4.1. Case Study: Regionalized Framework for Refractory Gold Systems
The current set of calculations focuses on a conceptual integrated gold mill originally designed for the processing of free-milling gold ores via conventional cyanide leaching. The underground mining operation is relatively small, providing on the order of 692.2 kt at 4.5 g/t Au for 100 koz of gold production per annum. With reserves in decline year over year, the mine is only forecasted to remain in production for another ~5 years. However, recent definition of a sizable satellite orebody (15.55 Mt at 4.5 g/t Au for 2.25 Moz) has significantly increased the resource base of the current operator. As a result, the company is considering upgrades to the current plant infrastructure to increase throughput and extend its operating life by bringing the new deposit online.
A potential limiting drawback is the mixed nature of the new resources; gold here occurs as native free grains in quartz-carbonate vein sets, coarse-to-fine inclusions in disseminated pyrite and both physically and chemically locked in disseminated fine-grained arsenian pyrite and arsenopyrite. The ore is mainly concentrated within a series of evenly spaced parallel subvertical structures within and adjacent to a broad shear zone spanning a major regional contact zone between mafic volcanic and sedimentary rock units. Detailed mineralogical, gold deportment and metallurgical testwork indicate that ~70% of the ore is refractory, with recoveries ranging from 30 to 99% by standard cyanidation. However, further testing has shown improved recoveries (>97%) for the refractory ore using a combination of concentrate flotation, ultrafine grinding and pressure oxidation.
Distal to the contact zone, the nature of gold mineralization is clear; whereas ore hosted within the mafic volcanics is generally free-milling, sediment-hosted refractory gold is strongly associated with As-bearing sulfides and related minerals. Unfortunately, the vast majority of the deposit occurs within the sedimentary units to the west of the main lithologic contact. Conventional and refractory ores are thus best delineated using mineral distributions and geochemical signatures that can define irregular domains of arsenic enrichment that are not clear upon visual inspection, i.e., ore type and grade calls are extremely difficult for the mine geologist. It would be both unproductive and unsustainable to perform expensive and time-consuming characterization testwork at the stope face following each round of blasting. Instead, the company has opted to undertake a major ore characterization program using drill core samples for geochemical, mineralogical and corresponding metallurgical response determinations. This data could then be used for predictive modelling of future ore block recoveries using data collected from drill core samples during routine definition drilling programs; this would allow for expedited decision-making earlier in the value chain, thereby improving mine planning.
However, given the high capital costs to upgrade the metallurgical plant, it remains unclear how the processing facility will respond to the varied ore types from multiple sources. Moreover, the operator is considering an ore sorting preconcentration step for the refractory ore prior to transport, which adds further complexity to the overall mass balance. There are also questions as to how to effectively design operating policies that will stabilize plant throughput against the significant potential for geological variability both within and between mining blocks from the new heterogeneous orebody. The overall concept for the calculations is summarized in
Figure 4; average ore compositions expected at the central mill facility include a 40–60% mass pull for refractory type ore resulting from the sorting process (see details in
Section 4.3). For the sake of clarity, the producing mine and new satellite deposit are herein referred to as Mines I and II, respectively.
This work implements stockpiling and blending practices using alternate modes of operation that can balance the ore feeds from the two mines in response to geological uncertainty. Ore type proportions for mining blocks from Mine II are based on predictive ML modelling of gold recoveries (using MLP regression), which are then combined with extracted ore from Mine I and fed into the DES portion of the framework to simulate system response. Adjustments can then be made to the available operational policies and related control strategies to maximize throughput and mitigate identified operational risks, e.g., ore stockouts.
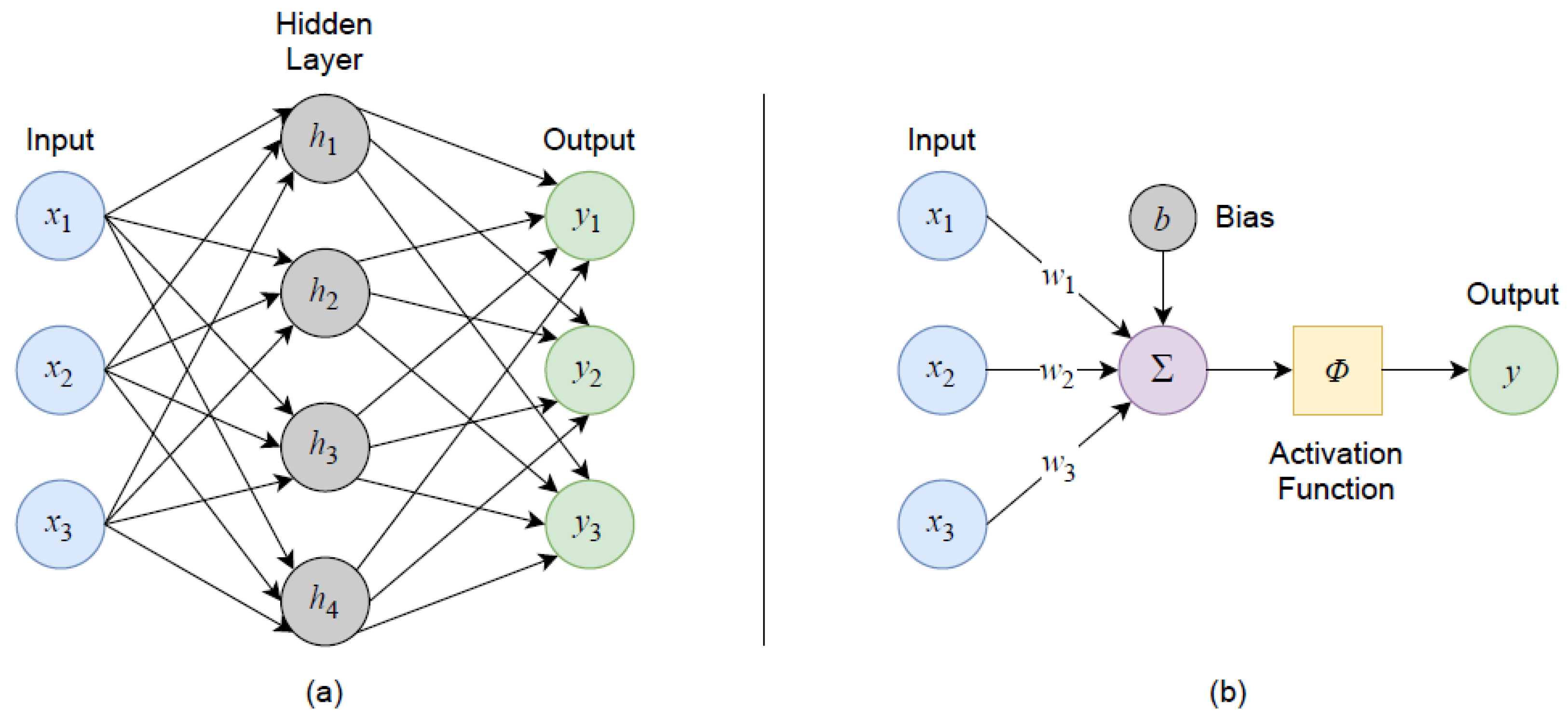
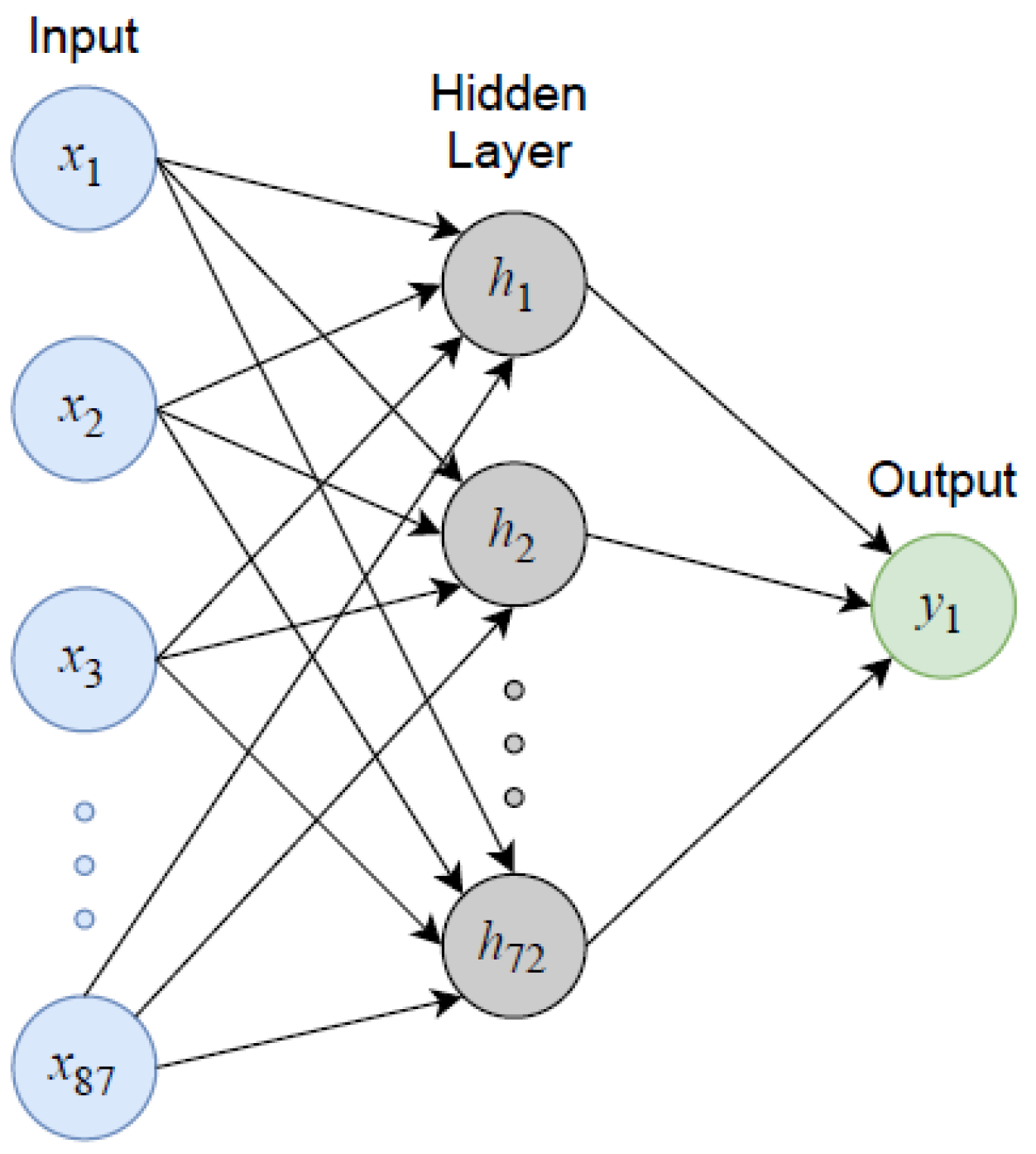
4.2. Multilayer Perceptron Regression Model
With the selected model architecture and hyperparameter tuning (see
Section 2.2), the model yielded its best performance with a training length on the order of 500 epochs, i.e., iterations through the entire training (
240 samples) and validation (
60 samples) sets. Plots of coefficient of determination (
score) and root-mean-square-error (RMSE) values show diminishing returns or reversals around this point for both training and validation subsets (
Figure 5). Overall, the extremely high
scores (>99%) and low RMSE values (<1.0) indicate that the model has performed very well on the current dataset. Moreover, the agreement between the training and validation metrics suggests that it is not overfitting to statistical noise and should thus generalize well to new data.
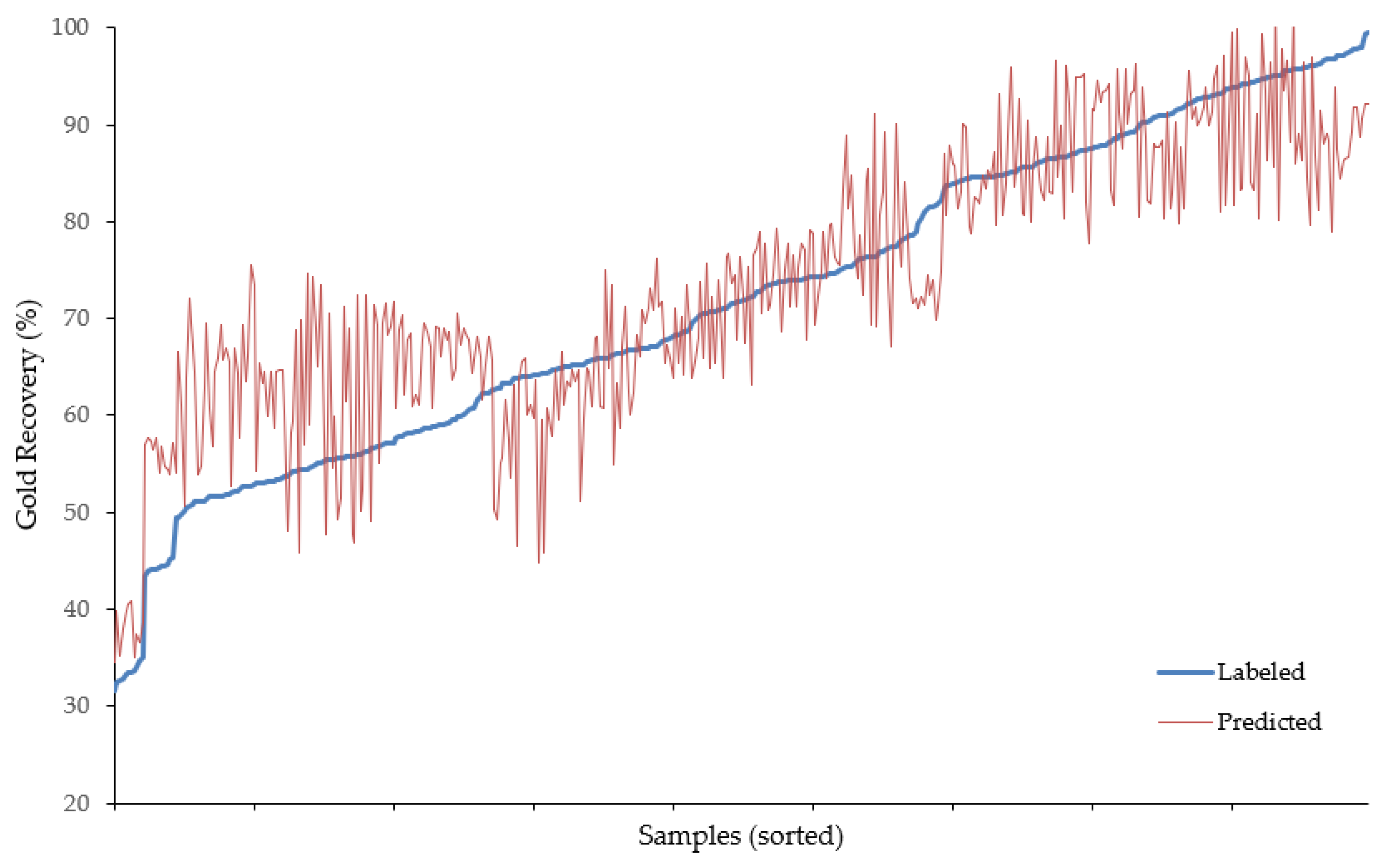
The model also performed quite well on the testing set, with
and RMSE values of 0.82 and 7.07, respectively. This indicates reasonable generalization to unseen datasets derived from similar geological environments and sampling protocols. Predictions from the final model (training length of 500 epochs) are shown with respect to the withheld observed (i.e., labeled) recoveries in
Figure 6, and comparative descriptive statistics are summarized in
Table 1. The predictive power of the model appears best in the mid-to-upper recovery ranges (~65–95%), which is positive as the most difficult and critical ore type classifications would occur in this span.
The decreased accuracy and higher error observed for the test set is not surprising, especially considering the relatively small training set size; in practice, a robust predictive model should be built on much larger datasets to improve confidence, particularly with the significant variability inherent to geological-based data. However, this exercise has shown the powerful predictive capability of MLP regression models for structured, i.e., tabular, datasets common to the mining industry. Regardless, the exact nature of the ML model is not what is important here. The key is that the presented model, despite performing rather well on the generated datasets, can be modified or replaced within the flexible DES framework to suit the needs or scope of the specific problem at hand.
It is critical for any sort of predictive modelling tool that appropriate ore characterization is established prior to implementation. This will often require an upfront surplus of sampling and analyses in order to adequately understand the nature of ore feeds; however, with sufficient time and validation of a robust predictive model, sampling frequency can likely be significantly reduced, in addition to more targeted analyses, both of which can result in long-term cost savings. Furthermore, with coupled analytical streams (e.g., geochemistry and mineralogy), additional savings may eventually be seen by employing other tools that could eliminate an analysis type altogether. For instance, with sufficient characterization, normative mineral phase calculations from geochemical data could possibly replace the need for mineralogical studies entirely.
In this study, the outputs of the MLP model, i.e., predicted recoveries, are used to determine relative proportions of conventional and refractory ore within each mining block from the new satellite deposit (Mine II). These proportions then serve as inputs for the DES framework in order to evaluate system-wide response to the varied ore feeds from both mines, under geological uncertainty.
4.3. Discrete Event Simulations
Ore type classifications for Mine II were based on the predicted recoveries made on the test set ( 450 samples). Ore with >90% recovery was deemed free-milling, whereas lower recovery rates were considered of the refractory type; these are herein abbreviated as FMO and RTO, respectively. In the context of this study, the test set also corresponded to the first 150 mining blocks (~3 years of production) forecasted for extraction from Mine II, allowing for a minimum of three samples per block. From a practical perspective, a much greater number of samples would be required for appropriate ore characterization; however, this setup was deemed sufficient for demonstrative purposes. Due to the limited number of samples available for ore characterization, natural background noise, i.e., geological uncertainty, was added to the relative proportions of FMO and RTO via random number generation using a normal distribution with a standard deviation of 3%.
Simplified mid-range mine plans were generated for each of Mines I and II, corresponding to ~3 years of operations. Both mines are expected to produce similar ore tonnages, on the order of 500 kt/y, from similarly sized stopes averaging ~10 kt each. According to these rates, each mine plan comprises 150 mining blocks; tonnages were randomly assigned using a uniform distribution between 5 and 15 kt. For Mine I, all ore was assumed to be free-milling; for Mine II, the relative proportions of FMO and RTO were determined as above. Moreover, the portion of RTO from Mine II was subject to a random mass pull in the range of 40–60% (with an assumed two-fold grade increase) by also applying a uniform distribution.
Additionally, a total of 100 of these mine plans, i.e., statistical scenarios, were created for each of the mines in order to evaluate system-wide effects in response to a range of potential distributions. This approach is critical to proper risk assessment and to improve confidence in the design of robust operational policies and practices under geological uncertainty. Finally, the two sets of mine plans were then combined using weighted averages to reflect the overall ore feed that would be received at the central processing plant, assuming similar production rates at Mines I and II. In this manner, a 70–30 tonnage split of FMO and RTO (recall
Figure 4) is expected as ore feed at the mill on average, bearing in mind that the refractory type ore has already undergone preconcentration via ore sorting. The proposed mining rates allow for a ~25% reduction in corporate guidance levels for Mine I, thereby extending operating life and providing more time to replace reserves through planned exploration. With the new production from Mine II, however, the result would be an approximate 50% increase in overall plant output to ~150 koz/y.
To handle the varied ore feeds, the proposed framework implements blending and stockpiling practices to mitigate the effects of unexpected changes in ore characteristics caused by geological uncertainty. These control strategies are described by two distinct operational modes, each governed by its own set of operating policies. Under Mode A, the mill receives 1245 t/d of ore from Mine I and 755 t/d of ore from Mine II; under Mode B, the mill receives 1370 t/d of ore from Mine I and 830 t/d of ore from Mine II. As summarized in
Table 2, the overall mass balance is such that Mode A is anticipated to deplete the RTO stockpile by 100 t/d, whereas Mode B is expected to replenish RTO by 220 t/d. Though Mode B achieves a higher overall throughput, Mode A is generally the preferred plant configuration as it produces an additional ~10 koz Au/y based on increased grades associated with a higher proportion of ore-sorted, i.e., preconcentrated, RTO. However, it is not sustainable to operate in Mode A indefinitely due to the rapid depletion of RTO using its assigned configuration rates. The decision to switch between modes is made at the end of 4-week production campaigns and is based on a determined threshold. When stockpiled RTO drops below this critical level at the end of a campaign, the planned one-day shutdown provides an opportunity for the necessary retooling of key equipment to apply Mode B, which acts as a replenishment phase.
Plant configuration rates for each mode, i.e., the absolute and relative proportions of FMO and RTO, are assessed with respect to geological forecasts of the combined ore feed from the two mines using mass balancing. Following the approach of Navarra et al. [
23], a deterministic analysis of the proposed configuration rates indicates that Mode A should be applied 2.2 times as frequently as Mode B, for an average throughput of 2062.5 t/d. However, this naïve calculation ignores the risk of stockout caused by geological uncertainty. The primary aim of the framework is to simultaneously maximize throughput and minimize target stockpile levels, meanwhile ensuring stable ore feed streams to mitigate stockout risk and avoid the disruption of continuous plant production. It is important to minimize stockpile levels as much as possible to reduce costs associated with excessive material handling and storage.
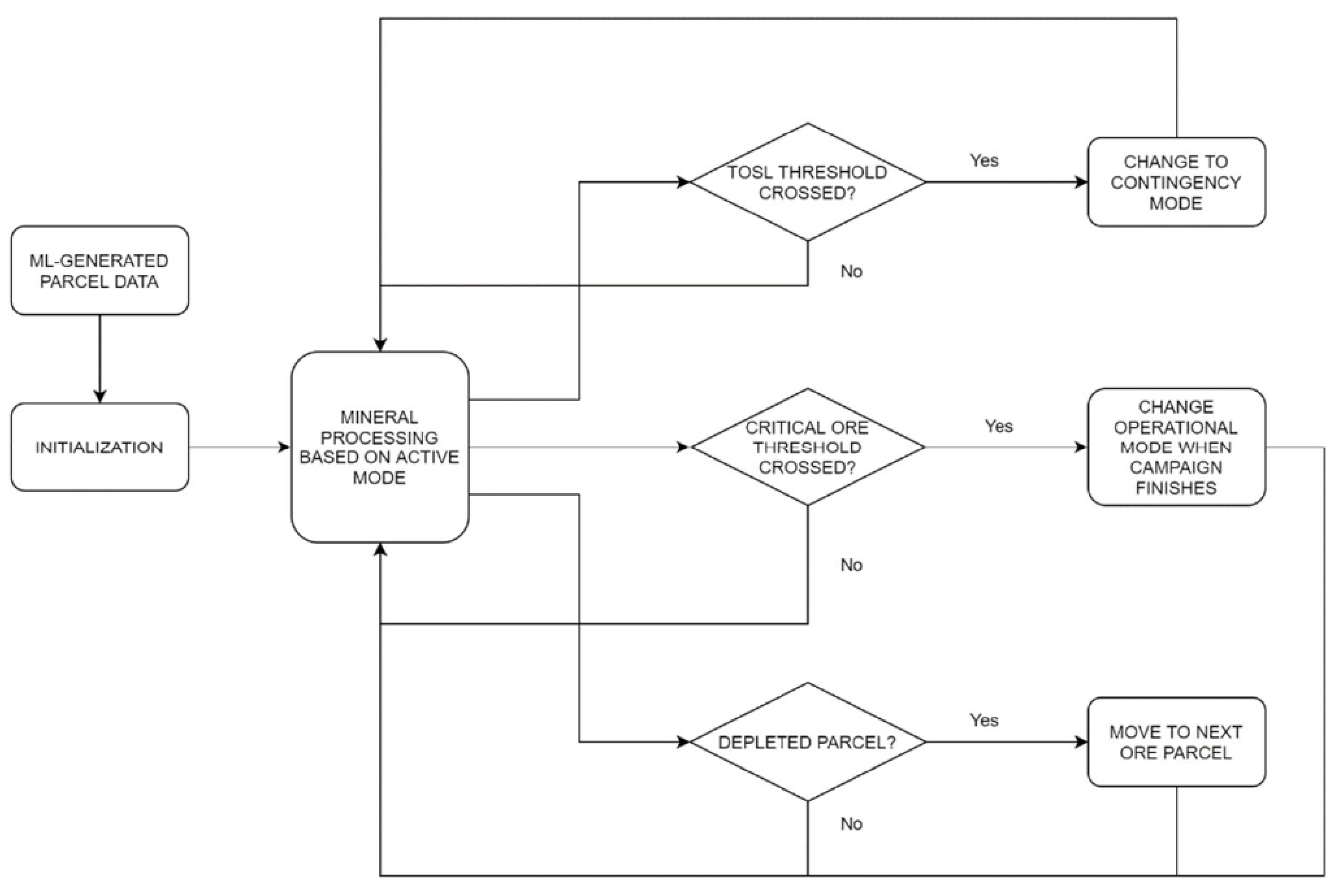
The framework implements two control variables in the decision-making process, including a critical RTO level and the target total stockpile level, computed as the sum of available FMO and RTO. Deterministic calculations indicate minimum threshold values of 2700 t and 5940 t for these variables, respectively. The critical ore level is determined as a function of campaign length (27 days) and rate of change under Mode A (100 t/d); the target total stockpile level is determined as the maximum rate of change between available FMO and RTO under either mode (220 t/d), also as a function of campaign duration. A negative threshold crossing for either of these variables represents a discrete event, which elicits a decision in the framework. Depending on the observed system response during simulations, these control variables can be adjusted by raising the threshold values as a form of operational buffer against geological uncertainty. Each simulation trial begins in Mode A as it is the more productive of the available operational modes; it is assumed that each combined ore feed block is processed to completion prior to loading the next parcel.
Recourse actions are also included in the model to handle situations in which one of the ore types is entirely depleted during a production campaign. When the target total stockpile level decreases below the set threshold prior to a planned shutdown, either a contingency mode or mining surge is enacted depending on the current system state. When the critical ore (RTO) is fully depleted under Mode A, a contingency mode is triggered, such that the configuration rate is reduced and only the available ore type (FMO) is processed for a brief 1-day period to allow RTO to temporarily replenish. Conversely, a depletion of FMO under Mode A requires a mining surge, which causes the total available ore to increase above the target level and is fed directly to the processing facility. When corresponding depletions occur under Mode B, these recourse actions are reversed. While these responses are important to relieve system stress caused by insufficient stockpile availability, they are generally unfavorable due to significantly reduced production throughputs; for instance, this study has opted to set production rates of 60% and 65% for the contingency modes under Modes A and B, respectively. As a result, adequately high threshold values for the two control variables must be selected to minimize the occurrence of such events, while balancing this risk against increased costs related to the additional infrastructure, equipment and handling required by larger stockpiles [
23,
25]. The overall decision-making logic for the model is shown in
Figure 7.
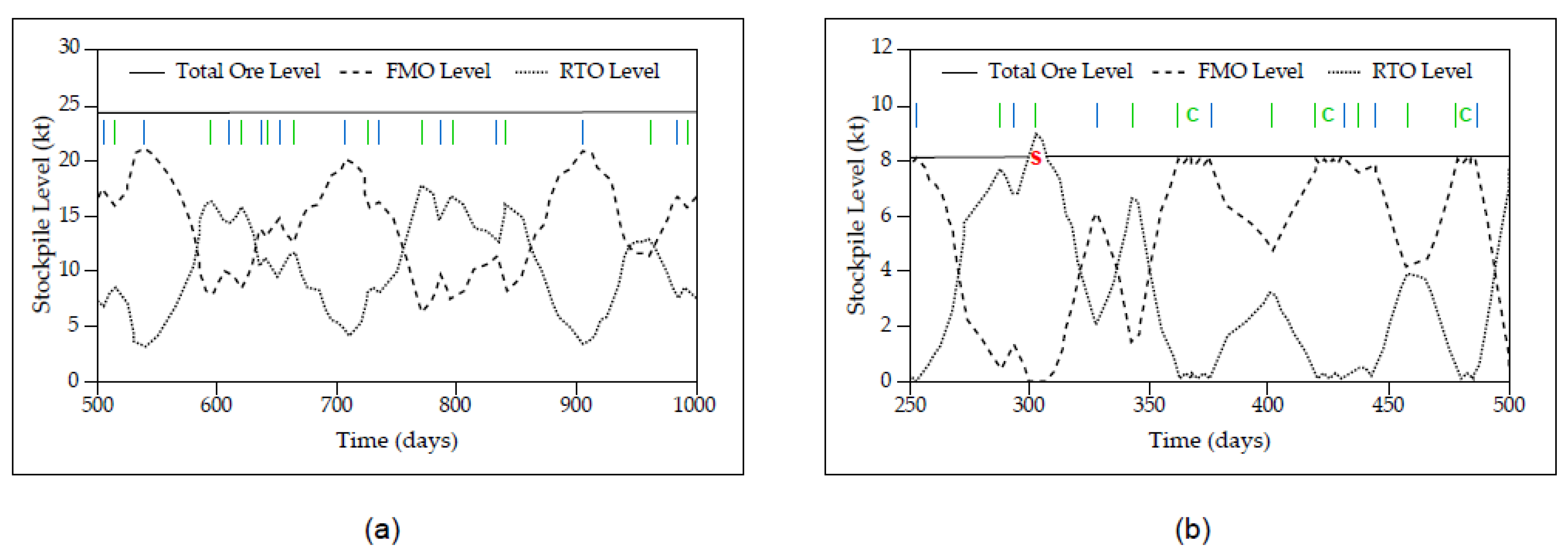
Representative graphical outputs from the DES framework are shown in
Figure 8, demonstrating the fluctuations in FMO and RTO feed stockpiles over operating periods of 500 days (
Figure 8a) and 250 days (
Figure 8b). The application of Mode A is indicated when FMO levels are increasing and RTO levels are decreasing; Mode B is reflected by increasing RTO levels and diminishing FMO levels. The alternation of these modes is key to the stable functioning of the processing plant by providing relief to the system before it comes under stress via suitably selected threshold values (e.g.,
Figure 8a). When these critical levels are set too low, the system is repeatedly stressed by inadequate ore availability, thus requiring immediate recourse actions which are both less productive and unsustainable.
Figure 8b illustrates a mine surging event caused by total depletion of FMO under Mode A (
300 days), wherein the additional ore is fed directly to the plant, in addition to three contingency mode segments caused by the depletion of RTO also under Mode A (
360, 420, 480 days). The jagged nature of the line segments in both plots is indicative of the significant geological uncertainty in combined ore feeds from both mines.
To select appropriate values for the two control variables, a series of simulations were run with varied combinations of RTO and target total ore levels attempted. Data from an initial set of six simulations are summarized in
Table 3; for these trials, the critical RTO level was held constant at 2700 t (deterministic result) and the target total ore level was varied between 5940 t and 12,150 t. This first pass was carried out on a single replication, i.e., one statistical realization or “mine plan”, in order to find a reasonable ore ratio range for further testing. In terms of throughput, it is clear that simulations 2, 3 and 4, corresponding to FMO:RTO ratios of 1.5, 2 and 2.5, respectively, performed the best. Despite a decrease in throughput, simulation 5 (3:1 ore ratio) was also retained based on a lower stockout risk. While simulation 6 did not experience any stockouts, it was ignored from further trials as stockpile levels would become unmanageably large as the critical ore level is raised. It is also notable that in general, the proportion of time spent in the more productive Mode A appears to vary directly with the FMO:RTO ratio.
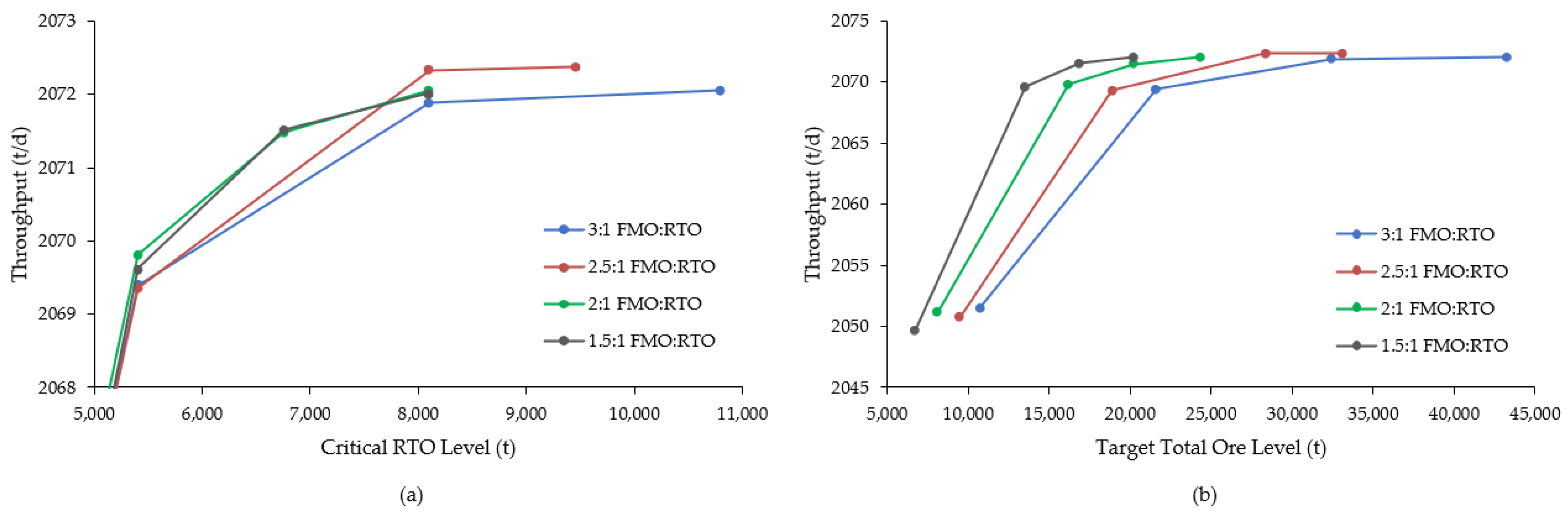
A second round of simulations then focused on raising the critical RTO level by factors of 2, 3 and 4 for each of the retained ore type ratios, i.e., FMO:RTO values of 1.5, 2, 2.5 and 3. These trials were executed using all 100 statistical replications in order to better gauge throughput rates and operational stockout risk over a range of distributions; the resulting data are summarized in
Figure 8 and
Figure 9. Throughputs for all of the ore ratio configurations appear to stabilize at a minimum critical RTO level of 8100 t (
Figure 9a) and target total ore levels in the range of 20–30 kt (
Figure 9b). While all of the ratios reached similar throughput rates, notably higher than the deterministic result of 2062.5 t/d, the two lowest ratios managed these levels with substantially smaller total ore stockpiles (differences on the order of 5–10 kt).
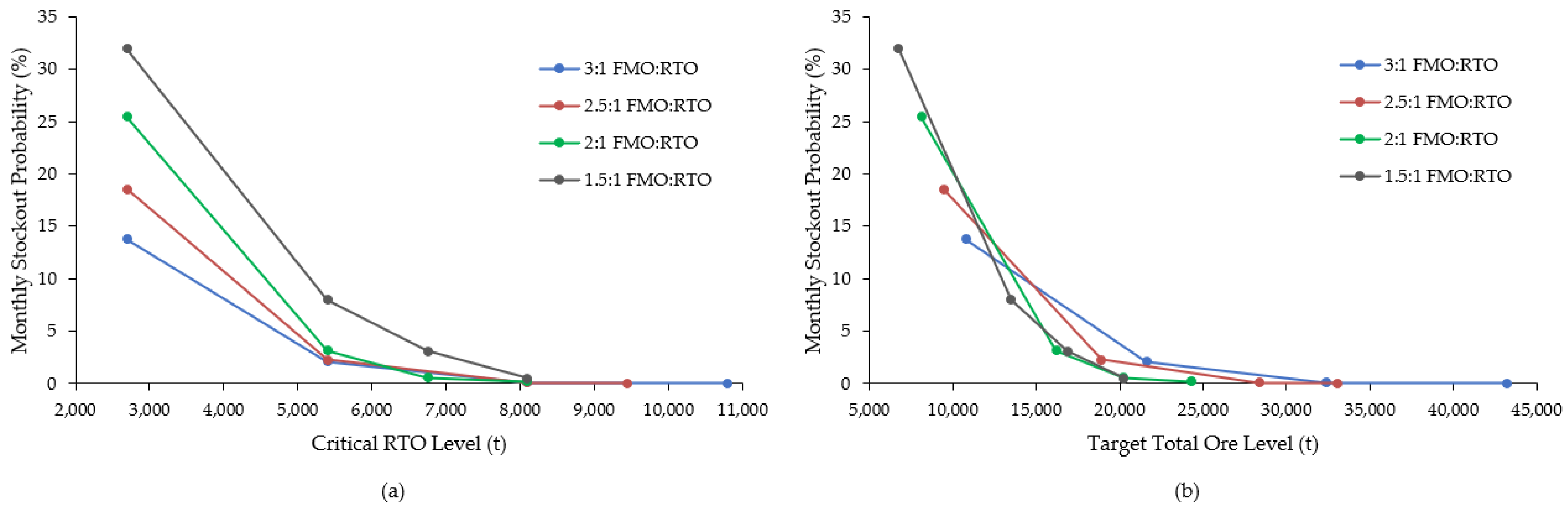
Considering the total tonnage from all 100 replications (~238.7 Mt) and the simulated average throughput rates, the resulting absolute numbers of operating days and ore stockout events were used to calculate the frequency of stockouts for each ore ratio. From these, monthly stockout probabilities were computed for each scenario, as shown in
Figure 10. These trends show that a 2:1 ratio of FMO and RTO generally reduces operational stockout risk (on a monthly basis) to near zero with the smallest ore feed stockpile levels. As a result, the final selected model for this study implements threshold values of 8100 t and 24,300 t for the critical RTO and target total ore control variables, respectively.
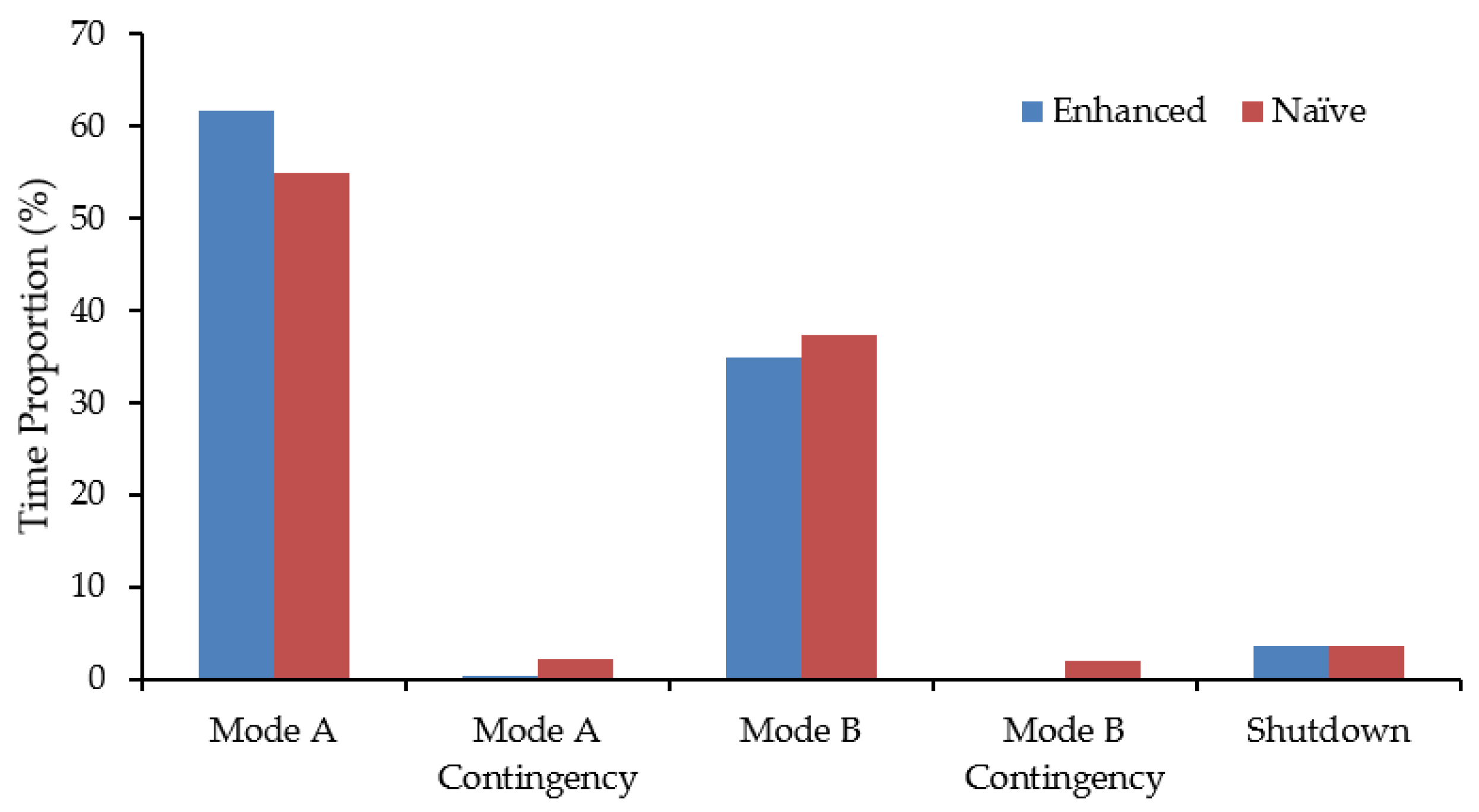
A histogram of modal time proportions (
Figure 11) compares the average performance of the final enhanced model vs. a naïve model that uses the deterministic values for both critical RTO (2700 t) and target total ore (5940 t) levels over 100 replications. It is evident that the enhanced model processes more ore under the more productive Mode A; moreover, this scenario results in less system stress resulting from ore feed depletions as evidenced by negligible application of contingency segments under either mode.
The stability of the final model allows for the efficient processing of 447.5 koz of gold (averaged over the 100 statistical replications) in ~3.15 years, which is just under the target annual guidance level of 150 koz. By comparison, the naïve scenario would take an additional ~2 weeks to process a similar number of ounces and would effectively be unsustainable due to chronic ore feed shortages. Armed with the confidence of stable system functioning using alternate modes of operation and the selected operational policies, a company is much better-positioned to proceed with a detailed project evaluation.
For demonstrative purposes, a high-level economic analysis using pretax net present value (NPV) was conducted to assess the value of bringing the new satellite deposit (Mine II) online. Under Option 1, the company simply continues to process the remaining ~500 koz of gold reserves at Mine I at a target annual guidance level of 100 koz; barring a significant resource expansion through underground exploration, the mine is thus projected to shut down in ~5 years. Under Option 2, guidance levels at Mine I are reduced to 75 koz Au/y, and Mine II is put into production at an equal guidance level for a target total of 150 koz Au/y. This would extend mine life at Mine I to just under 7 years, which also provides more opportunity to replace reserves. Once Mine I is fully depleted, guidance levels for Mine II would be increased to at least 150 koz Au/y to make up the difference.
To compare the two options, NPV was calculated as follows:
where
is the number of periods,
is the current time period,
is the net cash flow (i.e., revenue less costs) and
is the discount rate. Various gold prices from USD 1200/oz to USD 1900/oz were used as a form of sensitivity study to observe the relative trade-off. For Option 1, it was assumed that 100 koz Au are produced per annum at an all-in sustaining cost (AISC) of USD 850/oz. AISC is a non-GAAP (“generally accepted accounting principles”) measure frequently employed in the gold sector to improve transparency with stakeholders and provide a better comparative valuation scale for companies and/or mining projects. The AISC measure includes all operating costs, general and administrative site and corporate expenses, freight, treatment/refining costs, royalties, hedging effects, write-downs, sustaining capital (including near-mine exploration) and reclamation costs. The resulting NPV calculations for Option 1 are shown in
Table 4.
To evaluate Option 2, it is necessary to determine an approximate life-of-mine (LOM) for Mine II. Advanced deposit definition has identified 15.55 Mt at 4.5 g/t Au for a total of ~2.25 Moz of contained gold in reserves and indicated resources. The subvertical mineralized zones are expected to be extracted via the long hole stoping mining method. Using Taylor’s Rule [
59], this corresponds to an estimated mine life of ~12.5 years, assuming recovery and dilution factors of 85% and 15%, respectively. However, this option requires significant capital investment to increase capacity at the central processing plant and install an autoclave for the oxidative pretreatment of refractory ore. Community, permitting, distal exploration and nonsustaining capital costs are considered as “profit and loss” (P&L) investments, and are not typically included in AISC disclosures. An initial investment of USD 235M has thus been included at time
in the NPV calculations for Option 2, as shown in
Table 5. This amount includes USD 150M for a smaller industrial autoclave and USD 85M for the start-up costs at Mine II, in line with the upper range of average costs for an underground operation using long hole stoping with shaft access [
59]. In this scenario, both mines are operational for the first 7 years and the mill produces 150 koz Au/y at an assumed AISC of USD 1050/oz. Following depletion of gold reserves at Mine I, target guidance levels at Mine II are increased for the remaining 6 years with the mill continuing to produce 150 koz Au/y at an assumed AISC of USD 950/oz. Payback periods (in years) were also calculated based on cumulative NPV for each gold price.
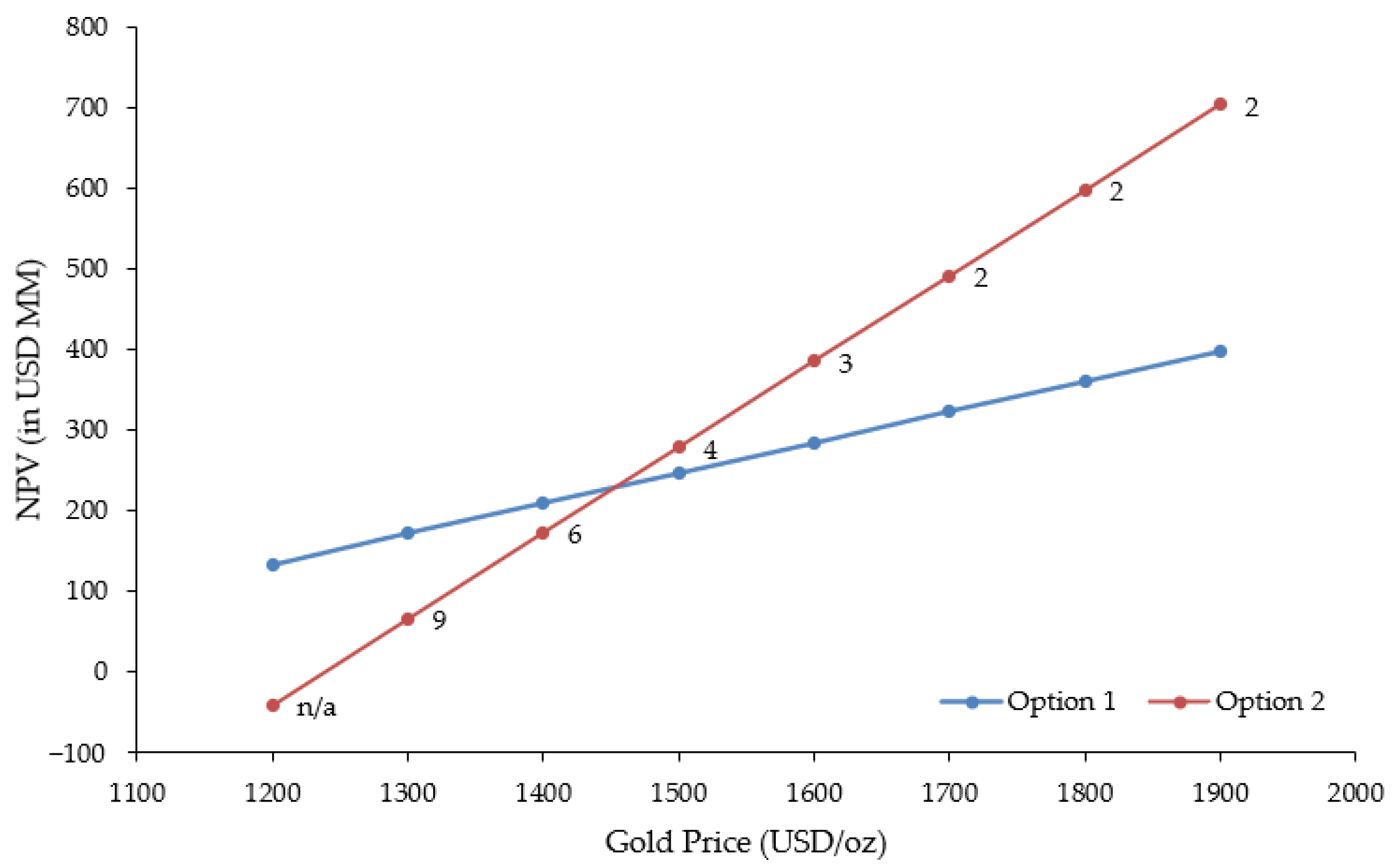
Figure 12 shows the relative trade-off between Options 1 and 2 over the range of gold prices considered for the current study. The breakeven point for bringing Mine II online appears to occur at a gold price of ~USD 1450/oz, with a payback period of ~5 years. The sensitivity to gold price could be further reduced by expanding the resource/reserve base at Mine II, in addition to further increases in mill capacity. This economic assessment is fairly crude in nature and relies on a number of assumptions; in practice, a much more elaborate evaluation would be completed using detailed capital and operating costs, coupled with historic and updated operational data from the plant in question.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}