
Machine Learning for Diagnosis of Alzheimer’s Disease and Early Stages



Abstract
:1. Introduction
2. Materials and Methods
2.1. Problem Exploration
- AD (Alzheimer Disease): the images in this group correspond to patients diagnosed with Alzheimer.
- CN (Cognitively Normal): corresponds to healthy individuals (control).
- MCI (Mild Cognitive Impairment): causes a slight but noticeable and measurable decline in cognitive abilities.
- EMCI (Early Mild Cognitive Impairment): an early stage of MCI with milder episodic memory impairment.
- LMCI (Late Mild Cognitive Impairment): a more advanced stage of MCI previous to AD.
- SMC (Significant Memory Concern): patients with SMC are characterized by self-report significant memory concern, quantified by using the Cognitive Change Index and the Clinical Dementia Rating (CDR) of zero. SMC participants score within the normal range for cognition, and the informant does not equate the expressed concern with progressive memory impairment. SMCs have been shown to be correlated with a higher likelihood of progression [18].
2.2. SVM Research
2.3. CNN Research
- 1.
- One convolutional layer with 32 filters, a kernel size of (3,3) and using “relu” as its activation function. The number of filters determines the number of kernels to convolve with the input volume. Each of these operations produces a 2D activation map. Layers early in the network architecture (i.e., closer to the actual input image) usually learn fewer convolutional filters while layers deeper in the network (i.e., closer to the output predictions) will learn more filters. This layer will expect an input of size (224, 224, 3) in order to fit our images.
- 2.
- One max pooling layer (2,2) to reduce the spatial dimensions of the output volume.
- 3.
- Another similar convolutional layer, although using 64 filters this time.
- 4.
- Another max pooling layer (2,2) to reduce the spatial dimensions of the output volume in the second convolutional layer.
- 5.
- One flattened layer to connect the multidimensional data from convolution to dense layers.
- 6.
- Two dense layers using the “relu” (64 units) and “softmax” (6 units) activation functions respectively. We use “softmax” to convert the scores to a normalized probability distribution.
- 1.
- One convolutional layer with 16 filters, a kernel size of (3,3) and using “relu” as its activation function.
- 2.
- One max pooling layer (2,2) to reduce the spatial dimensions of the output volume.
- 3.
- Another similar convolutional layer, but using 32 filters this time.
- 4.
- Another max pooling layer (2,2) to reduce the spatial dimensions of the output volume in the second convolutional layer
- 5.
- A third convolutional layer but using 64 filters.
- 6.
- A third max pooling layer (2,2) to reduce the spatial dimensions of the output volume in the third convolutional layer.
- 7.
- One flatten layer to connect the multidimensional data from convolution to dense layers.
- 8.
- Two dense layers using the “relu” (128 units) and “softmax” (6 units) activation functions respectively. We use “softmax” to convert the scores to a normalized probability distribution.
3. Results
3.1. SVM Results
3.2. CNN Results
3.3. Confusion Matrix
4. Discussion and Conclusions
- It is possible to detect the early stages in Alzheimer’s disease and this prediction can be as precise as the prediction of dementia itself. Significant memory concern (SMC) and early mild cognitive impairment (EMCI) have been proven to have an effect on the brain that can be detected and measured. Patients with early symptoms of dementia can be localized and preventive treatments can be applied.
- If the MRI images reach a high level of normalization and enough samples are accessible it is possible to build an SVM classifier able to predict Alzheimer’s stages with an F1 score higher than 99.7%. As mention throughout the research, a key point of this investigation is the high quality of the dataset and the segmentation, bias correction and spatial normalisation applied by SPM12 [11,12] beforehand. The large number of samples (6,028) used it also relevant when compared with similar investigations [10]. The results show that our model has outperformed other modern experiments [5,6,7,14,24,25]. A more detailed comparison with some of the most promising investigations conducted to date is made in Table 8.
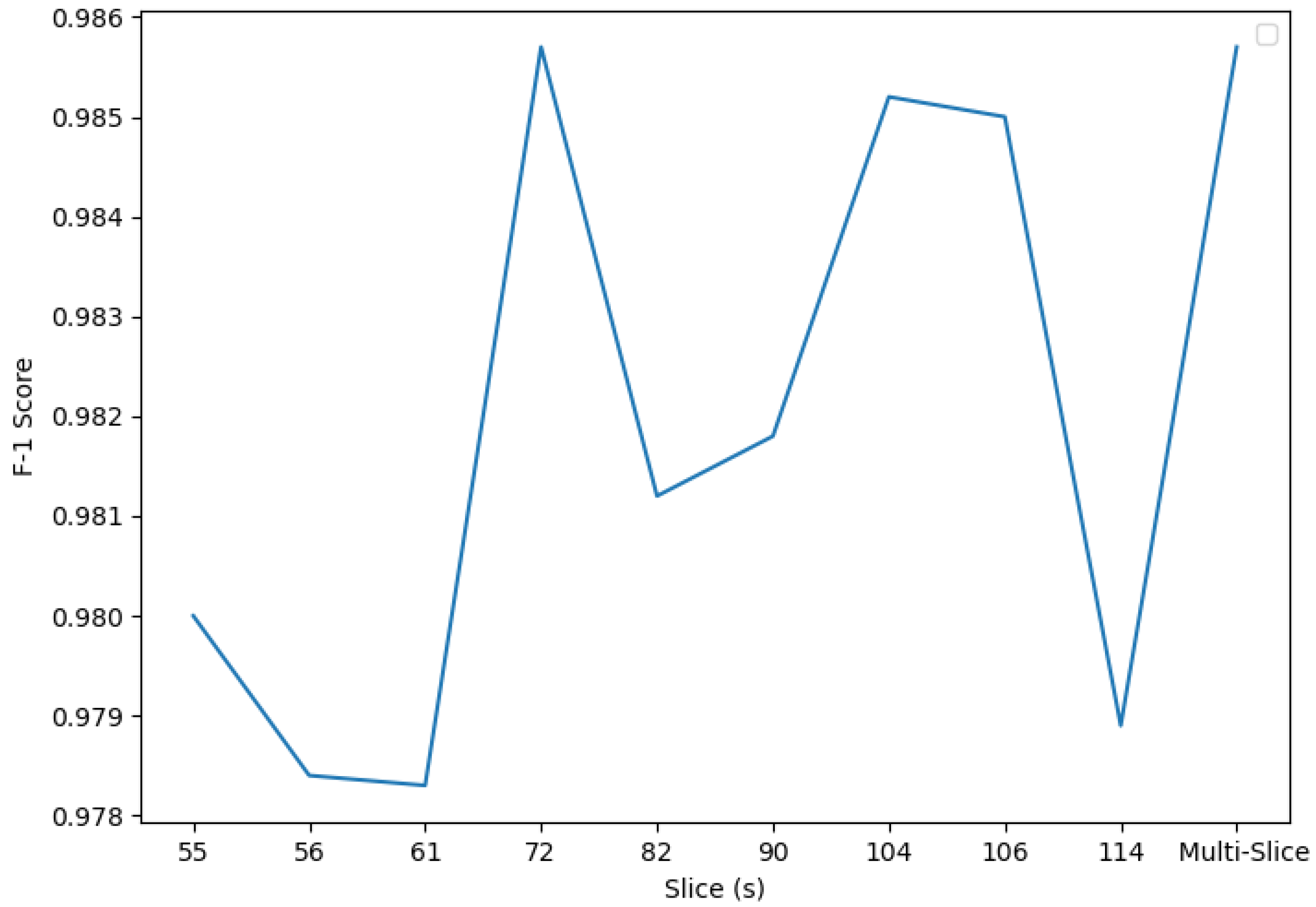
- In MRI images, some slices are more informative than others i.e., there are parts in the brain that contain more information and can be used more precisely to provide a diagnosis of the patient. Of the available slices in our dataset, slice 82 demonstrated the best results. This slice is located in the coronal plane, confirming the conclusions exposed by Luis Balderas in his thesis [9].
- In order to give a more accurate diagnosis, it is better to process all the information available in the brain rather than considering located regions only. Even if the disease has a more noticeable impact on specific regions, the information distributed throughout the brain’s mass makes a difference when seeking optimal results.
- Both SVM and CNN approached competent performances. Nevertheless, SVM stands out above CNN. A possible explanation for this is the normalization and regularity of the data. Since the available images are already resized, and the classifier is built using delimited and localized variation of the imaged zones, the edge identification power of CNN does not beat the capacity of SVM to allocate samples in , and group them using the partitions generated by its trained hyperplane.
- The Mallat algorithm, revealed in [26], can be used to access the wavelet coefficients at deeper levels of the approximation image, LL. These coefficients are still very informative, exposing the power of the wavelet transform even in today’s image classification tasks. Using the wavelet coefficients from the approximation image at level four gave an outstanding F1 score of 0.9979. This classifier, which used all the available coefficients from the set of slices, performed better than slice-isolated classifiers accessing wavelet coefficients at level three.
- PCA performs better than regular feature selection algorithms when facing image classification problems where data has certain continuity properties. Features are highly correlated with each other and present small variations. Applying feature selection could lead to missing wider anomalies that would otherwise be detected using a dimensionality reduction system.
- It would be possible to access a higher level of detail either by using a machine with better specifications or performing mini-batch training techniques. This approach could lead to obtaining a more informative training dataset. Examples of this include using wavelet coefficients at lower levels or training a CNN classifier using all the available images as input.
- Investigate whether accessing different types of wavelet coefficients (diagonal, horizontal or vertical) can lead to a better outcome in F1 score or not.
- Research on the structure of CNN models to develop smarter and more suitable networks using different distribution and types of convolutional layers.
- Develop new paradigms of research to process 3D images and investigate the possible use and applications of the 3D wavelet transform.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CN | Cognitively Normal |
| MCI | Mild Cognitive Impairment |
| EMCI | Early Mild Cognitive Impairment |
| LMCI | Late Mild Cognitive IMpairment |
| SMC | Significant Memory Concern |
| AD | Alzheimerś disease |
| MRA | Multiresolution Analysis |
| mRMR | Minimum Redundancy Maximum Relevance |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| TL | Transfer Learning |
References
- Tan, Y. Continuous Wavelet Transforms. In Wavelet Theory Approach to Pattern Recognition; Bunke, H., Wang, P.S.P., Eds.; World Scientific Publishing Co. Pte. Ltd.: Singapore, 2009; pp. 75–102. [Google Scholar]
- Iqbal, M.S.; Ahmad, I.; Khan, T.; Khan, S.; Ahmad, M.; Wang, L. Recent Advances of Deep Learning in Biology. In Deep Learning for Unmanned Systems; Koubaa, A., Azar, A.T., Eds.; Studies in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 984. [Google Scholar]
- Zhang, Y.; Dong, Z.; Phillips, P.; Wang, S.; Ji, G.; Yang, J.; Yuan, T. Detection of subjects and brain regions related to Alzheimer’s disease using 3D MRI scans based on eigenbrain and machine learning. Front. Comput. Neurosci. 2015, 9, 66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beheshti, I.; Demirel, H. Feature-ranking-based Alzheimer’s disease classification from structural MRI. Magn. Reson. Imaging 2016, 34, 252–263. [Google Scholar] [CrossRef] [PubMed]
- AbdulAzeem, Y.; Bahgat, W.; Badawy, M. A CNN based framework for classification of Alzheimer’s disease. Neural Comput. Appl. 2021, 33, 10415–10428. [Google Scholar] [CrossRef]
- Shanmugam, J.; Duraisamy, B.; Simon, B.; Bhaskaran, P. Alzheimer’s disease classification using pre-trained deep networks. Biomed. Signal Process. Control 2022, 71, 103217. [Google Scholar] [CrossRef]
- Eroglu, Y.; Yildirim, M.; Cinar, A. mRMR-based hybrid convolutional neural network model for classification of Alzheimer’s disease on brain magnetic resonance images. Int. J. Imaging Syst. Technol. 2021. [Google Scholar] [CrossRef]
- Alashwal, H.; Diallo, T.; Tindle, R.; Moustafa, A. Latent Class and Transition Analysis of Alzheimer’s Disease Data. Front. Comput. Sci. 2020, 2, 1–13. [Google Scholar] [CrossRef]
- Balderas, L. Development of Intelligent System for the automatic classification of Parkinson’s Disease Using MRI Images. Diploma Thesis, University of Granada, Granada, Spain, 2019. [Google Scholar]
- Valenzuela, O.; Jiang, X.; Carrillo, A.; Rojas, I. Multi-Objective Genetic Algorithms to Find Most Relevant Volumes of the Brain Related to Alzheimer’s Disease and Mild Cognitive Impairment. Int. J. Neural Syst. 2018, 28, 1850022. [Google Scholar] [CrossRef] [PubMed]
- Penny, W.; Friston, K.J.; Ashburner, J.T.; Kiebel, S.J.; Nichols, T.E. Statistical Parametric Mapping: The Analysis of Functional Brain Images; Academic Press: San Diego, CA, USA, 2007. [Google Scholar]
- Flandin, G.; Friston, K.; Carrillo, A.; Rojas, I. Analysis of family-wise error rates in statistical parametric mapping using random field theory. Hum. Brain Mapp. 2017, 40, 2052–2054. [Google Scholar] [CrossRef] [PubMed]
- Hasan, H.; Shafri, H.; Habshi, M. A Comparison Between Support Vector Machine (SVM) and Convolutional Neural Network (CNN) Models For Hyperspectral Image Classification. IOP Conf. Ser. Earth Environ. Sci. 2019, 357, 012035. [Google Scholar] [CrossRef] [Green Version]
- Buvaneswari, P.; Gayathri, R. Detection and Classification of Alzheimer’s disease from cognitive impairment with resting-state fMRI. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Afaq, S.; Shah, A.; Bennamoun, M. Convolutional Neural Network. In A Guide to Convolutional Neural Networks for Computer Vision; Medioni, G., Dickinson, S., Eds.; Morgan & Claypool Publishers: San Rafael, CA, USA, 2018; pp. 43–95. [Google Scholar]
- Khan, S.; Rahmani, H.; Afaq, S.; Shah, A.; Bennamoun, M. Examples of CNN Architectures. In A Guide to Convolutional Neural Networks for Computer Vision; Medioni, G., Dickinson, S., Eds.; Morgan & Claypool Publishers: San Rafael, CA, USA, 2018; p. 104. [Google Scholar]
- Logan, R.; Williams, B.; da Silva, M.; Indani, A.; Schcolnicov, N.; Ganguly, A.; Miller, S. Deep Convolutional Neural Networks With Ensemble Learning and Generative Adversarial Networks for Alzheimer’s Disease Image Data Classification. Front. Aging Neurosci. 2021, 13, 720226. [Google Scholar] [CrossRef]
- The Alzheimer’s Disease Neuroimaging Initiative. Available online: http://adni.loni.usc.edu/study-design/ (accessed on 20 May 2020).
- Billah, M.; Waheed, S. Minimum Redundancy Maximum Relevance (mRMR) Based Feature Selection from Endoscopic Images for Automatic Gastrointestinal Polyp Detection. Multimed. Tools Appl. 2020, 79, 23633–23643. [Google Scholar] [CrossRef]
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Mei, M. Principal Component Analysis; The University of Chicago: Chicago, IL, USA, 2009. [Google Scholar]
- Gidudu, A.; Gregg, H.; Tshilidzi, M. Image Classification Using SVMs: One-against-One Vs One-against-All. arXiv 2007, arXiv:0711.2914. [Google Scholar]
- Alinsaif, S.; Lang, J.; Alzheimer’s Disease Neuroimaging Initiative. 3D shearlet-based descriptors combined with deep features for the classification of Alzheimer’s disease based on MRI data. Comput. Biol. Med. 2021, 138, 104879. [Google Scholar] [CrossRef] [PubMed]
- You, Z.; Zeng, R.; Lan, X.; Ren, H.; You, Z.Y.; Shi, X.; Zhao, S.P.; Guo, Y.; Jiang, X.; Hu, X.P. Alzheimer’s Disease Classification With a Cascade Neural Network. Front. Public Health 2020, 8, 584387. [Google Scholar] [CrossRef] [PubMed]
- Tan, Y. Multiresolution Analysis and Wavelet Bases. In Wavelet Theory Approach to Pattern Recognition; Bunke, H., Wang, P.S.P., Eds.; World Scientific Publishing Co. Pte. Ltd.: Singapore, 2009; pp. 106–152. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level 5 | Level 4 | Level 3 | Level 2 | Level 1 |
|---|---|---|---|---|
| 918 | 2867 | 10,120 | 37,856 | 145,971 |
| Kernel | C | Gamma |
|---|---|---|
| linear, rbf, sigmoid | 1, 10, 100, 1000 | , , , , scale |
| CN | SMC | EMCI | MCI | LMCI | AD | Average | |
|---|---|---|---|---|---|---|---|
| 55 | 0.8090 | 1 | 1 | 1 | 1 | 0.8148 | 0.9373 |
| 56 | 0.8007 | 1 | 1 | 1 | 1 | 0.8133 | 0.9361 |
| 61 | 0.8083 | 1 | 1 | 1 | 1 | 0.8122 | 0.9367 |
| 72 | 0.7958 | 1 | 1 | 1 | 1 | 0.8040 | 0.9333 |
| 82 | 0.8091 | 1 | 1 | 1 | 1 | 0.8180 | 0.9379 |
| 90 | 0.7917 | 1 | 1 | 1 | 1 | 0.7980 | 0.9316 |
| 104 | 0.7825 | 1 | 1 | 1 | 1 | 0.7933 | 0.9293 |
| 106 | 0.7813 | 1 | 1 | 1 | 1 | 0.7706 | 0.9253 |
| 114 | 0.8035 | 1 | 1 | 1 | 1 | 0.8101 | 0.9356 |
| All | 0.8909 | 1 | 1 | 1 | 1 | 0.9032 | 0.9657 |
| CN | SMC | EMCI | MCI | LMCI | AD | Average | |
|---|---|---|---|---|---|---|---|
| 55 | 0.9912 | 0.9939 | 1 | 0.9984 | 0.9930 | 0.9917 | 0.9947 |
| 56 | 0.9930 | 0.9939 | 1 | 0.9984 | 0.9930 | 0.9933 | 0.9953 |
| 61 | 0.9947 | 0.9939 | 0.9896 | 0.9984 | 0.9903 | 0.9950 | 0.9936 |
| 72 | 0.9947 | 0.9939 | 0.9948 | 1 | 0.9930 | 0.9950 | 0.9952 |
| 82 | 0.9912 | 1 | 1 | 1 | 0.9958 | 0.9933 | 0.9967 |
| 90 | 0.9947 | 1 | 0.9948 | 1 | 0.9944 | 0.9967 | 0.9968 |
| 104 | 0.9947 | 1 | 1 | 0.9984 | 0.9958 | 0.9950 | 0.9973 |
| 106 | 0.9947 | 1 | 1 | 0.9984 | 0.9958 | 0.9950 | 0.9973 |
| 114 | 0.9947 | 1 | 0.9948 | 1 | 0.9944 | 0.9967 | 0.9968 |
| All | 0.9947 | 1 | 1 | 1 | 0.9958 | 0.9967 | 0.9979 |
| Multi-Slice | 0.9930 | 1 | 1 | 1 | 0.9958 | 0.9950 | 0.9973 |
| CN | SMC | EMCI | MCI | LMCI | AD | Average | |
|---|---|---|---|---|---|---|---|
| 55 | 0.9683 | 1 | 1 | 1 | 1 | 0.9701 | 0.9897 |
| 56 | 0.9682 | 1 | 1 | 1 | 1 | 0.9702 | 0.9897 |
| 61 | 0.9665 | 1 | 1 | 1 | 1 | 0.9685 | 0.9892 |
| 72 | 0.9652 | 1 | 1 | 1 | 1 | 0.9641 | 0.9873 |
| 82 | 0.9648 | 1 | 1 | 1 | 1 | 0.9668 | 0.9886 |
| 90 | 0.9686 | 1 | 1 | 1 | 1 | 0.9657 | 0.9879 |
| 104 | 0.9686 | 1 | 1 | 1 | 1 | 0.9698 | 0.9897 |
| 106 | 0.9700 | 1 | 1 | 1 | 1 | 0.9718 | 0.9903 |
| 114 | 0.9628 | 1 | 0.9984 | 1 | 1 | 0.9669 | 0.9880 |
| Multi-Slice | 0.9699 | 1 | 1 | 1 | 1 | 0.9709 | 0.9902 |
| CN | SMC | EMCI | MCI | LMCI | AD | Average | |
|---|---|---|---|---|---|---|---|
| 55 | 0.9385 | 1 | 1 | 1 | 1 | 0.9418 | 0.9800 |
| 56 | 0.9370 | 1 | 1 | 1 | 1 | 0.9399 | 0.9784 |
| 61 | 0.9338 | 1 | 0.9984 | 1 | 1 | 0.9377 | 0.9783 |
| 72 | 0.9561 | 1 | 1 | 1 | 1 | 0.9584 | 0.9857 |
| 82 | 0.9422 | 1 | 1 | 1 | 1 | 0.9449 | 0.9812 |
| 90 | 0.9439 | 1 | 1 | 1 | 1 | 0.9467 | 0.9818 |
| 104 | 0.9537 | 1 | 1 | 1 | 1 | 0.9572 | 0.9852 |
| 106 | 0.9521 | 1 | 1 | 1 | 1 | 0.9574 | 0.9850 |
| 114 | 0.9345 | 1 | 1 | 1 | 1 | 0.9388 | 0.9789 |
| Multi-Slice | 0.9563 | 1 | 1 | 1 | 1 | 0.9582 | 0.9857 |
| CN | SMC | EMCI | MCI | LMCI | AD | Average | |
|---|---|---|---|---|---|---|---|
| 55 | 0.8730 | 1 | 1 | 1 | 1 | 0.8773 | 0.9584 |
| 56 | 0.8839 | 1 | 1 | 1 | 1 | 0.8870 | 0.9618 |
| 61 | 0.8801 | 1 | 1 | 1 | 1 | 0.8758 | 0.9569 |
| 72 | 0.8731 | 1 | 1 | 1 | 1 | 0.8770 | 0.9583 |
| 82 | 0.8728 | 1 | 1 | 1 | 1 | 0.8808 | 0.9589 |
| 90 | 0.8667 | 1 | 0.9984 | 1 | 1 | 0.8752 | 0.9567 |
| 104 | 0.8785 | 1 | 0.9967 | 1 | 1 | 0.8826 | 0.9596 |
| 106 | 0.8662 | 1 | 1 | 1 | 1 | 0.8738 | 0.9567 |
| 114 | 0.8723 | 1 | 0.9984 | 1 | 1 | 0.8797 | 0.9584 |
| Multi-Slice | 0.8841 | 1 | 1 | 1 | 1 | 0.8873 | 0.9620 |
| Authors | Imaging | Stages | Preprocessing | Classifier | Accuracy |
|---|---|---|---|---|---|
| Beheshti et al., 2016 [4] | MRI | CN, AD | VBM plus DARTEL | PCA + SVM | 0.963 |
| You et al., 2020 [25] | EGG | CN, MCI, AD | ASTGCN | ASTGCN | 0.910 |
| AbdulAzeem et al., 2021 [5] | MRI | CN, MCI, AD | Grey scale conversion + Adaptative Thresholding | CNN | 0.975 |
| Eroglu et al., 2021 [7] | MRI | CN, MCI, AD | CNN(TL) | mRMR + SVM | 0.991 |
| Valenzuela et al., 2018 [10] | MRI | CN, MCInc, MCIc, AD | SMP12 | PCA + SVM | 0.944 |
| Proposed method | MRI | CN, SMC, EMCI, MCI, LMCI, AD | SPM12 + standardization | PCA + SVM | 0.997 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prado, J.J.; Rojas, I. Machine Learning for Diagnosis of Alzheimer’s Disease and Early Stages. BioMedInformatics 2021, 1, 182-200. https://doi.org/10.3390/biomedinformatics1030012
Prado JJ, Rojas I. Machine Learning for Diagnosis of Alzheimer’s Disease and Early Stages. BioMedInformatics. 2021; 1(3):182-200. https://doi.org/10.3390/biomedinformatics1030012
Chicago/Turabian StylePrado, Julio José, and Ignacio Rojas. 2021. "Machine Learning for Diagnosis of Alzheimer’s Disease and Early Stages" BioMedInformatics 1, no. 3: 182-200. https://doi.org/10.3390/biomedinformatics1030012
APA StylePrado, J. J., & Rojas, I. (2021). Machine Learning for Diagnosis of Alzheimer’s Disease and Early Stages. BioMedInformatics, 1(3), 182-200. https://doi.org/10.3390/biomedinformatics1030012