
Towards Automated Meta-Analysis of Clinical Trials: An Overview


Abstract
1. Introduction
- RQ1. What are the trends and key characteristics of studies showing automation in the meta-analysis and synthesis of clinical trial data.
- RQ2. What are the most common technologies, methods, tools, and software used in the meta-analysis and synthesis of data extracted from clinical trials.
- RQ3. What are the impacts that derive from the usage of the automation in the meta-analysis in clinical trials.
- RQ4. What are the challenges, guidelines, and obstacles to be addressed and what studies and research are proposed to achieve automation and maximum and reliable application of clinical trial results in daily medical practices.
2. Related Work
3. Materials and Methods
3.1. Study Design
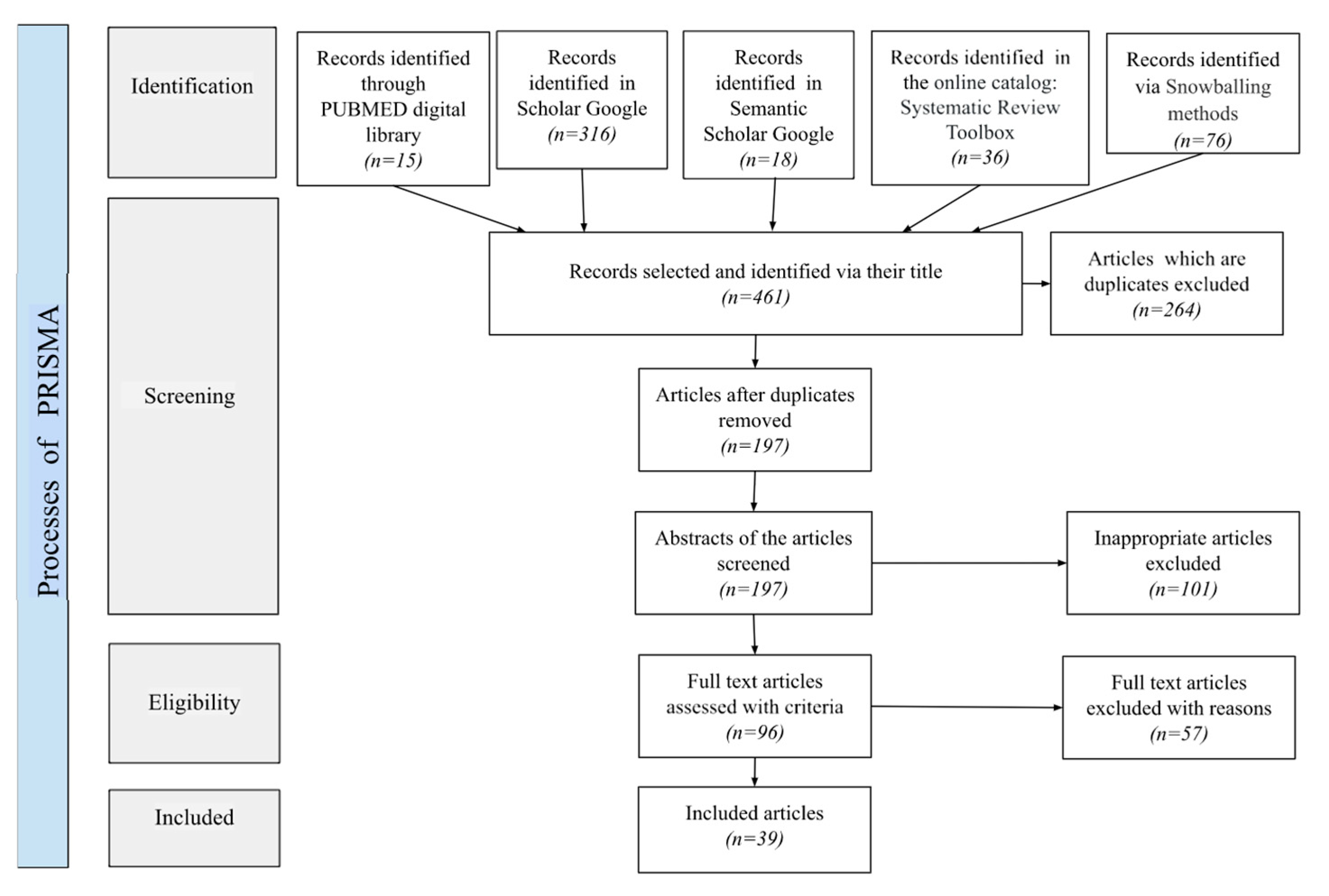
3.2. Literature Search and Study Selection
3.3. Data Screening
3.4. Data Extraction and Analyses
- Bibliographic elements of the included articles:
- ■
- Name of the studies’ object
- ■
- Reference
- ■
- Title
- ■
- Year
- ■
- Author(s)
- ■
- Journal
- Characteristics of the studies’ object:
- ■
- Name studies’ object
- ■
- Domain
- ■
- Type
- ■
- (Not)Free/(Not)Open
- ■
- Source Code
- ■
- Method/Language
4. Results
4.1. Framework/Tool (Includes 16 Studies)
- Caffe2 [32]
- CINeMA [33]
- OpenNN [43]
- Pymeta [44]
- PythonMeta [45]
- PyTorch [46]
- scikit-learn [47]
- ShinyMDE [48]
- Spark ML [49]
- TensorFlow [50]
- Torch [51]
- NeuroSynth [54]
- Automated meta-analysis of the ERP literature [58]
- CancerMA [59]
- CancerEST [60]
4.2. Package/Software (Includes 7 Studies)
- Amamida R Package [29]
- dmetar [34]
- DTA MA (Diagnostic Test Accuracy Meta-Analysis) (MetaDTA) [35]
- Keras [36]
- Meta-Essentials [37]
- metafor [38]
- MetaXL [41]
4.3. Model/Method/Approach (Includes 10 Studies)
- A Logic of the Meta-Analysis approach [28]
- Causal Learning Perspective [5]
- DIAeT [11]
- metamisc [40]
- Comprehensive gene expression meta-analysis [53]
- Text-mining the neurosynth corpus (NeuroSynth #2) [55]
- Social brain (NeuroSynth #3) [56]
- MetaCyto [57]
- Research Method Classification [61]
- AUTOMETA [62]
4.4. Web Application and Integrated Systems (Includes 5 Studies)
- Automated meta-analysis of biomedical texts [10]
- MetaInsight [39]
- Nested-Knowledge [72]
- netmeta [42]
- Whyis [52]
5. Discussion
5.1. Purpose of This Study
5.2. Benefits Arising from Automated Meta-Analysis
5.3. Comparison of Systems and Tools Currently Available
5.4. Limitations of This Study
6. Conclusions and Future Directions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sargeant, J.M.; Kelton, D.F.; O’Connor, A. Study Designs and Systematic Reviews of Interventions: Building Evidence Across Study Designs. Zoonoses Public Health 2014, 61, 10–17. [Google Scholar] [CrossRef]
- Russo, M.W. How to Review a Meta-analysis. Gastroenterol. Hepatol. 2007, 3, 637–642. [Google Scholar]
- Masoumi, S.; Shahraz, S. Meta-analysis using Python: A hands-on tutorial. BMC Med. Res. Methodol. 2022, 22, 193. [Google Scholar] [CrossRef] [PubMed]
- Christopoulou, S.C. Machine Learning Tools and Platforms in Clinical Trial Outputs to Support Evidence-Based Health Informatics: A Rapid Review of the Literature. Biomedinformatics 2022, 2, 511–527. [Google Scholar] [CrossRef]
- Cheng, L.; Katz-Rogozhnikov, D.A.; Varshney, K.R.; Baldini, I.; Cheng, L.; Katz-Rogozhnikov, D.A.; Varshney, K.R.; Baldini, I. Automated Meta-Analysis: A Causal Learning Perspective. arXiv 2021, arXiv:2104.04633. [Google Scholar]
- Ajiji, P.; Cottin, J.; Picot, C.; Uzunali, A.; Ripoche, E.; Cucherat, M.; Maison, P. Feasibility study and evaluation of expert opinion on the semi-automated meta-analysis and the conventional meta-analysis. Eur. J. Clin. Pharmacol. 2022, 78, 1177–1184. [Google Scholar] [CrossRef]
- O’Connor, A.M.; Glasziou, P.; Taylor, M.; Thomas, J.; Spijker, R.; Wolfe, M.S. A focus on cross-purpose tools, automated recognition of study design in multiple disciplines, and evaluation of automation tools: A summary of significant discussions at the fourth meeting of the International Collaboration for Automation of Systematic Reviews (ICASR). Syst. Rev. 2020, 9, 100. [Google Scholar] [CrossRef]
- Zintzaras, E.; Lau, J. Trends in meta-analysis of genetic association studies. J. Hum. Genet. 2008, 53, 1–9. [Google Scholar] [CrossRef]
- Johnson, E.E.; O’Keefe, H.; Sutton, A.; Marshall, C. The Systematic Review Toolbox: Keeping up to date with tools to support evidence synthesis. Syst. Rev. 2022, 11, 258. [Google Scholar] [CrossRef]
- Devyatkin, D.; Molodchenkov, A.; Lukin, A.; Kim, Y.; Boyko, A.; Karalkin, P.; Chiang, J.-H.; Volkova, G.; Lupatov, A. Towards Automated Meta-analysis of Biomedical Texts in the Field of Cell-based Immunotherapy. Biomed. Chem. Res. Methods 2019, 2, e00109. [Google Scholar] [CrossRef]
- Sanchez-Graillet, O.; Witte, C.; Grimm, F.; Grautoff, S.; Ell, B.; Cimiano, P. Synthesizing evidence from clinical trials with dynamic interactive argument trees. J. Biomed. Semant. 2022, 13, 16. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, K.; Li, J.; Zhu, Y.; Zhang, Y. Various Frameworks and Libraries of Machine Learning and Deep Learning: A Survey. Arch. Comput. Methods Eng. 2019, 1–24. [Google Scholar] [CrossRef]
- Scott, A.M.; Forbes, C.; Clark, J.; Carter, M.; Glasziou, P.; Munn, Z. Systematic review automation tools improve efficiency but lack of knowledge impedes their adoption: A survey. J. Clin. Epidemiol. 2021, 138, 80–94. [Google Scholar] [CrossRef]
- Jaspers, S.; De Troyer, E.; Aerts, M. Machine learning techniques for the automation of literature reviews and systematic reviews in EFSA. EFSA Support. Publ. 2018, 15, 1427E. [Google Scholar] [CrossRef]
- Khalil, H.; Ameen, D.; Zarnegar, A. Tools to support the automation of systematic reviews: A scoping review. J. Clin. Epidemiol. 2021, 144, 22–42. [Google Scholar] [CrossRef]
- Beller, E.; On behalf of the founding members of the ICASR group; Clark, J.; Tsafnat, G.; Adams, C.; Diehl, H.; Lund, H.; Ouzzani, M.; Thayer, K.; Thomas, J.; et al. Making progress with the automation of systematic reviews: Principles of the International Collaboration for the Automation of Systematic Reviews (ICASR). Syst. Rev. 2018, 7, 77. [Google Scholar] [CrossRef]
- Cowie, K.; Rahmatullah, A.; Hardy, N.; Holub, K.; Kallmes, K. Web-Based Software Tools for Systematic Literature Review in Medicine: Systematic Search and Feature Analysis. JMIR Med. Inform. 2021, 10, e33219. [Google Scholar] [CrossRef]
- Khangura, S.; Konnyu, K.; Cushman, R.; Grimshaw, J.; Moher, D. Evidence summaries: The evolution of a rapid review approach. Syst. Rev. 2012, 1, 10. [Google Scholar] [CrossRef]
- Oxman, A.D. Users’ guides to the medical literature. VI. How to use an overview. Evidence-Based Medicine Working Group. JAMA 1994, 272, 1367–1371. [Google Scholar] [CrossRef]
- Grant, M.J.; Booth, A. A typology of reviews: An analysis of 14 review types and associated methodologies. Health Inf. Libr. J. 2009, 26, 91–108. [Google Scholar] [CrossRef]
- Greenhalgh, T.; Peacock, R. Effectiveness and efficiency of search methods in systematic reviews of complex evidence: Audit of primary sources. BMJ 2005, 331, 1064–1065. [Google Scholar] [CrossRef] [PubMed]
- Shehzad, Z.; Kelly, C.; Reiss, P.T.; Craddock, R.C.; Emerson, J.W.; McMahon, K.; Copland, D.A.; Castellanos, F.X.; Milham, M.P. A multivariate distance-based analytic framework for connectome-wide association studies. Neuroimage 2014, 93, 74–94. [Google Scholar] [CrossRef] [PubMed]
- Ewendelken, C. Meta-analysis: How does posterior parietal cortex contribute to reasoning? Front. Hum. Neurosci. 2015, 8, 1042. [Google Scholar] [CrossRef] [PubMed]
- Chavez, R.S.; Heatherton, T.F. Representational Similarity of Social and Valence Information in the Medial pFC. J. Cogn. Neurosci. 2015, 27, 73–82. [Google Scholar] [CrossRef]
- Chawla, M.; Miyapuram, K.P. Comparison of meta-analysis approaches for neuroimaging studies of reward processing: A case study. In Proceedings of the 2015 International Joint Conference, Killarney, Ireland, 12–17 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Dockès, J.; A Poldrack, R.; Primet, R.; Gözükan, H.; Yarkoni, T.; Suchanek, F.; Thirion, B.; Varoquaux, G. NeuroQuery, comprehensive meta-analysis of human brain mapping. Elife 2020, 9, e53385. [Google Scholar] [CrossRef]
- Muller, A.M.; Meyer, M. Language in the brain at rest: New insights from resting state data and graph theoretical analysis. Front. Hum. Neurosci. 2014, 8, 228. [Google Scholar] [CrossRef]
- Peñaloza, R. Towards a Logic of Meta-Analysis. In Proceedings of the 17th International Conference on Principles of Knowledge Representation and Reasoning, Rhodes, Greece, 12–18 September 2020. [Google Scholar]
- Llambrich, M.; Correig, E.; Gumà, J.; Brezmes, J.; Cumeras, R. Amanida: An R package for meta-analysis of metabolomics non-integral data. Bioinformatics 2021, 38, 583–585. [Google Scholar] [CrossRef]
- Hsieh, M. Getting Started with Amazon SageMaker Studio: Learn to Build End-to-End Machine Learning Projects in the SageMaker Machine Learning IDE.; Packt Publishing Ltd.: Birmingham, UK, 2022. [Google Scholar]
- Simon, J. Learn Amazon SageMaker: A Guide to Building, Training, and Deploying Machine Learning Models for Developers and Data Scientists; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Hazelwood, K.; Bird, S.; Brooks, D.; Chintala, S.; Diril, U.; Dzhulgakov, D.; Fawzy, M.; Jia, B.; Jia, Y.; Kalro, A. Applied machine learning at Facebook: A datacenter infrastructure perspective. In Proceedings of the 2018 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 620–629. [Google Scholar]
- Nikolakopoulou, A.; Higgins, J.P.T.; Papakonstantinou, T.; Chaimani, A.; Del Giovane, C.; Egger, M.; Salanti, G. CINeMA: An approach for assessing confidence in the results of a network meta-analysis. PLoS Med. 2020, 17, e1003082. [Google Scholar] [CrossRef]
- Harrer, M.; Cuijpers, P.; Furukawa, T.A.; Ebert, D.D. Doing Meta-Analysis with R: A Hands-On Guide; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Patel, A.; Cooper, N.; Freeman, S.; Sutton, A. Graphical enhancements to summary receiver operating characteristic plots to facilitate the analysis and reporting of meta-analysis of diagnostic test accuracy data. Res. Synth. Methods 2020, 12, 34–44. [Google Scholar] [CrossRef]
- Ketkar, N. Introduction to Keras. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 97–111. [Google Scholar]
- Suurmond, R.; van Rhee, H.; Hak, T. Introduction, comparison, and validation of Meta-Essentials: A free and simple tool for meta-analysis. Res. Synth. Methods 2017, 8, 537–553. [Google Scholar] [CrossRef]
- Viechtbauer, W. Conducting Meta-Analyses in R with the metafor Package. J. Stat. Softw. 2010, 36, 1–48. [Google Scholar] [CrossRef]
- Owen, R.K.; Bradbury, N.; Xin, Y.; Cooper, N.; Sutton, A. MetaInsight: An interactive web-based tool for analyzing, interrogating, and visualizing network meta-analyses using R-shiny and netmeta. Res. Synth. Methods 2019, 10, 569–581. [Google Scholar] [CrossRef] [PubMed]
- Debray, T.P.; Damen, J.A.; Riley, R.D.; Snell, K.; Reitsma, J.B.; Hooft, L.; Collins, G.S.; Moons, K.G. A framework for meta-analysis of prediction model studies with binary and time-to-event outcomes. Stat. Methods Med. Res. 2018, 28, 2768–2786. [Google Scholar] [CrossRef] [PubMed]
- Doi, S.A.; Barendregt, J.J.; Khan, S.; Thalib, L.; Williams, G.M. Advances in the meta-analysis of heterogeneous clinical trials I: The inverse variance heterogeneity model. Contemp. Clin. Trials 2015, 45, 130–138. [Google Scholar] [CrossRef]
- Network Meta-Analysis Using Frequentist Methods [R Package Netmeta Version 0.9-8]. Available online: https://CRAN.R-project.org/package=netmeta (accessed on 29 December 2022).
- Open NN: An Open Source Neural Networks C++ Library. Available online: http://opennn.cimne.com (accessed on 30 December 2022).
- Hongyong, D. PyMeta. 2018. Available online: www.pymeta.com (accessed on 27 November 2022).
- Hongyong, D. PythonMeta 1.26. 2018. Available online: https://pypi.org/project/PythonMeta/ (accessed on 28 December 2022).
- The Linux Foundation. PyTorch. Available online: https://pytorch.org/ (accessed on 31 December 2022).
- Kramer, O. Machine Learning for Evolution Strategies; Springer: Cham, Switzerland, 2016; p. 20. [Google Scholar] [CrossRef]
- Shashirekha, H.L.; Wani, A.H. ShinyMDE: Shiny tool for microarray meta-analysis for differentially expressed gene detection. In Proceedings of the 2016 International Conference on Bioinformatics and Systems Biology (BSB), Allahabad, India, 4–6 March 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Polak, A. Scaling Machine Learning with Spark: Distributed ML with MLlib, TensorFlow, and Pytorch; O’Reilly Media: Sebastopol, CA, USA, 2023. [Google Scholar]
- Hope, T.; Resheff, Y.; Lieder, I. Learning TensorFlow: A Guide to Building Deep Learning Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Collobert, R.; Kavukcuoglu, K.; Farabet, C. Torch7: A Matlab-like Environment for Machine Learning. Available online: https://ronan.collobert.com/pub/matos/2011_torch7_nipsw.pdf (accessed on 31 December 2022).
- McCusker, J.P.; Rashid, S.M.; Agu, N.; Bennett, K.P.; McGuinness, D.L. Developing Scientific Knowledge Graphs Using Whyis. In SemSci@ ISWC; Rensselaer Polytechnic Ins.: Troy, NY, USA, 2018; pp. 52–58. [Google Scholar]
- Afroz, S.; Giddaluru, J.; Vishwakarma, S.; Naz, S.; Khan, A.A.; Khan, N. A Comprehensive Gene Expression Meta-analysis Identifies Novel Immune Signatures in Rheumatoid Arthritis Patients. Front. Immunol. 2017, 8, 74. [Google Scholar] [CrossRef]
- Yarkoni, T.; Poldrack, R.; Nichols, T.; Van Essen, D.C.; Wager, T.D. Large-scale automated synthesis of human functional neuroimaging data. Nat. Methods 2011, 8, 665–670. [Google Scholar] [CrossRef]
- Monti, R.; Lorenz, R.; Leech, R.; Anagnostopoulos, C.; Montana, G. Text-mining the neurosynth corpus using deep boltzmann machines. In Proceedings of the 2016 International Workshop on Pattern Recognition in Neuroimaging (PRNI), Trento, Italy, 22–24 June 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Tso, I.F.; Rutherford, S.; Fang, Y.; Angstadt, M.; Taylor, S.F. The “social brain” is highly sensitive to the mere presence of social information: An automated meta-analysis and an independent study. PLoS ONE 2018, 13, e0196503. [Google Scholar] [CrossRef]
- Hu, Z.; Jujjavarapu, C.; Hughey, J.J.; Andorf, S.; Lee, H.-C.; Gherardini, P.F.; Spitzer, M.H.; Thomas, C.G.; Campbell, J.; Dunn, P.; et al. MetaCyto: A Tool for Automated Meta-analysis of Mass and Flow Cytometry Data. Cell Rep. 2018, 24, 1377–1388. [Google Scholar] [CrossRef]
- Donoghue, T.; Voytek, B. Automated meta-analysis of the event-related potential (ERP) literature. Sci. Rep. 2022, 12, 1867. [Google Scholar] [CrossRef]
- Feichtinger, J.; McFarlane, R.J.; Larcombe, L.D. CancerMA: A web-based tool for automatic meta-analysis of public cancer microarray data. Database 2012, 2012, bas055. [Google Scholar] [CrossRef]
- Feichtinger, J.; McFarlane, R.J.; Larcombe, L.D. CancerEST: A web-based tool for automatic meta-analysis of public EST data. Database 2014, 2014, bau024. [Google Scholar] [CrossRef] [PubMed]
- Anisienia, A.; Mueller, R.M.; Kupfer, A.; Staake, T. Research Method Classification with Deep Transfer Learning for Semi-Automatic Meta-Analysis of Information Systems Papers. In Proceedings of the 54th Hawaii International Conference on System Sciences, online, 4–9 January 2021; pp. 6099–6108. [Google Scholar] [CrossRef]
- Mutinda, F.W.; Yada, S.; Wakamiya, S.; Aramaki, E. AUTOMETA: Automatic Meta-Analysis System Employing Natural Language Processing. Stud. Health Technol. Inform. 2022, 290, 612–616. [Google Scholar] [CrossRef]
- LISC-Literature Scanner-Lisc 0.2.0 Documentation. Available online: https://lisc-tools.github.io/lisc/ (accessed on 23 January 2023).
- Whitlock, M.C. Combining probability from independent tests: The weighted Z-method is superior to Fisher’s approach. J. Evol. Biol. 2005, 18, 1368–1373. [Google Scholar] [CrossRef] [PubMed]
- Schröder, M.S.; Culhane, A.C.; Quackenbush, J.; Haibe-Kains, B. survcomp: An R/Bioconductor package for performance assessment and comparison of survival models. Bioinformatics 2011, 27, 3206–3208. [Google Scholar] [CrossRef] [PubMed]
- Larionov, D.; Moscow, R.F.C.R.; Shelmanov, A.; Chistova, E.; Smirnov, I. Semantic Role Labeling with Pretrained Language Models for Known and Unknown Predicates. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019); INCOMA Ltd.: Varna, Bulgaria, 2019; pp. 619–628. [Google Scholar] [CrossRef]
- Aronson, A.R.; Lang, F.-M. An overview of MetaMap: Historical perspective and recent advances. J. Am. Med. Inform. Assoc. 2010, 17, 229–236. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Paper, Valencia, Spain, 3–7 April 2017. [Google Scholar]
- Srikant, R. Fast Algorithms for Mining Association Rules and Sequential Patterns; The University of Wisconsin-Madison: Madison, WI, USA, 1996. [Google Scholar]
- Srikant, R.; Agrawal, R. Mining quantitative association rules in large relational tables. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data—SIGMOD ’96, Montreal, QC, Canada, 4–6 June 1996. [Google Scholar] [CrossRef]
- Zaki, M. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef]
- Nested Knowledge Features. Available online: https://about.nested-knowledge.com/ (accessed on 31 December 2022).
- McCusker, J.P.; Dumontier, M.; Yan, R.; He, S.; Dordick, J.S.; McGuinness, D.L. Finding melanoma drugs through a probabilistic knowledge graph. Peer J. Comput. Sci. 2017, 3, e106. [Google Scholar] [CrossRef]
- Holzinger, A. Machine Learning for Health Informatics: State-of-the-Art and Future Challenges; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]


{kind=link}
| Name | Reference | Title | Year | Author(s) | Journal |
|---|---|---|---|---|---|
| A Logic of Meta-Analysis approach | [28] | Towards a Logic of Meta-Analysis | 2020 | Peñaloza, R | Proceedings of the International Conference on |
| Amamida R Package | [29] | Amanida: An R package for meta-analysis of metabolomics non-integral data | 2022 | Llambrich, Maria; Correig, Eudald; Gumà, Josep; Brezmes, Jesús; Cumeras, Raquel | Bioinformatics |
| Amazon SageMaker | [30,31] | Getting Started with Amazon SageMaker Studio: Learn to build end-to-end machine learning projects in the SageMaker machine learning IDE | 2022 | Hsieh, M | Packt Publishing Ltd. |
| Automated Meta-analysis of Biomedical Texts | [10] | Towards Automated Meta-analysis of Biomedical Texts in the Field of Cell-based Immunotherapy | 2019 | Devyatkin DA, Molodchenkov AI, Lukin AV et al. | Research and Methods |
| Caffe2 | [32] | Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective | 2018 | Hazelwood, K; et al. | IEEE International Symposium on High Performance Computer Architecture |
| Causal Learning Perspective | [5] | Automated Meta-Analysis: A Causal Learning Perspective | 2021 | Cheng, L; Katz-Rogozhnikov, D A; Varshney, K R; others | arXiv preprint |
| CINeMA | [33] | CINeMA: An approach for assessing confidence in the results of a network | 2020 | Nikolakopoulou, Adriani; Higgins, Julian P T; Papakonstantinou, Theodoros; Chaimani, Anna; Del Giovane, Cinzia; Egger, Matthias; Salanti, Georgia | PLOS Medicine |
| DIAeT | [11] | Synthesizing evidence from clinical trials with dynamic interactive | 2022 | Sanchez-Graillet; Witte, Olivia; Grimm, Christian; Grautoff, Frank; Ell, Steffen; Cimiano, Basil; Philipp | J. Biomed. Semantics |
| dmetar | [34] | Doing Meta-Analysis with R: A Hands-On Guide | 2021 | Harrer, Mathias; Cuijpers, Pim; Furukawa, Toshi A; Ebert, David D | CRC Press |
| DTA MA (Diagnostic Test Accuracy Meta-Analysis) (MetaDTA) | [35] | Graphical enhancements to summary receiver operating characteristic plots to facilitate the analysis and reporting of meta-analysis of diagnostic test accuracy data | 2021 | Patel, Amit; Cooper, Nicola; Freeman, Suzanne; Sutton, Alex | Res Synth Methods |
| Keras | [36] | Introduction to keras. In Deep learning with Python | 2017 | Ketkar, Nikhil | Apress, Berkeley, CA |
| Meta-Essentials | [37] | Introduction, comparison, and validation of Meta-Essentials: A free and simple tool for meta-analysis | 2017 | Suurmond, Robert; van Rhee, Henk; Hak, Tony | Res Synth Methods |
| metafor | [38] | Conducting Meta-Analyses in R with the metafor Package | 2010 | Viechtbauer, Wolfgang | Journal of Statistical Software |
| MetaInsight | [39] | MetaInsight: An interactive web-based tool for analyzing, interrogating, and visualizing network meta-analyses using R-shiny and netmeta | 2019 | Owen, Rhiannon K; Bradbury, Naomi; Xin, Yiqiao; Cooper, Nicola; Sutton, Alex | Res Synth Methods |
| metamisc | [40] | A framework for meta-analysis of prediction model studies with binary and time-to-event outcomes | 2019 | Debray, Thomas Pa; Damen, Johanna Aag; Riley, Richard D; Snell, Kym; Reitsma, Johannes B; Hooft, Lotty; Collins, Gary S; Moons, Karel Gm | Stat. Methods Med. Res. |
| MetaXL | [41] | Advances in the meta-analysis of heterogeneous clinical trials I: The | 2015 | Doi, Suhail A R; Barendregt, Jan J; Khan, Shahjahan; Thalib, Lukman; Williams, Gail M | Contemp. Clin. Trials |
| Nested-Knowledge | [17] | Web-Based Software Tools for Systematic Literature Review in Medicine: A Review and Feature Analysis | 2021 | Cowie; Rahmatullah, Kathryn; Hardy, Asad; Holub, Nicole; Kallmes, Karl; Kevin | Nested Knowledge, Inc. |
| netmeta | [42] | Network Meta-Analysis using Frequentist Methods [R package netmeta version 0.9-8 | 2022 | Rücker, Gerta; Krahn, Ulrike; König, Jochem; Efthimiou, Orestis; Davies, Annabel; Papakonstantinou, Theodoros; Schwarzer, Guido | CRAN package repository |
| OpenNN | [43] | Open NN: An Open Source Neural Networks C++ Library | 2022 | Lopez, Roberto | International Center for Numerical Methods in Engineering (CIMNE) |
| Pymeta | [44] | PyMeta | 2018 | Hongyong, Deng | PythonMeta Website |
| PythonMeta | [45] | PythonMeta 1.26 | 2018 | Hongyong, Deng | PythonMeta Website |
| PyTorch | [46] | PyTorch | Not found | PyTorch–Linux Foundation | |
| scikit-learn | [47] | scikit-learn | 2016 | Python Software Foundation | Python Software Foundation |
| ShinyMDE | [48] | ShinyMDE: Shiny tool for microarray meta-analysis for differentially expressed gene detection | 2016 | Shashirekha, H. L.; Wani, Agaz Hussain | HLS and team |
| Spark ML | [49] | Scaling Machine Learning with Spark: Distributed ML with MLlib, TensorFlow, and Pytorch | 2023 | Polak, A. | O’Reilly Media |
| TensorFlow | [50] | Learning TensorFlow: A Guide to Building Deep Learning Systems | 2017 | Hope, Tom; Resheff, Yehezkel S.; Lieder, Itay | O’Reilly Media |
| Torch | [51] | Torch7: A Matlab-like Environment for Machine Learning | 2019 | Collobert, Ronan; Kavukcuoglu, Koray; Farabet, Clement | Neural Information Processing Systems |
| Whyis | [52] | Developing Scientific Knowledge Graphs Using Whyis | 2018 | McCusker, J.P., Rashid, S.M., Agu, N., Bennett, K.P. and McGuinness, D.L. | SemSci |
| Comprehensive gene expression meta-analysis | [53] | A comprehensive gene expression meta-analysis identifies novel immune signatures in rheumatoid arthritis patients | 2017 | Afroz, S.; Giddaluru, J.; Vishwakarma, S.; Naz, S.; Khan, A.A.; Khan, N. | Frontiers in |
| NeuroSynth | [54] | Large-scale automated synthesis of human functional neuroimaging data | 2011 | Yarkoni T, Poldrack RA, Nichols TE, Van Essen DC, Wager TD | Nat. Methods |
| Text-mining the neurosynth corpus (NeuroSynth #2) | [55] | Text-mining the neurosynth corpus using deep boltzmann machines | 2016 | Monti R, Lorenz R, Leech R, Anagnostopoulos C, Montana G | 2016 International Workshop on Pattern Recognition in Neuroimaging |
| Social brain (NeuroSynth #3) | [56] | The “social brain” is highly sensitive to the mere presence of social information: An automated meta-analysis and an independent study | 2018 | Tso, Ivy F; Rutherford, Saige; Fang, Yu; Angstadt, Mike; Taylor, Stephan F | PLoS One |
| MetaCyto | [57] | MetaCyto: A Tool for Automated Meta-analysis of Mass and Flow Cytometry Data | 2018 | Hu Z, Jujjavarapu C, Hughey JJ, Andorf S, Lee HC, Gherardini PF et al. | Cell Rep. |
| Automated meta-analysis of the ERP literature | [58] | Automated meta-analysis of the event-related potential (ERP) literature | 2022 | Donoghue T, Voytek B | Sci. Rep. |
| CancerMA | [59] | CancerMA: a web-based tool for automatic meta-analysis of public cancer microarray data | 2012 | Feichtinger J, McFarlane RJ, Larcombe LD | Database |
| CancerEST | [60] | CancerEST: a web-based tool for automatic meta-analysis of public EST data | 2014 | Feichtinger J, McFarlane RJ, Larcombe LD | Database |
| Research Method Classification | [61] | Research Method Classification with Deep Transfer Learning for Semi-Automatic Meta-Analysis of Information Systems Papers | 2021 | Anisienia A, Mueller RM, Kupfer A, Staake T | Proceedings of the Annual Hawaii International Conference on System Sciences |
| AUTOMETA | [62] | AUTOMETA: Automatic Meta-Analysis System Employing Natural Language Processing | 2022 | Mutinda FW, Yada S, Wakamiya S, Aramaki E | Stud. Health Technol. Inform. |
| Name | Domain | Type | (Not)Free (Not)Open | Source Code | Method/Language |
|---|---|---|---|---|---|
| A Logic of Meta-Analysis approach | General purpose | Approach | No need | Not supported | Not supported |
| Amamida R Package | Metabolomic studies | Package | Open source | (https://github.com/mariallr/amanida, accessed on 23 December 2022) | R package |
| Amazon SageMaker | General purpose | Tool | Not free | (https://aws.amazon.com/sagemaker/resources/, accessed on 23 December 2022) | Python |
| Automated Meta-analysis of Biomedical Texts | Biomedical | All | Not described | No need | MetaMap; Fasttext model; Eclat algorithm/Python package |
| Caffe2 | General purpose | Framework | Open Source | (https://github.com/pytorch/pytorch, accessed on 22 December 2022) | Graph representation is shared among all backend implementation; C++ & Python API |
| Causal Learning Perspective | General purpose | Approach | No need | No need | Multiple Causal inference for automated Meta-Analysis (MCMA) |
| CINeMA | General purpose | Tool | Open source | (https://github.com/esm-ispm-unibe-ch/cinema, accessed on 25 December 2022) | Salanti approach; JavaScript, Docker, and R package |
| DIAeT | Evidence-based medicine (EBM) | Model/Method | Open source | (https://doi.org/10.5281/zenodo.5604516, accessed on 24 December 2022) | model Toulmin; Java |
| dmetar | General purpose | Package | Open source | (https://github.com/MathiasHarrer/Doing-Meta-Analysis-in-R, accessed on 25 December 2022; https://dmetar.protectlab.org/, accessed on 25 December 2022) | R package |
| DTA MA (Diagnostic Test Accuracy Meta-Analysis) (MetaDTA) | General purpose | Software | Open source | (https://github.com/CRSU-Apps/MetaDTA; https://crsu.shinyapps.io/dta_ma/, accessed on 25 December 2022) | R package |
| Keras | General purpose | Software | Open source | (https://keras.io/; https://github.com/keras-team/keras, accessed on 25 December 2022) | Python |
| Meta-Essentials | General purpose | Software | Open source | (https://www.erim.eur.nl/research-support/meta-essentials/download/, accessed on 26 December 2022; https://www.meta-essentials.com, accessed on 26 December 2022) | Excel files |
| metafor | General purpose | Software | Open source | (https://www.jstatsoft.org/article/view/v036i03, accessed on 27 December 2022) | R package |
| MetaInsight | General purpose | Web application | Not Open; Freely available | (https://crsu.shinyapps.io/metainsight, accessed on 22 December 2022) | Not described |
| metamisc | General purpose | Model/Method | Open source | (https://cran.r-project.org/web/packages/metamisc/index.html, accessed on 25 December 2022; https://github.com/smartdata-analysis-and-statistics/metamisc, accessed on 28 December 2022) | R package |
| MetaXL | Evidence-based medicine (EBM) | Software | Freely available | (http://www.epigear.com/index_files/metaxl.html, accessed on 27 December 2022) | Excel files |
| Nested-Knowledge | Evidence-based medicine (EBM) | Web application | Not free | (https://nested-knowledge.com/nest/qualitative/371, accessed on 26 December 2022) | Not described |
| netmeta | General purpose | Web application | Open source | (https://cran.r-project.org/web/packages/netmeta/index.html, accessed on 23 December 2022; https://github.com/guido-s/netmeta, accessed on 28 December 2022; https://link.springer.com/book/10.1007/978-3-319-21416-0, accessed on 26 December 2022; https://rdrr.io/cran/netmeta/src/R/netmeta.R, accessed on 26 December 2022) | R package |
| OpenNN | General purpose | Tool | Open source | (https://github.com/Artelnics/OpenNN, accessed on 27 December 2022; http://opennn.cimne.com/download.asp, accessed on 28 December 2022) | ANSI C++ |
| Pymeta | Evidence-based medicine (EBM) | Tool | Not Open | (https://www.pymeta.com/, accessed on 28 December 2022 | Python |
| PythonMeta | Evidence-based medicine (EBM) | Tool | Open source | https://pypi.org/project/PythonMeta/, accessed on 28 December 2022) | Python |
| PyTorch | Evidence-based medicine (EBM) | Tool | Open source | (https://github.com/pytorch/pytorch, accessed on 28 December 2022) | Python |
| scikit-learn | General purpose | Tool | Open source | (scikit-learn/scikit-learn: scikit-learn: machine learning in Python (github.com), accessed on 21 December 2022) | Python |
| ShinyMDE | genomics, molecular genetics | Tool | Not Open; Freely available | (https://hussain.shinyapps.io/App-1, accessed on 21 December 2022) | R package |
| Spark ML | General purpose | Tool | Open source | (https://github.com/apache/spark, accessed on 22 December 2022) | Java; Python; R |
| TensorFlow | General purpose | Tool | Open source | (https://github.com/tensorflow/tensorflow, accessed on 22 December 2022) | C++; Python |
| Torch | General purpose | Framework | Open source | (https://github.com/torch/torch7, accessed on 22 December 2022) | C++11; Lua; LuaJIT, C; CUDA and C++ |
| Whyis | General purpose | All | Open | (https://whyis.readthedocs.io/en/latest/index.html, accessed on 22 December 2022; https://github.com/tetherless-world/whyis, accessed on 22 December 2022) | probabilistic knowledge graphs by using Stouffer’s Z-Method/ Python; Flask framework; Fuseki; SPARQL; Graph Store HTTP Protocol; FileDepot Python library |
| Comprehensive gene expression meta-analysis | Biomedical | Method | Open | No need | Weighted Z-method/ survcomp R package |
| NeuroSynth | Medical | Framework | Open | (https://github.com/neurosynth, accessed on 26 December 2022) | naïve Bayes classification |
| Text-mining the neurosynth corpus (NeuroSynth #2) | Medical | Method | No need | No need | unsupervised study/ Deep Boltzmann machines for text-mining |
| Social brain (NeuroSynth #3) | Medical | Method | No need | (http://neurosynth.org/analyses/terms/social/, accessed on 28 December 2022) | Regions Of Interest (ROIs) analysis |
| MetaCyto | Biomedical | Method | No need | (http://bioconductor.org/packages/release/bioc/html/MetaCyto.html, accessed on 28 December 2022) | clustering methods with a scanning method/R package |
| Automated meta-analysis of the ERP literature | Medical | Tool | Open | (https://erpscanr.github.io/, accessed on 28 December 2022; https://github.com/ERPscanr/ERPscanr, accessed on 28 December 2022) | text-mining and word co-occurrence analyses |
| CancerMA | Biomedical | Tool | Open | (http://www.cancerma.org.uk, accessed on 28 December 2022) (not found) | HTML/CSS; Twitter Bootstrapp; Javascript/jQuery; Perl; R package; Bioconductor package |
| CancerEST | Biomedical | Tool | Open | (http://www.cancerest.org.uk/help.html http://www.cancerest.org.uk, accessed on 28 December 2022) (not found) | HTML/CSS; Twitter Bootstrapp; Javascript/jQuery; Perl; R package; Bioconductor package |
| Research Method Classification | General purpose | Method | No need | No need | Support Vector Models |
| AUTOMETA | Medical | Approach | No need | No need | BERT-based model |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christopoulou, S.C. Towards Automated Meta-Analysis of Clinical Trials: An Overview. BioMedInformatics 2023, 3, 115-140. https://doi.org/10.3390/biomedinformatics3010009
Christopoulou SC. Towards Automated Meta-Analysis of Clinical Trials: An Overview. BioMedInformatics. 2023; 3(1):115-140. https://doi.org/10.3390/biomedinformatics3010009
Chicago/Turabian StyleChristopoulou, Stella C. 2023. "Towards Automated Meta-Analysis of Clinical Trials: An Overview" BioMedInformatics 3, no. 1: 115-140. https://doi.org/10.3390/biomedinformatics3010009
APA StyleChristopoulou, S. C. (2023). Towards Automated Meta-Analysis of Clinical Trials: An Overview. BioMedInformatics, 3(1), 115-140. https://doi.org/10.3390/biomedinformatics3010009