1. Introduction
Epilepsy is one of the most common neurological disorders, second only to stroke, affecting individuals of all ages worldwide [
1]. It is characterized by recurrent seizures caused by abnormal neuronal activity in the brain. Rapid diagnosis of seizures is critical for effective treatment and management [
2]. Electroencephalography (EEG), a non-invasive tool for recording brain electrical activity, is one of the most commonly used diagnostic methods for epilepsy. EEG signals recorded during epileptic episodes exhibit distinctive patterns, such as spikes and sharp waves [
3], which make them effective for detecting seizures.
However, long-term EEG monitoring presents significant challenges. Traditional manual analysis requires specialized expertise, is highly labor-intensive, and is prone to human error, especially when processing large volumes of multi-channel EEG data. Consequently, automating EEG analysis with robust machine learning techniques has become a critical area of research in neuroscience [
4,
5,
6,
7,
8,
9,
10].
Over recent years, deep learning (DL) methods have been widely used in EEG analysis due to their ability to directly extract hierarchical features from raw data [
2,
11]. Convolutional neural networks (CNNs) [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23], for instance, excel at capturing spatial representations in static data, while recurrent neural networks (RNNs), particularly long short-term memory networks (LSTMs) [
24,
25,
26,
27,
28,
29,
30,
31,
32], can model sequential dependencies more effectively than traditional methods. However, CNN-only models often fail to incorporate EEG’s temporal dynamics, and RNNs alone struggle to extract adequate spatial representations. Fusing CNN and BiLSTM (bidirectional long short-term memory) [
33] architectures, as proposed in this work, offers a promising solution.
However, the aforementioned approaches merely concatenate CNNs and LSTM networks in a straightforward manner. While these methods have achieved notable advancements in the speed and depth of feature extraction, the resultant signal features often remain redundant and demonstrate limited effectiveness in detecting and classifying anomalous signals. Specifically, such approaches overlook the interrelationships among feature vectors and lack mechanisms for reinforcing and reconstructing these features. In contrast, the integration of an attention mechanism enables selective reconstruction and enhancement of the extracted features, which strengthens the correlations among salient features and provides more informative feature representations for the classifier. By employing an attention mechanism, the interdependencies among the previously extracted features are enhanced, while the overall architecture of the network can be simultaneously simplified.
Recent studies have demonstrated that incorporating attention mechanisms into neural networks can significantly boost feature salience. For instance, Zhou [
34] introduced a recurrent neural network model augmented with an attention mechanism and achieved an accuracy of 94.4% in EEG signal recognition for patients with epilepsy. Similarly, Deng [
35] employed a method that fuses a one-dimensional convolutional neural network (1D-CNN) with an attention mechanism, yielding strong classification performance in automatic seizure detection. Chirasani [
15] embedded a hierarchical attention mechanism into a two-stream convolutional framework, leveraging weighted features to distinguish between healthy subjects and patients with epilepsy, which resulted in marked improvements across various performance metrics. Furthermore, Tong [
36] integrated a multi-head attention mechanism with a BiLSTM, achieving a recognition accuracy of 96.61% for interictal and ictal EEG signals.
Nonetheless, most current deep learning–based automatic seizure detection models emphasize the construction of increasingly complex network architectures to extract features from shallow to deep levels, or employ graph-based methods to develop two-dimensional CNNs. Other approaches rely on traditional machine learning techniques to construct feature vectors before applying deep learning for feature processing and classification. These strategies typically fail to consider the interrelationships among feature vectors and lack mechanisms for feature reconstruction and enhancement. Conversely, attention mechanisms have the capacity to reconstruct and reinforce features extracted via CNNs, thereby amplifying associations among salient features and yielding more informative representations for downstream classification tasks.
Distinct from these prior approaches, the present study employs a Squeeze-and-Excitation (SE) attention module to perform weighted fusion of dual-branch features, emphasizing inter-channel importance and concurrently mining multi-scale temporal–frequency information in parallel. This approach results in improvements in both predictive accuracy and model stability. We propose a spatiotemporal hybrid model that integrates an attention mechanism for the intelligent auxiliary detection of epilepsy. In this model, temporal and multi-scale frequency features are extracted and fused via two parallel branches, enabling the capture of both fine-grained and global information from the input data. An attention module is then introduced to reinforce relevant features and suppress irrelevant ones. Finally, global pooling and feature fusion are applied prior to classification. This design addresses the limitations of the aforementioned individual methods and offers a novel strategy for the intelligent auxiliary detection of epilepsy in clinical settings.
Furthermore, existing models are often bottlenecked by two major issues: (1) computational complexity, making them unsuitable for deployment on resource-constrained devices, and (2) limited attention mechanisms, reducing their ability to adaptively focus on critical EEG features. To address these limitations, this study introduces a novel dual-channel approach, incorporating Squeeze-and-Excitation (SE) ResNet modules and a dual-branch CNN to optimize both spatial and temporal feature extraction. Our lightweight yet powerful model is demonstrated to not only achieve state-of-the-art performance but also maintain high computational efficiency, making it suitable for real-world clinical applications.
2. Materials and Methods
This section provides an overview of the database utilized and the proposed methodology. A dual-channel feature fusion spatiotemporal model incorporating an attention mechanism is employed for the classification of seizures into three categories: ictal (seizure) states and interictal (between-seizure) periods.
2.1. Dataset Description
- (1)
Bonn Dataset
The present study utilizes data from the Epilepsy Center of Bonn University Hospital (BUK) for experimental analysis [
37]. This dataset is one of the most widely used resources in the field of seizure detection, providing an ideal foundation for testing and validating new methods for seizure classification. The database comprises five classes, labeled A through E, with EEG signals recorded from five participants per class. Each participant contributed 100 EEG signals, with each signal consisting of 4097 data points representing brain activity recorded over a duration of 23.6 s. The signals were sampled at a frequency of 173.6 Hz [
38].
The dataset comprises five classes:
- A:
Normal EEG recordings from healthy subjects (scalp, eyes open).
- B:
Normal EEG recordings from healthy subjects (scalp, eyes closed).
- C:
Interictal EEG recordings from epileptic patients (scalp, contralateral to the lesion).
- D:
Interictal EEG recordings from epileptic patients (intracranial, ipsilateral to the lesion).
- E:
Ictal EEG recordings from epileptic patients (intracranial, ipsilateral to the lesion).
For the purposes of this study, we selected classes A (normal), C (interictal), and E (ictal) due to their heightened clinical relevance in routine diagnostic procedures. Classes B (eyes-closed normal) and D (intracranial interictal) were excluded to maintain a focus on scalp-recorded, non-invasive EEG data, which represents the clinical standard for initial epilepsy screening. This selection enhances both the clinical applicability and translational relevance of our findings.
In this study, class A signals are selected to represent normal EEG activity, class C signals correspond to interictal EEG patterns in epileptic patients, and class E signals are indicative of ictal (seizure) activity.
Figure 1 illustrates examples of EEG signals from the A, C, and E categories.
- (2)
CHB-MIT Scalp EEG Database
To further evaluate the generalizability of our model on a larger and more heterogeneous dataset, we conducted supplementary experiments using the CHB-MIT Scalp EEG Database [
39,
40]. This database consists of scalp EEG recordings from 22 pediatric epilepsy patients, comprising 5 males (aged 3–22 years) and 17 females (aged 1.5–19 years). All participants discontinued treatment one week prior to data collection. EEG signals were acquired at a sampling rate of 256 Hz with 16-bit resolution. Most files include 23 EEG channels, though some contain 24 or 26 channels, and all recordings adhere to the International 10–20 electrode placement system. Expert annotations indicate seizure onset and offset times, with considerable variability in seizure frequency and duration among subjects.
For experimental consistency and to ensure sample balance, we selected datasets uniformly containing 23 channels. The data were categorized into three classes: neurologist-identified normal signals, seizure episodes, and pre-seizure segments—the latter being especially important for seizure intervention. From each patient, two 5 s EEG segments were included; any non-compliant data were excluded from analysis. In total, this process yielded over 40,000 data points for experimental evaluation.
2.2. Preprocessing of the Dataset
To ensure that the data from different samples maintains the same order of magnitude, pre-normalization and data cropping are commonly applied in deep learning. These preprocessing techniques facilitate faster model training and improve the generalizability of the final model. In this study, to evaluate the performance of our model, the raw EEG data were normalized by dividing each sample point by the maximum value of its corresponding electrode channel.
Additionally, since computers cannot process non-numeric data directly, the original categorical labels {A, B, C, D, E} were converted to one-hot encoded vectors and further simplified to numerical values for three-class classification as follows:
- 0:
Normal (classes A and B);
- 1:
Interictal (classes C and D);
- 2:
Ictal (class E).
Following preprocessing, the dataset was divided into training and testing subsets, which were subsequently used to train and validate the deep learning model.
The segmentation and normalization of EEG signals are primarily handled by the data preparation module.
2.2.1. EEG Segmentation
EEG segmentation is a standard preprocessing technique used to obtain smoother signals from EEG data. Since EEG signals are inherently non-smooth—characterized by time-dependent variations—segmentation is applied as a preprocessing step to reduce non-smoothness and achieve smoother representations.
In the dataset, each of the 500 EEG signals has a duration of 23.6 s. The signals are sampled at a frequency of 173.6 Hz, resulting in 4096 data points per signal (23.6 × 173.6 = 4096). After segmentation, each signal is divided into two equal parts, creating a dataset with dimensions of 500 × 2048 × 2.
Each of the 500 EEG signals (23.6 s, 173.6 Hz sampling) contains 4096 data points (23.6 × 173.6 = 4096). After segmentation, each signal is divided into two equal parts, resulting in a dataset with dimensions 500 × 2048 × 2 (samples × time points × segments).
It is important to note that the third dimension (2) represents temporal segments rather than electrode channels. The Bonn dataset is single-channel, recorded from the Fp2 scalp electrode, and the dual-channel model processes the two temporal segments independently to capture short-term temporal dynamics.
2.2.2. Normalization
Normalizing EEG signals is essential due to significant amplitude variations caused by individual differences. The normalization process is defined as follows:
where
and
are the mean and standard deviation of all records, respectively, and represent the value of each record.
For dataset partitioning, this study divides the dataset into a training set and a test set at a ratio of 7:3, ensuring a sufficient number of data samples for evaluating model performance. During the training phase, the model’s robustness is further validated using the quadruple cross-validation method. Specifically, the training set is divided into four sections, with one section used as the validation set while the remaining three sections serve as training data. The roles of the training and validation sets are alternated throughout the cross-validation process to ensure comprehensive evaluation of the model’s performance.
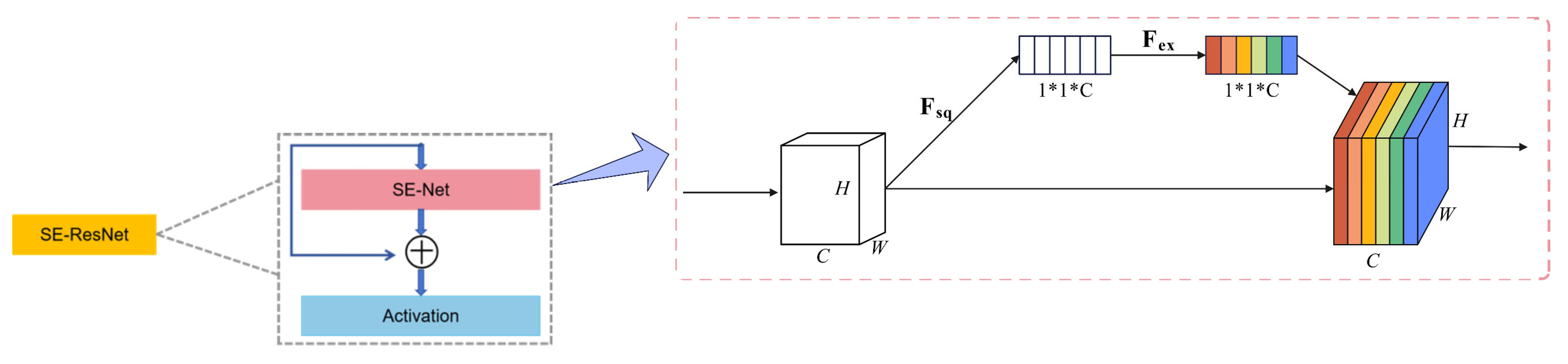
2.3. SE-Resnet Channel Attention Module
A key challenge in epileptic EEG classification lies in modeling the differences in voltage and signal amplitude across multiple channels. Treating all EEG channels with equal weight could result in information loss and reduce classification accuracy. To address this, we incorporate an SE-ResNet module, originally popular in image recognition tasks for channel attention, into our proposed model.
The SE-ResNet module has two key operations:
Squeeze Operation: Compresses global spatial information across all feature maps into a compact embedding via global average pooling. This step encodes the relevance of each feature map.
Excitation Operation: Applies fully connected layers and activation functions to the embedding, generating channel-wise weights that emphasize important features while suppressing less relevant ones. These recalibrated feature maps significantly improve the network’s ability to identify critical EEG features, as demonstrated in
Figure 2.
2.4. Chanel-1: BiLSTM_SE-Resnet Network
SE-ResNet focuses on the interdependencies between convolutional feature channels rather than emphasizing spatial information. The SE module consists of two key components: a compression operation and an excitation operation. The compression operation utilizes global average pooling to aggregate the most relevant information from each feature map, while the excitation operation computes inter-channel dependencies using fully connected layers and nonlinear activation functions. By scaling the importance of each feature map, the SE module enhances the network’s ability to distinguish essential channel-specific features.
Given that EEG signals are time-series data, long short-term memory (LSTM) networks outperform convolutional neural networks (CNNs) in classifying sequential data. The structure of a traditional LSTM is illustrated in
Figure 3. However, conventional LSTM networks have limitations in that they operate via one-way transmission. While they effectively extract data features in a forward direction, they perform poorly in recognizing backward dependencies. This issue is resolved through the bidirectional long short-term memory network (BiLSTM), which leverages both forward and backward information. The basic network structure of BiLSTM is depicted in
Figure 4.
Incorporating a BiLSTM module into the model improves its classification performance due to its ability to capture both temporal dependencies and bidirectional relationships. Based on these considerations, a novel BiLSTM_SE-ResNet network model is proposed in this study. The structure and parameters of the proposed model are shown in
Figure 5.
2.5. Chanel-2: Parallel Dual-Branch Convolutional Network
Convolutional neural networks (CNNs) are widely used for feature extraction from signal data. The structure of a CNN is illustrated in
Figure 6. The selection of the convolutional kernel is directly related to the receptive field of the network. In a CNN, there are two primary approaches to extracting more detailed features: increasing the network depth or increasing the network width.
While increasing the network depth can enhance feature extraction, it often leads to issues such as gradient explosion or vanishing gradients. These problems hinder parameter updates and adversely affect the network’s performance during training. On the other hand, increasing the network width effectively avoids these issues. To address this, a novel parallel dual-branch convolutional network is employed to increase the width of the network.
In this approach, each branch uses different convolutional kernels to extract feature details from the same original signal at varying levels. Because the network within each branch is relatively shallow, problems such as gradient explosion and vanishing gradients are effectively mitigated. The structure of the parallel dual-branch convolutional network is shown in
Figure 7.
2.6. The Proposed Method
Based on the above considerations, we propose a dual-channel feature fusion spatio-temporal model with an attention mechanism for the extraction, selection, and classification of features from epileptic EEG signals. The model’s feature extraction process is designed with two channels that simultaneously process the normalized EEG signals along with thermally encoded labels. The structure and parameters of the model are shown in
Figure 8 and
Table 1. The network primarily consists of a dual-branch convolutional network, a BiLSTM module, and an SE-ResNet attention module.
To enhance the feature extraction of temporal information, the EEG signals are input to Channel 1, which is comprised primarily of a BiLSTM and an SE-ResNet attention module. The BiLSTM is utilized to extract the temporal features embedded in the EEG dataset. To reconstruct and strengthen the extracted features and improve the association between effective features, the temporal features derived from the BiLSTM are fed into the SE-ResNet attention module. This enhances feature relevance, providing more robust feature vectors for classification.
Channel 2 is described as follows: The dual-branch CNN module in Channel 2 consists of two parallel branches, each with separate convolutional layers utilizing different convolutional kernels. This architecture increases the model’s receptive field and extracts feature structures at varying depths. Each CNN layer in both branches is followed by a Rectified Linear Unit (ReLU) activation layer and a pooling layer. The ReLU activation function is employed to prevent issues such as gradient explosion and vanishing gradients [
32]. A max-pooling layer with a stride of 2 is then applied to downsample the feature dimensions, improving computational efficiency.
Finally, the spatio-temporal features extracted from the two channels are concatenated using a concatenate layer, after which the detection classification results are obtained through a fully connected layer and a softmax activation function.
The final part of the model includes a fully connected layer with three neurons, where the softmax activation function is adopted. This model classifies epileptic EEG signals into three categories. To prevent overfitting and improve generalization, each convolutional and fully connected layer is connected to a dropout layer, with the dropout rate set to 0.5. By randomly deactivating specific neurons during training, the model’s performance is stabilized, and its ability to generalize is enhanced.
The loss function employed by the model during training is categorical cross-entropy. Furthermore, the learning rate is dynamically adjusted based on the validation loss using a learning rate scheduler in combination with the Adam optimizer. The model is trained with a batch size of 16 over a total of 100 epochs. The entire training process can be mathematically expressed by the following equation:
where
is the sample size;
and
are the true and predicted labels, respectively; and
is the categorical cross-entropy loss.
2.7. Evaluation Metrics
To evaluate the performance of the classification, this study employs the following evaluation metrics: sensitivity, specificity, and accuracy. These metrics are used to comprehensively assess the effectiveness of the proposed model. The calculations for these metrics are defined as follows:
- -
TP (True Positives) represents the number of correctly predicted positive classes;
- -
TN (True Negatives) represents the number of correctly predicted negative classes;
- -
FP (False Positives) represents the number of negative classes incorrectly predicted as positive;
- -
FN (False Negatives) represents the number of positive classes incorrectly predicted as negative.
2.8. Experimental Conditions
The model proposed in this study was trained on an NVIDIA GeForce RTX 4090 GPU with 16 GB of RAM, utilizing the TensorFlow v2.3 framework in conjunction with Python v3.8. The preprocessing of the dataset was implemented using Jupyter Notebook v7.0. To conduct quadruple cross-validation, the training set was evenly divided into four training groups. After each training session, the training and validation sets were alternated, and to reduce variability, the average results were calculated across the four rotations.
During training, the Adam optimizer was employed with a learning rate set to 0.001. Each batch consisted of 16 samples, and each experiment was run for a total of 100 iterations. The loss function used was categorical cross-entropy. Furthermore, the reliability of parameter updates was enhanced, as the learning rate for each iteration remained within a specific range due to bias correction performed by the Adam optimizer.
3. Results
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation, and the experimental conclusions that can be drawn.
3.1. The Experimental Result of Our Model
The performance of the proposed multi-channel spatiotemporal framework was evaluated using the publicly available Bonn University epilepsy dataset, which consists of three EEG categories: normal, interictal, and ictal. The dataset was divided into training and validation sets with a 70:30 ratio. The model was trained for 100 epochs with a batch size of 64.
Figure 9a presents the accuracy curves for the training, validation, and test sets. All three curves follow a similar trend, characterized by a rapid increase during the first 20 epochs (from approximately 35% to 90%), followed by stable convergence. The test accuracy (~98.57%) closely matches the validation accuracy, with a maximum deviation of less than 1% from the training accuracy. This consistency demonstrates the model’s robust generalization capability, as high performance is sustained on unseen data.
Figure 9b depicts the loss curves. The test loss stabilizes at approximately 0.2 after 40 epochs, closely paralleling the validation loss. Although the training loss decreases to around 0.05—reflecting optimization on the labeled data—the minimal gap (<0.02) between test and validation loss indicates the absence of significant overfitting.
For a more comprehensive evaluation of classification performance, we plotted the micro-averaged ROC curve on the test set (
Figure 10). The curve yields an area under the curve (AUC) of 0.9936, which approaches the theoretical maximum. This exceptionally high AUC, along with the curve’s proximity to the upper left corner, underscores the model’s ability to effectively discriminate between epileptic and non-epileptic signals with a minimal false positive rate—an essential consideration for clinical diagnosis. Notably, at a false positive rate of 0.1, the true positive rate exceeds 0.95, highlighting the model’s strong performance even under stringent error constraints.
3.2. Performance Comparison
To enhance the credibility of the experiment, the model was thoroughly analyzed by disassembling it layer by layer, and the performance of each component was compared under identical experimental conditions. All layers underwent the same data preprocessing procedures to demonstrate the necessity of performance enhancement and compensation across the model’s layers. Sensitivity, accuracy, and specificity were utilized during the testing phase to evaluate the classification performance of the model. The results are presented in
Table 2, with the best outcomes highlighted in bold.
The results indicate that the model proposed in this study achieves the highest overall performance, demonstrating superior classification results compared to other models. For epileptic EEG signal classification, the sensitivity and accuracy metrics are improved by approximately 7% compared to those of traditional CNN models. This improvement highlights the efficacy of the proposed multi-channel spatiotemporal hybrid model, which incorporates an attention mechanism, in correctly identifying positive samples while maintaining a lower loss rate.
Furthermore, the integration of the multi-branching module significantly enhances both accuracy and sensitivity. This improvement is primarily attributed to the module’s ability to enhance feature extraction, eliminate redundant features, and utilize the SE-ResNet module to emphasize the unique characteristics of the data. These advancements collectively validate the model’s superior performance in epileptic EEG signal classification.
Table 2 clearly illustrates that the proposed dual-channel architecture outperforms all baseline models across accuracy, sensitivity, and specificity metrics. Notably, our model’s specificity (99.43%) demonstrates its ability to markedly reduce false positives compared to traditional CNN methods, which scored 95.44%. This improvement is clinically significant, as it minimizes the likelihood of misdiagnosing normal EEG signals as ictal or interictal states, a critical factor in real-world applications.
Table 3 presents the classification performance of various candidate architectures in comparison to the proposed BiLSTM-SERNet-2CNN on the CHB-MIT dataset. All models were trained and evaluated using identical data splits. For each architecture, we report accuracy, sensitivity, and specificity as performance metrics.
As shown in
Table 3, the proposed BiLSTM-SERNet-2CNN model achieves the highest performance on the CHB-MIT dataset, with an accuracy of 98.65%, sensitivity of 97.06%, and specificity of 96.14%. Compared to the baseline 2CNN model, our approach improves accuracy by approximately 10 percentage points, and provides an additional ~3 percentage point gain over the BiLSTM-SEResnet architecture. These results demonstrate that the dual-branch time–frequency fusion combined with SE attention remains highly effective, even on a larger, multi-patient clinical dataset.
3.3. Comparison of Classification Performance with Other Methods
To validate the superiority of the proposed model, extensive comparative experiments were conducted against state-of-the-art methods.
Table 4 presents a summary of the performance of various approaches in classifying epileptic EEG signals. As demonstrated in the table, the proposed BiLSTM-SERNet-2CNN model achieves the highest classification accuracy, surpassing existing deep learning methodologies.
In addition to comparisons with our internal baselines, we evaluated the proposed model against several state-of-the-art methods previously reported in the literature, using the same CHB-MIT dataset.
Table 5 provides a summary of these comparative results.
As shown in
Table 5, our proposed model outperforms all previously reported methods on the CHB-MIT dataset. For instance, compared to the GIN model of Tao [
53] (96.20% Accuracy), our approach achieves a 2.45% improvement in accuracy. Similarly, relative to the BiLSTM + attention architecture of Alharthi [
54] (96.87% accuracy), our model demonstrates a 1.78% higher accuracy. These findings further validate the strong generalization capabilities of our method on a large, real-world EEG dataset.
3.4. Ablation Study on Hyperparameter Optimization
To assess the appropriateness of our hyperparameter selections, we conducted an ablation study examining variations in three key parameters: the number of BiLSTM units (64, 80, 128), CNN kernel sizes ([3, 5], [5, 7], [3]), and dropout rates (0.3, 0.5, 0.7). As summarized in
Table 6, the optimal configuration—comprising 80 BiLSTM units, dual-branch kernel sizes of (3, 5), and a dropout rate of 0.5—yielded the best performance, achieving an accuracy of 98.57% and a specificity of 99.43%.
4. Discussion
The present study proposed a novel dual-channel deep learning architecture that combines spatiotemporal feature extraction and attention mechanisms for the classification of epileptic EEG signals into three categories: normal, ictal, and interictal states. By leveraging the strengths of BiLSTM networks, SE-ResNet attention modules, and a parallel dual-branch CNN structure, the model achieves state-of-the-art accuracy while maintaining computational efficiency. This discussion evaluates the key aspects of the model, its performance relative to existing methods, and its clinical implications.
One of the primary contributions of this study is the combination of BiLSTM and SE-ResNet attention modules within the same channel. EEG signals are inherently dynamic and nonlinear, with strong temporal dependencies. While traditional CNNs excel at extracting spatial features, they often fail to capture these temporal relationships. The integration of BiLSTM networks into the proposed architecture addresses this limitation by allowing the model to extract bidirectional temporal features. Additionally, the SE-ResNet module enhances channel-wise feature dependency, effectively emphasizing critical EEG channels that may vary in signal characteristics across patients or conditions. This mechanism not only improves classification performance but also enhances the model’s ability to adapt to the unique patterns in complex EEG datasets.
The inclusion of a dual-branch CNN module in the second channel further amplifies the robustness and depth of extracted features. By using kernels of different sizes, the dual-branch structure captures feature details at varying receptive fields without increasing the network depth excessively. This design circumvents common issues such as vanishing gradients and excessive computational complexity. Ultimately, the dual-channel fusion mechanism effectively consolidates complementary spatial and temporal information, resulting in a more comprehensive and robust feature representation for precise classification.
The experimental results demonstrate the superior classification performance of the proposed model. With an overall accuracy of 98.57%, the model achieves substantial improvements over existing deep learning approaches in epileptic EEG signal classification. Notably, the specificity reached 99.43%, reflecting the model’s ability to minimize false-positive detections while reliably identifying normal EEG signals. Moreover, sensitivity improved by 5.12% compared to earlier CNN-based models, underscoring the efficiency of the dual-channel design in identifying ictal and interictal states.
The ablation studies conducted in this work highlight the importance of each component within the architecture. For example, the use of SE-ResNet contributed a 4.29% improvement in classification accuracy, while the BiLSTM module added a 1.62% boost in specificity. This demonstrates that the integration of attention mechanisms and bidirectional temporal modeling plays a critical role in optimizing the model’s classification capability. The multi-branch CNN module also significantly enhanced sensitivity and accuracy, further corroborating the effectiveness of leveraging multiple convolutional kernels to broaden the feature extraction scope.
In comparative experiments with existing methods, the proposed model consistently outperformed other deep learning architectures. For instance, the accuracy achieved by the BiLSTM-SE-ResNet-2CNN model surpassed that of traditional CNN-only models by approximately 7%. This remarkable improvement can be attributed to the attention mechanism’s ability to prioritize relevant features and eliminate redundant information. Furthermore, the proposed model achieved performance metrics that were superior to single-channel and uni-modal approaches, emphasizing the value of a multi-channel fusion strategy in capturing the full complexity of epileptic EEG signals.
In addition to accuracy, the proposed method demonstrated strong generalizability and scalability, as evidenced by its stable validation accuracy and lack of overfitting observed during training. This stability is particularly critical for clinical applications, where the ability to generalize across diverse patient populations and datasets is paramount.
A key strength of this study is the model’s lightweight design, achieved without compromising diagnostic accuracy or robustness. By maintaining a relatively shallow network depth and leveraging efficient modules such as SE-ResNet and BiLSTM, the model is well-suited for real-time clinical deployment on resource-constrained systems, such as portable medical devices. Furthermore, the use of cross-validation ensures that the model’s performance is rigorously validated against variability in the dataset. The ability to process raw EEG signals with minimal preprocessing simplifies their integration into real-world diagnostic workflows.
While our model exhibited excellent performance on the original dataset, these results alone do not ensure robustness across diverse clinical scenarios. To address this limitation, we conducted independent experiments on the larger CHB-MIT dataset. As presented in
Table 3 and
Table 5, the BiLSTM-SERNet-2CNN model achieved an accuracy of 98.65%, sensitivity of 97.06%, and specificity of 96.14%, outperforming both our internal baselines and several published methods. This strong performance on CHB-MIT—which comprises recordings from 23 distinct patients—demonstrates that our proposed architecture generalizes effectively to more heterogeneous, real-world EEG data. Moreover, these findings mitigate concerns regarding overfitting to a single dataset and support our assertion that the model can be reliably applied to other large-scale or multi-center EEG repositories.
However, certain limitations warrant further discussion. The model was validated on the Bonn University EEG dataset, which, while widely used and publicly available, may not fully represent the diversity of EEG signals encountered in different clinical settings. Additionally, the dataset’s relatively small size, with only 500 signals across three classes, cannot fully reflect the variability of EEG signals in larger patient populations or those recorded under different conditions. Future studies should aim to validate the model on larger, multi-center datasets that encompass a broader spectrum of epileptic EEG signals. Furthermore, although the dual-channel approach effectively integrates spatial and temporal information, it inherently increases computational complexity compared to single-channel models. Optimizing the model for even greater efficiency could enhance its real-world applicability in low-resource environments.
The proposed model holds significant potential for clinical application. Its high accuracy, sensitivity, and specificity could aid clinicians in the rapid and automated detection of epileptic seizures, reducing reliance on manual EEG analysis and accelerating diagnosis. Moreover, the model’s lightweight architecture could enable its implementation in portable or bedside monitoring systems, improving access to epilepsy diagnosis and management in both urban hospitals and remote healthcare facilities. These advancements could particularly benefit patients who require long-term continuous EEG monitoring for seizure prediction and intervention.
5. Conclusions
This study presents a novel dual-channel spatiotemporal deep learning model incorporating BiLSTM, SE-ResNet attention modules, and parallel dual-branch CNNs for the classification of epileptic EEG signals. The model effectively combines temporal dependency extraction with spatial feature representation, achieving a balanced and robust performance across sensitivity, specificity, and accuracy. With an accuracy of 98.57% and strong generalization capabilities, the proposed model outperforms existing state-of-the-art methods and demonstrates its potential for real-time clinical application in epilepsy diagnosis.
We have proposed a novel time–frequency fusion model, BiLSTM-SERNet-2CNN, for epileptic seizure detection. Beyond achieving state-of-the-art results on our original dataset, the model was further evaluated on the CHB-MIT Scalp EEG Database, where it attained an accuracy of 98.65%, sensitivity of 97.06%, and specificity of 96.14%, outperforming previously reported methods on the same dataset. These results highlight the strong generalization capability of the proposed approach across larger and more heterogeneous clinical EEG collections. In future work, we plan to extend validation to additional public datasets (such as TUH EEG and Bonn) and to investigate transfer learning strategies to further assess the model’s robustness in cross-domain scenarios.
The findings of this research underscore the value of integrating attention mechanisms and multi-channel architectures in deep learning for biomedical signal analysis. By prioritizing critical features and leveraging complementary spatial and temporal representations, the proposed model offers a highly effective solution for automated EEG classification.
Future work will focus on validating the model with larger and more diverse datasets, optimizing its computational efficiency, and exploring its application to other neurophysiological signal types. These efforts will further pave the way for the deployment of deep learning models in real-world clinical diagnostics, particularly for conditions requiring dynamic and high-resolution signal analysis, such as epilepsy. By bridging the gap between research innovations and practical healthcare needs, this work contributes to the advancement of accessible and efficient epilepsy monitoring and diagnosis.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}