
Application of Standardized Regression Coefficient in Meta-Analysis


Abstract
:1. Introduction
2. Standardized Regression Coefficient as an Effect-Size Index in Meta-Analysis
3. Literature Review of Applications
3.1. Public Health
3.2. Psychology
3.3. Other Sub-Fields
4. Meta-Analysis Example
4.1. Research Question
4.2. Material and Methods
4.2.1. Search Strategy
4.2.2. Screening of Studies
- (a)
- Type of study: prospective/retrospective longitudinal
- (b)
- Exposure: body mass index (BMI)
- (c)
- Age at measurement of body mass index: 2–19 years (childhood: 2–9 years; adolescence: 10–19 years)
- (d)
- Outcome: carotid intima-media thickness measured in adult (≥20 years)
- (e)
- Length of follow-up: at least 5 years
- (f)
- Mode of ascertainment of exposure and outcome: all measurements taken by health professionals or trained investigators or from medical records.
4.2.3. Data Synthesis and Analysis
4.3. Results
5. Detailed Description of Computations and Conversions
5.1. General
5.2. Obtaining Standardized Regression Coefficients
5.2.1. Coefficient β Reported from a Linear-Regression Model
5.2.2. Correlation Coefficient r Reported
5.2.3. Unstandardized Regression Coefficient b Reported
5.2.4. Mean Values of Outcome Variable Reported between Two Exposure Groups
- n1 = sample size in group 1 and n2 = sample size in group 2,
- M1 = mean value of response Y in group 1 and M2 = mean value in group 2
- SD1= standard deviation of Y in group 1 and SD2 standard deviation in group 2
- SD(Y) = full sample standard deviation oy outcome variable Y.
5.2.5. Mean Values of Outcome Variable Reported between More Than Two Exposure Groups
5.3. Obtaining Standard Error of Regression Coefficient from t-Value, p-Value or Confidence Interval
5.3.1. Standard Error from t-Value
5.3.2. Standard Error from p-Value
5.3.3. Standard Error from Confidence Interval
5.4. Pooling Betas from Two or More Independent Sub-Groups
- β1 = standardized regression coefficient among females,
- β2 = standardized regression coefficient among males,
- SE(β1) = SE of β1,
- SE(β2) = SE of β2,
- W1 = 1/(SE(β1))2 weight for females,
- W2 = 1/(SE(β2))2 weight for males.
5.5. Pooling Effect Sizes Measured in More Than One Time Point
5.6. Estimating SD of Reponse and Explonatory Variables
5.6.1. SD from Ranges
5.6.2. SD from Interquartile Range
5.6.3. SD from SE
5.6.4. Pooling Groups to Obtain SD
5.7. Other Topics
5.7.1. Interpretation with the Unit of Measurement of the Outcome Variable
5.7.2. Log-Transformed Data
5.7.3. Contacting Authors
5.7.4. Imputing Missing Statistics
6. Discussion
6.1. Issues Regarding the Conduction of Standardized Regression Coefficient
- (a)
- Different types of effect measures (e.g., correlation coefficients, regression coefficients, risk ratios, odd ratios and mean differences), which are not necessarily comparable.
- (b)
- Estimates without standard errors, which is a problem because meta-analysis methods typically weight each study by their standard error.
- (c)
- Estimates relating to various time points of the outcome occurrence or measurement.
- (d)
- Different methods of measurement for explanatory variables and outcomes.
- (e)
- Various sets of adjustment factors.
- (f)
- Different approaches to handling continuous explanatory variables (e.g., categorization, linear, non-linear trends, log-transforms), including the choice of cut point value when dichotomizing continuous values into “high” and “normal” groups.
6.1.1. Different Adjusted Covariates
6.1.2. Several Transformations and Conversions
6.1.3. Insufficient Reported Data
6.2. Meta-Analysis of Association between BMI and cIMT
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.T.; Rothstein, H.R. Introduction to Meta-Analysis, 2nd ed.; John Wiley & Sons, Ltd.: Oxford, UK, 2021; ISBN 978-1-119-55835-4. [Google Scholar]
- Lasserson, T.; Thomas, J.; Higgins, J.P.T. Chapter 1: Starting a review. In Cochrane Handbook for Systematic Reviews of Interventions; Higgins, J.P.T., Thomas, J., Chandler, J., Cumpston, M., Li, T., Page, M.J., Welch, V.A., Eds.; Cochrane: London, UK, 2022. [Google Scholar]
- Cooper, H.; Hedges, L.V. Research synthesis as a scientific process. In The Handbook of Research Synthesis and Meta-Analysis; Cooper, H., Hedges, L.V., Valentine, J.C., Eds.; Russell Sage Foundation: New York, NY, USA, 2009; pp. 3–16. ISBN 978-0-87154-163-5. [Google Scholar]
- Aloe, A.M.; Becker, B.J. An Effect Size for Regression Predictors in Meta-Analysis. J. Educ. Behav. Stat. 2012, 37, 278–297. [Google Scholar] [CrossRef]
- Nieminen, P.; Lehtiniemi, H.; Vähäkangas, K.; Huusko, A.; Rautio, A. Standardised regression coefficient as an effect size index in summarising findings in epidemiological studies. Epidemiol. Biostat. Public Health 2013, 10, e8854-2. [Google Scholar] [CrossRef]
- Epure, A.M.; Rios-Leyvraz, M.; Anker, D.; Di Bernardo, S.; da Costa, B.R.; Chiolero, A.; Sekarski, N. Risk factors during first 1000 days of life for carotid intima-media thickness in infants, children, and adolescents: A systematic review with meta-analyses. PLoS Med. 2020, 17, e1003414. [Google Scholar] [CrossRef]
- Lipsey, M.W.; Wilson, D.B. Practical Meta-Analysis; SAGE Publications: London, UK, 2000; ISBN 0-7619-2168-1. [Google Scholar]
- Aloe, A.M. Inaccuracy of regression results in replacing bivariate correlations. Res. Synth. Methods 2015, 6, 21–27. [Google Scholar] [CrossRef] [PubMed]
- Becker, B.J.; Wu, M.J. The synthesis of regression slopes in meta-analysis. Stat. Sci. 2007, 22, 414–429. [Google Scholar] [CrossRef]
- Kim, R.S. Standardized Regression Coefficients as Indices of Effect Sizes in Meta-Analysis. Ph.D. Thesis, The Florida State University, Tallahassee, FL, USA, 2011. [Google Scholar]
- Peterson, R.A.; Brown, S.P. On the use of beta coefficients in meta-analysis. J. Appl. Psychol. 2005, 90, 175–181. [Google Scholar] [CrossRef]
- Paul, P.A.; Lipps, P.E.; Madden, L.V. Meta-analysis of regression coefficients for the relationship between fusarium head blight and deoxynivalenol content of wheat. Phytopathology 2006, 96, 951–961. [Google Scholar] [CrossRef] [PubMed]
- Dzhambov, A.M.; Dimitrova, D.D.; Dimitrakova, E.D. Association between residential greenness and birth weight: Systematic review and meta-analysis. Urban For. Urban Green. 2014, 13, 621–629. [Google Scholar] [CrossRef]
- Wang, D.; Fu, X.; Zhang, J.; Xu, C.; Hu, Q.; Lin, W. Association between blood lead level during pregnancy and birth weight: A meta-analysis. Am. J. Ind. Med. 2020, 63, 1085–1094. [Google Scholar] [CrossRef]
- Pratt, T.C.; Cullen, F.T.; Sellers, C.S.; Winfree, L.T.; Madensen, T.D.; Daigle, L.E.; Fearn, N.E.; Gau, J.M. The Empirical Status of Social Learning Theory: A Meta-Analysis. Justice Q. 2010, 27, 765–802. [Google Scholar] [CrossRef]
- Rioux, C.; Castellanos-Ryan, N.; Parent, S.; Séguin, J.R. The interaction between temperament and the family environment in adolescent substance use and externalizing behaviors: Support for diathesis-stress or differential susceptibility? Dev. Rev. 2016, 40, 117–150. [Google Scholar] [CrossRef]
- Bowman, N.A. Effect Sizes and Statistical Methods for Meta-Analysis in Higher Education. Res. High. Educ. 2012, 53, 375–382. [Google Scholar] [CrossRef]
- Tian, Y.; Yao, J. The Impact of School Resource Investment on Student Performance: A Meta-analysis Based on Chinese Literature. SSRN Electron. J. 2020, 4, 389–410. [Google Scholar] [CrossRef]
- Abate, N. Obesity and cardiovascular disease: Pathogenetic role of the metabolic syndrome and therapeutic implications. J. Diabetes Complicat. 2000, 14, 154–174. [Google Scholar] [CrossRef]
- Sahoo, K.; Sahoo, B.; Choudhury, A.; Sofi, N.; Kumar, R.; Bhadoria, A. Childhood obesity: Causes and consequences. J. Fam. Med. Prim. Care 2015, 4, 187. [Google Scholar] [CrossRef]
- Lorenz, M.W.; Markus, H.S.; Bots, M.L.; Rosvall, M.; Sitzer, M. Prediction of clinical cardiovascular events with carotid intima-media thickness: A systematic review and meta-analysis. Circulation 2007, 115, 459–467. [Google Scholar] [CrossRef]
- Vach, W. Regression Models as a Tool in Medical Research; CRC Press: Boca Raton, FL, USA, 2013; ISBN 978-1-4665-17486. [Google Scholar]
- Vittinghoff, E.; Shiboski, S.C.; Glidden, D.V.; McCullogh, C.E. Regression Methods in Biostatistics: Linear, Logistic, Survival and Repeated Measures Models; Springer: Berlin/Heidelberg, Germany, 2005; ISBN 0-387-20275-7. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Erlbaum: Hillsdale, MI, USA, 1988; ISBN 0-8058-0283-5. [Google Scholar]
- Fey, C.F.; Hu, T.; Delios, A. The Measurement and Communication of Effect Sizes in Management Research. Manag. Organ. Rev. 2022, 1–22. [Google Scholar] [CrossRef]
- Shadish, W.R.; Haddock, C.K. Combining estimates of effect size. In The Handbook of Research Synthesis and Meta-Analysis, 2nd ed.; Russell Sage Foundation: New York, NY, USA, 2009; pp. 257–277. ISBN 978-0-87154-163-5. [Google Scholar]
- Deeks, J.J.; Higgins, J.P.; Altman, D.G. Chapter 10: Analysing data and undertaking meta-analyses. In Cochrane Handbook for Systematic Reviews of Interventions; Higgins, J.P.T., Thomas, J., Chandler, J., Cumpston, M., Li, T., Page, M.J., Welch, V.A., Eds.; Cochrane: London, UK, 2022. [Google Scholar]
- Gignac, G.E.; Szodorai, E.T. Effect size guidelines for individual differences researchers. Personal. Individ. Differ. 2016, 102, 74–78. [Google Scholar] [CrossRef]
- García-Hermoso, A.; Saavedra, J.M.; Ramírez-Vélez, R.; Ekelund, U.; del Pozo-Cruz, B. Reallocating sedentary time to moderate-to-vigorous physical activity but not to light-intensity physical activity is effective to reduce adiposity among youths: A systematic review and meta-analysis. Obes. Rev. 2017, 18, 1088–1095. [Google Scholar] [CrossRef]
- Ajala, O.; Mold, F.; Boughton, C.; Cooke, D.; Whyte, M. Childhood predictors of cardiovascular disease in adulthood. A systematic review and meta-analysis. Obes. Rev. 2017, 18, 1061–1070. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, C.; Mendes, V.; Peleteiro, B.; Delgado, I.; Araújo, J.; Aggerbeck, M.; Annesi-Maesano, I.; Sarigiannis, D.; Ramos, E. Association between the exposure to phthalates and adiposity: A meta-analysis in children and adults. Environ. Res. 2019, 179, 108780. [Google Scholar] [CrossRef]
- Ramsey, K.A.; Rojer, A.G.M.; D’Andrea, L.; Otten, R.H.J.; Heymans, M.W.; Trappenburg, M.C.; Verlaan, S.; Meskers, C.G.M.; Maier, A.B. The association of objectively measured physical activity and sedentary behavior with skeletal muscle strength and muscle power in older adults: A systematic review and meta-analysis. Ageing Res. Rev. 2021, 67, 101266. [Google Scholar] [CrossRef]
- Jones, M.D.; Booth, J.; Taylor, J.L.; Barry, B.K. Limited association between aerobic fitness and pain in healthy individuals: A cross-sectional study. Pain Med. 2016, 17, 1799–1808. [Google Scholar] [CrossRef]
- Burrows, N.J.; Barry, B.K.; Sturnieks, D.L.; Booth, J.; Jones, M.D. The Relationship between Daily Physical Activity and Pain in Individuals with Knee Osteoarthritis. Pain Med. 2020, 21, 2481–2495. [Google Scholar] [CrossRef]
- Mclaughlin, M.; Delaney, T.; Hall, A.; Byaruhanga, J.; Mackie, P.; Grady, A.; Reilly, K.; Campbell, E.; Sutherland, R.; Wiggers, J.; et al. Associations Between Digital Health Intervention Engagement, Physical Activity, and Sedentary Behavior: Systematic Review and Meta-analysis. J. Med. Internet Res. 2021, 23, e23180. [Google Scholar] [CrossRef]
- Woolley, K.; Fishbach, A. Immediate Rewards Predict Adherence to Long-Term Goals. Personal. Soc. Psychol. Bull. 2017, 43, 151–162. [Google Scholar] [CrossRef]
- Choi, I.; Lim, S.; Catapano, R.; Choi, J. Comparing two roads to success: Self-control predicts achievement and positive affect predicts relationships. J. Res. Pers. 2018, 76, 50–63. [Google Scholar] [CrossRef]
- Martinez-Calderon, J.; Flores-Cortes, M.; Morales-Asencio, J.M.; Luque-Suarez, A. Pain-Related Fear, Pain Intensity and Function in Individuals With Chronic Musculoskeletal Pain: A Systematic Review and Meta-Analysis. J. Pain 2019, 20, 1394–1415. [Google Scholar] [CrossRef]
- Martinez-Calderon, J.; Jensen, M.P.; Morales-Asencio, J.M.; Luque-Suarez, A. Pain Catastrophizing and Function in Individuals with Chronic Musculoskeletal Pain. Clin. J. Pain 2019, 35, 279–293. [Google Scholar] [CrossRef]
- Lee, Y.J.; Eck, J.E.; Corsaro, N. Conclusions from the history of research into the effects of police force size on crime—1968 through 2013: A historical systematic review. J. Exp. Criminol. 2016, 12, 431–451. [Google Scholar] [CrossRef]
- Park, S. Gender and performance in public organizations: A research synthesis and research agenda. Public Manag. Rev. 2021, 23, 929–948. [Google Scholar] [CrossRef]
- Araujo, J.; Patnam, M.; Popescu, A.; Valencia, F.; Yao, W. Effects of Macroprudential Policy: Evidence from Over 6000 Estimates; IMF Working Paper; International Monetary Fund: Washington, DC, USA, 2020. [Google Scholar]
- Raitakari, O.T.; Juonala, M.; Kähönen, M.; Taittonen, L.; Laitinen, T.; Mäki-Torkko, N.; Järvisalo, M.J.; Uhari, M.; Jokinen, E.; Rönnemaa, T.; et al. Cardiovascular Risk Factors in Childhood and Carotid Artery Intima-Media Thickness in Adulthood: The Cardiovascular Risk in Young Finns Study. J. Am. Med. Assoc. 2003, 290, 2277–2283. [Google Scholar] [CrossRef] [PubMed]
- Davis, P.H.; Dawson, J.D.; Riley, W.A.; Lauer, R.M. Carotid intimal-medial thickness is related to cardiovascular risk factors measured from childhood through middle age the muscatine Study. Circulation 2001, 104, 2815–2819. [Google Scholar] [CrossRef]
- Freedman, D.S.; Patel, D.A.; Srinivasan, S.R.; Chen, W.; Tang, R.; Bond, M.G.; Berenson, G.S. The contribution of childhood obesity to adult carotid intima-media thickness: The Bogalusa Heart Study. Int. J. Obes. 2008, 32, 749–756. [Google Scholar] [CrossRef] [PubMed]
- Khalil, A.; Huffman, M.D.; Prabhakaran, D.; Osmond, C.; Fall, C.H.D.; Tandon, N.; Lakshmy, R.; Prabhakaran, P.; Biswas, S.K.D.; Ramji, S.; et al. Predictors of carotid intima-media thickness and carotid plaque in young Indian adults: The New Delhi Birth Cohort. Int. J. Cardiol. 2013, 167, 1322–1328. [Google Scholar] [CrossRef]
- Oren, A.; Vos, L.E.; Uiterwaal, C.S.P.M.; Gorissen, W.H.M.; Grobbee, D.E.; Bots, M.L. Change in body mass index from adolescence to young adulthood and increased carotid intima-media thickness at 28 years of age: The Atherosclerosis Risk in Young Adults study. Int. J. Obes. 2003, 27, 1383–1390. [Google Scholar] [CrossRef]
- Charakida, M.; Khan, T.; Johnson, W.; Finer, N.; Woodside, J.; Whincup, P.H.; Sattar, N.; Kuh, D.; Hardy, R.; Deanfield, J. Lifelong patterns of BMI and cardiovascular phenotype in individuals aged 60-64 years in the 1946 British birth cohort study: An epidemiological study. Lancet Diabetes Endocrinol. 2014, 2, 648–654. [Google Scholar] [CrossRef]
- Terzis, I.D.; Papamichail, C.; Psaltopoulou, T.; Georgiopoulos, G.A.; Lipsou, N.; Chatzidou, S.; Kontoyiannis, D.; Kollias, G.; Iacovidou, N.; Zakopoulos, N.; et al. Long-term BMI changes since adolescence and markers of early and advanced subclinical atherosclerosis. Obesity 2012, 20, 414–420. [Google Scholar] [CrossRef]
- Lloyd, L.J.; Langley-Evans, S.C.; McMullen, S. Childhood obesity and adult cardiovascular disease risk: A systematic review. Int. J. Obes. 2010, 34, 18–28. [Google Scholar] [CrossRef]
- Juonala, M.; Magnussen, C.G.; Berenson, G.S.; Venn, A.; Burns, T.L.; Sabin, M.A.; Srinivasan, S.R.; Daniels, S.R.; Davis, P.H.; Chen, W.; et al. Childhood Adiposity, Adult Adiposity, and Cardiovascular Risk Factors. N. Engl. J. Med. 2011, 365, 1876–1885. [Google Scholar] [CrossRef] [Green Version]
- Ceponiene, I.; Klumbiene, J.; Tamuleviciute-Prasciene, E.; Motiejunaite, J.; Sakyte, E.; Ceponis, J.; Slapikas, R.; Petkeviciene, J. Associations between risk factors in childhood (12–13 years) and adulthood (48–49 years) and subclinical atherosclerosis: The Kaunas Cardiovascular Risk Cohort Study. BMC Cardiovasc. Disord. 2015, 15, 89. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Zhang, T.; Sun, D.; Li, C.; Bazzano, L.; Qi, L.; Krousel-Wood, M.; He, J.; Whelton, P.K.; Chen, W.; et al. Effect of Serum Adiponectin Levels on the Association Between Childhood Body Mass Index and Adulthood Carotid Intima-Media Thickness. Am. J. Cardiol. 2018, 121, 579–583. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, I.; Twisk, J.W.R.; Van Mechelen, W.; Kemper, H.C.G.; Seidell, J.C.; Stehouwer, C.D.A. Current and adolescent body fatness and fat distribution: Relationships with carotid intima-media thickness and large artery stiffness at the age of 36 years. J. Hypertens. 2004, 22, 145–155. [Google Scholar] [CrossRef]
- Freedman, D.S.; Dietz, W.H.; Tang, R.; Mensah, G.A.; Bond, M.G.; Urbina, E.M.; Srinivasan, S.; Berenson, G.S. The relation of obesity throughout life to carotid intima-media thickness in adulthood: The Bogalusa Heart Study. Int. J. Obes. 2004, 28, 159–166. [Google Scholar] [CrossRef] [PubMed]
- Hao, G.; Wang, X.; Treiber, F.A.; Harshfield, G.; Kapuku, G.; Su, S. Body mass index trajectories in childhood is predictive of cardiovascular risk: Results from the 23-year longitudinal Georgia Stress and Heart study. Int. J. Obes. 2018, 42, 923–925. [Google Scholar] [CrossRef] [PubMed]
- Hosseinpanah, F.; Seyedhoseinpour, A.; Barzin, M.; Mahdavi, M.; Tasdighi, E.; Dehghan, P.; Momeni Moghaddam, A.; Azizi, F.; Valizadeh, M. Comparison analysis of childhood body mass index cut-offs in predicting adulthood carotid intima media thickness: Tehran lipid and glucose study. BMC Pediatr. 2021, 21, 494. [Google Scholar] [CrossRef]
- Huynh, Q.; Blizzard, L.; Sharman, J.; Magnussen, C.; Schmidt, M.; Dwyer, T.; Venn, A. Relative contributions of adiposity in childhood and adulthood to vascular health of young adults. Atherosclerosis 2013, 228, 259–264. [Google Scholar] [CrossRef]
- Johnson, W.; Kuh, D.; Tikhonoff, V.; Charakida, M.; Woodside, J.; Whincup, P.; Hughes, A.D.; Deanfield, J.E.; Hardy, R. Body mass index and height from infancy to adulthood and carotid intima-media thickness at 60 to 64 years in the 1946 British Birth cohort study. Arterioscler. Thromb. Vasc. Biol. 2014, 34, 654–660. [Google Scholar] [CrossRef]
- Juonala, M.; Raitakari, M.; Viikari, J.S.A.; Raitakari, O.T. Obesity in youth is not an independent predictor of carotid IMT in adulthood: The Cardiovascular Risk in Young Finns Study. Atherosclerosis 2006, 185, 388–393. [Google Scholar] [CrossRef]
- Lee, Y.J.; Nam, C.M.; Kim, H.C.; Hur, N.W.; Suh, I. The association between obesity indices in adolescence and carotid intima-media thickness in young adults: Kangwha study. J. Prev. Med. Public Health 2008, 41, 107–114. [Google Scholar] [CrossRef]
- Wright, C.M.; Parker, L.; Lamont, D.; Craft, A.W. Implications of childhood obesity for adult health: Findings from thousand families cohort study. BMJ 2001, 323, 1280–1284. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Hou, D.; Liu, J.; Zhao, X.; Cheng, H.; Xi, B.; Mi, J. Childhood body mass index and blood pressure in prediction of subclinical vascular damage in adulthood: Beijing blood pressure cohort. J. Hypertens. 2017, 35, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Sauerbrei, W.; Collins, G.S.; Huebner, M.; Walter, S.D.; Cadarette, S.M.; Abrahamowicz, M. Guidance for designing and analysing observational studies. Med. Writ. 2017, 26, 17–21. [Google Scholar]
- Altman, D.G. Practical Statistics for Medical Research; Chapman and Hall: London, UK, 1991; ISBN 0-412-27630-5. [Google Scholar]
- Fitzmaurice, G.M.; Laird, N.M.; Ware, J.H. Applied Longitudinal Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 978-0-470-38027-7. [Google Scholar]
- Hozo, S.P.; Djulbegovic, B.; Hozo, I. Estimating the mean and variance from the median, range, and the size of a sample. BMC Med. Res. Methodol. 2005, 5, 13. [Google Scholar] [CrossRef]
- Wan, X.; Wang, W.; Liu, J.; Tong, T. Estimating the sample mean and standard deviation from the sample size, median, range and/or interquartile range. BMC Med. Res. Methodol. 2014, 14, 135. [Google Scholar] [CrossRef]
- Bland, M. Estimating Mean and Standard Deviation from the Sample Size, Three Quartiles, Minimum, and Maximum. Int. J. Stat. Med. Res. 2015, 4, 57–64. [Google Scholar] [CrossRef]
- Armitage, P.; Berry, G.; Matthews, J.N.S. Statistical Methods in Medical Research, 4th ed.; Blackwell Science: Oxford, UK, 2002; ISBN 9780632052578. [Google Scholar]
- Higgins, J.P.; White, I.R.; Anzures-Cabrera, J. Meta-analysis of skewed data: Combining results reported on log-transformed or raw scales. Stat. Med. 2008, 27, 6072–6092. [Google Scholar] [CrossRef]
- Selph, S.S.; Ginsburg, A.D.; Chou, R. Impact of contacting study authors to obtain additional data for systematic reviews: Diagnostic accuracy studies for hepatic fibrosis. Syst. Rev. 2014, 3, 107. [Google Scholar] [CrossRef]
- Higgins, J.P.; Li, T.; Deeks, J.J. Chapter 6: Choosing effect measures and computing estimates of effect. In Cochrane Handbook for Systematic Reviews of Interventions; Higgins, J., Thomas, J., Chandler, J., Cumpston, M., Li, T., Page, M., Welch, V., Eds.; Cochrane: London, UK, 2022. [Google Scholar]
- Idris, N.R.N.; Robertson, C. The effects of imputing the missing standard deviations on the standard error of meta analysis estimates. Commun. Stat. Simul. Comput. 2009, 38, 513–526. [Google Scholar] [CrossRef]
- Riley, R.D.; Moons, K.G.M.; Snell, K.I.E.; Ensor, J.; Hooft, L.; Altman, D.G.; Hayden, J.; Collins, G.S.; Debray, T.P.A. A guide to systematic review and meta-analysis of prognostic factor studies. BMJ 2019, 364, k4597. [Google Scholar] [CrossRef]
- Greenland, S.; Schesselman, J.J.; Criqui, M.H. The Fallacy of Employing Standardized Regression. J. Epidemiol. 1986, 123, 203–208. [Google Scholar] [CrossRef]
- Fernández-Castilla, B.; Aloe, A.M.; Declercq, L.; Jamshidi, L.; Onghena, P.; Natasha Beretvas, S.; Van den Noortgate, W. Concealed correlations meta-analysis: A new method for synthesizing standardized regression coefficients. Behav. Res. Methods 2019, 51, 316–331. [Google Scholar] [CrossRef] [PubMed]
- Yoneoka, D.; Henmi, M. Synthesis of linear regression coefficients by recovering the within-study covariance matrix from summary statistics. Res. Synth. Methods 2017, 8, 212–219. [Google Scholar] [CrossRef] [PubMed]
- Baillie, M.; le Cessie, S.; Schmidt, C.O.; Lusa, L.; Huebner, M. Ten simple rules for initial data analysis. PLoS Comput. Biol. 2022, 18, e1009819. [Google Scholar] [CrossRef] [PubMed]
- Nieminen, P. Ten Points for High-Quality Statistical Reporting and Data Presentation. Appl. Sci. 2020, 10, 3885. [Google Scholar] [CrossRef]

{kind=link}
| Study and Year of Publication | Country of Study | BMI Measured | Sample Size | Baseline Age (Years) | Final Age (Years) | |
|---|---|---|---|---|---|---|
| Childhood | Adolescent | |||||
| Ceponiene 2015 [52] | Lithuania | ✓ | 380 | 12–13 | 48–49 | |
| Davis 2001 [44] | United States | ✓ | 725 | 8–18 | 33–42 | |
| Du 2018 [53] | United States | ✓ | 1052 | 9.8 (3.2) a | 23–43 | |
| Ferreira 2004 [54] | Netherlands | ✓ | 159 | 13–16 | 36.5 (0.6) a | |
| Freedman 2004 [55] | United States | ✓ | ✓ | 513 | 4–17 | 23–40 |
| Hao 2018 [56] | United States | ✓ | 626 | 10–18 | 24 b | |
| Hosseinpanah 2021 [57] | Iran | ✓ | 1295 | 10.9 (4.0) | 29.8 (4.0) a | |
| Huynh 2013 [58] | Australia | ✓ | 2328 | 7–15 | 26–36 | |
| Johnson 2014 [59] | United Kingdom | ✓ | 1273 | 15 | 60–64 | |
| Juonala 2006 [60] | Finland | ✓ | 1081 | 3–9 | 24–30 | |
| Khalil 2013 [46] | India | ✓ | ✓ | 600 | 2, 11 | 33–38 |
| Lee 2008 [61] | South Korea | ✓ | 256 | 16 | 25 | |
| Oren 2003 [47] | Netherlands | ✓ | 750 | 12–16 | 27–30 | |
| Raitakari 2003 [43] | Finland | ✓ | 1170 | 12–18 | 33–39 | |
| Terzis 2012 [49] | Greece | ✓ | 106 | 12–17 | 40.5 (1.1) a | |
| Wright 2001 [62] | United Kingdom | ✓ | ✓ | 412 | 9, 13 | 50 |
| Yan 2017 [63] | China | ✓ | 1252 | 6–18 | 27–42 | |
| Reported Effect Size | Obtaining β and SE(β) | Combining within a Study | Estimating SD | Other Computations | |||
|---|---|---|---|---|---|---|---|
| Ceponiene [52] | b | 5.3.3 | 5.4 | 5.6.4 | |||
| Davis [44] | r | 5.2.2 | 5.4 | ||||
| Du [53] | b | 5.2.3 | 5.6.4 | 5.7.1 | |||
| Ferreira [54] | β | 5.7.2 | 5.7.2 | ||||
| Freedman [55] | r | 5.2.2 | 5.5 | ||||
| Hao [56] | b | 5.2.5 | 5.7.3 | ||||
| Hosseinpanah [57] | b | 5.2.5 | 5.6.4 | ||||
| Huynh [58] | b | 5.3.3 | 5.6.4 | ||||
| Johnson [59] | b | 5.3.3 | 5.4 and 5.5 | 5.6.2 | 5.7.1 | ||
| Juonala [60] | r | 5.2.2 | 5.4 | ||||
| Khalil [46] | b | 5.3.3 | 5.6.4 | ||||
| Lee [61] | b | 5.3.2 | 5.4 | 5.6.4 | 5.7.3 | ||
| Oren [47] | b | 5.3.3 | 5.6.4 | ||||
| Raitakari [43] | b | 5.2.3 | |||||
| Terzis [49] | β | 5.3.2 | |||||
| Wright [62] | β | 5.7.2 | 5.4 | 5.7.2 | |||
| Yan [63] | r | 5.2.2 | 5.4 | ||||
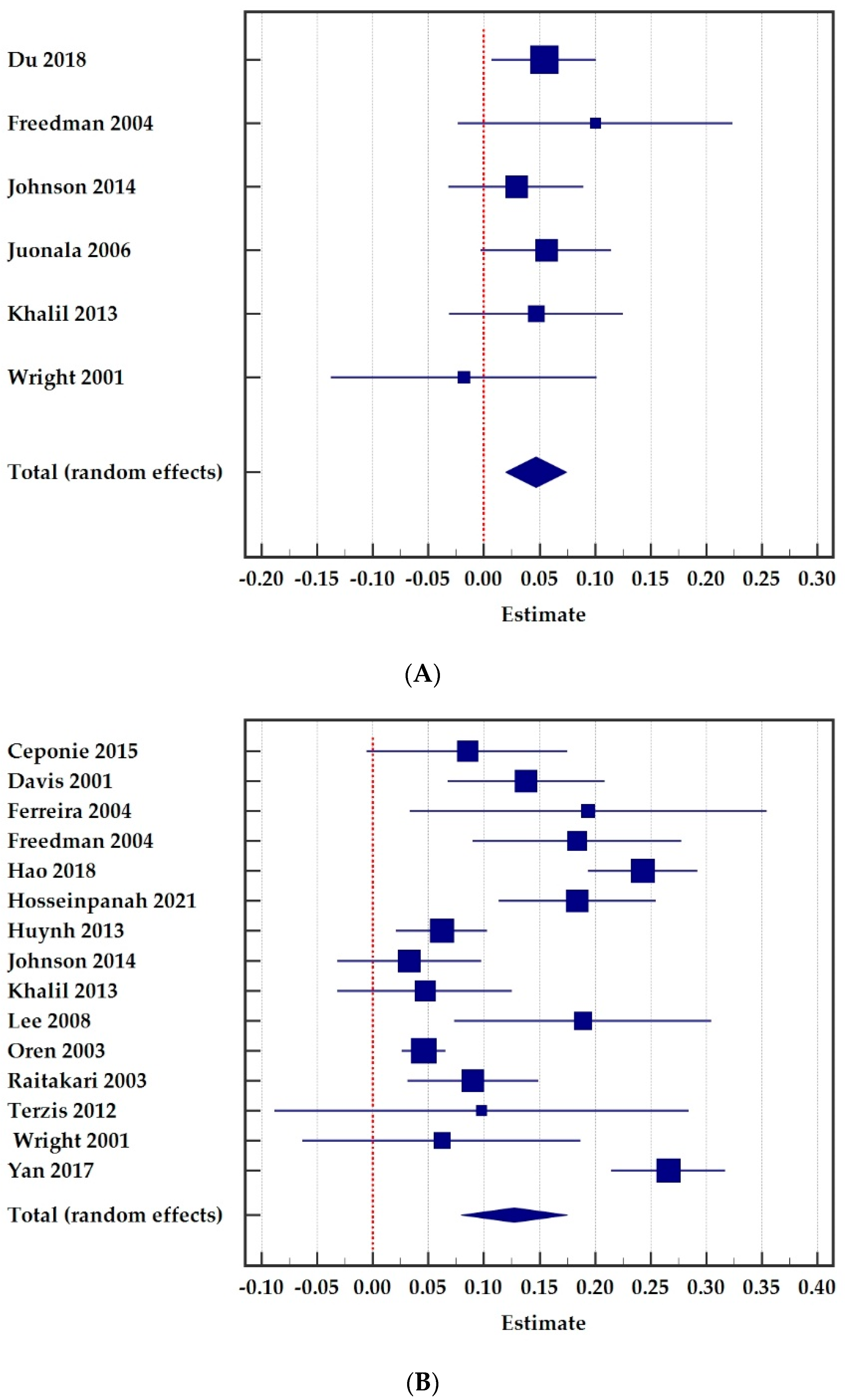
| β | SE(β) | Lower Limit of 95% CI | Upper Limit of 95% CI | Sample Size | Weight (%) | |
|---|---|---|---|---|---|---|
| Du 2018 | 0.054 | 0.024 | 0.007 | 0.101 | 1052 | 34.5 |
| Freedman 2004 | 0.100 | 0.063 | −0.023 | 0.223 | 246 | 5.0 |
| Johnson 2014 | 0.029 | 0.031 | −0.032 | 0.090 | 1273 | 20.7 |
| Juonala 2006 | 0.056 | 0.030 | −0.003 | 0.115 | 1078 | 22.1 |
| Khalil 2013 | 0.047 | 0.040 | −0.031 | 0.125 | 600 | 12.4 |
| Wright 2001 | −0.018 | 0.061 | −0.138 | 0.102 | 274 | 5.3 |
| Combined effect | 0.047 | 0.014 | 0.019 | 0.074 | 4523 |
| β | SE(β) | Lower Limit of 95% CI | Upper Limit of 95% CI | Sample Size | Weight (%) | |
|---|---|---|---|---|---|---|
| Ceponie 2015 | 0.085 | 0.046 | −0.005 | 0.175 | 380 | 6.5 |
| Davis 2001 | 0.138 | 0.036 | 0.067 | 0.209 | 725 | 7.2 |
| Ferreira 2004 | 0.194 | 0.082 | 0.033 | 0.355 | 161 | 4.3 |
| Freedman 2004 | 0.184 | 0.048 | 0.090 | 0.278 | 825 | 6.4 |
| Hao 2018 | 0.243 | 0.025 | 0.194 | 0.292 | 496 | 7.8 |
| Hosseinpanah 2021 | 0.184 | 0.036 | 0.113 | 0.255 | 1295 | 7.2 |
| Huynh 2013 | 0.052 | 0.022 | 0.021 | 0.103 | 2328 | 8.0 |
| Johnson 2014 | 0.033 | 0.033 | −0.032 | 0.098 | 1273 | 7.3 |
| Khalil 2013 | 0.047 | 0.040 | −0.031 | 0.125 | 600 | 6.9 |
| Lee 2006 | 0.189 | 0.059 | 0.073 | .0305 | 256 | 5.7 |
| Oren 2003 | 0.046 | 0.010 | 0.026 | 0.066 | 750 | 8.4 |
| Raitakari 2003 | 0.090 | 0.030 | 0.031 | 0.149 | 1170 | 7.5 |
| Terzis 2012 | 0.098 | 0.095 | −0.088 | 0.284 | 106 | 3.7 |
| Wright 2001 | 0.062 | 0.064 | −0.063 | 0.187 | 242 | 5.4 |
| Yan 2017 | 0.266 | 0.026 | 0.215 | 0.317 | 1252 | 7.7 |
| Combined effect | 0.127 | 0.024 | 0.080 | 0.175 | 11859 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nieminen, P. Application of Standardized Regression Coefficient in Meta-Analysis. BioMedInformatics 2022, 2, 434-458. https://doi.org/10.3390/biomedinformatics2030028
Nieminen P. Application of Standardized Regression Coefficient in Meta-Analysis. BioMedInformatics. 2022; 2(3):434-458. https://doi.org/10.3390/biomedinformatics2030028
Chicago/Turabian StyleNieminen, Pentti. 2022. "Application of Standardized Regression Coefficient in Meta-Analysis" BioMedInformatics 2, no. 3: 434-458. https://doi.org/10.3390/biomedinformatics2030028
APA StyleNieminen, P. (2022). Application of Standardized Regression Coefficient in Meta-Analysis. BioMedInformatics, 2(3), 434-458. https://doi.org/10.3390/biomedinformatics2030028