In recent years, interest in artificial intelligence (AI) has dramatically increased among researchers and practitioners from all fields, with successful real-world applications in consumer products, like digital assistants or content recommendation, as well as in manufacturing environments, like autonomous machinery and robotics. One aspect of AI that has attracted the most interest and enthusiasm in recent years is machine learning (ML), which is the foundation for many successful real-world AI applications. ML techniques are a group of algorithms that can find intricate patterns in data and use them to forecast future events in a variety of industries. To illustrate, in 2021, Zhao et al. [
1] presented and proposed a novel method for ground fissure identification and exploration by infrared remote sensing onboard an unmanned aerial vehicle (UAV). Using this method, a region of interest (ROI) that includes ground fissures directly above the middle of a long wall face, No. 12401 in the Shangwan coal mine was identified. In the same year, Zheng et al. [
2] proposed a Multi-class Oil Palm Detection approach (MOPAD) to reap both accurate detection of oil palm trees and accurate monitoring of their growing status. Based on a faster region-based convolutional neural network (faster R-CNN), MOPAD combines a refined pyramid feature (RPF) module and a hybrid class-balanced loss module to achieve a satisfying observation of the growing status for individual oil palms. In addition, Puniach et al. [
3] proposed a workflow for automatically determining the field of horizontal displacements caused by underground mining using ultra-high resolution orthomosaics. The study included a comparison of the effectiveness of image registration algorithms for matching of multi-temporal orthomosaics.
On the other hand, fleet management and scheduling are the most significant components of operations in the mining cycle. So, hauling costs, accounting for 60% of operating costs, play a crucial role in mining economics and can influence production costs and final product price [
4]. So, this paper aimed to make a correct prediction and selection of the fleet using the ML method and real data from the work environment. In open-pit mining, the complexity of operations, coupled with an uncertain and dynamic environment, limits the certainty of predictions. Consequently, to achieve production targets and decrease operational costs, the best accuracy in predictions with a minimum of opportunity lost in fleet management should be reflected by considering all the factors, no matter however small, which are related to each other. Accordingly, for many years, various methods have been performed and accomplished by many scientists and industrial companies to optimize fleet management by analyzing multiple situations. Lizotte and Bonates [
5] proposed a method to minimize shovel idle time, maximizing immediate truck use and allotting trucks to shovels to meet specific production purposes. However, in this study, all situations were considered stable. Hashemi and Sattarvand [
6] presented a dispatching simulation model in ARENA simulation software with the objective function of minimizing truck waiting times for trucks having a developed hauling cycle and obtained a 7.8% improvement by applying a flexible assignment of the trucks for the loaders, compared to the fixed assignment system. Temeng and Otuonye [
7] used the goal-programming-based dispatching model to maximize production rate and maintain ore quality compared to linear programming. Rodrigo et al. [
8] performed a novel system productivity simulation and optimization modeling framework. In their model, equipment availability was a variable in the expected productivity function of the system. The framework was used for allocating trucks by route. according to their operating performances, in a truck–shovel system of an open-pit mine so as to maximize the overall productivity of the fleet. In these three studies, only productivity was considered the main goal and idle time was neglected. In 2010, Topal and Ramazan [
9] presented a mixed-integer programming model (MIP). Their model provides substantial cost savings for equipment scheduling by optimizing truck usage. However, this study focused on decreasing the maintenance cost of mining. Gu et al. [
10] presented a dynamic management system of ore blending in an open-pit mine based on GIS/GPS/GPRS using technologies from space, wireless location, wireless communication, and computers to control ore quality and ensure the stability of ore grade. They just focused on ore grade control instead of fleet management. Cox et al. [
11] used a genetic algorithm to develop cyclic automata for dispatching trucks in mines, but, they should have focused on the real-time evolution of schedules and generalized the problem to include blending constraints. Ahangaran et al. [
12] discussed the changing trend of programming and dispatching control algorithms and automation conditions. Finally, a real-time dispatching model, compatible with the requirement of trucks with different capacities, was developed using flow-networks techniques and integer programming (IP). Additionally, the use of innovative methods in recent years has improved the performance of the transport systems in mines. This model was presented for blending purposes, too. Upadhyay and Askari-Nasab [
13] presented a framework using a discrete event simulation model (DES) of mine operations, which interacts with a goal programming (GP)-based mine operational optimization tool to develop an uncertainty-based short-term schedule. This framework allows the planner to make proactive decisions to achieve the mine’s operational and long-term objectives. Baek and Choi [
14] proposed a deep neural network (DNN)-based method for predicting ore production by truck-haulage systems in open-pit mines, which assisted comprehension of truck-haulage-system characteristics along with discrete haulage-operation sequences and supported the prediction of ore production through training of DNN-based deep learning models without the need to develop additional algorithms. This method needs to determine the optimum period for collecting training data. Moradi-Afrapoli et al. [
15] presented a new mixed-integer linear programming model (MILP) to solve the truck dispatching problem in surface mines. They showed that the fuzzy linear programming (FLP) model improved the ore production and truck wait time in the queues by more than 15%. However, further study by considering mixed truck sizes was needed. In 2021, Mohtasham et al. [
16] presented a multi-objective optimization model based upon a mixed-integer linear goal programming (MILGP) model, which determines the optimal production plan of the shovels and allocation plan of the trucks and shovels in order to maximize production, to meet desired head grade and tonnage at the ore destinations, and to minimize fuel consumption of trucks. Yeganejoo et al. [
17] developed, implemented, and validated an integrated simulation and optimization tool capable of predicting truck fleet productivity and determining optimal fleet size based on historical data collected from the active mine. Mohtasham et al. [
18] proposed new strategies based on mixed-integer non-linear programming (MINLP) models for the equipment sizing (ES) problem to verify the overall efficiency of the fleet. The developed models estimate the optimal size of trucks concerning the match factor value with two different strategies. The first strategy deals with each loader type, and the second strategy is applied simultaneously with all types of loaders. These studies did not integrate sources of uncertainty, including uncertainties related to crushers’ capacity, truck cycle times, shovel’s output, equipment failures, and ore quality into their proposed models. Upadhyay et al. [
19] presented a simulation-based fleet productivity estimation and fleet size determination algorithm developed to be used in open-pit mines to estimate fleet productivity and predict the required fleet size to meet production schedules in the presence of technical uncertainties. Their results showed that the developed simulation-based algorithm could predict fleet productivity with more than 20% higher accuracy and had lower dependency on haulage distances.
The mentioned studies have individual problems, including disregarding past expertise in mining operations, limited flexibility for change in the production process, and ignoring actual working situations in mines.
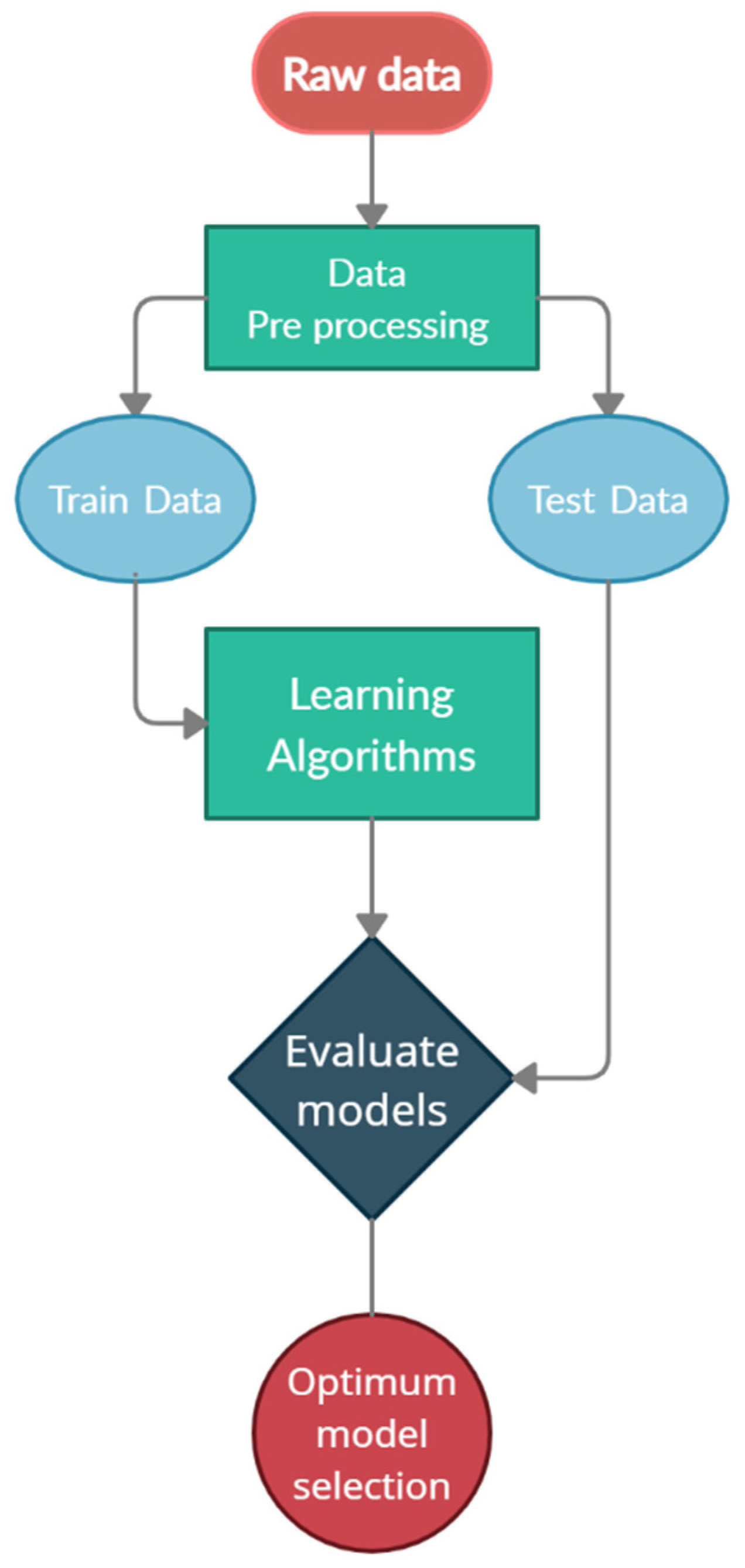
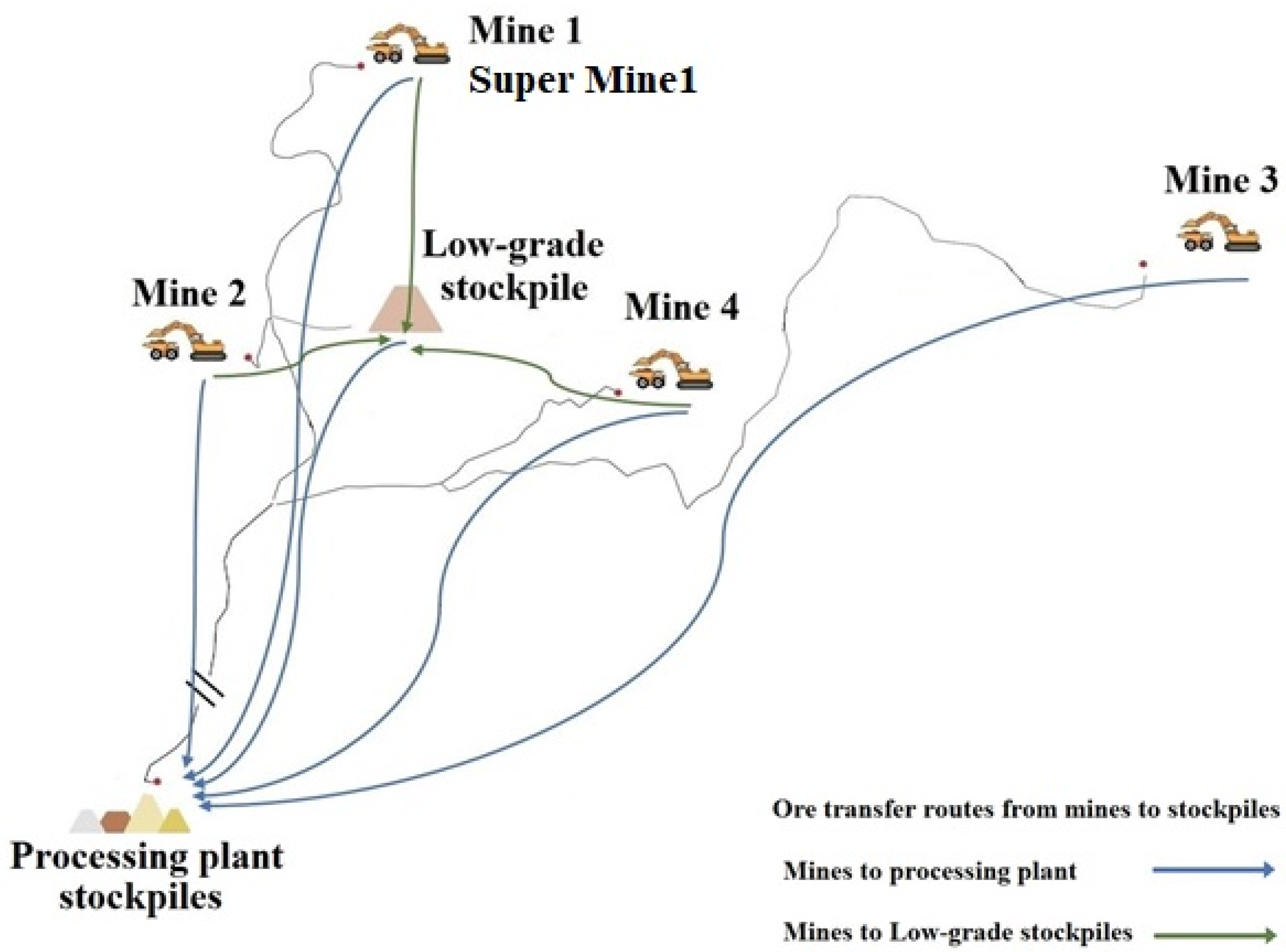
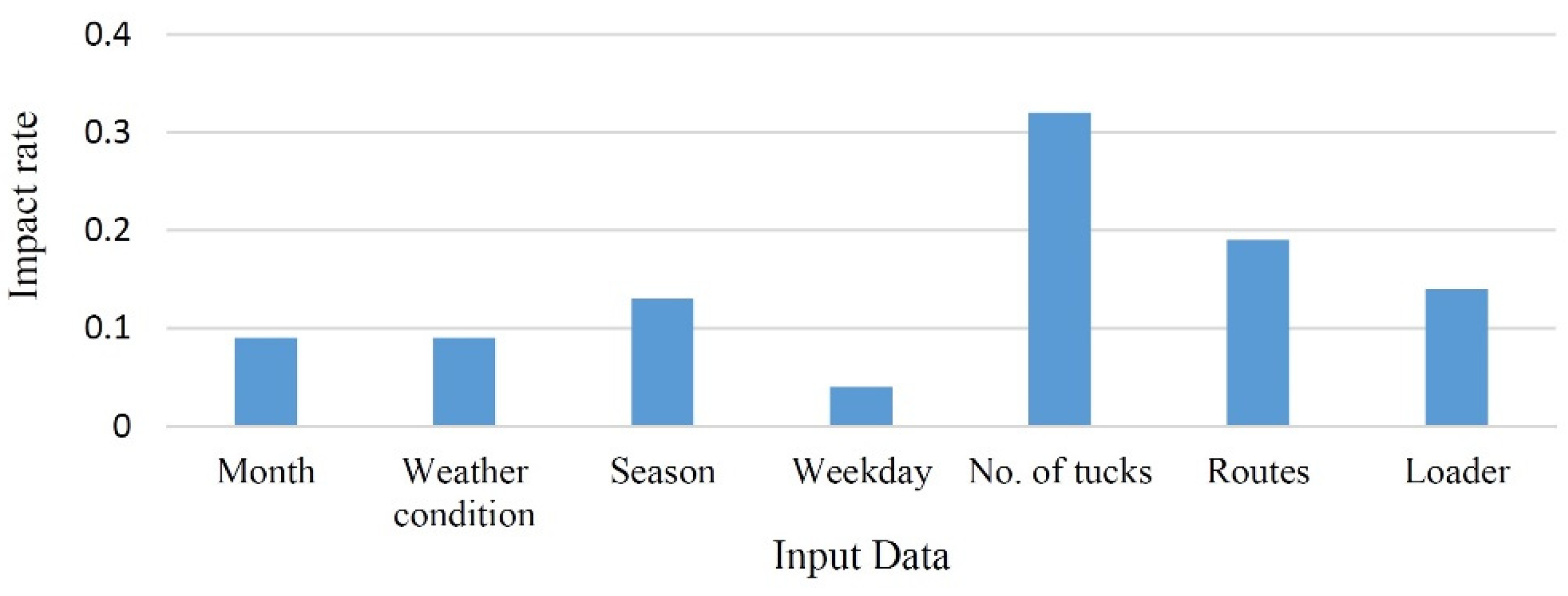
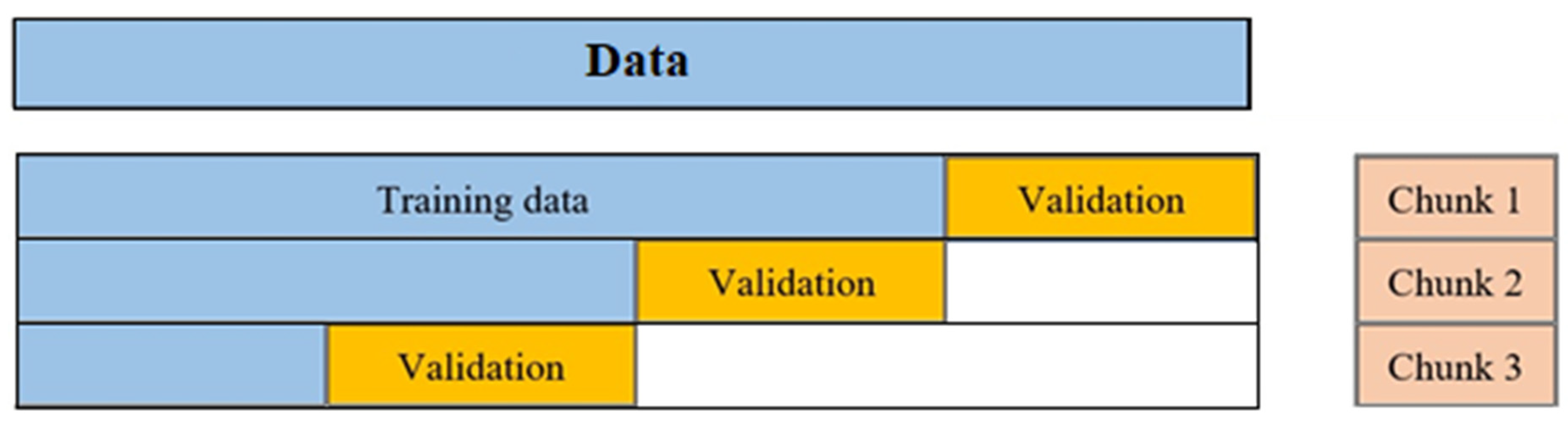
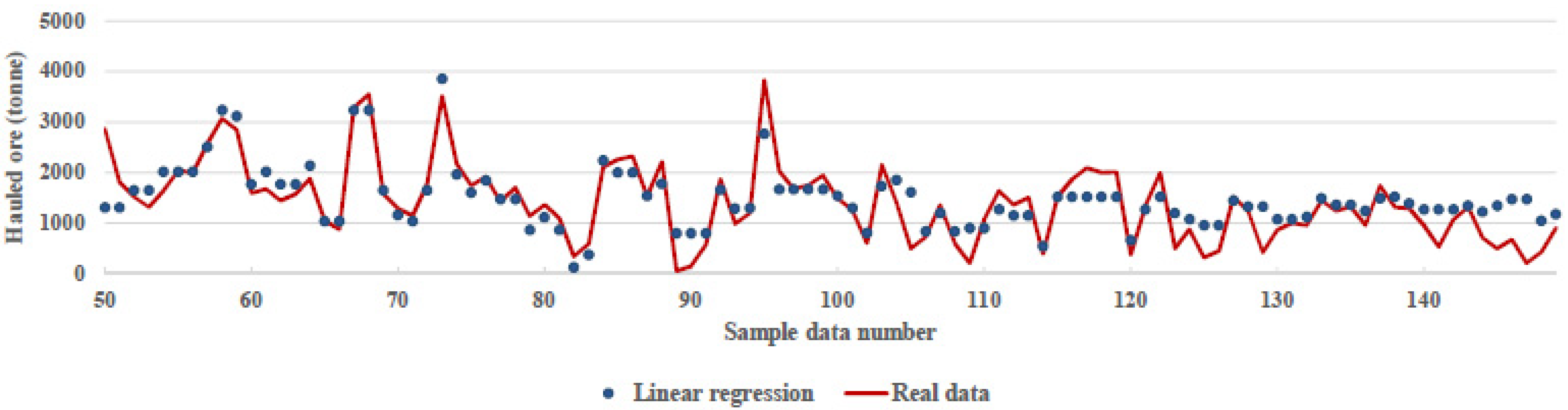
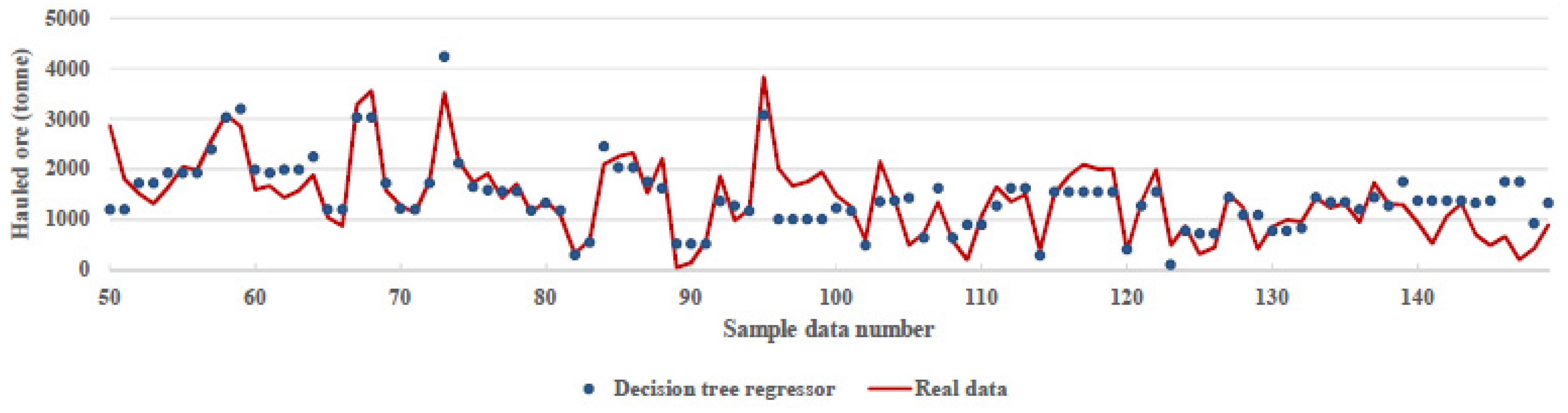
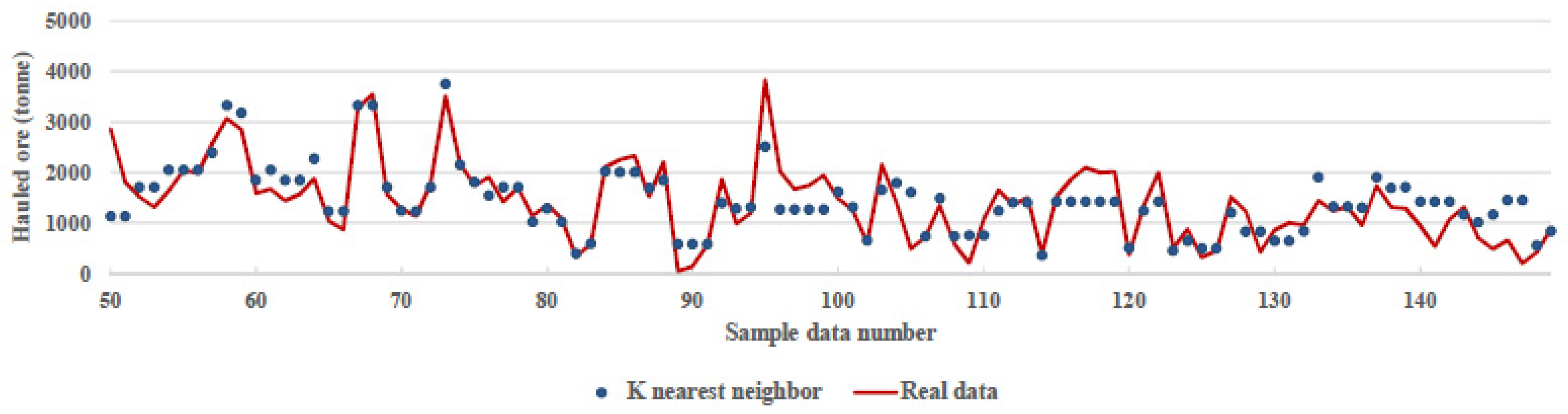
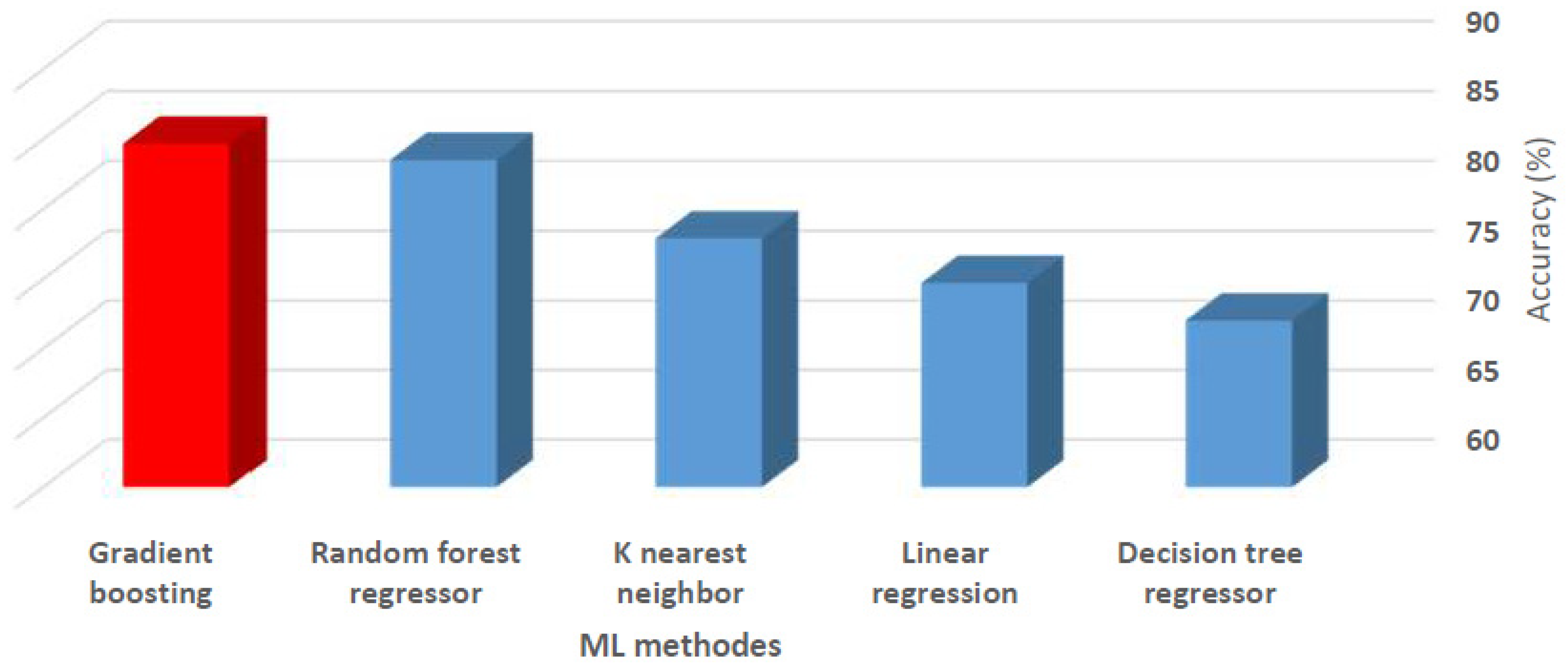
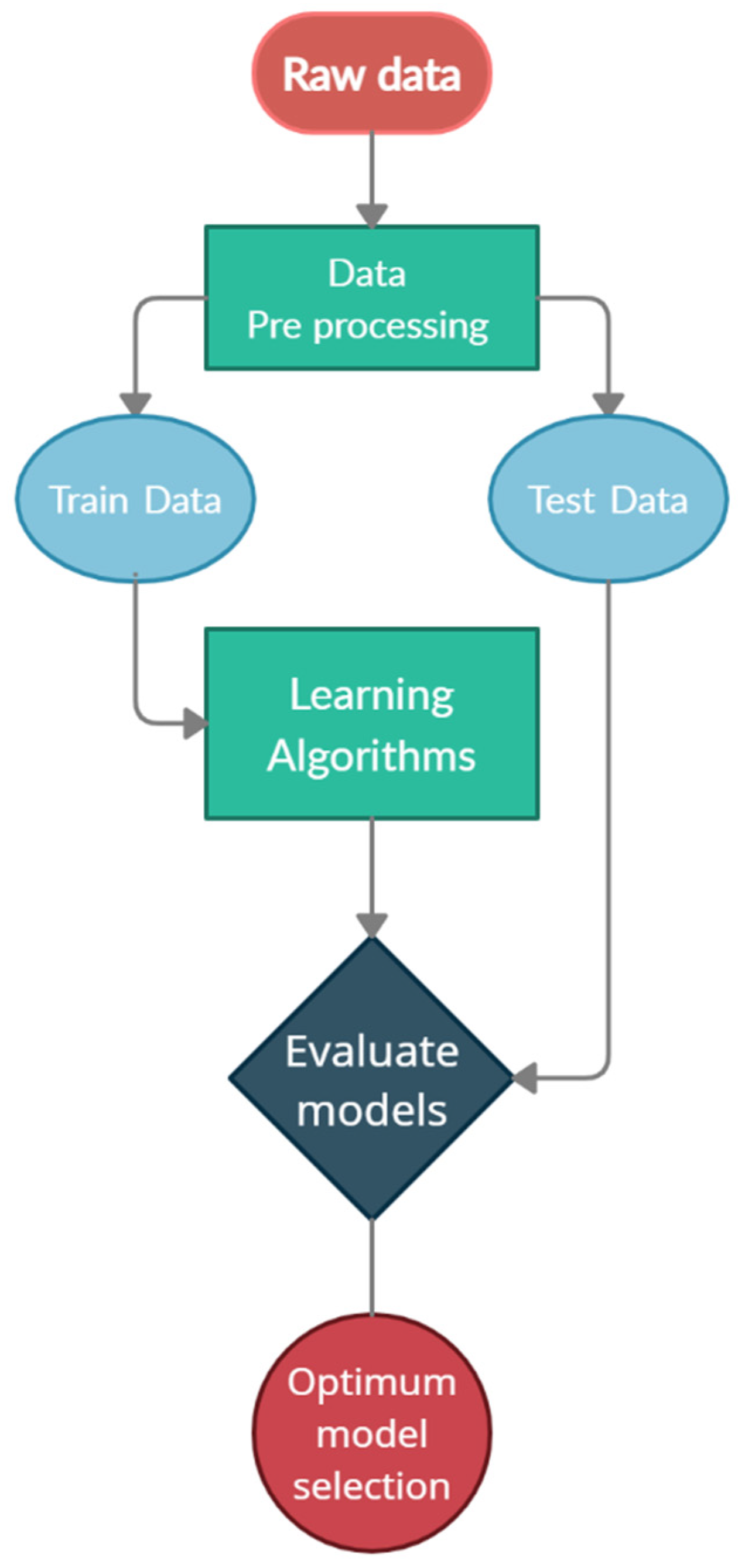
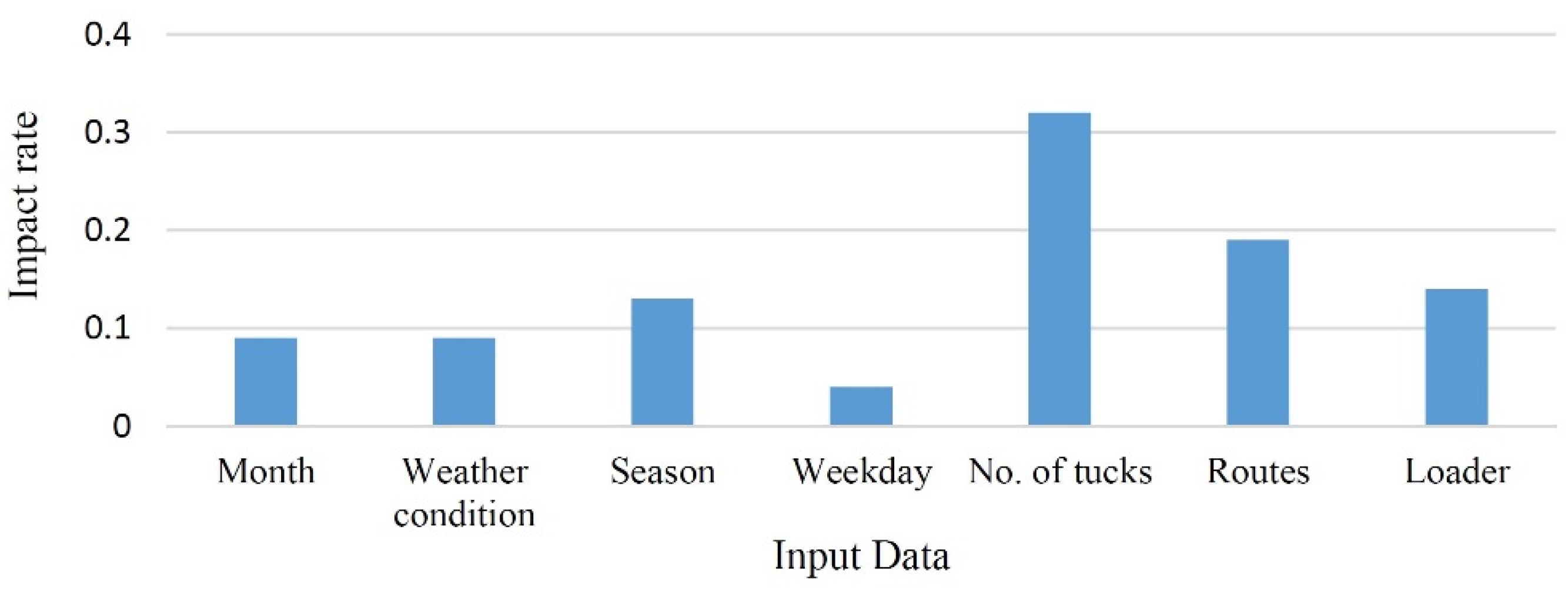
This paper uses machine ML, a novel approach known as a subfield of AI methods, which can be a beneficial approach to best fit environmental conditions and work situations to optimize fleet management and attain an adequate output. While fleet management is related to several factors and procedures, ML methods consider work situations, like routes, types of machinery, time, and weather conditions. Furthermore, these methods also help planners to make reliable and accurate predictions. Considering that this method uses historical data, one can be assured that the results of the method can be updated. On the other hand, with the progression of time and the adding of more data, the accuracy of the algorithms increases. Also, in this method, in contrast to other initiatives, the planning can be updated by considering various situations, even the difference in plant demand in a short time that does not require any costs for the mining department. In addition, this method can be used to predict machinery in the short and long terms.






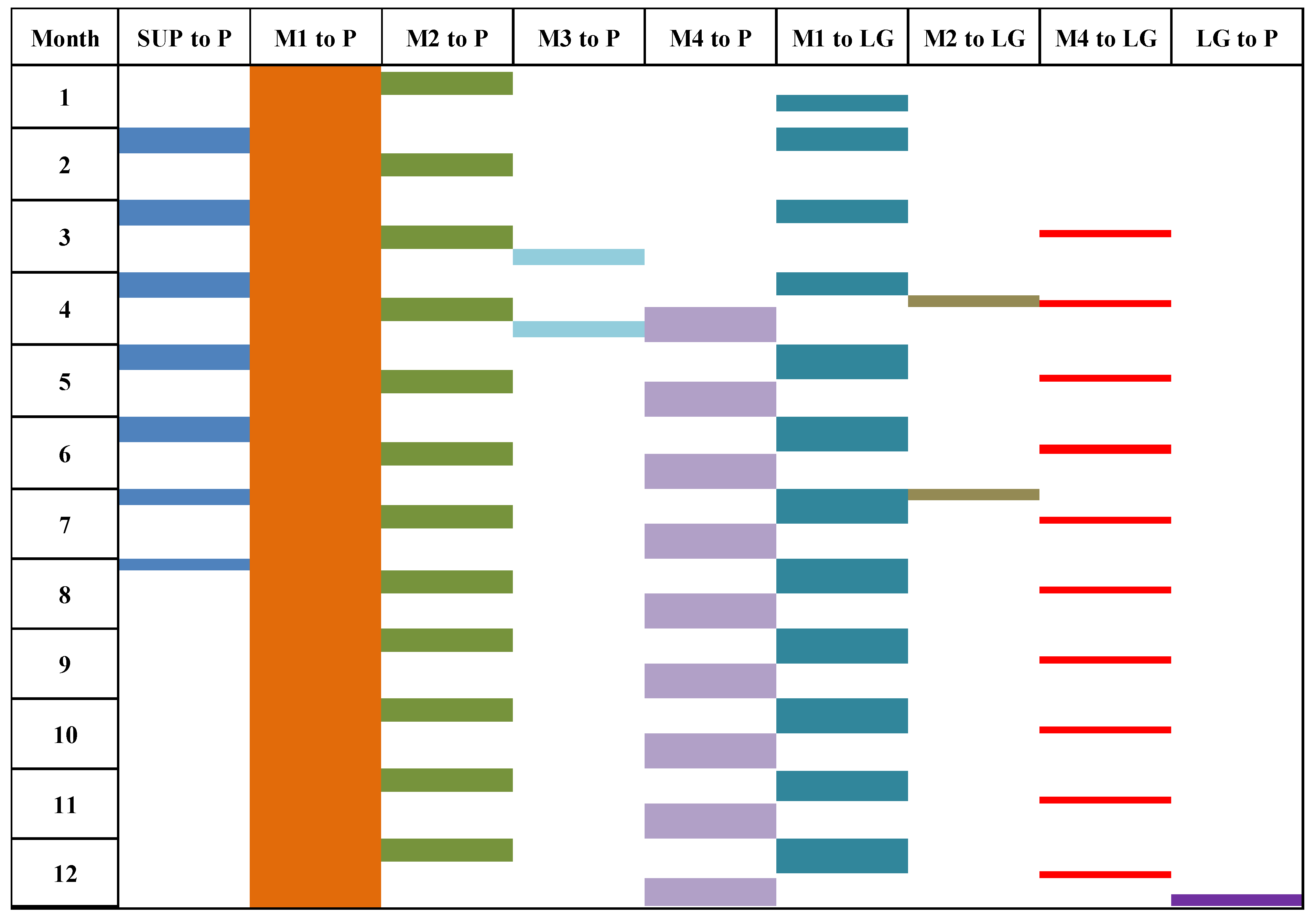
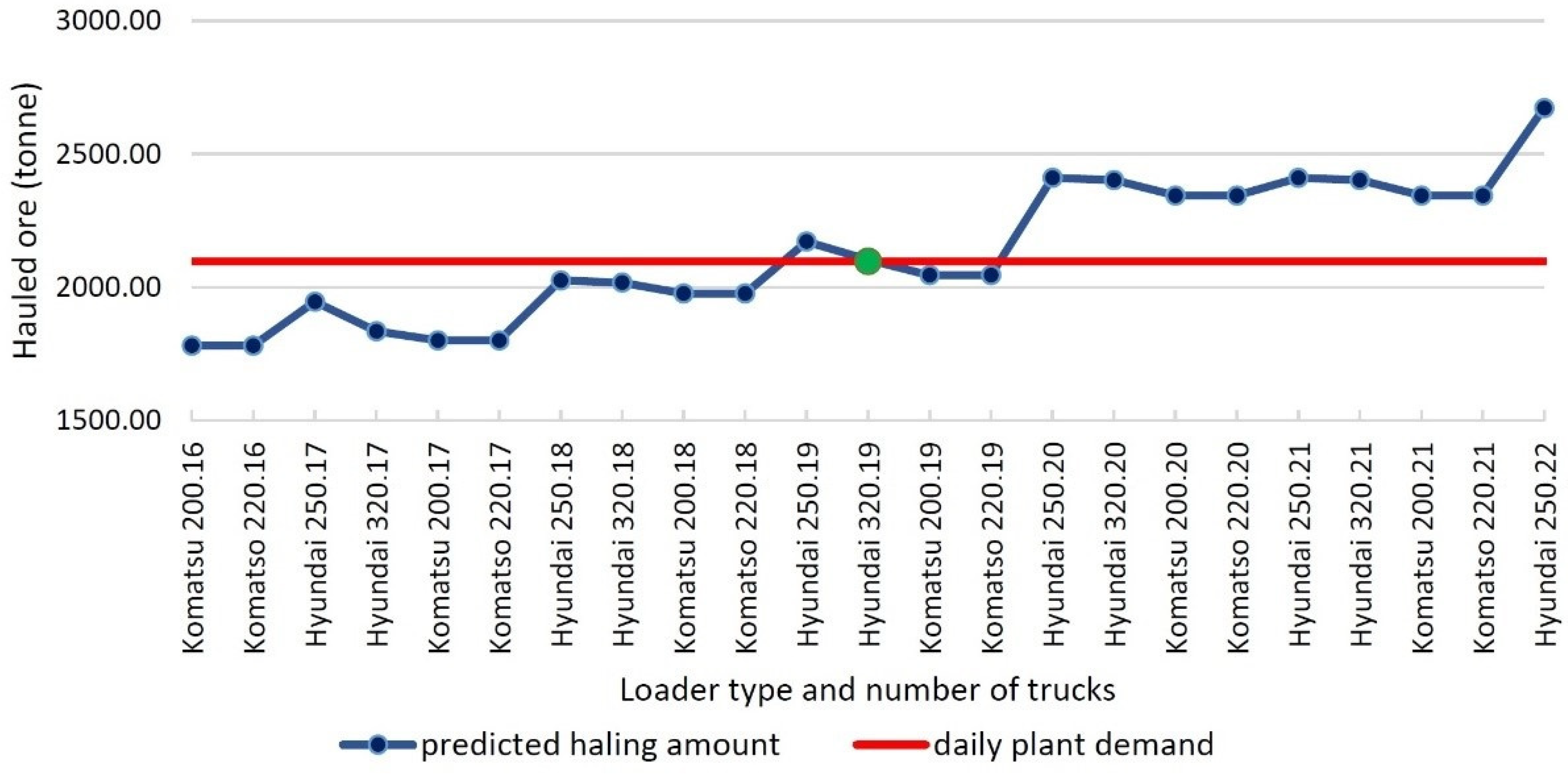

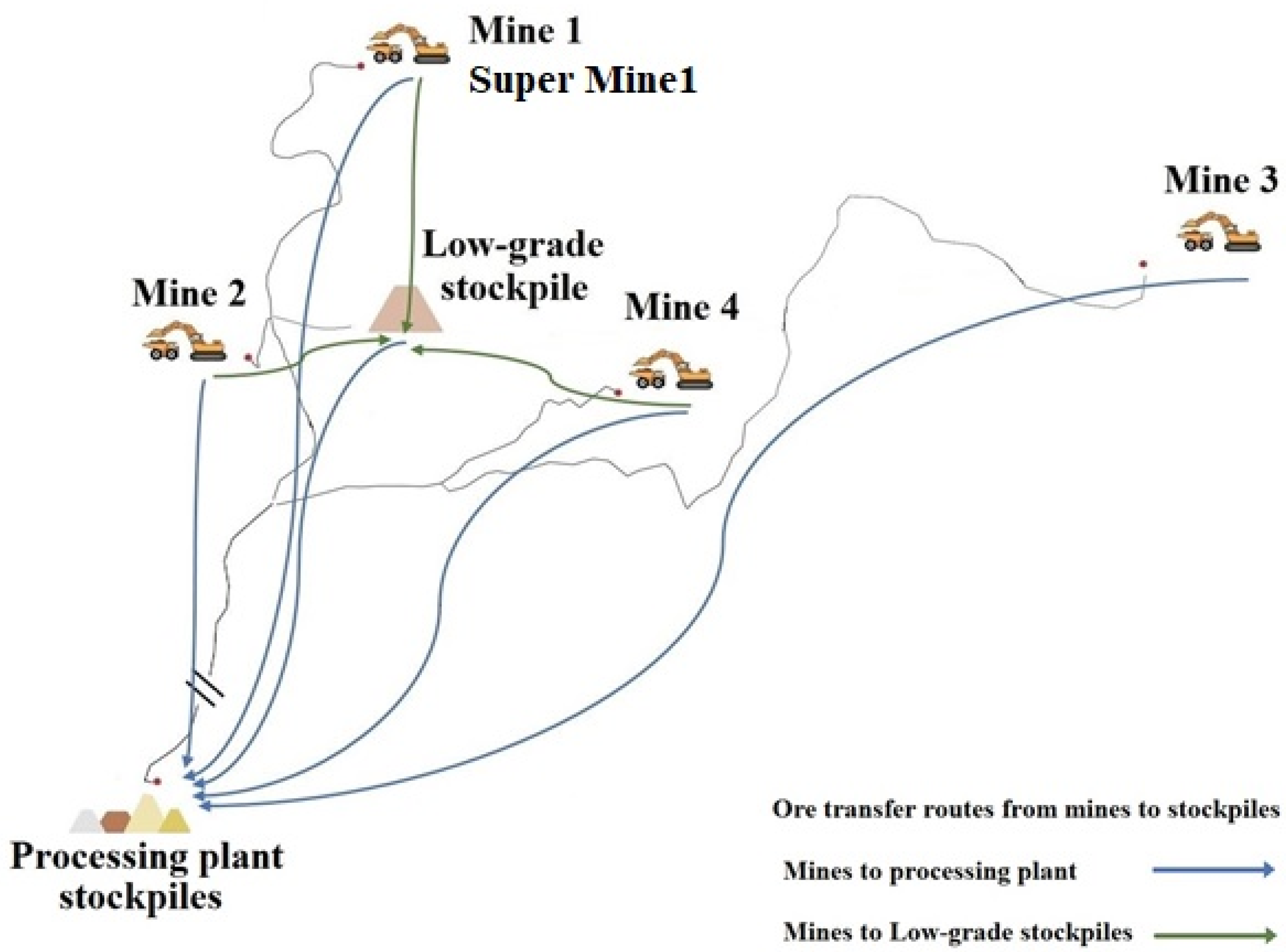
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
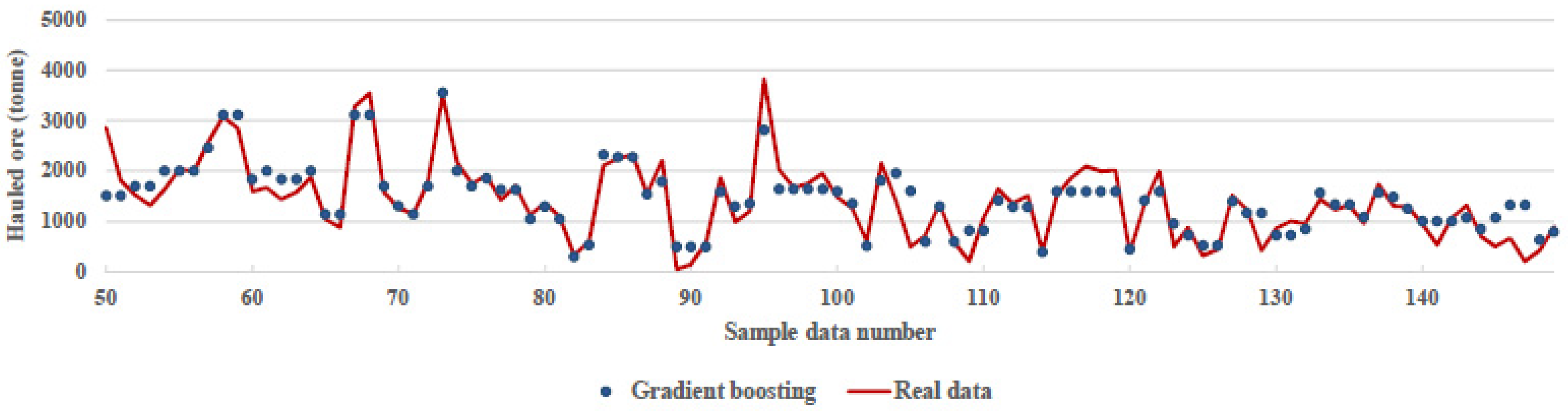{kind=link}
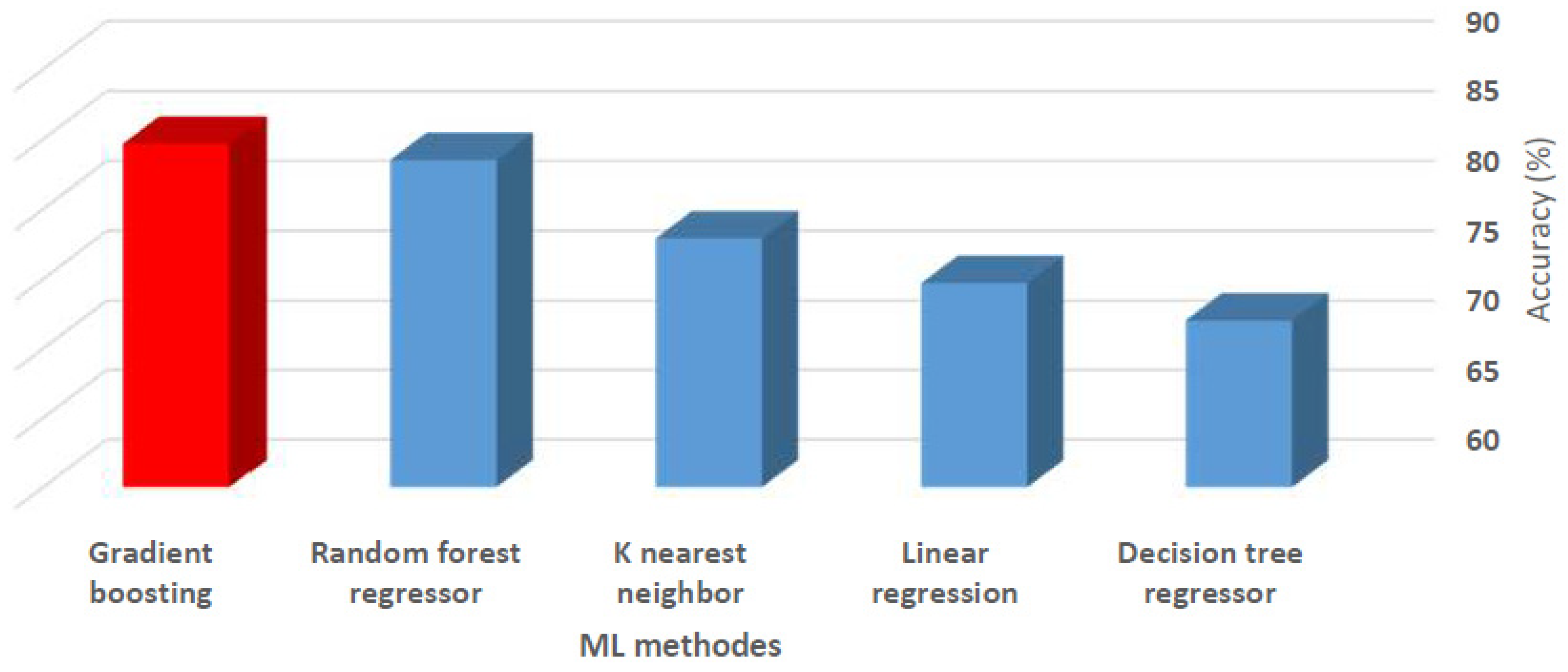{kind=link}
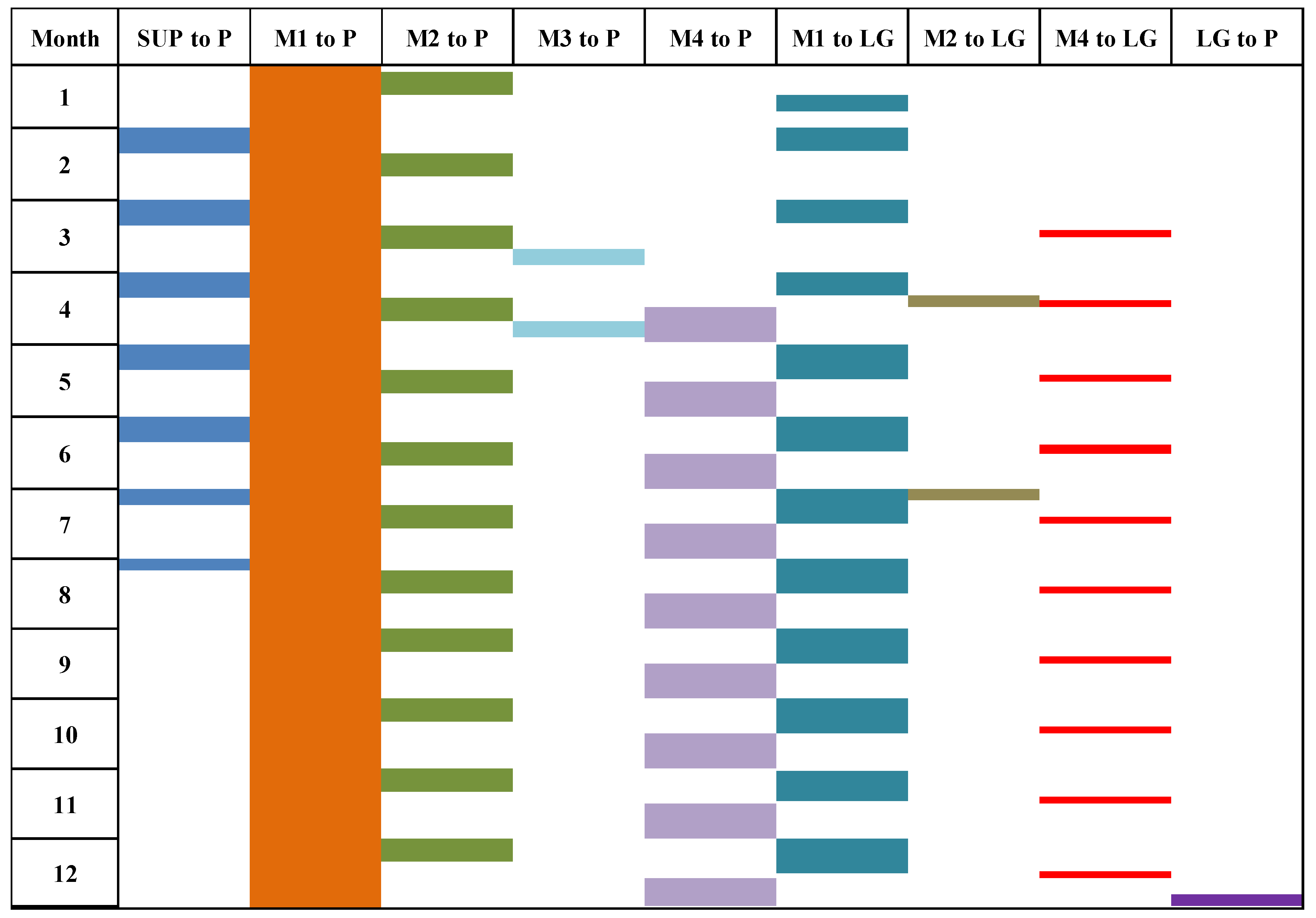{kind=link}
{kind=link}