
Feature Selection Based on Evolutionary Algorithms for Affective Computing and Stress Recognition †



Abstract
:1. Introduction
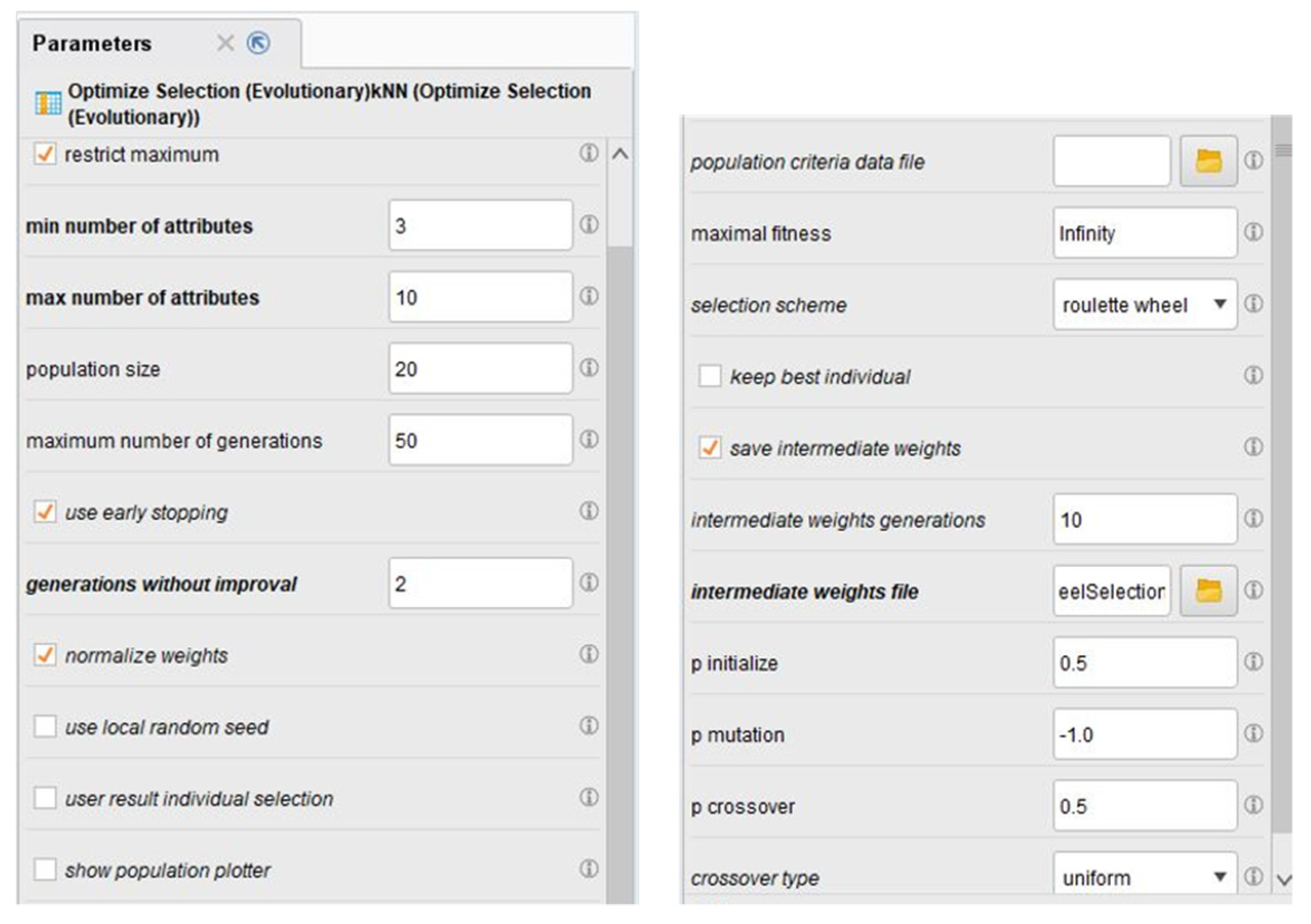
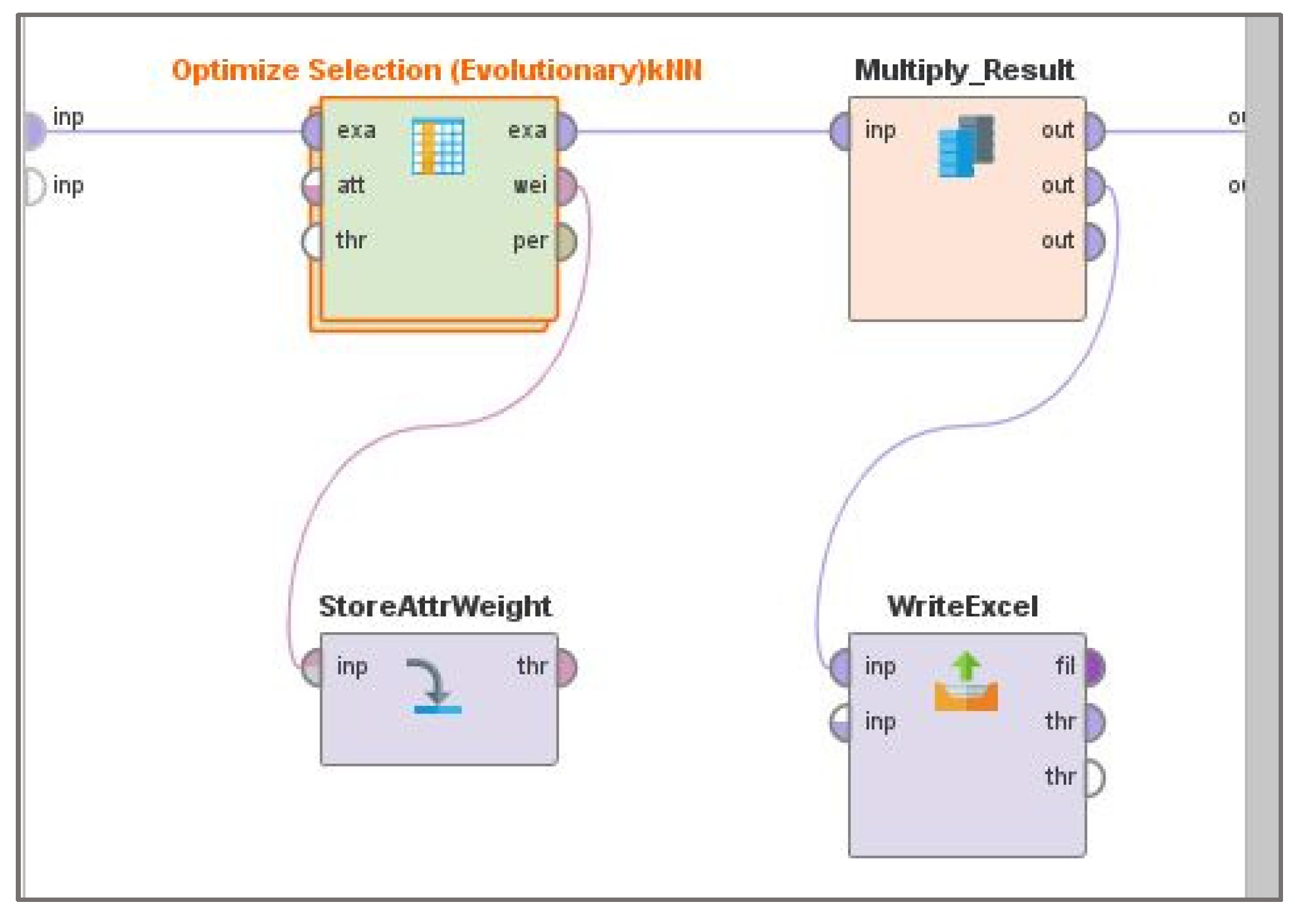
2. Materials and Methods
- Start with a randomly generated population of n parent individuals, where each individual represents a solution to a problem.
- Calculate the fitness (accuracy of the prediction, stating how good the individual solves the problem) of each parent individual in the population.
- Repeat a set of steps including mutation, crossover, evaluation, and selection, until n offspring (mutated and/or recombined version of the parent individuals, also synonym for all generated child individuals) has been created.
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Hazer-Rau, D.; Zhang, L.; Traue, H.C. A Workflow for Affective Computing and Stress Recognition from Biosignals. Eng. Proc. 2020, 2, 85. [Google Scholar] [CrossRef]
- De Jong, K. Evolutionary Computation—A Unified Approach; MIT Press: Cambridge, UK, 2008; Chapter 1. [Google Scholar]
- Rechenberg, I. Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipien der Biologischen Evolution; Frommann-Holzboog Verlag: Stuttgart, Germany, 1973. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems, 2nd ed.; University of Michigan Press: Ann Arbor, MI, USA, 1975; MIT Press: Cambridge, UK, 1992. [Google Scholar]
- Mamontov, D.; Polonskaia, I.; Skorokhod, A.; Semenkin, E.; Kessler, V.; Schwenker, F. Evolutionary Algorithms for the Design of Neural Network Classifiers for the Classification of Pain Intensity. In Multimodal Pattern Recognition of Social Signals in Human-Computer-Interaction (MPRSS 2018); Schwenker, F., Scherer, S., Eds.; Lecture Notes in Computer Science (LNCS); Springer: Cham, Switzerland, 2019; Volume 11377, pp. 84–100. [Google Scholar] [CrossRef]
- Kestler, H.A.; Haschka, M.; Muller, A.; Schwenker, F.; Palm, G.; Hoher, M. Evolutionary optimization of a wavelet classifier for the categorization of beat-to-beat variability signals. In Proceedings of the Computers in Cardiology 2000, Vol. 27 (Cat. 00CH37163), Cambridge, MA, USA, 24–27 September 2000; pp. 715–718. [Google Scholar] [CrossRef]
- Arunadevi, J.; Nithya, M.J. Comparison of Feature Selection Strategies for Classification using Rapid Miner. Int. J. Innov. Res. Comput. Commun. Eng. 2016, 4, 13556–13563. [Google Scholar] [CrossRef]
- Hazer-Rau, D.; Meudt, S.; Daucher, A.; Spohrs, J.; Hoffmann, H.; Schwenker, F.; Traue, H.C. The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction. Sensors 2020, 20, 2308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- RapidMiner Documentation—Operator Reference Guide. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/optimization/feature_selection/optimize_selection_evolutionary.html (accessed on 27 September 2021).
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1996; Chapter 1.6; pp. 8–12. [Google Scholar]
- Syswerda, G. Simulated Crossover in Genetic Algorithms. In Proceedings of the Second Workshop of Foundations of Genetic Algorithms, Vail, CO, USA, 26–29 July 1992; Whitley, D., Ed.; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993; pp. 239–255. [Google Scholar] [CrossRef]
- Daucher, A.; Gruss, S.; Jerg-Bretzke, L.; Walter, S.; Hazer-Rau, D. Preliminary classification of cognitive load states in a human machine interaction scenario. In Proceedings of the International Conference on Companion Technology (ICCT’17), Ulm, Germany, 11–13 September 2017; pp. 1–5. [Google Scholar]
- Hazer-Rau, D.; Zhang, L.; Traue, H.C. Performance Evaluation of Various Emotion Classification Approaches from Physiological Signals. Int. J. Artif. Intell. Appl. (IJAIA) 2018, 9, 31–41. [Google Scholar] [CrossRef]
- Zhong, J.; Hu, X.; Gu, M.; Zhang, J. Comparison of Performance between Different Selection Strategies on Simple Genetic Algorithms. In Proceedings of the 2005 International Conference on Computational Intelligence for Modelling, Control and Automation, Vienna, Austria, 28–30 November 2005. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Class-Problem | Feature Selection | Runtime | Classification Rates * (Training|Testing) |
|---|---|---|---|
| Two-classes | Evolutionary Algorithms | 6 min | 85.69%|86.64% |
| Forward Selection | 18 min | 86.14%|86.94% | |
| Six-classes | Evolutionary Algorithms | 23 min | 29.50%|28.84% |
| Forward Selection | 180 min | 29.46%|29.18% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hazer-Rau, D.; Arends, R.; Zhang, L.; Traue, H.C. Feature Selection Based on Evolutionary Algorithms for Affective Computing and Stress Recognition. Eng. Proc. 2021, 10, 42. https://doi.org/10.3390/ecsa-8-11288
Hazer-Rau D, Arends R, Zhang L, Traue HC. Feature Selection Based on Evolutionary Algorithms for Affective Computing and Stress Recognition. Engineering Proceedings. 2021; 10(1):42. https://doi.org/10.3390/ecsa-8-11288
Chicago/Turabian StyleHazer-Rau, Dilana, Ramona Arends, Lin Zhang, and Harald C. Traue. 2021. "Feature Selection Based on Evolutionary Algorithms for Affective Computing and Stress Recognition" Engineering Proceedings 10, no. 1: 42. https://doi.org/10.3390/ecsa-8-11288
APA StyleHazer-Rau, D., Arends, R., Zhang, L., & Traue, H. C. (2021). Feature Selection Based on Evolutionary Algorithms for Affective Computing and Stress Recognition. Engineering Proceedings, 10(1), 42. https://doi.org/10.3390/ecsa-8-11288