1. Introduction
Warehouses play a pivotal role in supply chain management by ensuring efficient distribution and balancing supply–demand dynamics. Optimizing storage allocation reduces storage durations, minimizes travel distances, and alleviates product flow bottlenecks, thereby enhancing overall operational efficiency [
1]. Furthermore, effective storage coordination streamlines warehouse operations, particularly in order picking tasks. Integrating the processes of storing incoming items and scheduling the material handling equipment (MHE) that are responsible for transporting them to their designated locations is crucial for maximizing resource utilization. Suboptimal location assignments can lead to increased travel distances and congestion, ultimately degrading the MHE scheduling efficiency.
Efficient storage location assignment is critical for warehouse optimization. Recent advancements employ innovative computational techniques to enhance these assignments. Waubert de Puiseau et al. (2022) [
2] applied deep reinforcement learning (DRL) to optimize storage locations, demonstrating significant reductions in transportation costs compared to manual methods. However, storage location planning should not be treated in isolation, as it directly impacts order picking efficiency and task scheduling. Bolaños-Zuñiga et al. (2023) [
3] developed integrated models that simultaneously optimize storage allocation and picking routes, incorporating product weight to improve operational speed and accuracy. Cai et al. (2021) [
4] demonstrated that combining storage planning with robotic path optimization in automated warehouses reduces both time and energy consumption.
A warehouse storage location assignment policy (SLAP) enhances warehouse efficiency by aligning storage capacity with demand, addressing the critical warehousing problem of optimal product allocation. Hausman et al. (1976) [
5] pioneered SLAP for automated warehouses, with policies typically classified as dedicated (D-SLAP), class-based, or randomized (R-SLAP) [
6]. This study focuses on both dedicated and randomized policies. Traditionally, warehouses relied on D-SLAP, where each product is assigned a fixed storage location. While straightforward, this approach has notable drawbacks, including excessive space requirements to accommodate peak inventory levels for all products [
7]. Manzini et al. (2006) [
8] showed that D-SLAP in large-scale warehouses leads to significant underutilization of storage space.
In contrast, R-SLAP has gained prominence with advancements in warehouse management systems (WMSs). Bartholdi and Hackman (2008) [
9] showed that real-time WMS tracking enables efficient item retrieval, improving space utilization and operational flexibility. Quintanilla et al. (2015) [
10] proposed a metaheuristic-based model for R-SLAP optimization, incorporating construction methods and local search algorithms to evaluate relocation strategies. As warehouse complexity increased, advanced optimization techniques emerged. Larco et al. (2017) [
11] introduced a mixed-integer linear programming (MILP) framework to minimize order preparation time and worker discomfort, integrating production planning with R-SLAP. Similarly, Tang and Li (2009) [
12] applied ant colony optimization (ACO) to optimize product placement, reducing retrieval times and enhancing space efficiency. Zhang et al. (2021) [
13] further advanced this field by combining internet of things (IoT)-enabled tracking with randomized storage assignment, improving cost efficiency and space utilization.
The scheduling of MHE operations in a warehouse has the same structure of the parallel machine scheduling problem (PMSP). PMSP involves assigning products to several MHE, such as AGVs or forklifts. The models for the PMSP vary based on the characteristics of the machines involved. In the UPMSP, machines have different speeds and abilities to handle specific tasks [
14]. This situation is common in real-world warehouses, where different types of MHE are used for various items. This requires a scheduling approach that considers each task’s requirements, the machines’ capabilities, and their overall performance.
Recent research integrates scheduling and storage allocation assignment to optimize both simultaneously [
15]. This approach accounts for interdependencies between scheduling decisions and storage allocations, improving overall efficiency. Applications extend beyond warehousing; for instance, Tang et al. (2016) [
16] developed an MILP model for bulk cargo ports, optimizing space allocation and ship scheduling. Fatemi-Anaraki et al. (2021) [
17] proposed a mathematical model integrating berth allocation and vessel scheduling in constrained waterways. Chen et al. (2022) [
18] introduced an MILP framework combining vehicle routing problems (VRPs) with zone picking, enhancing economic and service performance.
Warehouse operations often involve conflicting objectives, such as minimizing travel time while meeting delivery deadlines. To address this, researchers employed multi-objective optimization approaches. Zhang et al. (2023) [
19] optimized storage layouts using a specialized algorithm, balancing picking speed and shelf stability for sustainable operations. Leon et al. (2023) [
20] combined simulation and optimization to model real-world conditions, improving storage assignments while considering order picking and routing. Antunes et al. (2022) [
21] compared different optimization algorithms and concluded that the choice of a solution approach depends on the problem characteristics. They motivated the choice of NSGA-II for this study.
NSGA-II has proven effective in complex multi-objective engineering optimization problems. Gao et al. (2024) [
22] employed NSGA-II to optimize feeder bus route planning, addressing passenger flow, travel time, and cost within a three-dimensional space that included timetable coordination. Their use of NSGA-II demonstrated the algorithm’s capacity to achieve uniform Pareto fronts and adapt to real-time constraints in urban transit systems. Ma et al. (2023) [
23] proposed an improved NSGA-II for maritime search and rescue operations under severe weather conditions, emphasizing the algorithm’s ability to balance exploration and exploitation through enhanced population diversity and multi-task knowledge transfer. Niu et al. (2023) [
24] utilized NSGA-II for hydrogen production optimization, demonstrating its robustness under fluctuating power inputs. These recent studies underscore NSGA-II’s adaptability, supporting its adoption in this study for optimizing warehouse operations.
Despite extensive research on warehouse optimization, few studies address the joint optimization of storage location assignment (SLAP) and MHE scheduling decisions. This work bridges this critical gap by conducting a comparative analysis of two fundamental storage policies—Dedicated (D-SLAP) and Randomized (R-SLAP)—while simultaneously optimizing transportation costs, waiting times, and order lateness in warehouse operations.
This research is motivated by the growing operational complexity of modern warehouses, where co-optimization of storage allocation and MHE scheduling is essential for maximizing efficiency. By integrating SLAP with UPMSP, we present a multi-objective framework to evaluate how these policies differentially impact warehouse performance metrics, including cost efficiency and customer satisfaction.
Both SLAP and UPMSP are NP-hard combinatorial problems, rendering exact optimization methods computationally intractable. To address this, we leverage NSGA-II, a metaheuristic tailored for multi-objective optimization under conflicting criteria. NSGA-II is selected due to its:
Proven efficacy in Pareto front exploration, ensuring balanced trade-offs between objectives (e.g., minimizing transportation costs vs. tardiness).
Adaptability to problem-specific constraints, achieved through a customized three-string chromosome encoding that jointly optimizes scheduling and storage decisions.
Established robustness in logistics literature.
The proposed framework is validated via rigorous computational benchmarking and statistical testing, comparing D-SLAP and R-SLAP across scalable problem instances. Accordingly, the key contributions of this study are as follows:
Novel Integration of SLAP and UPMSP: A unified optimization model incorporating real-world constraints (precedence relationships, machine eligibility, limited resources, and dynamic product flows).
Algorithmic Innovation: A modified NSGA-II with a three-string chromosome representation, enabling simultaneous optimization of storage allocation and MHE scheduling.
Policy-Centric Benchmarking: A data-driven evaluation of D-SLAP and R-SLAP using multi-objective performance metrics (hypervolume, spacing) and parametric and nonparametric statistical tests, providing actionable insights for warehouse design.
The paper is structured as follows:
Section 2 formulates the problem and details the proposed NSGA-II implementation, including performance metrics and parameter tuning.
Section 3 presents experimental results across generated test instances.
Section 4 provides statistical analysis of the findings.
Section 5 concludes with key insights and future research directions.
2. Materials and Methods
This research proposes a comparative study of the performance of D-SLAP and R-SLP while utilizing an integrated strategy for scheduling MHE and storing goods in warehouses.
2.1. Problem Definition
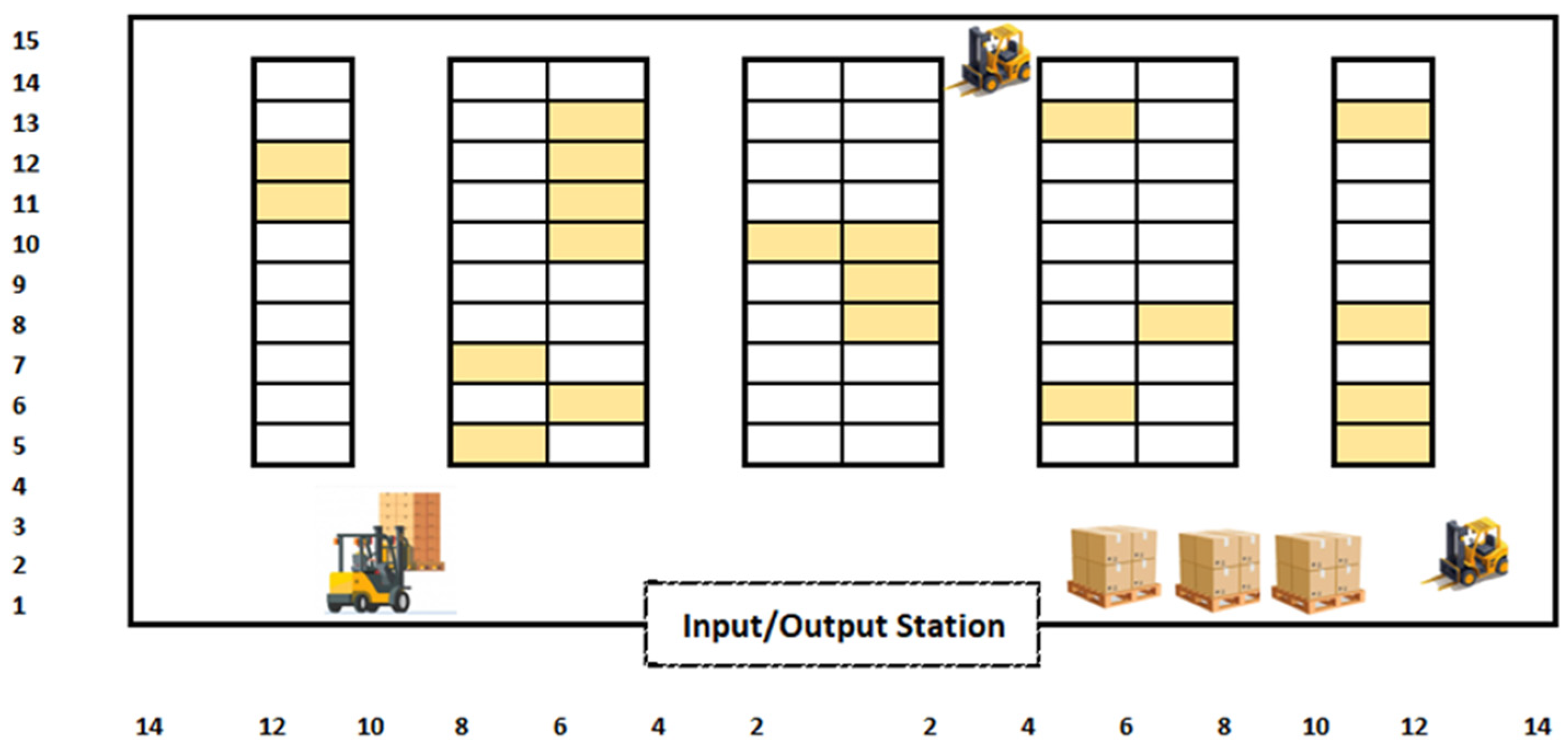
The products are transported from the input/output (I/O) station to the assigned storage locations in the warehouse. Both dedicated and randomized storage policy is applied for SLAP. As shown in
Figure 1, the warehouse layout is designed with wide aisles to ensure safe and efficient operation. To maximize storage capacity, vertical space is utilized with two storage levels available at each location. The I/O station, located in the center of the warehouse, serves both incoming and outgoing items. Each item represents a category of products, referred to as jobs. The warehouse is arranged into numbered locations for storage, with each location capable of holding a single pallet at a time. The total number of these locations is known in advance.
Various MHE, such as forklifts, trucks, and automated guided vehicles (AGVs), transport goods. All MHE are available at the start of the scheduling process and can access any storage location. However, they can only handle one job when moving a product to a storage location. No preemption or interruption is allowed during job processing. Products can only be handled when the needed and eligible machine and other required resources are available. Every product is moved and stored as pallets. These pallets vary in size, weight, and geometric configuration, hence the eligibility of specific machines to handle certain jobs. Due to the stacking of pallets above, beside, and in front of one another, precedence constraints exist between some jobs. In addition, a job can only be moved to a storage location if that location is unoccupied. This ensures that no overlap occurs with jobs stored previously in the exact location. Transportation times between the I/O station and storage locations depend on the machine and the location. On the other hand, processing times, which represent loading and unloading, are job- and MHE-dependent.
The key objective is to determine the optimal timing for moving products using the appropriate MHE and assigning storage locations, while minimizing transportation costs, waiting times, and lateness. Based on both D-SLAP and R-SLAP, three objectives need to be considered. The first objective () corresponds to the cost of transporting products using the appropriate MHE for the designated storage locations. The second objective () accounts for the waiting time of products at the I/O station before transferring them to their designated storage locations. The third objective () is the total tardiness in meeting the required due dates.
This research proposes a novel integrated optimization framework for simultaneous MHE scheduling and storage location assignment. Given the NP-hard complexity inherent to these combinatorial problems [
25], traditional exact solution methods become computationally intractable for practical-scale instances. To overcome this computational limitation, a customized NSGA-II implementation is proposed in this study, specifically designed for this integrated optimization challenge. The metaheuristic approach provides an efficient Pareto solution frontier while maintaining computational feasibility.
2.2. Non-Dominated Sorting Genetic Algorithm (NSGA-II)
NSGA-II is a widely adopted metaheuristic for solving multi-objective optimization problems [
26,
27]. Developed by Deb et al. (2002) [
28], NSGA-II employs a genetic algorithm framework to identify Pareto-optimal solutions through mechanisms such as selection, crossover, mutation, and Pareto-based ranking.
The algorithm begins by generating an initial population of feasible solutions randomly. This population evolves over iterations by applying different genetic operations such as selecting parents, crossover, mutation, and ranking solutions into non-dominated fronts. In the proposed technique, each solution (chromosome) is encoded using three distinct strings: (1) a job sequence, (2) a machine assignment, and (3) a location assignment. The length of each string corresponds to the number of jobs (N) to be scheduled. To ensure compliance with precedence constraints, a corrective algorithm proposed by Afzalirad et al. (2016) [
14] is used to adjust the job order and make it feasible. The machine assignment string is generated by randomly assigning an eligible machine to each job. The location assignment string varies depending on the storage policy.
Under D-SLAP, each job is assigned a dedicated storage location, ensuring that items do not share storage spaces.
Under R-SLAP, jobs are allocated to any available storage location at random.
An expanded double-point crossover operator is employed to explore neighborhood solutions. Using tournament selection, two parent chromosomes (Pr1 and Pr2) are selected. Two crossover points are randomly selected from a discrete uniform distribution, and gene segments between these points are exchanged to produce offspring (Ch1 and Ch2). The remaining positions in each child are filled with unassigned genes from the respective parent while preserving their original order.
To ensure feasibility, a corrective mechanism is applied to the job sequence strings. For the machine assignment strings, a random number (r ∈ [0,1]) is generated for each gene. If r > 0.5, the machine assignment is inherited from the opposite parent; otherwise, it is retained from the same parent. The location assignment follows a similar approach: if r > 0.5, the location is inherited from the parent; otherwise, a random feasible location is assigned. Post-crossover, a repair mechanism may be applied to maintain the feasibility of the generated solution.
A mutation operator enhances population diversity. A chromosome is randomly selected, and two genes in its job sequence string are swapped. If the resulting sequence violates precedence constraints, the correction mechanism is applied. For the machine assignment string, unchanged genes retain their parent assignments, while swapped genes undergo reassignment: if a number is randomly generated (r < 0.5), the original machine is retained; otherwise, a new eligible machine is selected. The location assignment string is generated based on the storage policy. For D-SLAP, each job is assigned a random dedicated storage location, while for R-SLAP, each job is assigned a random available storage location.
NSGA-II employs non-dominated sorting to classify solutions into Pareto fronts based on dominance relationships. Solutions within each front are further ranked using crowding distance, a measure of solution density in the objective space, to promote diversity. The algorithm terminates after a predefined number of iterations, yielding a set of non-dominated solutions.
2.3. Performance Metrics
Several metrics are used to evaluate the performance of multi-objective optimization algorithms [
29]. In this study, the used metrics are the number of solutions in the Pareto front (NPS), the Mean Ideal Distance (MID), a metric for diversification (DM), and a metric that evaluates the solutions’ dispersion (SNS). Finally, a Quality Metric (QM) that compares the dominance of solutions and calculates the percentage of solutions that belong to each storage policy is used. Equations (1) to (3) explain how these metrics are evaluated. In these equations, the index
refers to a Pareto front solution, while
is the
jth objective function value.
where
.
2.4. Parameter Tuning
Metaheuristic algorithms require careful parameter selection to ensure optimal performance. In this study, the Taguchi method is employed to determine the best parameter combinations for the NSGA-II algorithm. This approach efficiently evaluates multiple decision variables with fewer experiments by leveraging orthogonal arrays (OAs) instead of full factorial designs [
30].
For the proposed NSGA-II implementation, the following parameters are optimized: maximum number of iterations, population size, crossover rate, and mutation rate. An L9 OA is utilized to test each parameter at three distinct levels, as outlined in
Table 1. These levels are selected to accommodate both small and large test instances under D-SLAP and R-SLAP scenarios.
The NSGA-II algorithm is executed across all parameter combinations of the L9 OA, with each configuration evaluated over 10 replications. To assess performance, two key metrics are employed: Relative Percentage Deviation (RPD) and the signal-to-noise (S/N) ratio. The RPD, calculated using Equation (4), normalizes the acquired results. Here, the solution is the value of the performance measure acquired by each test instance, and Best is the best value of the performance measure obtained over all replications of this instance. The RPD provides a measure of the algorithms’ relative performance.
The Taguchi method only deals with one response variable. Therefore, the weighted mean of the performance measures (WMPM) is identified as in Equation (5).
In addition, the average value for 10 replications is calculated. The signal-to-noise (S/N) ratio is used to reduce the variation in the response variable. According to the Taguchi method, the S/N ratio for minimizing objectives is calculated using Equation (6).
The best parameter combinations for small- and large-sized instances are summarized in
Table 2. For each parameter of the NSGA-II algorithm, its best value is indicated as it provides a minimum value of WMPM and a maximum value of the S/N ratio.
Figure 2 and
Figure 3 display the average WMPM and signal-to-noise (S/N) ratio obtained for the NSGA-II algorithm at the different levels of the studied parameters, respectively. Accordingly,
Table 2 summarizes the best parameter combinations for the problem using D-SLAP and R-SLAP based on these figures.
4. Discussion
The performance of D-SLAP and R-SLAP was evaluated across three key objectives, with central tendency assessed using both the mean and median. The mean, as the arithmetic average, is ideal for symmetrically distributed data without outliers but is sensitive to extreme values. In contrast, the median, representing the middle value of an ordered dataset, is robust against outliers and preferable for skewed distributions. Under normality, the mean and median converge, whereas in skewed or outlier-laden data, the median provides a more reliable measure of central tendency. The selection between these metrics depends on the underlying data distribution.
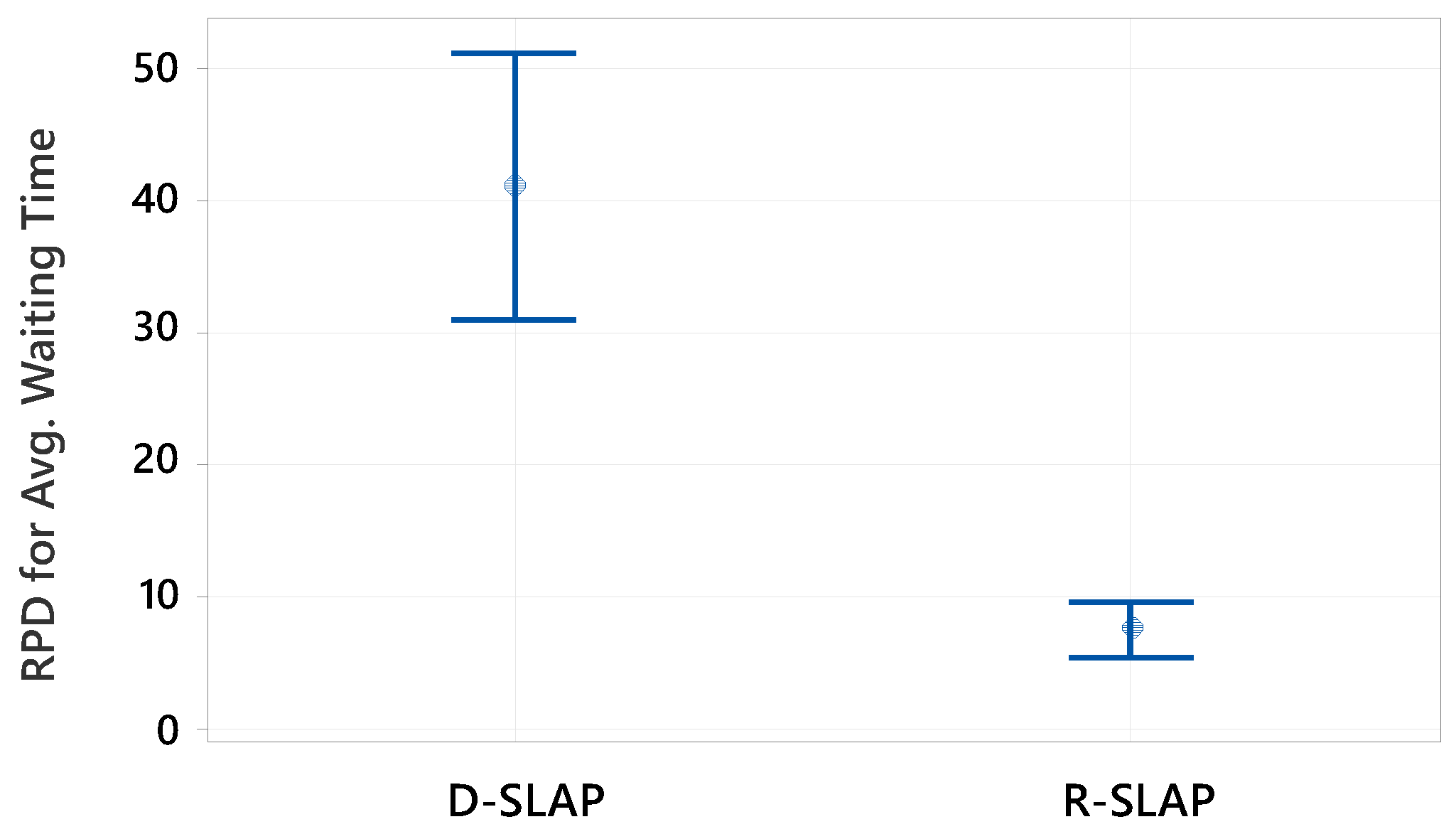
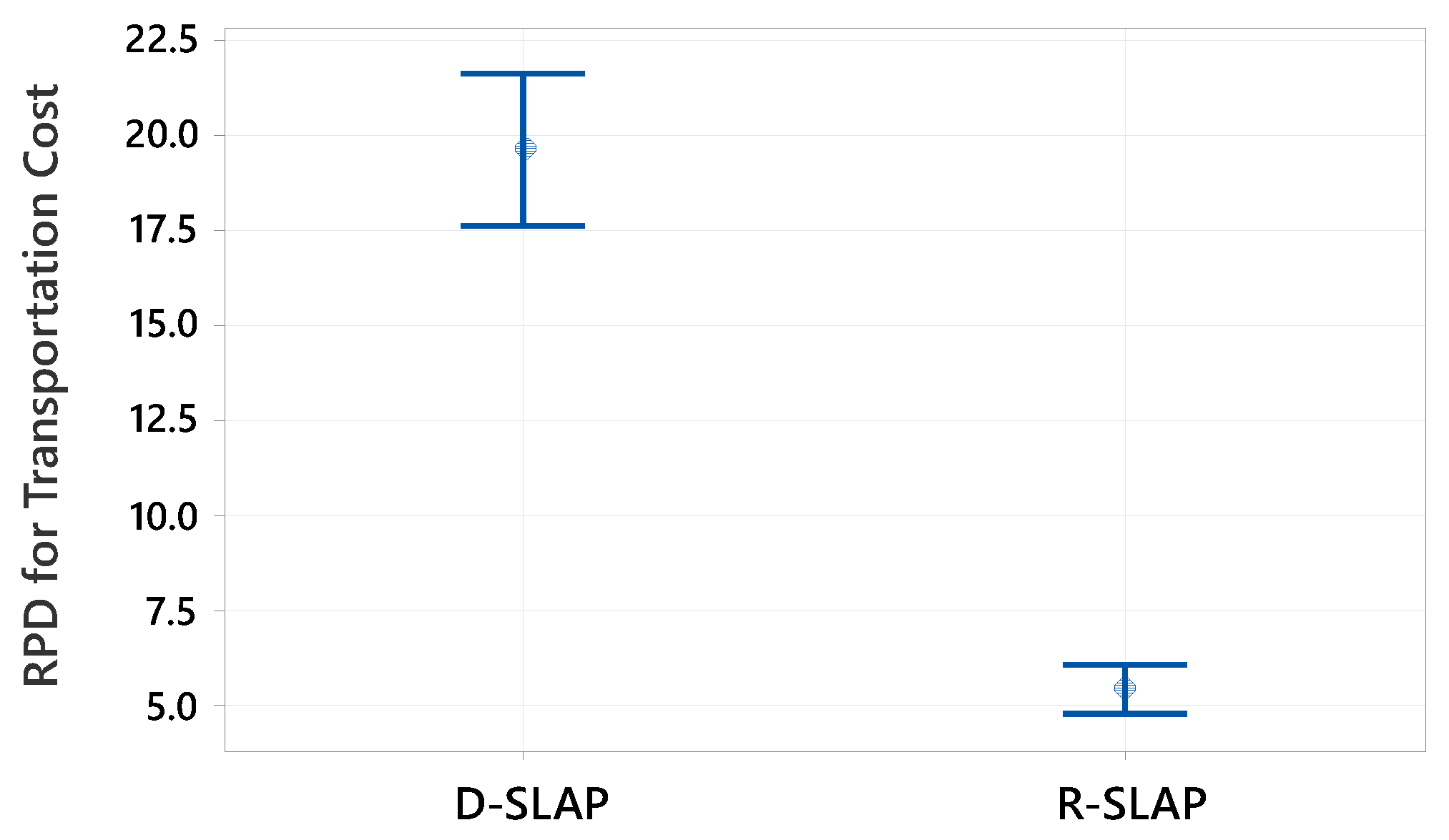
To compare policy performance, interval plots with 95% confidence intervals (CIs) were employed. However, since interval plots rely on aggregated data, they may obscure underlying variability. Therefore, formal hypothesis testing was conducted to rigorously assess the statistical significance of observed differences, accounting for paired data structures and ensuring population-level generalizability. Prior to test selection, normality testing (Shapiro–Wilk test) was performed, where a p-value < 0.05 indicated deviation from normality, necessitating non-parametric alternatives such as the Wilcoxon Signed Rank Test. Normally distributed data justified parametric tests, including the paired t-test.
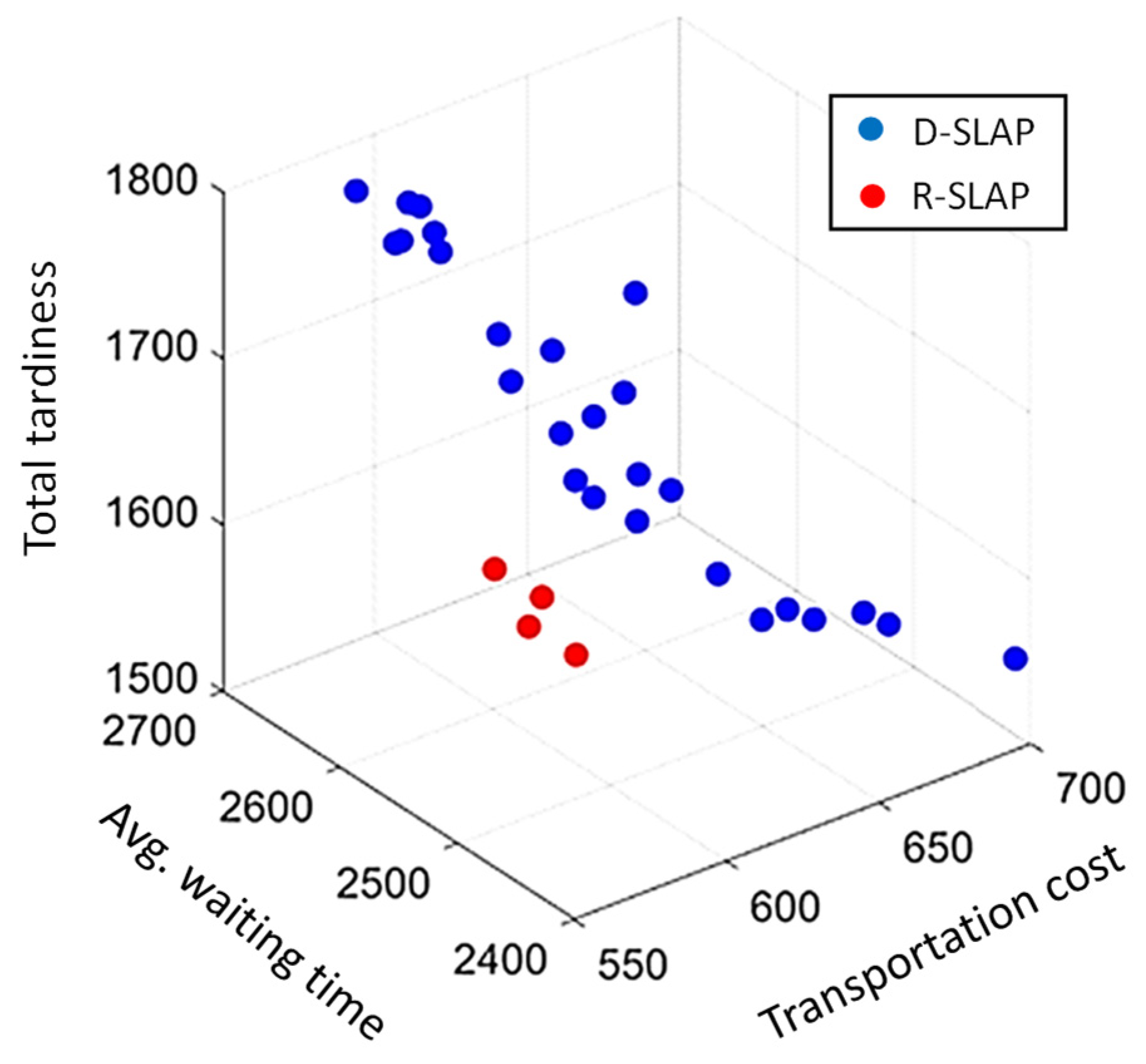
The RPD was considered for both policies for each of the 24 small and large-size test instances. The best objective value was calculated from each replication’s Pareto front. The differences between the ARPD values of D-DLAP and R-SLAP were calculated for each instance. This resulted in 12 paired differences per objective for each problem size. The Shapiro–Wilk test’s normality tests show different results for the three objectives. For small-sized test instances, the transportation cost shows normality (p-value > 0.100, RJ = 0.956); therefore, a paired t-test is appropriate. The average waiting time has non-normal data (p-value < 0.010, RJ = 0.833), suggesting using a Wilcoxon test. The total tardiness also has non-normal data (p-value < 0.010, RJ = 0.807), indicating the need for a non-parametric test due to non-normality and high variability. For large-size test instances, all three objective functions show approximately normal differences (p-values > 0.100, RJ values of 0.971, 0.979, and 0.965, respectively). This supports the use of a paired t-test for all three objectives. Overall, the differences for all objectives are approximately normally distributed, as indicated by p-values greater than 0.05 and high RJ values, making parametric tests such as the paired t-test suitable for further analysis.
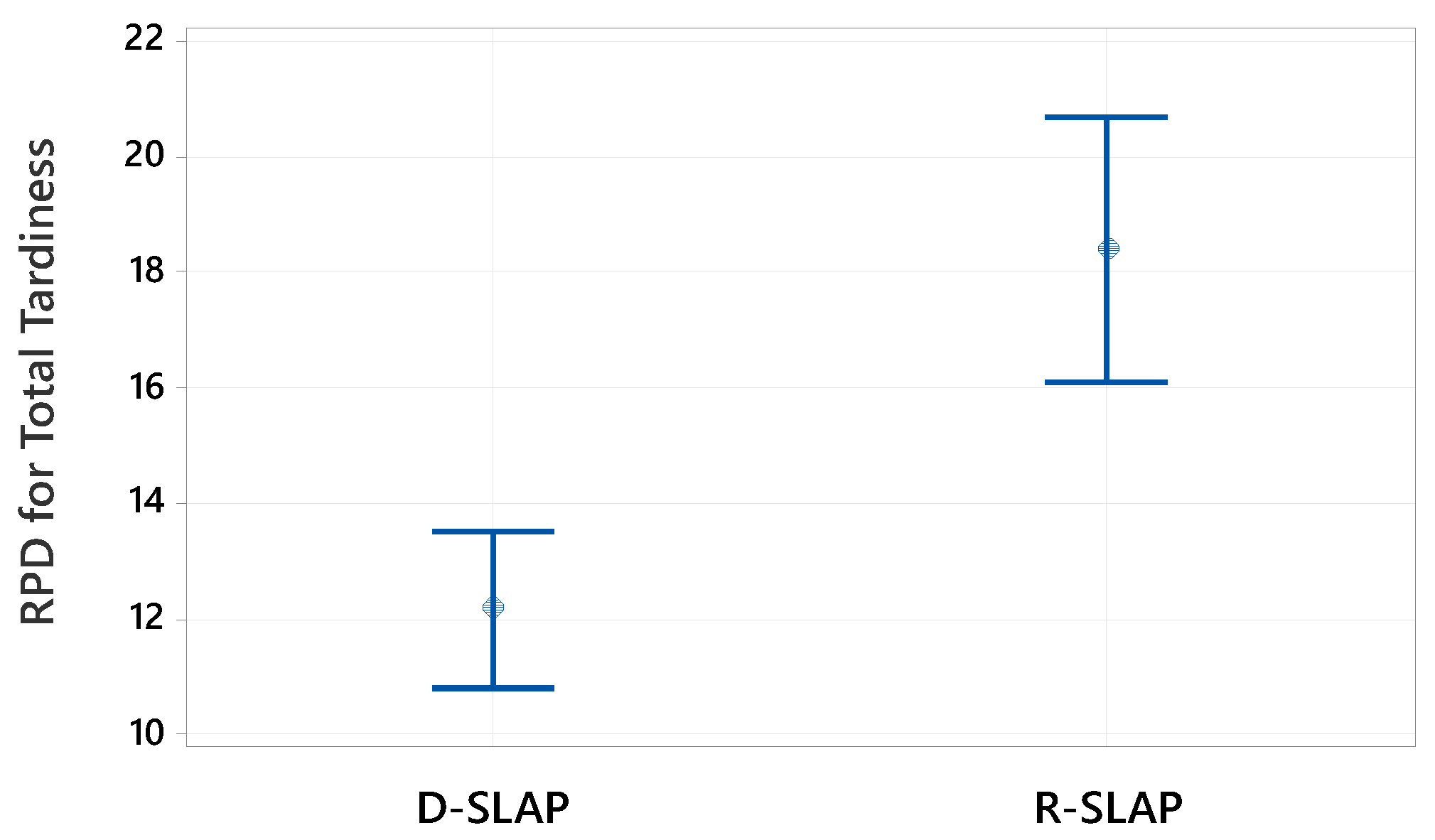
For the transportation cost related to small-size test instances, the paired t-test shows that D-SLAP significantly outperforms R-SLAP, with a mean ARPD difference of −18.81 for H0: μdifference = 0 and H1: μdifference < 0. For the average waiting time, the Wilcoxon Signed Rank Test shows a significant difference with a p-value of 0.021 and a median difference of 10.8521 for H0: μdifference = 0 and H1: μdifference > 0. This means D-SLAP performs worse than R-SLAP for this objective. For the total tardiness, the Wilcoxon Signed Rank Test shows a p-value of 0.944, greater than 0.05 for H0: μdifference < 0 and H1: μdifference ≠ 0. This means there is no significant difference between D-SLAP and R-SLAP, so they perform similarly for this objective.
Regarding the large-size test instances, the paired t-test is applied according to the normality test results of each objective. For the transportation cost, the paired t-test shows that D-SLAP significantly outperforms R-SLAP, with a mean ARPD difference of 14.17 for H0: μdifference = 0 and H1: μdifference > 0. This supports the results of the interval plot. For average waiting time, the paired t-test shows a significant difference with a p-value of 0.003 and a mean ARPD difference of −4.71 for H0: μdifference = 0 and H1: μdifference < 0. This means R-SLAP performs better than D-SLAP for this objective. For the total tardiness, the paired t-test shows a p-value of 0.010, less than 0.05 for H0: μdifference = 0 and H1: μdifference < 0. This means R-SLAP performs better than D-SLAP for this objective. It is worth noting that the choice of the alternative hypotheses is based on the results of the interval plots for the small- and large-sized test instances.
5. Conclusions
This study conducted a comparative analysis of two storage policies, D-SLAP and R-SLAP, to evaluate their impact on warehouse operations, integrating storage allocation with scheduling optimization. A customized NSGA-II metaheuristic was developed, incorporating three solution strings, job sequence, machine assignment, and location assignment, with policy-specific allocation logic. The model addressed multi-objective optimization, minimizing transportation costs, I/O station waiting times, and tardiness, while adhering to precedence, eligibility, and resource constraints. The Taguchi method was employed to optimize metaheuristic parameters for robustness.
This study provides valuable insights for warehouse managers seeking to optimize their operations. Key findings revealed that while both policies generated a similar number of optimal solutions, D-SLAP produced more uniformly distributed Pareto-optimal solutions, advantageous for scenarios requiring diverse alternatives. In contrast, R-SLAP yielded solutions closer to the ideal point, excelling in specific objectives. For small instances, D-SLAP outperformed R-SLAP in minimizing transportation costs. Both policies provide the same performance in terms of the total tardiness, whereas R-SLAP was superior in reducing waiting times. In large instances, R-SLAP dominated in transportation cost minimization, while D-SLAP excelled in waiting time and tardiness reduction. Statistical validation through parametric and non-parametric tests confirmed these performance differences, reinforcing the methodological rigor of the analysis.
From a practical standpoint, warehouse managers should select policies based on operational priorities: D-SLAP for balanced solution diversity and R-SLAP for targeted objective optimization. This research underscores the critical interplay between storage policies and scheduling, offering actionable insights for warehouse efficiency.
Future work should explore hybrid policies to leverage the strengths of both approaches. Additionally, incorporating dynamic supply–demand variability would enhance real-world applicability, while extending the model to include energy-efficient warehousing could address sustainability objectives.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}