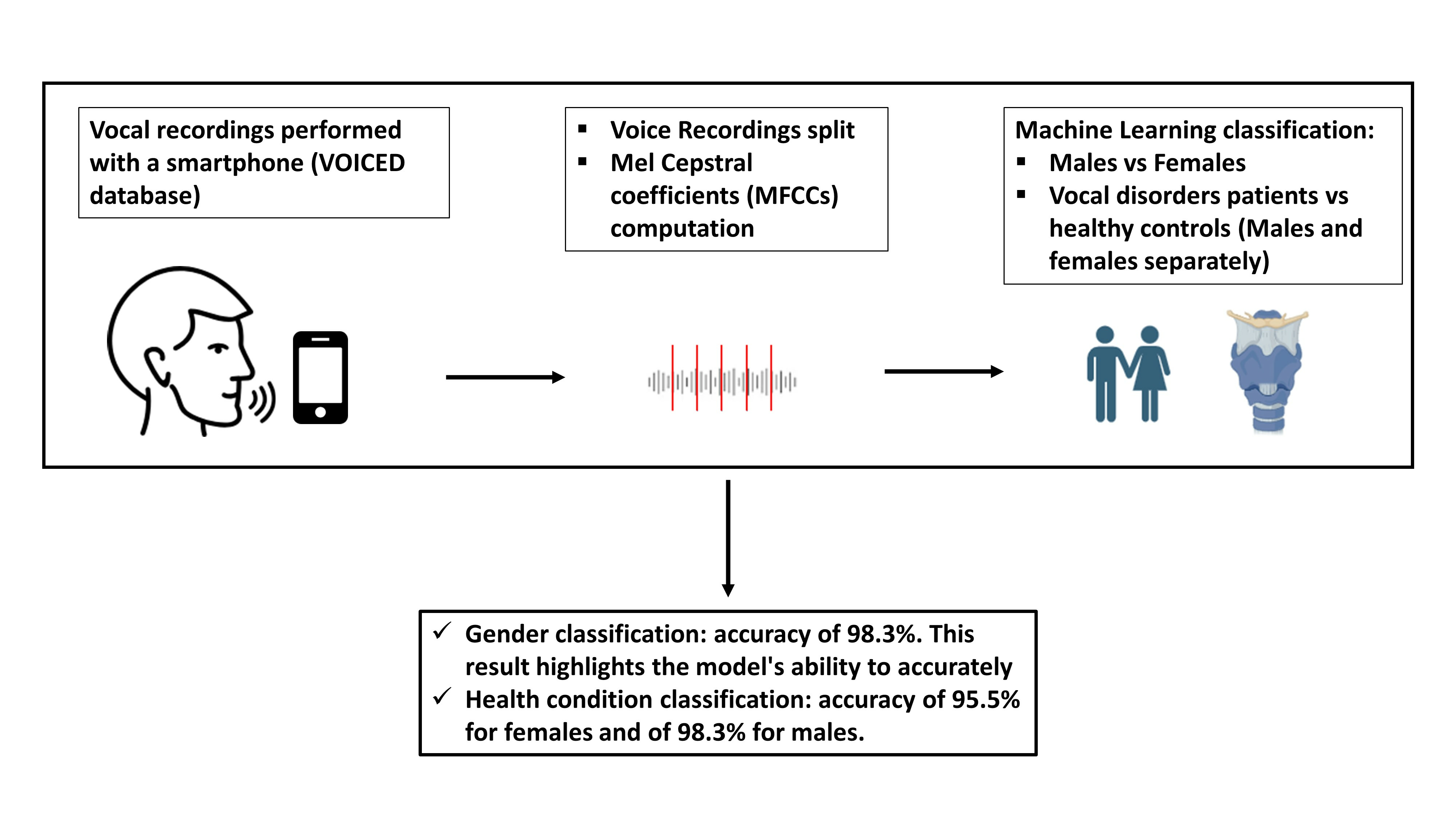
1. Introduction
2. Materials and Methods
2.1. Dataset and Classification Procedure
- Prosodic features: these encompass the rhythm and intonation of the speaker. Due to their inherently subjective and controllable nature, their extraction presents challenges [53].
2.2. Gender Classification
- Understanding the feasibility of employing ML techniques in speech analysis for gender discrimination.
- Defining the best models for the purpose.
2.3. Health Status Classification
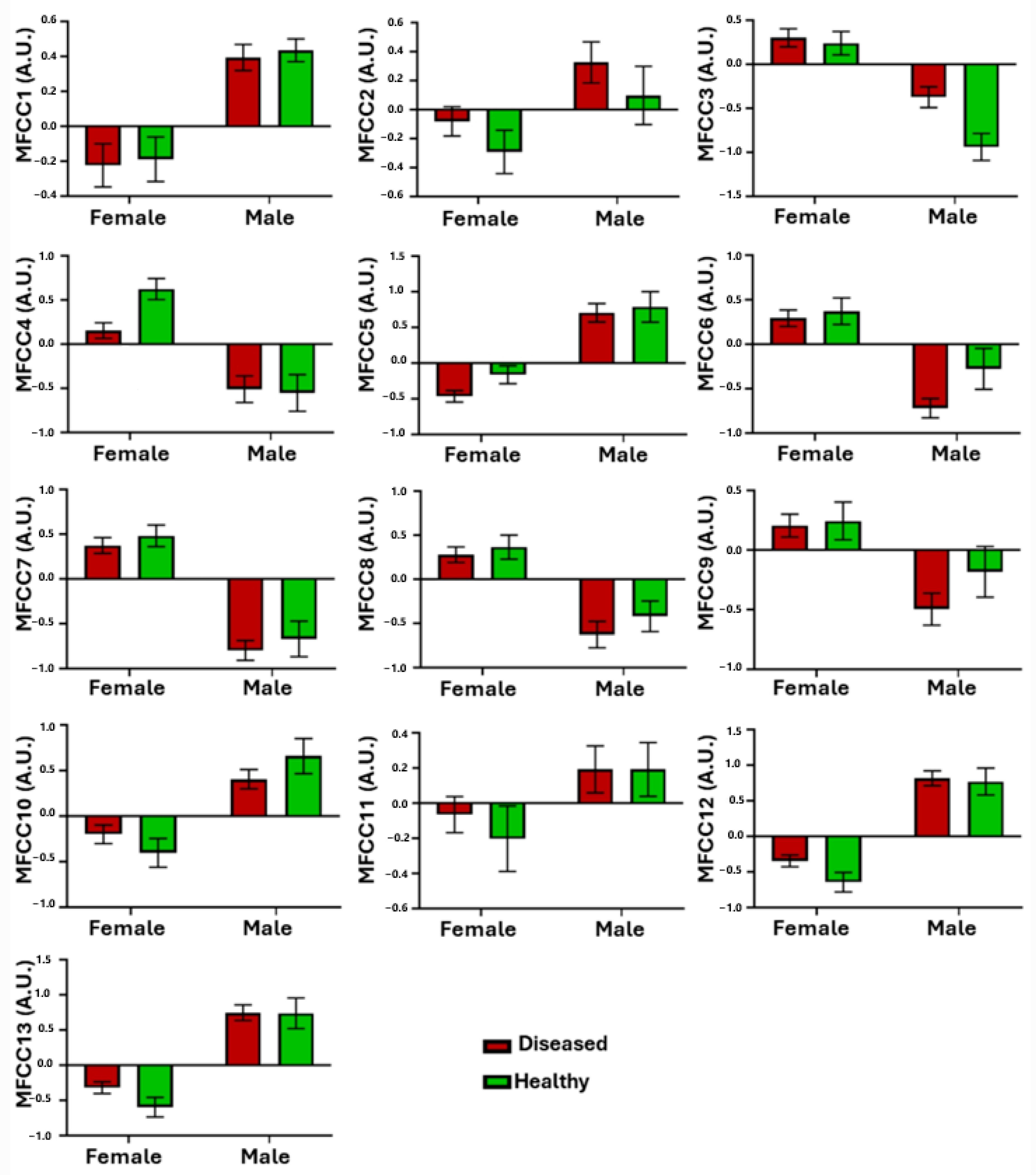
3. Results
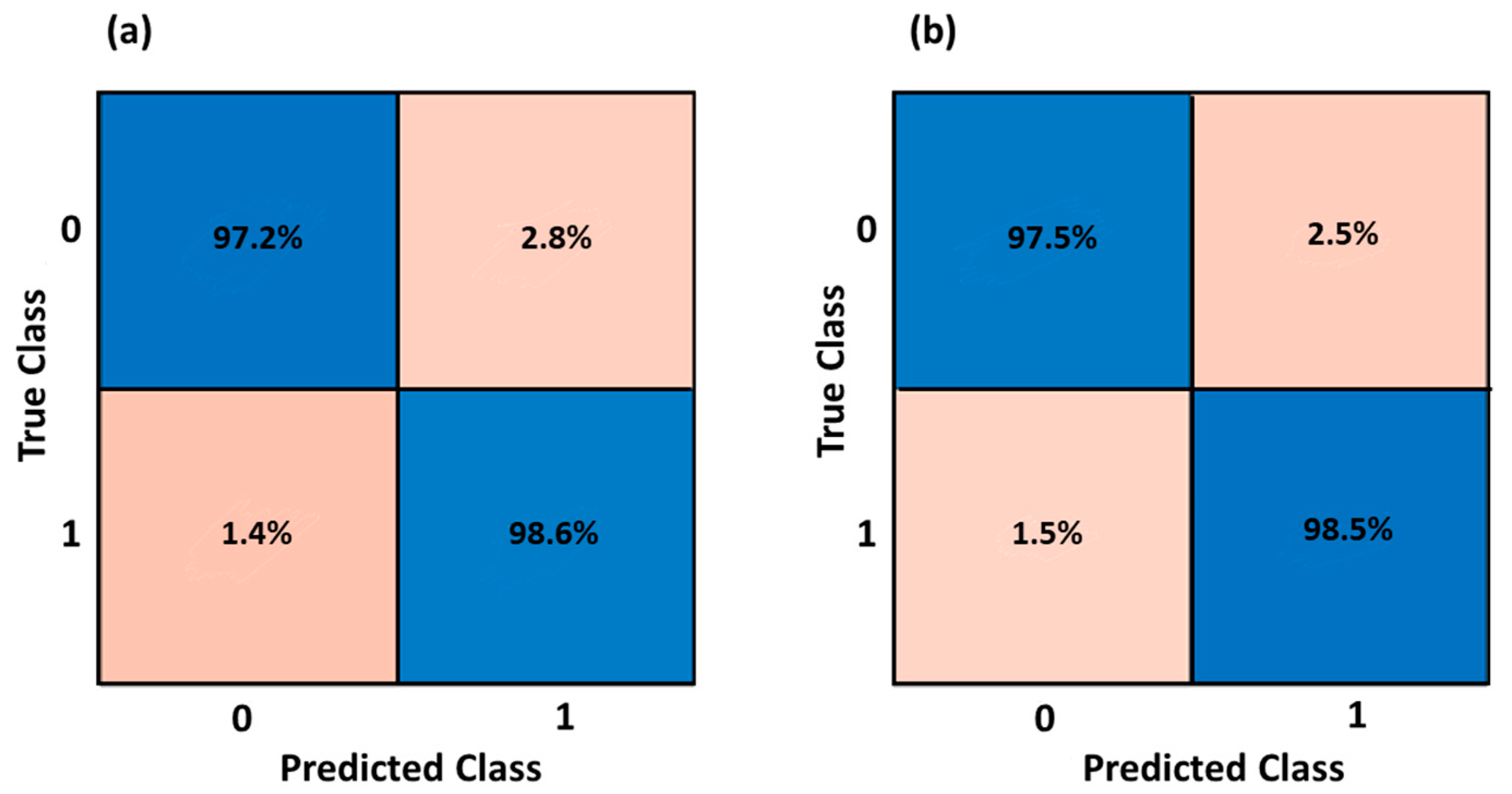
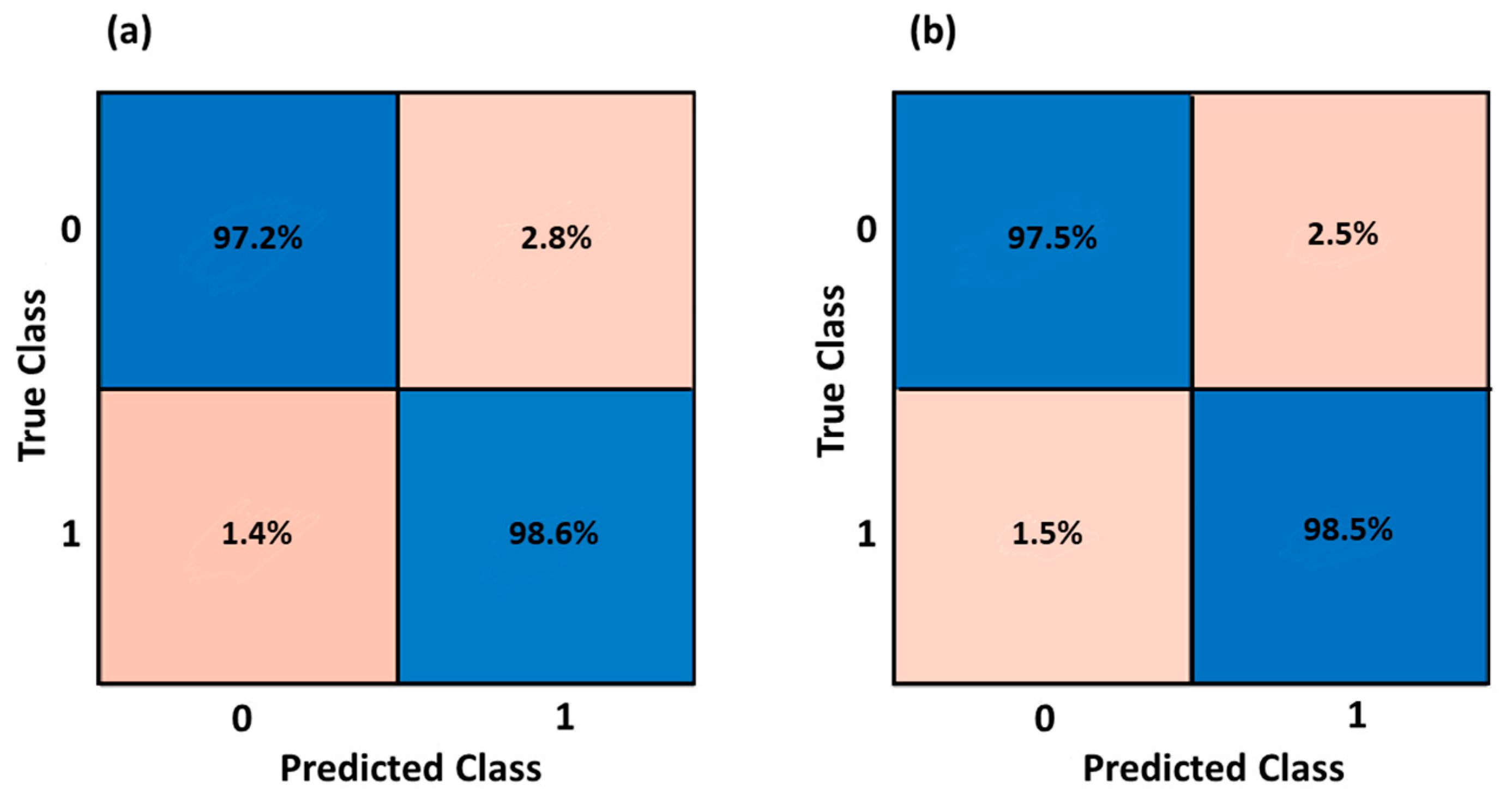
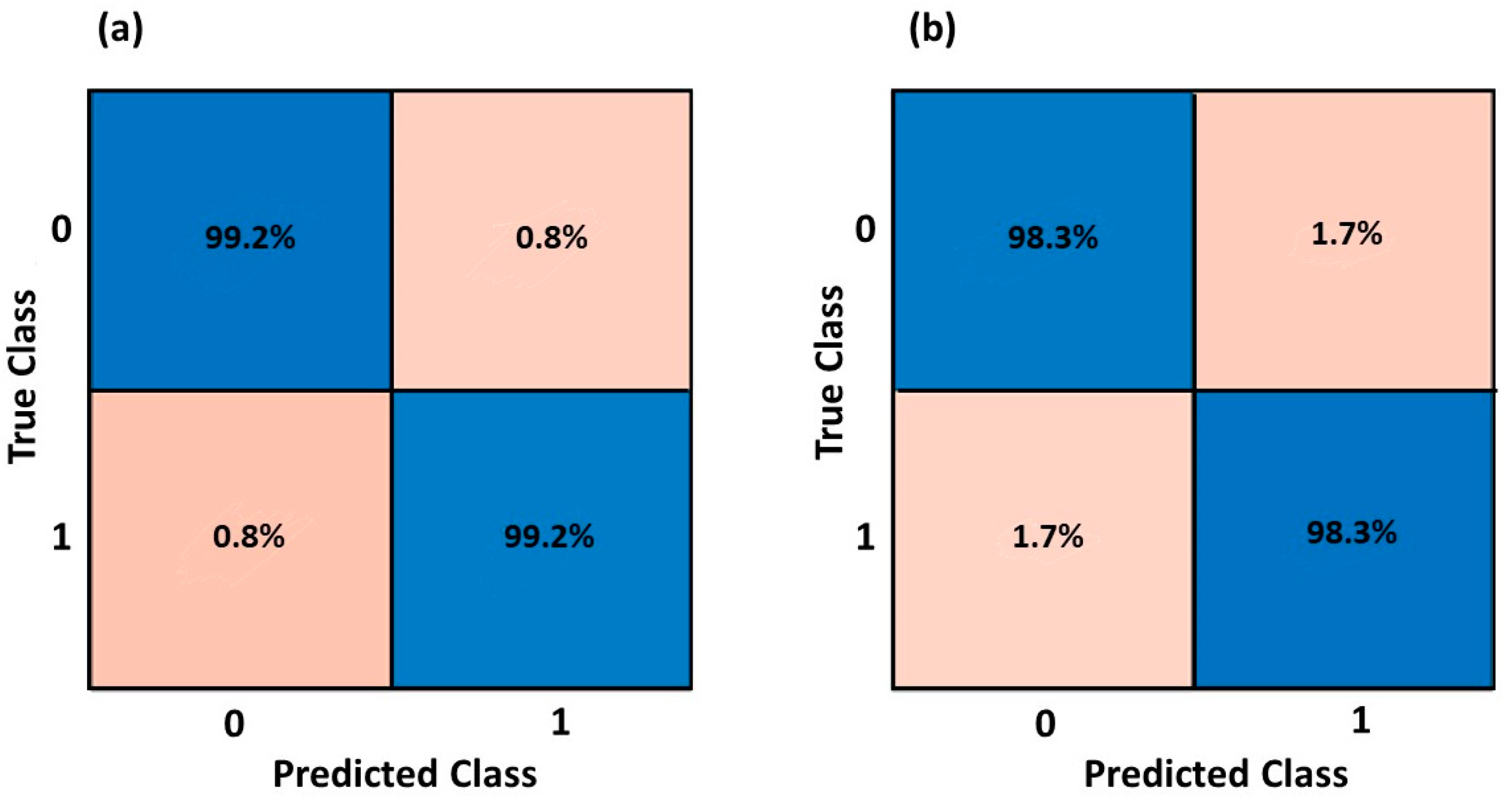
3.1. Gender Classification
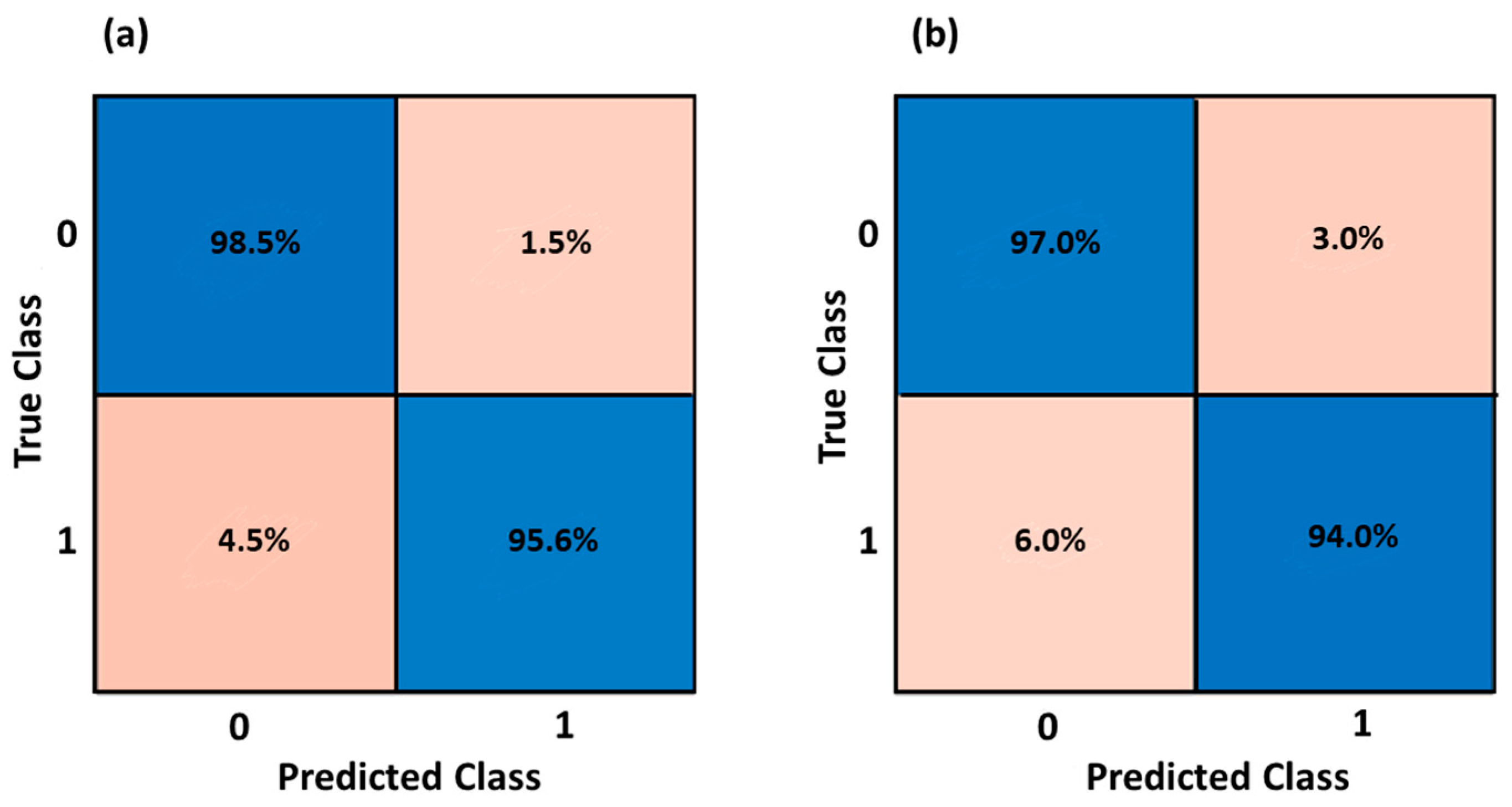
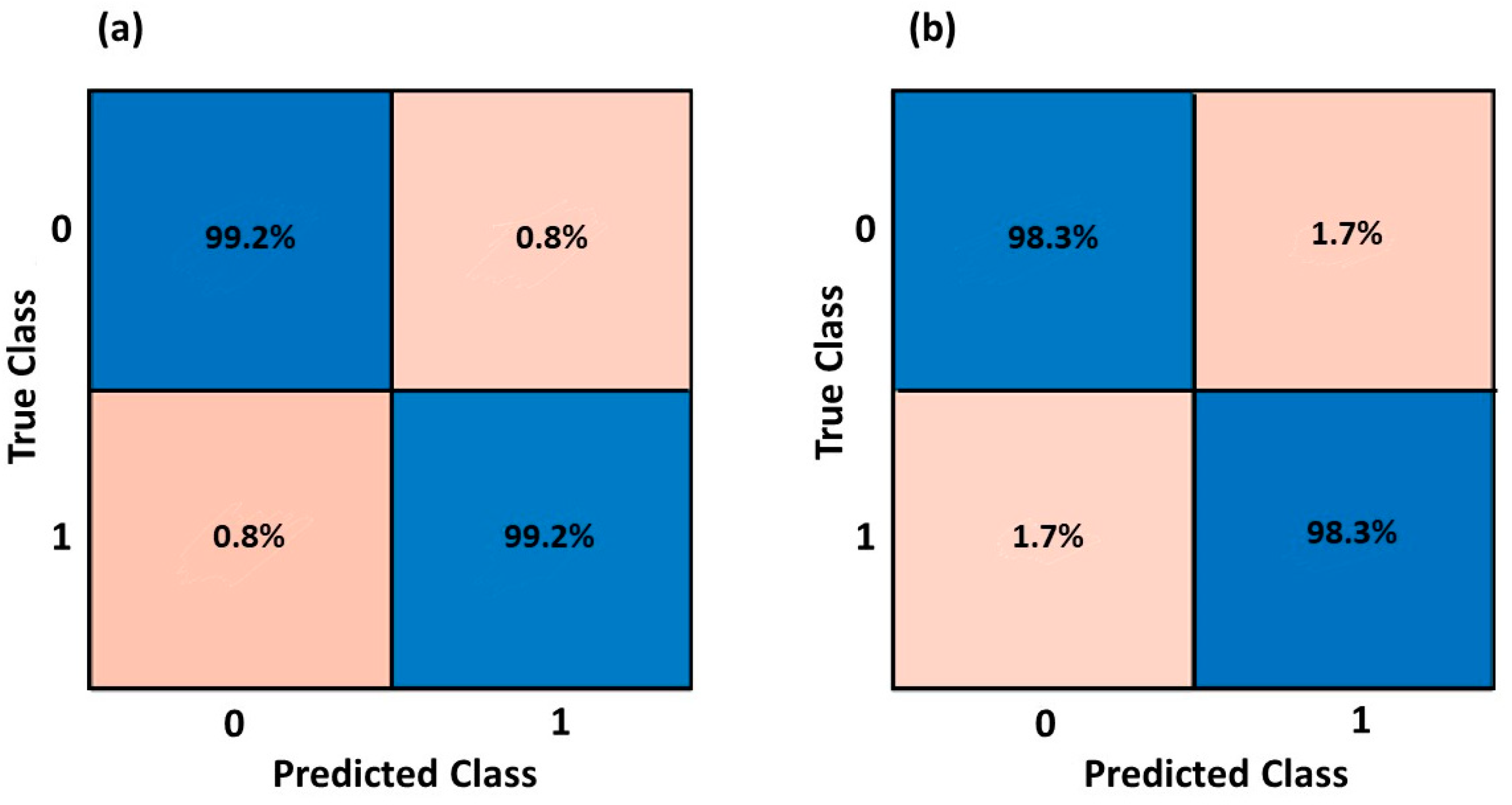
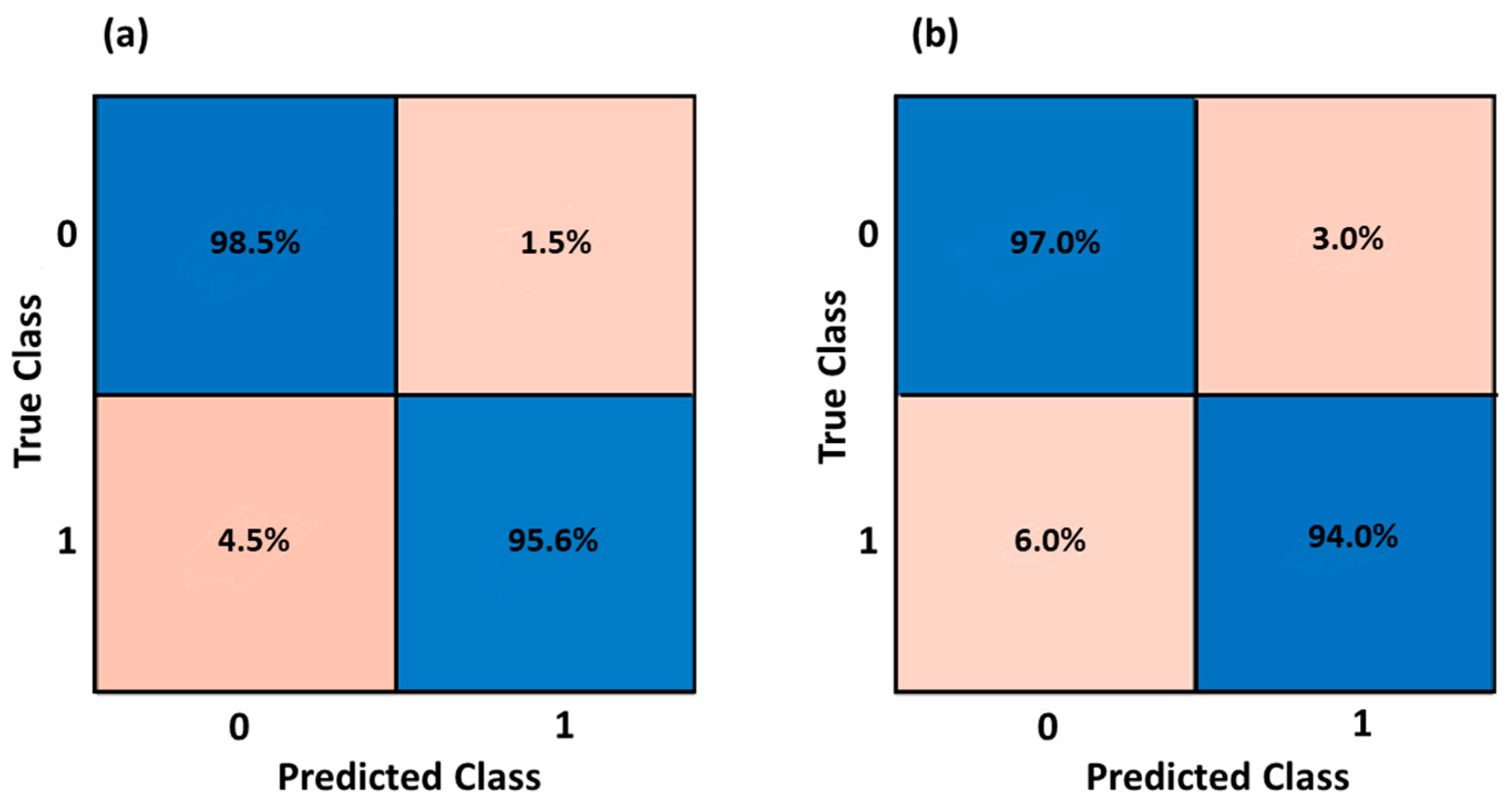
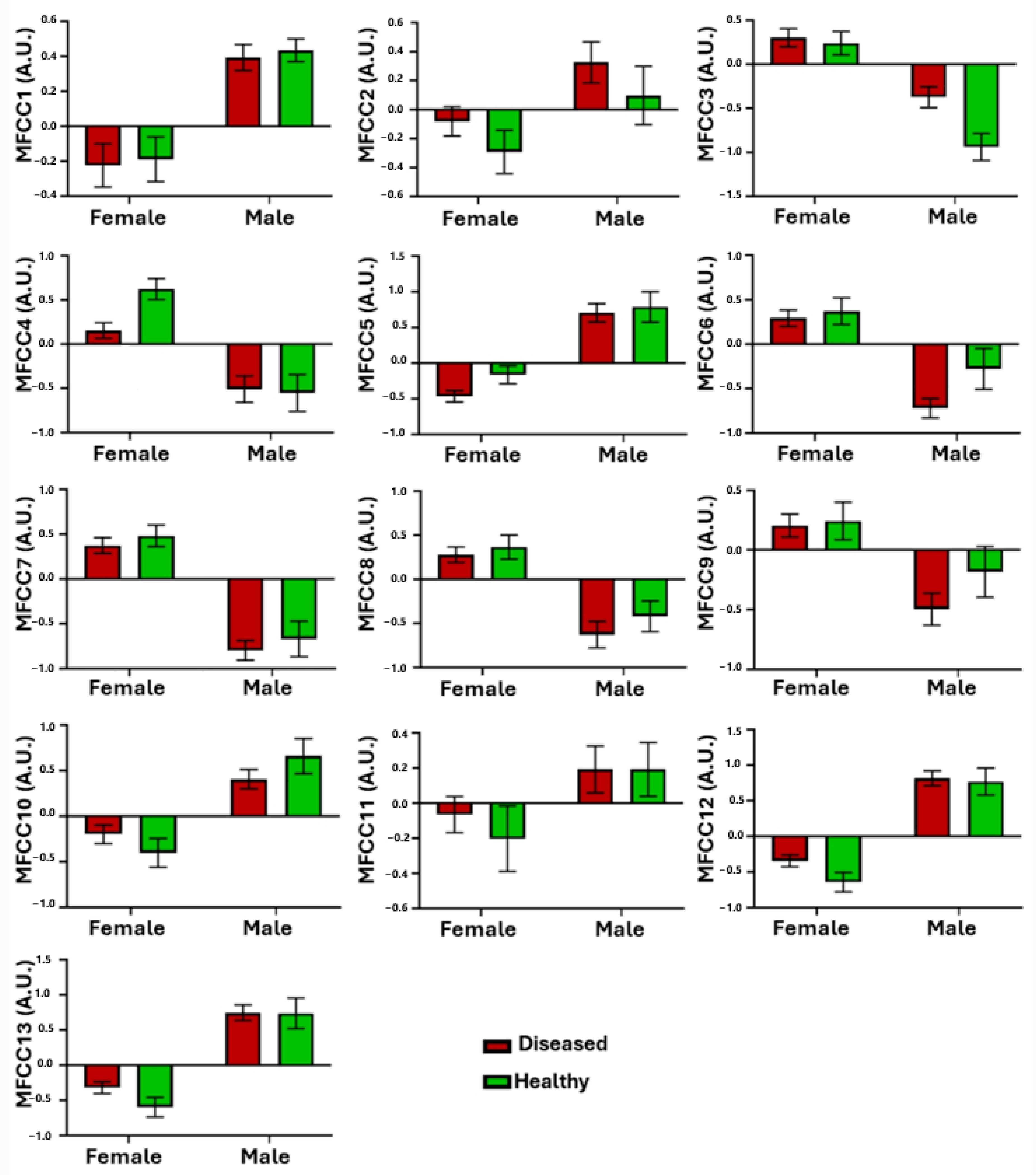
3.2. Health Status Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumhar, M.; Bhatia, J.B. Edge Computing in SDN-Enabled IoT-Based Healthcare Frameworks: Challenges and Future Research Directions. Int. J. Reliab. Qual. E-Healthc. IJRQEH 2022, 11, 1–15. [Google Scholar] [CrossRef]
- Majumder, S.; Deen, M.J. Smartphone Sensors for Health Monitoring and Diagnosis. Sensors 2019, 19, 2164. [Google Scholar] [CrossRef]
- Beduk, T.; Beduk, D.; Hasan, M.R.; Guler Celik, E.; Kosel, J.; Narang, J.; Salama, K.N.; Timur, S. Smartphone-Based Multiplexed Biosensing Tools for Health Monitoring. Biosensors 2022, 12, 583. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. A Crowdsourcing-Based Methodology Using Smartphones for Bridge Health Monitoring. Struct. Health Monit. 2019, 18, 1602–1619. [Google Scholar] [CrossRef]
- Durán-Vega, L.A.; Santana-Mancilla, P.C.; Buenrostro-Mariscal, R.; Contreras-Castillo, J.; Anido-Rifón, L.E.; García-Ruiz, M.A.; Montesinos-López, O.A.; Estrada-González, F. An IoT System for Remote Health Monitoring in Elderly Adults through a Wearable Device and Mobile Application. Geriatrics 2019, 4, 34. [Google Scholar] [CrossRef]
- Baig, M.M.; GholamHosseini, H.; Connolly, M.J. Mobile Healthcare Applications: System Design Review, Critical Issues and Challenges. Australas. Phys. Eng. Sci. Med. 2015, 38, 23–38. [Google Scholar] [CrossRef]
- Boccignone, G.; D’Amelio, A.; Ghezzi, O.; Grossi, G.; Lanzarotti, R. An Evaluation of Non-Contact Photoplethysmography-Based Methods for Remote Respiratory Rate Estimation. Sensors 2023, 23, 3387. [Google Scholar] [CrossRef]
- Isakadze, N.; Martin, S.S. How Useful Is the Smartwatch ECG? Trends Cardiovasc. Med. 2020, 30, 442–448. [Google Scholar] [CrossRef]
- Hekler, E.B.; Buman, M.P.; Grieco, L.; Rosenberger, M.; Winter, S.J.; Haskell, W.; King, A.C. Validation of Physical Activity Tracking via Android Smartphones Compared to ActiGraph Accelerometer: Laboratory-Based and Free-Living Validation Studies. JMIR mHealth uHealth 2015, 3, e3505. [Google Scholar] [CrossRef]
- Di Credico, A.; Petri, C.; Cataldi, S.; Greco, G.; Suarez-Arrones, L.; Izzicupo, P. Heart Rate Variability, Recovery and Stress Analysis of an Elite Rally Driver and Co-Driver during a Competition Period. Sci. Prog. 2024, 107, 00368504231223034. [Google Scholar] [CrossRef]
- Di Credico, A.; Perpetuini, D.; Chiacchiaretta, P.; Cardone, D.; Filippini, C.; Gaggi, G.; Merla, A.; Ghinassi, B.; Di Baldassarre, A.; Izzicupo, P. The Prediction of Running Velocity during the 30–15 Intermittent Fitness Test Using Accelerometry-Derived Metrics and Physiological Parameters: A Machine Learning Approach. Int. J. Environ. Res. Public. Health 2021, 18, 10854. [Google Scholar] [CrossRef]
- Uloza, V.; Padervinskis, E.; Vegiene, A.; Pribuisiene, R.; Saferis, V.; Vaiciukynas, E.; Gelzinis, A.; Verikas, A. Exploring the Feasibility of Smart Phone Microphone for Measurement of Acoustic Voice Parameters and Voice Pathology Screening. Eur. Arch. Otorhinolaryngol. 2015, 272, 3391–3399. [Google Scholar] [CrossRef]
- Jannetts, S.; Schaeffler, F.; Beck, J.; Cowen, S. Assessing Voice Health Using Smartphones: Bias and Random Error of Acoustic Voice Parameters Captured by Different Smartphone Types. Int. J. Lang. Commun. Disord. 2019, 54, 292–305. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, G.; Kwon, S. The Usefulness of Auditory Perceptual Assessment and Acoustic Analysis for Classifying the Voice Severity. J. Voice 2020, 34, 884–893. [Google Scholar] [CrossRef]
- Van der Woerd, B.; Wu, M.; Parsa, V.; Doyle, P.C.; Fung, K. Evaluation of Acoustic Analyses of Voice in Nonoptimized Conditions. J. Speech Lang. Hear. Res. 2020, 63, 3991–3999. [Google Scholar] [CrossRef]
- Lee, S.J.; Lee, K.Y.; Choi, H.-S. Clinical Usefulness of Voice Recordings Using a Smartphone as a Screening Tool for Voice Disorders. Commun. Sci. Disord. 2018, 23, 1065–1077. [Google Scholar] [CrossRef]
- Awan, S.N.; Shaikh, M.A.; Awan, J.A.; Abdalla, I.; Lim, K.O.; Misono, S. Smartphone Recordings Are Comparable to “Gold Standard” Recordings for Acoustic Measurements of Voice. J. Voice 2023, in press. [Google Scholar] [CrossRef]
- Fahed, V.S.; Doheny, E.P.; Busse, M.; Hoblyn, J.; Lowery, M.M. Comparison of Acoustic Voice Features Derived from Mobile Devices and Studio Microphone Recordings. J. Voice 2022, in press. [Google Scholar] [CrossRef]
- Amato, F.; Saggio, G.; Cesarini, V.; Olmo, G.; Costantini, G. Machine Learning-and Statistical-Based Voice Analysis of Parkinson’s Disease Patients: A Survey. Expert Syst. Appl. 2023, 219, 119651. [Google Scholar] [CrossRef]
- da Silva, G.d.A.P.; Feltrin, T.D.; dos Santos Pichini, F.; Cielo, C.A.; Pasqualoto, A.S. Quality of Life Predictors in Voice of Individuals with Chronic Obstructive Pulmonary Disease. J. Voice 2022, in press. [Google Scholar] [CrossRef]
- Ruiz, R.; Legros, C.; Guell, A. Voice Analysis to Predict the Psychological or Physical State of a Speaker. Aviat. Space Environ. Med. 1990, 61, 266–271. [Google Scholar]
- Alonso-Martin, F.; Malfaz, M.; Sequeira, J.; Gorostiza, J.F.; Salichs, M.A. A Multimodal Emotion Detection System during Human–Robot Interaction. Sensors 2013, 13, 15549–15581. [Google Scholar] [CrossRef]
- Chamishka, S.; Madhavi, I.; Nawaratne, R.; Alahakoon, D.; De Silva, D.; Chilamkurti, N.; Nanayakkara, V. A Voice-Based Real-Time Emotion Detection Technique Using Recurrent Neural Network Empowered Feature Modelling. Multimed. Tools Appl. 2022, 81, 35173–35194. [Google Scholar] [CrossRef]
- Asci, F.; Costantini, G.; Di Leo, P.; Zampogna, A.; Ruoppolo, G.; Berardelli, A.; Saggio, G.; Suppa, A. Machine-Learning Analysis of Voice Samples Recorded through Smartphones: The Combined Effect of Ageing and Gender. Sensors 2020, 20, 5022. [Google Scholar] [CrossRef]
- Saloni; Sharma, R.K.; Gupta, A.K. Disease Detection Using Voice Analysis: A Review. Int. J. Med. Eng. Inform. 2014, 6, 189–209. [Google Scholar] [CrossRef]
- Baker, J.; Ben-Tovim, D.I.; Butcher, A.; Esterman, A.; McLaughlin, K. Development of a Modified Diagnostic Classification System for Voice Disorders with Inter-Rater Reliability Study. Logop. Phoniatr. Vocol. 2007, 32, 99–112. [Google Scholar] [CrossRef]
- Shrivas, A.; Deshpande, S.; Gidaye, G.; Nirmal, J.; Ezzine, K.; Frikha, M.; Desai, K.; Shinde, S.; Oza, A.D.; Burduhos-Nergis, D.D. Employing Energy and Statistical Features for Automatic Diagnosis of Voice Disorders. Diagnostics 2022, 12, 2758. [Google Scholar] [CrossRef]
- Roy, N.; Barkmeier-Kraemer, J.; Eadie, T.; Sivasankar, M.P.; Mehta, D.; Paul, D.; Hillman, R. Evidence-Based Clinical Voice Assessment: A Systematic Review. Am. J. Speech-Lang. Pathol. 2013, 22, 212–226. [Google Scholar] [CrossRef]
- Jothilakshmi, S. Automatic System to Detect the Type of Voice Pathology. Appl. Soft Comput. 2014, 21, 244–249. [Google Scholar] [CrossRef]
- Panek, D.; Skalski, A.; Gajda, J.; Tadeusiewicz, R. Acoustic Analysis Assessment in Speech Pathology Detection. Int. J. Appl. Math. Comput. Sci. 2015, 25, 631–643. [Google Scholar] [CrossRef]
- Vizza, P.; Tradigo, G.; Mirarchi, D.; Bossio, R.B.; Lombardo, N.; Arabia, G.; Quattrone, A.; Veltri, P. Methodologies of Speech Analysis for Neurodegenerative Diseases Evaluation. Int. J. Med. Inf. 2019, 122, 45–54. [Google Scholar] [CrossRef]
- Kowalska-Taczanowska, R.; Friedman, A.; Koziorowski, D. Parkinson’s Disease or Atypical Parkinsonism? The Importance of Acoustic Voice Analysis in Differential Diagnosis of Speech Disorders. Brain Behav. 2020, 10, e01700. [Google Scholar] [CrossRef]
- Khanzode, K.C.A.; Sarode, R.D. Advantages and Disadvantages of Artificial Intelligence and Machine Learning: A Literature Review. Int. J. Libr. Inf. Sci. IJLIS 2020, 9, 3. [Google Scholar]
- Kindle, R.D.; Badawi, O.; Celi, L.A.; Sturland, S. Intensive Care Unit Telemedicine in the Era of Big Data, Artificial Intelligence, and Computer Clinical Decision Support Systems. Crit. Care Clin. 2019, 35, 483–495. [Google Scholar] [CrossRef]
- Aazam, M.; Zeadally, S.; Flushing, E.F. Task Offloading in Edge Computing for Machine Learning-Based Smart Healthcare. Comput. Netw. 2021, 191, 108019. [Google Scholar] [CrossRef]
- Salman, O.H.; Taha, Z.; Alsabah, M.Q.; Hussein, Y.S.; Mohammed, A.S.; Aal-Nouman, M. A Review on Utilizing Machine Learning Technology in the Fields of Electronic Emergency Triage and Patient Priority Systems in Telemedicine: Coherent Taxonomy, Motivations, Open Research Challenges and Recommendations for Intelligent Future Work. Comput. Methods Programs Biomed. 2021, 209, 106357. [Google Scholar] [CrossRef] [PubMed]
- Hjelm, N.M. Benefits and Drawbacks of Telemedicine. In Introduction to Telemedicine, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2017; pp. 134–149. [Google Scholar]
- Cesari, U.; De Pietro, G.; Marciano, E.; Niri, C.; Sannino, G.; Verde, L. A New Database of Healthy and Pathological Voices. Comput. Electr. Eng. 2018, 68, 310–321. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Verde, L.; De Pietro, G.; Veltri, P.; Sannino, G. An M-Health System for the Estimation of Voice Disorders. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 2; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- Yoon, H. Finding Unexpected Test Accuracy by Cross Validation in Machine Learning. Int. J. Comput. Sci. Netw. Secur. 2021, 21, 549–555. [Google Scholar]
- Di Credico, A.; Perpetuini, D.; Izzicupo, P.; Gaggi, G.; Cardone, D.; Filippini, C.; Merla, A.; Ghinassi, B.; Di Baldassarre, A. Estimation of Heart Rate Variability Parameters by Machine Learning Approaches Applied to Facial Infrared Thermal Imaging. Front. Cardiovasc. Med. 2022, 9, 893374. [Google Scholar] [CrossRef]
- Chiarelli, A.M.; Perpetuini, D.; Croce, P.; Filippini, C.; Cardone, D.; Rotunno, L.; Anzoletti, N.; Zito, M.; Zappasodi, F.; Merla, A. Evidence of Neurovascular Un-Coupling in Mild Alzheimer’s Disease through Multimodal EEG-fNIRS and Multivariate Analysis of Resting-State Data. Biomedicines 2021, 9, 337. [Google Scholar] [CrossRef]
- Perpetuini, D.; Di Credico, A.; Filippini, C.; Izzicupo, P.; Cardone, D.; Chiacchiaretta, P.; Ghinassi, B.; Di Baldassarre, A.; Merla, A. Is It Possible to Estimate Average Heart Rate from Facial Thermal Imaging? Eng. Proc. 2021, 8, 10. [Google Scholar]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear Discriminant Analysis: A Detailed Tutorial. Ai Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support Vector Machines: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 2001; Volume 2049, pp. 249–257. [Google Scholar]
- Zhang, Z. Introduction to Machine Learning: K-Nearest Neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Lin, C.-J. A Comparison of Methods for Multiclass Support Vector Machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef]
- Lu, L.; Zhang, H.-J.; Li, S.Z. Content-Based Audio Classification and Segmentation by Using Support Vector Machines. Multimed. Syst. 2003, 8, 482–492. [Google Scholar] [CrossRef]
- Kostyuchenko, E.; Rakhmanenko, I.; Balatskaya, L. Assessment of Speech Quality During Speech Rehabilitation Based on the Solution of the Classification Problem. In Proceedings of the Speech and Computer; Prasanna, S.R.M., Karpov, A., Samudravijaya, K., Agrawal, S.S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 382–390. [Google Scholar]
- Mary, L.; Yegnanarayana, B. Extraction and Representation of Prosodic Features for Language and Speaker Recognition. Speech Commun. 2008, 50, 782–796. [Google Scholar] [CrossRef]
- Mukherjee, H.; Obaidullah, S.M.; Santosh, K.C.; Phadikar, S.; Roy, K. Line Spectral Frequency-Based Features and Extreme Learning Machine for Voice Activity Detection from Audio Signal. Int. J. Speech Technol. 2018, 21, 753–760. [Google Scholar] [CrossRef]
- Karan, B.; Sahu, S.S.; Orozco-Arroyave, J.R.; Mahto, K. Non-Negative Matrix Factorization-Based Time-Frequency Feature Extraction of Voice Signal for Parkinson’s Disease Prediction. Comput. Speech Lang. 2021, 69, 101216. [Google Scholar] [CrossRef]
- Lugger, M.; Yang, B. The Relevance of Voice Quality Features in Speaker Independent Emotion Recognition. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-17–IV-20. [Google Scholar]
- Keller, E. The Analysis of Voice Quality in Speech Processing. In International School on Neural Networks, Initiated by IIASS and EMFCSC; Springer: Berlin/Heidelberg, Germany, 2004; pp. 54–73. [Google Scholar]
- Chen, L.; Wang, C.; Chen, J.; Xiang, Z.; Hu, X. Voice Disorder Identification by Using Hilbert-Huang Transform (HHT) and K Nearest Neighbor (KNN). J. Voice 2021, 35, 932.e1–932.e11. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Chen, J. Deep Neural Network for Automatic Classification of Pathological Voice Signals. J. Voice 2022, 36, 288.e15–288.e24. [Google Scholar] [CrossRef]
- Zhang, X.; Ding, Y.; Zhao, H.; Yi, L.; Guo, T.; Li, A.; Zou, Y. Mixed Skewness Probability Modeling and Extreme Value Predicting for Physical System Input–Output Based on Full Bayesian Generalized Maximum-Likelihood Estimation. IEEE Trans. Instrum. Meas. 2024, 73, 2504516. [Google Scholar] [CrossRef]
- Filippini, C.; Di Crosta, A.; Palumbo, R.; Perpetuini, D.; Cardone, D.; Ceccato, I.; Di Domenico, A.; Merla, A. Automated Affective Computing Based on Bio-Signals Analysis and Deep Learning Approach. Sensors 2022, 22, 1789. [Google Scholar] [CrossRef]
- Schaffer, C. Selecting a Classification Method by Cross-Validation. Mach. Learn. 1993, 13, 135–143. [Google Scholar] [CrossRef]
- Compton, E.C.; Cruz, T.; Andreassen, M.; Beveridge, S.; Bosch, D.; Randall, D.R.; Livingstone, D. Developing an Artificial Intelligence Tool to Predict Vocal Cord Pathology in Primary Care Settings. Laryngoscope 2023, 133, 1952–1960. [Google Scholar] [CrossRef]
- Hireš, M.; Gazda, M.; Drotar, P.; Pah, N.D.; Motin, M.A.; Kumar, D.K. Convolutional Neural Network Ensemble for Parkinson’s Disease Detection from Voice Recordings. Comput. Biol. Med. 2022, 141, 105021. [Google Scholar] [CrossRef]
- Mahmood, A.; Mehroz Khan, M.; Imran, M.; Alhajlah, O.; Dhahri, H.; Karamat, T. End-to-End Deep Learning Method for Detection of Invasive Parkinson’s Disease. Diagnostics 2023, 13, 1088. [Google Scholar] [CrossRef]
- Perpetuini, D.; Filippini, C.; Cardone, D.; Merla, A. An Overview of Thermal Infrared Imaging-Based Screenings during Pandemic Emergencies. Int. J. Environ. Res. Public. Health 2021, 18, 3286. [Google Scholar] [CrossRef]
- Maor, E.; Tsur, N.; Barkai, G.; Meister, I.; Makmel, S.; Friedman, E.; Aronovich, D.; Mevorach, D.; Lerman, A.; Zimlichman, E. Noninvasive Vocal Biomarker Is Associated with Severe Acute Respiratory Syndrome Coronavirus 2 Infection. Mayo Clin. Proc. Innov. Qual. Outcomes 2021, 5, 654–662. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section | Options | Values (Number of Subjects) |
|---|---|---|
| General Information | Age Gender Diagnosis Occupational status | Healthy (58), reflux laryngitis (39), hypokinetic dysphonia (41), hyperkinetic dysphonia (70) |
| Medical Questionnaires | Voice Handicap Index (VHI) Reflux Symptom Index (RSI) | 0–120 0–45 |
| Smoking Habits | Smoker Number of cigarettes smoked per day | No, casual smoker, habitual |
| Drinking habits | Alcohol consumption Number of glasses containing alcoholic beverage drunk in a day Amount of water’s liters drunk every day | No, casual drinker, habitual drinker |
| Model | Train: Average Accuracy | Test: Average Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| Linear Discriminant | 90.6% | 90.5% | 89.2% | 91.8% |
| Linear SMV | 91.2% | 91.5% | 92.7% | 90.3% |
| Quadratic SMV | 95.1% | 95.7% | 94.4% | 97.0% |
| Cubic SMV | 95.7% | 96.4% | 98.4% | 94.4% |
| Fine KNN | 98.0% | 98.3% | 98.3% | 98.3% |
| Narrow Neural Network | 94.6% | 95.4% | 94.2% | 96.6% |
| Medium Neural Network | 95.3% | 96.5% | 97.7% | 95.3% |
| Wide Neural Network | 95.7% | 95.4% | 94.2% | 96.6% |
| Bilayerd Neural Network | 95.0% | 94.0% | 92.0% | 96.0% |
| Trilayered Neural Network | 94.7% | 94.9% | 94.1% | 95.7% |
| Model | Train: Average Accuracy | Test: Average Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| Linear Discriminant | 70.1% | 75.5% | 71.8% | 80.7% |
| Linear SMV | 71.4% | 74.5% | 75.8% | 73.2% |
| Quadratic SMV | 86.5% | 85.5% | 91.5% | 79.5% |
| Cubic SMV | 92.5% | 93.8% | 94.0% | 93.6% |
| Fine KNN | 96.3% | 95.5% | 95.0% | 96.0% |
| Narrow Neural Network | 89.1% | 88.7% | 90.9% | 86.5% |
| Medium Neural Network | 90.8% | 90.5% | 90.0% | 91.0% |
| Wide Neural Network | 92.9% | 92.2% | 91.6% | 92.9% |
| Bilayerd Neural Network | 89.9% | 89.7% | 92.9% | 86.5% |
| Trilayered Neural Network | 89.2% | 89.8% | 93.0% | 86.6% |
| Model | Train: Average Accuracy | Test: Average Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| Linear Discriminant | 66.7% | 66.7% | 69.9% | 63.5% |
| Linear SMV | 60.5% | 67.3% | 66.9% | 67.7% |
| Quadratic SMV | 67.1% | 80.0% | 79.5% | 80.5% |
| Cubic SMV | 76.9% | 96.7% | 95.9% | 97.5% |
| Fine KNN | 98.3% | 98.3% | 97.9% | 98.4% |
| Narrow Neural Network | 98.5% | 90.5% | 90.0% | 91.0% |
| Medium Neural Network | 92.3% | 92.5% | 92.1% | 92.9% |
| Wide Neural Network | 92.4% | 93.9% | 92.7% | 94.1% |
| Bilayerd Neural Network | 90.6% | 93.0% | 92.5% | 93.5% |
| Trilayered Neural Network | 90.3% | 89.7% | 92.9% | 86.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Cesare, M.G.; Perpetuini, D.; Cardone, D.; Merla, A. Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones. BioMedInformatics 2024, 4, 549-565. https://doi.org/10.3390/biomedinformatics4010031
Di Cesare MG, Perpetuini D, Cardone D, Merla A. Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones. BioMedInformatics. 2024; 4(1):549-565. https://doi.org/10.3390/biomedinformatics4010031
Chicago/Turabian StyleDi Cesare, Michele Giuseppe, David Perpetuini, Daniela Cardone, and Arcangelo Merla. 2024. "Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones" BioMedInformatics 4, no. 1: 549-565. https://doi.org/10.3390/biomedinformatics4010031
APA StyleDi Cesare, M. G., Perpetuini, D., Cardone, D., & Merla, A. (2024). Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones. BioMedInformatics, 4(1), 549-565. https://doi.org/10.3390/biomedinformatics4010031